【论文阅读】InstructPix2Pix: Learning to Follow Image Editing Instructions

摘要:
提出了一种方法,用于教导生成模型根据人类编写的指令进行图像编辑:给定一张输入图像和一条书面指令,模型按照指令对图像进行编辑。
由于为此任务获取大规模训练数据非常困难,我们提出了一种生成配对数据集的方法,结合了两个大型预训练模型:
- 语言模型(GPT-3);
- 文本到图像模型(Stable Diffusion)。
这两个模型捕捉了关于语言和图像的互补知识,可以组合起来生成配对训练数据,用于同时涉及这两种模态的任务。
我们利用生成的配对数据训练了一个条件扩散模型,该模型给定输入图像和文本指令后,生成编辑后的图像。
模型在前向传播过程中直接执行图像编辑,且不需要额外的图像示例、输入/输出图像的完整描述或每个实例的微调。
1. 研究背景
-
图像编辑的挑战:
- 传统的图像编辑模型依赖于大量有监督的数据来指导模型生成,这通常需要提供 “原始图像-编辑后图像”对,导致数据标注成本极高。
- 这些模型通常缺乏灵活性,专门针对特定的编辑任务(如上色、修复等),不能广泛适应不同的编辑需求。
-
生成模型的局限性:
- 虽然一些文本到图像的生成模型(如 DALLE-2)本身具有图像编辑功能(如图像变化、区域填充),但它们在进行目标编辑时较为困难,因为相似的文本提示并不能保证产生相似的图像。
- Prompt-to-Prompt 方法解决了这一问题,通过将生成的图像与相似的文本提示联系起来,使得图像可以进行独立编辑。
-
多模型组合:
- 近年来的研究发现,多个大型预训练模型的结合能够有效解决一些单一模型无法完成的多模态任务(如图像描述和视觉问答)。这些方法包括:联合微调、通过提示信息进行通信、模型间的反馈引导等。
- 我们的方法与这些研究相似,结合了 GPT-3 和 Stable Diffusion 这两个互补能力强大的模型,但与以往的研究不同,我们通过这两种模型生成配对的多模态训练数据。
-
扩散模型:
- 在 扩散模型(如 Stable Diffusion)方面的进展推动了图像合成、视频、音频、文本等多模态生成模型的突破。文本到图像的扩散模型(如 Stable Diffusion)能够根据任意文本描述生成逼真的图像。
-
与现有方法的对比:
- 现有的一些编辑方法(如 SDEdit)主要是用于编辑真实图像,通常通过加噪和去噪来调整输入图像并生成新的图像。
- 然而, InstructPix2Pix 方法不同,它只依赖 单张图像 和 一条编辑指令,通过前向传播直接进行图像编辑,无需额外的用户手绘掩码或其他图像,这使得编辑过程更加简便和高效。
-
研究目标:
- 本研究的目标是开发 InstructPix2Pix 模型,能够在不依赖大量人工标注数据的情况下,通过自然语言指令进行灵活多样的图像编辑。这一目标对于非结构化的编辑任务尤为重要,因为用户可以通过自然语言直接描述编辑需求,避免了复杂的手动调整,极大地提升了图像编辑的便利性和灵活性。
![我们的方法包括两个部分:生成图像编辑数据集和在该数据集上训练扩散模型。(a)我们首先使用微调后的GPT-3生成指令和编辑后的标题。(b)然后,我们结合StableDiffusion [52] 和Prompt-to-Prompt [17] 从标题对生成图像对。我们使用这个过程创建了一个包含超过45万个训练样本的数据集。(c)最后,我们的InstructPix2Pix扩散模型在生成的数据上进行训练,以便根据指令编辑图像。在推理时,我们的模型能够推广到根据人类编写的指令编辑真实图像。](https://i-blog.csdnimg.cn/direct/e5890eff8389431b96416861a7de8e52.png)
2. 数据生成:生成配对的训练数据集
我们结合了两种大型预训练模型的能力——一个用于语言处理的大型语言模型(GPT-3)和一个文本到图像的模型(StableDiffusion)——来生成包含文本编辑指令及其对应的编辑前后图像的多模态训练数据集。以下是这个过程的两个关键步骤:
2.1 生成指令和配对标题
首先,我们在文本领域操作,利用大型语言模型根据图像描述生成编辑指令和编辑后的文本描述。例如,给定输入标题“女孩骑马的照片”,语言模型可以生成编辑指令“让她骑龙”以及修改后的输出标题“女孩骑龙的照片”。这种方式允许我们生成大量多样化的编辑,同时保持图像变化与文本指令之间的对应关系。

为此,我们对GPT-3进行了微调,训练数据来自于人类编写的编辑三元组:1) 输入标题,2) 编辑指令,3) 输出标题。训练数据由700个来自LAION-Aesthetics V2 6.5+数据集的输入标题及手动编写的指令和输出标题组成。通过微调GPT-3 Davinci模型一轮,我们的模型能够生成既富有创意又合理的指令和标题。最终生成的数据集包含454,445个样本。
2.2 从配对标题生成配对图像
接下来,我们使用预训练的文本到图像模型(如StableDiffusion)将一对标题(编辑前后的描述)转换为一对对应的图像。然而,文本到图像模型在生成图像时,可能会因为提示的微小变化而生成差异很大的图像。例如,“一只猫的照片”和“一只黑猫的照片”可能生成完全不同的图像,这对于我们训练编辑图像的模型并不适用。
为了解决这一问题,我们采用了Prompt-to-Prompt方法,这种方法通过在去噪过程中的交叉注意力权重共享来保证生成的图像在风格和内容上具有高度一致性。这可以确保生成的图像在相似性上保持一致,满足训练需求。

此外,不同的编辑可能会对图像产生不同程度的变化。因此,我们通过调节去噪步骤中共享注意力权重的比例(即p值),来控制图像对之间的相似度。为寻找合适的p值,我们为每对标题生成100个图像对,并通过CLIP空间中的方向相似度度量(衡量图像变化一致性)对这些图像对进行过滤,从而保证图像对的多样性和质量,提升数据生成的可靠性。
3. 模型结构:InstructPix2Pix的设计
InstructPix2Pix模型的核心就是通过一个强大的扩散模型,结合图像和文本指令来编辑图像。在生成过程中,模型不仅学会如何去噪,也学会如何根据不同的条件(图像、文本)调整图像,使得最终的生成图像既符合输入图像,也符合给定的文本指令。通过“无分类器引导”,我们可以在多样性和质量之间找到一个平衡。
3.1 扩散模型的基本原理
扩散模型的目标是通过逐步去噪生成数据。简单来说,扩散模型从一个随机噪声开始,然后逐步去除噪声来生成图像。这个过程通过一个自编码器实现:
- 编码器(Encoder,E):将图像压缩成潜在表示(latent representation)。
- 解码器(Decoder,D):将潜在表示转换回图像。
这个模型的核心目标是通过学习如何从噪声中恢复真实的图像数据,来生成新图像。
3.2 潜在扩散模型(Latent Diffusion)
潜在扩散模型的一个重要改进是它在潜在空间中工作,而不是直接在图像空间中。这让它更加高效,因为它减少了图像的复杂度并提高了生成质量。潜在空间是通过一个预训练的变分自编码器(VAE)获得的。
- 潜在空间:图像通过编码器转换成一个较低维度的潜在表示(latent representation),然后在这个表示上进行去噪,最后通过解码器重新生成图像。
3.3 InstructPix2Pix模型
InstructPix2Pix是基于上述潜在扩散模型的,并增加了“编辑图像”的功能。它的目标是根据文本指令修改图像。
例如,给定一个图像描述(比如“女孩骑马”),模型可以通过添加指令(例如“让她骑龙”)来改变原始图像,生成一个新的图像(“女孩骑龙”)。
3.3.1 模型如何工作:
- 图像和文本条件:InstructPix2Pix模型不仅输入图像(如“女孩骑马”),还输入文本指令(如“让她骑龙”)。
- 噪声预测:模型的任务是根据图像和指令,预测噪声并去除它,从而改变图像。它通过在潜在空间中处理图像的噪声来生成与指令相符的新图像。
3.3.2 无分类器引导(Classifier-free Guidance)
无分类器引导是一种方法,用于控制模型生成图像时,如何平衡图像的质量和多样性。基本思路是:
- 条件去噪:模型根据给定的条件(图像和文本指令)去生成图像。
- 无条件去噪:偶尔,模型也需要生成“无条件”的图像,也就是说,在没有任何条件限制下生成图像。这样可以让生成的图像更具多样性。
通过调整“引导尺度”(guidance scale),我们可以控制生成的图像在多大程度上与输入条件(图像和文本指令)相匹配。
例如:
- sI:控制图像与输入图像(cI)相符的程度。
- sT:控制图像与文本指令(cT)相符的程度。

3.3.3 如何调整引导尺度(sI 和 sT):
- 训练过程:在训练时,模型会有时只根据图像(或指令)去生成图像,有时根据两者一起生成图像。通过这种方式,模型学会如何平衡两者。
- 推理过程:在推理时,调整sI和sT的值来控制生成图像的质量。例如,当我们增加sI时,生成的图像会更贴近原始图像;增加sT时,生成的图像会更贴近文本指令。
4. 结果
4.1 定性对比:
![与其他编辑方法的比较。输入通过编辑字符串(最后两列)或真实输出图像的标题(中间两列)进行转换。我们将我们的方法与两项近期的工作进行比较:SDEdit [39] 和 Text2Live [6]。我们展示了 SDEdit 的两种配置:基于输出标题(OP)和基于编辑字符串(E)。](https://i-blog.csdnimg.cn/direct/91c455c1467a42b48bc71cc3e532eb2d.png)
-
本研究与两项相关工作的对比:
- SDEdit:基于预训练的扩散模型进行图像编辑。输入部分噪声的图像,去噪后生成编辑图像。缺点:需要提供完整的图像描述,而非简单的编辑指令。
- Text2Live:通过文本提示生成颜色+透明度增广层来编辑图像,适用于增量编辑。缺点:无法处理复杂的编辑类型。
-
结果:
- SDEdit 在处理风格变化较小的编辑时表现较好,但在处理较大或更复杂的变化时,难以保持图像的一致性(例如物体分离、身份保持等)。
- Text2Live 在处理加法图层(如修改背景)时效果不错,但对于其他类型的编辑任务则受到限制。
4.2 定量对比:
![我们绘制了输入图像一致性(Y轴)与编辑一致性(X轴)之间的权衡。对于这两个指标,值越高越好。对于这两种方法,我们将文本指导设置为7.5,并在范围 [1.0, 2.2] 内调整我们的 sI,以及在 [0.3, 0.9] 之间调整 SDEdit 的强度(去噪量)。](https://i-blog.csdnimg.cn/direct/d7b4ecb6ba3f4154bd119d09610ded38.png)
- 指标:
- CLIP图像嵌入余弦相似度:衡量编辑后的图像与原始图像的相似度。
- 方向性CLIP相似度:衡量文本描述的变化与图像变化的一致性。
- 这两个指标是对立的,增强编辑效果会导致与原图的相似度降低,反之亦然。
- 结果表明,与 SDEdit 对比时,本文方法在相同的方向性相似度下,图像一致性 更高,表现更优。
4.3 消融实验
![我们通过固定 sT 并调整 sI 的值在 [1.0, 2.2] 范围内,比较了我们模型的消融变体(较小的训练数据集,没有 CLIP 过滤)。我们提出的配置表现最佳。](https://i-blog.csdnimg.cn/direct/b71db3e0e69741d4a1163621ec6228e1.png)
- 数据集大小和过滤方法:
- 数据集大小:减少数据集的大小会导致模型在执行编辑时只能进行较小、细微的调整,无法进行大范围的图像修改(表现为高图像相似度,但低方向性相似度)。
- CLIP过滤:去除CLIP过滤会导致编辑图像与输入图像的整体一致性降低。
- 分类器无关引导的影响:
- sT(文本指令的引导尺度):增大 sT 强化文本指令的影响,使得输出图像更符合指令要求,编辑效果更强。
- sI(输入图像的引导尺度):增大 sI 有助于保持输入图像的结构,使输出图像更接近输入图像,从而保持图像一致性。
- 结果:
- 在实际操作中,通常通过调整 sT 和 sI 的值来平衡一致性与编辑强度。
- 最佳的引导尺度范围是:
- sT:5 到 10
- sI:1 到 1.5
5. 主要局限性:
-
生成数据集的视觉质量:我们的模型依赖于生成数据集的视觉质量,因此受到用于生成图像的扩散模型(如Stable Diffusion)的限制。
-
泛化能力的限制:该方法在处理新的编辑指令时存在一定的局限性,尤其是在图像变化与文本指令的关联上,受到:
- GPT-3用于微调的人工编写指令的局限;
- GPT-3生成指令和修改图像描述的能力的限制;
- Prompt-to-Prompt方法修改生成图像的能力的限制。
-
空间推理和物体计数的困难:模型在处理与物体计数和空间推理相关的指令时表现不佳,例如“将它移到图像的左侧”,“交换它们的位置”,“将两个杯子放在桌子上,一个放在椅子上” 等。
-
数据和模型的偏见:由于模型和数据的偏见,生成的图像可能会继承或引入这些偏见(如图14所示)。

未来的研究方向:
- 空间推理的指令处理:如何改进模型对空间推理指令的理解和执行。
- 与用户交互结合的指令:如何将指令与其他调节方式(如用户交互)结合,以增强模型的灵活性。
- 基于指令的图像编辑评估:如何有效地评估基于指令的图像编辑结果。
- 人类反馈的整合:如何利用人类反馈改进模型,未来可通过“人类在回路中的强化学习”策略来提高模型与人类意图的一致性。
相关文章:
【论文阅读】InstructPix2Pix: Learning to Follow Image Editing Instructions
摘要: 提出了一种方法,用于教导生成模型根据人类编写的指令进行图像编辑:给定一张输入图像和一条书面指令,模型按照指令对图像进行编辑。 由于为此任务获取大规模训练数据非常困难,我们提出了一种生成配对数据集的方…...

常用在汽车PKE无钥匙进入系统的高度集成SOC芯片:CSM2433
CSM2433是一款集成2.4GHz频段发射器、125KHz接收器和8位RISC(精简指令集)MCU的SOC芯片,用在汽车PKE无钥匙进入系统里。 什么是汽车PKE无钥匙进入系统? 无钥匙进入系统具有无钥匙进入并且启动的功能,英文名称是PKE&…...

【第四课】rust声明式宏理解与实战
目录 前言 理解宏 实战宏 前言 上一课在介绍vector时,我们再一次提到了rust中的宏,在初始化vector时使用了vec!宏,当时补了一句有机会会好好说明一下rust中的宏,并且写一个hashmap宏来初始化hashmap。想了想一直介绍基本语法还…...

渗透测试--Linux下的文件传输方法
渗透测试过程中,我们经常会需要文件传输,本文主要探讨Linux主机上我们对文件传输的方法。 编码方式 Linux 检查MD5 md5sum id_rsa Linux Base64 编码/解码 编码 cat id_rsa |base64 -w 0;echo 解码 echo -n LS0tLS1CRUdJTiBPUEVOU1NIIFBSSVZBVE…...
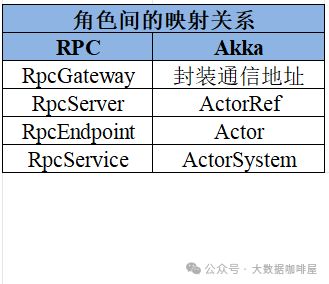
浅议Flink中的通讯工具: Akka
在Flink中,各个组件之间需要频繁交换数据和控制信息。Flink选择了基于Actor模型的Akka框架作为通信基础。 Akka是什么 Actor模型 Actor模型是用于单个进程中并发的场景。 在Actor模型中: ActorSystem负责管理actor生命周期 将每个实体视为独立的 Ac…...
基于YOLOv8深度学习的独居老人情感状态监护系统(PyQt5界面+数据集+训练代码)
本研究提出了一种创新的独居老人情感状态监护系统,基于YOLOV8深度学习模型,旨在通过对老年人面部表情的实时监测与分析,来精准识别其情感变化,从而提高独居老人的生活质量,确保其心理健康。本系统通过整合先进的YOLOV8…...

Qt添加外部库:静态库和动态库,批量添加头文件
Qt添加外部库需要知道库文件的位置才能正确链接,如果是静态库,要确保LIBS变量中包含正确的库文件路径和库文件名;如果是动态库,除了库路径外,还需要考虑动态库的加载路径。在 Windows 下,可以将动态库所在路径添加到系…...

Unity类银河战士恶魔城学习总结(P132 Merge skill tree with skill Manager 把技能树和冲刺技能相组合)
【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili 教程源地址:https://www.udemy.com/course/2d-rpg-alexdev/ 本章节实现了解锁技能后才可以使用技能,先完成了冲刺技能的锁定解锁 Dash_Skill.cs using System.Collections; using System…...

Docker入门之Windows安装Docker初体验
在之前我们认识了docker的容器,了解了docker的相关概念:镜像,容器,仓库:面试官让你介绍一下docker,别再说不知道了 之后又带大家动手体验了一下docker从零开始玩转 Docker:一站式入门指南&#…...

DNS实验作业
实验要求 1.搭建dns服务器能够对自定义的正向或者反向域完成数据解析查询。 2.配置从DNS服务器,对主dns服务器进行数据备份。 实验步骤: 1.关闭防护墙 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2.正向解析 [rootlo…...

CSS回顾-CSS选择器详解
一、引言 我来填坑啦!之前在CSS基础知识详解中介绍过,CSS 是一门基于规则的语言。是由选择器与样式信息组成:选择器 {样式信息}。CSS 选择器是 CSS 规则的关键,能精准定位 HTML 元素,CSS3 新增选择器更是增强了设计能…...

FFMPEG录像推流时遇到的问题
FFMPEG录像推流时遇到的问题,记录一下供大参考 1. ret avformat_write_header( ofmt_ctx, NULL ); 执行写入头后,所有的流的时间基都会被内部重新设置,所以并不你想象的把原来的时间直接入到avPACKET中就可以发送了。必须要把你每个流的P…...
)
【STM32+K210项目】基于K210智能人脸识别+车牌识别系统(完整工程资料源码)
运行效果: 基于K210的智能人脸与车牌识别系统工程 目录: 运行效果: 目录: 前言: 一、国内外研究现状与发展趋势 二、相关技术基础 2.1 人脸识别技术 2.2 车牌识别技术 三、智能小区门禁系统设计 3.1 系统设计方案 3.2 系统设计目标 3.3 智能小区门禁系统硬件设计 3.3.1 控…...
Unity脚本基础规则
Unity脚本基础规则 如何在Unity中创建一个脚本文件? 在Project窗口中的Assets目录下,选择合适的文件夹,右键,选择第一个Create,在新出现的一栏中选择C# Script,此时文件夹内会出现C#脚本图标,…...

基于AIRTEST和Jmeter、Postman的自动化测试框架
基于目前项目和团队技术升级,采用了UI自动化和接口自动化联动数据,进行相关测试活动,获得更好的测试质量和测试结果。...

使用 Azure OpenAI 服务对数据进行联合 SharePoint 搜索
作者:来自 Elastic Gustavo Llermaly 使用 Azure OpenAI 服务处理你的数据,并使用 Elastic 作为向量数据库。 在本文中,我们将探索 Azure OpenAI 服务 “On Your Data”,使用 Elasticsearch 作为数据源。我们将使用 Elastic Shar…...

JavaScript学习笔记 1】初识JS
目录 一、JS是什么? 二、JS的作用? 三、JS的组成 四、JS的书写位置 1. 内部JS 2. 外部JS(外部导入) 3. 内联JS 4. 练习 五、JS的注释与结束符 1. 注释 2. 结束符 3. JS该不该加分号? 六、JS的输入和输出语法 1. 输出语法 a. 输出在页面中 b. …...

Linux-Samba
文章目录 Samba配置服务配置 🏡作者主页:点击! 🤖Linux专栏:点击! ⏰️创作时间:2024年11月18日13点20分 Samba配置 Samba是一个能让 Linux 系统应用与 Microsoft 网络通讯协议的软件&#x…...

【Java Web】JSON 以及 JSON 转换
JSON(JavaScript Object Notation)一种灵活、高效、轻量级的数据交换格式,广泛应用于各种数据交换和存储场景。 基本特点 1、简单易用:JSON格式非常简单,易于理解和使用。 2、轻量级:相比XML等其他数据格…...

Qt 元对象系统
Qt 元对象系统 Qt 元对象系统1. 元对象的概念2. 元对象系统的核心组件2.1 QObject2.2 Q_OBJECT 宏2.3 Meta-Object Compiler (MOC) 3. 信号与槽3.1 基本概念信号与槽的本质信号和槽的关键特征 3.2 绑定信号与槽参数解析断开连接 3.3 标准信号与槽查找标准信号与槽使用示例规则与…...
:当TTS调用量突破500万/月,这3个架构断层将触发收入增长断崖)
ElevenLabs商业规模化陷阱(内部白皮书节选):当TTS调用量突破500万/月,这3个架构断层将触发收入增长断崖
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Growing Business ElevenLabs 已从语音合成初创公司快速演进为全球 AI 语音基础设施的关键提供者,其业务增长体现在 API 调用量年增超 320%、企业客户数突破 12,000 家ÿ…...

ScrollNice:用虚拟滚动区域替代鼠标滚轮的Windows效率工具
1. 项目概述:当鼠标滚轮失灵时,我们如何优雅地“滚动”?作为一名长期与代码和文档打交道的开发者,我深知一个顺手的鼠标滚轮有多重要。但现实往往很骨感——无论是用了多年的老鼠标滚轮开始“打滑”,还是在某些需要单手…...

多智能体安全协调中的约束推断与CBF应用
1. 多智能体安全协调中的约束推断方法概述在分布式多智能体系统中,安全协调一直是个极具挑战性的问题。想象一下,当一群机器人在仓库中协同搬运货物时,每个机器人可能只知道部分环境信息(比如某些障碍物的位置)&#x…...

从仿真到PCB:基于74LS系列芯片的十字路口交通灯系统实战设计
1. 项目背景与设计目标 十字路口交通灯控制系统是数字电路课程的经典实践项目。记得我第一次接触这个课题时,既兴奋又忐忑——兴奋的是终于能把课本上的与非门、触发器应用到真实场景,忐忑的是从仿真到实物可能存在的各种"坑"。这个基于74LS系…...

AI营销技能库:模块化设计提升Claude Code与智能体工作流效率
1. 项目概述:一个为AI营销工作流设计的技能库如果你正在用Claude Code、Cursor这类AI编程工具做营销、内容创作或增长相关的工作,并且感觉每次都要花大量时间写重复的提示词,或者希望团队能有一套标准化的AI工作流程,那么这个名为…...

GPTs 商店深度观察:超级 Agent 的孵化器?
GPTs 商店深度观察:会是下一代超级 AI Agent 的全民孵化器吗? 摘要/引言 2024年6月,OpenAI官方公布了一组数据:GPTs商店上线仅7个月,平台上的自定义GPT数量已经突破1200万,月活使用用户超过8000万,累计为开发者创造的分成收入超过3.2亿美元。这个上线之初被很多业内人士…...

ARM嵌入式开发:硬件抽象层与调试监控技术解析
1. ARM嵌入式开发中的硬件抽象层与调试监控在ARM嵌入式系统开发中,硬件抽象层(HAL)和调试监控器是两大核心基础设施。它们如同汽车的底盘和仪表盘——HAL负责统一管理发动机、变速箱等硬件组件,而调试监控器则提供实时运行数据与交…...

Steam成就管理终极指南:三步掌握高效成就解锁技巧
Steam成就管理终极指南:三步掌握高效成就解锁技巧 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&…...

ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南
ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式无法在其他播放器播放而烦恼吗?你是否经历过精心收藏的音乐只能…...

【Unity 2D实战】巧用Cinemachine Confiner:告别穿帮镜头,实现精准地图边界限制
1. 为什么需要地图边界限制? 在2D游戏开发中,摄像机跟随角色移动是最基础的功能之一。但很多新手开发者都会遇到一个尴尬的问题:当角色走到地图边缘时,摄像机依然会继续移动,导致玩家看到地图之外的空白区域或者未设计…...