Spark RDD sortBy算子什么情况会触发shuffle
在 Spark 的 RDD 中,sortBy 是一个排序算子,虽然它在某些场景下可能看起来是分区内排序,但实际上在需要全局排序时会触发 Shuffle。这里我们分析其底层逻辑,结合源码和原理来解释为什么会有 Shuffle 的发生。
1. 为什么 sortBy 会触发 Shuffle?
关键点 1:全局有序性要求
sortBy 并非单纯的分区内排序。它的目标是按照用户指定的键对整个 RDD 的数据进行排序,这种操作需要保证全局顺序。为实现这一点,必须:
- 对数据进行 重新分区(Repartition),确保每个分区中的数据按照全局范围内的排序键正确分布;
- 每个分区内部再完成排序。
这些步骤不可避免地引入了 Shuffle,因为数据需要从一个分区转移到另一个分区以保证全局有序性。
关键点 2:底层调用 repartitionAndSortWithinPartitions
sortBy 的底层实现会调用 repartitionAndSortWithinPartitions 方法:
this.keyBy(f).repartitionAndSortWithinPartitions(new RangePartitioner(numPartitions, this, ascending))(ordInverse).values
-
keyBy(f):- 将数据转化为
(key, value)格式,key是排序的关键字,value是原始数据。
- 将数据转化为
-
RangePartitioner:- 使用
RangePartitioner将数据根据排序键重新分区(这一步需要 Shuffle)。
- 使用
-
repartitionAndSortWithinPartitions:- 先 Shuffle 数据以保证每个分区内的 key 是按范围划分的;
- 然后对每个分区内的数据进行排序。
Shuffle 的触发
- 当目标分区数量与当前分区数量不一致时(用户指定分区数或默认分区数),会触发 Shuffle;
- 即使目标分区数一致,只要需要保证全局有序,也需要重新分布数据来确保各分区内数据按键范围划分。
2. Shuffle 的作用
- 全局排序:分区间重新分布数据,确保所有分区的排序键范围是连续的。
- 负载均衡:通过
RangePartitioner分布数据,避免某些分区过大或过小的问题。 - 分区内排序:确保每个分区内部数据按键排序。
3. 源码分析
repartitionAndSortWithinPartitions 的核心逻辑如下:
def repartitionAndSortWithinPartitions(partitioner: Partitioner)(implicit ord: Ordering[K]): RDD[(K, V)] = withScope {val shuffled = new ShuffledRDD[K, V, V](this, partitioner)shuffled.setKeyOrdering(ord)new MapPartitionsRDD(shuffled, (context, pid, iter) => {val sorter = new ExternalSorter[K, V, V](context, Some(partitioner), Some(ord))sorter.insertAll(iter)context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)sorter.iterator})
}
-
ShuffledRDD:- 触发 Shuffle,将数据根据分区器重新分布。
-
ExternalSorter:- 对每个分区内的数据进行排序(如果数据超出内存,会使用磁盘作为临时存储)。
4. 举例说明 Shuffle 的发生
sortBy 的行为取决于传递的参数。为了实现分区内排序,你需要明确控制 sortBy 的参数设置。如果不显式指定目标分区数(numPartitions 参数),sortBy 默认不会触发 Shuffle,因此只会在分区内排序。
例子 1:带 Shuffle 的全局排序
val rdd = sc.parallelize(Seq(5, 2, 4, 3, 1), numSlices = 2)
val sortedRdd = rdd.sortBy(x => x, ascending = true, numPartitions = 3)// 指定目标分区数
println(sortedRdd.collect().mkString(", "))
- 初始数据分区:
分区 1:[5, 2],分区 2:[4, 3, 1] - 重新分区和排序后:
分区 1:[1, 2],分区 2:[3, 4],分区 3:[5] - Shuffle 触发原因:
数据必须重新分布,确保分区键范围([1-2], [3-4], [5])。 - 特点:
触发 Shuffle 操作,数据按照RangePartitioner进行分区。
每个分区内局部排序后,实现全局排序。
例子 2:分区内排序(无 Shuffle)
val rdd = sc.parallelize(Seq(5, 2, 4, 3, 1), numSlices = 2) // 两个分区
// 如果只需要分区内排序,mapPartitions 提供了无 Shuffle 的选择。
val sorted = rdd.mapPartitions(partition => partition.toList.sorted.iterator)
sorted.collect().foreach(println)
- 初始数据分区:
分区 1:[5, 2],分区 2:[4, 3, 1] - 排序后:
分区 1:[2, 5],分区 2:[1, 3, 4] - 无 Shuffle 原因:
数据仅在分区内排序,分区间顺序无全局保证。
5. 总结
sortBy在需要全局排序时触发 Shuffle,这是为了重新分区以确保分区范围和分区内排序。- 如果只需要分区内排序,
mapPartitions提供了无 Shuffle 的选择。
注意事项:
- 全局排序带来的 Shuffle 会显著增加网络传输和计算成本。
- 如无必要,尽量避免全局排序,优先考虑局部排序或 Top-N 算法以优化性能。
相关文章:

Spark RDD sortBy算子什么情况会触发shuffle
在 Spark 的 RDD 中,sortBy 是一个排序算子,虽然它在某些场景下可能看起来是分区内排序,但实际上在需要全局排序时会触发 Shuffle。这里我们分析其底层逻辑,结合源码和原理来解释为什么会有 Shuffle 的发生。 1. 为什么 sortBy 会…...

机器视觉相机重要名词
机器视觉相机的重要名词包括: • 工业数字相机:又称工业相机,是机器视觉系统中的关键组件。 • 电荷偶合元件(CCD):一种图像传感器,能将光学影像转换为数字信号。 • 互补金属氧化物半导体&…...

Django:从入门到精通
一、Django背景 Django是一个由Python编写的高级Web应用框架,以其简洁性、安全性和高效性而闻名。Django最初由Adrian Holovaty和Simon Willison于2003年开发,旨在简化Web应用的开发过程。作为一个开放源代码项目,Django迅速吸引了大量的开发…...

android viewpager2 嵌套 recyclerview 手势冲突
老规矩直接上代码, 不分析: import android.content.Context import android.util.AttributeSet import android.view.MotionEvent import android.view.View import android.view.ViewConfiguration import android.view.ViewGroup import android.widg…...
)
依赖管理(go mod)
目录 各版本依赖管理的时间分布 一、GOPATH 1. GOROOT是什么 定义: 作用: 默认值: 是否需要手动设置: 查看当前的 GOROOT: 2. GOPATH:工作区目录 定义: 作用:…...

Apple Vision Pro开发001-开发配置
一、Vision Pro开发硬件和软件要求 硬件要求软件要求 1、Apple Silicon Mac(M系列芯片的Mac电脑) 2、Apple vision pro-真机调试 XCode15.2及以上,调试开发和打包发布Unity开发者账号&&苹果开发者账号 二 、开启无线调试 1、Apple Vision Pro和Mac连接同…...

android 动画原理分析
一 android 动画分为app内的view动画和系统动画 基本原理都是监听Choreographer的doframe回调 二 app端的实现是主要通过AnimationUtils来实现具体属性的变化通过invilate来驱动 wms来进行更新。这个流程是在app进程完成 这里不是我分析的重点 直接来看下系统动画里面的本地动…...

Elasticsearch 6.8 分析器
在 Elasticsearch 中,分析器(Analyzer)是文本分析过程中的一个关键组件,它负责将原始文本转换为一组词汇单元(tokens)。 分析器由三个主要部分组成:分词器(Tokenizer)、…...

实验室资源调度系统:基于Spring Boot的创新
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

实验三:构建园区网(静态路由)
目录 一、实验简介 二、实验目的 三、实验需求 四、实验拓扑 五、实验任务及要求 1、任务 1:完成网络部署 2、任务 2:设计全网 IP 地址 3、任务 3:实现全网各主机之间的互访 六、实验步骤 1、在 eNSP 中部署网络 2、配置各主机 IP …...

3. SQL优化
SQL性能优化 在日常开发中,MySQL性能优化是一项必不可少的技能。本文以具体案例为主线,结合实际问题,探讨如何优化插入、排序、分组、分页、计数和更新等操作,帮助你实现数据库性能的飞跃。 一、索引设计原则 索引是MySQL优化的…...

web——upload-labs——第十一关——黑名单验证,双写绕过
还是查看源码, $file_name str_ireplace($deny_ext,"", $file_name); 该语句的作用是:从 $file_name 中去除所有出现在 $deny_ext 数组中的元素,替换为空字符串(即删除这些元素)。str_ireplace() 在处理时…...

AWS CLI
一、AWS CLI介绍 1、简介 AWS CLI(Amazon Web Services Command Line Interface)是一个命令行工具,它允许用户通过命令行与 Amazon Web Services(AWS)的各种云服务进行交互和管理。使用 AWS CLI,用户可以直接在终端或命令行界面中执行命令来配置、管理和自动化AWS资源,…...

springboot:责任链模式实现多级校验
责任链模式是将链中的每一个节点看作是一个对象,每个节点处理的请求不同,且内部自动维护一个下一节点对象。 当一个请求从链式的首段发出时,会沿着链的路径依此传递给每一个节点对象,直至有对象处理这个请求为止。 属于行为型模式…...
CentO7安装单节点Redis服务
本文目录 一、Redis安装与配置1.1 安装redis依赖1.2 上传压缩包并解压1.3 编译安装1.4 修改配置并启动1、复制配置文件2、修改配置文件3、启动Redis服务4、停止redis服务 1.5 redis连接使用1、 命令行客户端2、 图形界面客户端 一、Redis安装与配置 1.1 安装redis依赖 Redis是…...

FreeRTOS学习14——时间管理
时间管理 时间管理FreeRTOS 系统时钟节拍FreeRTOS 系统时钟节拍简介FreeRTOS 系统时钟节拍处理FreeRTOS 系统时钟节拍来源 FreeRTOS 任务延时函数vTaskDelay()vTaskDelayUntil() 时间管理 在前面的章节实验例程中,频繁地使用了 FreeRTOS 提供的延时函数,…...

统⼀数据返回格式快速⼊⻔
为什么会有统⼀数据返回? 其实统一数据返回是运用了AOP(对某一类事情的集中处理)的思维。 优点: 1.⽅便前端程序员更好的接收和解析后端数据接⼝返回的数据。 2.降低前端程序员和后端程序员的沟通成本,因为所有接⼝都…...

Python学习------第十天
数据容器-----元组 定义格式,特点,相关操作 元组一旦定义,就无法修改 元组内只有一个数据,后面必须加逗号 """ #元组 (1,"hello",True) #定义元组 t1 (1,"hello") t2 () t3 tuple() prin…...
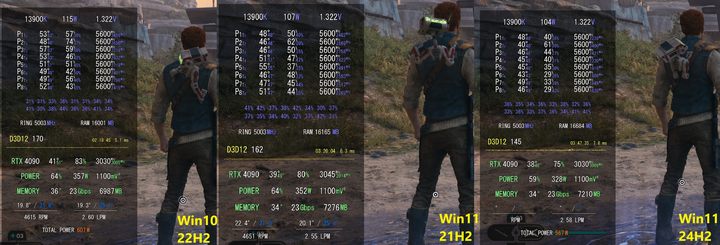
Win11 24H2新BUG或影响30%CPU性能,修复方法在这里
原文转载修改自(更多互联网新闻/搞机小知识): 一招提升Win11 24H2 CPU 30%性能,小BUG大影响 就在刚刚,小江在网上冲浪的时候突然发现了这么一则帖子,标题如下:基准测试(特别是 Time…...

element ui 走马灯一页展示多个数据实现
element ui 走马灯一页展示多个数据实现 element ui 走马灯一页展示多个数据实现 element ui 走马灯一页展示多个数据实现 主要是对走马灯的数据的操作,先看js处理 let list [{ i: 1, name: 1 },{ i: 2, name: 2 },{ i: 3, name: 3 },{ i: 4, name: 4 },]let newL…...

从RISC-V到SSITH:构建下一代硬件安全架构的开放之路
1. 项目概述:从“亡羊补牢”到“未雨绸缪”的硬件安全范式转移在智能设备无处不在的今天,我们正面临一个尴尬的现实:许多产品的安全设计,更像是在一栋已经建好的毛坯房里,见缝插针地安装防盗门和监控摄像头。这种“事后…...

RE3SIM系统:3D真实感仿真数据生成技术解析
1. RE3SIM系统概述:3D真实感仿真数据生成新范式在机器人操作领域,获取高质量训练数据一直是制约算法发展的瓶颈。传统基于真实环境的示教数据采集不仅需要昂贵硬件支持,还依赖专业操作人员,单次任务采集成本可达数千元。RE3SIM系统…...

02数据模型与单词仓库-鸿蒙PC端Electron开发
欢迎加入开源鸿蒙PC社区 https://harmonypc.csdn.net/ 源码仓库 https://atomgit.com/qq_33247427/englishProject.git 效果截图 第2篇:数据模型与单词仓库 系列教程导航 篇号 标题 状态 01 环境搭建与项目创建 ✅ 已完成 02 数据模型与单词仓库 本篇 …...

企业微信代开发应用:CallBackUrl验证失败排查与CorpID加密升级实战
1. 企业微信代开发应用验证失败的典型场景 最近不少服务商朋友反馈,代开发应用在验证CallBackUrl时频繁失败。这个问题其实源于企业微信在2022年6月底进行的一次安全升级。当时官方发布公告称,为了提升账户安全性,所有新建的代开发应用都需要…...

汉字可视化探索平台:基于Flask+Vue的汉字浏览系统架构与实现
1. 项目概述:一个汉字学习者的“浏览器”如果你和我一样,对汉字的结构、演变和背后的文化故事着迷,那你一定经历过这样的时刻:在阅读古籍、碑帖,或者仅仅是看到一个生僻字时,心里会冒出无数个问号——这个字…...

Linux端口转发到外网完全教程:iptables DNAT+SNAT实现内网服务暴露
一、什么是外网端口转发Linux端口转发到外网,是指将Linux服务器上某个端口的流量,转发到外网(公网)的另一台服务器。这样做的典型场景是:你有一台内网服务器没有公网IP,但另一台海外服务器有公网IP…...

麻省理工博士生弃博投身数字人类研究:10年、100亿美元、5万台H100或可实现
【导语:麻省理工学院博士生Isaak Freeman放弃攻读博士学位,投身数字人类研究。他认为人类若保持碳基形态将在智力竞争中被AI淘汰,而将意识迁移到数字基质上是出路,并给出实现数字人类的粗略计算和路线图。】数字人类:从…...

Flutter For Openharmony第三方库: animated_text_kit 的鸿蒙化适配指南
Flutter 三方库 animated_text_kit 的鸿蒙化适配指南 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 前言:文字是可动的 嘿~亲爱的开发者小伙伴们,大家好呀!👋 今天我们要一起探索一个超级有…...

深夜“哔哔”声源排查指南:从原理到实战解决电子设备异响
1. 深夜“哔哔”声的普遍困扰与根源剖析你有没有在凌晨三点被一阵微弱但执着的“哔哔”声从睡梦中拽出来过?那种感觉,就像有个看不见的小精灵在你家天花板的某个角落,每隔一分钟就用气声对你进行一次精准的精神攻击。你猛地坐起,睡…...

本地化AI代码助手部署指南:从模型选型到性能调优
1. 项目概述:一个面向开发者的本地化AI代码助手最近在GitHub上看到一个挺有意思的项目,叫“JPeetz/Hermes-Studio”。乍一看名字,可能会联想到希腊神话里的信使赫尔墨斯,或者某个设计软件。但点进去你会发现,这其实是一…...