【大数据学习 | HBASE高级】hive操作hbase
一般在查询hbase的数据的时候我们可以直接使用hbase的命令行或者是api进行查询就行了,但是在日常的计算过程中我们一般都不是为了查询,都是在查询的基础上进行二次计算,所以使用hbase的命令是没有办法进行数据计算的,并且对于hbase的压力也会增加很多,hbase的本身并没有提供任何的计算逻辑,所以我们要依赖于mapreducer进行计算,这个代码上面我们已经实现过了,但是后续开发过程中很少有人会直接开发mr程序,这个代码的复杂程度比较高,并且会非常大的拖慢我们的开发速度,所以一般我们都会使用hive以外表的形式操作hbase中的数据,进行多表的管理查询计算或者是进行数据的导入和导出。
首先在hive中增加hbase的链接信息。
修改hive-site.xml中的值。
<property><name>hive.zookeeper.quorum</name><value>hadoop106,hadoop107,hadoop108</value>
</property>
<property><name>hive.zookeeper.client.port</name><value>2181</value>
</property>在自己的hadoop目录下的mapred-site.xml文件修改:
<property><name>hive.zookeeper.quorum</name><value>hadoop106,hadoop107,hadoop108</value>
</property>
<property><name>hive.zookeeper.client.port</name><value>2181</value>
</property>在hive/conf目录中增加log4j.properties文件输入日志级别设置
log4j.rootLogger=error,consolelog4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c %M(): %m%n然后启动hive就可以直接连接hbase了
1. 创建hive的内部表
hive的内部表,hive会不仅会管理元数据信息,也会管理整个表的其他所有数据。当在hive创建该表时,将会在hbase创建映射表。
create table student_hive(id int,name string,age int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:name,info:age")
TBLPROPERTIES ("hbase.table.name" = "student_hbase1");
# 删除hive中的表
drop table student_hive;
# 内部表在删除的时候hbase的表也会被删除
可以看到hbase中的映射表被删除。
2. 创建外部表
有的时候在hbase中已经存在一个表并且其中存在数据,我们需要使用hive进行分析,那么我们就需要创建一个外部表进行映射。
# 首先在hbase中创建表
create 'student_hbase','info'
# 增加数据
put 'student_hbase','1','info:name','zhangsan'
put 'student_hbase','1','info:age','20'
put 'student_hbase','2','info:name','lisi'
put 'student_hbase','2','info:age','30'
# 这个时候就需要创建外部表进行映射
create external table student_hive(id int,name string,age int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:name,info:age")
TBLPROPERTIES ("hbase.table.name" = "student_hbase");hbase:012:0> create 'student_hbase','info'
Created table student_hbase
Took 1.2293 seconds
=> Hbase::Table - student_hbase
hbase:013:0> list
TABLE
student_hbase
hainiu:advance_split_region
hainiu:info
hainiu:stu
hainiu:student
5 row(s)
Took 0.0148 seconds
=> ["student_hbase", "hainiu:advance_split_region", "hainiu:info", "hainiu:stu", "hainiu:student"]
hbase:014:0> put 'student_hbase','1','info:name','zhangsan'
Took 0.3755 seconds
hbase:015:0> put 'student_hbase','1','info:age','20'
Took 0.0229 seconds
hbase:016:0> put 'student_hbase','2','info:name','lisi'
Took 0.0219 seconds
hbase:017:0> put 'student_hbase','2','info:age','30'
Took 0.0128 seconds
hbase:018:0> scan 'student_hbase';
ROW COLUMN+CELL 1 column=info:age, timestamp=2024-11-13T22:35:58.531, value=20 1 column=info:name, timestamp=2024-11-13T22:35:58.471, value=zhangsan 2 column=info:age, timestamp=2024-11-13T22:36:05.765, value=30 2 column=info:name, timestamp=2024-11-13T22:35:58.604, value=lisi
2 row(s)
Took 0.1260 seconds 
删除表,因为hive对应的是外部表所以hbase的表不会被删除掉。
drop table student_hive;3. 关联计算表的值
hbase中创建工资表
#创建salary工资表
create 'salary','info'
put 'salary','001','info:id','1'
put 'salary','002','info:id','1'
put 'salary','003','info:id','1'
put 'salary','004','info:id','2'
put 'salary','005','info:id','2'
put 'salary','006','info:id','2'put 'salary','001','info:salary','1000'
put 'salary','002','info:salary','2000'
put 'salary','003','info:salary','3000'
put 'salary','004','info:salary','4000'
put 'salary','005','info:salary','5000'
put 'salary','006','info:salary','6000'#创建hive的表映射
create external table salary_hive(salary_id string,id int,salary int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:id,info:salary")
TBLPROPERTIES ("hbase.table.name" = "salary");现在实现关联查询,每个用户的平均工资是多少,以及人名。
select a.name,avg(b.salary) as avg
from student_hive a join salary_hive b
on a.id = b.id
group by a.name可以根据计算得出最终结果。
4. hbase的数据导入导出
hbase的数据导出
# 使用hive的导出命令可以直接导出数据
insert overwrite local directory '/home/hadoop/salary.txt' select * from salary_hive;可以通过外表的形式直接将数据导出到文件夹中。

结果数据查看:。。
导入数据
不能用hive的load方式直接将数据导入到hbase中,但是可以通过中间表的形式导入进行。
# 首先在本地创建teacher.txt 输入以下内容
1,yeniu,20
2,xinniu,30
3,qingniu,35
# 在hive中创建临时表
create table teacher_tmp(id int,name string,age int)
row format delimited fields terminated by ',';
# 将数据加载到临时表中
load data local inpath '/home/hadoop/teacher.txt' into table teacher_tmp;
# 创建和hbase的外部映射表
create table teacher_hive(id int,name string,age int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:name,info:age")
TBLPROPERTIES ("hbase.table.name" = "teacher_hbase");#从临时表使用mr将数据导入到hbase中insert into teacher_hive select * from teacher_tmp;5. hbase的bulkload
在大数据的场景计算中,有时候我们会遇见将大量数据一次性导入到hbase的情况,但是这个时候hbase是不能够容纳的,因为插入的数据首先会进入到memstore中如果大量插入数据会造成memstore的内存压力急剧增大,这个时候机器的其他进程是没有办法执行的,并且还会出现非常严重的问题,比如hbase在大量插入数据的时候首先这个region会急剧增加,后续region会按照拆分策略进行region拆分,当前region下线,插入程序会直接卡死造成hbase宕机等严重问题,为了解决这个问题,hbase给用户提供了一种新的插入数据的方式bulkload方式,这个方式中会跳过hbase本身的过程,首先在使用hbase的提供的mapreduce程序按照插入数据的格式和hbase的表格式生成hfile文件,然后我们将hfile文件一次性插入到hbase对应的hdfs的文件夹中,这种方式是最快捷并且对于hbase的压力最小的方式。
过程如下:
# 首先在本地创建文件a.txt 输入以下内容
1,zhangsan,20
2,lisi,30
3,wangwu,40
5 zhaosi,50
# 然后将数据上传到hdfs中
hdfs dfs -put a.txt /
# 在hbase中创建表
create 't','info'
# 然后将id当成是rowkey,info:name存放名称 info:age存放年龄执行importTSV方法,产生hfile文件
-Dimporttsv.separator :指定分隔符-Dimporttsv.columns :指定列映射 HBASE_ROW_KEY强制要求写 cf:pk指定rowkey字段 其他字段与hive表中对应-Dimporttsv.skip.bad.lines:是否跳过无效行-Dimporttsv.bulk.output:hfile输出路径hbase表名hdfs://worker-1:8020/data/hainiu/t2 :用于生成hfile文件的输入目录具体执行命令如下:
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator=',' \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age \
-Dimporttsv.skip.bad.lines=false \
-Dimporttsv.bulk.output=/t \
default:t hdfs://ns1/a.txt查看hdfs文件,发现hfile文件已经生成,然后我们将数据导入到hdfs对应的目录中。
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /t default:t相关文章:
【大数据学习 | HBASE高级】hive操作hbase
一般在查询hbase的数据的时候我们可以直接使用hbase的命令行或者是api进行查询就行了,但是在日常的计算过程中我们一般都不是为了查询,都是在查询的基础上进行二次计算,所以使用hbase的命令是没有办法进行数据计算的,并且对于hbas…...

集群聊天服务器(9)一对一聊天功能
目录 一对一聊天离线消息服务器异常处理 一对一聊天 先新添一个消息码 在业务层增加该业务 没有绑定事件处理器的话消息会派发不出去 聊天其实是服务器做一个中转 现在同时登录两个账号 收到了聊天信息 再回复一下 离线消息 声明中提供接口和方法 张三对离线的李…...
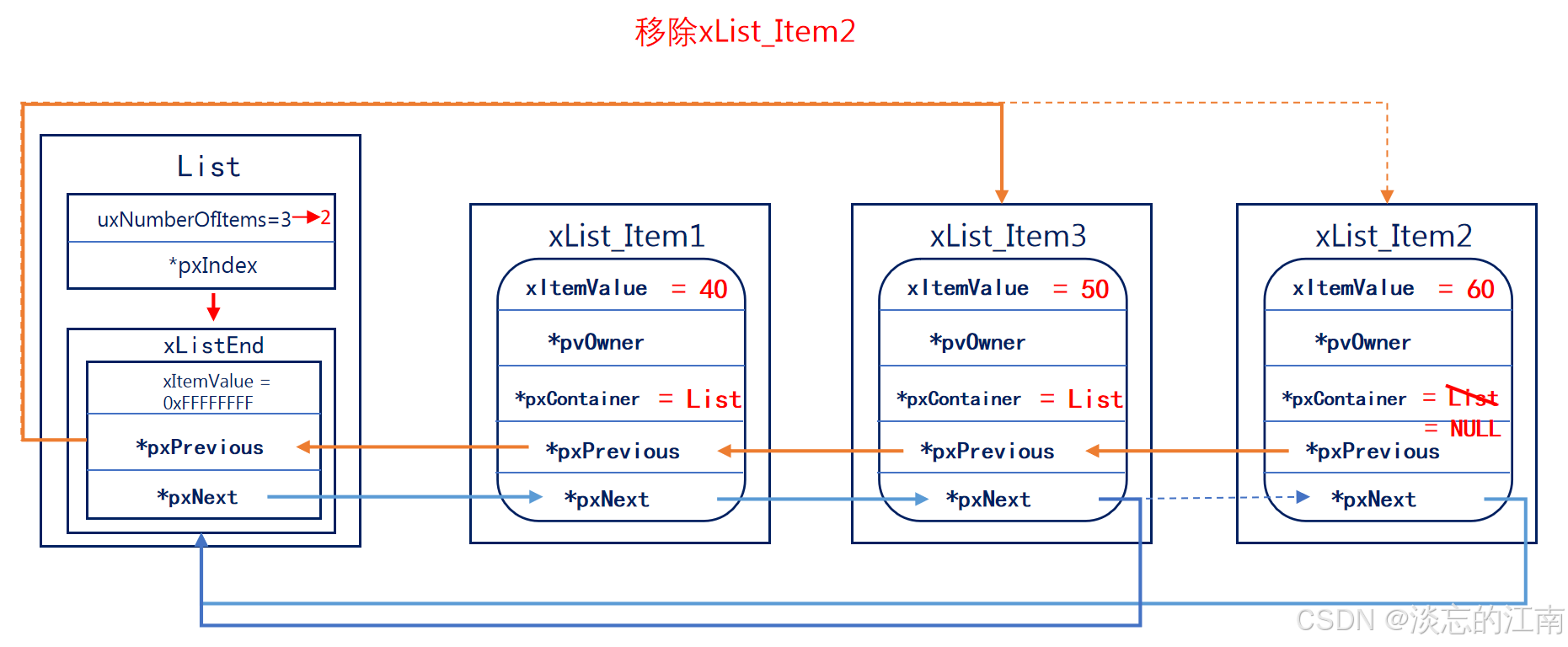
《FreeRTOS列表和列表项篇》
FreeRTOS列表和列表项 1. 什么是列表和列表项?1.1 列表list1.2 列表项list item 2. 列表和列表项的初始化2.1 列表的初始化2.2 列表项的初始化 3. 列表项的插入4. 列表项末尾插入5. 列表项的删除6. 列表的遍历 列表和列表项是FreeRTOS的一个数据结构,是F…...

C++:哈希拓展-位图
目录 一.问题导入 二.什么是位图? 2.1如何确定目标数在哪个比特位? 2.2如何存放高低位 2.3位图模拟代码实现 2.3.1如何标记一个数 2.3.2如何重置标记 2.3.3如何检查一个数是否被标记 整体代码实现 标准库的Bitset 库中的bitset的缺陷 简单应用 一.问题导入 这道…...

【数据结构与算法】查找
文章目录 一.查找二.线性结构的查找2.1顺序查找2.2折半查找2.3分块查找 三.树型结构的查找3.1二叉排序树1.定义2.二叉排序树的常见操作3.性能分析 3.2平衡二叉树1.定义2.平衡二叉树的常见操作3.性能分析 3.3B树1.定义2.B树的相关操作 3.4B树1.定义2.B树与B树的比较 四.散列表1.…...

从零开始学习 sg200x 多核开发之 milkv-duo256 编译运行 sophpi
sophpi 是 算能官方针对 sg200x 系列的 SDK 仓库 https://github.com/sophgo/sophpi ,支持 cv180x、cv81x、sg200x 系列的芯片。 SG2002 简介 SG2002 是面向边缘智能监控 IP 摄像机、智能猫眼门锁、可视门铃、居家智能等多项产品领域而推出的高性能、低功耗芯片&a…...

LLM - 使用 LLaMA-Factory 微调大模型 Qwen2-VL SFT(LoRA) 图像数据集 教程 (2)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/143725947 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 LLaMA-…...
_265)
基于STM32设计的大棚育苗管理系统(4G+华为云IOT)_265
文章目录 一、前言1.1 项目介绍【1】项目开发背景【2】设计实现的功能【3】项目硬件模块组成【4】设计意义【5】国内外研究现状【6】摘要1.2 设计思路1.3 系统功能总结1.4 开发工具的选择【1】设备端开发【2】上位机开发1.5 参考文献1.6 系统框架图1.7 系统原理图1.8 实物图1.9…...

深入浅出《钉钉AI》产品体验报告
1. 引言 随着人工智能技术的迅猛发展,企业协同办公领域迎来了新的变革。钉钉作为阿里巴巴集团旗下的企业级通讯与协同办公平台,推出了钉钉AI助理,旨在提高工作效率,优化用户体验。本报告将对钉钉AI助理进行全面的产品体验分析&am…...
)
2020年计挑赛往届真题(C++)
因为17号要开赛了,甚至是用云端编辑器,debuff拉满,只能临时抱佛脚了 各个选择题的选择项我就不标出来了,默认ABCD排,手打太麻烦了 目录 单选题: 1.阅读以下语句:double m0;for(int i3;i>0;i--)m1/i;…...

ES6进阶知识二
一、promise方法的案例 Promise对象通过new Promise()语法创建,它接受一个函数作为参数,该函数接受两个参数:resolve和reject。resolve表示异步操作成功,reject表示异步操作失败。 案例:异步加载图片 const loadIma…...
)
大语言模型通用能力排行榜(2024年10月8日更新)
数据来源SuperCLUE 榜单数据为通用能力排行榜 排名 模型名称 机构 总分 理科 文科 Hard 使用方式 发布日期 - o1-preview OpenAI 75.85 86.07 76.6 64.89 API 2024年11月8日 - Claude 3.5 Sonnet(20241022) Anthropic 70.88 82.4…...

第六节、Docker 方式部署指南 github 上项目 mkdocs-material
一、简介 MkDocs 可以同时编译多个 markdown 文件,形成书籍一样的文件。有多种主题供你选择,很适合项目使用。 MkDocs 是快速,简单和华丽的静态网站生成器,可以构建项目文档。文档源文件在 Markdown 编写,使用单个 YAML 配置文件配置。 MkDocs—markdown项目文档工具,…...

【MySQL】MySQL中的函数之JSON_REPLACE
在 MySQL 中,JSON_REPLACE() 函数用于在 JSON 文档中替换现有的值。如果指定的路径不存在,则 JSON_REPLACE() 不会修改 JSON 文档。如果需要添加新的键值对,可以使用 JSON_SET() 函数。 基本语法 JSON_REPLACE(json_doc, path, val[, path,…...

【大数据学习 | HBASE高级】hbase的API操作
首先引入hbase的依赖 <dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.4.13</version></dependency><dependency><groupId>org.slf4j<…...

C++(Qt)软件调试---内存泄漏分析工具MTuner (25)
C(Qt)软件调试—内存泄漏分析工具MTuner (25) 文章目录 C(Qt)软件调试---内存泄漏分析工具MTuner (25)[toc]1、概述🐜2、下载MTuner🪲3、使用MTuner分析qt程序内存泄漏🦧4、相关地址ὁ…...

python核心语法
目录 核⼼语法第⼀节 变量0.变量名规则1.下⾯这些都是不合法的变量名2.关键字3.变量赋值4.变量的销毁 第⼆节 数据类型0.数值1.字符串2.布尔值(boolean, bool)3.空值 None 核⼼语法 第⼀节 变量 变量的定义变量就是可变的量,对于⼀些有可能会经常变化的数据&#…...

MATLAB用CNN-LSTM神经网络的语音情感分类深度学习研究
全文链接:https://tecdat.cn/?p38258 在语音处理领域,对语音情感的分类是一个重要的研究方向。本文将介绍如何通过结合二维卷积神经网络(2 - D CNN)和长短期记忆网络(LSTM)构建一个用于语音分类任务的网络…...
智能网页内容截图工具:AI助力内容提取与可视化
我们每天都会接触到大量的网页内容。然而,如何从这些内容中快速提取关键信息,并有效地进行整理和分享,一直是困扰我们的问题。本文将介绍一款我近期完成的基于AI技术的智能网页内容截图工具,它能够自动分析网页内容,截…...

Axure设计之文本编辑器制作教程
文本编辑器是一个功能强大的工具,允许用户在图形界面中创建和编辑文本的格式和布局,如字体样式、大小、颜色、对齐方式等,在Web端实际项目中,文本编辑器的使用非常频繁。以下是在Axure中模拟web端富文本编辑器,来制作文…...

PFC2D几何操作避坑指南:geometry命令导出STL成功,DXF却报错?手把手教你排查
PFC2D几何操作避坑指南:geometry命令导出STL成功,DXF却报错?手把手教你排查 在岩土工程和颗粒流分析领域,PFC2D/3D作为一款强大的离散元分析软件,其几何操作功能是构建复杂模型的关键。许多用户在尝试使用geometry exp…...

企业级长文档AI落地避坑指南,从PDF解析失真到语义断裂修复——Claude 2026六大隐性能力详解
更多请点击: https://intelliparadigm.com 第一章:PDF解析失真问题的根源与本质诊断 PDF 文件虽为“便携式文档格式”,但其内部结构高度异构——文本可能嵌入在图形路径中、字体被子集化或完全缺失、字符编码映射断裂,甚至存在跨…...

2025届学术党必备的五大降重复率方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下知网已然上线了AI检测功能,会针对论文里疑似人工智能生成的内容展开识别。为…...

喜马拉雅VIP音频下载指南:xmly-downloader-qt5完整解决方案
喜马拉雅VIP音频下载指南:xmly-downloader-qt5完整解决方案 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 你是否曾为…...

如何在Windows任务栏实时监控股票行情:TrafficMonitor股票插件终极指南
如何在Windows任务栏实时监控股票行情:TrafficMonitor股票插件终极指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 你是否曾经在工作时频繁切换窗口查看股票行情…...

基于OpenClaw的GitHub趋势智能监控器:自动化追踪与AI摘要推送
1. 项目概述:一个为开发者打造的GitHub趋势智能监控器 作为一名长期泡在GitHub上的开发者,我深知每天手动刷“Trending”页面有多低效。热门项目层出不穷,但真正值得关注的往往就那么几个,而且很容易被淹没在信息流里。直到我遇到…...

Linux操作系统软件编程——多线程
什么是线程线程的定义是轻量级的进程,可以实现多任务的并发。线程是操作系统任务调度的最小单位,一个进程至少有一个线程线程的创建由某个进程创建,且进程创建线程时,会为其分配独立的栈区空间(默认8M)。线…...

Windows安装安卓APK的终极指南:APK Installer免费工具完整教程
Windows安装安卓APK的终极指南:APK Installer免费工具完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法直接运行安卓应用而烦…...

ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略
ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux…...

大模型评测实战指南:从基准测试到技术选型的全流程解析
1. 项目概述:为什么我们需要一个“大模型评测”清单?如果你在过去一年里深度参与过大语言模型(LLM)的应用开发、技术选型或者仅仅是技术追踪,你大概率会和我有同样的感受:“评测”这件事,变得越…...