关于强化学习的一份介绍
在这篇文章中,我将介绍与强化学习有关的一些东西,具体包括相关概念、k-摇臂机、强化学习的种类等。
一、基本概念
所谓强化学习就是去学习:做什么才能使得数值化的收益信号最大化。学习者不会被告知应该采取什么动作,而是必须通过自己去发现哪些动作会产生最丰厚的收益。
所以,我们可以发现强化学习会带来一个独有的挑战,即试探与开发之间的折中平衡。也就是说,智能体(agent)必须开发已有的经验来获取收益,但于此同时也要进行试探,使得未来可以获得更好的动作选择空间。
强化学习也可以通过马尔科夫决策过程(MDP)来描述,即是说:机器在环境中,每下一次的行动仅与当前状态有关,但在之后选择并进行了某一项行动后,这个行动会反馈回刚才的决策中。
其中关于MDP,我们可以有这样的一个定义:
马尔科夫决策过程是一个五元组 S,A,P,R,γ其中:
S 表示状态集合;
A 表示动作集合;
P 是状态转移概率矩阵,表示在状态 s 采取动作 aa 后转移到状态 s′ 的概率;
R 是奖励函数,表示在状态 s 采取动作 a 后得到的即时奖励;
γ 是折扣因子,用于减少未来奖励的影响。
而MDP中的马尔可夫是指马尔可夫性质,即下一状态的概率分布只依赖于当前状态,而不依赖于历史状态序列。
我们知道强化学习中存在一个反馈机制,当智能体执行某个动作后,它会从环境中获得即时奖励,并且环境会转移到一个新的状态。这种反馈不是直接改变动作被选择的概率,而是通过更新智能体的策略来间接影响未来的动作选择。策略是一个从状态到动作的概率分布,智能体学习的策略将决定它在特定状态下选择特定动作的概率。
总节来说就是:智能体在执行动作后会收到奖励并转移到新状态,但这并不直接改变动作被选择的概率。相反,它是通过更新策略来影响未来的决策。
然后是强化学习中其他的一些概念:
智能体 (Agent): 是执行动作的学习实体。
环境 (Environment): 是智能体所处的世界,它根据智能体的动作给出响应。
状态 (State): 描述了环境的当前情况。(强化学习十分依赖状态这一概念,它既可以作为策略和价值函数的输入,又同时作为模型的输入与输出。)
动作 (Action): 智能体可以执行的行为。
奖励 (Reward): 环境对智能体采取的动作给予的反馈,用数值表示,智能体的目标就是最大化累计奖励。
在这里补充一下,一些优化方法,如遗传算法、模拟退火算法等方法它们都可以用于解决强化学习的问题,而不必显式运用价值函数。它们都采用大量静态策略,每个策略在扩展的较长时间与环境的一个独立实例进行交互。这些方法选择获取了最多收益的策略以及其变种来产生下一代的策略,然后继续循环更替,我们将之称为进化方法,因为我们不难发现它们的过程与生物的进化过程十分相似。不过这些进化方法忽视了强化学习问题中的一些有用结构:它们忽略了所有策略是状态到动作的函数这一事实,同时也没有注意个体在生命周期中都有经历过哪些状态,采取了哪些动作。所以,尽管进化与学习间有许多的共性,并且二者往往是相伴的,但我们还是会认为进化方法并不适用于强化学习问题。
二、K-摇臂机
K-摇臂机(Multi-Armed Bandit, MAB)问题是强化学习中的一个经典问题,也是一个简单的强化学习问题,它可以帮助我们理解在不确定情况下如何做出最佳决策。
2.1 定义
假设你在一家赌场里面对一台有 k 个摇臂的老虎机,每个摇臂都有不同的中奖概率。每次拉其中一个摇臂,你都会得到一个奖励(通常是金钱)。你的目标是在有限次尝试内最大化累计奖励。在这个问题中,“摇臂”代表不同的选项,“多臂”则指多个选择。
2.2 问题特点
探索与利用(Exploration vs. Exploitation):这是MAB问题的核心。你需要在探索(尝试不同的摇臂以了解它们的平均奖励)和利用(拉最有可能带来高奖励的摇臂)之间找到一个平衡点。
不确定性:在开始时,你对每个摇臂的期望奖励一无所知,必须通过试验来估计每个摇臂的真实期望值。
即时反馈:每次拉摇臂后,你会立即得到一个奖励,这是一个即时反馈问题。
2.3 ε-greedy 策略
我们可以使用价值的估计来进行动作的选择,这一类方法统称为“动作-价值”方法。那么,一种自然的方式就是通过计算实际收益的平均值来估计动作的价值:
所以,最简单的一种动作选择方法就是选择具有最高估计值的动作,即进行贪心选择。但这时会出现一个问题,就是这种贪心选择只顾眼前的收益,而可能会失去更大的收益,因为它不会选择那些虽然当前是低价值但在未来会去的极高价值的动作。那么,我们需要对其改进,我们让agent在大部分时间里是贪心的,但有时(以很小的概率ε)会去独立于动作-价值估计值而从所有的动作中等概率随机做出选择,而这种方法就是ε-贪心(greedy) 策略,所以可以总结出它的概念为:
ε-greedy 策略:大部分时间选择当前估计奖励最高的摇臂(利用),一小部分时间随机选择一个摇臂(探索)。
我们令Q(k)记录摇臂k的平均奖赏,若摇臂k被尝试了n次,得到的奖赏为v1,v2,v3……,vn,那么平均奖赏为:
此时,如果我们直接用该式来计算平均奖赏则需要记录n个平均奖赏值,所以为了更加高效,我们采用增量式计算,即每尝试一次后就立即更新Q(k),那么这个平均奖赏就应更新为:
具体用一个代码举例:
import numpy as np
import randomclass MultiArmedBandit:def __init__(self, num_arms, epsilon=0.1):self.num_arms = num_arms# 初始化每个摇臂的实际平均奖励self.true_rewards = np.random.normal(loc=0.0, scale=1.0, size=num_arms)# 初始化每个摇臂的经验平均奖励self.estimates = np.zeros(num_arms)# 初始化每个摇臂的尝试次数self.attempts = np.zeros(num_arms, dtype=int)# 探索与利用的参数self.epsilon = epsilondef pull_arm(self, arm):reward = np.random.normal(loc=self.true_rewards[arm], scale=1.0)return rewarddef update_estimate(self, arm, reward):# 使用增量式更新公式self.attempts[arm] += 1self.estimates[arm] += (reward - self.estimates[arm]) / self.attempts[arm]def choose_arm(self):if random.random() < self.epsilon:# 探索:随机选择一个摇臂return random.randint(0, self.num_arms - 1)else:# 利用:选择估计奖励最高的摇臂return np.argmax(self.estimates)# 参数设置
num_arms = 10
epsilon = 0.1
num_trials = 1000# 创建 K-摇臂机对象
bandit = MultiArmedBandit(num_arms, epsilon)# 进行多次尝试
for trial in range(num_trials):chosen_arm = bandit.choose_arm()reward = bandit.pull_arm(chosen_arm)bandit.update_estimate(chosen_arm, reward)# 打印结果
print("True Rewards:", bandit.true_rewards)
print("Estimated Rewards:", bandit.estimates)
print("Attempts per Arm:", bandit.attempts)其运行结果为:
True Rewards: [ 0.05273471 1.40458756 0.32813439 -1.25692634 -0.67451511 -1.97502727-0.60326298 -0.22662436 -0.49297712 0.25822946]
Estimated Rewards: [ 0.54674629 1.45132379 0.18953721 -1.67282471 0.1013343 -2.52797267-1.07719265 0.19331869 -0.47083797 0.14306436]
Attempts per Arm: [ 12 922 11 8 3 6 10 13 5 10]2.4 乐观初始值
目前,我们所讨论的方法都在一定程度上依赖于初始动作值的选择,但这样一来,它们就是有偏的,在统计学的角度来看。不过,在实际中,这并非是一个问题,但它会称为用户需要调整的一个参数。那么,这个初始值该如何分配呢?可以考虑分配一个较高的初始值,以鼓励agent在早期多做尝试,以发现真正优秀的动作,而这样的一个思路就是乐观初始值的思路。
2.5 置信度上界
在之前的动作-价值的估计总会存在不确定性,所以试探的存在是必要的。所以在非贪心动作中,最好是根据动作的潜力来选择可能事实上优秀的动作,这就要考虑它们的估计值有多接近最大值,以及估计这些动作的不确定风性。一个有效的思路就是基于置信度上界的动作选择,即按照这个公式:
其中,平方根项是对 a 动作值估计的不确定性或方差的度量。因此,最大值的大小是动作 a 的可能真实值上界,而参数 c 决定了置信水平。
2.6 梯度摇臂机算法
现在,让我们针对每个动作 a 考虑学习一个数值化的偏好函数。偏好函数越大,动作就越频繁地被选择,但偏好函数的概念并非从“收益”上提出的。只有一个动作对另一个动作的相对偏好才是重要的,那么对于如下的这个softmax分布来说,若对于每一个动作的偏好函数都加上1000,则不会对动作概率产生任何影响,式子如下:
其中,表示动作 a 在时刻 t 被选择的概率。另外,所有偏好函数的初始值都是一样的,所以它们被选择的概率是一样的。
2.7 关联搜索
关联搜索任务也叫上下文相关的摇臂机,它既涉及采用学习去搜索最优的动作,又将这些动作与表现最优时的情景关联在一起。它介于k摇臂机问题与完整的强化学习问题之间。它与完整的强化学习问题相似的点是它需要学习一种策略,但它与k摇臂机相似是体现在每个动作只影响即时收益。所以,如果允许动作可以影响下一刻的情景与收益那么就是完整的学习问题。
三、分类
如果我们按照有无环境模型来对强化学习去分类的话,它可以被分为两类,一是有模型的强化学习,二是无模型的强化学习。具体地:
基于模型的强化学习(Model-Based RL):在这种设置下,智能体尝试构建一个环境的模型,然后利用这个模型来预测未来的状态和奖励,从而做出决策。这种方法的优点是可以减少与真实环境的交互次数,但缺点是模型构建可能会引入误差。
无模型的强化学习(Model-Free RL):智能体不试图构建环境模型,而是直接从与环境的交互中学习。这类方法包括基于价值的方法(如Q-Learning)、基于策略的方法(如Policy Gradients)和Actor-Critic方法。
如果我们按照学习目标去分类的话,那么强化学习可以分为策略优化与Q-Learning
策略优化(Policy Optimization):直接优化策略本身,使其在长期能够获得更高的累计奖励。
Q-Learning:学习动作-价值函数,即在给定状态下采取某个动作所能获得的预期未来奖励。
此外还有特殊类型的,比如:
逆向强化学习(Inverse Reinforcement Learning, IRL):从观察到的专家行为中学习奖励函数。
层级强化学习(Hierarchical Reinforcement Learning, HRL):将任务分解成多个子任务,每个子任务可以独立学习,从而简化整体学习过程。
部分可观测的强化学习(Partially Observable Markov Decision Processes, POMDPs):当环境不是完全可观测时,智能体需要处理不确定性的信息。
此上
相关文章:
关于强化学习的一份介绍
在这篇文章中,我将介绍与强化学习有关的一些东西,具体包括相关概念、k-摇臂机、强化学习的种类等。 一、基本概念 所谓强化学习就是去学习:做什么才能使得数值化的收益信号最大化。学习者不会被告知应该采取什么动作,而是必须通…...

Python3.11.9+selenium,获取图片验证码以及输入验证码数字
Python3.11.9+selenium,获取图片验证码以及输入验证码数字 1、遇到问题:登录或修改密码需要验证码 2、解决办法: 2.1、安装ddddocr pip install ddddocr 2.2、解析验证码函数 import ddddocr def get_capcha_text():#获取验证码图片ele_pic = driver.find_element(By.XPAT…...

Flutter:事件队列,异步操作,链式调用。
Flutter分2种队列 1、事件队列:异步的处理,按顺序执行 import package:flutter/material.dart; main(){testFuture1();testFuture2(); }// 按顺序执行处理A->B->C testFuture1() async {Future((){return 任务A;}).then((value){print(按顺序执行&…...

从零开始学习 sg200x 多核开发之 eth0 自动使能并配置静态IP
前文提到 sophpi 默认没有使能有线网络,需要手工配置: [rootsg200x]~# ifconfig eth0 up [rootsg200x]~# udhcpc -i eth0 [rootsg200x]~# ifconfig eth0 Link encap:Ethernet HWaddr EA:BD:18:08:1E:87 inet addr:192.168.188.142 Bcast:192.1…...

《TCP/IP网络编程》学习笔记 | Chapter 11:进程间通信
《TCP/IP网络编程》学习笔记 | Chapter 11:进程间通信 《TCP/IP网络编程》学习笔记 | Chapter 11:进程间通信进程间通信的基本概念通过管道实现进程间通信通过管道进行进程间双向通信 运用进程间通信习题(1)什么是进程间通信&…...
)
开源模型应用落地-qwen模型小试-Qwen2.5-7B-Instruct-tool usage入门-集成心知天气(二)
一、前言 Qwen-Agent 是一个利用开源语言模型Qwen的工具使用、规划和记忆功能的框架。其模块化设计允许开发人员创建具有特定功能的定制代理,为各种应用程序提供了坚实的基础。同时,开发者可以利用 Qwen-Agent 的原子组件构建智能代理,以理解和响应用户查询。 本篇将介绍如何…...

通过声纹或者声波来切分一段音频
通过声纹识别或基于声波特征的模型,确实可以帮助切分一段音频并区分出不同讲话者的语音片段。这种技术被称为 基于声纹的语音分割 或 基于说话人识别的音频分割。其核心原理是利用每个说话者的 声纹特征(即每个人独特的语音特征)来识别和切分…...

sql专场练习(二)(16-20)完结
第十六题 用户登录日志表为user_id,log_id,session_id,visit_time create table sql2_16(user_id int,log_id int,session_id int,visit_time string );没有数据 visit_time 时间格式为2024-11-15 用sql查询近30天每天平均登录用户数量 with t1 as (select visit_time,coun…...

[ 网络安全介绍 2 ] 网络安全发展现状
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

《基于Oracle的SQL优化》读书笔记
查看执行计划set autotrace traceonly explain在当前session中将优化器模式改为RULE。alter session set optimizer_modeRULE;统计信息存储在oracle的数据字典里,且从多个维度描述了oracle数据库里相关对象的实际数据量,实际数据分布等详细信息。 -- 对…...

零基础利用实战项目学会Pytorch
目录 pytorch简介 1.线性回归 2.数据类型 2.1数据类型检验 2.2Dimension0/Rank0 2.3 Dim1/Rank1 2.4 Dim2/Rank2 3.一些方法 4.Pytorch完成分类任务 4.1模型参数 4.2 前向传播 4.3训练以及验证 4.4 三行搞定! 4.5 准确率 5、Pytorch完成回归任务 5.…...
Goroutine 以及其中的锁和思想)
Go八股(Ⅵ)Goroutine 以及其中的锁和思想
Goroutine与并发编程的关系 什么是并发 是指多个任务在同一时间段内进行处理,但不一定是在同一时刻执行。并发强调的是“结构上的并行性”,也就是说,程序能够在一个时间端内同时处理多个任务,但是这些任务可能是交替进行的。例如…...

向潜在安全信息和事件管理 SIEM 提供商提出的六个问题
收集和解读数据洞察以制定可用的解决方案是强大网络安全策略的基础。然而,组织正淹没在数据中,这使得这项任务变得复杂。 传统的安全信息和事件管理 ( SIEM ) 工具是组织尝试使用的一种方法,但由于成本、资源和可扩展性等几个原因࿰…...
蓝桥杯每日真题 - 第15天
题目:(钟表) 题目描述(13届 C&C B组B题) 解题思路: 理解钟表指针的运动: 秒针每分钟转一圈,即每秒转6度。 分针每小时转一圈,即每分钟转6度。 时针每12小时转一圈…...

Python的Matplotlib
介绍: Matplotlib 是一个非常强大的 Python 绘图库,支持多种不同类型的图表。以下是 Matplotlib 支持的一些常见图表类型: 前情提要: from matplotlib import rcParams# 设置支持中文的字体 rcParams[font.sans-serif] [SimHei…...
Python数据分析:分组转换transform方法
大家好,在数据分析中,需要对数据进行分组统计与计算,Pandas的groupby功能提供了强大的分组功能。transform方法是groupby中常用的转换方法之一,它允许在分组的基础上进行灵活的转换和计算,并将结果与原始数据保持相同的…...

高效灵活的Django URL配置与反向URL实现方案
高效灵活的Django URL配置与反向URL实现方案 目录 📑 1. 基本的Django URL配置及反向URL的实现 🔧 2. 使用path()替代re_path()配置URL的优势与劣势 🛠️ 3. 使用URL命名空间(namespace)提高URL管理的可维护性 &…...

深入探讨 MySQL 配置与优化:从零到生产环境的最佳实践20241112
深入探讨 MySQL 配置与优化:从零到生产环境的最佳实践 引言 MySQL 是全球最受欢迎的开源关系型数据库之一,其高性能、灵活性和广泛的社区支持使其成为无数开发者的首选。然而,部署一台高效、稳定的 MySQL 实例并非易事。本文将结合一个实际…...

Java-Redisson分布式锁+自定义注解+AOP的方式来实现后台防止重复请求扩展
1. 添加依赖 首先,在项目的pom.xml文件中添加Redisson和Spring AOP的相关依赖: <dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.16.8</version> </dependency> <dependency…...
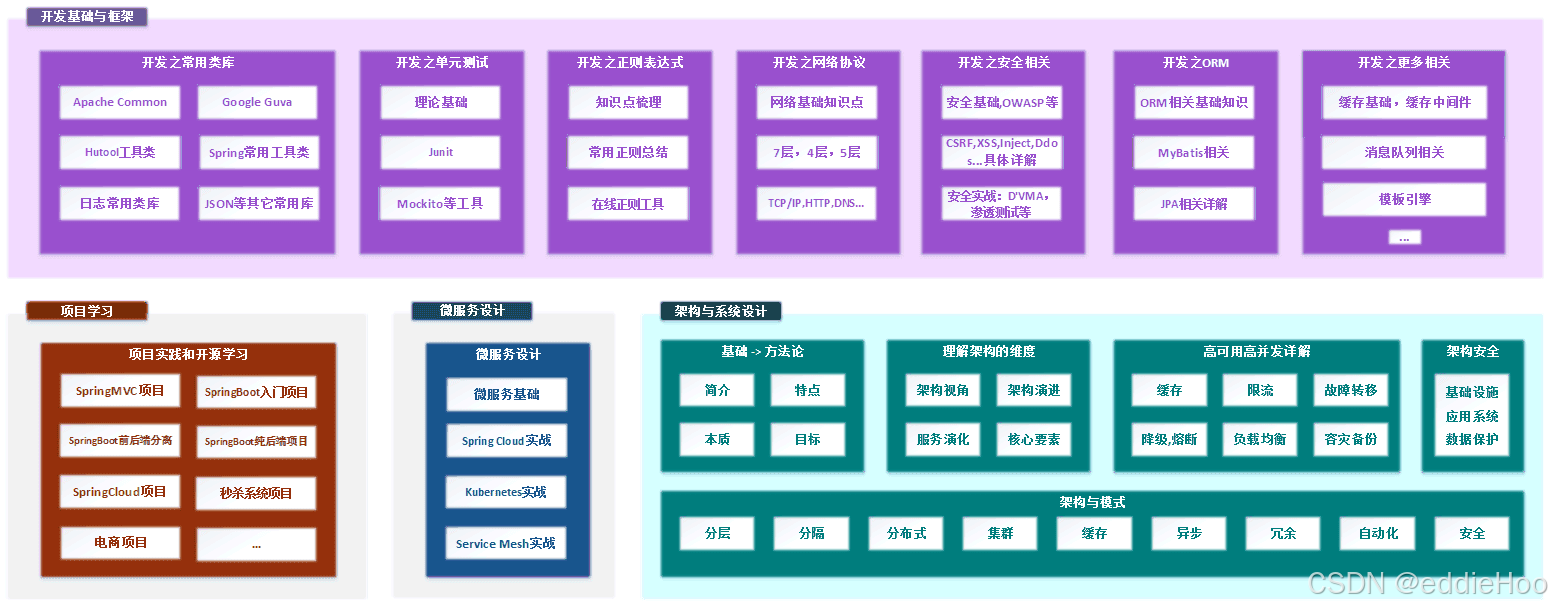
Java 全栈知识体系
包含: Java 基础, Java 部分源码, JVM, Spring, Spring Boot, Spring Cloud, 数据库原理, MySQL, ElasticSearch, MongoDB, Docker, k8s, CI&CD, Linux, DevOps, 分布式, 中间件, 开发工具, Git, IDE, 源码阅读,读书笔记, 开源项目......

Wnt/β-catenin信号通路在组织修复与再生中的关键作用
1. Wnt/β-catenin信号通路:细胞修复的"总指挥" 想象一下你手指被划伤后伤口愈合的过程,或者肝脏在受损后自我修复的神奇能力。这些看似平常的现象背后,其实隐藏着一个精密的分子调控网络——Wnt/β-catenin信号通路。这条通路就像…...

药物发现必备:RDKit分子指纹在虚拟筛选中的7种高级用法
药物发现必备:RDKit分子指纹在虚拟筛选中的7种高级用法 在当今药物研发领域,虚拟筛选已成为加速药物发现流程的关键技术。面对海量化合物库,如何高效准确地识别潜在活性分子?RDKit分子指纹技术提供了强有力的解决方案。不同于基础…...
缩略语大全:从C-V2X到VRUCW,一文搞懂所有专业术语)
智能网联汽车(CAV)缩略语大全:从C-V2X到VRUCW,一文搞懂所有专业术语
智能网联汽车(CAV)术语全解析:从技术原理到场景应用 在智能交通系统快速发展的今天,智能网联汽车(Connected-Automated Vehicle, CAV)已经成为行业变革的核心驱动力。无论是汽车工程师、软件开发人员还是交通规划者,都需要掌握这一领域的关键…...
)
小波分解选型指南:如何为你的数据选择最合适的pywt小波函数(db4/haar/symlets对比)
小波分解选型指南:如何为你的数据选择最合适的pywt小波函数(db4/haar/symlets对比) 在信号处理领域,小波分解就像一把瑞士军刀,能够同时提供时域和频域的信息。但面对pywt库中琳琅满目的小波函数——从经典的Haar到复杂…...
的本地引入 详细步骤)
阿里图标库(Iconfont)的本地引入 详细步骤
阿里图标库(Iconfont)本地引入 Vue3 详细步骤(文字版) 一、准备工作 登录 Iconfont 官网 访问 Iconfont 官网,使用账号登录(若无账号需注册)。 选择图标并加入项目 在搜索框输入关键词&#x…...
)
别再只用CEC2005了!手把手教你用MATLAB跑通CEC2017测试集(附完整代码)
从CEC2005到CEC2017:MATLAB实战迁移指南与性能优化技巧 当优化算法研究者还在使用CEC2005作为基准测试时,前沿论文早已转向更具挑战性的CEC2017测试集。这个转变不仅仅是数字上的更新,更代表着优化算法评估标准的一次重大飞跃。本文将带你从零…...

ArcGIS字段值提取:别再手动截取了,用Python和VB脚本5分钟搞定
ArcGIS字段值提取:Python与VB脚本高效自动化方案 引言:告别低效手工操作 在GIS数据处理工作中,属性表字段值的提取是再常见不过的操作。想象一下这样的场景:你手头有一份包含数万条记录的行政区划数据,需要从"BSM…...

8路HD-SDI录播主机CYS-08
在广电录制、教育录播、会议记录等场景中,稳定、高清、易管理的视频录制设备至关重要。春源丽影CYS-08 推出的8路HD-SDI硬盘录像机,凭借全接口支持、双编码技术、智能存储等核心优势,为多路高清录制需求提供了专业级解决方案。8路高清输入&am…...

OpenClaw自动化测试:Qwen3.5-9B在API接口校验中的实战应用
OpenClaw自动化测试:Qwen3.5-9B在API接口校验中的实战应用 1. 为什么选择OpenClaw做接口自动化测试 去年接手一个个人项目时,我遇到了接口测试的痛点:每次后端更新都要手动验证几十个API,不仅耗时还容易遗漏边缘case。尝试过Pos…...

OpenClaw+ollama-QwQ-32B内容处理:自动生成周报与会议纪要
OpenClawollama-QwQ-32B内容处理:自动生成周报与会议纪要 1. 为什么需要自动化内容处理工具 每周五下午三点,我的日历总会准时弹出"编写本周工作报告"的提醒。这个看似简单的任务,却常常让我陷入两难:要么花半小时手动…...