学习日记_20241115_聚类方法(层次聚类)
前言
提醒:
文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。
其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展及意见建议,欢迎评论区讨论交流。
文章目录
- 前言
- 聚类算法
- 经典应用场景
- 层次聚类
- 优点
- 缺点
- 总结
- 简单实例(函数库实现)
- 数学表达
- 凝聚型层次聚类(Agglomerative Hierarchical Clustering)
- 分裂型层次聚类(Divisive Hierarchical Clustering)
- 1. 初始化
- 2. 选择分裂簇
- 4. 分裂方法
- 5. 更新簇的数量
- 6. 迭代过程
- 7. 结果表示
- 备注
- 手动实现
- 代码分析
- distance = euclidean_distance(point1, point2)
- agglomerative_clustering(points, distance_threshold=5)中distance_threshold
聚类算法
聚类算法在各种领域中有广泛的应用,主要用于发现数据中的自然分组和模式。以下是一些常见的应用场景以及每种算法的优缺点:
经典应用场景
-
市场细分:根据消费者的行为和特征,将他们分成不同的群体,以便进行有针对性的营销。
-
图像分割: 将图像划分为多个区域或对象,以便进行进一步的分析或处理。
-
社交网络分析:识别社交网络中的社区结构。
-
文档分类:自动将文档分组到不同的主题或类别中。
-
异常检测识别数据中的异常点或异常行为。
-
基因表达分析:在生物信息学中,根据基因表达模式对基因进行聚类。
层次聚类
层次聚类
层次聚类(Hierarchical
Clustering)是一种聚类分析方法,通过构建一个树状结构(或树形图),将数据集中的样本分组。层次聚类有两种主要类型:凝聚型(自下而上)和分裂型(自上而下)。以下是层次聚类的优缺点:优点
直观易理解:层次聚类通过树形图(Dendrogram)展示聚类结构,使得结果更直观易懂,方便分析数据之间的关系。
无需预先指定聚类数:与K-Means等方法不同,层次聚类不需要用户提前指定聚类的数量。用户可以根据树形图的结构选择适合的聚类数。
适用于各种类型的数据:可以处理任意类型的距离度量(如欧几里得距离、曼哈顿距离等),也可以应用于不规则形状的聚类。
适合小规模数据集:在小规模数据集上表现良好,可以提供更细致的聚类结果。
可嵌套的聚类结果:层次聚类可以生成不同层次的聚类,用户可以根据不同的需求选择不同的聚类层次。缺点
计算复杂度高:层次聚类的时间复杂度通常为 O ( n 3 ) O(n^3) O(n3) 或 O ( n 2 log n ) O(n^2 \log n) O(n2logn),因此在大规模数据集上可能会表现得非常缓慢。
对噪声和离群点敏感:层次聚类对数据中的噪声和离群点非常敏感,这可能会影响最终的聚类结果。
难以处理非球形簇:尽管层次聚类可以处理不同形状的聚类,但在实际应用中,很多实现仍然假设簇是球形的,因此对某些复杂形状的簇处理不佳。
合并或分裂的不可逆性:在凝聚型层次聚类中,一旦两个簇被合并,就无法再分开。这可能导致最终聚类结果不够灵活和准确。
选择距离度量和合并准则的挑战:层次聚类的结果对所选择的距离度量和合并准则(如单连接、全连接、平均连接等)非常敏感,不同的选择可能导致完全不同的聚类结果。总结
层次聚类是一种强大且直观的聚类方法,适合小规模数据集和探索性数据分析。然而,由于其计算复杂度高、对噪声敏感以及合并不可逆性等缺点,在处理大规模数据集或需要高效实时处理的场景中可能不够理想。在选择层次聚类时,用户应考虑数据的规模、特性以及所需的聚类精度。
简单实例(函数库实现)
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
# 生成随机数据
np.random.seed(42)
data = np.random.rand(10, 2) # 生成10个二维随机点
# 打印生成的数据点
print("Generated Data Points:")
print(data)
# 进行层次聚类
linked = linkage(data, method='ward') # 使用Ward方法进行聚类
# 绘制树形图
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(data[:, 0], data[:, 1], c='black')
# 在每个点旁边添加编号
for i, (x, y) in enumerate(zip(data[:, 0], data[:, 1])):plt.text(x, y, str(i), fontsize=15, ha='right')
plt.title('First Scatter Plot')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.subplot(1, 2, 2)
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title("Hierarchical Clustering Dendrogram")
plt.xlabel("Sample index")
plt.ylabel("Distance")
plt.show()#我们使用numpy生成10个二维的随机点,进行聚类分析。使用scipy.cluster.hierarchy.linkage函数
#进行层次聚类。在这个例子中,使用ward了方法,该方法最小化聚类间的方差。data数据分布与代码运行结果:

数学表达
层次聚类(Hierarchical Clustering)是一种将数据点逐步合并成类的聚类方法,形成一个树状结构(树形图,dendrogram)。它可以分为两种主要类型:凝聚型(Agglomerative)和分裂型(Divisive)。下面将结合数学表达式对其进行详细讲解。
凝聚型层次聚类(Agglomerative Hierarchical Clustering)
以下是凝聚型层次聚类的数学描述:
1. 初始化
假设有 n n n 个数据点 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn},初始时每个数据点作为一个独立的簇。记每个数据点对应的簇为 C i = { x i } C_i = \{x_i\} Ci={xi}。
2. 距离度量 为了判断簇之间的相似度,首先需要定义簇之间的距离。对于任意两个簇 C i C_i Ci 和 C j C_j Cj,选择一种距离度量方法,常见的有:
- 单链接(Single Linkage): d ( C i , C j ) = min x ∈ C i , y ∈ C j d ( x , y ) d(C_i, C_j) = \min_{x \in C_i, y \in C_j} d(x, y) d(Ci,Cj)=x∈Ci,y∈Cjmind(x,y)
- 全链接(Complete Linkage): d ( C i , C j ) = max x ∈ C i , y ∈ C j d ( x , y ) d(C_i, C_j) = \max_{x \in C_i, y \in C_j} d(x, y) d(Ci,Cj)=x∈Ci,y∈Cjmaxd(x,y)
- 平均链接(Average Linkage): d ( C i , C j ) = 1 ∣ C i ∣ ⋅ ∣ C j ∣ ∑ x ∈ C i ∑ y ∈ C j d ( x , y ) d(C_i, C_j) = \frac{1}{|C_i| \cdot |C_j|} \sum_{x \in C_i} \sum_{y \in C_j} d(x, y) d(Ci,Cj)=∣Ci∣⋅∣Cj∣1x∈Ci∑y∈Cj∑d(x,y)
- Ward方法: d ( C i , C j ) = ∣ C i ∣ ⋅ ∣ C j ∣ ∣ C i ∣ + ∣ C j ∣ ⋅ ∥ μ i − μ j ∥ 2 d(C_i, C_j) = \sqrt{\frac{|C_i| \cdot |C_j|}{|C_i| + |C_j|} \cdot \|\mu_i - \mu_j\|^2} d(Ci,Cj)=∣Ci∣+∣Cj∣∣Ci∣⋅∣Cj∣⋅∥μi−μj∥2 其中, μ i \mu_i μi 和 μ j \mu_j μj 分别是簇 C i C_i Ci 和 C j C_j Cj 的质心(均值)。在聚类分析中, ∣ C k ∣ |C_k| ∣Ck∣ 表示簇 C k C_k Ck中的数据点的数量,即簇 C k C_k Ck的大小。
3. 合并过程
在每一步中,找到距离最小的两个簇 C a C_a Ca 和 C b C_b Cb,然后合并它们: C n e w = C a ∪ C b C_{new} = C_a \cup C_b Cnew=Ca∪Cb
更新簇的数量: k = k − 1 k = k - 1 k=k−1
4. 更新距离矩阵 合并后,需要更新距离矩阵。对于新产生的簇 C n e w C_{new} Cnew 和其他簇 C k C_k Ck 的距离可以根据选择的距离度量方式进行计算。例如:
- 对于单链接: d ( C n e w , C k ) = min ( d ( C a , C k ) , d ( C b , C k ) ) d(C_{new}, C_k) = \min(d(C_a, C_k), d(C_b, C_k)) d(Cnew,Ck)=min(d(Ca,Ck),d(Cb,Ck))
- 对于全链接: d ( C n e w , C k ) = max ( d ( C a , C k ) , d ( C b , C k ) ) d(C_{new}, C_k) = \max(d(C_a, C_k), d(C_b, C_k)) d(Cnew,Ck)=max(d(Ca,Ck),d(Cb,Ck))
- 对于平均链接: d ( C n e w , C k ) = ∣ C a ∣ ⋅ d ( C a , C k ) + ∣ C b ∣ ⋅ d ( C b , C k ) ∣ C a ∣ + ∣ C b ∣ d(C_{new}, C_k) = \frac{|C_a| \cdot d(C_a, C_k) + |C_b| \cdot d(C_b, C_k)}{|C_a| + |C_b|} d(Cnew,Ck)=∣Ca∣+∣Cb∣∣Ca∣⋅d(Ca,Ck)+∣Cb∣⋅d(Cb,Ck)
- 对于Ward方法: d ( C n e w , C k ) = ∣ C n e w ∣ ⋅ ∣ C k ∣ ∣ C n e w ∣ + ∣ C k ∣ ⋅ ∥ μ n e w − μ k ∥ 2 d(C_{new}, C_k) = \sqrt{\frac{|C_{new}| \cdot |C_k|}{|C_{new}| + |C_k|} \cdot \|\mu_{new} - \mu_k\|^2} d(Cnew,Ck)=∣Cnew∣+∣Ck∣∣Cnew∣⋅∣Ck∣⋅∥μnew−μk∥2
其中, μ n e w \mu_{new} μnew 是合并后新簇的质心。5. 终止条件
重复步骤3和步骤4,直到所有数据点合并为一个簇,或者达到预定的簇数量 k k k。
6. 结果表示
最终结果可以用树形图(dendrogram)表示,展示了所有簇的合并过程及其对应的距离。
通过以上的数学表达和步骤,可以较为清晰地理解凝聚型层次聚类的过程及其特征。
分裂型层次聚类(Divisive Hierarchical Clustering)
分裂型层次聚类(Divisive Hierarchical Clustering)是与凝聚型层次聚类相反的方法,它从一个整体簇开始,然后逐步将其分裂成更小的簇。以下是分裂型层次聚类的数学表达和过程描述:
1. 初始化
假设有 n n n 个数据点 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn},初始时所有数据点都被视为一个单一的簇:
C = { X } C = \{X\} C={X}2. 选择分裂簇
在每一步,选择一个簇 C k C_k Ck 进行分裂。通常选择具有最大内部离散度的簇,以确保分裂后的簇之间的差异最大。>##### 3. 距离度量
定义簇的离散度(内部距离),可以使用某种度量,例如簇的总方差:
D ( C k ) = ∑ x ∈ C k d ( x , μ k ) 2 D(C_k) = \sum_{x \in C_k} d(x, \mu_k)^2 D(Ck)=x∈Ck∑d(x,μk)2
其中 μ k \mu_k μk 是簇 C k C_k Ck 的质心, d ( x , μ k ) d(x, \mu_k) d(x,μk) 是数据点 x x x 到簇质心的距离。4. 分裂方法
选择一个适当的分裂方法(例如 K-means)。假设我们将簇 C k C_k Ck 分裂为两个子簇 C k 1 C_{k1} Ck1 和 C k 2 C_{k2} Ck2:
C k → C k 1 , C k 2 C_k \rightarrow C_{k1}, C_{k2} Ck→Ck1,Ck25. 更新簇的数量
增加新的簇数量:
m = m + 1 m = m + 1 m=m+16. 迭代过程
重复步骤 2 到 5,直到达到预定的簇数量 k k k 或者所有簇都无法再分裂为止。
7. 结果表示
最终结果可以用树形图(dendrogram)表示,展示了所有簇的分裂过程及其对应的离散度。
备注
在分裂型层次聚类中,选择分裂的方式和度量内部离散度的标准会显著影响聚类的结果。常用的分裂方法包括 K-means 算法、PCA 等。
手动实现
import numpy as np# 计算两个样本之间的欧氏距离
def euclidean_distance(a, b):return np.sqrt(np.sum((a - b) ** 2))# 计算簇之间的距离,这里使用最小距离法
def calculate_cluster_distance(cluster1, cluster2):min_distance = float('inf')for point1 in cluster1:for point2 in cluster2:distance = euclidean_distance(point1, point2)if distance < min_distance:min_distance = distancereturn min_distance# 初始化簇,每个样本作为一个簇
def initialize_clusters(points):return [[point] for point in points]# 找到距离最近的两个簇
def find_closest_clusters(clusters):min_distance = float('inf')pair = (None, None)for i in range(len(clusters)):for j in range(i + 1, len(clusters)):distance = calculate_cluster_distance(clusters[i], clusters[j])if distance < min_distance:min_distance = distancepair = (i, j)return pair# 合并两个簇
def merge_clusters(clusters, pair):i, j = pairmerged_cluster = clusters[i] + clusters[j]clusters.pop(j)clusters.pop(i)clusters.append(merged_cluster)return clusters# 凝聚型层次聚类
def agglomerative_clustering(points, distance_threshold):clusters = initialize_clusters(points)while len(clusters) > 1:closest_pair = find_closest_clusters(clusters)if calculate_cluster_distance(clusters[closest_pair[0]], clusters[closest_pair[1]]) > distance_threshold:breakclusters = merge_clusters(clusters, closest_pair)return clusters# 示例数据
points = np.array([[1, 2], [2, 2], [5, 8], [1, 3], [8, 8], [9, 10]])# 调用凝聚型层次聚类算法
clusters = agglomerative_clustering(points, distance_threshold=5)# 打印结果
for i, cluster in enumerate(clusters):print(f"Cluster {i+1}: {cluster}")
结果为:
代码分析
distance = euclidean_distance(point1, point2)
对于
points列表中的每一个元素point,将其放入一个新列表中,然后将这些新列表组成一个新的列表。agglomerative_clustering(points, distance_threshold=5)中distance_threshold
distance_threshold(距离阈值):在聚类分析中,这是用来决定两个簇是否应该被视为“接近”或“相似”的临界值。如果两个簇之间的距离小于或等于这个阈值,则通常认为这两个簇足够接近,可以考虑将它们合并;如果距离大于这个阈值,则认为它们是独立的,不应该合并。
代码为,如果计算得出的两个最近簇(clusters[closest_pair[0]]和clusters[closest_pair[1]])之间的距离大于给定的距离阈值(distance_threshold),那么执行if语句块中的代码:运行结束。
相关文章:

学习日记_20241115_聚类方法(层次聚类)
前言 提醒: 文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。 其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展…...

安卓开发怎么获取返回上一级activity事件
在Android开发中,要获取返回上一级Activity的事件,通常是通过点击设备上的返回按钮或者在代码中调用finish()方法时触发的。为了处理这个事件,你可以在当前Activity中重写onBackPressed()方法。 以下是一个简单的例子: Override…...

神经网络与Transformer详解
一、模型就是一个数学公式 模型可以描述为:给定一组输入数据,经过一系列数学公式计算后,输出n个概率,分别代表该用户对话属于某分类的概率。 图中 a, b 就是模型的参数,a决定斜率,b决定截距。 二、神经网络的公式结构 举例:MNIST包含了70,000张手写数字的图像,其中…...

C语言之MakeFile
Makefile 的引入是为解决多文件项目中手动编译繁琐易错、缺乏自动化构建、项目管理维护困难以及跨平台构建不便等问题,实现自动化、规范化的项目构建与管理 MakeFile 简单的来说,MakeFile就是编写编译命令的文件 文件编写格式 目标:依赖文件列表 <Tab>命令列表…...

vue项目PC端和移动端实现在线预览docx、excel、pdf文件
可以参考vue-office官方github:GitHub - loonghe/vue-office: 支持word(.docx)、excel(.xlsx,.xls)、pdf等各类型office文件预览的vue组件集合,提供一站式office文件预览方案,支持vue2和3,也支持React等非Vue框架。…...
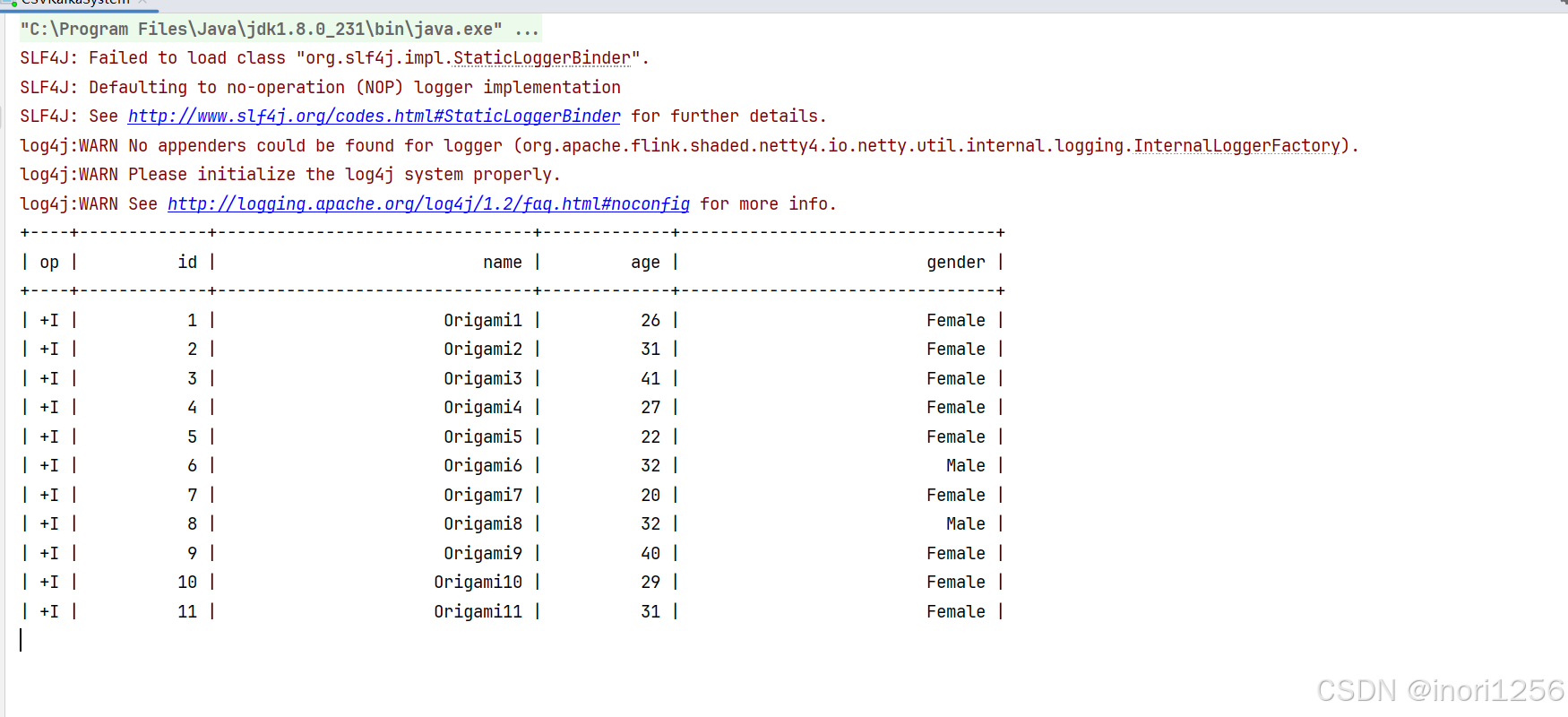
FlinkSql读取kafka数据流的方法(scala)
我的scala版本为2.12 <scala.binary.version>2.12</scala.binary.version> 我的Flink版本为1.13.6 <flink.version>1.13.6</flink.version> FlinkSql读取kafka数据流需要如下依赖: <dependency><groupId>org.apache.flink&…...

.NET 9 中 IFormFile 的详细使用讲解
在.NET应用程序中,处理文件上传是一个常见的需求。.NET 9 提供了 IFormFile 接口,它可以帮助我们轻松地处理来自客户端的文件上传。以下是 IFormFile 的详细使用讲解。 IFormFile 接口简介 IFormFile 是一个表示上传文件的接口,它提供了以下…...
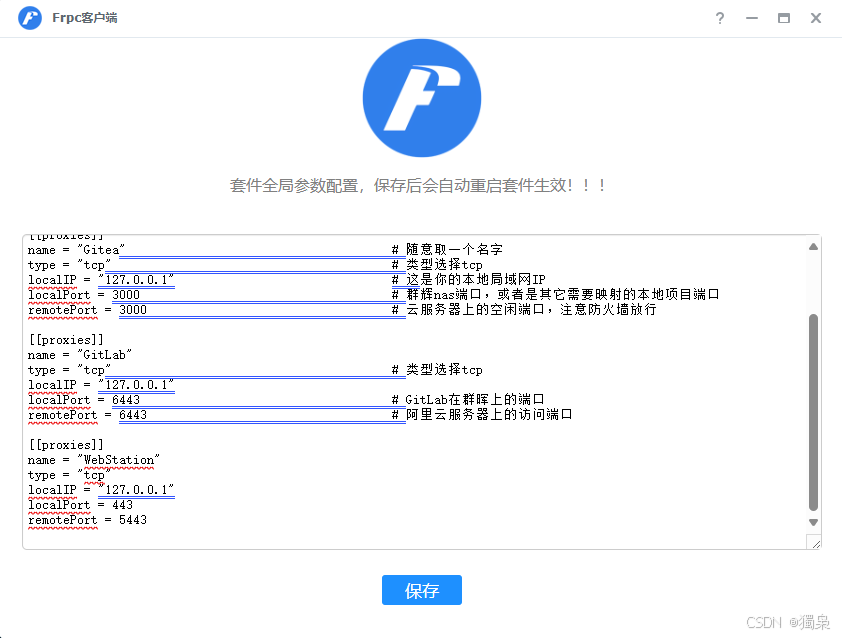
使用阿里云远程访问 Synology Web Station 的指南
使用阿里云远程访问 Synology Web Station 的指南 本文将指导如何通过阿里云服务器配置 Nginx 和 FRP,远程访问部署在 Synology NAS 上的 Web Station 服务,同时支持 HTTPS 安全访问。 背景 通过 Synology NAS 的 Web Station,可以部署 Wor…...

LlamaFactory介绍
目录 一、什么是LlamaFactory 1. 安装 LlamaFactory 2. 下载 LLaMA 模型 3. 运行 LLaMA 模型 4. 微调 LLaMA 模型 5. 优化本地运行 6. 推理加速 7. 硬件要求 二、总结 一、什么是LlamaFactory LlamaFactory 是一个用于训练和运行 LLaMA(Meta 的开源大型语言模型)模型…...
vue 项目使用 nginx 部署
前言 记录下使用element-admin-template 改造项目踩过的坑及打包部署过程 一、根据权限增加动态路由不生效 原因是Sidebar中路由取的 this.$router.options.routes,需要在计算路由 permission.js 增加如下代码 // generate accessible routes map based on roles const acce…...

<项目代码>YOLOv8 玉米地杂草识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…...

Wxml2Canvas小程序将dom转为图片,bug总结
1.显示文字 标签上面使用 data-type"text" 加上class名 <view data-type"text" class"my_draw_canvas"><text data-type"text" class"center my_draw_canvas" data-text"企业出游证明">企业出游证明…...

[ 网络安全介绍 3 ] 网络安全事件相关案例有哪些?
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

SpringMVC学习笔记(二)
五、Rest风格编程 (一)Rest风格URL规范介绍 1、什么是restful RESTful架构,就是目前最流行的一种互联网软件架构风格。它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。REST这个词,是Roy T…...

51c嵌入式~单片机合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/12362395 一、不同的电平信号的MCU怎么通信? 下面这个“电平转换”电路,理解后令人心情愉快。电路设计其实也可以很有趣。 先说一说这个电路的用途:当两个MCU在不同的工作电压下工作&…...

JavaScript:浏览器对象模型BOM
BOM介绍 浏览器对象模型(Brower Object Model,BOM)提供了独立于内容而与浏览器窗口进行交互的对象,其核心对象是window BOM由一系列相关的对象构成,并且每个对象都提供了很多方法和属性。 BOM与DOM区别 DOM是文档对…...

Unity音频导入设置
参考:unity官方文档 导入设置 Force To Mono:强制单声道。启用后音频片段将降混为单声道声音。可以节省该资源所占据的空间。 Normalize:峰值归一化。降混过程通常会导致信号比原始信号更安静。峰值归一化的信号为音频源的音量属性提供了后…...

【数据分享】中国对外投资合作发展报告(2013-2023)
数据介绍 绪 论............................................................................................................................. 1 对外投资合作高质量发展迈出新步伐................................................................... 2 第一篇 发…...

java8之Stream流
文章目录 Stream流的定义和特性定义特性中间操作终结操作 生成流forEachmapfilterlimitsorted并行(parallel)程序Collectors Stream流的定义和特性 定义 Stream是Java 8 API添加的一个新的抽象,用于以声明性方式处理数据集合。它…...

pipx安装提示找不到包
执行: pipx install --include-deps --force "ansible6.*"WARNING: Retrying (Retry(total4, connectNone, readNone, redirectNone, statusNone)) after connection broken by NewConnectionError(<pip._vendor.urllib3.connection.HTTPSConnection …...

Docker化部署KingbaseES V9:从镜像导入到开发版License激活实战
1. 为什么选择Docker部署KingbaseES V9? 在开发测试环境中,传统数据库安装方式往往需要耗费大量时间在环境配置和依赖解决上。我去年参与的一个政务云项目就遇到过这种情况:团队花了三天时间在不同操作系统的测试机上反复折腾依赖库ÿ…...
)
告别wx.startRecord!微信小程序录音功能保姆级教程(RecorderManager全解析)
微信小程序录音功能深度重构指南:从wx.startRecord到RecorderManager的完整迁移方案 在微信小程序开发生态中,音频处理能力一直是实现丰富交互体验的核心组件之一。随着技术架构的持续优化,微信团队对录音API进行了重大升级,用更现…...

STR912评估板UART0通信故障排查与解决方案
1. MCBSTR9评估板UART0通信故障排查指南最近在调试STR912芯片的串口通信时,发现一个硬件设计上的"坑"值得分享。使用Keil MCBSTR9评估板V2版本时,UART0(COM1)接口竟然无法正常工作!经过一番排查,…...

【免费下载】 慧荣SM2258XT开卡工具集合
慧荣SM2258XT开卡工具集合 【下载地址】慧荣SM2258XT开卡工具集合 本仓库提供了一套专门针对慧荣SM2258XT主控的固态硬盘、移动硬盘及SSDM.2硬盘的开卡工具集合。该工具集合旨在解决因主控问题导致的设备无法识别、不识别或容量显示错误等问题。通过使用本工具包,您…...

vibe coding效率高:一个新mcp server已经试运行尚可
下面是文档: judicial-doc-quality-mcp v0.1.0 司法裁判文书质量评估 MCP 服务器 — 桥接架构,零 LLM 调用 English | 中文 概述 judicial-doc-quality-mcp 是一个基于 Model Context Protocol (MCP) 的裁判文书质量评估服务器,采用**桥接…...

Bubble Navigation实战:构建现代化电商App导航系统的终极指南
Bubble Navigation实战:构建现代化电商App导航系统的终极指南 【免费下载链接】bubble-navigation 🎉 [Android Library] A light-weight library to easily make beautiful Navigation Bar with ton of 🎨 customization option. 项目地址…...

SBA系列生物传感分析仪的工作原理是什么?
SBA系列生物传感分析仪利用酶促反应来进行定量分析,测定的关键传感器是固定化酶和过氧化氢电极复合传感器,分析过程基于以下生化反应:底物 固定化酶膜 → 产物谷氨酸 谷氨酸氧化酶 α-酮戊二酸葡萄糖 葡萄糖氧化…...

AI智能体的开发与测试
AI智能体(AI Agent)的开发与测试是一项将大语言模型(LLM)能力转化为企业级稳定应用的系统工程。它不仅需要先进的算法,更依赖于严密的工程架构与创新的测试方法。以下是AI智能体开发与测试的全景指南:第一部…...

边缘云环境下数据流模型FlowUnits的设计与实践
1. 数据流模型的演进与边缘云挑战数据流计算作为分布式系统领域的核心范式,已经深刻改变了我们处理海量数据的方式。这种基于有向无环图(DAG)的计算模型,通过将数据处理逻辑分解为独立的算子(operator)并明…...

【开源】基于 ASP.NET Core Blazor Server 10.0 构建的学生信息查询系统
学生查询系统基于 ASP.NET Core Blazor Server 10.0 构建的学生信息查询系统,使用 Excel 文件作为数据源,支持动态列适配和响应式布局。功能特性灵活查询:支持按姓名、学号进行模糊查询,可单独或组合使用动态列适配:不…...