24/11/14 算法笔记 GMM高斯混合模型
高斯混合模型(Gaussian Mixture Model,简称 GMM)是一种概率模型,用于表示具有多个子群体的数据集,其中每个子群体的数据分布可以用高斯分布(正态分布)来描述。GMM 是一种软聚类方法,意味着它为每个数据点分配一个属于每个聚类的概率分布,而不是硬聚类方法中的严格分类。
GMM 的组成
一个 GMM 由以下几个部分组成:
- 聚类数量(K):模型中高斯分布(聚类)的数量。
- 均值向量(μkμk):每个高斯分布的均值向量,其中 kk 表示聚类索引。
- 协方差矩阵(ΣkΣk):每个高斯分布的协方差矩阵,描述了数据在各个维度上的分布范围和形状。
- 混合系数(πkπk):每个高斯分布的权重,表示数据属于该聚类的概率,所有混合系数之和为1。
GMM 的数学表达
GMM 的概率密度函数(PDF)可以表示为:


GMM 的学习
GMM 的参数学习通常使用 EM 算法进行,EM算法前面有将,是一个策略优化算法
24/11/14 算法笔记 EM算法期望最大化算法-CSDN博客
我们来看一下简单的GMM源代码
import numpy as np
from scipy.stats import multivariate_normalclass GaussianMixture:def __init__(self, n_components, covariance_type='full', n_iter=100, random_state=None):self.n_components = n_components # 聚类数量self.covariance_type = covariance_type # 协方差类型self.n_iter = n_iter # 迭代次数self.random_state = random_state # 随机种子self.weights_ = None # 混合系数self.means_ = None # 均值self.covariances_ = None # 协方差def _initialize_parameters(self, X):"""随机初始化均值、协方差和权重"""n_samples, n_features = X.shapeself.weights_ = np.ones(self.n_components) / self.n_components # 初始化权重random_indices = np.random.choice(n_samples, self.n_components, replace=False)self.means_ = X[random_indices] # 随机选择均值self.covariances_ = np.array([np.eye(n_features)] * self.n_components) # 初始化协方差为单位矩阵def _e_step(self, X):"""E步骤:计算每个数据点属于每个高斯分布的责任"""n_samples = X.shape[0]responsibilities = np.zeros((n_samples, self.n_components))for k in range(self.n_components):rv = multivariate_normal(mean=self.means_[k], cov=self.covariances_[k])responsibilities[:, k] = self.weights_[k] * rv.pdf(X)# 归一化责任responsibilities /= responsibilities.sum(axis=1, keepdims=True)return responsibilitiesdef _m_step(self, X, responsibilities):"""M步骤:更新均值、协方差和权重"""n_samples = X.shape[0]effective_n = responsibilities.sum(axis=0) # 每个聚类的有效样本数量# 更新权重self.weights_ = effective_n / n_samples# 更新均值self.means_ = np.dot(responsibilities.T, X) / effective_n[:, np.newaxis]# 更新协方差for k in range(self.n_components):diff = X - self.means_[k]self.covariances_[k] = np.dot(responsibilities[:, k] * diff.T, diff) / effective_n[k]def fit(self, X):"""训练模型"""self._initialize_parameters(X) # 初始化参数for _ in range(self.n_iter): # 迭代更新responsibilities = self._e_step(X) # E步骤self._m_step(X, responsibilities) # M步骤def predict(self, X):"""预测数据点的聚类标签"""responsibilities = self._e_step(X) # 计算责任return np.argmax(responsibilities, axis=1) # 返回最大责任的聚类索引def sample(self, n_samples):"""从模型中生成新样本"""samples = np.zeros((n_samples, self.means_.shape[1]))for i in range(n_samples):k = np.random.choice(self.n_components, p=self.weights_) # 根据权重选择聚类samples[i] = np.random.multivariate_normal(self.means_[k], self.covariances_[k]) # 生成样本return samples接下来让我们分析下每段代码
1.初始化函数 __init__
def __init__(self, n_components, covariance_type='full', n_iter=100, random_state=None):self.n_components = n_components # 聚类数量self.covariance_type = covariance_type # 协方差类型self.n_iter = n_iter # 迭代次数self.random_state = random_state # 随机种子self.weights_ = None # 混合系数self.means_ = None # 均值self.covariances_ = None # 协方差这是类的构造函数,用于初始化GMM模型的参数:
n_components:模型中高斯分布(聚类)的数量。covariance_type:协方差矩阵的类型,可以是'full'、'diag'或'spherical',分别表示全协方差、对角协方差和球面协方差。n_iter:EM算法的最大迭代次数。random_state:随机数生成器的种子,用于结果的可重复性。weights_、means_和covariances_:这些属性将在模型训练后存储模型参数。
2.参数初始化函数 _initialize_parameters
def _initialize_parameters(self, X):"""随机初始化均值、协方差和权重"""n_samples, n_features = X.shapeself.weights_ = np.ones(self.n_components) / self.n_components # 初始化权重random_indices = np.random.choice(n_samples, self.n_components, replace=False)self.means_ = X[random_indices] # 随机选择均值self.covariances_ = np.array([np.eye(n_features)] * self.n_components) # 初始化协方差为单位矩阵这个函数用于随机初始化模型参数:
self.weights_:权重初始化为均等分布。self.means_:均值初始化为数据集中随机选择的点。self.covariances_:协方差矩阵初始化为单位矩阵,适用于全协方差情况。- 协方差可以告诉我们两个变量是如何一起变化的。如果两个变量的协方差是正的,那么它们倾向于朝相同的方向变化;如果协方差是负的,那么一个变量增加时,另一个变量倾向于减少。
3.E步骤函数 _e_step
def _e_step(self, X):"""E步骤:计算每个数据点属于每个高斯分布的责任"""n_samples = X.shape[0]responsibilities = np.zeros((n_samples, self.n_components))for k in range(self.n_components):#函数用于生成符合多元正态分布的随机样本。rv = multivariate_normal(mean=self.means_[k], cov=self.covariances_[k])responsibilities[:, k] = self.weights_[k] * rv.pdf(X)# 归一化责任responsibilities /= responsibilities.sum(axis=1, keepdims=True)return responsibilitiesE步骤计算每个数据点属于每个高斯分布的责任(后验概率):
- 使用
multivariate_normal.pdf计算每个高斯分布的PDF值。 - 将每个高斯分布的PDF值乘以相应的权重,得到未归一化的责任。
- 通过将每个数据点的责任除以其总和来归一化责任,确保每个数据点的责任之和为1。
PDF值通常指的是概率密度函数(Probability Density Function)的值。概率密度函数是连续概率分布的一个核心概念,它描述了随机变量在给定区间内取值的概率密度。对于连续随机变量,其概率密度函数的图形可以告诉我们随机变量取某个特定值的可能性。
4.M步骤函数 _m_step
def _m_step(self, X, responsibilities):"""M步骤:更新均值、协方差和权重"""n_samples = X.shape[0]effective_n = responsibilities.sum(axis=0) # 每个聚类的有效样本数量# 更新权重self.weights_ = effective_n / n_samples# 更新均值self.means_ = np.dot(responsibilities.T, X) / effective_n[:, np.newaxis]# 更新协方差for k in range(self.n_components):diff = X - self.means_[k]self.covariances_[k] = np.dot(responsibilities[:, k] * diff.T, diff) / effective_n[k]M步骤根据E步骤计算的责任更新模型参数:
self.weights_:权重更新为每个聚类的有效样本数量除以总样本数量。self.means_:均值更新为加权平均,权重是每个数据点对每个聚类的责任。self.covariances_:协方差更新为加权的样本偏差的外积,权重是每个数据点对每个聚类的责任。
5.训练函数 fit
def fit(self, X):"""训练模型"""self._initialize_parameters(X) # 初始化参数for _ in range(self.n_iter): # 迭代更新responsibilities = self._e_step(X) # E步骤self._m_step(X, responsibilities) # M步骤- 首先调用
_initialize_parameters函数初始化参数。 - 然后进行指定次数的迭代,每次迭代都包括E步骤和M步骤。
6.预测函数 predict
def predict(self, X):"""预测数据点的聚类标签"""responsibilities = self._e_step(X) # 计算责任return np.argmax(responsibilities, axis=1) # 返回最大责任的聚类索引- 首先调用
_e_step函数计算新数据点对每个聚类的责任。 - 然后返回责任最大的聚类索引作为预测标签。
7.采样函数 sample
def sample(self, n_samples):"""从模型中生成新样本"""samples = np.zeros((n_samples, self.means_.shape[1]))for i in range(n_samples):k = np.random.choice(self.n_components, p=self.weights_) # 根据权重选择聚类samples[i] = np.random.multivariate_normal(self.means_[k], self.covariances_[k]) # 生成样本return samples- 首先初始化一个空的样本数组。
- 然后根据每个聚类的权重随机选择一个聚类。
- 从选定的聚类对应的高斯分布中生成一个样本。
- 重复上述过程,直到生成所需数量的样本。
相关文章:
24/11/14 算法笔记 GMM高斯混合模型
高斯混合模型(Gaussian Mixture Model,简称 GMM)是一种概率模型,用于表示具有多个子群体的数据集,其中每个子群体的数据分布可以用高斯分布(正态分布)来描述。GMM 是一种软聚类方法,…...

Linux下编译安装Nginx
以下是在Linux下编译安装Nginx的详细步骤: 一、安装依赖库 安装基本编译工具和库 在Debian/Ubuntu系统中,使用以下命令安装:sudo apt -y update sudo apt -y install build - essential libpcre3 - dev zlib1g - dev libssl - dev在CentOS/…...

算力100问☞第4问:算力的构成元素有哪些?
算力的构成元素是一个多维度且相互交织的体系,它融合了硬件基础设施、软件优化策略、数据处理效能以及分布式计算技术等多个层面,共同塑造了强大的计算能力。具体如下: 1、硬件基础设施 中央处理器(CPU):…...

安装paddle
网址:飞桨PaddlePaddle-源于产业实践的开源深度学习平台 或者找对应python和cuda版本的paddle下载后安装: https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html 你想要安装paddlepaddle - gpu2.6.1.post112版本。在你提供的文件列表中&am…...

飞凌嵌入式RK3576核心板已适配Android 14系统
在今年3月举办的RKDC2024大会上,飞凌嵌入式FET3576-C核心板作为瑞芯微RK3576处理器的行业首秀方案重磅亮相,并于今年6月率先量产发货,为客户持续稳定地供应,得到了众多合作伙伴的认可。 FET3576-C核心板此前已提供了Linux 6.1.57…...
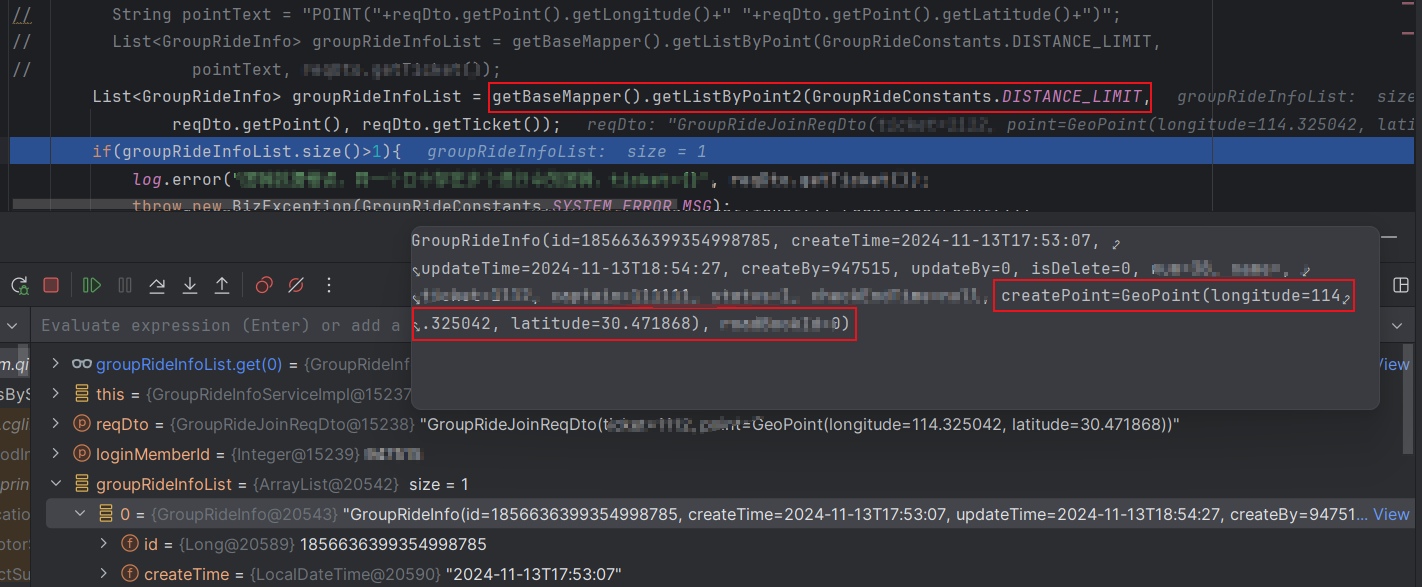
SpringBoot+MyBatis+MySQL的Point实现范围查找
前言 最近做了一个功能,需要通过用户当前位置点获取指定范围内的数据。由于后端存储用的是 MySQL,故选择使用 MySQL 中的 Point 实现范围查找功能。ORM 框架用的是 MyBatis,MyBatis 原生并不支持 Point 字段与 POJO 的映射,需要自…...

【Apache Paimon】-- 1 -- Apache Paimon 是什么?
目录 1、简介 2、概览 3、哪些场景可以使用 Paimon 4、周边生态 5、小结 6、参考 1、简介 我们听说过数据仓库、数据湖、数据湖仓,那你听说过流式数据仓库(Stream warehouse,简称:Streamhouse)吗?那我们今天就来解锁看看他们之中的新秀: Apache paimon 到底是什么…...

解决VsCode无法跳转问题
在settings.json中加入以下代码 { "files.associations": { "*.c":"c", "*.h":"c", "*.s":"masm" }, "includePath":[ "${workspaceFold…...

优化C++设计模式:用模板代替虚函数与多态机制
文章目录 0. 引言1. 模板编程替换虚函数和多态的必要性1.1. MISRA C对类型转换和虚函数的规定1.2. 虚函数与多态问题的影响及如何适应MISRA C要求1.3. 模板编程的优势:替代虚函数和多态机制 2. 设计模式改进2.1. 单例模式的改进与静态局部变量的对比(第二种实现) 2.…...

浪浪云轻量服务器搭建vulfocus网络安全靶场
什么是网络安全靶场 网络安全靶场是一个模拟真实网络环境的训练平台,旨在为网络安全专业人员提供一个安全的环境来测试和提高他们的技能。靶场通常包括各种网络设备、操作系统、应用程序和安全工具,允许用户在其中进行攻击和防御练习。以下是网络安全靶…...

C++builder中的人工智能(23):在现代C++ Windows上轻松录制声音
在这篇文章中,我们将探讨如何在现代C Windows上轻松录制声音。声音以波形和数字形式存在,其音量随时间变化。在C Builder中,使用Windows设备进行录音非常简单。要录制声音,在多设备应用程序中,必须使用FMX.Media.hpp头…...

避免误差!Android 中正确计算时间差的方式
在 Android 开发中,计时和计算时间差异是非常常见的需求,比如记录事件发生的间隔、统计应用启动时间、测量网络请求的响应时间等。在实现这些功能时,我们通常需要一个可靠的时间源来确保计时的准确性。那么为什么 Android 推荐使用 SystemClo…...

unity3d————Resources异步加载
知识点一:Resources异步加载是什么? 在Unity中,资源加载可以分为同步加载和异步加载两种方式。同步加载会在主线程中直接进行,如果加载的资源过大,可能会导致程序卡顿,因为从硬盘读取数据到内存并进行处理…...

YOLOv11改进,YOLOv11添加GnConv递归门控卷积,二次创新C3k2结构
摘要 视觉 Transformer 在多种任务中取得了显著的成功,这得益于基于点积自注意力的新空间建模机制。视觉 Transformer 中的关键因素——即输入自适应、长距离和高阶空间交互——也可以通过卷积框架高效实现。作者提出了递归门控卷积(Recursive Gated Convolution,简称 gnCo…...

如何选择国产化CMS来建设政务网站?
在介绍CMS之前,我们先了解国家为什么要网站为什么要完成国产化改造? 1、信创国产化网站建站响应了国家的信息安全战略,支持自主可控的信息技术产业的发展,减少对进口软硬件的依赖,保障国家信息安全。 2、国产替代&…...

C/C++语言基础--initializer_list表达式、tuple元组、pair对组简介
本专栏目的 更新C/C的基础语法,包括C的一些新特性 前言 initializer_list表达式、tuple元组、pair对组再C日常还是比较常用的,尤其是对组在刷算法还是挺好用的,这里做一个简介;这三个语法结合C17的结构化绑定会更好用ÿ…...

paddle表格识别数据制作
数据格式 其中主要数据有两个一个表格结构的检测框,一个是tokens,注意的地方是 1、只能使用双引号,单引号不行 2、使用带引号的地方是tokens里面 "<tr>", "<td", " colspan2", ">",&quo…...

python selenium库的使用:通过兴趣点获取坐标
通过兴趣点获取坐标 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.common.exceptions import TimeoutException# 保存Cookies到文件(可选) import pi…...

如何优化Kafka消费者的性能
要优化 Kafka 消费者性能,你可以考虑以下策略: 并行消费:通过增加消费者组中的消费者数量来并行处理更多的消息,从而提升消费速度。 批量消费:配置 fetch.min.bytes 和 fetch.max.wait.ms 参数来控制批量消费的大小和…...

机器学习 决策树
决策树-分类 1 概念 1、决策节点通过条件判断而进行分支选择的节点。如:将某个样本中的属性值(特征值)与决策节点上的值进行比较,从而判断它的流向。 2、叶子节点没有子节点的节点,表示最终的决策结果。 3、决策树的深度所有节点的最大层…...

C++ 列表初始化容器
initializer_list是一个模板类,可能你已经用过它了但不知道而已,比如下面的代码就用了 #include <iostream> #include <vector>int main() {std::vector<int> vc({ 1,2,3,4 }); //这里调用了构造函数,实参为{1,2,3,4}ret…...

如何高效管理光盘镜像:WinCDEmu虚拟光驱专业使用指南
如何高效管理光盘镜像:WinCDEmu虚拟光驱专业使用指南 【免费下载链接】WinCDEmu 项目地址: https://gitcode.com/gh_mirrors/wi/WinCDEmu WinCDEmu是一款功能强大的开源虚拟光驱软件,专为Windows系统设计,提供高效的光盘镜像挂载与管…...

I2C总线设计实战:从物理层到协议层,解决多设备挂载与信号完整性问题
1. 项目概述:从“能挂多少”到“如何挂好”的深度思考“I2C总线上最多能挂多少个设备?” 这几乎是每个嵌入式工程师在项目初期都会问的问题。乍一看,答案似乎很简单:7位地址能寻址128个,10位地址能寻址1024个。但如果你…...

基于图数据库与语义分析的个人知识管理系统Engram-Mem部署与实践
1. 项目概述与核心价值最近在整理个人知识库和笔记系统时,我遇到了一个几乎所有深度思考者都会面临的困境:信息过载与知识碎片化。我们每天都在阅读文章、保存链接、记录灵感,但这些信息就像散落一地的拼图,彼此孤立,难…...

MemoryOS:开源时序知识图谱AI记忆系统
AI的记忆困局:为什么需要"时序"和"知识图谱"?用过ChatGPT或任何AI助手的人大概都有过这样的体验:昨天告诉AI自己住在北京,今天问它"我住哪儿",它可能还能答对;但是过了两周&…...

Habitat-Lab:Meta开源具身AI仿真平台,从零搭建智能体训练场
1. 项目概述:从虚拟到现实的智能体训练场如果你对机器人、具身智能或者强化学习感兴趣,那么“Habitat-Lab”这个名字你大概率不会陌生。简单来说,Habitat-Lab是一个由Meta AI(前Facebook AI Research)开源的、用于具身…...

自托管MCP服务器模板:快速构建AI智能体私有工具箱
1. 项目概述:一个为AI智能体赋能的“工具箱”模板最近在折腾AI智能体(Agent)开发的朋友,可能都听说过MCP(Model Context Protocol)这个概念。简单来说,MCP就像是为AI大模型准备的一套标准化的“…...

Windows 11系统优化终极指南:免费提升性能与隐私保护的完整方案
Windows 11系统优化终极指南:免费提升性能与隐私保护的完整方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutt…...

redis:AOF
Redis AOF(Append Only File)核心知识点总结一、核心定义与作用AOF 是 Redis 的一种持久化方式,以文本 / 二进制形式记录所有写命令(如 set、lpush 等),核心作用是保存数据、实现宕机后的数据恢复ÿ…...

魔兽争霸III终极兼容性增强插件:5大核心功能解决现代系统兼容问题
魔兽争霸III终极兼容性增强插件:5大核心功能解决现代系统兼容问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸…...