数据科学与SQL:组距分组分析 | 区间分布问题
目录
0 问题描述
1 数据准备
2 问题分析
3 小结
0 问题描述
绝对值分布分析也可以理解为组距分组分析。对于某个指标而言,一个记录对应的指标值的绝对值,肯定落在所有指标值的绝对值的最小值和最大值构成的区间内,根据一定的算法,在把这个区间划分为等距离的几个小区间,统计落入这些区间的指标值的绝对值的情况,决策者就可以得到指标值的绝对值在各个区间的分布情况。
以销售表为例,销售表如下:
| country | sale_month | sales_number | sales_value |
| USA | 2008-01-01 | 1200 | 500000 |
| USA | 2008-02-01 | 1150 | 450000 |
| USA | 2008-03-01 | 1300 | 520000 |
| USA | 2008-04-01 | 1280 | 510000 |
| USA | 2008-05-01 | 1350 | 530000 |
| USA | 2008-06-01 | 1400 | 535000 |
| USA | 2008-07-01 | 1300 | 510000 |
| USA | 2008-08-01 | 1250 | 460000 |
| USA | 2008-09-01 | 1400 | 530000 |
| USA | 2008-10-01 | 1380 | 520000 |
| USA | 2008-11-01 | 1450 | 540000 |
| USA | 2008-12-01 | 1500 | 545000 |
| USA | 2009-01-01 | 1600 | 550000 |
| USA | 2009-02-01 | 1390 | 532000 |
| USA | 2009-03-01 | 1730 | 570000 |
| USA | 2009-04-01 | 1900 | 600000 |
| USA | 2009-05-01 | 1850 | 585000 |
| USA | 2009-06-01 | 3800 | 780000 |
| USA | 2009-07-01 | 1700 | 560000 |
| USA | 2009-08-01 | 1490 | 542000 |
| USA | 2009-09-01 | 1830 | 580000 |
| USA | 2009-10-01 | 2000 | 610000 |
| USA | 2009-11-01 | 1950 | 595000 |
| USA | 2009-12-01 | 1900 | 590000 |
1 数据准备
create table sales asselect 'USA' country, '2008-01-01' sale_month, '1200' sales_number, '500000' sales_value union allselect 'USA' country, '2008-02-01' sale_month, '1150' sales_number, '450000' sales_value union allselect 'USA' country, '2008-03-01' sale_month, '1300' sales_number, '520000' sales_value union allselect 'USA' country, '2008-04-01' sale_month, '1280' sales_number, '510000' sales_value union allselect 'USA' country, '2008-05-01' sale_month, '1350' sales_number, '530000' sales_value union allselect 'USA' country, '2008-06-01' sale_month, '1400' sales_number, '535000' sales_value union allselect 'USA' country, '2008-07-01' sale_month, '1300' sales_number, '510000' sales_value union allselect 'USA' country, '2008-08-01' sale_month, '1250' sales_number, '460000' sales_value union allselect 'USA' country, '2008-09-01' sale_month, '1400' sales_number, '530000' sales_value union allselect 'USA' country, '2008-10-01' sale_month, '1380' sales_number, '520000' sales_value union allselect 'USA' country, '2008-11-01' sale_month, '1450' sales_number, '540000' sales_value union allselect 'USA' country, '2008-12-01' sale_month, '1500' sales_number, '545000' sales_value union allselect 'USA' country, '2009-01-01' sale_month, '1600' sales_number, '550000' sales_value union allselect 'USA' country, '2009-02-01' sale_month, '1390' sales_number, '532000' sales_value union allselect 'USA' country, '2009-03-01' sale_month, '1730' sales_number, '570000' sales_value union allselect 'USA' country, '2009-04-01' sale_month, '1900' sales_number, '600000' sales_value union allselect 'USA' country, '2009-05-01' sale_month, '1850' sales_number, '585000' sales_value union allselect 'USA' country, '2009-06-01' sale_month, '3800' sales_number, '780000' sales_value union allselect 'USA' country, '2009-07-01' sale_month, '1700' sales_number, '560000' sales_value union allselect 'USA' country, '2009-08-01' sale_month, '1490' sales_number, '542000' sales_value union allselect 'USA' country, '2009-09-01' sale_month, '1830' sales_number, '580000' sales_value union allselect 'USA' country, '2009-10-01' sale_month, '2000' sales_number, '610000' sales_value union allselect 'USA' country, '2009-11-01' sale_month, '1950' sales_number, '595000' sales_value union allselect 'USA' country, '2009-12-01' sale_month, '1900' sales_number, '590000' sales_value
;2 问题分析
第一步:按照给定的分组方法,计算区间开始,区间结束的值。计算区间范围维度表DIM
select group_num, min_num + group_step * pos begin_num --区间开始, min_num + group_step * (pos + 1) end_num --区间结束, pos
from (select pos, group_num, group_step, min_numfrom (select--分组方法CEIL(1 + LOG(10, count_num) / LOG(10, 2)) group_num,--极差/组数 =组距CEIL((max_num - min_num) / CEIL(1 + LOG(10, count_num) / LOG(10, 2))) group_step,min_numfrom (SELECT MAX(sales_number) max_num,MIN(sales_number) min_num,COUNT(*) COUNT_NUMFROM sales) t) tlateral view posexplode(split(space(cast(group_num as int) - 1), space(1))) tmp as pos, value) t
第二步:关联数据表SALES,计算落入区间范围的个数
with dim as (
select group_num, min_num + group_step * pos begin_num --区间开始, min_num + group_step * (pos + 1) end_num --区间结束, posfrom (select pos, group_num, group_step, min_numfrom (select--分组方法CEIL(1 + LOG(10, count_num) / LOG(10, 2)) group_num,--极差/组数 =组距CEIL((max_num - min_num) / CEIL(1 + LOG(10, count_num) / LOG(10, 2))) group_step,min_numfrom (SELECT MAX(sales_number) max_num,MIN(sales_number) min_num,COUNT(*) COUNT_NUMFROM sales) t) tlateral view posexplode(split(space(cast(group_num as int) - 1), space(1))) tmp as pos, value) t)select concat_ws('-', cast(b.begin_num as string), cast(b.end_num as string)) group_name, count(*) cnt
from dim bleft join sales a
WHERE a.sales_number >= b.begin_numAND a.sales_number < b.end_num
GROUP BY concat_ws('-', cast(b.begin_num as string), cast(b.end_num as string))
3 小结
组距分组是将全部变量值依次划分为若干个区间,并将这一区间的变量值作为一组。组距分组是数值型数据分组的基本形式。离散变量的整数值如果变动幅度较大,而且总体单位数N又很大,则也要进行组距分组。 在组距分组中,各组之间的取值界限称为组限,一个组的最小值称为下限,最大值称为上限;上限与下限的差值称为组距;上限与下限值的平均数称为组中值,它是一组变量值的代表值。
具体步骤如下:
1. 确定组数。一组数据的组数一般与数据本身的特点及数据的多少有关。由于分组的目的之一是为了观察数据分布的特征,因此组数的多少应适中。如组数太少,数据的分布就会过于集中,组数太多,数据的分布就会过于分散,这都不便于观察数据分布的特征和规律。组数的确定应以能够显示数据的分布特征和规律为目的。
2.确定各组的组距。组距是一个组的上限与下限的差,可根据全部数据的最大值和最小值(即极差)及所分的组数来确定,即组距=(最大值-最小值)/组数。
3.根据分组整理成频数分布表。

如果您觉得本文还不错,对你有帮助,那么不妨可以关注一下我的数字化建设实践之路专栏,这里的内容会更精彩。
专栏 原价99,现在活动价59.9,按照阶梯式增长,还差5个人上升到69.9,最终恢复到原价。
专栏优势:
(1)一次收费持续更新。
(2)实战中总结的SQL技巧,帮助SQLBOY 在SQL语言上有质的飞越,无论你应对业务难题及面试都会游刃有余【全网唯一讲SQL实战技巧,方法独特】
SQL很简单,可你却写不好?每天一点点,收获不止一点点-CSDN博客
(3)实战中数仓建模技巧总结,让你认识不一样的数仓。【数据建模+业务建模,不一样的认知体系】(如果只懂数据建模而不懂业务建模,数仓体系认知是不全面的)
(4)数字化建设当中遇到难题解决思路及问题思考。
我的专栏具体链接如下:
数字化建设通关指南_莫叫石榴姐的博客-CSDN博客
相关文章:
数据科学与SQL:组距分组分析 | 区间分布问题
目录 0 问题描述 1 数据准备 2 问题分析 3 小结 0 问题描述 绝对值分布分析也可以理解为组距分组分析。对于某个指标而言,一个记录对应的指标值的绝对值,肯定落在所有指标值的绝对值的最小值和最大值构成的区间内,根据一定的算法&#x…...

odoo18中模型的常用字段类型
字段的公共属性: Char 字符类型,对应数据库中varchar类型,除了通用类型外接收另外两个参数: size: 字符长度,超出的长度将被截断 trim: 默认True,是否字段值应该被去空白。 Text 文本类型,对应数据库…...

【如何用更少的数据作出更好的决策】-gpt生成
如何用更少的数据作出更好的决策 用更少的数据作出更好的决策是一种能力的体现,需要结合有效的方法、严谨的逻辑以及对问题的深刻理解。以下是一些可以帮助你实现这一目标的策略: 明确目标 在收集和分析数据之前,先明确你的决策目标是什么…...

ara::com 与 AUTOSAR 元模型的关系总结
原文链接:AUTOSAR_EXP_ARAComAPI的7章笔记(6) 整体说明 先是表明此前解释 ara::com API 思想和机制时未涉及具体 AP 元模型清单部分,本章旨在阐明 ara::com 与相关元模型部分的关系,且是较高层次的基本理解性介绍&am…...

springboot整合hive
springboot整合hive pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.…...

浅谈 proxy
应用场景 Vue2采用的defineProperty去实现数据绑定,Vue3则改为Proxy,遇到了什么问题? - 在Vue2中不能检测数组和对象的变化 1. 无法检测 对象property 的添加或移除 var vm new Vue({data:{a:1} })// vm.a 是响应式的vm.b 2 // vm.b 是…...

Ansys Maxwell:SheetScan - 导入材料特性曲线
你好, 在这篇博文中,我展示了如何使用 Ansys Maxwell“SheetScan”工具导入材料特性数据集。在这篇博文中,我展示了如何导入复杂磁导率实部数据集以用于涡流(频率相关)求解器,并以 Ferroxcube 磁芯材料规格…...

解决 Android 单元测试 No tests found for given includes:
问题 报错: Execution failed for task :testDebugUnitTest. > No tests found for given includes: 解决方案 1、一开始以为是没有给测试类加public修饰 2、然后替换 Test 注解的包可以解决,将 org.junit.jupiter.api.Test 修改为 org.junit.Tes…...

人工智能的核心思想-神经网络
神经网络原理 引言 在理解ChatGPT之前,我们需要从神经网络开始,了解最简单的“鹦鹉学舌”是如何实现的。神经网络是人工智能领域的基础,它模仿了人脑神经元的结构和功能,通过学习和训练来解决复杂的任务。本文将详细介绍神经网络…...

JAVA中的Lamda表达式
JAVA中的Lamda表达式 Lambda 表达式的语法使用场景示例代码1.代替匿名内部类2. 带参数的 Lambda 表达式3. 与集合框架结合使用4. 使用 Stream 操作 总结 Java 的 Lambda 表达式是 Java 8 引入的一个新特性,用于简化代码,特别是在处理函数式编程时。Lambd…...

锂电池学习笔记(一) 初识锂电池
前言 锂电池近几年一直都是很热门的产品,充放电管理更是学问蛮多,工作生活中难免会碰到,所以说学习锂电池是工程师的必备知识储备,今天学习锂电池的基本知识,分类,优缺点,循序渐进 学习参考 【…...

深度学习2
四、tensor常见操作 1、元素值 1.1、获取元素值 tensor.item() 返回tensor的元素;只能在一个元素值使用,多个报错,当存在多个元素值时需要使用索引进行获取到一个元素值时在使用 item。 1.2、元素值运算 tensor对元素值的运算:…...
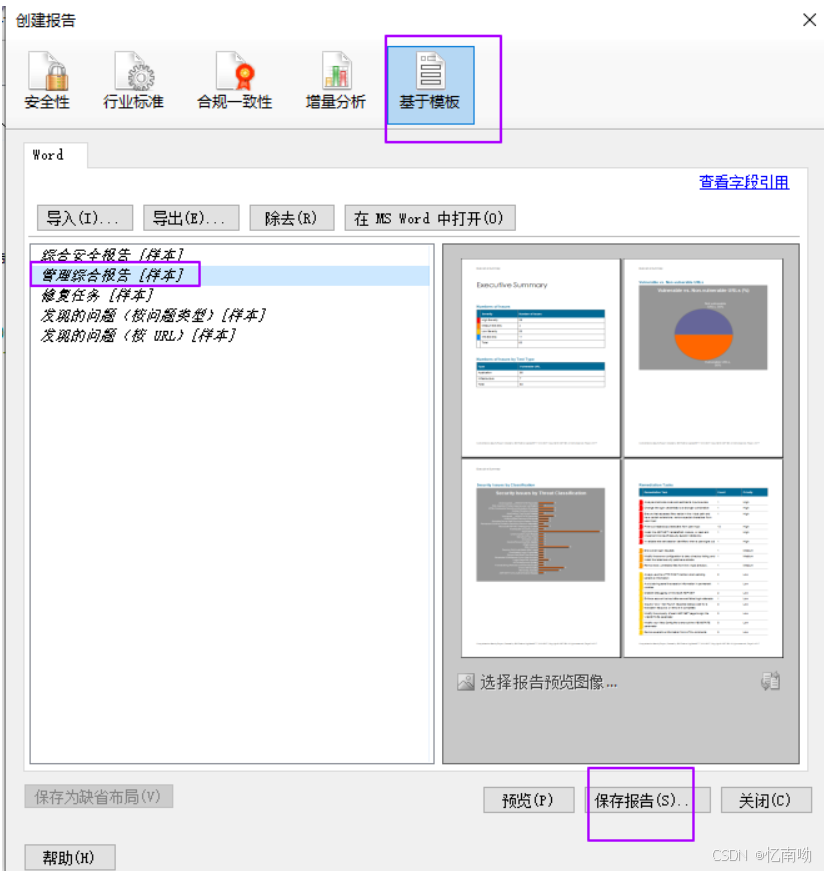
第六节-AppScan扫描报告
第六节-AppScan扫描报告 1.加载扫描结果 1.点击【打开】 2.选择之前保存过的扫描结果 3.等待加载完成 2.领导查看的报告 1.点击【报告】 2.模板选择为【缺省值】 3.最低严重性选择为【中】,测试类型选择为【应用程序】 4.点击【布局】 5.选择【其他徽标】&#x…...

【c++丨STL】stack和queue的使用及模拟实现
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:C、STL 目录 前言 一、什么是容器适配器 二、stack的使用及模拟实现 1. stack的使用 empty size top push和pop swap 2. stack的模拟实现 三、queue的…...

基于SpringBoot的在线教育系统【附源码】
基于SpringBoot的在线教育系统 效果如下: 系统登录页面 系统管理员主页面 课程管理页面 课程分类管理页面 用户主页面 系统主页面 研究背景 随着互联网技术的飞速发展,线上教育已成为现代教育的重要组成部分。在线教育系统以其灵活的学习时间和地点&a…...

Kafka-副本分配策略
一、上下文 《Kafka-创建topic源码》我们大致分析了topic创建的流程,为了保持它的完整性和清晰度。细节并没有展开分析。下面我们就来分析下副本的分配策略以及副本中的leader角色的确定逻辑。当有了副本分配策略,才会得到分区对应的broker,…...

市场波动不断,如何自我提高交易心理韧性?
交易市场,一个由无数变量交织而成的复杂领域,常常因各方因素的微妙变化而掀起波澜。在这里,机遇与挑战并存,诱人的利润与潜在的风险如影随形,共同考验着每一位交易员的智慧与心理承受能力。在这样的环境下,…...

加速科技精彩亮相中国国际半导体博览会IC China 2024
11月18日—20日,第二十一届中国国际半导体博览会(IC China 2024)在北京国家会议中心顺利举办,加速科技携重磅产品及全系测试解决方案精彩亮相,加速科技创始人兼董事长邬刚受邀在先进封装创新发展论坛与半导体产业前沿与…...

利用c语言详细介绍下选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它是每次选出最小或者最大的元素放在开头或者结尾位置(采用升序的方式),最终完成列表排序的算法。 一、图文介绍 我们还是使用数组【10,5,3…...

华为流程L1-L6业务流程深度细化到可执行
该文档主要介绍了华为业务流程的深度细化及相关内容,包括流程框架、建模方法、流程模块描述、流程图建模等,旨在帮助企业构建有效的流程体系,实现战略目标。具体内容如下: 华为业务流程的深度细化 流程层级:华为业务流程分为 L1 - L6 六个层级,L1 为流程大类,L2 为流程…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...