设计LRU缓存
LRU缓存
- LRU缓存的实现思路
- LRU缓存的操作
- C++11 STL实现LRU缓存
- 自行设计双向链表 + 哈希表
LRU(Least Recently Used,最近最少使用)缓存是一种常见的缓存淘汰算法,其基本思想是:当缓存空间已满时,移除最近最少使用的数据。LRU缓存通常通过链表(双向链表)和哈希表相结合来实现,利用哈希表快速查找,链表保持数据的使用顺序。
链接:leetcode 设计LRU缓存
LRU缓存的实现思路
实现思路:哈希表 + 双向链表
-
为什么使用哈希表?
哈希表:用来存储键值对,可以在常数时间内(O(1))进行查找、插入和删除操作。 -
为什么使用双向带头尾链表?
双向链表:用来维护数据的使用顺序。最近使用的元素放在链表的头部,最久未使用的元素放在链表的尾部。通过这种方式可以在O(1)的时间复杂度下实现删除最久未使用的元素。
LRU缓存的操作
- Get(key): 如果键存在于缓存中,返回对应的值并将该键值对移到链表头部,表示最近被访问过。如果不存在,返回-1。
- Put(key, value): 插入键值对。如果缓存已满,则删除最久未使用的元素,之后插入新的键值对,并将其移到链表头部。
C++11 STL实现LRU缓存
时间复杂度分析:
get(key):查找操作是O(1),然后通过 touch 函数将键移到链表头部,也是在O(1)时间内完成的。
put(key, value):插入或更新键值对的操作是O(1),如果缓存满了需要删除最久未使用的元素(evict),删除操作也是O(1)。因此,get 和 put 操作的时间复杂度都是 O(1)。
#include <iostream>
#include <unordered_map>
#include <list>class LRUCache {
public:LRUCache(int capacity) : capacity(capacity) {}// 获取缓存中的值int get(int key) {auto it = cache.find(key);if (it == cache.end()) {return -1; // 未找到键,返回 -1}touch(it); // 标记为最近使用return it->second.first; // 返回对应的值}// 插入新的键值对void put(int key, int value) {auto it = cache.find(key);if (it != cache.end()) {touch(it); // 标记为最近使用it->second.first = value; // 更新值} else {if (cache.size() == capacity) {evict(); // 删除最久未使用的元素}// 插入新的键值对到链表头部order.push_front(key);cache[key] = {value, order.begin()}; // 存入哈希表,值和链表位置}}private:// 更新元素为最近使用void touch(std::unordered_map<int, std::pair<int, std::list<int>::iterator>>::iterator it) {int key = it->first;order.erase(it->second.second); // 删除当前元素order.push_front(key); // 将元素插入链表头部it->second.second = order.begin(); // 更新迭代器位置}// 淘汰最久未使用的元素void evict() {int key_to_evict = order.back(); // 获取尾部元素(最久未使用)order.pop_back(); // 从链表中移除cache.erase(key_to_evict); // 从哈希表中删除}int capacity; // 缓存容量std::list<int> order; // 双向链表,维护键的访问顺序std::unordered_map<int, std::pair<int, std::list<int>::iterator>> cache; // 哈希表,存储键值对和链表位置
};int main() {LRUCache cache(2); // 设置缓存容量为2cache.put(1, 1); // 缓存: {1=1}cache.put(2, 2); // 缓存: {1=1, 2=2}std::cout << cache.get(1) << std::endl; // 返回 1,缓存: {2=2, 1=1}cache.put(3, 3); // 淘汰键 2,缓存: {1=1, 3=3}std::cout << cache.get(2) << std::endl; // 返回 -1 (未找到)cache.put(4, 4); // 淘汰键 1,缓存: {3=3, 4=4}std::cout << cache.get(1) << std::endl; // 返回 -1 (未找到)std::cout << cache.get(3) << std::endl; // 返回 3std::cout << cache.get(4) << std::endl; // 返回 4return 0;
}
效果:代码简洁,但效率不高。

自行设计双向链表 + 哈希表
#include <iostream>
#include <unordered_map>using namespace std;struct DLinkedNode {int key, value;DLinkedNode* prev;DLinkedNode* next;DLinkedNode() : key(0), value(0), prev(nullptr), next(nullptr) {}DLinkedNode(int _key, int _value) : key(_key), value(_value), prev(nullptr), next(nullptr) {}
};class LRUCache {
private:unordered_map<int, DLinkedNode*> cache;DLinkedNode* head;DLinkedNode* tail;int size;int capacity;public:LRUCache(int _capacity) : capacity(_capacity), size(0) {// 使用伪头部和伪尾部节点head = new DLinkedNode();tail = new DLinkedNode();head->next = tail;tail->prev = head;}int get(int key) {if (!cache.count(key)) {return -1; // 如果找不到该键,返回 -1}DLinkedNode* node = cache[key];moveToHead(node); // 移动到链表头部return node->value; // 返回值}void put(int key, int value) {if (!cache.count(key)) {// 如果 key 不存在,创建新节点DLinkedNode* node = new DLinkedNode(key, value);cache[key] = node;addToHead(node); // 添加到链表头部++size;if (size > capacity) {// 超过容量,删除尾部节点DLinkedNode* removed = removeTail();cache.erase(removed->key); // 从哈希表中删除该键delete removed; // 防止内存泄漏--size;}}else {// 如果 key 存在,更新值,并移到头部DLinkedNode* node = cache[key];node->value = value;moveToHead(node);}}void addToHead(DLinkedNode* node) {node->prev = head;node->next = head->next;head->next->prev = node;head->next = node;}void removeNode(DLinkedNode* node) {node->prev->next = node->next;node->next->prev = node->prev;}void moveToHead(DLinkedNode* node) {removeNode(node); // 移除节点addToHead(node); // 重新添加到头部}DLinkedNode* removeTail() {DLinkedNode* node = tail->prev;removeNode(node);return node;}
};int main() {LRUCache cache(2); // 缓存容量为2cache.put(1, 1); // 缓存: {1=1}cache.put(2, 2); // 缓存: {1=1, 2=2}cout << cache.get(1) << endl; // 返回 1,缓存: {2=2, 1=1}cache.put(3, 3); // 淘汰键 2,缓存: {1=1, 3=3}cout << cache.get(2) << endl; // 返回 -1,键 2 不存在cache.put(4, 4); // 淘汰键 1,缓存: {3=3, 4=4}cout << cache.get(1) << endl; // 返回 -1,键 1 不存在cout << cache.get(3) << endl; // 返回 3cout << cache.get(4) << endl; // 返回 4return 0;
}
代码转自力扣官方题解。
效果:时间复杂度明显降低, 效率提高。
总结
上述实现利用了哈希表和双向链表的组合,保证了LRU缓存操作的高效性。哈希表提供了O(1)的查找和更新时间,而双向链表提供了O(1)的插入和删除操作,确保了缓存的高效管理。这个实现适用于高性能缓存系统,如数据库缓存、Web缓存等。
相关文章:
设计LRU缓存
LRU缓存 LRU缓存的实现思路LRU缓存的操作C11 STL实现LRU缓存自行设计双向链表 哈希表 LRU(Least Recently Used,最近最少使用)缓存是一种常见的缓存淘汰算法,其基本思想是:当缓存空间已满时,移除最近最少使…...

python中的base64使用小笑话
在使用base64的时候将本地的图片转换为base64 代码如下,代码绝对正确 import base64 def image_to_data_uri(image_path):with open(image_path, rb) as image_file:image_data base64.b64encode(image_file.read()).decode(utf-8)file_extension image_path.sp…...

Python之time时间库
time时间库 概述获取当前时间time库datetime库区别 时间元组处理获取时间元组的各个部分时间戳和时间元组的转换 格式化时间格式化时间解析时间格式符号说明 暂停程序计时操作简单计时高精度计时计时器类的实现 UTC时间操作time库datetime库 概述 time是Python标准库中的一个模…...

Easyexcel(4-模板文件)
相关文章链接 Easyexcel(1-注解使用)Easyexcel(2-文件读取)Easyexcel(3-文件导出)Easyexcel(4-模板文件) 文件导出 获取 resources 目录下的文件,使用 withTemplate 获…...

国产linux系统(银河麒麟,统信uos)使用 PageOffice 动态生成word文件
PageOffice 国产版 :支持信创系统,支持银河麒麟V10和统信UOS,支持X86(intel、兆芯、海光等)、ARM(飞腾、鲲鹏、麒麟等)、龙芯(LoogArch)芯片架构。 数据区域填充文本 数…...

Window11+annie 视频下载器安装
一、ffmpeg环境的配置 下载annie之前需要先配置ffmpeg视频解码器。 网址下载地址 https://ffmpeg.org/download.html1、在网址中选择window版本 2、点击后选择该版本 3、下载完成后对压缩包进行解压,后进行环境的配置 (1)压缩包解压&#…...
配置篇(七))
SAP GR(Group Reporting)配置篇(七)
1.7、合并处理的配置 1.7.1 定义方法 菜单路径 组报表的SAP S4HANA >合并处理的配置>定义方法 事务代码 SPI4...

共建智能软件开发联合实验室,怿星科技助力东风柳汽加速智能化技术创新
11月14日,以“奋进70载,智创新纪元”为主题的2024东风柳汽第二届科技周在柳州盛大开幕,吸引了来自全国的汽车行业嘉宾、技术专家齐聚一堂,共襄盛举,一同探寻如何凭借 “新技术、新实力” 这一关键契机,为新…...
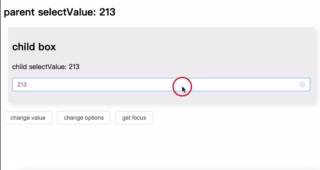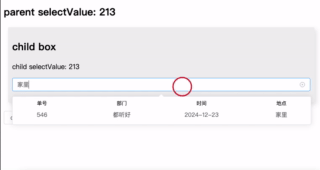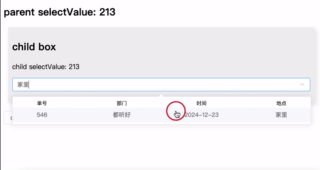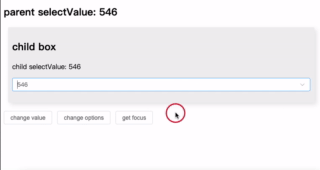
优化表单交互:在 el-select 组件中嵌入表格显示选项
介绍了一种通过 el-select 插槽实现表格样式数据展示的方案,可更直观地辅助用户选择。支持列配置、行数据绑定及自定义搜索,简洁高效,适用于复杂选择场景。完整代码见GitHub 仓库。 背景 在进行业务开发选择订单时,如果单纯的根…...

每日一题 LCR 079. 子集
LCR 079. 子集 主要应该考虑遍历的顺序 class Solution { public:vector<vector<int>> subsets(vector<int>& nums) {vector<vector<int>> ans;vector<int> temp;dfs(nums,0,temp,ans);return ans;}void dfs(vector<int> &…...

cocos creator 3.8 Node学习 3
//在Ts、js中 this指向当前的这个组件实例 //this下的一个数据成员node,指向组件实例化的这个节点 //同样也可以根据节点找到挂载的所有组件 //this.node 指向当前脚本挂载的节点//子节点与父节点的关系 // Node.parent是一个Node,Node.children是一个Node[] // th…...

微信小程序底部button,小米手机偶现布局错误的bug
预期结果:某button fixed 到页面底部,进入该页面时,正常显示button 实际结果:小米13pro,首次进入页面,button不显示。再次进入时,则正常展示 左侧为小米手机第一次进入。 遇到bug的解决思路&am…...

【计组】复习题
冯诺依曼型计算机的主要设计思想是什么?它包括哪些主要组成部分? 主要设计思想: ①采用二进制表示数据和指令,指令由操作码和地址码组成。 ②存储程序,程序控制:将程序和数据存放在存储器中,计算…...

Apache Maven 标准文件目录布局
Apache Maven 采用了一套标准的目录布局来组织项目文件。这种布局提供了一种结构化和一致的方式来管理项目资源,使得开发者更容易导航和维护项目。理解和使用标准目录布局对于有效的Maven项目管理至关重要。本文将探讨Maven标准目录布局的关键组成部分,并…...
Android 功耗分析(底层篇)
最近在网上发现关于功耗分析系列的文章很少,介绍详细的更少,于是便想记录总结一下功耗分析的相关知识,有不对的地方希望大家多指出,互相学习。本系列分为底层篇和上层篇。 大概从基础知识,测试手法,以及案例…...

【Xbim+C#】创建圆盘扫掠IfcSweptDiskSolid
基础回顾 https://blog.csdn.net/liqian_ken/article/details/143867404 https://blog.csdn.net/liqian_ken/article/details/114851319 效果图 代码示例 在前文基础上,增加一个工具方法: public static IfcProductDefinitionShape CreateDiskSolidSha…...
IntelliJ+SpringBoot项目实战(四)--快速上手数据库开发
对于新手学习SpringBoot开发,可能最急迫的事情就是尽快掌握数据库的开发。目前数据库开发主要流行使用Mybatis和Mybatis Plus,不过这2个框架对于新手而言需要一定的时间掌握,如果快速上手数据库开发,可以先按照本文介绍的方式使用JdbcTemplat…...

利用oss进行数据库和网站图片备份
1.背景 由于网站迁移到香港云 服务器,虽然便宜,但是宿主服务器时不时重启,为了预防不可控的因素导致网站资料丢失,所以想到用OSS 备份网站数据,bucket选择在香港地区创建,这样和你服务器传输会更快。 oss…...

Excel - VLOOKUP函数将指定列替换为字典值
背景:在根据各种复杂的口径导出报表数据时,因为关联的表较多、数据量较大,一行数据往往会存在三个以上的字典数据。 为了保证导出数据的效率,博主选择了导出字典code值后,在Excel中处理匹配字典值。在查询百度之后&am…...

实验室管理平台:Spring Boot技术构建
3系统分析 3.1可行性分析 通过对本实验室管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本实验室管理系统采用SSM框架,JAVA作为开发语言&a…...
)
告别卡顿!用WebRTC-Streamer在浏览器里丝滑播放海康/大华监控(附完整代码)
告别卡顿!用WebRTC-Streamer在浏览器里丝滑播放海康/大华监控(附完整代码) 监控视频的实时查看一直是许多开发者和运维人员头疼的问题。传统的解决方案如Flash早已被淘汰,而基于FLV.js的方案又常常面临延迟高、卡顿、标签页切换暂…...

i.MX6Q烧录翻车实录:从‘No Device Connected’到‘Push error’,我拔掉一个USB WiFi才搞定
i.MX6Q烧录实战:当USB设备冲突遇上OTG接口的排查指南 那天下午的阳光透过窗户斜射进实验室,我正对着i.MX6Q开发板进行例行固件更新。Mfgtools工具已经准备就绪,开发板电源接通,一切看起来都很完美——直到屏幕上跳出那个令人沮丧…...
的5个高效应用场景)
从模型验证到单元测试:PyTorch张量比较函数(allclose/isclose/eq/equal)的5个高效应用场景
从模型验证到单元测试:PyTorch张量比较函数的高效应用场景 在PyTorch项目中,张量比较是贯穿整个机器学习工作流的基础操作。无论是验证模型收敛性、调试自定义层,还是确保数据预处理一致性,选择恰当的比较函数能显著提升开发效率和…...

Captain AI助力Ozon大卖店群高效管理,实现规模化运营
随着Ozon商家运营规模的扩大,多店铺运营(店群)成为很多资深大卖的选择,通过多店铺布局,可扩大市场覆盖、分散运营风险、提升整体销量。但店群运营过程中,商家常常面临“管理繁琐、数据混乱、效率低下”的问…...

思源宋体TTF:免费专业中文字体终极使用指南
思源宋体TTF:免费专业中文字体终极使用指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版找不到合适的免费字体而烦恼吗?思源宋体TTF正是你需要…...

为你的Hermes Agent项目配置Taotoken作为自定义模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent项目配置Taotoken作为自定义模型提供商 应用场景类,假设你正在使用Hermes Agent框架并希望接入更多…...

2025届最火的十大降重复率平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网所具备的降AI技术,目的在于使论文里人工智能生成部分的内容重复率得以降低&…...

软件测试中的bug管理:高效定位、跟踪与修复全流程解析
在软件测试全生命周期中,bug管理是保障产品质量、提升开发效率的核心环节。从bug的精准定位到全流程跟踪,再到最终的有效修复,每一个步骤都需要专业的方法、工具与团队协作。对于软件测试从业者而言,掌握科学的bug管理体系&#x…...

我用豆包写的论文 AI 率为什么 95%?这款工具一次降到 4% 万方检测合格
我用豆包写的论文 AI 率为什么 95%?这款工具一次降到 4% 万方检测合格 去年我用豆包写了 1 万字的生物学本科论文——自己读着挺顺、像人写的。送学校万方 AIGC 检测——AI 率 95.7%,学校卡的是 30%。我整个人懵了。 这篇文章我把当时的实测过程写下来—…...

透明计费如何帮助精准预测与控制AI功能月度开支
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 透明计费如何帮助精准预测与控制AI功能月度开支 1. 项目背景:深度集成AI的网站 我们负责一个内容创作辅助网站&#x…...