上交大与上海人工智能研究所联合推出医学多语言模型,模型数据代码开源
今天为大家介绍的是来自上海交通大学的王延峰与谢伟迪团队的一篇论文。开源的多语言医学语言模型的发展可以惠及来自不同地区、语言多样化的广泛受众。
来源丨 DrugAI、 机器人的脑电波

论文:https://www.nature.com/articles/s41467-024-52417-z
MMedC:https://huggingface.co/datasets/Henrychur/MMedC
MMedBench:https://huggingface.co/datasets/Henrychur/MMedBench
代码:https://github.com/MAGIC-AI4Med/MMedLM
在近期研究中,大型语言模型在医疗领域展现了巨大潜力。例如,GPT-4和MedPalm-2等闭源模型表现优异,通过了美国医学执照考试。同时,像Llama 2这样的开源模型也促进了医学专用语言模型的发展,如MEDITRON、PMC-LLaMA、MedAlpaca和ChatDoctors,逐步缩小了与闭源模型的性能差距。然而,这些模型主要面向英语应用,限制了其在更广泛语言环境中的使用。在开源的多语言LLM领域,尽管模型如BLOOM和InternLM已在多语言语料库上训练,但在非英语医学问题上的表现仍不理想,主要原因是医疗内容在通用数据集中占比不足。本文通过开发一个开源的多语言医疗语言模型,旨在填补这一空白。

该研究的贡献包括三方面:
-
构建了一个包含255亿tokens的多语言医学语料库MMedC,用于自回归训练;
-
提出了一个多语言医学多项选择问答基准MMedBench,用于评估模型在零样本和微调设置下的问答和推理能力;
-
测试了多种现有模型及在MMedC上进一步训练的模型。通过这些全面评估,作者希望更好地理解模型在多语言医学问题处理中的能力。
方 法
为了实现自回归训练,开发了一个大规模多语言医疗语料库(MMedC),汇集了超过255亿个涵盖主要六种语言的医疗相关标记:英语、中文、日语、法语、俄语和西班牙语。这一多样化的数据集由四个不同的来源编制而成:
(i) 设计了一个自动化管道从大众多语言语料库中过滤医疗相关内容,确保数据集的聚焦和相关性;
(ii) 策划并收集了多种语言的医学教科书,并通过精心设计的预处理如光学字符识别(OCR)、启发式数据过滤等转换为文本;
(iii) 为保证医疗知识的广泛涵盖,从一些开源医疗网站中加入文本,丰富了语料库的权威和综合性信息;
(iv) 整合了一些现有的小规模医疗语料数据集,进一步增强了广度和深度。
据了解,MMedC代表了第一个多语言医疗领域的专用语料库。
对于基准评估的设定,开始于汇聚现有的跨六种语言的医疗多选问答数据集,如同于MMedC。进一步通过使用GPT-4增强它们的推理内容,丰富数据集以支持正确答案的解释。因此,增强的数据集涵盖53,566对问答,其中每种语言都提供独特的多选问答及随附的推理推断。这个广泛的收集囊括了从内科、生物化学、药理学到精神病学等多个医学领域。
实 验
在评估阶段,我们对十一种现有支持多国语言的LLMs进行全面基准测试,包括GPT-3.5、GPT-4、Gemini-1.0、BLOOM、InternLM、InternLM 2, MedAlpaca、ChatDoctor、PMC-LLaMA、Mistral、BioMistral、MEDITRON、Llama 2 和 Llama 3,以及那些在MMedC上进一步训练的LLM。模型在三种不同设置下进行评估:零样本、参数高效微调(PEFT)和完整微调。考虑到评估推理质量的复杂性,在运用主流自动化指标之外,我们还结合了人类评级分数在我们的分析中。这种双重方法不仅提供了对每个模型性能的全面度量,还使我们能够深入探究自动化指标与人工评分之间的相关性,从而丰富了用于评估大型语言模型推理能力的方法。
在实验中,那些进一步在MMedC上进行自回归训练的模型一致展示出提升的性能,从而强调了我们编制的多语言语料库的重要性和有效性。最终模型MMed-Llama 3在多语言和仅英语基准上均表现最佳。我们将公开我们的数据集(除去有许可证限制的书籍,我们将提供一个书名列表)、代码库和训练模型,以促进未来的研究。此外,我们深知稳健评估指标准确性的重要性,尤其是在涉及复杂长句的医学文本生成时。为此,详细的人类评级结果也将针对个别案例公开发布。
数据统计
作者统计了两个数据集的详细情况,即目前最广泛的多语言医学语料库MMedC和新的多语言医学基准MMedBench。

如图2所示,MMedC是一个包含超过255亿tokens的多语言医学语料库,主要来自四个来源:从大型多语言语料库中过滤的医学内容、医学教科书、医学网站以及现有的小规模语料库。语料库涵盖六种语言,英语占比42%,俄语最少,仅占7%,但即使最小份额也相当于约20亿tokens。
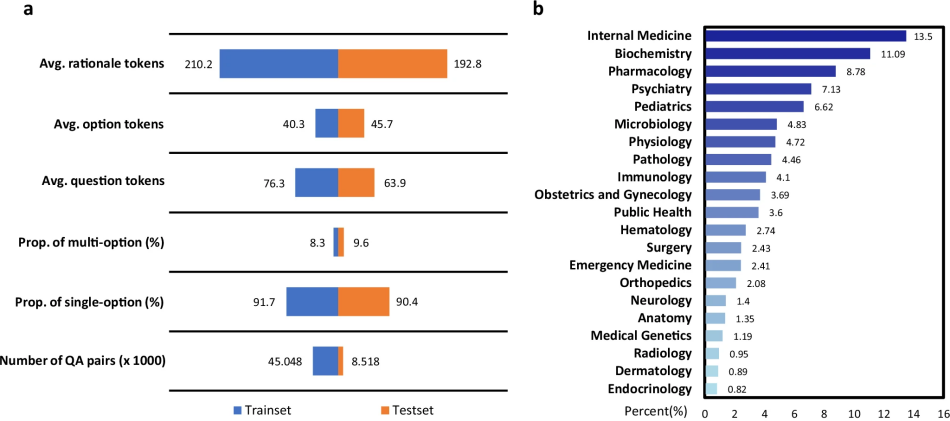
为了更好地评估多语言医学模型,作者还提出了MMedBench,一个多语言医学问答基准。该基准包含训练和测试用例的数量、答案选项分布,以及问答对的平均长度。如图3a所示,MMedBench包含许多带有多选答案的问题,答案部分平均有200个标记,用于训练模型生成和理解复杂的推理内容。
作者利用GPT-4将每个问题分类为21个医学主题,如内科、生物化学、药理学、精神病学、微生物学等,并由至少两位临床医生验证其准确性,确保涵盖医学领域的广度。图3b展示了MMedBench从基础临床医学到药理学和公共卫生等专业领域的医学问题,尤其侧重于内科和生物化学。这表明该基准在评估模型处理广泛医学问题的能力方面非常有效。
MMedBench评估
作者使用MMedBench对主要的LLMs进行了全面评估,包括零样本、参数高效微调(PEFT)和全量微调。评估侧重于多项选择题的准确性和生成推理的能力。模型分为四类:闭源LLMs、流行的开源LLMs、医学专用开源LLMs,以及在MMedC上进一步训练的模型。
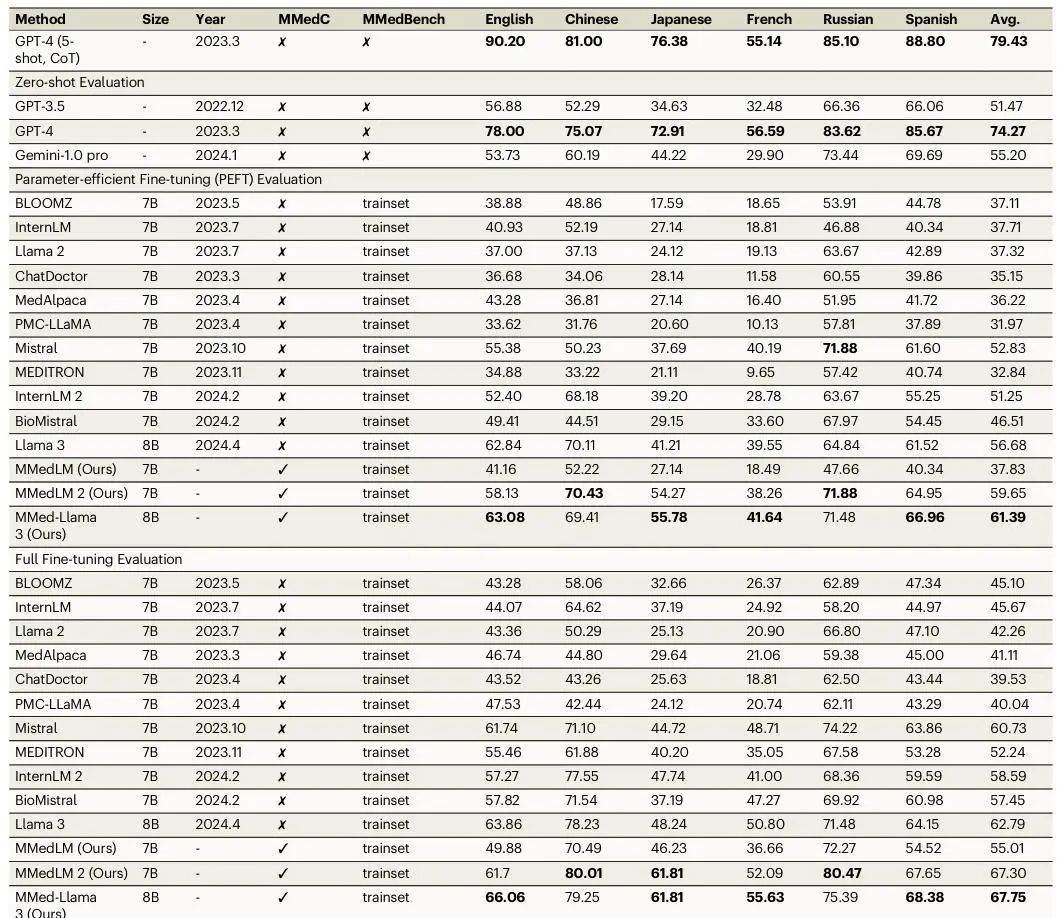
首先,作者评估了GPT-3.5、GPT-4和Gemini-1.0 pro等闭源模型,它们仅在零样本设置下测试。由于训练数据不公开,难以判断其是否真正“零样本”。接着,作者评估了开源模型如Mistral、InternLM 2和Llama 3,发现它们在零样本设置下表现较差,故在微调设置下进行对比。最后,作者测试了在MMedC上进一步训练的模型,包括MMedLM、MMedLM 2和MMed-Llama 3,这些模型通过自回归训练,提升了医学领域的知识。
在多语言多项选择问答任务中,医学专用LLMs在英语中表现较好,但在其他语言中的表现显著下降。微调后的开源模型逐步缩小了与GPT系列的差距,如Mistral、InternLM 2和Llama 3在MMedBench上的平均准确率分别为60.73、58.59和62.79。进一步在MMedC上训练后,MMed-Llama 3表现出显著提升,如在全量微调中,MMed-Llama 3的准确率达到67.75,高于未训练版本的62.79。

除了多项选择问答任务,作者还评估了各模型的推理能力,使用BLEU、ROUGE等自动化指标以及BERT-score进行评价,并结合人工评分。作者随机选取测试集中的50个样本,由5位医学研究生对生成结果进行评分,评价标准包括准确性、推理能力和专业知识,同时使用GPT-4作为辅助评估者。图4a显示,MMed-Llama 3在人工评分(4.10)和GPT-4评分(4.73)中均得分最高。
作者还分析了自动化指标与人工评分的相关性,结果表明GPT-4的评分与人工评分的相关性最高,但不易推广到新模型评估。在自动化指标中,BERT-score表现最为可靠,因此建议在未来研究中使用BERT-score作为推理能力评估的基准。
英文基准评估
作者在MMed-Llama 3的微调中加入了额外的英文指令,并与其他LLMs在英文基准上进行了对比。评估基准包括MedQA、MedMCQA、PubMedQA和MMLU-Medical。MedQA和MedMCQA主要测试诊断和治疗能力,PubMedQA侧重于生物医学学术问答,MMLU-Medical则评估基本医学知识。
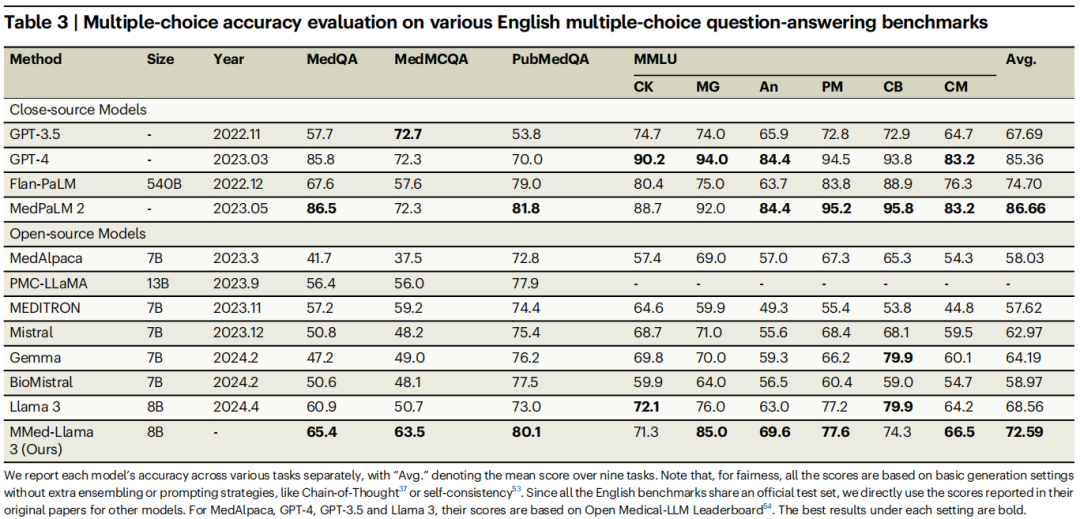
如表所示,MMed-Llama 3在这些基准上表现出色,在MedQA、MedMCQA和PubMedQA上分别提升了4.5%、4.3%和2.2%。在MMLU上,该模型的表现也优于大部分开源LLMs,显著超越GPT-3.5,得分72.59对比67.69。
数据组成的消融研究
作者对MMedLM、MMedLM 2和MMed-Llama 3在全量微调下的数据组成进行了分析,使用InternLM等模型作为基础。总体结果一致,以下讨论重点在MMed-Llama 3。
作者区分了高质量数据(HQ-Data)和未指定来源数据(US-Data)。HQ-Data来自经过人工验证的书籍和网站内容,US-Data则是从通用语料库中筛选的医学内容。结果表明,添加全面的推理数据使模型多选题的准确率平均提高了4.06个百分点,从58.72上升到62.79。然而,仅在英语数据上进行自回归训练没有显著提升,可能是因为英语过拟合,导致其他语言表现下降。扩展到整个多语言医学语料库后,模型表现显著改善,准确率提升到64.40,推理能力在BLEU-1和ROUGE-1上分别提高0.48和0.54。此外,加入自动收集的US-Data后,准确率进一步提升到67.75,推理能力也有所提升。
讨 论
作者的研究表明,基于MMedC的自回归训练能显著提升模型性能,尤其在多语言医学背景下。高质量、多样化的数据源能提高模型表现,而在MMedBench上结合推理数据微调也提高了问答准确率。此外,强大的LLM基础模型可提升最终结果,说明未来应更注重构建医学开源数据集。该研究推动了多语言医学LLM的发展,有助于实现更广泛的医学人工智能应用、提升跨语言检索生成能力,并在临床上缓解语言障碍、文化差异等问题。然而,数据偏见、解释性不足及语言覆盖有限仍是面临的挑战,未来需要进一步改进。
参考链接:
Qiu P, Wu C, Zhang X, et al. Towards building multilingual language model for medicine[J]. Nature Communications, 2024, 15(1): 8384.
相关文章:
上交大与上海人工智能研究所联合推出医学多语言模型,模型数据代码开源
今天为大家介绍的是来自上海交通大学的王延峰与谢伟迪团队的一篇论文。开源的多语言医学语言模型的发展可以惠及来自不同地区、语言多样化的广泛受众。 来源丨 DrugAI、 机器人的脑电波 论文:https://www.nature.com/articles/s41467-024-52417-z MMedC࿱…...

网络安全:我们的安全防线
在数字化时代,网络安全已成为国家安全、经济发展和社会稳定的重要组成部分。网络安全不仅仅是技术问题,更是一个涉及政治、经济、文化、社会等多个层面的综合性问题。从宏观到微观,网络安全的重要性不言而喻。 宏观层面:国家安全与…...

理解 Python 中的 __getitem__ 方法:在自定义类中启用索引和切片操作
理解 Python 中的 __getitem__ 方法:在自定义类中启用索引和切片操作 在Python中,__getitem__是一个特殊方法,属于数据模型方法之一,它使得Python对象能够支持下标访问和切片操作。这个方法提供了一种机制,允许类的实…...

【数据结构】【线性表】【练习】反转链表
申明 该题源自力扣题库19,文章内容(代码,图表等)均原创,侵删! 题目 给你单链表的头指针head以及两个整数left和right,其中left<right,请你反转从位置left到right的链表节点&…...

vue2+3 —— Day5/6
自定义指令 自定义指令 需求:当页面加载时,让元素获取焦点(一进页面,输入框就获取焦点) 常规操作:操作dom “dom元素.focus()” 获取dom元素还要用ref 和 $refs <input ref"inp" type&quo…...

汽车资讯新视角:Spring Boot技术革新
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

关于win11电脑连接wifi的同时,开启热点供其它设备连接
背景: 我想要捕获手机流量,需要让手机连接上电脑的热点。那么问题来了,我是笔记本电脑,只能连接wifi上网,此时我的笔记本电脑还能开启热点供手机连接吗?可以。 上述内容,涉及到3台设备&#x…...

【Apache Paimon】-- 2 -- 核心特性 (0.9.0)
目录 1、实时更新 1.1、实时大批量更新 1.2、支持定义合并引擎 1.3、支持定义更新日志生成器 2、海量数据追加处理 2.1、append table 2.2、快速查询 3、数据湖功能(类比:hudi、iceberg、delta) 3.1、支持 ACID 事务 3.2、支持 Time…...

golang对日期格式化
1.对日期格式化为 YYYY-mm-dd, 并且没有数据时,返回空 import ("encoding/json""time" )type DateTime time.Timetype SysRole struct {RoleId int64 gorm:"type:bigint(20);primary_key;auto_increment;角色ID;" json:&quo…...
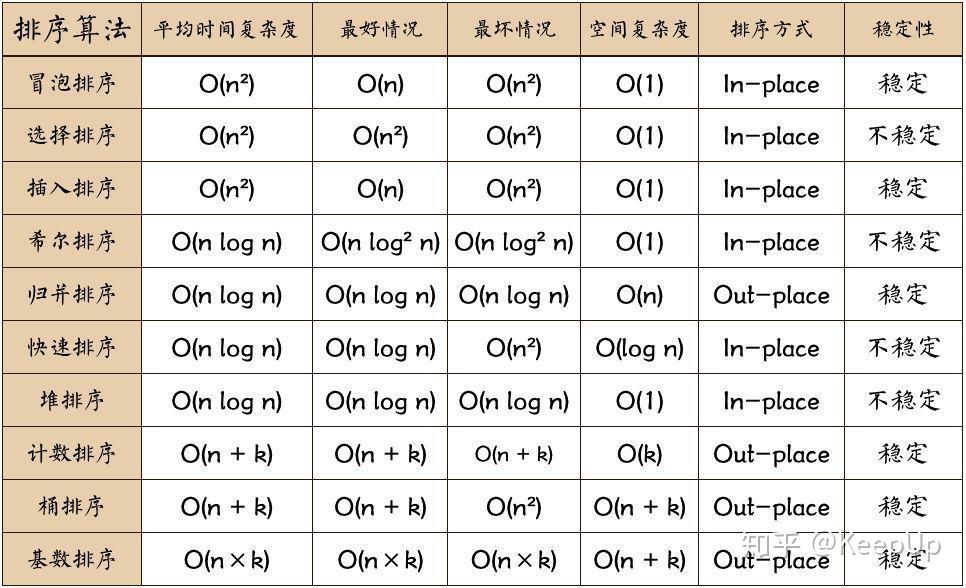
【数据结构与算法】排序
文章目录 排序1.基本概念2.分类2.存储结构 一.插入排序1.1直接插入排序1.2折半插入排序1.3希尔排序 二.选择排序2.1简单选择排序2.2堆排序 三.交换排序3.1冒泡排序3.2快速排序 四.归并排序五.基数排序**总结** 排序 1.基本概念 排序(sorting)又称分类&…...

前端常见的几个包管理工具详解
文章目录 前端常见的几个包管理工具详解一、引言二、包管理工具详解1、npm1.1、npm的安装与使用 2、yarn2.1、yarn的安装与使用 3、pnpm3.1、pnpm的安装与使用 三、步骤二4、包管理工具的选择 四、总结优缺点对比 前端常见的几个包管理工具详解 一、引言 在前端开发的世界里&…...
PyAEDT:Ansys Electronics Desktop API 简介
在本文中,我将向您介绍 PyAEDT,这是一个 Python 库,旨在增强您对 Ansys Electronics Desktop 或 AEDT 的体验。PyAEDT 通过直接与 AEDT API 交互来简化脚本编写,从而允许在 Ansys 的电磁、热和机械求解器套件之间无缝集成。通过利…...
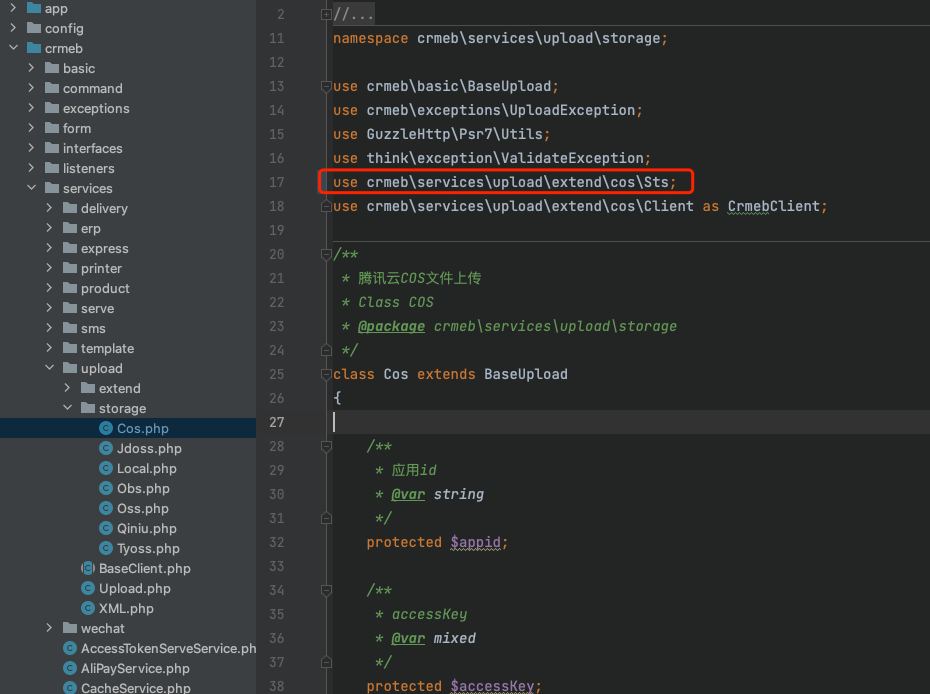
腾讯云存储COS上传视频报错
bug表现为:通过COS上传视频时报错"Class \"QCloud\\COSSTS\\Sts\" not found" 修复办法为:找到文件crmeb/services/upload/storage/Cos.php 将Sts引入由QCloud\COSSTS\Sts;改为crmeb\services\upload\extend\cos\Sts; 修改后重启服…...
 如何在Tomcat中配置访问日志?)
Tomcat(17) 如何在Tomcat中配置访问日志?
在Apache Tomcat中配置访问日志是一个重要的步骤,它可以帮助你跟踪和分析服务器的HTTP请求。访问日志通常记录了每个请求的详细信息,如客户端IP地址、请求时间、请求的URL、HTTP状态码等。以下是如何在Tomcat中配置访问日志的详细步骤和代码示例。 步骤…...

根据频繁标记frequent_token,累加size
根据频繁标记frequent_token,累加size for k, v in contents.items(): 0 (LDAP Built with OpenLDAP LDAP / SDK, /:=@) 1 (LDAP SSL support unavailable, :) 2 (suEXEC mechanism enabled lili wrapper /usr/sbin/suexec, ()/:) 3 (Digest generating secret for digest au…...

2、计算机网络七层封包和解包的过程
计算机网络osi七层模型 1、网络模型总体预览2、数据链路层4、传输层5.应用层 1、网络模型总体预览 图片均来源B站:网络安全收藏家,没有本人作图 2、数据链路层 案例描述:主机A发出一条信息,到路由器A,这里封装目标MAC…...

无人机飞手入门指南
无人机飞手入门指南旨在为初学者提供一份全面的学习路径和实践建议,帮助新手快速掌握无人机飞行技能并了解相关法规知识。以下是一份详细的入门指南: 一、了解无人机基础知识 1. 无人机构造:了解无人机的组成部分,如机身、螺旋桨…...

Redis与IO多路复用
1. Redis与IO多路复用概述 1.1 Redis的单线程特性 Redis是一个高性能的键值存储系统,其核心优势之一便是单线程架构。在Redis 6.0之前,其所有网络IO和键值对的读写操作都是由一个主线程顺序串行处理的。这种设计简化了多线程编程中的锁和同步问题&…...

基于Java和Vue实现的上门做饭系统上门做饭软件厨师上门app
市场前景 生活节奏加快:在当今快节奏的社会中,越来越多的人因工作忙碌、时间紧张而无法亲自下厨,上门做饭服务恰好满足了这部分人群的需求,为他们提供了便捷、高效的餐饮解决方案。个性化需求增加:随着人们生活水平的…...

spi 回环
///tx 极性0 (sclk信号线空闲时为低电平) /// 相位0 (在sclk信号线第一个跳变沿进行采样) timescale 1ns / 1ps//两个从机 8d01 8d02 module top(input clk ,input rst_n,input [7:0] addr ,input …...
)
Midjourney输出≠成品!树莓派自动裁切+水印+背胶封装印相工作流(附GitHub开源项目+硬件BOM清单)
更多请点击: https://intelliparadigm.com 第一章:Midjourney输出≠成品!树莓派自动裁切水印背胶封装印相工作流(附GitHub开源项目硬件BOM清单) Midjourney生成的高分辨率图像只是创作起点,真正交付实体印…...

ensp关闭完美世界运行时显示权限不够
Windows PowerShell 版权所有(C) Microsoft Corporation。保留所有权利。安装最新的 PowerShell,了解新功能和改进!https://aka.ms/PSWindowsPS C:\Users\Administrator> net stop MessageTransfer 发生系统错误 5。拒绝访问。…...

C8051F系列MCU Flash存储操作与优化实践
1. C8051F系列MCU Flash存储操作核心解析在嵌入式系统开发中,Flash存储器的可靠操作是每个工程师必须掌握的技能。不同于RAM的随意读写,Flash存储有其独特的物理特性和操作约束。以Silicon Labs的C8051F系列微控制器为例,其内部Flash存储器采…...

Axolotl与LLaMA-Factory对比:架构与扩展性分析-方案选型对比
1. 问题背景与选型目标 在大型语言模型(LLM)落地的浪潮中,“微调”已从少数研究团队的实验行为,变为大量中小企业甚至个人开发者的刚需。业务团队不再仅仅使用 API 调用闭源模型,而是希望基于开源基座模型(…...

Ctool:一站式解决开发者的日常编码烦恼
Ctool:一站式解决开发者的日常编码烦恼 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在日常开发工作中,我们常常需要处理各种编码转换…...

MCP Loom:快速构建AI工具与数据连接器的开发框架
1. 项目概述:MCP Loom,一个连接AI与真实世界的“织布机”如果你最近在折腾AI应用开发,特别是想让你的AI助手(比如Claude、Cursor等)能直接操作你电脑上的文件、数据库,甚至调用外部API,那么你很…...
复现论文:Landsat8波段组合如何影响土地覆盖分类精度?)
用Google Earth Engine (GEE)复现论文:Landsat8波段组合如何影响土地覆盖分类精度?
基于Google Earth Engine的Landsat8波段组合优化实验:从理论到实践 在遥感影像分析领域,波段选择一直是影响分类精度的关键因素。传统方法往往直接使用所有可用波段作为输入特征,却忽视了波段间可能存在的冗余信息。本文将通过Google Earth E…...

告别龟速下载!用阿里云Maven仓库和离线驱动包,5分钟搞定DBeaver所有JDBC驱动配置
极速配置DBeaver JDBC驱动的双轨方案:阿里云Maven加速与离线整合包实战 每次打开DBeaver准备连接数据库时,看着进度条缓慢爬升的驱动下载界面,你是否也感到焦虑?特别是在紧急排查生产环境问题的关键时刻,这种等待简直让…...

Java开发者收藏 | 你的经验不是负担,而是转型AI应用开发的加速器!
本文为Java开发者提供了清晰的AI应用开发转型路径。强调Java后端经验在AI领域是宝贵财富而非负担,并介绍了拥抱AI的优势。文章提出了分阶段学习路线,涵盖基础概念、框架选型(Spring AI、LangChain4j、Spring AI Alibaba)、可视化工…...
:核心抽象层 —— 块 、分区 、inode 从原理到实操)
【Linux 指南】文件系统系列(二):核心抽象层 —— 块 、分区 、inode 从原理到实操
上一篇我们吃透了磁盘的底层原理,搞懂了磁盘通过 CHS/LBA 寻址定位扇区,也知道扇区是磁盘硬件的最小读写单位(512 字节)。但随之而来的两个核心问题摆在眼前:一是逐个扇区读写磁盘效率极低,磁头的寻道和旋转…...