在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?
大家好,我是锋哥。今天分享关于【在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?】面试题。希望对大家有帮助;

在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?
在 Elasticsearch 中,倒排索引(Inverted Index)是查询高效性的核心。倒排索引将每个词(token)映射到包含该词的文档列表,这使得 Elasticsearch 能够迅速确定哪些文档包含某个查询词。具体来说,当你执行一个搜索请求时,Elasticsearch 会查找倒排索引来定位包含查询词的文档。以下是如何在 Elasticsearch 中根据一个词找到对应的倒排索引的详细步骤:
1. 文档和字段的索引结构
Elasticsearch 是基于 Lucene 的,索引的核心是倒排索引。在 Elasticsearch 中,文档是以 JSON 格式存储的,每个文档可以包含多个字段,每个字段又可以有不同的数据类型(如 text、keyword、date 等)。通常,文本字段(如文章的标题或正文)会被分词(tokenize),每个词或词组都会生成一个 token。
当你向 Elasticsearch 索引文档时,系统会自动分析每个字段的内容,并为该字段生成倒排索引。
2. 倒排索引的结构
倒排索引的基本构成如下:
- 术语表(Terms): 倒排索引的术语表(terms)记录了所有出现过的词(token)。这些词就是你查询时使用的关键词。
- 倒排列表(Posting List): 对于术语表中的每个词,会有一个倒排列表,倒排列表包含了所有包含该词的文档 ID(以及可能的位置信息)。倒排列表的形式通常是一个文档 ID 的列表,但有时还会包含该词在文档中出现的频率或位置等额外信息。
例如,假设我们有以下三篇文档:
- 文档 1: "Elasticsearch is a search engine"
- 文档 2: "Elasticsearch powers search solutions"
- 文档 3: "Search engines are powerful tools"
在 Elasticsearch 中,首先会进行分词处理(假设使用默认的标准分词器),得到以下词汇:
- 文档 1:
["elasticsearch", "is", "a", "search", "engine"] - 文档 2:
["elasticsearch", "powers", "search", "solutions"] - 文档 3:
["search", "engines", "are", "powerful", "tools"]
然后,这些词汇会被放入倒排索引中,倒排索引的基本形式可能如下:
- "elasticsearch" → [文档 1, 文档 2]
- "search" → [文档 1, 文档 2, 文档 3]
- "engine" → [文档 1, 文档 3]
- "powers" → [文档 2]
- "solutions" → [文档 2]
- "engines" → [文档 3]
- "are" → [文档 3]
- "powerful" → [文档 3]
- "tools" → [文档 3]
3. 倒排索引的构建过程
当你向 Elasticsearch 插入文档时,索引会经历以下过程来创建倒排索引:
-
文本分析:
- 每个字段(特别是
text类型字段)会经过 分析器(analyzer)处理。分析器会首先对文本进行 分词,即将文本内容切分成独立的单词(tokens)。 - 分词之后,文本还会经过 标准化处理,如将大写字母转换为小写字母、去除停用词(例如 "and"、"the" 等)等,具体处理方式由分析器的配置决定。
- 每个字段(特别是
-
构建倒排索引:
- 分词后的每个 token 会被索引,并与对应的文档 ID 关联。例如,如果某个词出现在多个文档中,该词的倒排列表就会记录所有包含该词的文档 ID。
- Elasticsearch 将倒排索引按词语存储到一个词典(或称术语表)中。
4. 查询时的倒排索引查找
当你发起查询时,Elasticsearch 会通过以下步骤根据查询词找到倒排索引并快速定位相关文档:
4.1 查询解析
假设你提交了以下查询:
{"query": {"match": {"message": "search engine"}}
}
查询中的 "search engine" 会被分词为 ["search", "engine"]。
4.2 查找倒排索引
Elasticsearch 会在倒排索引中查找每个分词:
- 查找 "search":根据倒排索引,Elasticsearch 查到
"search"出现在文档 1、文档 2 和文档 3 中。 - 查找 "engine":根据倒排索引,Elasticsearch 查到
"engine"出现在文档 1 和文档 3 中。
4.3 合并结果
然后,Elasticsearch 会将这两个查询的结果合并。对于 match 查询,默认的行为是 交集:即返回同时包含 "search" 和 "engine" 的文档。因此,最终匹配的文档是文档 1 和文档 3。
4.4 计算相关性
Elasticsearch 还会根据每个文档中查询词的出现频率、文档长度等因素计算相关性分数(score)。分数较高的文档会排在前面。
5. 倒排索引的优化
倒排索引的结构本身是高度优化的,以支持高效的查询:
- 压缩存储: 倒排索引会进行压缩存储,以节省空间。常见的压缩方式包括 delta 编码 和 前缀编码,这些方法可以显著减小索引的存储空间。
- 位置存储: 对于一些特殊类型的查询(如短语查询、近似查询),Elasticsearch 还会记录词语在文档中的 位置,以支持精确的短语匹配。
总结
Elasticsearch 使用倒排索引来高效地支持搜索操作。每个查询词在倒排索引中都有一个倒排列表,列表中包含了包含该词的所有文档 ID。查询时,Elasticsearch 通过查找这些倒排列表,快速找出相关文档,然后根据相关性进行排序和过滤。通过使用倒排索引,Elasticsearch 能够在海量数据中快速定位到匹配的文档,从而提供高效的搜索性能。
相关文章:
在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?
大家好,我是锋哥。今天分享关于【在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?】面试题。希望对大家有帮助; 在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的? 在 Elasticsearch 中…...
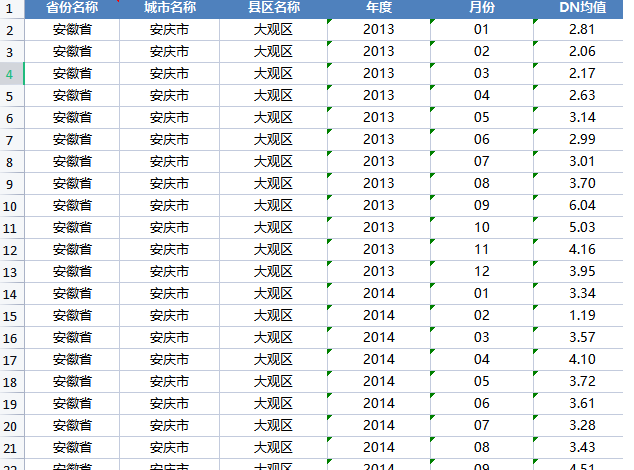
1992-2021年 各省市县经过矫正的夜间灯光数据(GNLD、VIIRS)区域汇总:省份、城市、区县面板数据
1992-2021年 各省市县经过矫正的夜间灯光数据(GNLD、VIIRS)区域汇总:省份、城市、区县面板数据 .r.rar https://download.csdn.net/download/2401_84585615/90001905 从1992年至2021年,中国各省份、城市及区县的夜间灯光数据经过…...

linux实战-黑链——玄机靶场
黑链的特征: 隐藏链接:黑链通常隐藏在网站页面中,使用CSS、JavaScript或其他手段使其对普通用户不可见,但仍然能被搜索引擎爬虫检测到。恶意内容:这些链接指向的内容可能包含恶意软件、钓鱼页面或其他不良内容&#x…...

鸿蒙NEXT开发案例:字数统计
【引言】 本文将通过一个具体的案例——“字数统计”组件,来探讨如何在鸿蒙NEXT框架下实现这一功能。此组件不仅能够统计用户输入文本中的汉字、中文标点、数字、以及英文字符的数量,还具有良好的用户界面设计,使用户能够直观地了解输入文本…...

uniapp vue2项目迁移vue3项目
uniapp vue2项目迁移vue3项目,必须适配的部分 一、main.js 创建应用实例 // 之前 - Vue 2 import Vue from vue import App from ./App Vue.config.productionTip false // vue3 不再需要 App.mpType app // vue3 不再需要 const app new Vue({ ...App }) …...

16.C++STL 3(string类的模拟,深浅拷贝问题)
⭐本篇重点:string类的模拟,自己实现一个简单的string类 ⭐本篇代码:c学习/05.string类的学习 橘子真甜/c-learning-of-yzc - 码云 - 开源中国 (gitee.com) 目录 一. 经典string类的模拟 1.1 深浅拷贝问题 1.2 使用深拷贝完成经典string类的…...
神经网络10-Temporal Fusion Transformer (TFT)
Temporal Fusion Transformer (TFT) 是一种专为时序数据建模而设计的深度学习模型,它结合了Transformer架构和其他技术,旨在有效地处理和预测时序数据中的复杂模式。TFT 于 2020 年由 Google Research 提出,旨在解决传统模型在时序预测中的一…...

“iOS profile文件与私钥证书文件不匹配”总结打ipa包出现的问题
目录 文件和证书未加载或特殊字符问题 证书过期或Profile文件错误 确认开发者证书和私钥是否匹配 创建证书选择错误问题 申请苹果 AppId时勾选服务不全问题 总结 在上线ios平台的时候,在Hbuilder中打包遇见了问题,生成ipa文件时候,一…...

《图像梯度与常见算子全解析:原理、用法及效果展示》
简介:本文深入探讨图像梯度相关知识,详细介绍图像梯度是像素灰度值在不同方向的变化速度,并以 “pig.JPG” 图像为例,通过代码展示如何选取图像部分区域并分析其像素值以论证图像梯度与边缘信息的关联。接着全面阐述了 Sobel 算子,…...

【c++篇】:探索c++中的std::string类--掌握字符串处理的精髓
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨文章所属专栏:c篇–CSDN博客 文章目录 前言一.std::string对象的创建二.std::string对象的访问三.std::str…...

LlamaIndex ollama 搭建本地RAG应用,建立本地知识库
目录 简介安装前的准备下载ollama创建llamaindex conda环境,为后面编码作准备 环境变量迁移ollama到其他盘运行ollama方式一方式二禁止ollama开机自启动运行第一个模型 Chatbox聊天下载Chatbox配置ollama地址和模型验证 建立自身特定知识数据搭配大语言模型创建项目…...

draggable的el-dialog实现对话框标题可以选择
请看图 这个对话框使用了el-dialog并且draggable属性设置成了true,所以标题栏这里就可以拖动,现在用户想选中标题栏的文本进而复制。我看到这个需求头都大了。 我能想到的方案有三个:1. 取消draggable为true 2. 标题文案后面加一个复制按钮 …...

2024年Android面试总结
2024年Android面试总结 1.动画类型有哪些?插值器原理? 2.StringBuffer和StringBuilder区别? 3.jvm内存模型? 4.线程池7大核心参数及原理? 5.Android多进程通信方式有哪些?各自的优缺点? 6…...

树莓派3:64位系统串口(UART)使用问题的解决方法
前言 当我们要使用串口进行zigbee的短距离通信时,发现无法使用串口. 原因 树莓派3bCPU内部有两个串口,一个硬件串口(就是我们平时使用的UART),还有一个迷你串口(mini-uart),在老版本的树莓派中把硬件串口分配在GPIO上,可以单独使用.但是在新的树莓派中官方把硬件串口给了蓝牙…...
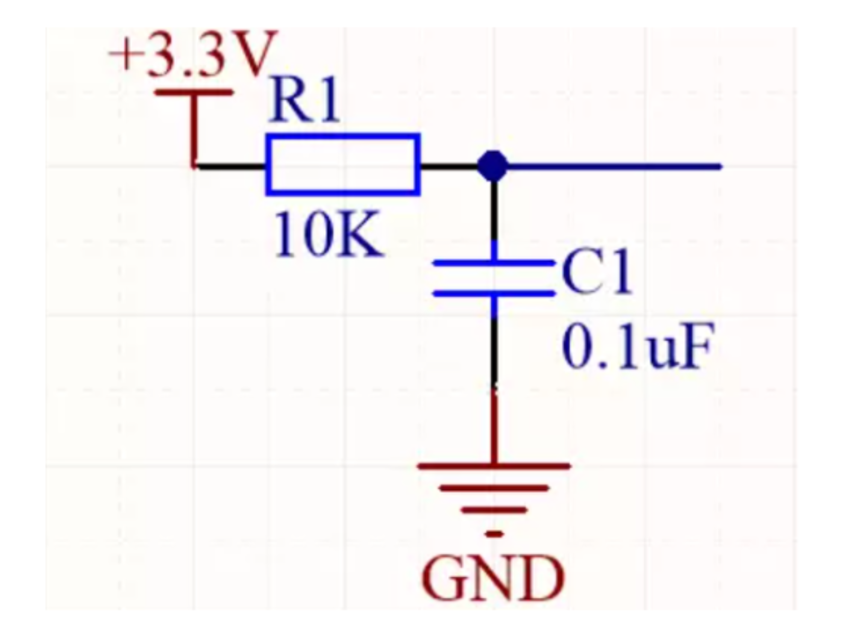
SemiDrive E3 硬件设计系列---唤醒电路设计
一、前言 E3 系列芯片是芯驰半导体高功能安全的车规级 MCU,对于 MCU 的硬件设计部分,本系列将会分模块进行讲解,旨在介绍 E3 系列芯片在硬件设计方面的注意事项与经验,本文主要讲解 E3 硬件设计中唤醒电路部分的设计。 二、RTC 模…...

淘宝接口高并发采集核心要点解读,开启电商数据智能应用新纪元
一、引言 在电商蓬勃发展的今天,淘宝作为全球知名的电商巨头,其平台上的数据犹如一座蕴藏无限价值的宝藏。准确且高效地采集淘宝接口数据,并通过高并发技术实现大规模数据获取,对于电商企业的精准营销、市场趋势分析、竞品监测以及…...

C#里怎么样快速使用LINQ实现查询?
C#里怎么样快速使用LINQ实现查询? 在C#里使用LINQ,是一个方便的功能, 不过,要学会使用这部分的功能,需要比较多的学习时间,否则,使用起就比较难。 因为它的表现方式,与编程语言通用的功能,还是差别比较大。 当数据量比较小,没有特定的顺序时,使用LINQ访问会比较好…...

2024新版微软edge浏览器输入百度网址时自动补全tn=68018901……小尾巴的解决
以前一直是Windows11 21h2版本,浏览器内输入baidu不会自动补全tnxx的百度推广小尾巴。然后前几天在BIOS内开启了tpm2.0,升级Windows11到了24h2版本。 发现在edge浏览器内只要输入b,就会自动补全为baidu.com?tnXXX的这么一个百度推广形式。开…...

uni-app打包H5自定义微信分享
1、配置分享信息 修改uni-app的index.html,添加Open Graph(OG)标签来配置分享信息。 <!DOCTYPE html> <html lang="en"><head><meta charset="UTF-8" /><meta name="description" content="标题"/>…...

大模型专栏--大模型应用场景
紧接着第一篇,什么是大模型,这篇文章讨论一下大模型的应用场景和应用方式有哪些? 基础使用 随着 GPT 的出现,AI 大模型已经越来越多得出现在日常生活和学术研究,工作中。 按照使用方向有以下几种: 自然语…...

Taotoken 用量看板如何帮助个人开发者清晰掌握月度 AI 支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 用量看板如何帮助个人开发者清晰掌握月度 AI 支出 对于独立开发者和小型项目团队而言,将大模型能力集成到产品…...

告别环境配置焦虑:用 Bochs 2.6.10 在 Ubuntu 上快速搭建你的第一个‘自制操作系统’实验台
从零构建操作系统实验环境:Bochs 2.6.10在Ubuntu下的实战指南当我在大学第一次尝试编写引导扇区代码时,花了整整三天时间才让屏幕上显示出"Hello World"。这段经历让我深刻意识到:环境配置的复杂度往往比算法本身更令人崩溃。本文将…...

记忆学习导向的高速运动感知图像的去模糊及目标识别【附数据】
✨ 长期致力于深度卷积网络、长短期记忆网络、相机高速运动感知、运动去模糊、运动目标识别研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)融合DCNN与…...

如何高效使用NHSE:动物森友会存档编辑器的完整专业指南
如何高效使用NHSE:动物森友会存档编辑器的完整专业指南 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否厌倦了在《集合啦!动物森友会》中花费数百小时收集稀有物品&a…...

从零开始将Taotoken接入静态网站实现动态AI交互
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始将Taotoken接入静态网站实现动态AI交互 1. 场景与核心思路 对于使用 Hugo、Hexo、VuePress 等工具生成的静态网站&#x…...

机器学习在供水管网泄漏检测与定位中的实践与挑战
1. 项目概述:当机器学习遇见地下“血管”城市地下的供水管网,就像人体的血管网络,日夜不息地输送着生命之源。然而,与人体血管会老化、破裂一样,这些埋藏在地下的管道也时刻面临着泄漏的风险。传统的检漏方法ÿ…...

物理视角下的神经网络:从表达性、统计到动力学的统一理解框架
1. 从物理视角看神经网络:为什么我们需要新的理解框架 如果你和我一样,在实验室里泡了十几年,从早期的多层感知机一路跟到现在的Transformer和扩散模型,你可能会有一个强烈的感受:我们手里的工具越来越强大,…...

Windows远程桌面免费解锁指南:家庭版也能享受多用户并发连接
Windows远程桌面免费解锁指南:家庭版也能享受多用户并发连接 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾经因为Windows家庭版无法使用远程桌面而烦恼?或者需要多人同时访问同一…...

驳AGI学习不可行论:数据分布与归纳偏置是理论证明的关键
1. 项目概述:当复杂性理论遇上AGI学习的“不可能性”证明最近在AI理论圈子里,一篇题为《Reclaiming AI as a theoretical tool for cognitive science》的论文(简称[VRGA24])引起了不小的波澜。这篇论文的核心主张相当大胆&#x…...

量子软件不稳定测试检测:基于机器学习的自动化解决方案
1. 量子软件测试中的“幽灵”:不稳定测试的挑战与机遇在量子软件开发的日常工作中,最让人头疼的莫过于那些“薛定谔的测试”——你永远不知道下一次运行它会通过还是失败。这就是不稳定测试(Flaky Tests),它们像幽灵一…...