elasticsearch介绍和部署
1 elasticsearch介绍
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。可以很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
2 ES相关的术语介绍

**index:**也叫索引,一个索引最少要有一个分片。指的是逻辑的存储和读取单元。一个索引也可以叫做1个文档名
**shard:**分片,用于实际存储数据信息。索引数据可以分布到集群中的不同节点,每个索引可以分为多个分片。分片可以提高数据存储和查询的效率
**replica:**副本,用于索引分片冗余,以及提高数据的可靠性和查询性能。副本可以分布在不同的节点上,确保即使某些节点故障,数据也不会丢失
**primary shard:**主分片,负责数据的读写
**replica shard:**副本分片,从primary shard同步数据且,负责读的负载均衡。也就是说读数据时,会往多个副本读取。
**allocation:**把索引的不同分片分配到整个集群的过程
**document:**文档,用于的实际数据的载体,分为元数据和源数据
-
源数据:指的是用户实际的存储。数据存储在"_source"字段中
-
元数据:用于描述数据的数据,比如
_index,_id,_type,_source
ES集群颜色和含义:
-
green代表所有的主分片和副本分片都正常访问
-
yellow代码部分副本分片无法访问
- 例如,副本数量大于集群数量。导致没有可用节点分配
-
red代表部分主分片无法访问
ES相关端口:
- 9200,支持http|https协议,对外部提供服务访问
- 9300,支持tcp协议,对内部ES集群进行数据传输
2 elasticsearch的安装
01 单点方式部署
| IP | 主机名 | 内存 |
|---|---|---|
| 10.0.0.091 | elk91 | 2G |
提示:elasticsearch的deb安装包集成了java环境,因此安装包体积较大,也可以二进制部署,软件和java环境分开部署。
1.以7.17.22版本为例:wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.22-amd64.deb
2.安装软件包
dpkg -i elasticsearch-7.17.22-amd64.deb
3.修改配置文件:vim /etc/elasticsearch/elasticsearch.yml
# 指定集群的名称,每个ES集群的名称要唯一
17 cluster.name: wzy-com# 数据的存储路径,默认即可
33 path.data: /var/lib/elasticsearch# 日志的存储路径,默认即可
37 path.logs: /var/log/elasticsearch# 指定监听本地的地址,监听全部则写成 0.0.0.0
56 #network.host: 10.0.0.91# 对外的访问端口
http.port: 9200# 集群之间数据传输端口
61 #http.port: 9200# 部署集群为单点类型
discovery.type: "single-node"
简化的配置为:
[root@elk91~]# yy /etc/elasticsearch/elasticsearch.yml
cluster.name: wzy-com
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.type: "single-node"
3.启动es
systemctl restart elasticsearch.service[root@elk91~]# netstat -antlp | grep 9[23]00
tcp6 0 0 :::9300 :::* LISTEN 3235/java
tcp6 0 0 :::9200 :::* LISTEN 3235/java
4.如果启动失败,就去看日志:/var/log/elasticsearch/wzy-com.log;或者journalctl -fu elasticsearch
5.访问es
[root@elk91~]# curl http://10.0.0.91:9200
{"name" : "elk91","cluster_name" : "wzy-com","cluster_uuid" : "ypPsMv8WQOmQZ3H1VSF-Xw","version" : {"number" : "7.17.22","build_flavor" : "default","build_type" : "deb","build_hash" : "38e9ca2e81304a821c50862dafab089ca863944b","build_date" : "2024-06-06T07:35:17.876121680Z","build_snapshot" : false,"lucene_version" : "8.11.3","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}
6.卸载es
dpkg命令说明:
-
dpkg -r 卸载
-
dpkg -P 卸载并移除配置文件
卸载后再使用rm -rf /tmp*
02 集群方式部署
1.环境准备
| IP地址 | 主机名 |
|---|---|
| 10.0.0.91 | elk91 |
| 10.0.0.92 | elk92 |
| 10.0.0.93 | elk93 |
- 所有节点设置正确的时间:
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime - 安装ES软件
1.所有节点修改配置文件为:
cat >/etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: elk-wzy
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300# 配置ES集群的服务发现列表主机
discovery.seed_hosts: ["10.0.0.91","10.0.0.92","10.0.0.93"]# 配置ES集群启动时参与master选举的节点
cluster.initial_master_nodes: ["10.0.0.91","10.0.0.92","10.0.0.93"]
EOF
最后启动es:systemctl enable elasticsearch --now
2.验证是否为集群还是脑裂。访问任意1个节点,看到主机列表为3个节点就是搭建成功了。否则卸载重新搭建
[root@elk91~]# curl -s 10.0.0.93:9200/_cat/nodes
10.0.0.91 29 96 5 0.66 0.53 0.44 cdfhilmrstw - elk91
10.0.0.93 25 96 2 0.60 0.43 0.22 cdfhilmrstw - elk93
10.0.0.92 48 96 3 0.47 0.57 0.32 cdfhilmrstw * elk92
# 卸载
systemctl disable elasticsearch --now
dpkg -P elasticsearch
rm -rf /tmp/* /var/{log,lib}/elasticsearch# 安装
dpkg -i elasticsearch-7.17.22-amd64.deb
cat >/etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: efk-wzy
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["10.0.0.91","10.0.0.92","10.0.0.93"]
cluster.initial_master_nodes: ["10.0.0.91","10.0.0.92","10.0.0.93"]
EOF
systemctl enable elasticsearch --now
03 ES的堆内存设置
此操作为可选项:
-Xms 和 -Xmx 是 JVM(Java 虚拟机)启动参数,用于设置堆内存(Heap Memory)的初始大小和最大大小。这两个参数直接影响 Java 应用的性能和内存管理。建议设置为主机内存的一半
修改 /etc/elasticsearch/jvm.options ,
...
-Xms4096m
-Xmx4096m
...
相关文章:
elasticsearch介绍和部署
1 elasticsearch介绍 Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。可以很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsea…...

Flutter之使用mqtt进行连接和信息传输的使用案例
目录 引言 什么是MQTT? 在Flutter中使用MQTT 安装 iOS 安卓 创建一个全局的客户端对象 配置客户端对象 连接(异步) 监听接受的消息 发送消息 监听连接状态和订阅的回调 引言 随着移动应用开发技术的发展,实时通信成为…...

汽车HiL测试:利用TS-GNSS模拟器掌握硬件性能的仿真艺术
一、汽车HiL测试的概念 硬件在环(Hardware-in-the-Loop,简称HiL)仿真测试,是模型基于设计(Model-Based Design,简称MBD)验证流程中的一个关键环节。该步骤至关重要,因为它整合了实际…...
【MyBatisPlus·最新教程】包含多个改造案例,常用注解、条件构造器、代码生成、静态工具、类型处理器、分页插件、自动填充字段
文章目录 一、MyBatis-Plus简介二、快速入门1、环境准备2、将mybatis项目改造成mybatis-plus项目(1)引入MybatisPlus依赖,代替MyBatis依赖(2)配置Mapper包扫描路径(3)定义Mapper接口并继承BaseM…...
)
前端知识点---rest(javascript)
文章目录 前端知识点---rest(javascript)rest的用法基本语法特点使用场景与扩展运算符(spread)区别小练习 前端知识点—rest(javascript) rest出现于ES2015 function doSum(a,b, ...args) //示例中的args就是一个rest参数 //它会将后续的所有参数存储…...
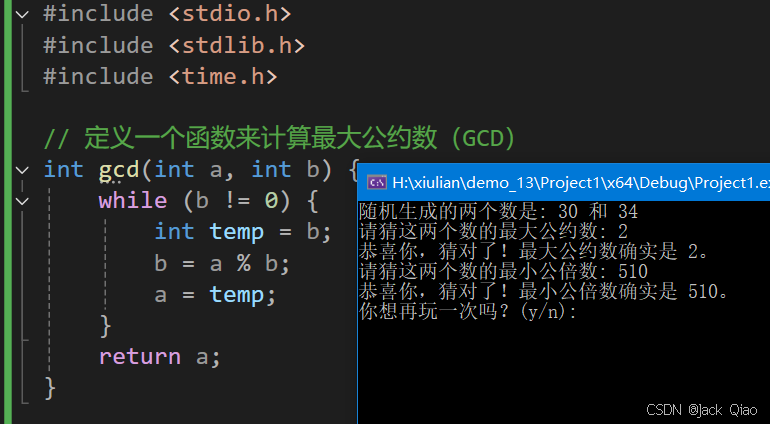
13. 猜最大公约数最小公倍数小游戏
文章目录 概要整体架构流程技术名词解释技术细节小结 1. 概要 ~ Jack Qiao对米粒说:“今天咱们玩个小游戏,这个游戏的玩家需要猜出,两个随机生成的整数的最大公约数(GCD)和最小公倍数(LCM)。如…...

Git 多仓库提交用户信息动态设置
Git 多仓库提交用户信息动态设置 原文地址:dddhl.cn 前言 在日常开发中,我们可能需要同时管理多个远程仓库(如 GitHub、Gitee、GitLab),而每个仓库使用不同的邮箱和用户名。比如,GitHub 和 Gitee 使用相…...

2024.6使用 UMLS 集成的基于 CNN 的文本索引增强医学图像检索
Enhancing Medical Image Retrieval with UMLS-Integrated CNN-Based Text Indexing 问题 医疗图像检索中,图像与相关文本的一致性问题,如患者有病症但影像可能无明显异常,影响图像检索系统准确性。传统的基于文本的医学图像检索࿰…...

了解Redis(第一篇)
目录 Redis基础 什么事Redis Redis为什么这么快 除了 Redis,你还知道其他分布式缓存方案吗? 说-下 Redis 和 Memcached 的区别和共同点 为什么要用Redis? 什么是 Redis Module?有什么用? Redis基础 什么事Redis Redis (REmote DIctionary S…...

UE5 第一人称射击项目学习(二)
在上一章节中。 得到了一个根据视角的位置创建actor的项目。 现在要更近一步,对发射的子弹进行旋转。 不过,现在的子弹是圆球形态的,所以无法分清到底怎么旋转,所以需要把子弹变成不规则图形。 现在点开蓝图。 这里修改一下&…...

npm/cnpm的使用
npm 1、安装npm 前往nodejs官网下载安装node 验证是否安装成功node node -v node安装npm也会安装 npm -v 2、使用npm 1. 初始化项目 在一个项目文件夹中运行: npm init 根据提示输入项目信息(如项目名称、版本号等)。 如果你希望快速初…...

go-zero(六) JWT鉴权
go-zero JWT鉴权 还记得我们之前登录功能,返回的信息是token吗? 这个token其实就是JSON Web Token简称JWT,它是一种开放标准(RFC 7519),用于在网络应用环境间安全地传递声明信息。 它是一种基于 JSON 的令牌…...

做一个FabricJS.cc的中文文档网站——面向markdown编程
📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!📢本文作者:由webmote 原创📢作者格言:新的征程,用爱发电&#…...

开发 + 安全:网络安全的协作方法
开发团队和安全团队之间由来已久的紧张关系一直是组织内部摩擦的根源。开发人员优先考虑速度和效率,旨在通过快节奏、迭代的开发周期快速交付功能和产品并高效前进。另一方面,安全团队努力平衡风险和创新,但必须专注于使用护栏保护敏感数据和…...

Next.js- App Router 概览
#题引:我认为跟着官方文档学习不会走歪路 一:App Router与Page Router 在 v13 版本中,Next.js 引入了一个基于 React 服务器组件 构建的新的 App Router,而在这之前,Next.js 使用的是Page Router。 目录结构 pages …...

python oa服务器巡检报告脚本的重构和修改(适应数盾OTP)有空再去改
Two-Step Vertification required: Please enter the mobile app OTPverification code: 01.因为巡检的服务器要双因子认证登录,也就是登录堡垒机时还要输入验证码。这对我的巡检查服务器的工作带来了不便。它的机制是每一次登录,算一次会话…...

【工控】线扫相机小结 第四篇
背景 这一片主要是对第三篇继续补充。话说上一篇讲到了两种模式的切换,上一篇还遗留了一个Bug,在这一篇里进行订正! 代码回顾 /// <summary>/// 其实就是打开触发/// </summary>void SetLineSacanWorkMode(){-----首先设置为帧…...

亲测解决Unpack operator in subscript requires Python 3.11 or newer
这个问题是在小虎想提前定义一个list,然后作为index list来调用另一个list里面的变量出现的问题。 环境 Ubuntu 22.04 + python 3.10 故障代码示例 NoneList = [None] * opt.spatial_dims TargetMask = Target[i] == torch.arange(1...

数据结构 ——— 堆排序算法的实现
目录 前言 向下调整算法(默认建大堆) 堆排序算法的实现(默认升序) 前言 在之前几章学习了如何用向上调整算法和向下调整算法对数组进行建大/小堆数据结构 ——— 向上/向下调整算法将数组调整为升/降序_对数组进行降序排序代码…...

On-Chip-Network之Topology
片上网络拓扑决定了网络中节点和通道之间的物理布局和连接。拓扑对整体网络性价比的影响是巨大的。拓扑决定了消息 必须经过的跳数(或路由器)以及跳数之间的互连长度,从而显著影响网络延迟。由于经过路由器和链路会产生功耗,因此 …...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...