Python数据分析:分组转换transform方法
大家好,在数据分析中,需要对数据进行分组统计与计算,Pandas的groupby功能提供了强大的分组功能。transform方法是groupby中常用的转换方法之一,它允许在分组的基础上进行灵活的转换和计算,并将结果与原始数据保持相同的结构。因此,transform非常适合需要将计算结果返回到原始DataFrame的情况。
1.transform方法基本概念
transform方法可以对每个分组进行计算,并将结果“广播”回原始DataFrame,使得返回的DataFrame形状与原始数据一致。与其他groupby操作不同,transform返回的数据不会改变原始DataFrame的行数,而是将分组后的计算结果逐行赋值给原始DataFrame。
transform方法的基本语法如下:
DataFrame.groupby('列名')['列名'].transform(func)
-
groupby('列名'):指定需要分组的列。 -
transform(func):对每个分组应用函数func,可以是内置的聚合函数,也可以是自定义函数。
常见的聚合函数包括求均值(mean)、求和(sum)、最大值(max)、最小值(min)等。
2.示例数据集
使用一个包含员工信息的示例数据集,包括员工姓名、部门和薪资信息,方便演示各种transform操作。
import pandas as pd# 创建示例数据集
data = {'姓名': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank'],'部门': ['销售', '销售', 'IT', 'IT', '市场', '市场'],'薪资': [7000, 6800, 9000, 8500, 7500, 7700]
}
df = pd.DataFrame(data)
print("原始数据集:\n", df)
结果如下所示:
姓名 部门 薪资
0 Alice 销售 7000
1 Bob 销售 6800
2 Charlie IT 9000
3 David IT 8500
4 Eve 市场 7500
5 Frank 市场 77003.分组计算并广播结果
假设希望计算每个部门的平均薪资,并将该值赋予每位员工。使用transform方法可以实现这点,计算部门平均薪资并广播:
# 使用 transform 计算每个部门的平均薪资
df['部门平均薪资'] = df.groupby('部门')['薪资'].transform('mean')
print("部门平均薪资:\n", df)
结果如下所示:
姓名 部门 薪资 部门平均薪资
0 Alice 销售 7000 6900.0
1 Bob 销售 6800 6900.0
2 Charlie IT 9000 8750.0
3 David IT 8500 8750.0
4 Eve 市场 7500 7600.0
5 Frank 市场 7700 7600.0
在这个示例中,transform('mean')计算了每个部门的平均薪资,并将计算结果广播回原始DataFrame的每一行中。
4.使用自定义函数进行转换
transform不仅支持常规的聚合函数,还支持自定义函数。假设计算每位员工的薪资与部门平均薪资的差异,可以使用自定义函数实现。
# 自定义函数计算薪资与部门平均薪资的差异
df['薪资差异'] = df.groupby('部门')['薪资'].transform(lambda x: x - x.mean())
print("薪资差异:\n", df)
结果如下所示:
姓名 部门 薪资 部门平均薪资 薪资差异
0 Alice 销售 7000 6900.0 100.0
1 Bob 销售 6800 6900.0 -100.0
2 Charlie IT 9000 8750.0 250.0
3 David IT 8500 8750.0 -250.0
4 Eve 市场 7500 7600.0 -100.0
5 Frank 市场 7700 7600.0 100.0
通过自定义lambda函数,计算了每位员工的薪资差异,进一步揭示了员工与部门平均水平的偏差情况。
5.transform与apply的区别
transform:返回的结果与原始DataFrame的形状一致,每个分组的计算结果会逐行赋值给原DataFrame。
apply:通常返回缩小后的DataFrame,适合整体的分组操作。
以下示例展示了apply与transform的差异:
# 使用 apply 计算每个部门的薪资均值
df_apply = df.groupby('部门')['薪资'].apply(lambda x: x.mean())
print("使用 apply 结果:\n", df_apply)
结果如下所示:
部门
IT 8750.0
市场 7600.0
销售 6900.0
Name: 薪资, dtype: float64
apply直接返回分组后的平均薪资,而transform会将分组后的均值按行赋回原DataFrame。transform的输出与原DataFrame形状一致,因此适合需要广播结果的计算。
6.transform方法的高级应用
6.1 计算每位员工的部门排名
可以使用transform和rank函数计算每位员工在其部门内的薪资排名:
# 计算每位员工的部门薪资排名
df['部门薪资排名'] = df.groupby('部门')['薪资'].transform('rank', ascending=False)
print("部门薪资排名:\n", df)
结果如下所示:
姓名 部门 薪资 部门平均薪资 薪资差异 部门薪资排名
0 Alice 销售 7000 6900.0 100.0 1.0
1 Bob 销售 6800 6900.0 -100.0 2.0
2 Charlie IT 9000 8750.0 250.0 1.0
3 David IT 8500 8750.0 -250.0 2.0
4 Eve 市场 7500 7600.0 -100.0 2.0
5 Frank 市场 7700 7600.0 100.0 1.0
在这个示例中,transform('rank')计算了每位员工在其部门内的薪资排名。
6.2 归一化处理:按部门归一化薪资
归一化处理通常用于数据预处理,使数据更加集中和标准化。以下代码展示如何按部门对薪资进行归一化:
# 按部门归一化薪资
df['归一化薪资'] = df.groupby('部门')['薪资'].transform(lambda x: (x - x.min()) / (x.max() - x.min()))
print("按部门归一化薪资:\n", df)
结果如下所示:
姓名 部门 薪资 部门平均薪资 薪资差异 部门薪资排名 归一化薪资
0 Alice 销售 7000 6900.0 100.0 1.0 1.0
1 Bob 销售 6800 6900.0 -100.0 2.0 0.0
2 Charlie IT 9000 8750.0 250.0 1.0 1.0
3 David IT 8500 8750.0 -250.0 2.0 0.0
4 Eve 市场 7500 7600.0 -100.0 2.0 0.0
5 Frank 市场 7700 7600.0 100.0 1.0 1.0
在这个示例中,使用lambda函数实现了归一化操作 (x - x.min()) / (x.max() - x.min()),将每个部门的薪资归一化到[0, 1]区间。归一化后的薪资可以更直观地比较不同部门内部的薪资差异。
6.3 标准化处理:按部门标准化薪资
标准化是数据预处理中的另一种常用方法,通常用于使数据符合正态分布。以下代码展示如何按部门对薪资进行标准化:
# 按部门标准化薪资
df['标准化薪资'] = df.groupby('部门')['薪资'].transform(lambda x: (x - x.mean()) / x.std())
print("按部门标准化薪资:\n", df)
结果如下所示:
姓名 部门 薪资 部门平均薪资 薪资差异 部门薪资排名 归一化薪资 标准化薪资
0 Alice 销售 7000 6900.0 100.0 1.0 1.0 0.707
1 Bob 销售 6800 6900.0 -100.0 2.0 0.0 -0.707
2 Charlie IT 9000 8750.0 250.0 1.0 1.0 0.707
3 David IT 8500 8750.0 -250.0 2.0 0.0 -0.707
4 Eve 市场 7500 7600.0 -100.0 2.0 0.0 -0.707
5 Frank 市场 7700 7600.0 100.0 1.0 1.0 0.707
在这个示例中,使用transform方法对每个部门的薪资进行标准化处理 (x - x.mean()) / x.std(),从而将数据转换为均值为0、标准差为1的分布,方便不同部门之间的薪资比较。
transform方法为Pandas的分组操作提供了强大的支持,适用于在分组基础上进行灵活的逐行计算和结果广播。本文通过实例展示transform的基本用法、自定义函数的应用、分组排名、归一化和标准化等场景。通过掌握transform的使用技巧,可以使数据处理和分析更加高效和灵活。
相关文章:
Python数据分析:分组转换transform方法
大家好,在数据分析中,需要对数据进行分组统计与计算,Pandas的groupby功能提供了强大的分组功能。transform方法是groupby中常用的转换方法之一,它允许在分组的基础上进行灵活的转换和计算,并将结果与原始数据保持相同的…...

高效灵活的Django URL配置与反向URL实现方案
高效灵活的Django URL配置与反向URL实现方案 目录 📑 1. 基本的Django URL配置及反向URL的实现 🔧 2. 使用path()替代re_path()配置URL的优势与劣势 🛠️ 3. 使用URL命名空间(namespace)提高URL管理的可维护性 &…...

深入探讨 MySQL 配置与优化:从零到生产环境的最佳实践20241112
深入探讨 MySQL 配置与优化:从零到生产环境的最佳实践 引言 MySQL 是全球最受欢迎的开源关系型数据库之一,其高性能、灵活性和广泛的社区支持使其成为无数开发者的首选。然而,部署一台高效、稳定的 MySQL 实例并非易事。本文将结合一个实际…...

Java-Redisson分布式锁+自定义注解+AOP的方式来实现后台防止重复请求扩展
1. 添加依赖 首先,在项目的pom.xml文件中添加Redisson和Spring AOP的相关依赖: <dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.16.8</version> </dependency> <dependency…...
Java 全栈知识体系
包含: Java 基础, Java 部分源码, JVM, Spring, Spring Boot, Spring Cloud, 数据库原理, MySQL, ElasticSearch, MongoDB, Docker, k8s, CI&CD, Linux, DevOps, 分布式, 中间件, 开发工具, Git, IDE, 源码阅读,读书笔记, 开源项目......

树状数组+概率论,ABC380G - Another Shuffle Window
目录 一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 二、解题报告 1、思路分析 2、复杂度 3、代码详解 一、题目 1、题目描述 2、输入输出 2.1输入 2.2输出 3、原题链接 G - Another Shuffle Window 二、解题报告 1、思路分析 不难用树状数组计…...

机器学习day1-数据集
机器学习 一、机器学习 1.定义 让计算机在数据中学习规律并根据得到的规律对未来进行预测。 2.发展史 19世纪50年代:图灵测试提出、塞缪尔开发的西洋跳棋程序,标志着机器学习正式进入发展期 19世纪80年代:神经网络反向传播(…...

【Golang】——Gin 框架中的路由与请求处理
文章目录 1. 路由基础1.1 什么是路由?1.2 Gin 中的路由概述 2. 创建简单路由2.1 基本路由定义2.2 不同请求方法的路由 3. 路由参数3.1 路径参数3.2 查询参数 4. 路由分组4.1 为什么使用路由分组?4.2 路由分组示例 5. 请求处理与响应5.1 Gin 中的 Context…...

nuxt3添加wowjs动效
1、安装wowjs pnpm i wowjs1.1.32、node_modules复制wowjs代码 路径/node_modules/wowjs/dist/wow.js。不知道路径则查看node_modules/wowjs/package.json里面的main选项 2.1、在public文件夹创建wowjs.js文件 /public/wowjs.js export default (callthis) > { // !!// 这是…...

我们是如何实现 TiDB Cloud Serverless 的 - 成本篇
作者: shiyuhang0 原文来源: https://tidb.net/blog/fbedeea4 背景 Serverless 数据库是云原生时代的产物,它提供全托管,按需付费,自动弹性的云数据库服务,让客户免于繁重的数据库运维工作。关于 Serve…...

PCL算法汇总
参考 【2024最新版】PCL点云处理算法汇总(C长期更新版)_pcl点云聚类c-CSDN博客...
sql注入之二次注入(sqlilabs-less24)
二阶注入(Second-Order Injection)是一种特殊的 SQL 注入攻击,通常发生在用户输入的数据首先被存储在数据库中,然后在后续的操作中被使用时,触发了注入漏洞。与传统的 SQL 注入(直接注入)不同&a…...

Android compose 软键盘 遮挡对话框中TextField 输入框
在AlertDialog对话框中含有TextField输入框时,弹出软件盘会遮挡输入框 解决1: 在AndroidManifest.xml的 MainActivity中添加如下 android:windowSoftInputMode"adjustResize" 然后AlertDialog 中的modify. modify.windowInsetsP…...
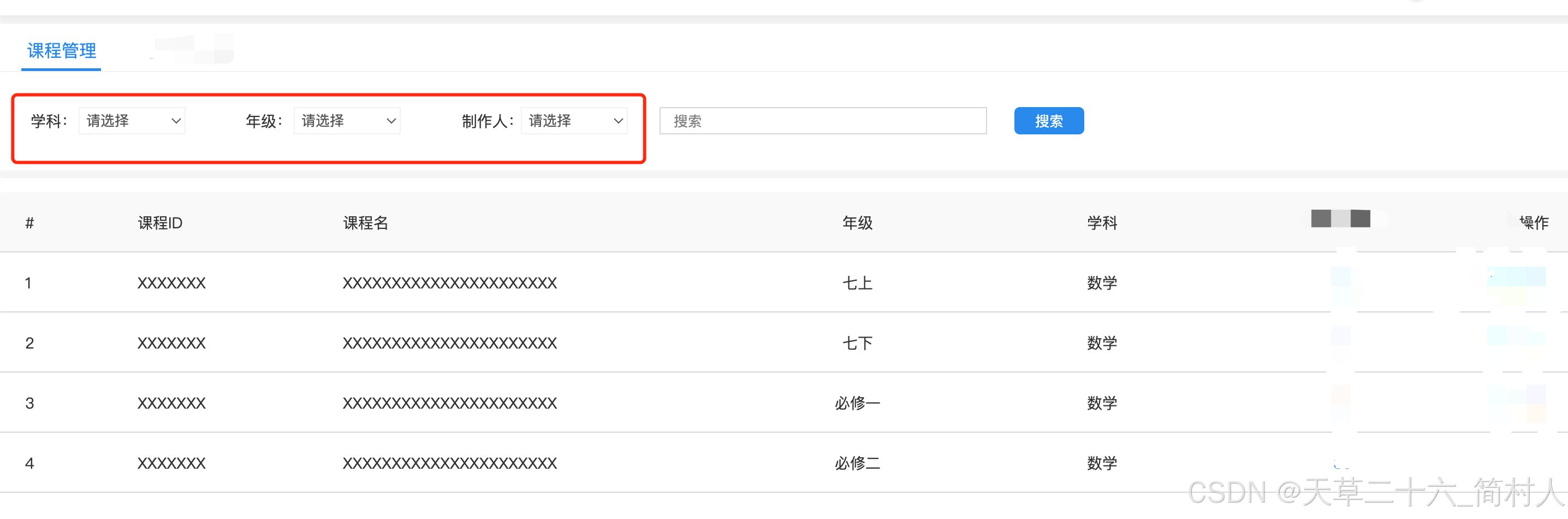
spring-data-elasticsearch 3.2.4 实现桶bucket排序去重,实现指定字段的聚合搜索
一、背景 es索引有一个文档CourseIndex,下面是示意: creatorIdgradesubjectnameno1002270英语听力课程一N00232DS91004380数学口算课程N00209DK71003480物理竞赛课程N00642XS21002280英语听力课程二N00432WS31002290英语听力课程三N002312DP5 在搜索的时候&#…...

【项目开发】分析六种常用软件架构
未经许可,不得转载。 文章目录 软件架构核心内容设计原则分层架构常见层次划分优缺点应用场景事件驱动架构核心组件优缺点应用场景微核架构核心概念优缺点应用场景微服务架构核心组件设计与实施优缺点应用场景云架构云架构模式优缺点应用场景软件架构 软件架构是指一个软件系…...

算法和程序的区别
算法(Algorithm)和程序(Program)是计算机科学中两个密切相关但不同的概念。让我们通过以下几个方面来比较它们: ### 1. 设计 vs 实现 - **算法设计(Algorithm Design)**: - **定…...

用指针遍历数组
#include<stdio.h> int main() {//定义一个二维数组int arr[3][4] {{1,2,3,4},{2,3,4,5},{3,4,5,6},};//获取二维数组的指针int (*p)[4] arr;//二维数组里存的是一维数组int[4]for (int i 0; i < 3; i){//遍历一维数组for (int j 0; j <4; j){printf("%d &…...

《Probing the 3D Awareness of Visual Foundation Models》论文解析——多视图一致性
一、论文简介 论文讨论了大规模预训练产生的视觉基础模型在处理任意图像时的强大能力,这些模型不仅能够完成训练任务,其中间表示还对其他视觉任务(如检测和分割)有用。研究者们提出了一个问题:这些模型是否能够表示物体…...

使用pip安装esp32的擦除、写入固件的esptool库
esptool库可以为esp32的开发板烧录新的固件,但是如果为了烧录固件就要装esp-idf软件包,甚至需要用make编译安装很久,实在太费时费力了! 好消息就是,esp提供了python的esptool库,这样只要使用pip安装上这个…...

传奇996_23——杀怪掉落,自动捡取,捡取动画
一、杀怪掉落 前置: 添加地图地图刷怪怪物掉落(术语叫爆率,掉落叫爆率,而且文档上叫爆率) 刷怪步骤:在\MirServer\Mir200\Envir\MonItems文件夹中建立以怪物名字为文件名的txt文件写法案例: …...

Sentinel-1A极化矩阵处理实战:用SNAP生成C2矩阵的7个关键参数解析与效果对比
Sentinel-1A极化矩阵处理实战:用SNAP生成C2矩阵的7个关键参数解析与效果对比 当处理Sentinel-1A极化SAR数据时,C2矩阵的生成质量直接影响后续地物分类、变化检测等应用的精度。许多初学者在使用SNAP的Polarimetric-Matrices算子时,往往直接采…...
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台 1. 企业内容中台的业务场景与挑战 现代企业面临内容生产的三大痛点:创意产出效率低、设计资源不足、多平台适配成本高。以电商行业为例,一个中型电商平台每月需要…...

OpenClaw备份恢复:Qwen3-VL:30B飞书配置迁移指南
OpenClaw备份恢复:Qwen3-VL:30B飞书配置迁移指南 1. 为什么需要备份恢复OpenClaw配置 上周我的主力开发机突然硬盘故障,导致所有数据丢失。最让我头疼的不是代码仓库——它们都有远程备份,而是那套精心调校的OpenClaw飞书助手配置。这个助手…...

STM32红外遥控器设计与多协议控制实现
基于STM32的万能红外遥控器设计与实现1. 项目概述1.1 系统架构本设计采用STM32F103RCT6作为主控芯片,构建了一个多功能红外遥控系统。系统架构包含以下核心模块:主控模块:STM32F103RCT6微控制器人机交互模块:1.44寸LCD显示屏 4x4…...

从零开始:用STM32CubeMX+Keil5开发计算器的5个关键陷阱与解决方案
从零开始:用STM32CubeMXKeil5开发计算器的5个关键陷阱与解决方案 当你第一次尝试用STM32CubeMX和Keil5开发一个计算器时,可能会觉得这不过是几个简单数学运算的组合。但真正动手后,你会发现从工具链配置到算法实现,处处都是"…...

深度解析:Live2D Widget WebSocket实时交互架构实践
深度解析:Live2D Widget WebSocket实时交互架构实践 【免费下载链接】live2d-widget 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platform 项目地址: https://gitcode.com/gh_mirrors/li/live2d-widget 在当今Web应用追求沉浸式体验的浪潮…...

技术洞察:如何通过数据预处理优化clip命令行图表生成性能
技术洞察:如何通过数据预处理优化clip命令行图表生成性能 【免费下载链接】clip Create charts from the command line 项目地址: https://gitcode.com/gh_mirrors/cli/clip 在数据可视化领域,clip作为一个命令行驱动的图表生成工具,为…...

CameraFileCopy:重新定义无网络文件传输的安卓应用
CameraFileCopy:重新定义无网络文件传输的安卓应用 【免费下载链接】cfc Demo/test android app for libcimbar. Copy files over the cell phone camera! 项目地址: https://gitcode.com/gh_mirrors/cfc/cfc 在移动设备普及的今天,我们依然经常面…...

Hugo-PaperMod导航菜单异常修复:从故障诊断到性能优化全指南
Hugo-PaperMod导航菜单异常修复:从故障诊断到性能优化全指南 【免费下载链接】hugo-PaperMod A fast, clean, responsive Hugo theme. 项目地址: https://gitcode.com/GitHub_Trending/hu/hugo-PaperMod Hugo-PaperMod作为一款轻量级响应式主题,…...

【LaTeX】学术论文高效排版:从零搭建初稿模板
1. 为什么你需要LaTeX论文模板? 第一次写学术论文时,我像大多数人一样打开了Word。结果光是调整格式就花了三天——页码突然跑到封面中间、参考文献编号莫名其妙重置、公式和图片永远对不齐。直到导师扔给我一个.tex文件说"用这个",…...