MySQL底层概述—1.InnoDB内存结构
大纲
1.InnoDB引擎架构
2.Buffer Pool
3.Page管理机制之Page页分类
4.Page管理机制之Page页管理
5.Change Buffer
6.Log Buffer
1.InnoDB引擎架构
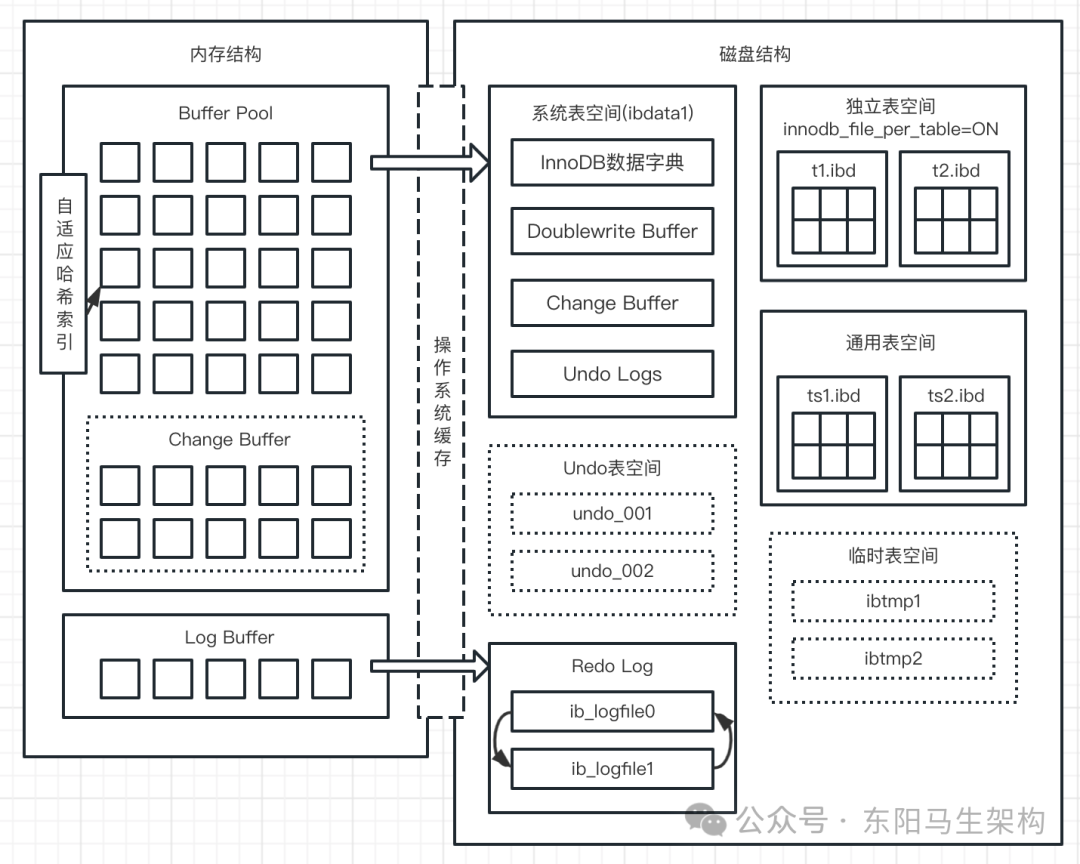
(1)InnoDB引擎架构图
(2)InnoDB内存结构
(1)InnoDB引擎架构图
下面是InnoDB引擎架构图,主要分为内存结构和磁盘结构两大部分。
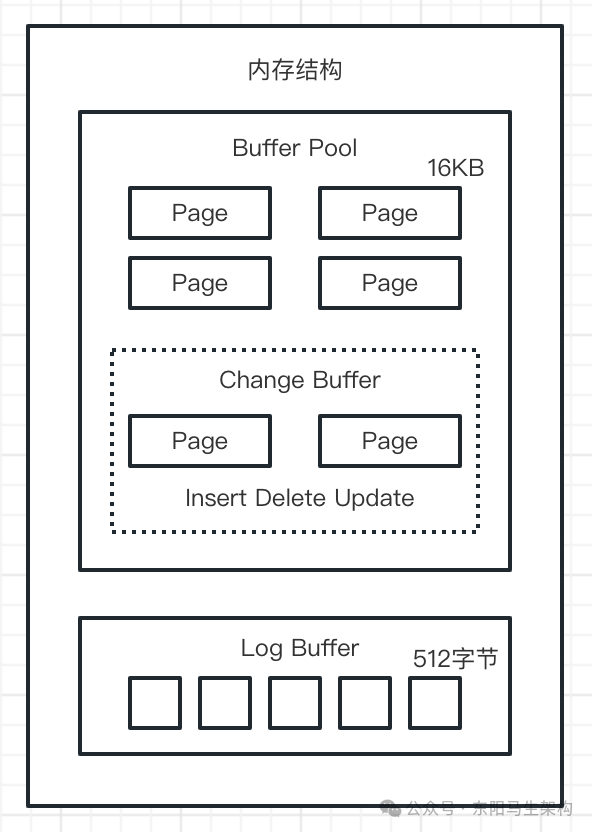
(2)InnoDB内存结构
2.Buffer Pool
(1)Buffer Pool基本概念
(2)如何判断数据页是否缓存在Buffer Pool
(1)Buffer Pool基本概念
Buffer Pool是缓冲池的意思。Buffer Pool的作用是缓存表数据与索引数据,减少磁盘IO,提升效率。
Buffer Pool由缓存数据页(Page)和对缓存数据页进行描述的控制块组成。控制块存储着缓存页的表空间、数据页号、在Buffer Pool中的地址等。
Buffer Pool默认大小是128M,以Page页为单位,Page页默认大小16K。而控制块的大小约为数据页的5%,大概是800字节。
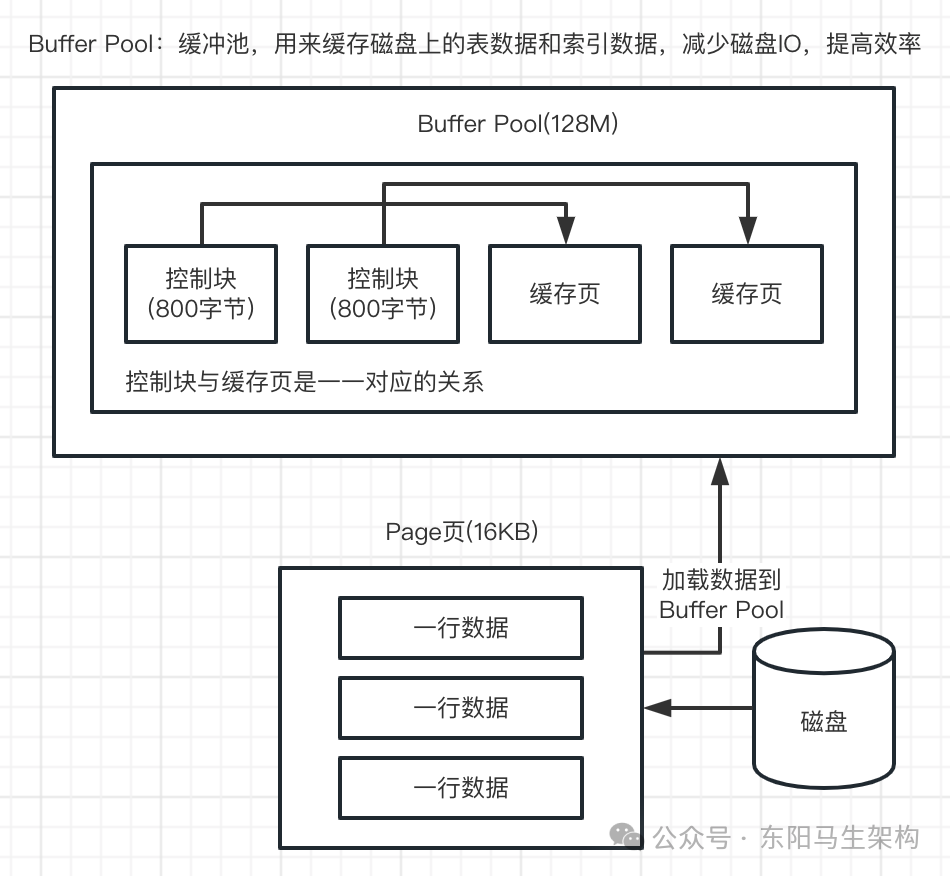
注意:Buffer Pool大小为128M指的就是缓存页的总大小。控制块则一般占5%,所以每次会多申请6M的内存空间用于存放控制块。
(2)如何判断数据页是否缓存在Buffer Pool
MySQl中有一个哈希表数据结构:key是表空间号 + 数据页号,然后value就是缓存页对应的控制块。
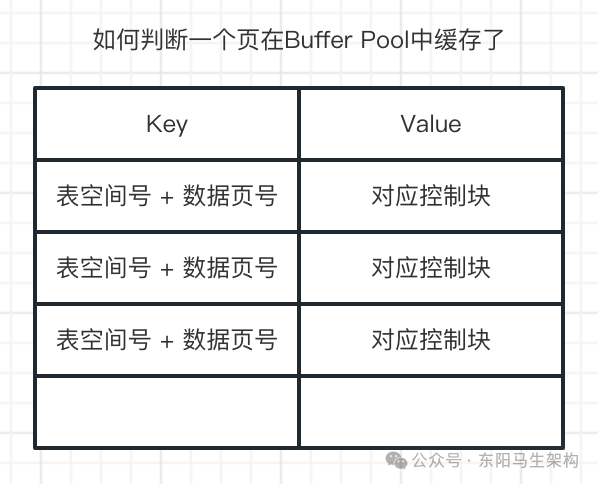
当需要访问某个页的数据时:会先从哈希表中根据表空间号 + 页号看看是否存在对应的缓存页。如果有,则直接使用。如果没有,则从Free链表中选出一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。
3.Page管理机制之Page页分类
Buffer Pool的底层采用链表数据结构管理Page。在InnoDB访问表记录和索引时会在Buffer Pool中的Page页缓存,以后使用同样的表记录和索引时,就可以减少磁盘IO操作,提升效率。
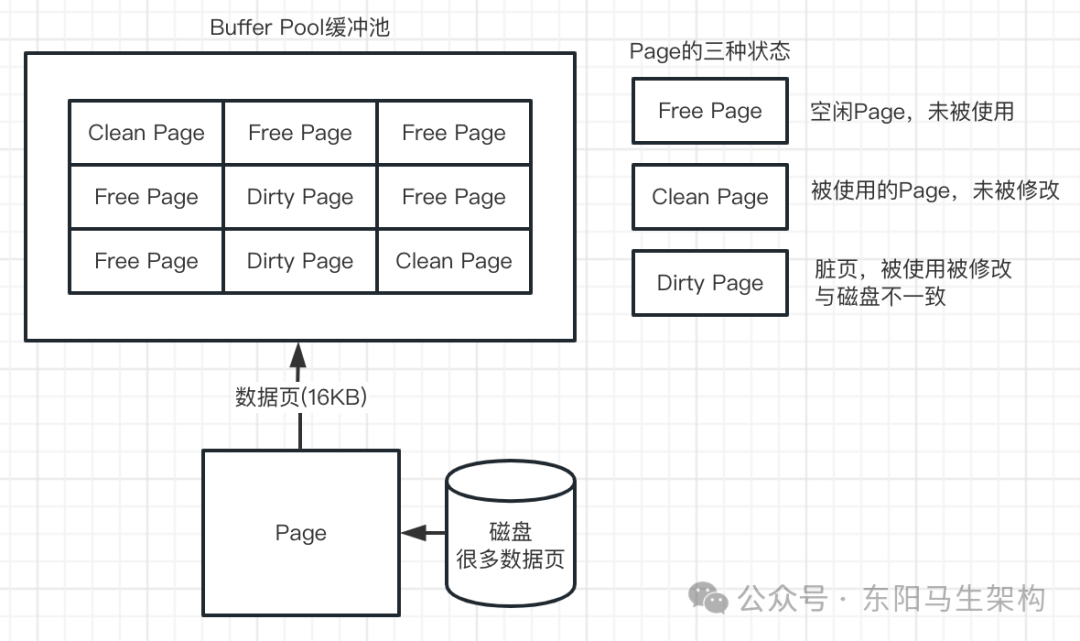
Page根据状态可以分为三种类型:
一.Free Page:空闲Page,未被使用。
二.Clean Page:被使用Page,没被修改。
三.Dirty Page:被使用Page,已被修改。
脏页中的数据和磁盘的数据产生了不一致。
4.Page管理机制之Page页管理
(1)Free List空闲缓冲区
(2)Flush List需刷盘的缓冲区
(3)LRU List正在使用的缓冲区
针对上面的三种Page类型,InnoDB会通过三种链表结构来维护和管理。
(1)Free List表示空闲缓冲区(管理Free Page)
一.Free链表的初始化
Buffer Pool初始化时会先向操作系统申请连续的内存空间,然后把它划分成若干个控制块&缓存页,接着把所有空闲的缓存页对应的控制块作为节点放到一个链表中,这个链表就是Free链表。
二.Free链表的基节点
Free链表中只有一个基节点是不记录缓存页信息的(单独申请空间),基节点存放了Free链表的头节点地址、尾节点地址和节点个数。
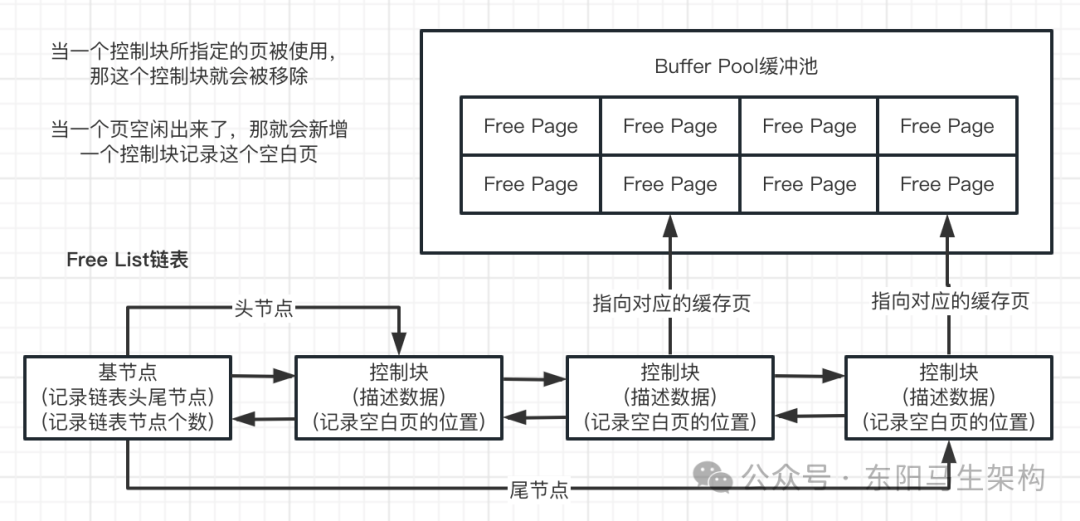
三.从磁盘加载数据页的流程
步骤1:首先从Free链表中取出一个空闲的控制块(对应缓存页)。
步骤2:然后把该缓存页对应的控制块信息填上,如缓存页所在的表空间、数据页号之类的信息。
步骤3:接着把该缓存页对应的Free链表节点(即控制块)从链表中移除,表示该缓存页已经被使用了。
(2)Flush List表示需要刷新到磁盘的缓冲区(管理Dirty Page)
Flush List管理的Dirty Page会按修改时间排序。InnoDB引擎为了提高处理效率,在每次修改缓存页后,并非立刻把修改刷新到磁盘上,而是在未来某个时间点进行刷新操作。
凡是被修改过的缓存页对应的控制块都会作为节点加入到Flush链表,Flush链表的结构与Free链表的结构相似。
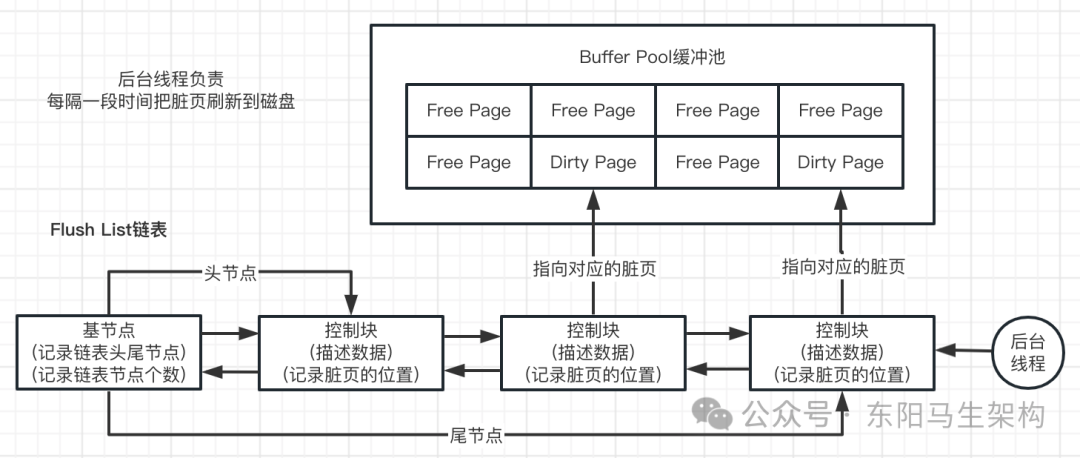
脏页既存在于Flush链表中,也存在于LRU链表中,但它们互不影响。LRU链表负责管理Page的可用性和释放,Flush链表负责管理脏页的刷盘操作。
(3)LRU List表示正在使用的缓冲区(管理Clean Page和Dirty Page)
一.普通LRU算法
二.普通LRU链表的优缺点
三.改进型LRU算法
四.冷数据区的数据页何时会被转到到热数据区
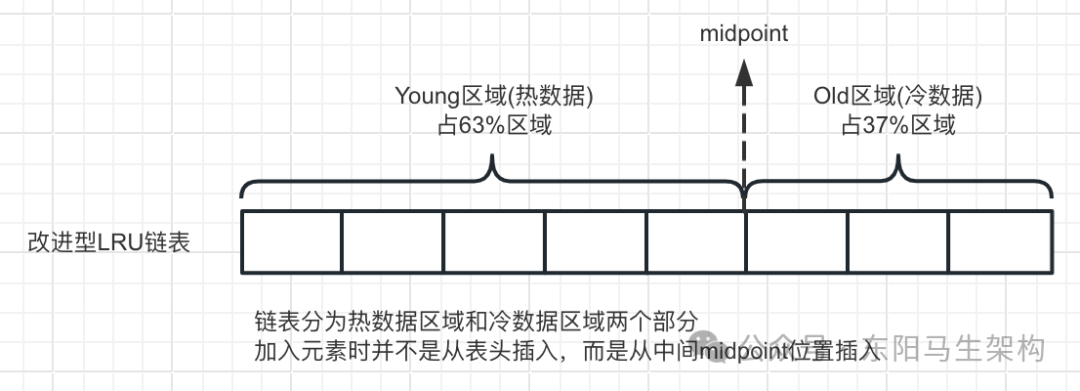
缓冲区以midpoint为基点:链表的前面部分称为热数据列表,存放经常访问的数据,占63%。链表的后面部分称为冷数据列表,存放使用较少数据,占37%。
一.普通LRU算法
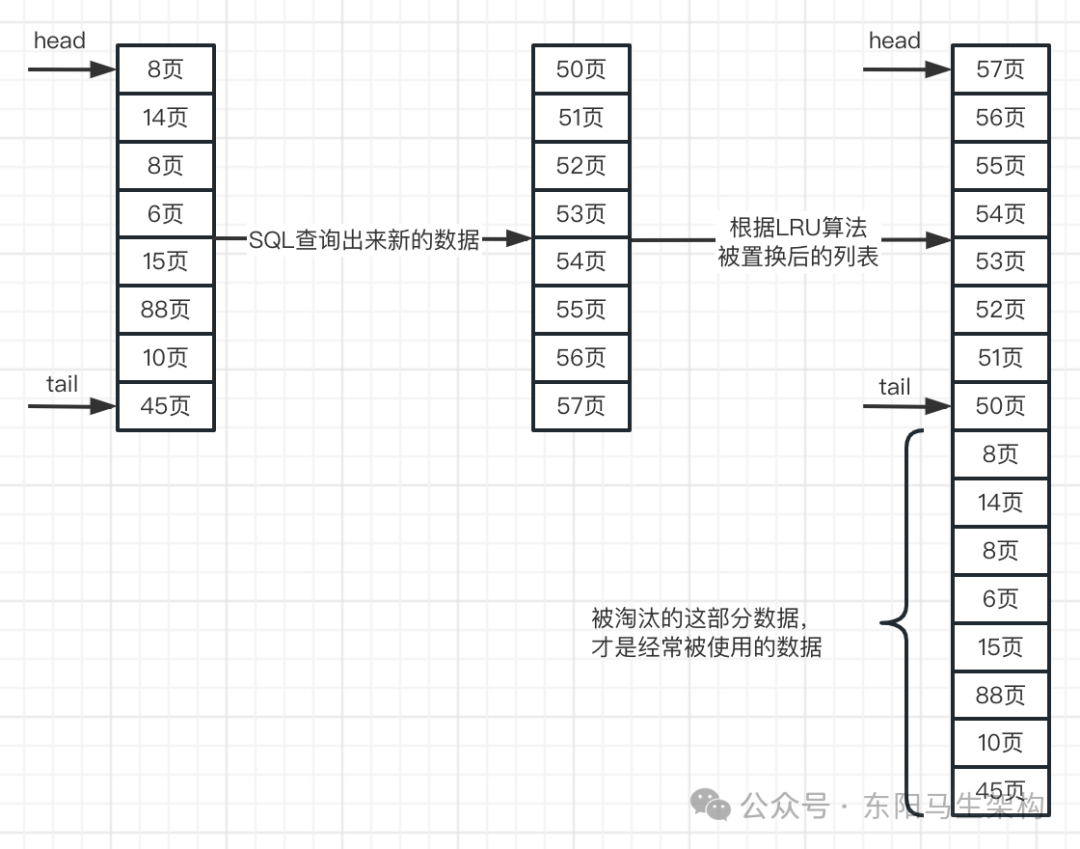
LRU = Least Recently Used(最近最少使用),就是末尾淘汰法。新数据从链表头部加入,释放空间时从末尾淘汰。
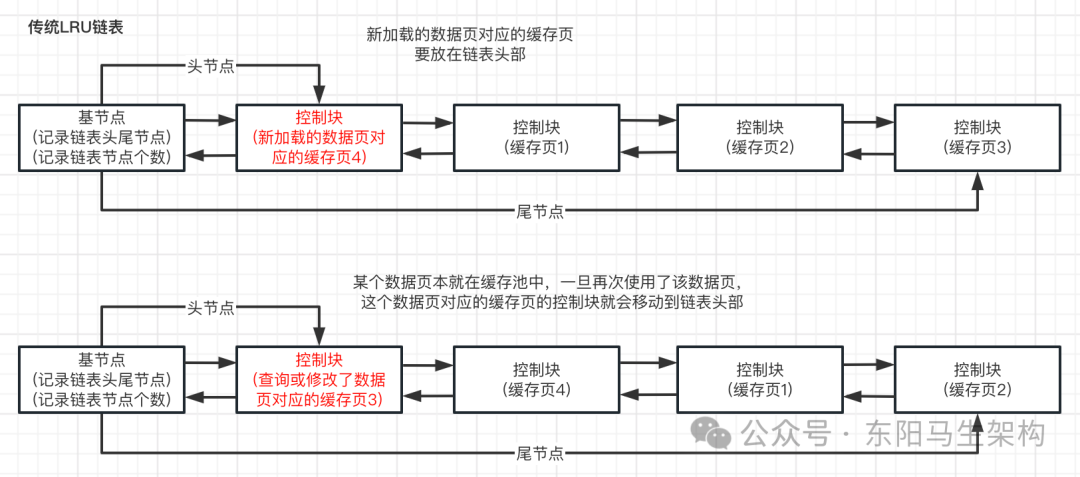
步骤1:当要访问某个不在Buffer Pool中的数据页时,就把该数据页加载到Buffer Pool,并且把其缓存页对应的控制块作为节点添加到LRU链表的头部。
步骤2:当要访问某个在Buffer Pool中的数据页时,就把其缓存页对应的控制块移动到LRU链表头部。
步骤3:当需要释放空间时,从最末尾淘汰。
二.普通LRU链表的优缺点
优点:(热数据最快被获取)
所有最近使用的数据都在链表表头,最近未使用的数据都在链表表尾,可以保证热数据能最快被获取到。
缺点:(全表扫描 + 预读机制)
如果发生全表扫描,则可能将真正的热数据淘汰。由于MySQL中存在预读机制,很多预读的页会被放到LRU链表的表头。如果这些预读的页没用到,那么就可能会导致真正的热数据在尾部被淘汰。全表扫描的发生场景是:没有建立合适的索引或查询时使用select *等。
三.改进型LRU算法
改进的LRU链表分为热数据和冷数据两个部分。往LRU链表加入元素时并不从表头插入,而是从中间midpoint位置插入,也就是从磁盘中新读出的数据会放在冷数据区的头部。
如果数据很快被访问,那么Page就会向热数据列表头部移动;如果数据没有被访问,那么Page会逐步向冷数据列表尾部移动,等待淘汰。
四.冷数据区的数据页何时会被转到到热数据区
在对某个处于冷数据列表的缓存页进行第一次访问时,就会在它对应的控制块中记录下这个访问时间。
如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该缓存页就不会从冷数据列表移动到热数据列表的头部,否则就将该缓存页从冷数据列表移动到热数据列表的头部,从而避免全表扫描带来的访问频率很低但占用大量缓存页的问题。
这个间隔时间由innodb_old_blocks_time控制,默认是1s。这也就意味着,对于从磁盘加载到LRU链表冷数据列表的缓存页来说,如果第一次和最后一次访问的时间间隔小于1s,则不会加入热数据列表。
5.Change Buffer
(1)Change Buffer基本概念
(2)Change Buffer的数据更新流程
(3)为什么写缓冲区仅适用于二级索引页
(4)什么情况下会进行merge
(5)Change Buffer的使用场景(写多读少)
(1)Change Buffer基本概念
Change Buffer是写缓冲区,用于优化对二级索引(辅助索引)页的更新。
对于DML操作:如果请求的是辅助索引(非唯一键索引)且没有在缓冲池中,那么不会立刻将数据页加载到Buffer Pool中,而是会先在Change Buffer中记录数据的变更,等未来数据被读取时再将数据合并恢复放到Buffer Pool,以减少磁盘IO。
Change Buffer默认占Buffer Pool空间25%,最大占50%。可根据读写业务量进行调整,参数是innodb_change_buffer_max_size。

(2)Change Buffer的数据更新流程
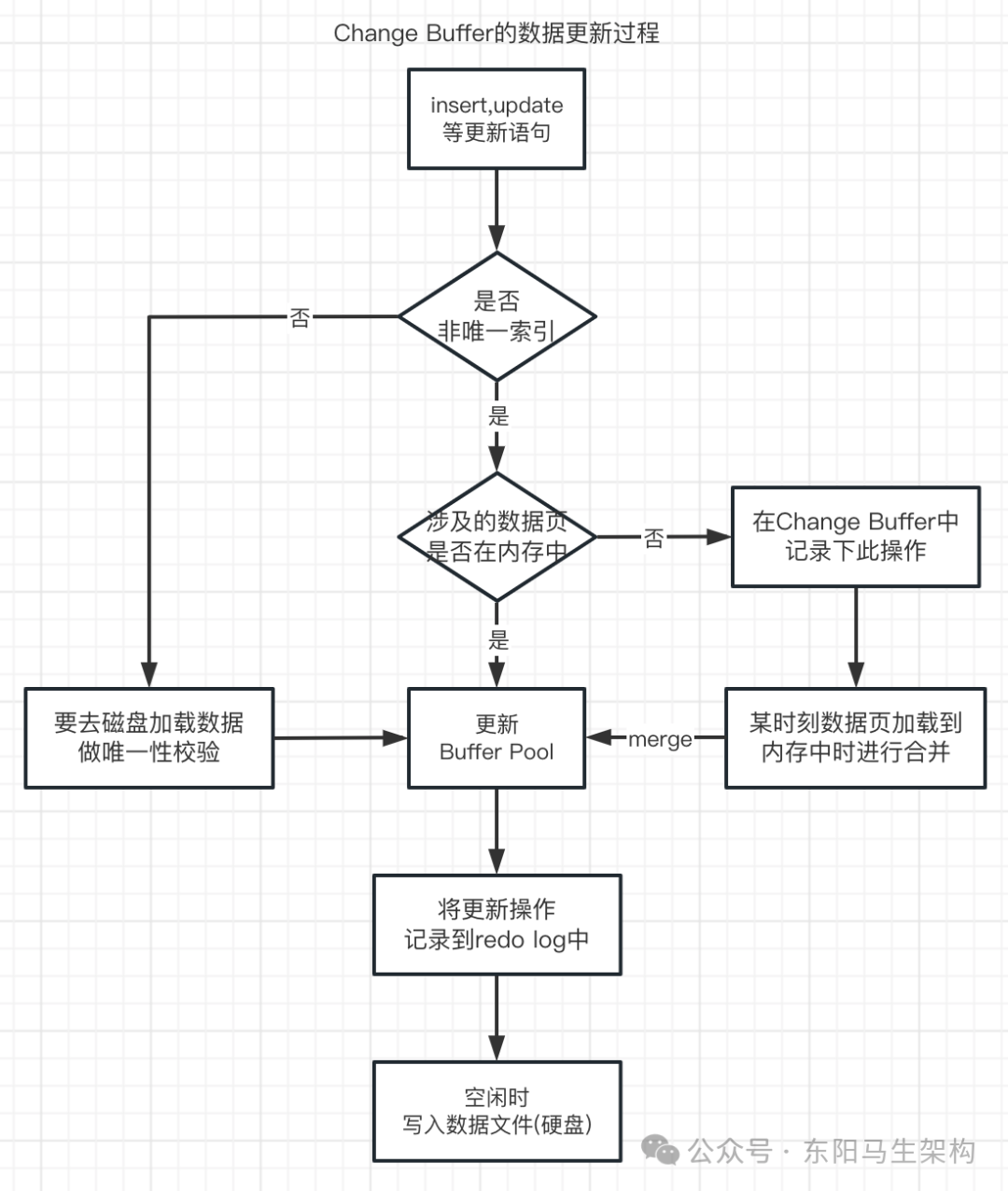
情况1:
对于唯一索引,需要将数据页读入内存。然后判断没有冲突才插入更新值,语句执行结束。
情况2:
对于普通索引,更新一条记录时,步骤如下:
步骤一:如果该记录在Buffer Pool中存在,那么就直接在Buffer Pool中修改,进行一次内存操作。
步骤二:如果该记录在Buffer Pool中不存在(没有命中),那么在不影响数据一致性的前提下,InnoDB会将该记录的更新操作缓存在Change Buffer中,先不用去磁盘查询数据,从而避免一次磁盘IO。
步骤三:当下次查询该记录时,InnoDB才会将数据页读入内存,然后执行Change Buffer中与该记录有关的操作。
(3)为什么写缓冲区仅适用于二级索引页
如果新增或修改发生在唯一索引中,那么InnoDB必须要做唯一性校验。此时就必须查询磁盘,进行一次IO操作。也就是会直接将记录查询到Buffer Pool中,然后在缓冲池修改,不需要在Change Buffer操作了。
如果新增或修改发生在非索引中,那么InnoDB还是要做唯一性校验。此时也必须查询磁盘,进行一次IO操作。
(4)什么情况下会进行merge
将Change Buffer中数据的变更应用到原数据页的过程称为merge。Change Buffer上的缓存数据是可以持久化的,以下情况会进行持久化:
一.访问这个数据页会触发merge
二.系统有后台线程会定期merge
三.在数据库正常关闭的过程中也会执行merge
(5)Change Buffer的使用场景
Change Buffer的主要目的是将记录的变更操作缓存下来,所以在merge发生前应当尽可能多的缓存变更信息,这样Change Buffer的优势发挥得就越明显。
应用场景是写多读少的业务。此时页面在写完后马上被访问的概率较小,Change Buffer使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
6.Log Buffer
(1)Log Buffer的作用
(2)Log Buffer的刷盘策略
(3)Adaptive Hash Index
(1)Log Buffer的作用
Log Buffer指的是日志缓冲区。
Log Buffer是用来保存要写入磁盘log文件(Redo/Undo)的log数据。Log Buffer可以优化每次更新操作后要写文件而产生的磁盘IO问题,因为每次更新操作都是需要写log到redo log和undo log磁盘文件的。
Log Buffer日志缓冲区的内容会定期刷新到磁盘log文件中,Log Buffer日志缓冲区满时会自动将其刷新到磁盘。当遇到BLOB或多行更新的大事务时,增加日志缓冲区可节省磁盘IO。
Log Buffer主要是用于记录InnoDB引擎日志,InnoDB在DML操作时会产生redo和undo日志。
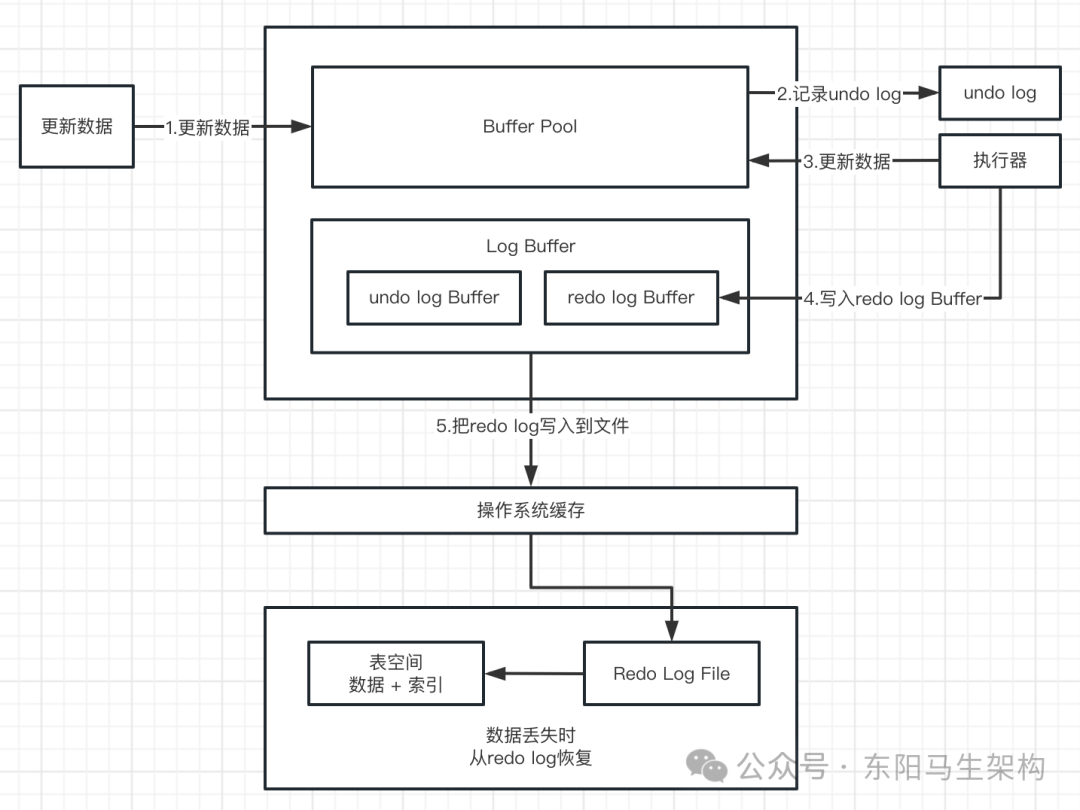
Log Buffer空间满了,会自动写入磁盘,默认16M。可以通过将innodb_log_buffer_size参数调大,减少磁盘IO频率。
(2)Log Buffer的刷盘策略
innodb_flush_log_at_trx_commit参数控制日志刷新行为,默认为1。
一.innodb_flush_log_at_trx_commit = 0
每隔1秒写日志文件Log Buffer和刷盘操作,最多丢失1秒数据。写日志文件Log Buffer -> OS cache -> 刷盘OS Cache -> 磁盘文件。
二.innodb_flush_log_at_trx_commit = 1
事务提交,立刻写日志文件和刷盘,数据不丢失,但是会频繁IO操作。
三.innodb_flush_log_at_trx_commit = 2
事务提交,立刻写日志文件Log Buffer,每隔1秒钟进行刷盘操作。
(3)Adaptive Hash Index
自适应哈希索引,用于优化对Buffer Pool数据的查询,InnoDB存储引擎会监控对表索引的查找。
自适应哈希索引指的是:如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
相关文章:
MySQL底层概述—1.InnoDB内存结构
大纲 1.InnoDB引擎架构 2.Buffer Pool 3.Page管理机制之Page页分类 4.Page管理机制之Page页管理 5.Change Buffer 6.Log Buffer 1.InnoDB引擎架构 (1)InnoDB引擎架构图 (2)InnoDB内存结构 (1)InnoDB引擎架构图 下面是InnoDB引擎架构图,主要分为内存结构和磁…...
计算两个日期天数之差)
MySQL:DATEDIFF()计算两个日期天数之差
题目需求: 计算出比前一天温度要高的日期。 select a.id from weather a, weather b where a.temperature > b.temperature and datediff(a.recordDate, b.recordDate) 1; DATEDIFF(date1, date2)函数用于计算两个日期之间的天数差。函数返回date1和date2之…...

Linux 编译Ubuntu24内核
参考来源: 编译并更新内核:https://www.cnblogs.com/smlile-you-me/p/18248433 编译报错–sub-make: https://forum.linuxfoundation.org/discussion/865005/facing-error-in-building-the-kernel 1.下载源码,执行如下命令,会在/usr/src下多…...

Android系统中init进程、zygote进程和SystemServer进程简单学习总结
Android系统中,init、zygote和SystemServer进程是系统启动和运行的关键进程,它们之间有着密切的关系,本文针对这三个进程的学习做一个简单汇总,方便后续查询。 1、init进程 Android用户空间执行的第一个程序就是它,可…...

Flask 基于wsgi源码启动流程
1. 点击 __call__ 进入到源码 2. 找到 __call__ 方法 return 执行的是 wsgi方法 3. 点击 wsgi 方法 进到 wsgi return 执行的是 response 方法 4. 点击response 方法 进到 full_dispatch_request 5. full_dispatch_request 执行finalize_request 方法 6. finalize_request …...

leetcode代码 50道答案
简单难度:两数之和 def twoSum(nums, target): for i in range(len(nums)): for j in range(i 1, len(nums)): if nums[i] nums[j] target: return [i, j] return [] 简单难度:有效的括号 def isVa…...

Centos-stream 9,10 add repo
Centos-stream repo前言 Centos-stream 9,10更换在线阿里云创建一键更换repo 自动化脚本 华为centos-stream 源 , 阿里云centos-stream 源 华为epel 源 , 阿里云epel 源vim /centos9_10_repo.sh #!/bin/bash # -*- coding: utf-8 -*- # Author: make.h...

【隐私计算大模型】联邦深度学习之拆分学习Split learning原理及安全风险、应对措施以及在大模型联合训练中的应用案例
Tips:在两方场景下,设计的安全算法,如果存在信息不对等性,那么信息获得更多的一方可以有概率对另一方实施安全性攻击。 1. 拆分学习原理 本文介绍了一种适用于隐私计算场景的深度学习实现方案——拆分学习,又称分割…...

DataWhale—PumpkinBook(TASK05决策树)
课程开源地址及相关视频链接:(当然这里也希望大家支持一下正版西瓜书和南瓜书图书,支持文睿、秦州等等致力于开源生态建设的大佬✿✿ヽ(▽)ノ✿) Datawhale-学用 AI,从此开始 【吃瓜教程】《机器学习公式详解》(南瓜…...

elasticsearch7.10.2集群部署带认证
安装elasticsearch rpm包安装 下载地址 https://mirrors.aliyun.com/elasticstack/7.x/yum/7.10.2/ 生成证书 #1.生成CA证书 # 生成CA证书,执行命令后,系统还会提示你输入密码,可以直接留空 cd /usr/share/elasticsearch/bin ./elasticsearch-certutil ca#会在/usr/share/el…...

Java基础-I/O流
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 字节流 定义 说明 InputStream与OutputStream示意图 说明 InputStream的常用方法 说明 OutputStrea…...
全面解析多种mfc140u.dll丢失的解决方法,五种方法详细解决
当你满心期待地打开某个常用软件,却突然弹出一个错误框,提示“mfc140u.dll丢失”,那一刻,你的好心情可能瞬间消失。这种情况在很多电脑用户的使用过程中都可能出现。无论是游戏玩家还是办公族,面对这个问题都可能不知所…...

详细探索xinput1_3.dll:功能、问题与xinput1_3.dll丢失的解决方案
本文旨在深入探讨xinput1_3.dll这一动态链接库文件。首先介绍其在计算机系统中的功能和作用,特别是在游戏和输入设备交互方面的重要性。然后分析在使用过程中可能出现的诸如文件丢失、版本不兼容等问题,并提出相应的解决方案,包括重新安装相关…...
)
InfluxDB时序数据库笔记(一)
InfluxDB笔记一汇总 1、时间序列数据库概述2、时间序列数据库特点3、时间序列数据库应用场景4、InfluxDB数据生命周期5、InfluxDB历史数据需要另外归档吗?6、InfluxDB历史数据如何归档?7、太麻烦了,允许的话选择设施完备的InfluxDB云产品吧8、…...

Spring Boot 3.x + OAuth 2.0:构建认证授权服务与资源服务器
Spring Boot 3.x OAuth 2.0:构建认证授权服务与资源服务器 前言 随着Spring Boot 3的发布,我们迎来了许多新特性和改进,其中包括对Spring Security和OAuth 2.0的更好支持。本文将详细介绍如何在Spring Boot 3.x版本中集成OAuth 2.0…...

2024年09月CCF-GESP编程能力等级认证Scratch图形化编程二级真题解析
本文收录于《Scratch等级认证CCF-GESP图形化真题解析》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 一、单选题(共 10 题,每题 3 分,共 30 分) 第 1 题 据有关资料,山东大学于 1972 年研制成功 DJL-1 计算机,并于 1973 年投入运行,其综合性能居当时全国第…...
)
Linux 正则表达式(basic and extened)
正则表达式(Regular Expressions),整理自: https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html gred sed 定义 Regular Expressions (REs) provide a mechanism to select specific strings from a set of character strings.…...

GB 35114-2017 学习笔记(规避版权阉割版)
GB 35114-2017 学习笔记(规避版权阉割版) openstd.samr.gov.cn 国家标准全文公开系统 这个政府网站提供GB 35114-2017标准的的预览和下载,有需要的自行下载 GB 35114-2017作为一个国家强制标准,在国家标准全文公开系统 自己做个…...

YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
《YOLO-FaceV2:一种尺度与遮挡感知的人脸检测器》 1.引言2.相关工作3.YOLO-FaceV23.1网络结构3.2尺度感知RFE模型3.3遮挡感知排斥损失3.4遮挡感知注意力网络3.5样本加权函数3.6Anchor设计策略3.7 归一化高斯Wasserstein距离 4.实验4.1 数据集4.2 训练4.3 消融实验4.3.1 SEAM块4…...

进程间通信--详解
目录 前言一、进程间通信介绍1、进程间通信目的2、进程间通信发展3、进程间通信的分类4、进程间通信的必要性5、进程间通信的技术背景6、进程间通信的本质理解 二、管道1、什么是管道2、匿名管道pipe(1)匿名管道的原理(2)pipe函数…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...