Hive分桶超详细!!!
1、分桶的意义
数据分区可能导致有些分区,数据过多,有些分区,数据极少。分桶是将数据集分解为若干部分(数据文件)的另一种技术。
分区和分桶其实都是对数据更细粒度的管理。当单个分区或者表中的数据越来越大,分区不能细粒度的划分数据时,我们就采用分桶技术将数据更细粒度的划分和管理。
分桶其实跟我们MR中的分区是一样的。
2、分桶的原理
与MapReduce中的HashPartitioner的原理一模一样
MapReduce:使用key的hash值对reduce的数量进行取模(取余)
hive:使用分桶字段的hash值对分桶的数量进行取模(取余)。针对某一列进行分桶存储。每一条记录都是通过分桶字段的值的hash对分桶个数取余,然后确定放入哪个桶。
MapReduce: Key 单词 reduce的数量是3个,最后形成3个。
hello --> hello 进行hash算法 --> 得到的hash值对3取模(0 1 2)
MapReduce假如不指定分区,是否有分区呢?答案是有,使用默认分区HashPartitioner。
Hive --> 假如 我指定分桶字段为 id , 桶的数量为 3个,就是hash(id) % 3 = 0 1 2
桶是一个个的文件,分区是一个个的文件夹。
hash 是一种算法,你需要知道,任何值都可以 hash
举例:hello --> 237847238
"hello".hashCode()
3、分桶有啥好处
分区的意义:提高查询效率
分桶的意义:将每一个分区的数据进行切分,变成一个个小文件,然后进行抽样查询(从一堆数据中找一些数据进行分析)。在进行多表联查的时候,可以提高效率(hive优化的时候再提)。
两个大表 join,使用分桶表,查询速度快。
4、分桶的实战
创建分桶的表:
create table stu_bucket(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by ' ';
设置reduce的数量:
注意:
想要将表创建为4个桶,需要将hive中mapreduce.job.reduces参数设置为>=4或设置为-1;
通过 set mapreduce.job.reduces ; 可以查看参数的值hive (yhdb)> set mapreduce.job.reduces;
mapreduce.job.reduces=-1
hive (yhdb)> set mapreduce.job.reduces=-1;reduces = -1 表示让系统自行决定reduce的数量。在 wordcount 的时候,创建了三个分区,reduce 的数量设置为 3,最合理,也可以设置为 1,也可以设置为 4。
加载数据:
建议:不要使用load直接加载!
使用:创建普通表,加载普通表的数据到分桶表。数据:student.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16建议不要使用load直接加载,但是可以尝试一下:
load data local inpath '/home/hivedata/student.txt' into table stu_bucket;

如上所示:Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
1、reduce=-1 让job自行决定开启多少个reduce,或者设置数量大于等于桶的数量。
2、建议关闭本地模式:

官方建议使用 创建临时表加载数据:使用insert将数据插入到分桶表
hive(yhdb)> truncate table stu_bucket;(删除表内数据,不删表结构,因此只能删内表)
hive(yhdb)> create table temp_stu(id int, name string)
row format delimited fields terminated by ' ';
hive(yhdb)> load data local inpath '/home/hivedata/student.txt' into table temp_stu;
hive(yhdb)> insert into table stu_bucket select * from temp_stu cluster by (id);
5、分桶的查询
数据不对语法: tablesample(bucket x out of y on sno)select * from stu_bucket;
select * from stu_bucket tablesample(bucket 1 out of 1);查询第一桶
select * from stu_bucket tablesample(bucket 1 out of 4 on id);查询第一桶和第三桶
select * from stu_bucket tablesample(bucket 1 out of 2 on id);查询第二桶和第四桶的数据
select * from stu_bucket tablesample(bucket 2 out of 2 on id);
查询对8取余的第一桶的数据:
select * from stu_bucket tablesample(bucket 1 out of 8 on id);其他查询:
查询前三条
select * from stu_bucket limit 3;
select * from stu_bucket tablesample(3 rows);
查询百分比的数据select * from stu_bucket tablesample(13 percent);大小的百分比所占的那一行。
查询固定大小的数据select * from stu_bucket tablesample(68b); 单位(K,KB,MB,GB...)固定大小所占的那一行。 byte--字节 bit --位
随机抽三行数据select * from stu_bucket order by rand() limit 3;6、总结(重要)
定义阶段:
clustered by (id); ---指定表内的字段进行分桶。
sorted by (id asc|desc) ---指定数据的排序规则,表示咱们预期的数据是以这种规则进行的排序举例:
create table stu_bucket2(id int, name string)
clustered by(id) sorted by(id desc)
into 4 buckets
row format delimited fields terminated by ' ';
sorted by 指定分桶表中的每一个桶的排序规则
导入数据阶段:
cluster by (id)
--指定getPartition以哪个字段来进行hash,并且排序字段也是指定的字段,排序是以asc排列
--相当于distribute by (id) sort by (id)insert into table stu_bucket select * from student cluster by (id);
想当于:
insert into table stu_bucket select * from student distribute by (id) sort by (id) ;distribute by (id) -- 指定getPartition以哪个字段来进行hash
sort by (name asc | desc) --指定排序字段
-- 区别:distribute by 这种方式可以分别指定getPartition和sort的字段总结:
分区使用的是表外字段,分桶使用的是表内字段
分桶更加细粒度的管理数据,更多的是使用来做抽样、join
cluster 和 clusted 的区别:一个是导入数据的时候调用的,一个是创建表的时候使用的。
sort by 和 sorted by 区别:sort by 是导入数据的时候,sorted by 是分桶排序规则指定的时候
distribute by 和 cluster by 的区别:前一个是分区,后一个是分区并排序。
partition by 和 partitioned by 的区别:partition by 一般和开窗函数一起使用,partitioned by 建表的时候一起使用。
相关文章:
Hive分桶超详细!!!
1、分桶的意义 数据分区可能导致有些分区,数据过多,有些分区,数据极少。分桶是将数据集分解为若干部分(数据文件)的另一种技术。 分区和分桶其实都是对数据更细粒度的管理。当单个分区或者表中的数据越来越大,分区不能细粒度的划分数据时,我…...
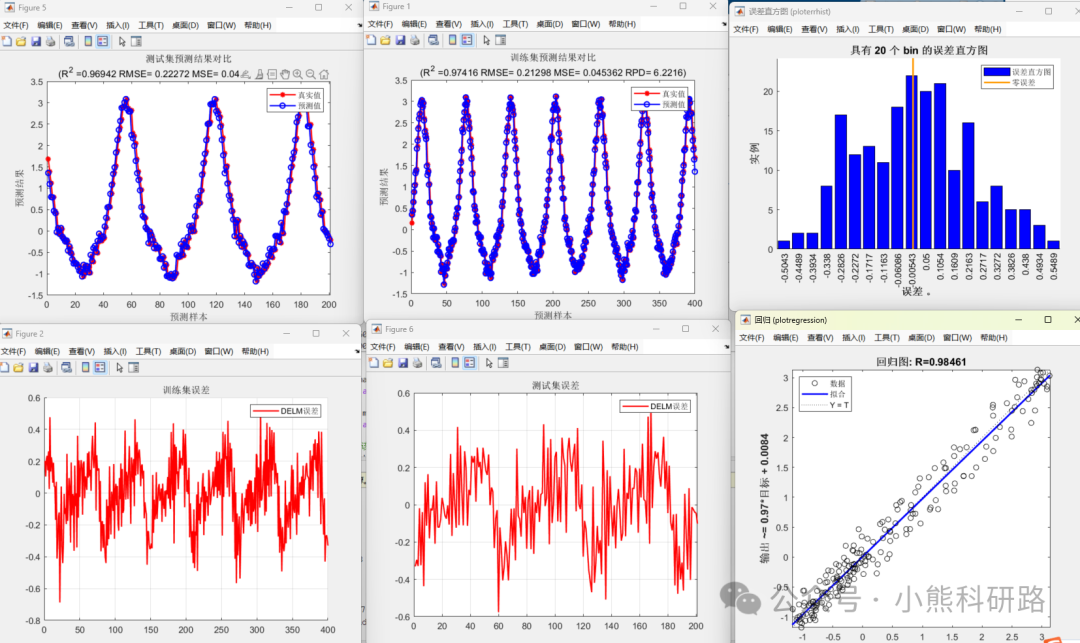
【深度学习之回归预测篇】 深度极限学习机DELM多特征回归拟合预测(Matlab源代码)
深度极限学习机 (DELM) 作为一种新型的深度学习算法,凭借其独特的结构和训练方式,在诸多领域展现出优异的性能。本文将重点探讨DELM在多输入单输出 (MISO) 场景下的应用,深入分析其算法原理、性能特点以及未来发展前景。 1、 DELM算法原理及其…...
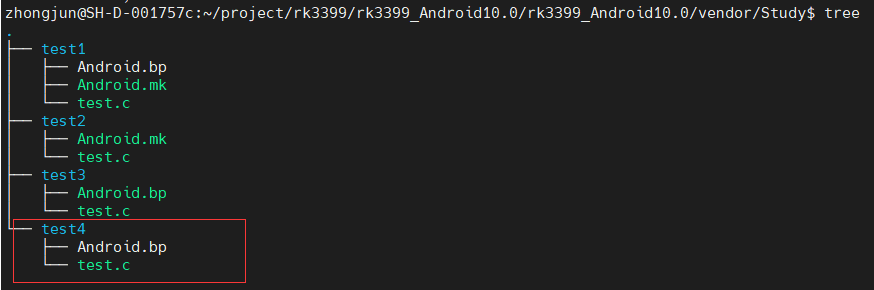
Android mk/bp构建工具介绍
零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等,加上网络上其实没有一个完整的介绍Bluedroid系列的文档࿰…...

数据源及分层开发
数据源及分层开发 1. 使用Tomcat数据源 连接池工作原理: 连接池是由容器提供的,用来管理池中连接对象。 连接池自动分配连接对象并对闲置的连接进行回收。 数据源(DataSource): javax.sql.DataSource接口负责建立…...

气膜场馆照明设计:科技与环保的完美结合—轻空间
气膜场馆的照明设计,选用高效节能的400瓦LED灯具,结合现代节能技术,提供强大而均匀的光照。LED灯具在光效和寿命方面优势显著,不仅降低运营能耗,还有效减少碳排放,为绿色场馆建设贡献力量。 科学分布&…...

并行IO接口8255
文章目录 8255A芯片组成外设接口三个端口两组端口关于C口(★) 内部逻辑CPU接口 8255A的控制字(★)位控字(D70)方式选择控制字(D71) 8255A的工作方式工作方式0(基本输入/输…...

Level DB --- SkipList
class SkipList class SkipList 是Level DB中的重要数据结构,存储在memtable中的数据通过SkipList来存储和检索数据,它有优秀的读写性能,且和红黑树相比,更适合多线程的操作。 SkipList SkipList还是一个比较简单的数据结构&a…...

第二十二周机器学习笔记:动手深度学习之——线性代数
第二十周周报 摘要Abstract一、动手深度学习1. 线性代数1.1 标量1.2 向量1.3 矩阵1.4 张量1.4.1 张量算法的基本性质 1.5 降维1.5.1 非降维求和 1.6 点积1.6.1 矩阵-向量积1.6.2 矩阵-矩阵乘法 1.7 范数 总结 摘要 本文深入探讨了深度学习中的数学基础,特别是线性代…...

leetcode 50个简单和中等难度的题
简单难度题目(25个) 两数之和 (Two Sum)有效的括号 (Valid Parentheses)罗马数字转整数 (Roman to Integer)最长公共前缀 (Longest Common Prefix)合并两个有序链表 (Merge Two Sorted Lists)移除链表元素 (Remove Linked List E…...

多模态大模型(5)--LLaVA
人类通过如视觉、语言、听觉等多种渠道与世界互动,每个单独的渠道在表示和传达某些概念时都有其独特的优势,人工智能(AI)的一个核心愿景是开发一个能够有效遵循多模态视觉和语言指令的通用助手,与人类意图一致…...

Vue实训---3-element plus的使用与布局
1.引入ElementPlus ElementPlus官网指南:快速开始 | Element Plus 在我们的项目main.js文件中,加入红框里的内容: import { createApp } from vue import App from ./App.vue // 引入全局样式,是对样式的初始化 import "/a…...

TritonServer中加载模型,并在Gunicorn上启动Web服务调用模型
TritonServer中加载模型,并在Gunicorn上启动Web服务调用模型 一、TritonServer中加载模型1.1 搭建本地仓库1.2 配置文件1.3 服务端代码1.4 启动TritonServer二、Gunicorn上启动Web服务2.1 安装和配置Gunicorn2.2 启动Gunicorn三、调用模型四、性能优化与监控五、总结在深度学习…...

快速删除 node_modules 目录的集中方法
要快速删除 node_modules 目录,可以使用以下几种方法: 方法 1: 使用 rimraf 如果你在 Windows 上或者想要一个跨平台的解决方案,可以使用 rimraf 这个工具,它是 Node.js 版本的 rm -rf。 安装 rimraf: npm install …...

shell编程--if判断与for循环
shell编程与其他编程语言一样都有if判断与循环,今天了解一下if判断语句和for循环语句。 if判断语句讲解 我们写出一个if判断 a 1 b 2if [ "$a" -eq "$b" ]; thenecho "相等" elseecho "不相等" fi 在shell中-eq是表示…...

Makefile基础应用
1 使用场景 在Linux环境下,我们通常需要通过命令行来编译代码。例如,在使用gcc编译C语言代码时,需要使用以下命令。 gcc -o main main.c 使用这种方式编译代码非常吃力,每次调试代码都需要重新在命令行下重新编译,重复…...

计算机网络基础全攻略:探秘网络构建块(1/10)
一、计算机网络基础概念 计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路和通信设备连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统…...

SpringMVC-Day1
SpringMVC 1.SpringMVC介绍 springMVC是一种基于Java实现MVC模型的轻量级Web框架 优点: 使用简单,开发便捷(相较于Servelt) 灵活性强 使用SpringMVC技术开发web程序流程 创建web工程(Maven结构) 设置…...

【虚拟机】VMWare的CentOS虚拟机断电或强制关机出现问题
VMware 虚拟机因为笔记本突然断电故障了,开机提示“Entering emergency mode. Exit the shell to continue.”,如下图所示: 解决方法:输入命令: xfs_repair -v -L /dev/dm-0 注:报 no such file or direct…...
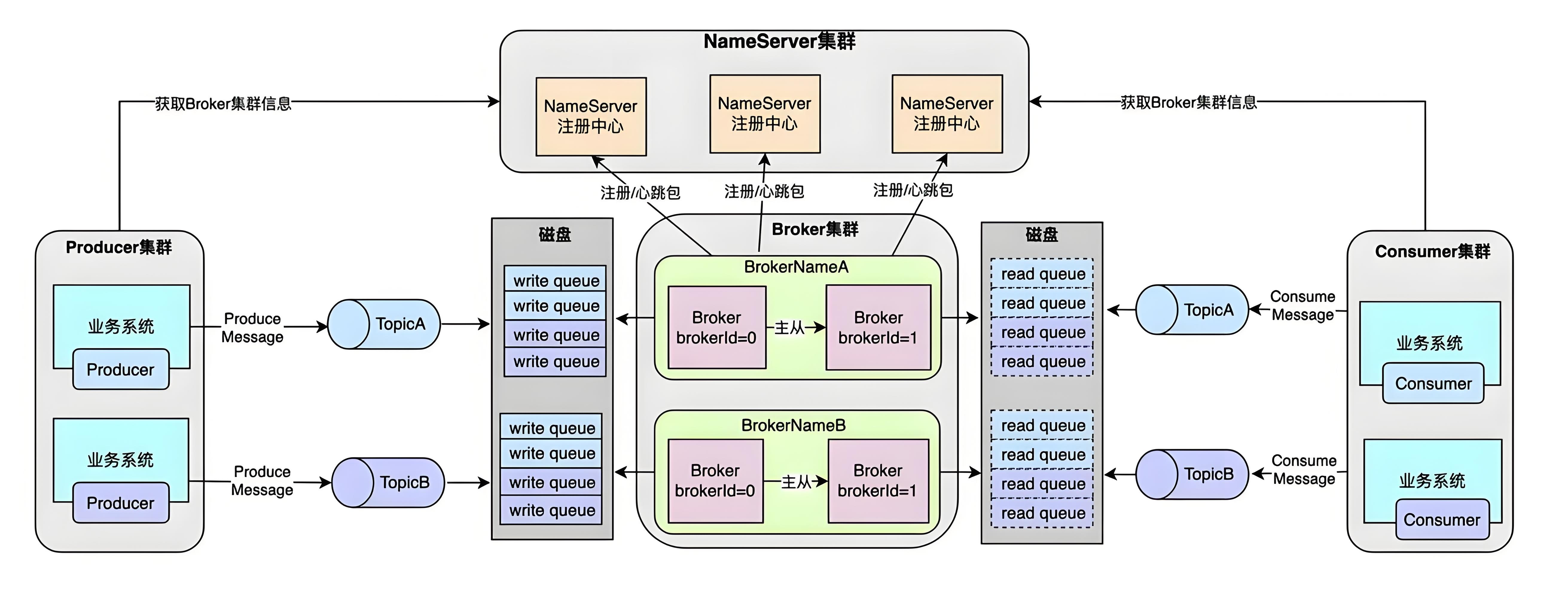
探索 RocketMQ:企业级消息中间件的选择与应用
一、关于RocketMQ RocketMQ 是一个高性能、高可靠、可扩展的分布式消息中间件,它是由阿里巴巴开发并贡献给 Apache 软件基金会的一个开源项目。RocketMQ 主要用于处理大规模、高吞吐量、低延迟的消息传递,它是一个轻量级的、功能强大的消息队列系统&…...

vue中v-if和v-for优先级
在Vue中,v-for的优先级高于v-if。这意味着在同一个元素上使用v-if和v-for时,v-for将首先被解析,然后是v-if。 下面是一个代码示例: <template><div><div v-for"item in items" v-if"item.isDispl…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...

DSP、FPGA、STM32大对决:谁才是嵌入式开发的“天选之子”?
在嵌入式开发的广阔天地里,DSP、FPGA 和 STM32(作为通用 MCU 的典型代表)可以说是三款绕不开的核心处理器。很多初学者甚至有一定经验的工程师在选择时都会陷入纠结:我的项目到底该选哪一个?为了帮你彻底理清思路&…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...

清华大学学位论文LaTeX模板:30分钟快速排版终极指南
清华大学学位论文LaTeX模板:30分钟快速排版终极指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 还在为论文格式烦恼吗?清华大学官方LaTeX模板thuthesis让…...