《操作系统 - 清华大学》4 -5:非连续内存分配:页表一反向页表
文章目录
- 1. 大地址空间的问题
- 2. 页寄存器( Page Registers )方案
- 3. 基于关联内存(associative memory )的反向页表(inverted page table)
- 4. 基于哈希(hashed)查找的反向页表
- 5. 小结
1. 大地址空间的问题
接下来再考虑另一个问题,单级页表或者多级页表的大小都和逻辑地址空间大小有对应关系,逻辑空间越大,其实意味着对应的页表就越多,有什么办法使得页表大小不与逻辑地址空间大小尽量没有那么大的关系,尽量与物理地址大小建立对应关系。这其实就是反向页表的想法,这个想法其实也是逐步产生的,看看反向页表有什么样特点。

如果是 64 位的寻址空间,它为此要建立页表,即使用了五级页表,它占的空间也是很大。那么能不能有一个办法,建立一个数据结构,它里面存的信息的总容量和逻辑地址空间的大小没有关系,如果没有关系,那逻辑空间的地址和物理空间的地址的映射关系怎么建立?
一级或者多级页表都是以逻辑页的页号做 index ,来索引一个大数组,那反过来想想,能不能以物理页做 index,来查找对应逻辑页的页号呢?
2. 页寄存器( Page Registers )方案
首先第一个办法是页寄存器的设计方案:

可以理解为有一个页寄存器数组,但是需要注意,它这里面 index 变了,index 不是页号,而是物理页号,页帧号,根据物理页号可以查出来它对应的页号是多少。因为物理页号里面存的内容是页表里的内容,有属性、对应的页号,需要注意正好反过来了,它是以页帧号为索引,页表项内容是页好,而前面讲的是以页号为索引,页表项内容是页帧号,正好是反过来的。

这种方式就使得本身寄存器的容量只与物理地址空间大小相关,而以逻辑地址空间的大小是无关的,可以限制寄存器的数量。但是有这个设计之后,很明显的一个问题,之前查找的时候是根据 page number 来查找 frame number,那如果建立了这么一个数据结构之后,怎么去找到 page number 所在的位置?
因为得到的只是以 frame number 为index 的数组,其实如果采取页寄存器,最大的问题在于怎么去把根据页号来找到页帧号的关系建联起来,这好像是一个问题。
但是它的好处是占的空间很少。
> 举个例子,如果物理内存大小是 4K * 4K = 16M ,物理空间有16M,页的 size 定义是4K,也意味着页帧数量一共有4K,这时候一个页寄存器占 8 B,意味着整个页寄存器的数量应该是8 * 4K = 32K,那在整个页地址空间中占的比例是 32K/16M,大约0.2%,确实可以看到这种方法的内存占用确实比较小。
但是它的问题在于怎么把这两者映射关系给建立好,光建立这么一个数据结构好像还是没法去有效根据页号找的页帧号?
3. 基于关联内存(associative memory )的反向页表(inverted page table)
那可以采取另一种办法,关联内存存储器:

关联存储器是一个很特殊的存储器,有这个存储器之后,可以并行地查找页号所对应的页帧号,就是它的 key 是页号,它的 value 是页帧号,就类似于 TLB,其实可以设计个 TLB 专门这么来放。
那么基于关联存储器这种设计,但是它存在一个很大的问题:

它这个开销太大,设计成本太大,关联存储器用到硬件逻辑很复杂,所以导致它这个容量不可能做很大。即使刚才说的16M 容量,其实对于关联存储器来说也是一个很大的开销,而且这个还需要放到 CPU 里面去,如果说放到外面的话,那其实还存在一个问题是内存访问的开销问题,这个是它的一个缺陷。
就是说它设计可以做得很好,但是具体实现的时候会发现成本代价,导致它无法做得特别大,这是它的一个问题。而且对于关联寄存器来说,一个大容量的关联存储器,其实它的访问速度还会下降。这两者使得这种方式不够实用,为此我们还需要新的方式。
4. 基于哈希(hashed)查找的反向页表
第三种方式就是基于哈希计算的一个反向列表:
 可以把刚才关联存储机制用另一种方法实现,把根据 page number 查找 frame number 过程用 hashtable 来实现,当然这里面需要注意什么呢?
可以把刚才关联存储机制用另一种方法实现,把根据 page number 查找 frame number 过程用 hashtable 来实现,当然这里面需要注意什么呢?
- hashtable 很明显是一个很简单的数学计算方法,哈希函数建好之后,只要给哈希函数输入一个值,它会得到一个输出,输入就是 page number,输出就应该是 frame number。哈希函数本身计算也可以用软件来计算,也可以用硬件来加速,为了能够提高效率,很明显应该用硬件加速方式,还需硬件帮助。
- 需要注意为了提高效率,可以把哈希函数再加一个参数,PID 当前运行程序的 ID,PID 加上 page number 可以很好地做 input, 来设计出比较简洁的哈希函数,算出对应的帧号 page number,那整个组织结构还是没变,从基于寄存器的组织变成了基于关联存储器的组织,再变成基于 hash table 的组织,这种方式可以有效地缓解完成映射开销。

- 当然相对而言这种方式还是有问题,问题在于查找的时候也许能查找,但是查找时候会出现哈希碰撞,比如对应一个 input,会存在多个 output。需要去了解对应的多个页帧号到底选的是哪一个?这是需要去了解的,在这里面也强调了为什么要通过程序的 ID 来缓解这种冲突。
- 这种方式还是需要把整个反向页表放到内存里面去,所以做哈希计算的时候也需要到内存里面去取数,其实说白了内存的开销还是很大,为此还需要有一个类似于 TLB 的机制来把它缓存起来,降低访问反向页表的时间。这是要考虑的两个问题。
目前来说这种机制在高端的 CPU 里面才存在。它的好处很明显,它不受制于逻辑地址空间或者虚拟空间大小的限制。它的容量可以说很小,因为它只和物理空间有关。前面也讲到了每一个运行的程序都需要有一个 page table,二级或者多级的页表,但对于这个而言,整个系统只要一个,因为它用的是物理页帧的页帧号来做 index, 限定这个表,而这个表和有多少个进程其实也没有关系。所以说相对而言,它占的空间比一级页表、二级页表要节省很多。但它是有代价,它需要有一种高速的哈希计算硬件处理机制,还有个高效的函数,以及还有解决冲突机制,才能够有效地使得整个访问效率得到保障,那这种机制就是有硬件有相应的软件配合,操作系统软件配合可以在空间和时间上取得一个比较好的结果。
5. 小结
非连续内存管理机制,这里面包含两种方法,一种方法是基于段映射机制,一种是基于分页映射机制,重点是分页。特别是怎么去有效地设计一个页表来提高页表的访问的效率和节省页表所占的空间。
相关文章:
《操作系统 - 清华大学》4 -5:非连续内存分配:页表一反向页表
文章目录 1. 大地址空间的问题2. 页寄存器( Page Registers )方案3. 基于关联内存(associative memory )的反向页表(inverted page table)4. 基于哈希(hashed)查找的反向页表5. 小结 1. 大地址空间的问题 …...

志愿者小程序源码社区网格志愿者服务小程序php
志愿者服务小程序源码开发方案:开发语言后端php,tp框架,前端是uniapp。 一 志愿者端-小程序: 申请成为志愿者,志愿者组织端进行审核。成为志愿者后,可以报名参加志愿者活动。 志愿者地图:可以…...

Java语言编程,通过阿里云mongo数据库监控实现数据库的连接池优化
一、背景 线上程序连接mongos超时,mongo监控显示连接数已使用100%。 java程序报错信息: org.mongodb.driver.connection: Closed connection [connectionId{localValue:1480}] to 192.168.10.16:3717 because there was a socket exception raised by…...

使用ufw配置防火墙,允许特定范围IP访问
文章目录 1. 安装 UFW(如果尚未安装)2. 允许特定 IP 地址访问 22 端口3. 允许特定子网访问 22 端口4. 启用 UFW5. 检查 UFW 状态6. 重新加载 UFW(如果需要)7. 删除规则(如果需要) 在ubuntu上使用 ufw&#…...

实现 UniApp 右上角按钮“扫一扫”功能实战教学
实现 UniApp 右上角按钮“扫一扫”功能实战教学 需求 点击右上角扫一扫按钮(onNavigationBarButtonTap监听),打开扫一扫页面(uni.scanCode) 扫描后,以网页的形式打开扫描内容(web-view组件),限制只能浏览带有执行域名的网站,例如…...

【2024亚太杯亚太赛APMCM C题】数学建模竞赛|宠物行业及相关产业的发展分析与策略|建模过程+完整代码论文全解全析
第一个问题是:请基于附件 1 中的数据以及你的团队收集的额外数据,分析过去五年中国宠物行业按宠物类型的发展情况。并分析中国宠物行业发展的因素,预测未来三年中国宠物行业的发展。 第一个问题:分析中国宠物行业按宠物类型的发展…...

ubtil循环函数调用
什么是until until循环是一种控制流结构。它与while循环相反,while循环是在条件为真时执行循环体,而until循环是在条件为假时执行循环体,直到条件为真时才停止循环。 until代码示例: i0 do until [ ! $i -lt 10 ] echo $…...

使用EFK收集k8s日志
首先我们使用EFK收集Kubernetes集群中的日志,本次实验讲解的是在Kubernetes集群中启动一个Elasticsearch集群,如果企业内已经有了Elasticsearch集群,可以直接将日志输出至已有的Elasticsearch集群。 文章目录 部署elasticsearch创建Kibana创建…...
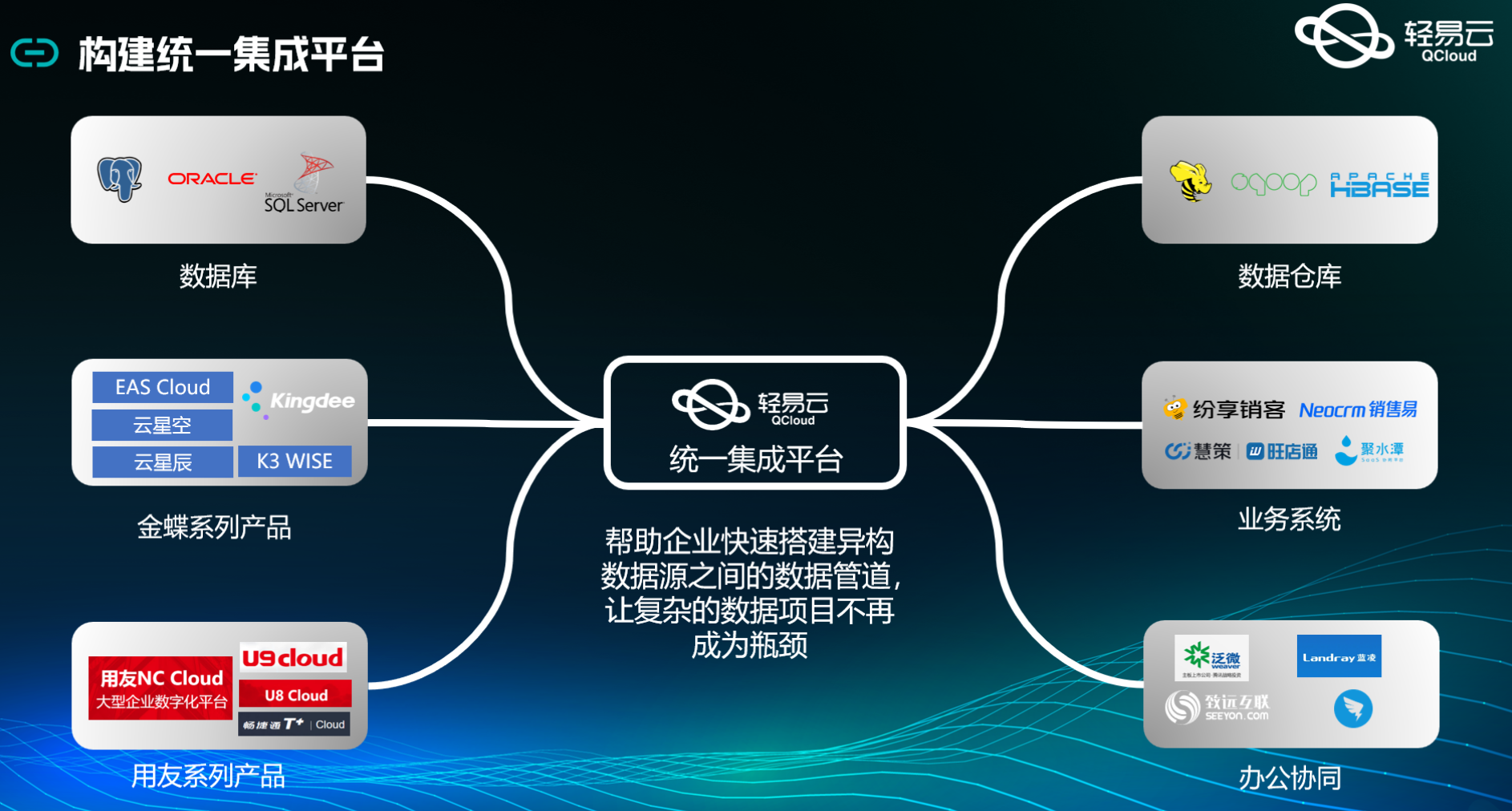
聚水潭与MySQL数据集成案例分享
聚水潭数据集成到MySQL的技术案例分享 在现代数据驱动的业务环境中,如何高效、可靠地实现不同系统之间的数据对接成为企业关注的焦点。本次案例将详细介绍如何通过轻易云数据集成平台,将聚水潭的数据无缝集成到MySQL数据库中,实现从“聚水谭…...

Python 版本的 2024详细代码
2048游戏的Python实现 概述: 2048是一款流行的单人益智游戏,玩家通过滑动数字瓷砖来合并相同的数字,目标是合成2048这个数字。本文将介绍如何使用Python和Pygame库实现2048游戏的基本功能,包括游戏逻辑、界面绘制和用户交互。 主…...

SpringCloud框架学习(第四部分:Gateway网关)
目录 十一、Gateway新一代网关 1.概述 2.Gateway三大核心 3.工作流程 4.入门配置 5.路由映射 (1)8001 外部添加网关 (2)服务间调用添加网关 (3)存在问题 6.Gateway高级特性 (1&#x…...
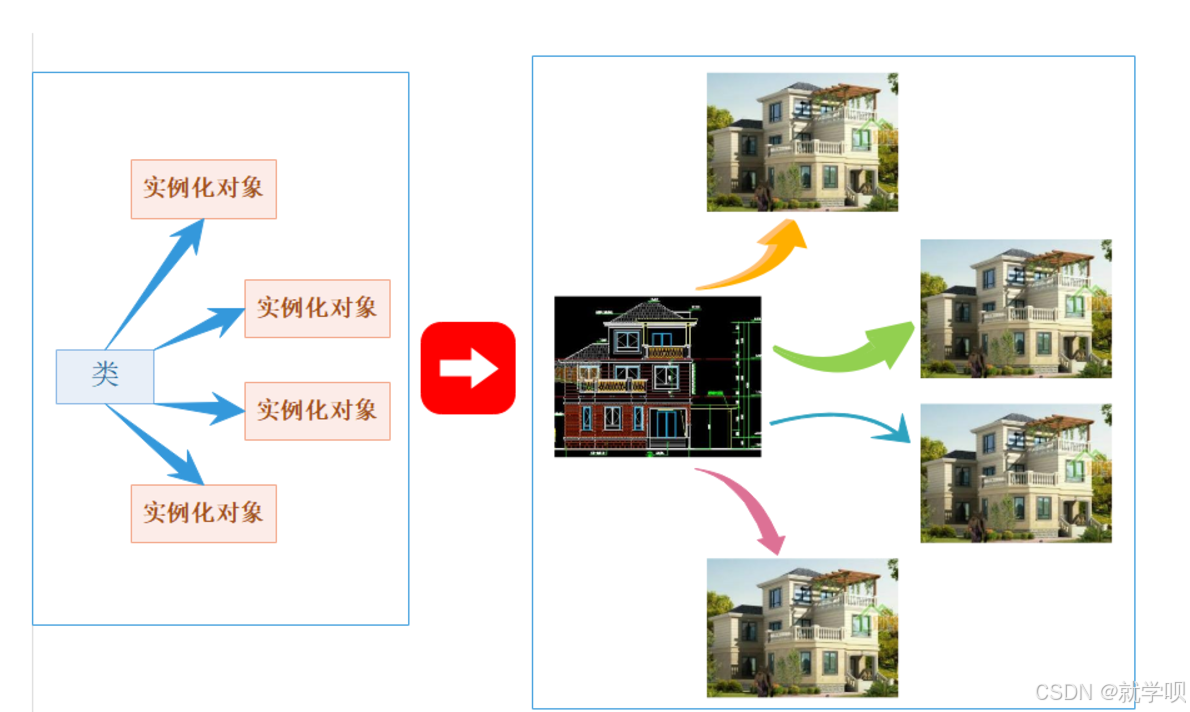
C++ 类和对象 (上 )
学习本身就是一件很快乐的事情 一. 面向对象和面向过程 我们在学习计算机的过程中经常会听到xxx是一门面向对象的语言 xxx是一门面向过程的语言 那么到底什么是面向对象 什么是面向过程呢? 简单介绍下 面向过程 面向过程关注的是过程 分析出求解问题的步骤&…...
)
HAProxy面试题及参考答案(精选80道面试题)
目录 什么是 HAProxy? HAProxy 主要有哪些功能? HAProxy 的关键特性有哪些? HAProxy 的主要功能是什么? HAProxy 的作用是什么? 解释 HAProxy 在网络架构中的作用。 HAProxy 与负载均衡器之间的关系是什么? HAProxy 是如何实现负载均衡的? 阐述 HAProxy 的四层…...
探索PyCaret:一个简化机器学习的全栈库
探索PyCaret:一个简化机器学习的全栈库 机器学习领域充满了挑战,从数据预处理、特征工程到模型训练与评估,再到模型部署。对于数据科学初学者或者时间有限的开发者,这一流程可能显得繁琐且复杂。幸运的是,PyCaret 提供…...

英语写作中“联系、关联”associate correlate 及associated的用法
似乎是同义词的associate correlate 实际上意思差别明显,associate 是人们把两者联系在一起(主观联系),而correlate 指客观联系。 例如: We always associate sports with health.(我们总是将运动和健康联…...

深度学习之目标检测的技巧汇总
1 Data Augmentation 介绍一篇发表在Big Data上的数据增强相关的文献综述。 Introduction 数据增强与过拟合 验证是否过拟合的方法:画出loss曲线,如果训练集loss持续减小但是验证集loss增大,就说明是过拟合了。 数据增强目的 通过数据增强…...
【Flask+Gunicorn+Nginx】部署目标检测模型API完整解决方案
【Ubuntu 22.04FlaskGunicornNginx】部署目标检测模型API完整解决方案 文章目录 1. 搭建深度学习环境1.1 下载Anaconda1.2 打包环境1.3 创建虚拟环境1.4 报错 2. 安装flask3. 安装gunicorn4. 安装Nginx4.1 安装前置依赖4.2 安装nginx4.3 常用命令 5. NginxGunicornFlask5.1 ng…...

Spark核心组件解析:Executor、RDD与缓存优化
Spark核心组件解析:Executor、RDD与缓存优化 Spark Executor Executor 是 Spark 中用于执行任务(task)的执行单元,运行在 worker 上,但并不等同于 worker。实际上,Executor 是一组计算资源(如…...

“AI玩手机”原理揭秘:大模型驱动的移动端GUI智能体
作者|郭源 前言 在后LLM时代,随着大语言模型和多模态大模型技术的日益成熟,AI技术的实际应用及其社会价值愈发受到重视。AI智能体(AI Agent)技术通过集成行为规划、记忆存储、工具调用等机制,为大模型装上…...

离散数学【关系】中的一些特殊关系
在数学中,关系是描述集合之间元素间关系的方式。以下是对一些常见关系的详细分析及举例: 1. 空关系 (Empty Relation) 空关系是指在一个集合中,没有任何元素之间存在关系。即对于集合中的所有元素,空关系都不包含任何有序对。 …...

Google I/O 2026 | 开发者主题演讲精华集锦
作者 / Google I/O 团队AI 已不再只是提供辅助,而是迈向了能够在整个工作流中独立处理复杂任务的智能体阶段。在今年的 I/O 大会上,我们发布了 Gemini 3.5 系列模型,并升级了我们的 "智能体优先" 式开发平台 Antigravity࿰…...

深度学习解码星际湍流:从光谱图估计MHD模式能量分数
1. 项目概述与核心价值在星际介质(ISM)的研究中,磁流体动力学(MHD)湍流扮演着能量传输、物质混合和结构形成的“发动机”角色。它并非一团混沌,而是可以分解为三种具有不同物理特性的基本模式:阿…...

工厂适合做跨境独立站吗?5个判断标准
工厂适合做跨境独立站吗?5个判断标准对很多制造企业来说,跨境电商独立站确实是一条值得认真考虑的出海路径。但它并不适合所有工厂一上来就重投入。要不要做独立站,关键不在于“别人都在做”,而在于产品是否适合、预算是否可控、团…...

3个关键维度重新定义工作价值:科学量化你的职业选择
3个关键维度重新定义工作价值:科学量化你的职业选择 【免费下载链接】worth-calculator Calculating the actual value of your job beyond just salary 项目地址: https://gitcode.com/gh_mirrors/wo/worth-calculator 你是否曾在深夜加班时思考,…...

Android性能优化深度解析:从理论到实践
在Android开发领域,性能优化是确保应用流畅运行和用户体验的关键。作为一名安卓开发工程师,掌握性能优化技术不仅能提升应用质量,还能在面试和实际工作中脱颖而出。本文将以性能优化为核心领域,深入探讨其理论、工具和实践方法,并提供代码示例和常见面试问题及答案。文章内…...

告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略
告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略在虚幻引擎5(UE5)开发流程中,打包环节往往是开发者体验的分水岭——顺畅的打包过程能保持创作心流,而频繁的报错和漫长等待则会严重消耗开发热情。本文将…...

FModel深度指南:UE5.3+ Pak解包与Nanite资源导出实战
1. 这不是“下载器”,而是一把解构现代游戏资产的手术刀很多人第一次听说FModel,是在某个游戏论坛里看到一句轻描淡写的“用FModel扒资源”。于是下载、双击、拖进exe——结果卡在“Loading Pak Files”十分钟不动,或者导出一堆黑屏贴图、错位…...

2026保姆级免费在线去水印教程:想保存无水印视频?用这些方法就够了
你是不是也遇到过这样的尴尬:刷到一个特别喜欢的视频想保存下来做素材,结果画面中间杵着大大的水印;或者朋友发来一张好图,角落的Logo怎么都去不掉?自己研究半天,又是下软件又是找教程,结果要么…...

[开源] 急诊分诊能力闯关训练系统:面向护士与临床教学的可视化季票式技能成长平台
本项目是专为急诊科护士、进修生及实习生设计的分诊判断力训练工具,以「病例闯关 季票进度 多维反馈」为核心机制,将抽象的分诊能力拆解为20个难度递进的实战关卡。我们不做泛泛而谈的题库,而是用时间压力、星级评价、连胜激励和薄弱点定位…...

【审计专栏】【财务领域】第二十八篇 全球/中国货币流动中离钱最近的岗位01
全球/中国货币流动和流入/流出最近的距离相关信息,特别关注“离钱最近的岗位”,按照指定表格格式输出如下: 编号 类型 国家 省/市/区县 行业 公司类型 岗位类型【含管理岗/基层岗位】 离货币收入/投放的距离指标和偏差指数和期望/方差 指标类型 模型逐步推理思考的…...