【人工智能】从零开始用Python实现逻辑回归模型:深入理解逻辑回归的原理与应用
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门!
逻辑回归是一种经典的统计学习方法,用于分类问题尤其是二分类问题。它通过学习数据的特征和目标标签之间的关系,输出样本属于某个类别的概率。本文将从零开始用Python实现逻辑回归模型,深入探讨其数学原理,并逐步讲解如何编写代码实现。我们会涵盖从数据预处理、特征归一化、梯度下降算法到模型训练的每一个细节。通过丰富的代码示例和详细的中文注释,本文将帮助读者从头掌握逻辑回归模型的构建与优化。
正文
目录
- 逻辑回归简介
- 逻辑回归的数学原理
- 2.1 逻辑回归的假设函数
- 2.2 损失函数的推导
- 2.3 梯度下降优化
- 从零开始实现逻辑回归模型
- 3.1 数据预处理
- 3.2 逻辑回归模型类的定义
- 3.3 编写模型训练方法
- 3.4 编写模型预测方法
- 逻辑回归模型的性能评估
- 4.1 准确率与混淆矩阵
- 4.2 交叉验证
- 完整代码实现
- 实验与结果分析
- 总结
1. 逻辑回归简介
逻辑回归是一种广泛应用的分类模型,通常用于二分类问题。不同于线性回归直接输出一个数值,逻辑回归使用一个Sigmoid函数将预测值映射到[0, 1]区间,以此表示样本属于某个类别的概率。逻辑回归的目标是找到最佳的参数,使得模型能够正确地将输入映射到相应的类别。
2. 逻辑回归的数学原理
逻辑回归的数学基础是线性模型,通过线性组合的输入特征生成一个预测值,然后利用Sigmoid函数将其转换为概率。
2.1 逻辑回归的假设函数
逻辑回归的假设函数为:
h θ ( x ) = σ ( θ T x ) = 1 1 + e − θ T x h_{\theta}(x) = \sigma(\theta^T x) = \frac{1}{1 + e^{-\theta^T x}} hθ(x)=σ(θTx)=1+e−θTx1
其中:
- h θ ( x ) h_{\theta}(x) hθ(x) 是预测的概率值;
- θ \theta θ 是模型的参数向量;
- x x x 是特征向量;
- σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1是Sigmoid激活函数。
Sigmoid函数的输出在(0, 1)之间,表示样本属于正类(标签为1)的概率。
2.2 损失函数的推导
逻辑回归的目标是最小化损失函数(Cost Function),通常选择对数似然函数作为损失函数。对于单个样本,损失函数为:
L ( h θ ( x ) , y ) = − y log ( h θ ( x ) ) − ( 1 − y ) log ( 1 − h θ ( x ) ) L(h_{\theta}(x), y) = -y \log(h_{\theta}(x)) - (1 - y) \log(1 - h_{\theta}(x)) L(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
其中 y 为样本的真实标签。当 y=1 时,我们最小化 − log ( h θ ( x ) ) -\log(h_{\theta}(x)) −log(hθ(x));当 y=0 时,我们最小化 − log ( 1 − h θ ( x ) ) -\log(1 - h_{\theta}(x)) −log(1−hθ(x))。
总体的损失函数,即所有样本的平均损失为:
J ( θ ) = 1 m ∑ i = 1 m ( − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ) J(\theta) = \frac{1}{m} \sum_{i=1}^m \left(-y^{(i)} \log(h_{\theta}(x^{(i)})) - (1 - y^{(i)}) \log(1 - h_{\theta}(x^{(i)}))\right) J(θ)=m1i=1∑m(−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i))))
2.3 梯度下降优化
为了优化损失函数,我们可以使用梯度下降法更新参数 ( \theta )。梯度下降的更新公式为:
θ = θ − α ∇ J ( θ ) \theta = \theta - \alpha \nabla J(\theta) θ=θ−α∇J(θ)
其中:
α \alpha α 是学习率;
- ∇ J ( θ ) \nabla J(\theta) ∇J(θ) 是损失函数 J ( θ ) J(\theta) J(θ)关于参数的梯度。
梯度的计算公式为:
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m} \sum_{i=1}^m \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_j^{(i)} ∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)
3. 从零开始实现逻辑回归模型
接下来,我们将逐步实现逻辑回归模型,包括数据预处理、模型定义、训练和预测。
3.1 数据预处理
首先,我们使用一个简单的二分类数据集。数据集需要进行标准化处理,以提高模型的训练效果。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 生成简单的二分类数据集
np.random.seed(0)
X = np.random.randn(100, 2) # 100个样本,每个样本2个特征
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 简单的线性可分数据# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
3.2 逻辑回归模型类的定义
接下来,我们定义逻辑回归模型类,包括初始化、Sigmoid函数和损失函数的实现。
class LogisticRegression:def __init__(self, learning_rate=0.01, n_iterations=1000):self.learning_rate = learning_rateself.n_iterations = n_iterationsself.weights = Noneself.bias = Nonedef sigmoid(self, z):# 定义Sigmoid激活函数return 1 / (1 + np.exp(-z))def compute_cost(self, y, y_pred):# 计算损失函数m = len(y)cost = (-1 / m) * np.sum(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred))return cost
3.3 编写模型训练方法
使用梯度下降算法优化模型参数。梯度计算基于损失函数的偏导数。
def fit(self, X, y):# 初始化参数m, n = X.shapeself.weights = np.zeros(n)self.bias = 0for i in range(self.n_iterations):# 计算线性模型的预测值linear_model = np.dot(X, self.weights) + self.biasy_pred = self.sigmoid(linear_model)# 计算梯度dw = (1 / m) * np.dot(X.T, (y_pred - y))db = (1 / m) * np.sum(y_pred - y)# 更新权重和偏差self.weights -= self.learning_rate * dwself.bias -= self.learning_rate * db# 每100次迭代打印一次损失if i % 100 == 0:cost = self.compute_cost(y, y_pred)print(f"Iteration {i}: Cost {cost}")
3.4 编写模型预测方法
逻辑回归的预测输出是一个概率值,可以通过设置一个阈值(如0.5)来决定样本属于哪个类别。
def predict(self, X):# 预测函数linear_model = np.dot(X, self.weights) + self.biasy_pred = self.sigmoid(linear_model)return [1 if i > 0.5 else 0 for i in y_pred]
4. 逻辑回归模型的性能评估
为了评估逻辑回归模型的性能,我们使用准确率和混淆矩阵。
4.1 准确率与混淆矩阵
准确率表示正确预测的比例,混淆矩阵能更清晰地展示模型的分类表现。
from sklearn.metrics import accuracy_score, confusion_matrix# 模型训练与预测
model = LogisticRegression(learning_rate=0.1, n_iterations=1000)
model.fit(X_train, y_train)
predictions = model.predict(X_test)# 计算准确率和混淆矩阵
accuracy = accuracy_score(y_test, predictions)
conf_matrix = confusion_matrix(y_test, predictions)print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
4.2
交叉验证
交叉验证通过多次数据划分和训练,得到模型更加稳定和可靠的性能评价。
5. 完整代码实现
以下是逻辑回归模型的完整代码实现:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrixclass LogisticRegression:def __init__(self, learning_rate=0.01, n_iterations=1000):self.learning_rate = learning_rateself.n_iterations = n_iterationsself.weights = Noneself.bias = Nonedef sigmoid(self, z):return 1 / (1 + np.exp(-z))def compute_cost(self, y, y_pred):m = len(y)cost = (-1 / m) * np.sum(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred))return costdef fit(self, X, y):m, n = X.shapeself.weights = np.zeros(n)self.bias = 0for i in range(self.n_iterations):linear_model = np.dot(X, self.weights) + self.biasy_pred = self.sigmoid(linear_model)dw = (1 / m) * np.dot(X.T, (y_pred - y))db = (1 / m) * np.sum(y_pred - y)self.weights -= self.learning_rate * dwself.bias -= self.learning_rate * dbif i % 100 == 0:cost = self.compute_cost(y, y_pred)print(f"Iteration {i}: Cost {cost}")def predict(self, X):linear_model = np.dot(X, self.weights) + self.biasy_pred = self.sigmoid(linear_model)return [1 if i > 0.5 else 0 for i in y_pred]# 数据准备
np.random.seed(0)
X = np.random.randn(100, 2)
y = (X[:, 0] + X[:, 1] > 0).astype(int)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 训练与评估
model = LogisticRegression(learning_rate=0.1, n_iterations=1000)
model.fit(X_train, y_train)
predictions = model.predict(X_test)accuracy = accuracy_score(y_test, predictions)
conf_matrix = confusion_matrix(y_test, predictions)print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
6. 实验与结果分析
在不同的学习率、迭代次数、数据分布下,我们可以调整模型参数并观察损失函数的变化。
7. 总结
本文从零开始用Python实现了逻辑回归模型,包括数学原理、代码实现和性能评估。通过这些步骤,读者可以深入理解逻辑回归的工作原理,并掌握如何从头构建和优化分类模型。
相关文章:

【人工智能】从零开始用Python实现逻辑回归模型:深入理解逻辑回归的原理与应用
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 逻辑回归是一种经典的统计学习方法,用于分类问题尤其是二分类问题。它通过学习数据的特征和目标标签之间的…...
推荐一款功能强大的光学识别OCR软件:Readiris Dyslexic
Readiris Dyslexic是一款功能强大的光学识别OCR软件,可以扫描任何纸质文档并将其转换为完全可编辑的数字文件(Word,Excel,PDF),然后用你喜欢的编辑器进行编辑。该软件提供了一种轻松创建,修改和签名PDF的完整解决方法&…...

Python爬虫----python爬虫基础
一、python爬虫基础-爬虫简介 1、现实生活中实际爬虫有哪些? 2、什么是网络爬虫? 3、什么是通用爬虫和聚焦爬虫? 4、为什么要用python写爬虫程序 5、环境和工具 二、python爬虫基础-http协议和chrome抓包工具 1、什么是http和https协议…...

css-50 Projects in 50 Days(3)
html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>旋转页面</title><link rel"sty…...

另外一种缓冲式图片组件的用法
文章目录 1. 概念介绍2. 使用方法2.1 基本用法2.2 缓冲原理3. 示例代码4. 内容总结我们在上一章回中介绍了"FadeInImage组件"相关的内容,本章回中将介绍CachedNetworkImage组件.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在本章回中介绍的CachedNetwo…...

字节青训-小C的外卖超时判断、小C的排列询问
目录 一、小C的外卖超时判断 问题描述 测试样例 解题思路: 问题理解 数据结构选择 算法步骤 最终代码: 运行结果: 二、小C的排列询问 问题描述 测试样例 最终代码: 运行结果: 编辑 一、小C的外卖超时判断…...

PHP 伪静态详解及实现方法
概述 在现代 Web 开发中,URL 的设计对用户体验和搜索引擎优化(SEO)至关重要。动态 URL 虽然功能强大,但往往显得冗长且不友好。伪静态(URL 重写)技术通过将动态 URL 转换为静态样式,不仅提高了…...

Spring Boot 简单预览PDF例子
目录 前言 一、引入依赖 二、使用步骤 1.创建 Controller 处理 PDF 生成和预览 2.创建预览页面 总结 前言 使用 Spring Boot 创建一个生成 PDF 并进行预览的项目,你可以按以下步骤进行。我们将使用 Spring Boot、Thymeleaf、iText 等技术来完成这个任务。 一、引入…...

【魔珐有言-注册/登录安全分析报告-无验证方式导致安全隐患】
前言 由于网站注册入口容易被机器执行自动化程序攻击,存在如下风险: 暴力破解密码,造成用户信息泄露,不符合国家等级保护的要求。短信盗刷带来的拒绝服务风险 ,造成用户无法登陆、注册,大量收到垃圾短信的…...
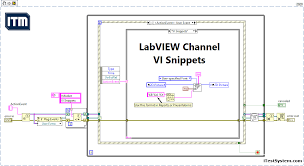
LabVIEW 使用 Snippet
在 LabVIEW 中,Snippet(代码片段) 是一个非常有用的功能,它允许你将 一小段可重用的代码 保存为一个 图形化的代码片段,并能够在不同的 VI 中通过拖放来使用。 什么是 Snippet? Snippet 就是 LabVIEW 中的…...

单片机_day3_GPIO
目录 1. 灯如何才能亮 1.1原理图 1.2 二极管 1.3 换了一个灯和原理图 编辑 1.4 三极管 1.4.1 NPN型三极管 1.4.2 PNP型三极管 2. 基本概念 3. 输入 3.1 浮空输入 3.2 上拉输入 3.3 下拉输入 3.4 模拟输入 4. 输出 4.1 推挽输出 4.2 开漏输出 如何让开漏输出…...

Python小游戏24——小恐龙躲避游戏
首先,你需要安装Pygame库。如果你还没有安装,可以通过以下命令安装: 【bash】 pip install pygame 【python】代码 import pygame import random # 初始化Pygame pygame.init() # 设置屏幕尺寸 screen_width 800 screen_height 600 screen …...

Python 的多态笔记
Python的多态实际是通过instance 实现的 class Person:def __init__(self, name,age):self.name nameself.age agedef feed_pet(self,pet):#isinastance(obj,类)-->判断obj,是不是这个类的对象,或者判断obj是不是该类的子类的对象if isinstance(pet, Pet):sel…...

go module使用
go module介绍 go module是go官⽅⾃带的go依赖管理库,在1.13版本正式推荐使⽤ go module可以将某个项⽬(⽂件夹)下的所有依赖整理成⼀个 go.mod ⽂件,⾥⾯写⼊了依赖的版本等 使⽤ go module之后我们可不⽤将代码放置在src下了 使⽤ go module 管理依赖后会在项⽬根⽬录下⽣成…...

c ++零基础可视化——数组
c 零基础可视化 数组 一些知识: 关于给数组赋值,一个函数为memset,其在cplusplus.com中的描述如下: void * memset ( void * ptr, int value, size_t num );Sets the first num bytes of the block of memory pointed by ptr to…...

CVE-2024-2961漏洞的简单学习
简单介绍 PHP利用glibc iconv()中的一个缓冲区溢出漏洞,实现将文件读取提升为任意命令执行漏洞 在php读取文件的时候可以使用 php://filter伪协议利用 iconv 函数, 从而可以利用该漏洞进行 RCE 漏洞的利用场景 PHP的所有标准文件读取操作都受到了影响࿱…...

计算机组成原理笔记----基础篇
计算机系统硬件软件 软件 ├── 系统软件 │ ├── 操作系统 │ └── 工具软件 └── 应用软件├── 办公软件├── 媒体软件└── 浏览器软件硬件 ├── 计算机硬件 │ ├── 中央处理器(CPU) │ ├── 存储设备 │ │ ├── …...

TheadLocal出现的内存泄漏具体泄漏的是什么?弱引用在里面有什么作用?什么情景什么问题?
首先ThreadLocal是什么就不介绍了!这篇是讲讲里面的东西。 再简单说一下强引用和弱引用,举个例子,我们平常new出来的对象就是强引用的,在栈中有强引用,所以在gc的时候,堆中的实例对象不会被清除掉。 弱引…...

AI在电商平台中的创新应用:提升销售效率与用户体验的数字化转型
1. 引言 AI技术在电商平台的应用已不仅仅停留在基础的数据分析和自动化推荐上。随着人工智能的迅速发展,越来越多的电商平台开始将AI技术深度融合到用户体验、定价策略、供应链优化、客户服务等核心业务中,从而显著提升运营效率和用户满意度。在这篇文章…...

CTF-RE 从0到N:RC4
RC4加密算法简介 RC4是由Ron Rivest于1987年设计的一种流加密算法。它通过伪随机数生成器生成密钥流,并将该密钥流与明文进行异或运算来完成加密和解密。 RC4的加密流程 RC4主要包含两个阶段: 密钥调度算法 (Key Scheduling Algorithm, KSA)ÿ…...

BG3ModManager终极指南:如何轻松管理博德之门3模组避免游戏崩溃?
BG3ModManager终极指南:如何轻松管理博德之门3模组避免游戏崩溃? 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager BG3ModMana…...

ngx_http_create_request
1 定义 ngx_http_create_request 函数 定义在 ./nginx-1.24.0/src/http/ngx_http_request.cngx_http_request_t * ngx_http_create_request(ngx_connection_t *c) {ngx_http_request_t *r;ngx_http_log_ctx_t *ctx;ngx_http_core_loc_conf_t *clcf;r ngx_http_…...

Cursor AI 使用限制突破:设备标识重置与多账户管理的技术实现
Cursor AI 使用限制突破:设备标识重置与多账户管理的技术实现 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

droidrun-agent:基于MCP协议连接AI智能体与安卓设备的自动化桥梁
1. 项目概述:当AI助手需要“动手”时在AI Agent(智能体)领域,我们常常遇到一个瓶颈:模型可以生成完美的计划、写出漂亮的代码,但它如何与真实世界交互,尤其是如何操作一台物理设备?比…...

SQLite Having 子句详解
SQLite Having 子句详解 SQLite 是一款轻量级的数据库管理系统,广泛应用于移动应用、桌面应用以及各种嵌入式系统。在 SQLite 中,HAVING 子句是一个非常重要的特性,它用于对 GROUP BY 子句的查询结果进行过滤。本文将详细介绍 SQLite 的 HAVING 子句,包括其用法、语法以及…...

基于WebSocket的Web即时通讯后端架构设计与实战部署指南
1. 项目概述:一个面向开发者的Web即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个稳定、可控且能深度定制的即时通讯模块。市面上成熟的IM SDK很多,但要么是黑盒,出了问题排查困难;要么是功能臃肿࿰…...

Super IO插件:Blender文件操作效率革命,从繁琐拖拽到智能粘贴
Super IO插件:Blender文件操作效率革命,从繁琐拖拽到智能粘贴 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io Super IO是一款革命性的Blender插件,通…...

《凰标》:写给所有被资本轻视的创作者@凤凰标志
——写给所有不被看见的创作者没有流量即是无用, 没有热度即是不值, 没有商业变现能力即是小众累赘。在资本主导的文娱评价体系里,这条偏见像一道隐形天花板,横亘在每一个草根创作者的头顶。一、被算法淹没的匠心 他们怀揣赤诚热爱…...

BetaClaw:开源AI代理运行时,统一多模型调用与智能成本控制
1. 项目概述:一个为开发者打造的“瑞士军刀”级AI代理运行时如果你和我一样,每天都在和不同的AI模型打交道,那你一定也经历过这种痛苦:想用Claude写点创意文案,得去Anthropic的API;想用GPT-4o分析代码&…...

基于LLM的多智能体协作框架:从原理到实践构建自主开发团队
1. 项目概述与核心价值最近在开源社区里,一个名为zxkane/autonomous-dev-team的项目引起了我的注意。乍一看这个标题,你可能会联想到科幻电影里的全自动机器人编程,或者是一些过于理想化的“AI接管开发”的噱头。但在我花时间深入研究和实践之…...