网络爬虫总结与未来方向
通过深入学习和实际操作,网络爬虫技术从基础到进阶得以系统掌握。本节将全面总结关键内容,并结合前沿技术趋势与最新资料,为开发者提供实用性强的深度思考和方案建议。
1. 网络爬虫技术发展趋势
1.1 趋势一:高性能分布式爬虫
随着互联网信息规模指数增长,高性能分布式爬虫成为趋势。以 Scrapy-Redis 和 Apache Kafka 为代表的工具正逐渐成为主流。
技术方案
-
任务分布与负载均衡
- 使用 Redis 管理爬取任务队列,支持多节点协同作业。
- 借助 负载均衡器(如 Nginx) 分配任务流量,避免单点瓶颈。
-
数据去重与缓存
- Redis 提供内存缓存功能,快速去重已爬取 URL。
- Bloom Filter(布隆过滤器)有效降低内存消耗。
-
大规模分布式架构
- 引入 Apache Kafka 实现分布式消息队列。
- 使用 Elasticsearch 作为存储层,快速索引和检索海量数据。
案例:多节点分布式爬取新闻网站
- 新闻数据实时爬取。
- 分布式部署在 Kubernetes 集群,利用 Pod 动态扩展。
- 数据存储到 Elasticsearch,支持全文检索和分析。
apiVersion: apps/v1
kind: Deployment
metadata:name: distributed-crawler
spec:replicas: 5template:spec:containers:- name: crawlerimage: crawler-image:latestresources:limits:memory: "512Mi"cpu: "500m"1.2 趋势二:智能爬虫
现代反爬机制日益复杂,传统爬虫难以应对。智能爬虫结合 深度学习 和 强化学习 可有效提升爬取成功率。
智能化页面解析
- 深度学习技术:
- 使用 Faster R-CNN 模型对页面结构进行检测。
- 提取复杂 DOM 树中目标元素。
- 工具链:
- Pyppeteer:高效渲染和爬取动态网页。
- Playwright:跨浏览器支持更强的操作能力。
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=True)page = browser.new_page()page.goto("https://example.com")content = page.inner_text('div.content')print(content)行为模拟与反检测
-
模拟真实用户行为:
- 随机点击、滚动等操作。
- 动态调整访问速度。
-
绕过 JavaScript 指纹检测:
- 使用 Fingerprint.js Pro 隐藏爬虫行为。
1.3 趋势三:数据语义化与结构化
未来,语义化数据爬取将成为趋势。
技术方案
- Schema.org 标准:通过 JSON-LD 或 RDF 提供结构化数据接口。
- 知识图谱构建:
- 使用 SPARQL 语言查询知识库。
- 融合 NLP 模型对文本信息进行知识抽取。
2. 深度学习在爬虫中的应用
深度学习技术提供了爬虫项目全新的突破点。
2.1 OCR 技术
在爬取验证码或嵌入式图片信息时,OCR 技术是关键。
技术实现
- 工具:
- Tesseract OCR:轻量化开源引擎。
- CRNN(卷积递归神经网络):适合复杂场景。
案例:爬取包含验证码的网页
from pytesseract import image_to_string
from PIL import Imagecaptcha = Image.open("captcha.png")
result = image_to_string(captcha)
print(f"识别结果: {result}")前沿进展
- 使用 Vision Transformer (ViT) 模型提升 OCR 识别率。
- 在场景文本识别(如广告牌和视频帧)中表现卓越。
2.2 自然语言处理
爬虫结果中的非结构化文本需要 NLP 技术进行分析。
技术点
-
情感分析
- 使用 Transformer 模型(如 BERT)分析情感倾向。
- 应用:舆情监测、电商评论分析。
-
关键词提取
- 工具:TextRank、TF-IDF。
- 应用:抽取网页标题和摘要。
from transformers import pipelinenlp = pipeline("sentiment-analysis")
result = nlp("I love this product!")
print(result)- 实体识别
- 自动识别人名、地点等信息。
- 构建知识图谱和语义搜索。
3. 爬虫项目实战与优化
3.1 综合实战案例
案例:电商网站爬虫
- 功能:
- 爬取商品名称、价格和评价。
- 分析热销商品趋势。
技术选型
-
数据爬取:
- 使用 Scrapy 获取基本信息。
- 借助 Playwright 动态渲染复杂页面。
-
数据存储与分析:
- 数据存储:MongoDB + ElasticSearch。
- 数据分析:Pandas + Matplotlib。
代码示例
import scrapyclass EcommerceSpider(scrapy.Spider):name = 'ecommerce'start_urls = ['https://example.com/products']def parse(self, response):for product in response.css('.product-item'):yield {'name': product.css('h2::text').get(),'price': product.css('.price::text').get()}3.2 持续优化策略
-
代码性能调优
- 使用异步库(如 asyncio)提高爬取效率。
- 优化爬取逻辑,减少多余请求。
-
分布式架构
- 使用 Celery 实现任务队列,结合 Redis 提高任务分发性能。
-
日志与监控
- 部署 ELK 堆栈(Elasticsearch、Logstash、Kibana)监控爬虫状态。
总结
本章深入探讨了网络爬虫的核心能力与未来方向,并结合最新技术趋势丰富了内容。开发者可通过智能化、分布式和深度学习技术实现更高效、更智能的爬虫系统,同时需严格遵守道德规范与法律合规,打造真正具有实际应用价值的爬虫工具。
参考文献:
- 最新 NLP 模型文档:Hugging Face
- 分布式爬虫实践:Scrapy-Redis
- 深度学习 OCR 框架:TensorFlow OCR

相关文章:
网络爬虫总结与未来方向
通过深入学习和实际操作,网络爬虫技术从基础到进阶得以系统掌握。本节将全面总结关键内容,并结合前沿技术趋势与最新资料,为开发者提供实用性强的深度思考和方案建议。 1. 网络爬虫技术发展趋势 1.1 趋势一:高性能分布式爬虫 随…...

C++ 核心数据结构:Stack 与 Queue 类深度解析
🌟快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。 🌟 目录 💯前言 💯Stack 类 (一)Stack 类的概念与特点 (二&#x…...

Python枚举类详解:用enum模块高效管理常量数据
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 在编程中,常量的管理是一个关键环节,合理的管理常量可以提高代码的可读性和可维护性。Python的enum模块提供了一种有效的方式来组织常量数据,通过枚举类(Enum)将相关的常量值集合在一起,使代码更具结…...

企业OA管理系统:Spring Boot技术深度探索
4系统概要设计 4.1概述 本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示: 图4-1系统工作原理…...

汽车免拆诊断案例 | 2012款路虎揽胜运动版柴油车加速无力
故障现象 一辆2012款路虎揽胜运动版车,搭载3.0T柴油发动机(型号为306DT),累计行驶里程约为10.2万km。车主进厂反映,车辆行驶中加速无力,且发动机故障灯异常点亮。 故障诊断 接车后试车,发动…...

uniapp接入高德地图
下面代码兼容安卓APP和H5 高德地图官网:我的应用 | 高德控制台 ,绑定服务选择《Web端(JS API)》 /utils/map.js 需要设置你自己的key和安全密钥 export function myAMap() {return new Promise(function(resolve, reject) {if (typeof window.onLoadM…...

(UI自动化测试)web自动化测试
web自动化测试 UI自动化测试介绍 自动化测试理论: 图片上的文字等等不能做测试,只能发现固定的bug 工具选择及介绍 浏览器驱动:找元素--核心:驱动(操作元素)--通过代码...

【es6进阶】如何使用Proxy实现自己的观察者模式
观察者模式(Observer mode)指的是函数自动观察数据对象,一旦对象有变化,函数就会自动执行。这里,我们是使用es6的proxy及reflect来实现这个效果。 实现效果 业务分析 源数据 const object2 {name: "张三"…...

住宅IP怎么在指纹浏览器设置运营矩阵账号
矩阵账号的运营已经成为了许多企业和个人推广策略中的重要一环。通过构建和管理多个社交媒体或电商平台的账号,可以有效地扩大品牌影响力,提高市场覆盖率。然而,随着平台对账号关联的限制越来越严格,如何安全、有效地运营这些矩阵…...

表格数据处理中大语言模型的微调优化策略研究
论文地址 Research on Fine-Tuning Optimization Strategies for Large Language Models in Tabular Data Processing 论文主要内容 这篇论文的主要内容是研究大型语言模型(LLMs)在处理表格数据时的微调优化策略。具体来说,论文探讨了以下…...

CentOS7 如何查看kafka topic中的数据
1. 确保 Kafka 服务运行 先检查 Kafka 和 Zookeeper 是否正在运行: systemctl status kafka systemctl status zookeeper 如果没有启动,先启动服务: systemctl start zookeeper systemctl start kafka 2. 进入 Kafka 安装目录 通常 …...

VRRP实现出口网关设备冗余备份
VRRP虚拟路由冗余 vrrp实现设备主备备份 Tips: VRRP能够在不改变组网的情况下,将多台路由器虚拟成一个虚拟路由器,通过配置虚拟路由器的IP地址为默认网关,实现网关的备份。协议版本: VRRPV2 (常用)和VRRPV3:VRRPV2仅适用于IPv4…...

超详细:Redis分布式锁
如何基于 Redis 实现一个最简易的分布式锁? 不论是本地锁还是分布式锁,核心都在于“互斥”。 在 Redis 中, SETNX 命令是可以帮助我们实现互斥。SETNX 即 SET if Not eXists (对应 Java 中的 setIfAbsent 方法),如果 key 不存在…...

Vue与React的Suspense组件对比
在Vue和React中都内置了Suspense组件,该组件用于处理异步组件加载。当Suspense包裹的实际组件内容尚未加载完成时会先展示后备内容,等待组件内容加载完成后再切换成实际组件内容。这可以显著提升用户体验,适用于大数据加载、组件懒加载等场景…...

Spring框架深度剖析:特性、安全与优化
文章目录 Spring框架简介主要特性1. 依赖注入(Dependency Injection, DI)2. 面向切面编程(Aspect-Oriented Programming, AOP)3. 声明式事务管理4. 强大的MVC框架5. 集成测试支持6. 多种数据访问技术的支持 安全性1. 认证…...
硬盘文件误删:全面解析、恢复方案与预防策略
一、硬盘文件误删现象概述 在日常使用电脑的过程中,硬盘文件误删是许多用户都曾遇到过的问题。这种意外的数据丢失,不仅可能让我们辛苦编辑的文档、珍贵的照片和视频等瞬间消失,还可能对工作和生活造成重大影响。硬盘文件误删,如…...
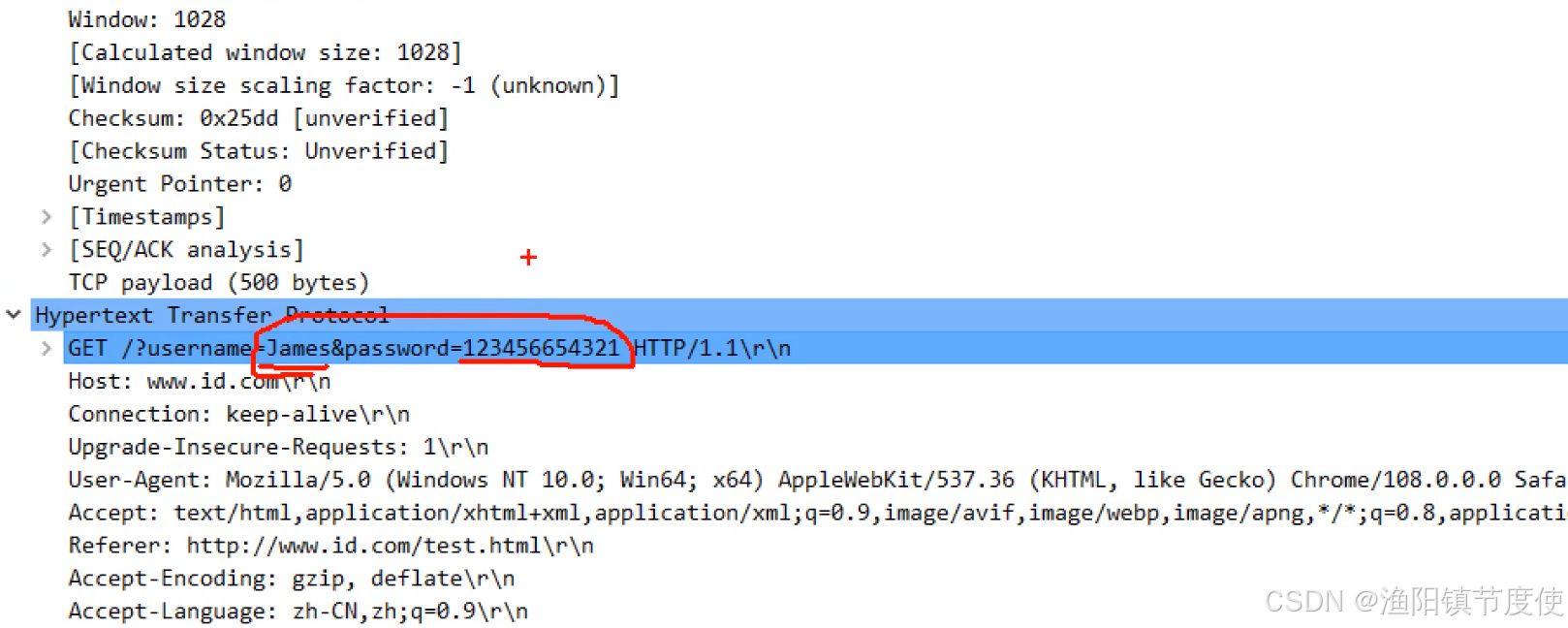
tcpdump抓包 wireShark
TCPdump抓包工具介绍 TCPdump,全称dump the traffic on anetwork,是一个运行在linux平台可以根据使用者需求对网络上传输的数据包进行捕获的抓包工具。 tcpdump可以支持的功能: 1、在Linux平台将网络中传输的数据包全部捕获过来进行分析 2、支持网络层…...
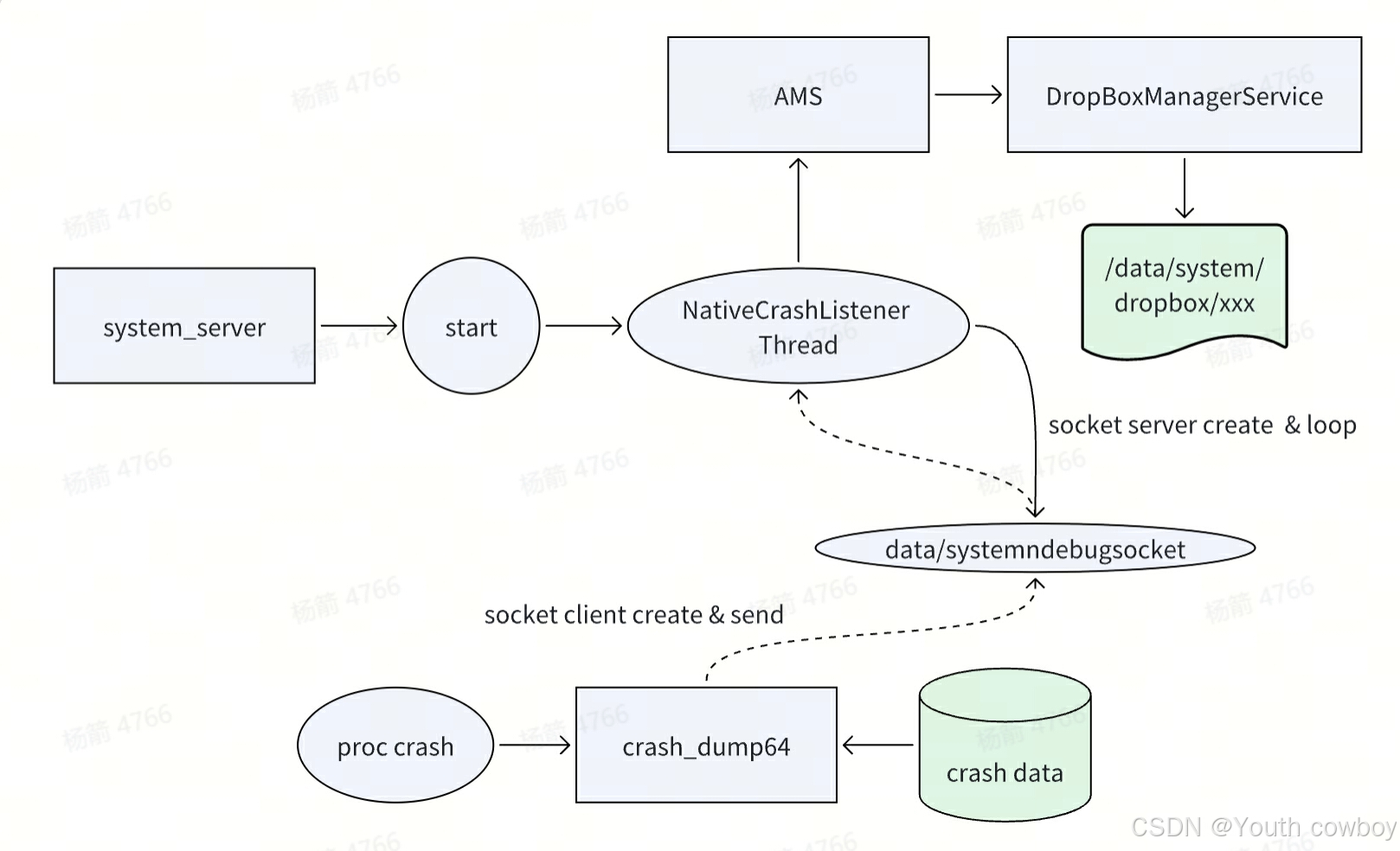
Android system_server进程
目录 一、system_server进程介绍 二、system_server进程启动流程 2.1 startBootstrapServices 2.2 startCoreServices 2.3 startOtherServices 2.4 startApexServices 三、如何使用系统服务 3.1 app进程调用系统服务 3.2 native进程调用系统服务 3.3 system_server进…...

Vue3+element-plus 实现中英文切换(Vue-i18n组件的使用)
1、前言 在 Vue 3 项目中结合 vue-i18n 和 Element Plus 实现中英文切换是一个常见的需求。下面是一个详细的步骤指南,帮助你完成这个任务。 安装引入 1. 安装依赖 首先,你需要安装 vue-i18n 和 Element Plus。 npm install vue-i18nnext element-p…...
)
python实现猜数字游戏( 可视化easygui窗口版本 )
1.先上源代码 import random import easygui as egdef guess_ordinary():answer random.randint(0, 11)user_answer int(eg.enterbox(msg "请在0-10中选择一个整数: ", title "猜数字"))if user_answer answer:eg.msgbox(msg "恭喜你ÿ…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...