Flink-Source的使用
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源。
Flink 做为一款流式计算框架,它可用来做批处理,也可以用来做流处理,这个 Data Sources 就是数据的来源地。
flink在批/流处理中常见的source主要有两大类。
预定义Source
基于本地集合的source(Collection-based-source)
基于文件的source(File-based-source)
基于网络套接字(socketTextStream)
自定义Source

预定义Source演示
Collection [测试]--本地集合Source
在flink最常见的创建DataStream方式有四种:
l 使用env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式。
注意:类型要一致,不一致可以用Object接收,但是使用会报错,比如:env.fromElements("haha", 1);
![]()
源码注释中有写:
![]()
|使用env.fromCollection(),这种方式支持多种Collection的具体类型,如List,Set,Queue
l 使用env.generateSequence()方法创建基于Sequence的DataStream --已经废弃了
l 使用env.fromSequence()方法创建基于开始和结束的DataStream
一般用于学习测试时编造数据时使用
1.env.fromElements(可变参数);
2.env.fromColletion(各种集合);
3.env.fromSequence(开始,结束);
package com.bigdata.source;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class _01YuDingYiSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 各种获取数据的SourceDataStreamSource<String> dataStreamSource = env.fromElements("hello world txt", "hello nihao kongniqiwa");dataStreamSource.print();// 演示一个错误的//DataStreamSource<Object> dataStreamSource2 = env.fromElements("hello", 1,3.0f);//dataStreamSource2.print();DataStreamSource<Tuple2<String, Integer>> elements = env.fromElements(Tuple2.of("张三", 18),Tuple2.of("lisi", 18),Tuple2.of("wangwu", 18));elements.print();// 有一个方法,可以直接将数组变为集合 复习一下数组和集合以及一些非常常见的APIString[] arr = {"hello","world"};System.out.println(arr.length);System.out.println(Arrays.toString(arr));List<String> list = Arrays.asList(arr);System.out.println(list);env.fromElements(Arrays.asList(arr),Arrays.asList(arr),Arrays.asList(arr)).print();// 第二种加载数据的方式// Collection 的子接口只有 Set 和 ListArrayList<String> list1 = new ArrayList<>();list1.add("python");list1.add("scala");list1.add("java");DataStreamSource<String> ds1 = env.fromCollection(list1);DataStreamSource<String> ds2 = env.fromCollection(Arrays.asList(arr));// 第三种DataStreamSource<Long> ds3 = env.fromSequence(1, 100);ds3.print();// execute 下面的代码不运行,所以,这句话要放在最后。env.execute("获取预定义的Source");}
}
本地文件的案例:
package com.bigdata.source;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.io.File;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class _02YuDingYiSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 获取并行度System.out.println(env.getParallelism());// 讲第二种Source File类型的// 给了一个相对路径,说路径不对,老闫非要写,我咋办?// 相对路径,转绝对路径File file = new File("datas/wc.txt");File file2 = new File("./");System.out.println(file.getAbsoluteFile());System.out.println(file2.getAbsoluteFile());DataStreamSource<String> ds1 = env.readTextFile("datas/wc.txt");ds1.print();// 还可以获取hdfs路径上的数据DataStreamSource<String> ds2 = env.readTextFile("hdfs://bigdata01:9820/home/a.txt");ds2.print();// execute 下面的代码不运行,所以,这句话要放在最后。env.execute("获取预定义的Source");}
}Socket [测试]
socketTextStream(String hostname, int port) 方法是一个非并行的Source,该方法需要传入两个参数,第一个是指定的IP地址或主机名,第二个是端口号,即从指定的Socket读取数据创建DataStream。该方法还有多个重载的方法,其中一个是socketTextStream(String hostname, int port, String delimiter, long maxRetry),这个重载的方法可以指定行分隔符和最大重新连接次数。这两个参数,默认行分隔符是”\n”,最大重新连接次数为0。
提示:
如果使用socketTextStream读取数据,在启动Flink程序之前,必须先启动一个Socket服务,为了方便,Mac或Linux用户可以在命令行终端输入nc -lk 8888启动一个Socket服务并在命令行中向该Socket服务发送数据。Windows用户可以在百度中搜索windows安装netcat命令。
使用nc 进行数据的发送
yum install -y nc
nc -lk 8888 --向8888端口发送消息,这个命令先运行,如果先运行java程序,会报错!如果是windows平台:nc -lp 8888

代码演示:
//socketTextStream创建的DataStream,不论怎样,并行度永远是1
public class StreamSocketSource {public static void main(String[] args) throws Exception {//local模式默认的并行度是当前机器的逻辑核的数量StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();int parallelism0 = env.getParallelism();System.out.println("执行环境默认的并行度:" + parallelism0);DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);//获取DataStream的并行度int parallelism = lines.getParallelism();System.out.println("SocketSource的并行度:" + parallelism);SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] words = line.split(" ");for (String word : words) {collector.collect(word);}}});int parallelism2 = words.getParallelism();System.out.println("调用完FlatMap后DataStream的并行度:" + parallelism2);words.print();env.execute();}
}
以下用于演示:统计socket中的 单词数量,体会流式计算的魅力!
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class SourceDemo02_Socket {public static void main(String[] args) throws Exception {//TODO 1.env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//TODO 2.source-加载数据DataStream<String> socketDS = env.socketTextStream("bigdata01", 8889);//TODO 3.transformation-数据转换处理//3.1对每一行数据进行分割并压扁DataStream<String> wordsDS = socketDS.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2每个单词记为<单词,1>DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3分组KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4聚合SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedDS.sum(1);//TODO 4.sink-数据输出result.print();//TODO 5.execute-执行env.execute();}
}自定义数据源
SourceFunction:非并行数据源(并行度只能=1) --接口
RichSourceFunction:多功能非并行数据源(并行度只能=1) --类
ParallelSourceFunction:并行数据源(并行度能够>=1) --接口
RichParallelSourceFunction:多功能并行数据源(并行度能够>=1) --类 【建议使用的】
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Random;
import java.util.UUID;/*** 需求: 每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)* 要求:* - 随机生成订单ID(UUID)* - 随机生成用户ID(0-2)* - 随机生成订单金额(0-100)* - 时间戳为当前系统时间*/@Data // set get toString
@AllArgsConstructor
@NoArgsConstructor
class OrderInfo{private String orderId;private int uid;private int money;private long timeStamp;
}
// class MySource extends RichSourceFunction<OrderInfo> {
//class MySource extends RichParallelSourceFunction<OrderInfo> {
class MySource implements SourceFunction<OrderInfo> {boolean flag = true;@Overridepublic void run(SourceContext ctx) throws Exception {// 源源不断的产生数据Random random = new Random();while(flag){OrderInfo orderInfo = new OrderInfo();orderInfo.setOrderId(UUID.randomUUID().toString());orderInfo.setUid(random.nextInt(3));orderInfo.setMoney(random.nextInt(101));orderInfo.setTimeStamp(System.currentTimeMillis());ctx.collect(orderInfo);Thread.sleep(1000);// 间隔1s}}// source 停止之前需要干点啥@Overridepublic void cancel() {flag = false;}
}
public class CustomSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// 将自定义的数据源放入到env中DataStreamSource dataStreamSource = env.addSource(new MySource())/*.setParallelism(1)*/;System.out.println(dataStreamSource.getParallelism());dataStreamSource.print();env.execute();}}通过ParallelSourceFunction创建可并行Source
/*** 自定义多并行度Source*/
public class CustomerSourceWithParallelDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> mySource = env.addSource(new MySource()).setParallelism(6);mySource.print();env.execute();}public static class MySource implements ParallelSourceFunction<String> {@Overridepublic void run(SourceContext<String> ctx) throws Exception {ctx.collect(UUID.randomUUID().toString());/*如果不设置无限循环可以看出,设置了多少并行度就打印出多少条数据*/}@Overridepublic void cancel() {}}
}如果代码换成ParallelSourceFunction,每次生成12个数据,假如是12核数的话。
总结:Rich富函数总结 ctrl + o

Rich 类型的Source可以比非Rich的多出有:
- open方法,实例化的时候会执行一次,多个并行度会执行多次的哦(因为是多个实例了)
- close方法,销毁实例的时候会执行一次,多个并行度会执行多次的哦
- getRuntimeContext 方法可以获得当前的Runtime对象(底层API)
Kafka Source --从kafka中读取数据
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/datastream/kafka/
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version>
</dependency>创建一个topic1 这个主题:
cd /opt/installs/kafka3/bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic topic1通过控制台向topic1发送消息:
bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic topic1package com.bigdata.day02;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic1",new SimpleStringSchema(),properties);DataStreamSource<String> dataStreamSource = env.addSource(kafkaSource);// 以下代码跟flink消费kakfa数据没关系,仅仅是将需求搞的复杂一点而已// 返回true 的数据就保留下来,返回false 直接丢弃dataStreamSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String word) throws Exception {// 查看单词中是否包含success 字样return word.contains("success");}}).print();env.execute();}
}相关文章:
Flink-Source的使用
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源。 Flink 做为一款流式计算框架,它可用来做批处理,也可以用来做流处理,这个 Data Sources 就是数据的来源地。 flink在批/流处理中常见的source主要有两大类…...

C0031.在Clion中使用mingw编译器来编译opencv的配置方法
mingw编译器编译opencv库的配置方法...
)
Android——连接MySQL(Java版)
Android——连接MySQL(Java版) 目录: Android——连接MySQL(Java版)一、JDBC1、什么是JDBC2、载入JDBC3、创建JDBC的工具类 二、使用数据库 一、JDBC 1、什么是JDBC JDBC全称Java Database Connectivity,译为Java语言连接数据库,是sun公司制…...

「四」体验HarmonyOS端云一体化开发模板——工程目录结构与云侧工程一键部署AGC云端
关于作者 白晓明 宁夏图尔科技有限公司董事长兼CEO、坚果派联合创始人 华为HDE、润和软件HiHope社区专家、鸿蒙KOL、仓颉KOL 华为开发者学堂/51CTO学堂/CSDN学堂认证讲师 开放原子开源基金会2023开源贡献之星 「目录」 「一」HarmonyOS端云一体化概要 「二」体验HarmonyOS端云一…...

Kotlin:后端开发的新宠
在当今的软件开发领域,编程语言的选择对于项目的成功至关重要。Kotlin,一种由 JetBrains 开发的编程语言,近年来在后端领域逐渐崭露头角,展现出了广阔的应用前景。 一、Kotlin 简介 Kotlin 是一种基于 JVM(Java Virt…...

SSM全家桶 1.Maven
或许总要彻彻底底地绝望一次 才能重新再活一次 —— 24.11.20 maven在如今的idea中已经实现自动配置,不需要我们手动下载 一、Maven的简介和快速入门 Maven 是一款为 Java 项目构建管理、依赖管理的工具(软件),使用 Maven 可以自动化构建测试、打包和发…...

SpringBoot 集成 html2Pdf
一、概述: 1. springboot如何生成pdf,接口可以预览可以下载 2. vue下载通过bold如何下载 3. 一些细节:页脚、页眉、水印、每一页得样式添加 二、直接上代码【主要是一个记录下次开发更快】 模板位置 1. 导入pom包 <dependency><g…...

利用 Watchtower 自动监听并更新正在运行的 Docker 容器
本文首发于只抄博客,欢迎点击原文链接了解更多内容。 前言 大部分 VPS 和 NAS 用户或多或少都有用 Docker 来部署一些 Self-hosting 的服务,其中大部分项目都是开源项目,更新频率非常高,特别是一些版本 0.x 的项目,及…...

Nodejs开发仿马蜂窝旅游小程序API接口,服务器端开发,商家后台 Vue3+微信小程序+koa+mongodb+node.js
文章目录 🚀 开启您的互联网创业新篇章一、🔥 课程亮点:二、🌐 适合人群:学习这个课程后,您将会收获到三、旅游后台管理系统1.后台登录界面2.后台首页 四、前台旅游小程序1.首页展示2.目的地界面3.搜索功能…...

极限失控的大模型使电力系统面临的跨域攻击风险及应对措施
目录: 0 引言 1 就大模型发生极限失控的风险进行讨论的必要性、紧迫性 1.1 预训练的数据来源 1.2 能力涌现与不可解释性 1.3 大模型与物质世界的连接 1.4 数量效应与失控 1.5 大模型发生极限失控的风险 1.5.1 人工智能反叛所需要素能力的拼图 1.5.2 火种源…...

mybatis-plus方法无效且字段映射失败错误排查
问题: Invalid bound statement (not found): com.htlc.assetswap.mapper.WalletMapper.insert,并且select * 进行查询时带下划线的字段未成功映射。 排查: 1.检查WalletMapper接口,确保继承自BaseMapper 2.启用驼峰命名法映射。a…...
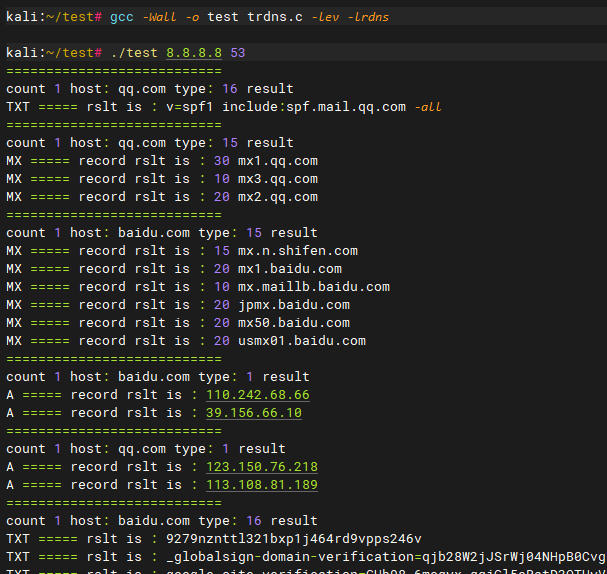
librdns一个开源DNS解析库
原文地址:librdns一个开源DNS解析库 – 无敌牛 欢迎参观我的个人博客:无敌牛 – 技术/著作/典籍/分享等 介绍 librdns是一个开源的异步多功能插件式的解析器,用于DNS解析。 源代码地址:GitHub - vstakhov/librdns: Asynchrono…...

Unity3D 逻辑服的Entity, ComponentData与System划分详解
前言 在Unity3D中,逻辑服(Entity, ComponentData和System)是一种非常高效的组件化设计模式,它可以帮助开发者更好地管理游戏中的实体和逻辑。本文将详细介绍Unity3D逻辑服的概念以及如何实现Entity、ComponentData和System的划分。 对惹,这…...

跟《经济学人》学英文:2024年11月23日这期 Why British MPs should vote for assisted dying
Why British MPs should vote for assisted dying A long-awaited liberal reform is in jeopardy in jeopardy:在危险中 jeopardy:美 [ˈdʒepərdi] 危险;危机;风险; 原文: THIS NEWSPAPER believes …...

基于阿里云服务器部署静态的website
目录 一:创建服务器实例并connect 二:本地文件和服务器share 三:关于IIS服务器的安装预配置 四:设置安全组 五:建站流程 六:关于备案 一:创建服务器实例并connect 创建好的服务器实例在云…...

【2024 Optimal Control 16-745】Ubuntu22.04 安装Julia
找不到Julia 内核 下载Julia curl -fsSL https://install.julialang.org | sh官网下载:Julia 安装 IJulia 打开 Julia REPL(在终端中输入 julia)并执行以下命令安装 IJulia: using Pkg Pkg.add("IJulia")这将为 Ju…...

nuget默认包管理格式:packages.config、packageReference区别
packages.config 和 PackageReference 是 NuGet 中的两种包管理格式,各有优劣,适用于不同的场景。以下是它们的详细对比: 1. packages.config 格式 这是 NuGet 的传统包管理格式,早期版本使用的默认方法。 特点 依赖声明文件&…...

element-plus教程:Input Number 数字输入框
一、基础用法 要使用Input Number数字输入框,只需要在<el-input-number>元素中使用v-model绑定变量即可。例如: <template><el-input-number v-model"value" /> </template><script lang"ts" setup>…...

M|横道世之介
rating: 8.0 豆瓣: 8.8 上映时间: “2013” 类型: M剧情爱情 导演: 冲田修一 Shichi Okita 主演: 冲田修一 Shichi Okita吉高由里子 Yuriko Yoshitaka 国家/地区: 日本 片长/分钟: 160分钟 M|横道世之介 横道世之介是一个热情、纯真的人,大家…...

借助算力云跑模型
算力平台:FunHPC | 算力简单易用 AI乐趣丛生 该文章只讲述了最基本的使用步骤(因为我也不熟练)。 【注】:进入平台,注册登录账号后,才能租用。学生认证+实名认证会有免费的算力资源࿰…...

XUnity.AutoTranslator:打破语言障碍,让Unity游戏实时翻译变得简单
XUnity.AutoTranslator:打破语言障碍,让Unity游戏实时翻译变得简单 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为看不懂外语游戏而烦恼吗?XUnity.AutoTranslat…...

工业智能化的时序选型指南:当数据底座遇见机器学习
随着工业 4.0 和物联网的深入发展,企业对时序数据的诉求已经发生了质的改变:“仅仅把海量数据存下来,并在大屏上画成折线图”已经远远无法满足高阶的业务需求。风机设备的预测性维护、流水线能耗的异常检测、智能电网的产量预测……这些高价值…...

黑龙江移远科技,是懂预算、懂场景、更懂服务的专业服务商
很多人误以为移远科技只是简单卖设备的贸易公司,实则不然。依托全品牌货源优势、极致性价比、五星贴心服务、专属方案定制,企业早已从传统销售商,升级为综合性通讯安防解决方案服务商,全方位解决客户采购难、选型难、售后难、预算…...

Java + Spring Boot 操作 Kafka 完整学习指南
前置条件:ZooKeeper 集群 Kafka 集群已启动(3个ZK节点 3个Broker) Broker 地址:172.17.0.7:9092, 172.17.0.7:9093, 172.17.0.7:9094第一阶段:原生 Java API 操作 Kafka目的:理解底层原理,Spr…...

Cowrie SSH蜜罐:协议层行为建模与威胁情报流水线
1. 为什么一个SSH蜜罐能比防火墙更早告诉你“有人在敲门” 你有没有过这种经历:某天凌晨三点,安全告警平台突然弹出一条“SSH暴力破解尝试激增”,点开一看——IP来自巴西、乌克兰、越南,每秒27次登录请求,用户名穷举了…...

告别卡顿:用微PE给旧电脑无损重装Win11,顺便教你用分区工具合理分配C盘空间
旧电脑焕新指南:用微PE无损重装Win11与智能分区实战 当你的旧电脑开始频繁卡顿、开机时间超过两分钟,甚至打开浏览器都要等待十几秒时,先别急着换新机。很多情况下,这只是系统长期使用积累的"垃圾"和不当分区导致的性能…...
)
012-java精品项目-淘客系统源码(安卓+IOS+php后端)
本文介绍了一个完整的淘宝客App开发项目,包含Android端、iOS端、后端服务和数据库系统。项目提供了详细的接口文档(淘宝客App接口文档.doc)和客户申请资料(淘宝客客户需要申请资料.doc),并包含完整的淘宝客…...

基于Simulink的四开关buck-boost变换器闭环仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

Claude Code 基础配置篇-三层配置体系详解
基础配置篇 —— Rules、Memory、Custom Instructions 三层配置体系详解系列导读: Claude Code 最让新手头疼的问题是"每次写的代码风格都不一样"、“总要重新解释项目架构”。本篇将彻底解决这个问题。通过建立三层配置体系,你可以让 Claude …...

Windows视觉效果关不关?电脑卡顿这样优化最快
Windows 系统具备视觉效果,其中半透明毛玻璃效果,窗口淡入淡出效果,任务栏缩略图预览效果,着实使桌面看上去颇为酷炫,然而在这些华丽特效的背后,实际上消耗着诸多系统资源,特别是内存以及显卡性…...