LlamaIndex ollama 搭建本地RAG应用,建立本地知识库
目录
- 简介
- 安装前的准备
- 下载ollama
- 创建llamaindex conda环境,为后面编码作准备
- 环境变量
- 迁移ollama到其他盘
- 运行ollama
- 方式一
- 方式二
- 禁止ollama开机自启动
- 运行第一个模型
- Chatbox聊天
- 下载Chatbox
- 配置ollama地址和模型
- 验证
- 建立自身特定知识数据搭配大语言模型
- 创建项目环境
- 代码
- 运行结果
- streamlit应用
- 本文所使用的源码地址
- 参考
简介
- ollama:本地运行大型语言模型的工具软件。用户可以轻松下载、运行和管理各种开源 LLM。降低使用门槛,用户能快速启动运行本地模型。
- LlamaIndex:用来连接大语言模型和外部数据的框架(外部数据指自身领域的特定知识),它将两者结合起来,提升回答的准确性。
安装前的准备
下载ollama
- ollama官方下载地址 https://ollama.com/download ,目前最新版是0.4.2。

创建llamaindex conda环境,为后面编码作准备
- 为啥要用conda呢?
后面要编码,考虑不同项目依赖的python版本可能不同,用conda来管理,可以快速新增python环境,如果环境搞砸了,用命令删除也很方便。
- conda下载地址 https://www.anaconda.com/download/success

环境变量
| 参数 | 标识与配置 |
|---|---|
| OLLAMA_MODELS | 表示模型文件的存放目录,默认目录为当前用户目录即 C:\Users%username%.ollama\modelsWindows 系统 建议不要放在C盘,可放在其他盘(如 d:\software\ollama\models) |
| OLLAMA_HOST | 表示ollama 服务监听的网络地址,默认为127.0.0.1 如果想要允许其他电脑访问 Ollama(如局域网中的其他电脑),建议设置成 0.0.0.0 |
| OLLAMA_PORT | 表示ollama 服务监听的默认端口,默认为11434 如果端口有冲突,可以修改设置成其他端口(如8080等) |
| OLLAMA_ORIGINS | 表示HTTP 客户端的请求来源,使用半角逗号分隔列表 如果本地使用不受限制,可以设置成星号 * |
| OLLAMA_KEEP_ALIVE | 表示大模型加载到内存中后的存活时间,默认为5m即 5 分钟 (如纯数字300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活) 建议设置成 24h ,即模型在内存中保持 24 小时,提高访问速度 |
| OLLAMA_NUM_PARALLEL | 表示请求处理的并发数量,默认为1 (即单并发串行处理请求) 建议按照实际需求进行调整 |
| OLLAMA_MAX_QUEUE | 表示请求队列长度,默认值为512 建议按照实际需求进行调整,超过队列长度的请求会被抛弃 |
| OLLAMA_DEBUG | 表示输出 Debug 日志,应用研发阶段可以设置成1 (即输出详细日志信息,便于排查问题) |
| OLLAMA_MAX_LOADED_MODELS | 表示最多同时加载到内存中模型的数量,默认为1 (即只能有 1 个模型在内存中) |
-
注意下
OLLAMA_HOST,好像会自动创建用户环境变量。本地直接用127.0.0.1。方便调试。

-
OLLAMA_MODELS环境建议配置一下,默认是在C盘,一个模型一般是几个G。比较占用空间。

迁移ollama到其他盘
- 由于ollama是直接安装在C盘,C盘如果空间紧张,可以像我一样迁移到D盘,如果觉得没有必要,可忽略此步骤。
-
- 方法就是在C盘创建软链接,将真是数据放到D盘。
Administrator 是我的用户名
mklink /D C:\Users\Administrator\.ollama D:\software\Ollama\.ollama
mklink /D C:\Users\Administrator\AppData\Local\Ollama D:\software\Ollama\log
mklink /D C:\Users\Administrator\AppData\Local\Programs\Ollama D:\software\Ollama\app
- 迁移后的结果

运行ollama
方式一
- 在程序栏中找到

点击就会运行。然后右下角会出现ollama的小图标。

方式二
- 在命令行中输入
ollama serve(我没有独显,是以CPU方式运行的)

禁止ollama开机自启动
- 如果不想让ollama开机自启动,打开任务管理器, 到
启动栏目,选中右键 -> 禁用止自启动。

运行第一个模型
- 打开https://ollama.com/ 网站在输入框中输入
qwen。进入qwen2.5-coder,coder表示对编程方面的问题有优化。
- 在详情页面可以看到各种版本tag。可以根据自身电脑配置情况使用哪一个。一般来说模型越大就越消耗资源。

- 我选择的是当前最新版本。运行的命令是。如何没有就会先下载。
ollama run qwen2.5-coder

- 运行后的界面如下图所示。

- 然后我们输入一个问题,验证是否成功。
13.8与13.11哪个大?

- 可以看出答案正确,安装成功了。
Chatbox聊天
- 面对CMD的窗口聊天体验不太好,所以我们用一下Chatbox软件。
下载Chatbox
- 下载地址 https://chatboxai.app/en

配置ollama地址和模型
- 第一个下拉框选择 ollama , 下面的下拉框选地址和模型配置。

验证
- 我们输入一个问题,验证是否成功。
13.8与13.11哪个大?

-
结果正确。
-
然后我们再试一个冷门问题
介绍一下CSDN博主愤怒的苹果ext擅长什么?。

-
可以看出这个问题它是不知道的。
建立自身特定知识数据搭配大语言模型
- 一般对于模型不知道或不准确的回答有两种解决方案
- 1、模型微调。
- 2、建立自身特定知识数据 + 大语言模型
- 对于要求准确度不是很高的场景一般会采用建立自身特定知识数据的方案。本文要实践的就是这种方案。
创建项目环境
- 利用conda创建
conda create -n llamaindex python=3.10.13conda activate llamaindex# 安装依赖
pip install llama-index
pip install llama-index-llms-ollama
pip install llama-index-embeddings-ollama
pip install llama-index-readers-file
-
如果不知道怎么在pycharm中应用conda环境,可以看我这篇文章 https://blog.csdn.net/baidu_19473529/article/details/143442416,就不再赘述。
-
拉取嵌入模型.
ollama pull quentinz/bge-small-zh-v1.5
代码
- test.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.ollama import Ollama
from llama_index.core.node_parser import SentenceSplitter
import logging
import sys# 增加日志信息
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 配置 嵌入模型/预训练,这里我们用quentinz/bge-small-zh-v1.5
from llama_index.embeddings.ollama import OllamaEmbedding
Settings.embed_model = OllamaEmbedding(model_name="quentinz/bge-small-zh-v1.5")
# 配置ollama的LLM模型,这里我们用qwen2.5-coder
Settings.llm = Ollama(model="qwen2.5-coder", request_timeout=600.0)#特定知识数据
data_file = ['D:/work/self/Llamaindex-sample/data/a.txt']
documents = SimpleDirectoryReader(input_files=data_file).load_data()
index = VectorStoreIndex.from_documents(documents, transformations=[SentenceSplitter(chunk_size=256)])query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("介绍一下CSDN博主愤怒的苹果ext擅长什么?")
print(response)- 特定知识数据内容 a.txt
CSDN博主愤怒的苹果ext擅长Ai、Fw、Fl、Br、Ae、Pr、Id、Ps等软件的安装与卸载,精通CSS、JavaScript、PHP、ASP、C、C++、C#、Java、Ruby、Perl、Lisp、python、Objective-C、ActionScript、Pascal等单词的拼写,熟悉Windows、Linux、Mac、Android、IOS、WP8等系统的开关机。
运行结果

- 可以看出现在的运行结果基本上就是我们想要的结果了。
streamlit应用
-
通过硬编码的方式去问答没有图形化界面方便,下面引入streamlit就能得到干净好看的Web问答界面了,
-
命令行运行
pip install streamlit
- 代码 app.py
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.memory import ChatMemoryBuffer
import os
import tempfile
import hashlib# OLLAMA_NUM_PARALLEL:同时处理单个模型的多个请求
# OLLAMA_MAX_LOADED_MODELS:同时加载多个模型
os.environ['OLLAMA_NUM_PARALLEL'] = '2'
os.environ['OLLAMA_MAX_LOADED_MODELS'] = '2'# Function to handle file upload
def handle_file_upload(uploaded_files):if uploaded_files:temp_dir = tempfile.mkdtemp()for uploaded_file in uploaded_files:file_path = os.path.join(temp_dir, uploaded_file.name)with open(file_path, "wb") as f:f.write(uploaded_file.getvalue())return temp_dirreturn None# Function to calculate a hash for the uploaded files
def get_files_hash(files):hash_md5 = hashlib.md5()for file in files:file_bytes = file.read()hash_md5.update(file_bytes)return hash_md5.hexdigest()# Function to prepare generation configuration
def prepare_generation_config():with st.sidebar:st.sidebar.header("Parameters")max_length = st.slider('Max Length', min_value=8, max_value=5080, value=4056)temperature = st.slider('Temperature', 0.0, 1.0, 0.7, step=0.01)st.button('Clear Chat History', on_click=clear_chat_history)generation_config = {'num_ctx': max_length,'temperature': temperature}return generation_config# Function to clear chat history
def clear_chat_history():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,你需要什么帮助吗?"}]# File upload in the sidebar
st.sidebar.header("Upload Data")
uploaded_files = st.sidebar.file_uploader("Upload your data files:", type=["txt", "pdf", "docx"],accept_multiple_files=True)generation_config = prepare_generation_config()# Function to initialize models
@st.cache_resource
def init_models():embed_model = OllamaEmbedding(model_name="quentinz/bge-small-zh-v1.5")Settings.embed_model = embed_modelllm = Ollama(model="qwen2.5-coder", request_timeout=360.0,num_ctx=generation_config['num_ctx'],temperature=generation_config['temperature'])Settings.llm = llmdocuments = SimpleDirectoryReader(st.session_state['temp_dir']).load_data()index = VectorStoreIndex.from_documents(documents)memory = ChatMemoryBuffer.from_defaults(token_limit=4000)chat_engine = index.as_chat_engine(chat_mode="context",memory=memory,system_prompt="You are a chatbot, able to have normal interactions.",)return chat_engine# Streamlit application
st.title("💻 Local RAG Chatbot 🤖")
st.caption("🚀 A RAG chatbot powered by LlamaIndex and Ollama 🦙.")# Initialize hash for the current uploaded files
current_files_hash = get_files_hash(uploaded_files) if uploaded_files else None# Detect if files have changed and init models
if 'files_hash' in st.session_state:if st.session_state['files_hash'] != current_files_hash:st.session_state['files_hash'] = current_files_hashif 'chat_engine' in st.session_state:del st.session_state['chat_engine']st.cache_resource.clear()if uploaded_files:st.session_state['temp_dir'] = handle_file_upload(uploaded_files)st.sidebar.success("Files uploaded successfully.")if 'chat_engine' not in st.session_state:st.session_state['chat_engine'] = init_models()else:st.sidebar.error("No uploaded files.")
else:if uploaded_files:st.session_state['files_hash'] = current_files_hashst.session_state['temp_dir'] = handle_file_upload(uploaded_files)st.sidebar.success("Files uploaded successfully.")if 'chat_engine' not in st.session_state:st.session_state['chat_engine'] = init_models()else:st.sidebar.error("No uploaded files.")# Initialize chat history
if 'messages' not in st.session_state:st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,你需要什么帮助吗?"}]# Display chat messages from history
for message in st.session_state.messages:with st.chat_message(message['role'], avatar=message.get('avatar')):st.markdown(message['content'])# Display chat input field at the bottom
if prompt := st.chat_input("Ask a question about Datawhale:"):with st.chat_message('user'):st.markdown(prompt)# Generate responseprint("st.session_state ",st.session_state)response = st.session_state['chat_engine'].stream_chat(prompt)with st.chat_message('assistant'):message_placeholder = st.empty()res = ''for token in response.response_gen:res += tokenmessage_placeholder.markdown(res + '▌')message_placeholder.markdown(res)# Add messages to historyst.session_state.messages.append({'role': 'user','content': prompt,})st.session_state.messages.append({'role': 'assistant','content': response,})
- 运行app.py的命令
streamlit run app.py
-
运行后将自动打开浏览器页面

-
启动完成后,首先上传外部数据,初始化模型。

- 再提问验证是否成功。

- 与前面的回答差不多就表示成功了。
本文所使用的源码地址
- https://github.com/1030907690/Llamaindex-sample
参考
- https://juejin.cn/post/7418086006114713619
- https://blog.llyth.cn/1555.html
- https://www.bilibili.com/opus/978763969531478024
- https://github.com/datawhalechina/handy-ollama/blob/main/notebook/C7/LlamaIndex_RAG/%E4%BD%BF%E7%94%A8LlamaIndex%E6%90%AD%E5%BB%BA%E6%9C%AC%E5%9C%B0RAG%E5%BA%94%E7%94%A8.ipynb
相关文章:
LlamaIndex ollama 搭建本地RAG应用,建立本地知识库
目录 简介安装前的准备下载ollama创建llamaindex conda环境,为后面编码作准备 环境变量迁移ollama到其他盘运行ollama方式一方式二禁止ollama开机自启动运行第一个模型 Chatbox聊天下载Chatbox配置ollama地址和模型验证 建立自身特定知识数据搭配大语言模型创建项目…...

draggable的el-dialog实现对话框标题可以选择
请看图 这个对话框使用了el-dialog并且draggable属性设置成了true,所以标题栏这里就可以拖动,现在用户想选中标题栏的文本进而复制。我看到这个需求头都大了。 我能想到的方案有三个:1. 取消draggable为true 2. 标题文案后面加一个复制按钮 …...

2024年Android面试总结
2024年Android面试总结 1.动画类型有哪些?插值器原理? 2.StringBuffer和StringBuilder区别? 3.jvm内存模型? 4.线程池7大核心参数及原理? 5.Android多进程通信方式有哪些?各自的优缺点? 6…...

树莓派3:64位系统串口(UART)使用问题的解决方法
前言 当我们要使用串口进行zigbee的短距离通信时,发现无法使用串口. 原因 树莓派3bCPU内部有两个串口,一个硬件串口(就是我们平时使用的UART),还有一个迷你串口(mini-uart),在老版本的树莓派中把硬件串口分配在GPIO上,可以单独使用.但是在新的树莓派中官方把硬件串口给了蓝牙…...
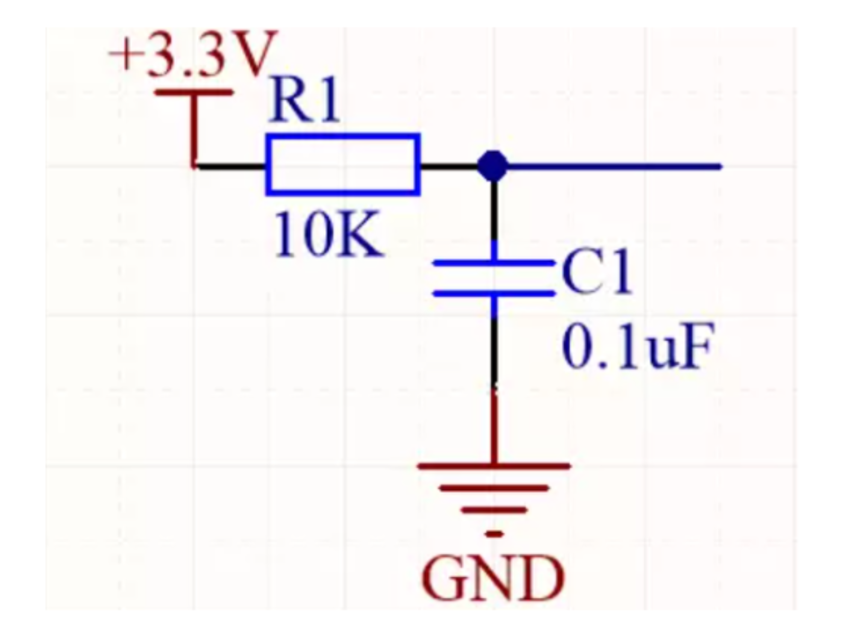
SemiDrive E3 硬件设计系列---唤醒电路设计
一、前言 E3 系列芯片是芯驰半导体高功能安全的车规级 MCU,对于 MCU 的硬件设计部分,本系列将会分模块进行讲解,旨在介绍 E3 系列芯片在硬件设计方面的注意事项与经验,本文主要讲解 E3 硬件设计中唤醒电路部分的设计。 二、RTC 模…...

淘宝接口高并发采集核心要点解读,开启电商数据智能应用新纪元
一、引言 在电商蓬勃发展的今天,淘宝作为全球知名的电商巨头,其平台上的数据犹如一座蕴藏无限价值的宝藏。准确且高效地采集淘宝接口数据,并通过高并发技术实现大规模数据获取,对于电商企业的精准营销、市场趋势分析、竞品监测以及…...

C#里怎么样快速使用LINQ实现查询?
C#里怎么样快速使用LINQ实现查询? 在C#里使用LINQ,是一个方便的功能, 不过,要学会使用这部分的功能,需要比较多的学习时间,否则,使用起就比较难。 因为它的表现方式,与编程语言通用的功能,还是差别比较大。 当数据量比较小,没有特定的顺序时,使用LINQ访问会比较好…...

2024新版微软edge浏览器输入百度网址时自动补全tn=68018901……小尾巴的解决
以前一直是Windows11 21h2版本,浏览器内输入baidu不会自动补全tnxx的百度推广小尾巴。然后前几天在BIOS内开启了tpm2.0,升级Windows11到了24h2版本。 发现在edge浏览器内只要输入b,就会自动补全为baidu.com?tnXXX的这么一个百度推广形式。开…...

uni-app打包H5自定义微信分享
1、配置分享信息 修改uni-app的index.html,添加Open Graph(OG)标签来配置分享信息。 <!DOCTYPE html> <html lang="en"><head><meta charset="UTF-8" /><meta name="description" content="标题"/>…...

大模型专栏--大模型应用场景
紧接着第一篇,什么是大模型,这篇文章讨论一下大模型的应用场景和应用方式有哪些? 基础使用 随着 GPT 的出现,AI 大模型已经越来越多得出现在日常生活和学术研究,工作中。 按照使用方向有以下几种: 自然语…...
-顶点动画)
骑砍2霸主MOD开发(29)-顶点动画
一.定制化顶点动画(MorphAnimation) 定制化顶点动画用于人物Agent的面部表情. 1.创建MorphAnimation对应静态资源morph_animation.tpac 2.Agent设置对应MorphAnimation [EngineMethod("set_agent_facial_animation", false)] void SetAgentFacialAnimation(UIntPtr …...

-Dspring.profiles.active=dev与--spring.profiles.active=dev的区别
在Spring Boot应用程序中,-Dspring.profiles.activedev和--spring.profiles.activedev都用于指定要激活的Spring配置文件(profile),但它们在不同的环境中使用,并且有不同的作用域。 -Dspring.profiles.activedev&#…...
单例设计对象与代码块)
面向对象高级(2)单例设计对象与代码块
面向对象高级(2) 单例设计模式、main方法与代码块 引言; 设计模式:特定环境下特定问题的处理方法。可理解为一种经典的可以参照的模板。单例设计模式则是只存在单个对象实例、且只有一种方法获取对象实例的一种设计模式。 单例设…...

47小型项目的规划与实施
每天五分钟学Linux | 第四十七课:小型项目的规划与实施 大家好!欢迎再次来到我们的“每天五分钟学Linux”系列教程。在前面的课程中,我们学习了并发编程的知识,包括如何管理和使用进程与线程。今天,我们将探讨如何规划…...

堤防安全监测系统方案
一、背景情况 堤防是开发利用水资源和防治水灾害的重要工程措施之一,对防洪、供水、生态、发电、航运等至关重要。我国现有堤防9.8万多座,其中大中型堤防4700多座、小型堤防9.4万座,80%以上修建于上世纪50至70年代。由于堤防管护力量薄弱&am…...

聊聊Flink:这次把Flink的window分类(滚动、滑动、会话、全局)、窗口函数讲透
一、窗口 窗口(Window)是处理无界流的关键所在。窗口将流分成有限大小的“桶”,我们可以在其上应用算子计算。Flink可以使用window()和windowAll()定义一个窗口,二者都需要传入一个窗口分配器WindowAssigner,WindowAs…...

mysql-分析MVCC原理
一、MVCC简介 MVCC是一种用来解决读写冲读的无锁并发控制,也就是为事务分配单增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照,所以MVCC可以为数据库解决一些问题。…...

由于答案过大,请对a取模。取模后的答案不是原问题的答案 取模有何意义呢 详解
在许多情况下,处理大数时会将 a 取模,即用 a m o d m a \mod m amodm的结果代替 a a a,然后继续计算。这种做法的核心问题是:取模后的值与原问题之间的关系是否保持一致。取模后的意义在于,它在不改变问题核心特性的前…...

【c++篇】掌握动态内存的奥妙
【C篇】动态内存 一、Static 关键字1.1函数内部的静态变量1.2 全局静态变量1.3静态成员变量1.4静态成员函数 二、内存管理2.1栈区(Stack)2.2堆区(Heap) 三、动态内存分配机制3.1、动态内存分配的两种方法c语言c 3.2new 和delete的用法3.3语法和类型安全性…...

5.4.2-3 编写Java程序读取HDFS文件
在本次实战中,我们通过Java程序实现了从Hadoop分布式文件系统(HDFS)读取文件的功能。首先,我们创建了ReadFileOnHDFS类,并在其中实现了两个方法:read1()和read1_()。read1()方法展示了如何打开HDFS文件并逐…...

Scroll Reverser终极指南:彻底告别macOS滚动方向混乱的智能解决方案
Scroll Reverser终极指南:彻底告别macOS滚动方向混乱的智能解决方案 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser Scroll Reverser是一款专为macOS设计的智能滚动方…...

VMware Workstation Pro 17免费许可证密钥完整指南:快速激活专业虚拟化工具
VMware Workstation Pro 17免费许可证密钥完整指南:快速激活专业虚拟化工具 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major …...

基于XAI与增量删除的地球观测数据特征精炼实战
1. 项目概述与核心思路在机器学习项目中,我们常常陷入一个思维定式:数据越多,模型性能就越好。尤其是在处理地球观测这类多模态、高维度的时序数据时,从哨兵卫星的光谱波段、气象站的小时级观测到静态地形数据,我们习惯…...

结构可识别性映射:破解模型不可识别下的时间序列分类难题
1. 项目概述:当模型“看不清”时,如何让分类器“看得清”?在生物医学、工业过程监控等领域,我们常常面对这样的场景:你有一堆传感器记录下的时间序列数据,比如病人的心率变化、反应器内的温度波动ÿ…...

石墨烯六边形Hubbard模型的量子模拟研究
1. 石墨烯六边形Hubbard模型的量子模拟背景在凝聚态物理研究中,理解强关联电子系统的行为一直是核心挑战。这类系统展现出超导、量子自旋液体等丰富物理现象,而Hubbard模型作为描述电子在晶格中相互作用的最简模型,已成为理论研究的重要工具。…...

非欧几里得机器学习:流形与拓扑结构下的回归与嵌入方法
1. 项目概述:当数据不再“平直” 在机器学习的日常实践中,我们习惯于将数据点视为高维欧几里得空间(即我们熟悉的“平直”空间,如二维平面、三维空间)中的向量。线性回归、主成分分析(PCA)乃至大…...

Gradio模型部署全攻略:从Hugging Face Spaces到AWS EC2实战
1. 项目概述与部署价值当你花了几周甚至几个月时间,终于训练出一个效果不错的机器学习模型,比如一个能识别猫狗图片的分类器,或者一个能生成诗歌的文本模型,接下来的问题往往不是技术上的,而是工程上的:怎么…...

数字孪生与视频孪生空间智能治理技术白皮书
数字孪生与视频孪生空间智能治理技术白皮书——镜像视界浙江科技有限公司:无感定位跨镜追踪透明化空间管- 编制单位:镜像视界浙江科技有限公司- 权威背书:国家十四五重点课题研究、镜像视界浙江普陀时空大数据应用技术联合研究院联合研究、河…...

前缀和与差分进阶总结 | 技巧归纳与实战应用
前缀和与差分进阶总结 | 技巧归纳与实战应用 引言 前缀和与差分是数组处理中两种重要且互补的技术。它们看似简单,却在 LeetCode 和实际工程中有着广泛的应用。前缀和将区间查询从 O(n) 优化到 O(1),差分将区间更新从 O(n) 优化到 O(1)。两者的结合使用可…...

3层深度清理技术:Display Driver Uninstaller显卡驱动彻底卸载解决方案
3层深度清理技术:Display Driver Uninstaller显卡驱动彻底卸载解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driv…...