【大模型】LLaMA: Open and Efficient Foundation Language Models
链接:https://arxiv.org/pdf/2302.13971
论文:LLaMA: Open and Efficient Foundation Language Models
Introduction
- 规模和效果
7B to 65B,LLaMA-13B 超过 GPT-3 (175B) - Motivation
如何最好地缩放特定训练计算预算的数据集和模型大小,并不是模型参数越大越好,给定一个目标级别的性能,首选模型不是训练最快的而是推理最快的
Approach
- 预训练数据
表中数据的混合:

- CommonCrawl数据:对数据进行重复数据删除,使用 fastText 线性分类器执行语言识别以删除非英语页面并使用 ngram 语言模型过滤低质量的内容。
- C4:发现使用不同的预处理 CommonCrawl 数据集可以提高性能。对于质量使用启发式方法,比如标点符号和单词句子数量
- Github:根据字母数字字符的线长或比例过滤低质量的文件,并删除带有正则表达式的样板,例如标题;在文件级别对结果数据集进行重复数据删除
- Wikipedia:20种语言,删除超链接、评论和其他格式样板。
- Gutenberg and Books3:两个书籍数据,书籍级别执行重复数据删除,删除内容重叠超过 90% 的书籍。
- ArXiv:科学数据,在第一部分和书目之前删除了所有内容,删除了评论、tex 文件、以及用户编写的内联扩展定义和宏,以增加论文之间的一致性。
- Stack Exchange:涵盖各种领域的高质量问题和答案网站,范围从计算机科学到化学,从 28 个最大的网站保留数据,从文本中删除 HTML 标签并按分数对答案进行排序
- Tokenizer:BPE,将所有数字拆分为单个数字,并回退到字节以分解未知的 UTF-8 字符。共计1.4T tokens。
- 训练集使用:除了 Wikipedia 和 Books 域之外,每个token在训练期间仅使用一次,执行大约两个 epoch。
- 结构
-
Pre-normalization(GPT-3):提高训练稳定性(后归一化是针对输出,前归一化是在每个sub-layer的输入),RMSNorm「对于 Post-LN 方式,Layer Norm 放置在 Self-Attn sub layer 和 FFN sub layer 的 output 上,实证发现会导致 output 上的梯度过大,训练时不稳定,loss 不能稳定下降;Pre-LN 方式下,梯度值则比较稳定」

-
SwiGLU activation function(PaLM)
原始的 Transformer 中 FFN layer 使用 ReLU 激活函数,如下:

对 FFN 的实现方式进行改进,可以提升 Transformer 在语言模型上的表现,主要思路是借鉴 Gated Linear Units (GLU) 的做法,并将 GLU 中的 sigmoid 激活函数更换为 Swish 激活函数。原始 GLU 的形式:

将其中的 sigmoid 激活函数σ更改为Swishβ 激活函数 (f(x)=x⋅sigmoid(β⋅x)),则有:

FFN 可使用 SwiGLU 替换为 (此处省略了 Bias 项):

-
Rotary Embeddings [GPTNeo]:rotary positional embeddings (RoPE)
Rope和相对位置编码相比油更好的外推性(外推性是指大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题)
对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量,然后对每个 token 位置都计算对应的旋转位置编码,接着对每个 token 位置的 query 和 key 向量的元素按照 两两一组 应用旋转变换,最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。

- 优化器
AdamW,β1 = 0.9, β2 = 0.95,cosine learning rate schedule,weight decay of 0.1 and gradient clipping of 1.0 - 高效实现
- 使用因果多头注意力的有效实现来减少内存使用和运行时间,xformers library;不存储注意力权重,也不加算被mask的key/query的分数【Causal Multi-Head Attention:由于是解码器,为了保持 Left-to-Right 自回归特点而 Mask 掉的那些位置,不计算 Attention weights.】
- 减少了在后向传递期间重新计算的激活量
- 使用模型和序列并行性来减少模型的内存使用
- 重叠网络上的激活和 GPU 之间的通信(由于 all_reduce 操作)
- 训练 65B 模型,2048个80GB A100 ,380 个token/s/GPU。 1.4T token的数据集训练 21 天
Results
包括zero-shot 和 few-shot 任务,20个benchmark
- Common Sense Reasoning

- 闭卷问答


模型推理可以在单个v100运行 - 阅读理解

- 数学推理
Minerva 是一系列 PaLM 模型,在从 ArXiv 和 Math Web Page 中提取的 38.5B 标记上进行微调,而 PaLM 或 LLAMA 都没有在数学数据上进行微调

maj1@k 表示我们为每个问题生成 k 个样本并执行多数投票的评估 - 代码生成

- 大规模多任务语言理解

预训练数据中使用了有限数量的书籍和学术论文
- 训练期间性能的演变


指令微调
非常少量的微调提高了 MLU 的性能,进一步提高了模型遵循指令的能力

偏见、有毒性和错误信息
大型语言模型已被证明可以重现和放大训练数据中存在的偏差
-
RealToxicityPrompts基准
RealToxicityPrompts 由模型必须完成的大约 100k 个提示组成;然后通过向 PerspectiveAPI 3 请求自动评估毒性分数(分数越高,有毒越多)

-
CrowS-Pairs
该数据集允许测量 9 个类别中的偏见:性别、宗教、种族/颜色、性取向、年龄、国籍、残疾、身体外观和社会经济地位

分数越高Bias越大 -
WinoGender(性别偏见)

4. TruthfulQA
该基准可以评估模型生成错误信息或虚假声明的风险

与 GPT-3 相比,LLaMA在这两个类别中得分都更高,但正确答案的比率仍然很低
总结
贡献点一:“以少胜多”
- LLaMA-13B outperforms GPT-3-175B on most benchmarks, despite being 10× smaller;
- LLaMA-65B is competitive with PaLM-540B;
贡献点二:open-sourcing - 训练数据全都 publicly available;
- 参数公开;
Toread:Chinchilla and PaLM
相关文章:
【大模型】LLaMA: Open and Efficient Foundation Language Models
链接:https://arxiv.org/pdf/2302.13971 论文:LLaMA: Open and Efficient Foundation Language Models Introduction 规模和效果 7B to 65B,LLaMA-13B 超过 GPT-3 (175B)Motivation 如何最好地缩放特定训练计算预算的数据集和模型大小&…...

模拟器多开限制ip,如何设置单窗口单ip,每个窗口ip不同
很多手游多开玩家都是利用安卓模拟器实现手游多开,但是很多手游会限制ip,导致多开之后封号等问题,模拟器本身没有更换IP的功能,就需要通过第三方软件来实现 安卓模拟器概述 雷电模拟器、夜神模拟器、mum模拟器等都是目前市场上比较…...

hive的存储格式
1) 四种存储格式 hive的存储格式分为两大类:一类纯文本文件,一类是二进制文件存储。 Hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET 第一类:纯文本文件存储 textfile: 纯文本文件存储格式…...
)
鸿蒙学习高效开发与测试-应用程序框架(3)
文章目录 1、应用程序框架1、规范化后台进程管理2、原生支持分布式3、支持多设备的统一窗口管理4、 组件共享及面向对象5、逻辑与界面解耦6、灵活扩展机制2、HarmonyOS SDK1、 开放能力 Kit2、开放能力的检索和使用3、 方舟工具链4、前端编译器架构1、应用程序框架 应 用 程 序…...

什么命令可以查看数据库中表的结构
1. MySQL 查看表结构 sql 复制代码 DESCRIBE 表名; 或者: sql 复制代码 SHOW COLUMNS FROM 表名; 更详细的表信息 sql 复制代码 SHOW CREATE TABLE 表名; 2. PostgreSQL 查看表结构 sql 复制代码 \d 表名 列出表的字段及类型 sql 复制代码 SELECT column_name, da…...

django基于python 语言的酒店推荐系统
摘 要 酒店推荐系统旨在提供一个全面酒店推荐在线平台,该系统允许用户浏览不同的客房类型,并根据个人偏好和需求推荐合适的酒店客房。用户可以便捷地进行客房预订,并在抵达后简化入住登记流程。为了确保连续的住宿体验,系统还提供…...

【深度学习|onnx】往onnx中写入训练的超参或者类别等信息,并在推理时读取
1、往onnx中写入 在训练完毕之后,我们先使用torch.onnx.export() 导出onnx模型,然后我们再使用以下代码来往metadata中写入信息: # Metadatad {# stride: int(max(model.stride)),names: model.names,mean : [0,0,0],std : [1,1,1],normali…...

WebSocket详解、WebSocket入门案例
目录 1.1 WebSocket介绍 http协议: webSocket协议: 1.2WebSocket协议: 1.3客户端(浏览器)实现 1.3.2 WebSocket对象的相关事宜: 1.3.3 WebSOcket方法 1.4 服务端实现 服务端如何接收客户端发送的请…...

05_Spring JdbcTemplate
在继续了解Spring的核心知识前,我们先看看Spring的一个模板类JdbcTemplate,它是一个JDBC的模板类,用来简化JDBC的操作。 接下来以实际来进行说明 一、实例环境准备 数据库及表准备 我们在本地mysql中新增一个数据库test,并新增一张数据表:user create database if not…...

Bug:引入Feign后触发了2次、4次ContextRefreshedEvent
Bug:引入Feign后发现监控onApplication中ContextRefreshedEvent事件触发了2次或者4次。 【原理】在Spring的文档注释中提示到: Event raised when an {code ApplicationContext} gets initialized or refreshed.即当 ApplicationContext 进行初始化或者刷…...
最新VSCode保姆级安装教程(附安装包)
文章目录 一、VSCode介绍 二、VSCode下载 下载链接:https://pan.quark.cn/s/19a303ff81fc 三、VSCode安装 1.解压安装文件:双击打开并安装VSCode 2.勾选我同意协议:然后点击下一步 3.选择目标位置:点击浏览 4.选择D盘安装&…...

layui 表格点击编辑感觉很好用,实现方法如下
1. 在 HTML 页面中引入 layui 的相关资源文件:html <link rel"stylesheet" href"https://cdn.staticfile.org/layui/2.5.6/css/layui.css"> <script src"https://cdn.staticfile.org/layui/2.5.6/layui.js"></script&…...
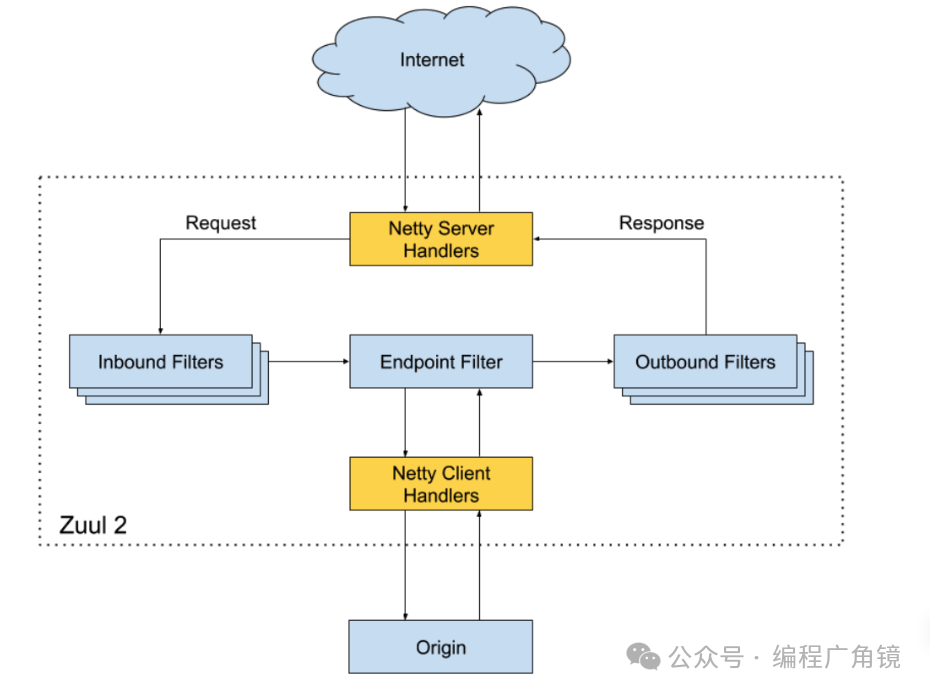
三十一、构建完善微服务——API 网关
一、API 网关基础 系统拆分为微服务后,内部的微服务之间是互联互通的,相互之间的访问都是点对点的。如果外部系统想调用系统的某个功能,也采取点对点的方式,则外部系统会非常“头大”。因为在外部系统看来,它不需要也没…...

非对称之美(贪心)
非对称之美(贪心) import java.util.*; public class Main{public static void main(String[] arg) {Scanner in new Scanner(System.in);char[] ch in.next().toCharArray(); int n ch.length; int flag 1;for(int i 1; i < n; i) {if(ch[i] ! ch[0]) {flag …...

详细教程-Linux上安装单机版的Hadoop
1、上传Hadoop安装包至linux并解压 tar -zxvf hadoop-2.6.0-cdh5.15.2.tar.gz 安装包: 链接:https://pan.baidu.com/s/1u59OLTJctKmm9YVWr_F-Cg 提取码:0pfj 2、配置免密码登录 生成秘钥: ssh-keygen -t rsa -P 将秘钥写入认…...

C#桌面应用制作计算器进阶版01
基于C#桌面应用制作计算器做出了少量改动,其主要改动为新增加了一个label控件,使其每一步运算结果由label2展示出来,而当点击“”时,最终运算结果将由label1展示出来,此时label清空。 修改后运行效果 修改后全篇代码 …...
[开源] 告别黑苹果!用docker安装MacOS体验苹果系统
没用过苹果电脑的朋友可能会对苹果系统好奇,有人甚至会为了尝鲜MacOS去折腾黑苹果。如果你只是想体验一下MacOS,这里有个更简单更优雅的解决方案,用docker安装MacOS来体验苹果系统。 一、项目简介 项目描述 Docker 容器内的 OSX(…...

多模态大模型(4)--InstructBLIP
BLIP-2通过冻结的指令调优LLM以理解视觉输入,展示了在图像到文本生成中遵循指令的初步能力。然而,由于额外的视觉输入由于输入分布和任务多样性,构建通用视觉语言模型面临很大的挑战。因而,在视觉领域,指令调优技术仍未…...
)
【Linux】基于 Busybox 构建嵌入式 Linux(未完成)
嵌入式 Linux 1.需要 Toolchain 2.需要 Bootloader 3.需要嵌入式 Linux 基本组件: Linux kernelDTBRoot filesystem InitShellDaemonShared librariesConfiguration fileDevice nodeproc and sysKernel Module 基于 Busybox 构建 1.编译 Linux kernel 2.编译 …...

Unet++改进38:添加GLSA(2024最新改进方法)具有聚合和表示全局和局部空间特征的能力,这有利于分别定位大目标和小目标
本文内容:添加GLSA注意力机制 目录 论文简介 1.步骤一 2.步骤二 3.步骤三 4.步骤四 论文简介 基于变压器的模型已经被广泛证明是成功的计算机视觉任务,通过建模远程依赖关系和捕获全局表示。然而,它们往往被大模式的特征所主导,导致局部细节(例如边界和小物体)的丢失…...

农文旅融合实践:六亩半如何以草莓采摘+植物染色激活乌鲁木齐亲子游市场
一、行业背景随着文旅产业复苏和乡村振兴战略深入推进,乌鲁木齐及周边地区的农文旅融合项目迎来新的发展机遇。根据相关行业观察,融合农业采摘与非遗文化体验的"农文旅"模式正成为新趋势,为城市居民提供了差异化的周末游选择。五月…...

GPU加速网络爬虫:OpenCL异构计算在数据采集中的实践
1. 项目概述:一个面向硬件加速的开源抓取工具包最近在折腾一些数据采集和自动化任务时,我常常遇到一个瓶颈:当需要处理海量网页、进行高频次请求或者解析复杂的动态内容时,传统的基于CPU的抓取框架(比如Scrapy、Reques…...

芯片晶圆平面度如何测量?半导体制造中的光学形貌检测方案
晶圆作为集成电路的核心承载基片,表面形貌的精度直接关系到光刻聚焦质量、芯片电学性能及最终良率。从8英寸到12英寸的大尺寸晶圆制造中,平面度、翘曲度(Warp)、总厚度变化(TTV)及局部平面度(SF…...

从ARIMA差分到MIM网络:一个老派时间序列技巧如何革新了深度学习预测
从差分思想到记忆网络:传统时间序列技巧如何重塑深度学习架构 在气象预报的雷达回波图中,降水云团的形态每秒钟都在剧烈变化;城市交通流量监测数据里,早晚高峰的波动与平峰期形成鲜明对比;股票市场的价格曲线更是以难以…...

免费LLM API实战指南:从选型到架构的完整解决方案
1. 项目概述:一份免费LLM API的实用指南 如果你正在开发AI应用,或者只是想低成本地体验各种大语言模型,那么“API调用成本”绝对是一个绕不开的痛点。无论是OpenAI还是Anthropic,按Token计费的模式在频繁调用下,账单数…...

Lumi Diary:基于OpenClaw Skill的本地AI记忆伴侣设计与实践
1. 项目概述:一个住在你设备里的记忆精灵如果你和我一样,对把生活点滴交给云端总有点不放心,但又渴望有一个能懂你、能帮你把碎片记忆编织成故事的伙伴,那么 Lumi Diary 的出现,可能正是时候。这不是又一个需要你手动打…...

Python网络爬虫实战:构建自动化招聘信息聚合工具JobClaw
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 JobClaw。这名字起得挺形象,“Claw”是爪子的意思,合起来就是“工作抓取器”。简单来说,它是一个帮你从各大招聘网站上自动抓取、聚合和分析职位信息的工具。对于正在找…...

AI智能体通过MCP协议连接Figma:实现设计稿自动化操作与代码生成
1. 项目概述:当AI智能体学会“看”设计稿最近在折腾一个挺有意思的东西:让AI智能体(比如Cursor、Claude Code)能直接和Figma对话。听起来有点科幻?其实原理不复杂,就是通过一个叫Model Context Protocol&am…...

从雨篷结构事故处理谈幕墙钢结构的概念设计
从雨篷结构事故处理谈幕墙钢结构的概念设计 雨篷结构设计是幕墙钢结构设计最重要内容。但由于雨篷静定结构体系的先天不足,外加设计师理论认识水平与设计经验的限制、施工时的不当行为,经常造成工程事故。这些设计缺陷和工程事故的发生,多是由于对雨篷进行概念设计时认知不…...

电源设计和效率优化案例C01
本文重点讲清楚三个非常重要的问题: 手把手教会计算电源的效率计算,包括线性电源和开关电源等 1-电源的上下管的 Qg和Rdson为什么是一对矛盾量? 2-单相30A的电流输出电源要求,对上下管子应该如何取舍这两个参数,为什么? 电源设计是硬件设计的核心组成部分,尤其事目前…...