进程间通信--详解
目录
- 前言
- 一、进程间通信介绍
- 1、进程间通信目的
- 2、进程间通信发展
- 3、进程间通信的分类
- 4、进程间通信的必要性
- 5、进程间通信的技术背景
- 6、进程间通信的本质理解
- 二、管道
- 1、什么是管道
- 2、匿名管道pipe
- (1)匿名管道的原理
- (2)pipe函数
- (3)管道实现进程间通信
- (4)匿名管道的特点
- (i)管道只能用于具有血缘关系的进程进行通信
- (ii)管道内部自带同步与互斥机制
- (iii)管道提供面向流式的通信服务 —— 面向字节流
- (iv)管道是基于文件的
- (v)管道是单向通信的
- (vi)管道能够保证一定程度的数据读取的原子性
- (3)匿名管道的四种特殊情况
- (4)管道的大小
- (5)管道的通讯场景--- 进程池
- 3、命名管道
- (1)命名管道的原理
- (2)使用命令行创建命名管道
- (3)用命名管道实现serve&client通信
- (4)匿名管道与命名管道的比较
- 三、system V进程间通信
- 1、system V共享内存
- (1)共享内存的基本原理
- (2)共享内存数据结构
- (3)共享内存的建立与释放
- (4)共享内存的创建---shmget
- (5)共享内存的释放
- (i)使用命令释放共享内存资源---ipcrm
- (ii)使用程序释放共享内存资源--- shmctl
- (6)共享内存的关联---shmat
- (7)共享内存的去关联--- shmdt
- (8)用共享内存实现serve&client通信
- (9)借助管道实现访问控制版的共享内存
- 2、System V —— 消息队列(了解)
- (1)消息队列的基本原理
- (2)消息队列数据结构
- (3)接口
- (i)消息队列的创建
- (ii)消息队列的释放
- (iii)向消息队列发送数据
- (v)从消息队列获取数据
- 3、System V —— 信号量(了解)
- (1)相关概念的铺垫
- (2)什么是信号量
- (3)为什么要有信号量
- (4)如何使用信号量
- (5)接口
- (i)信号量集的创建
- (ii)信号量集的删除
- (iii)信号量集的操作
- 4、内核是如何组织管理IPC资源的
前言
如何理解进程间通信?
进程具有独立性,所以进程想要通信难度是比较大的,成本高。
在日常生活中,通信的本质是传递信息,但站在程序员角度来看,进程间通信的本质:让不同的进程看到同一份资源(内存空间)。
进程间通信就是进程之间互相传递数据,那么进程间能直接相互传递数据吗?
不能,因为进程具有独立性,所有的数据操作都会发生写时拷贝,父子进程都不能传递,更不要说两个进程毫无关系还想直接相互传递数据。
所以两个进程如果想要通信就一定要通过中间媒介的方式来进行通信,那么就必须先想办法让不同的进程看到同一份公共的资源,这里所谓公共的资源就是系统通过某种方式提供的系统内存。 这块空间通常是由操作系统提供的,可以被两个不同的进程都看到,然后它们才能实现通信。
传递数据就是由一个进程拷到对应的内存里,这块内存另一个进程当然也能看到,所以也自然能从内存里拷到自己的进程中。
综上所述,我们就知道了进程间通信要学的就是如何通过系统,让不同的进程看到同一份资源。操作系统提供的通信方案有很多种,这句话的含义就是操作系统让不同进程看到同一份资源的方式有很多种,最典型的有管道、消息队列、共享内存、信号量等等。下面主要谈管道和共享内存,而信号量会在后面多线程的部分再展开,这里主要以概念为主。
所以进程间通信的本质就是让不同的进程,能看到同一份系统资源,而这份资源就是系统通过某种方式提供的系统内存,因为方式是有差别的,所以通信策略也是有差别的。
一、进程间通信介绍
1、进程间通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程(可以理解为一个进程将数据加工成半成品通过某种通信方式给到另一个进程,另一个进程再做加工)。
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如 Debug 进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
为什么要进行进程间通信?
往往是出于交互数据、控制、通知等目的。
2、进程间通信发展
在进程间通信发展的过程主要有两种流派,一种是只在主机上通信,就是 System V,另一种是可以在主机上的进程跨网络通信,就是 POSIX。下面主要学习 System V,等到后面网络部分再学习 POSIX。
管道是操作系统本身提供的,所以这里能接触到的是管道和 System V 进程间的通信方式。
- 管道
- System V 进程间通信
- POSIX 进程间通信
3、进程间通信的分类
(1)管道
- 匿名管道 pipe
- 命名管道
(2)System V IPC
主要用于单机通信。
System V 消息队列
System V 共享内存(不常用)
System V 信号量(了解原理)
(3)POSIX IPC
主要用于网络通信。
消息队列
共享内存
信号量
互斥量
条件变量
读写锁
上面这些分类的标准在我们使用者看来,都是接口上具有一定的规律。
4、进程间通信的必要性
单进程无法使用并发能力,也无法实现多进程协同。
进程间通信有很多目的,比如:传输数据、同步执行流、消息通知等,就是为了实现多进程协同。
进程间通信不是目的,只是一种手段。
5、进程间通信的技术背景
- 进程是具有独立性的。进程是通过虚拟地址空间 + 页表来保证进程运行的独立性(进程内核数据结构 + 进程的代码和数据)。
- 通信成本较高,进程本身就已经具有独立性了,这时要让不同进程看到同一份资源,肯定不容易。
6、进程间通信的本质理解
进程间通信的前提是:首先要让不同的进程看到同一块“内存”(特定的结构组织的)。
那么我们所谓的进程看到同一块 “内存”是属于哪一个进程呢?—— 不能隶属于任何一个进程,而应该更强调共享。
二、管道
1、什么是管道
现实生活中也存在着很多管道,它们的共同点是:都有一个入口和一个出口(最典型的特点:只能单向通信),在这其中就传送着人们所需要的自来水、石油资源等。
而互联网中的管道传送的是数据资源,所以计算机就模拟出一条管道。数据资源一定是有人想传入,并且有人想获取,那么这里的有人就分别对应发送进程和接受进程。
现实中构建管道所使用的材料是钢铁,而计算机中构建管道缓冲区所使用的材料是系统内存,而这里的系统内存就是让不同进程所看到的同一块系统资源。上面所说的概念只是一种感性的理解,还没有涉及到任何的系统概念,归根结底是想让大家明白不同角色的定位。
管道是 Unix 中最古老的进程间通信的形式。
我们把从一个进程连接到另一个进程的一个数据流称为一个 “管道”。
例如,统计我们当前使用云服务器上的登录用户个数。

其中,who命令和wc命令都是两个程序,当它们运行起来后就变成了两个进程,who进程通过标准输出将数据打到“管道”当中,wc进程再通过标准输入从“管道”当中读取数据,至此便完成了数据的传输,进而完成数据的进一步加工处理。

注意: who命令用于查看当前云服务器的登录用户(一行显示一个用户),wc -l用于统计当前的行数。
管道不能是进程 A 或进程 B 提供的,一定是操作系统提供的,只是两个进程恰好利用某种方式通过管道来进行通信。任何的中间资源不能隶属于某一个进程,因为进程具有独立性,一旦某种中间通信资源隶属于某个进程,那么其它进程一定不能看到。
管道一共有两种通信方案:匿名管道和命名管道。它们的底层原理基本上是一样的,区别在于它们各自的侧重点不同。
2、匿名管道pipe
匿名管道是供具有血缘关系的进程进行进程间通信,常用于父子进程之间。 即便是父子,它们的数据也不是共享的,而是私有的,凡是共享的都是因为双方都不写入罢了。
所有的通信方式,特别是进程间通信,首先是得保证不同的进程看到同一份资源。匿名管道就是这个管道没有名字,它也不需要,匿名管道是由子进程继承父进程的文件描述符中的内容来的。

补充:进程退出,那么曾经打开的文件也会被关闭(因为进程中保存着打开文件的相关数据结构,而进程退出后,文件就自然会被关闭)。同样,管道也是文件,所以管道的生命周期就是进程的生命周期。
怎么保证父子进程看到同一份资源呢?
我们已经对文件描述符很熟悉了,它和管道强相关的,这里要强调的是:在 struct file 之后是提供文件的方法和缓冲区的。

要回答这个问题,我们就要讲:
(1)匿名管道的原理
匿名管道用于进程间通信,且仅限于本地父子进程之间的通信。
进程间通信的本质就是,让不同的进程看到同一份资源,使用匿名管道实现父子进程间通信的原理就是,让两个父子进程先看到同一份被打开的文件资源,然后父子进程就可以对该文件进行写入或是读取操作,进而实现父子进程间通信。

注意:
- 这里父子进程看到的同一份文件资源是由操作系统来维护的,所以当父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝。
- 管道虽然用的是文件的方案,但操作系统一定不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率,而且也没有必要。也就是说,这种文件是一批不会把数据写到磁盘当中的文件,换句话说,磁盘文件和内存文件不一定是一一对应的,有些文件只会在内存当中存在,而不会在磁盘当中存在,像临时文件一样,不会有磁盘级路径,不会有文件名所以也是为什么叫匿名管道。

(2)pipe函数
pipe函数用于创建匿名管道,pip函数的函数原型如下:
int pipe(int pipefd[2]);
pipe函数的参数是一个输出型参数,数组pipefd用于返回两个指向管道读端和写端的文件描述符:
| 数组元素 | 含义 |
|---|---|
| pipefd[0] | 管道读端的文件描述符 |
| pipefd[1] | 管道写端的文件描述符 |
(3)管道实现进程间通信
在创建匿名管道实现父子进程间通信的过程中,需要pipe函数和fork函数搭配使用,具体步骤如下:
1、父进程调用pipe函数创建管道。



2、父进程 fork 子进程

3、父进程写,子进程读,通常 fd[0] 对应 read,fd[1] 对应 write,子进程关闭 fd[1],父进程关闭 fd[0],再让父进程等待子进程

4、父进程读,子进程写
代码演示:
//child->write, father->read
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{int fd[2] = { 0 };if (pipe(fd) < 0){ //使用pipe创建匿名管道perror("pipe");return 1;}pid_t id = fork(); //使用fork创建子进程if (id == 0){//childclose(fd[0]); //子进程关闭读端//子进程向管道写入数据const char* msg = "hello father, I am child...";int count = 10;while (count--){write(fd[1], msg, strlen(msg));sleep(1);}close(fd[1]); //子进程写入完毕,关闭文件exit(0);}//fatherclose(fd[1]); //父进程关闭写端//父进程从管道读取数据char buff[64];while (1){ssize_t s = read(fd[0], buff, sizeof(buff));if (s > 0){buff[s] = '\0';printf("child send to father:%s\n", buff);}else if (s == 0){printf("read file end\n");break;}else{printf("read error\n");break;}}close(fd[0]); //父进程读取完毕,关闭文件waitpid(id, NULL, 0);return 0;
}
(4)匿名管道的特点
(i)管道只能用于具有血缘关系的进程进行通信
它常用父子进程通信
通常,一个管道由一个进程创建,然后该进程调用 fork(),此后父子进程之间就可应用该管道。
(ii)管道内部自带同步与互斥机制
我们将一次只允许一个进程使用的资源,称为临界资源。 管道在同一时刻只允许一个进程对其进行写入或是读取操作,因此管道也就是一种临界资源。
临界资源是需要被保护的,若是我们不对管道这种临界资源进行任何保护机制,那么就可能出现同一时刻有多个进程对同一管道进行操作的情况,进而导致同时读写、交叉读写以及读取到的数据不一致等问题。
为了避免这些问题,内核会对管道操作进行同步与互斥:
- 同步: 两个或两个以上的进程在运行过程中协同步调,按预定的先后次序运行。比如,A任务的运行依赖于B任务产生的数据。
比如:通信双方在管道中,如果其中一方不写了,另一方把数据读完后就必须等待对方写入才可以继续读;反之如果一方写满了,另一方不读,那么一方就必须等待另一方读取后才可以继续写。这种特性就叫做进程间同步,它们两方必须得通过某种同步机制来保证数据安全:管道是内存空间。如果一方不写,另一方还在那读,那么读到的数据肯定是垃圾数据;同样,如果一方一直写入,但另外一方却不读,那就可能会导致原来的数据被覆盖。
- 互斥: 一个公共资源同一时刻只能被一个进程使用,多个进程不能同时使用公共资源。
实际上,同步是一种更为复杂的互斥,而互斥是一种特殊的同步。对于管道的场景来说,互斥就是两个进程不可以同时对管道进行操作,它们会相互排斥,必须等一个进程操作完毕,另一个才能操作,而同步也是指这两个不能同时对管道进行操作,但这两个进程必须要按照某种次序来对管道进行操作。
也就是说,互斥具有唯一性和排它性,但互斥并不限制任务的运行顺序,而同步的任务之间则有明确的顺序关系。
(iii)管道提供面向流式的通信服务 —— 面向字节流
这里先简单理解一下,更进一步理解需要后面学习到网络部分。
流是什么?
下面是一段缓冲区,那么一定要有人去缓冲区中写入和读取。流就是想按几个字节写就按几个字节写,想按几个字节读就按几个字节读。 像这样的缓冲区对于读和写而言,就是字节流。

对于进程A写入管道当中的数据,进程B每次从管道读取的数据的多少是任意的,这种被称为流式服务,与之相对应的是数据报服务:
- 流式服务: 数据没有明确的分割,不分一定的报文段。
- 数据报服务: 数据有明确的分割,拿数据按报文段拿。
(iv)管道是基于文件的
一般而言,进程退出,管道释放,所以管道的生命是随进程的,文件的生命周期也是随进程的。
(v)管道是单向通信的
管道是单向通信的,其本质是半双工通信的一种特殊情况。
在数据通信中,数据在线路上的传送方式可以分为以下三种:
- 单工通信(Simplex Communication):单工模式的数据传输是单向的。通信双方中,一方固定为发送端,另一方固定为接收端。
- 半双工通信(Half Duplex):半双工数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。
- 全双工通信(Full Duplex):全双工通信允许数据在两个方向上同时传输,它的能力相当于两个单工通信方式的结合。全双工可以同时(瞬时)进行信号的双向传输。
举一个生活中的例子:人与人之间交流时一般是半双工(一个人说,一个人听),而在吵架时可能就是全双工(两个人都在说,也都在听)。
(vi)管道能够保证一定程度的数据读取的原子性
如果往管道写 hello world,刚准备写 world,而 hello 就被读走了,此时就不能保证原子性。这里的一定程度一般指的是 4kb。
原子性的详细介绍主要是在后面的多线程部分。
(3)匿名管道的四种特殊情况
在使用管道时,可能出现以下四种特殊情况:
- 写端进程不写,读端进程一直读,那么此时会因为管道里面没有数据可读,管道为空,read会阻塞。
- 读端进程不读,写端进程一直写,那么当管道被写满后,管道为满,write会阻塞。
- 写端进程将数据写完后将写端关闭,那么读端进程会读完管道当中的数据,会读到返回值0,管道角度,表示对端关闭,进程角度,表示子进程退出,文件角度,表示读到文件结尾。
- 读端进程将读端关闭,而写端进程还在一直向管道写入数据,那么操作系统会将写端进程杀掉。此时子进程代码都还没跑完就被终止了,属于异常退出,那么子进程必然收到了某种信号。OS会给目标进程发送什么信号呢?
写入端还在写,读端关闭,此时子进程会触发13)SIGPIPE,子进程会被操作系统杀掉,子进程就会退出,父进程wait等待,会拿到子进程的退出信息,包括退出信号。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{int fd[2] = { 0 };if (pipe(fd) < 0){ //使用pipe创建匿名管道perror("pipe");return 1;}pid_t id = fork(); //使用fork创建子进程if (id == 0){//childclose(fd[0]); //子进程关闭读端//子进程向管道写入数据const char* msg = "hello father, I am child...";int count = 10;while (count--){write(fd[1], msg, strlen(msg));sleep(1);}close(fd[1]); //子进程写入完毕,关闭文件exit(0);}//fatherclose(fd[1]); //父进程关闭写端close(fd[0]); //父进程直接关闭读端(导致子进程被操作系统杀掉)int status = 0;waitpid(id, &status, 0);printf("child get signal:%d\n", status & 0x7F); //打印子进程收到的信号return 0;
}

(4)管道的大小
a. 子进程一直写,每次写一个字节,然后计数器统计,父进程不要读。可以看到结果是 65536 byte,也就是管道的大小是 64kb,不过操作系统不同数据可能不一样

b. ulimit -a 查看系统资源
这里通过计算器算出来结果其实也才 4 kb,而实践出来却是 64kb。这里的 64kb 是当前云服务器管道的最大容量,而这里的 4kb 只是以原子性写入管道中的单元大小(可以通过 man 7 pipe 手册进行查看,可以看到 PIPE_BUF 是 4096 byte(4kb),只要在这个范围内就都是原子的)。


c. 使用man手册
根据man手册,在2.6.11之前的Linux版本中,管道的最大容量与系统页面大小相同,从Linux 2.6.11往后,管道的最大容量是65536字节。
根据man手册,我使用的是Linux 2.6.11之后的版本,因此管道的最大容量是65536字节。
(5)管道的通讯场景— 进程池

3、命名管道
(1)命名管道的原理
匿名管道只能用于具有共同祖先的进程(具有亲缘关系的进程)之间的通信,通常,一个管道由一个进程创建,然后该进程调用fork,此后父子进程之间就可应用该管道。
如果要实现两个毫不相关进程之间的通信,可以使用命名管道来做到。命名管道就是一种特殊类型的文件,两个进程通过命名管道的文件名打开同一个管道文件,此时这两个进程也就看到了同一份资源,进而就可以进行通信了。
注意:
- 普通文件是很难做到通信的,即便做到通信也无法解决一些安全问题。
- 命名管道和匿名管道一样,都是内存文件,只不过命名管道在磁盘有一个简单的映像,但这个映像的大小永远为0,因为命名管道和匿名管道都不会将通信数据刷新到磁盘当中。
(2)使用命令行创建命名管道
我们可以使用mkfifo命令创建一个命名管道。
syc@VM-4-17-ubuntu:~/linux/lesson24$ mkfifo fifo

可以看到,创建出来的文件的类型是p,代表该文件是命名管道文件。

使用这个命名管道文件,就能实现两个进程之间的通信了。我们在一个进程(进程A)中用shell脚本每秒向命名管道写入一个字符串,在另一个进程(进程B)当中用cat命令从命名管道当中进行读取。

(3)用命名管道实现serve&client通信
服务端的代码如下:
Server.cc:
#include "Server.hpp"
#include <iostream>int main()
{Server server;std::cout << "pos 1" << std::endl;server.OpenPipeForRead();std::cout << "pos 2" << std::endl;std::string message;while (true){if (server.RecvPipe(&message) > 0){std::cout << "client Say# " << message << std::endl;}else{break;}std::cout << "pos 3" << std::endl;}std::cout << "client quit, me too!" << std::endl;server.ClosePipe();return 0;
}
Server.hpp:
#pragma once
#include <iostream>
#include "Comm.hpp"class Init
{
public:Init(){umask(0);int n = ::mkfifo(gpipeFile.c_str(), gmode);if (n < 0){std::cerr << "mkfifo error" << std::endl;return;}std::cout << "mkfifo success" << std::endl;// sleep(10);}~Init(){int n = ::unlink(gpipeFile.c_str());if (n < 0){std::cerr << "unlink error" << std::endl;return;}std::cout << "unlink success" << std::endl;}
};Init init;class Server
{
public:Server():_fd(gdefultfd){}bool OpenPipeForRead(){_fd = OpenPipe(gForRead);if(_fd < 0) return false;return true;}// std::string *: 输出型参数// const std::string &: 输入型参数// std::string &: 输入输出型参数int RecvPipe(std::string *out){char buffer[gsize];ssize_t n = ::read(_fd, buffer, sizeof(buffer)-1);if(n > 0){buffer[n] = 0;*out = buffer;}return n;}void ClosePipe(){ClosePipeHelper(_fd);}~Server(){}
private:int _fd;
};
客户端的代码如下:
Client.cc
#include "Client.hpp"
#include <iostream>int main()
{Client client;client.OpenPipeForWrite();std::string message;while(true){std::cout << "Please Enter# ";std::getline(std::cin, message);client.SendPipe(message);}client.ClosePipe();return 0;
}
Client.hpp:
#pragma once
#include <iostream>
#include "Comm.hpp"class Client
{
public:Client():_fd(gdefultfd){}bool OpenPipeForWrite(){_fd = OpenPipe(gForWrite);if(_fd < 0) return false;return true;}// std::string *: 输出型参数// const std::string &: 输入型参数// std::string &: 输入输出型参数int SendPipe(const std::string &in){return ::write(_fd, in.c_str(), in.size());}void ClosePipe(){ClosePipeHelper(_fd);}~Client(){}
private:int _fd;
};
管道代码:
#pragma once#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>const std::string gpipeFile = "./fifo";
const mode_t gmode = 0600;
const int gdefultfd = -1;
const int gsize = 1024;
const int gForRead = O_RDONLY;
const int gForWrite = O_WRONLY;int OpenPipe(int flag)
{// 如果读端打开文件时,写端还没打开,读端对用的open就会阻塞int fd = ::open(gpipeFile.c_str(), flag);if (fd < 0){std::cerr << "open error" << std::endl;}return fd;
}void ClosePipeHelper(int fd)
{if (fd >= 0)::close(fd);
}
Makefile:
SERVER=server
CLIENT=client
CC=g++
SERVER_SRC=Server.cc
Client_SRC=Client.cc.PHONY:all
all:$(SERVER) $(CLIENT)$(SERVER):$(SERVER_SRC)$(CC) -o $@ $^ -std=c++11
$(CLIENT):$(Client_SRC)$(CC) -o $@ $^ -std=c++11.PHONY:clean
clean:rm -f $(SERVER) $(CLIENT)
(4)匿名管道与命名管道的比较
- 匿名管道是供具有血缘关系的进程进行进程间通信;命名管道可供非具有血缘关系的进程进行进程间通信。
- 让不同进程看到同一份资源的手段不一样,匿名管道是通过子进程继承的方式(父子共享文件的特征让进程看到同一份资源);命名管道是通过打开同一目录的方式(命名管道是文件路径具有唯一性的特征)。
- pipe 创建的管道文件因为没有名字,所以它只能在在内存上;fifo 创建的管道文件有名字,所以它在磁盘上,只不过不会把数据写到磁盘上。
- FIFO(命名管道)与 pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。匿名管道由 pipe 函数创建并打开,命名管道由 mkfifo 函数创建,打开用 open。
三、system V进程间通信
管道通信本质是基于文件的,也就是说操作系统并没有为此做过多的设计工作,而system V IPC是操作系统特地设计的一种通信方式。但是不管怎么样,它们的本质都是一样的,都是在想尽办法让不同的进程看到同一份由操作系统提供的资源。
system V IPC提供的通信方式有以下三种:
- system V共享内存
- system V消息队列
- system V信号量
其中,system V共享内存和system V消息队列是以传送数据为目的的,而system V信号量是为了保证进程间的同步与互斥而设计的,虽然system V信号量和通信好像没有直接关系,但属于通信范畴。
说明一下:
system V共享内存和system V消息队列就类似于手机,用于沟通信息;system V信号量就类似于下棋比赛时用的棋钟,用于保证两个棋手之间的同步与互斥。
1、system V共享内存
(1)共享内存的基本原理
共享内存让不同进程看到同一份资源的方式就是,在物理内存当中申请一块内存空间,然后将这块内存空间分别与各个进程各自的页表之间建立映射,再在虚拟地址空间当中开辟空间并将虚拟地址填充到各自页表的对应位置,使得虚拟地址和物理地址之间建立起对应关系,至此这些进程便看到了同一份物理内存,这块物理内存就叫做共享内存。

注意:
这里所说的开辟物理空间、建立映射等操作都是调用系统接口完成的,也就是说这些动作都由操作系统来完成。
(2)共享内存数据结构
在系统当中可能会有大量的进程在进行通信,因此系统当中就可能存在大量的共享内存,那么操作系统必然要对其进行管理,所以共享内存除了在内存当中真正开辟空间之外,系统一定还要为共享内存维护相关的内核数据结构。
共享内存的数据结构如下:
struct shmid_ds {struct ipc_perm shm_perm; /* operation perms */int shm_segsz; /* size of segment (bytes) */__kernel_time_t shm_atime; /* last attach time */__kernel_time_t shm_dtime; /* last detach time */__kernel_time_t shm_ctime; /* last change time */__kernel_ipc_pid_t shm_cpid; /* pid of creator */__kernel_ipc_pid_t shm_lpid; /* pid of last operator */unsigned short shm_nattch; /* no. of current attaches */unsigned short shm_unused; /* compatibility */void *shm_unused2; /* ditto - used by DIPC */void *shm_unused3; /* unused */
};
当我们申请了一块共享内存后,为了让要实现通信的进程能够看到同一个共享内存,因此每一个共享内存被申请时都有一个key值,这个key值用于标识系统中共享内存的唯一性。
可以看到上面共享内存数据结构的第一个成员是shm_perm,shm_perm是一个ipc_perm类型的结构体变量,每个共享内存的key值存储在shm_perm这个结构体变量当中,其中ipc_perm结构体的定义如下:
struct ipc_perm{__kernel_key_t key;__kernel_uid_t uid;__kernel_gid_t gid;__kernel_uid_t cuid;__kernel_gid_t cgid;__kernel_mode_t mode;unsigned short seq;
};
注: 共享内存的数据结构shmid_ds和ipc_perm结构体分别在/usr/include/linux/shm.h和/usr/include/linux/ipc.h中定义。
(3)共享内存的建立与释放
- 共享内存的建立大致包括以下两个过程:
- 在物理内存当中申请共享内存空间。
- 将申请到的共享内存挂接到地址空间,即建立映射关系。
- 共享内存的释放大致包括以下两个过程:
- 将共享内存与地址空间去关联,即取消映射关系。
- 释放共享内存空间,即将物理内存归还给系统。
(4)共享内存的创建—shmget
创建共享内存我们需要用shmget函数,shmget函数的函数原型如下:
int shmget(key_t key, size_t size, int shmflg);
1. shmget函数的参数说明:
- 第一个参数key,表示待创建共享内存在系统当中的唯一标识。
- 第二个参数size,表示待创建共享内存的大小。
- 第三个参数shmflg,表示创建共享内存的方式。
传入shmget函数的第一个参数key,需要我们使用ftok函数进行获取
ftok函数的函数原型如下:
key_t ftok(const char *pathname, int proj_id);
ftok函数的作用就是,将一个已存在的路径名pathname和一个整数标识符proj_id转换成一个key值,称为IPC键值,在使用shmget函数获取共享内存时,这个key值会被填充进维护共享内存的数据结构当中。需要注意的是,pathname所指定的文件必须存在且可存取。
注意:
1.使用ftok函数生成key值可能会产生冲突,此时可以对传入ftok函数的参数进行修改。
2.需要进行通信的各个进程,在使用ftok函数获取key值时,都需要采用同样的路径名和和整数标识符,进而生成同一种key值,然后才能找到同一个共享资源。
传入shmget函数的第三个参数shmflg,常用的组合方式有以下两种:
| 组合方式 | 作用 |
|---|---|
| IPC_CREAT | 如果内核中不存在键值与key相等的共享内存,则新建一个共享内存并返回该共享内存的句柄;如果存在这样的共享内存,则直接返回该共享内存的句柄 |
| IPC_CREAT | IPC_EXCL |
换句话说:
使用组合IPC_CREAT,一定会获得一个共享内存的句柄,但无法确认该共享内存是否是新建的共享内存。
使用组合IPC_CREAT | IPC_EXCL,只有shmget函数调用成功时才会获得共享内存的句柄,并且该共享内存一定是新建的共享内存。
2. shmget函数的返回值说明:
- shmget调用成功,返回一个有效的共享内存标识符(用户层标识符)。
- shmget调用失败,返回-1。
注意: 我们把具有标定某种资源能力的东西叫做句柄,而这里shmget函数的返回值实际上就是共享内存的句柄,这个句柄可以在用户层标识共享内存,当共享内存被创建后,我们在后续使用共享内存的相关接口时,都是需要通过这个句柄对指定共享内存进行各种操作。
至此我们就可以使用ftok和shmget函数创建一块共享内存了,创建后我们可以将共享内存的key值和句柄进行打印,以便观察,代码如下:
Client.cc:
#include <iostream>
#include "Comm.hpp"int main()
{key_t k = ::ftok(gpath.c_str(), gprojId);std::cout << "k : " << ToHex(k) << std::endl;return 0;
}
Comm.hpp:
#pragma once#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>const std::string gpath = "/home/whb/code";
int gprojId = 0x6666;
int gshmsize = 4096;std::string ToHex(key_t k)
{char buffer[64];snprintf(buffer, sizeof(buffer), "0x%x", k);return buffer;
}
Server.cc:
#include <iostream>
#include <unistd.h>
#include "Comm.hpp"int main()
{// 1. 创建Keykey_t k = ::ftok(gpath.c_str(), gprojId);if(k < 0){std::cerr << "ftok error" << std::endl;return 1;}std::cout << "k : " << ToHex(k) << std::endl;// 2. 创建共享内存 && 获取int shmid = ::shmget(k, gshmsize, IPC_CREAT | IPC_EXCL);if(shmid < 0){std::cerr << "shmget error" << std::endl;return 2;}std::cout << "shmid: " << shmid << std::endl;return 0;
}
Makefile:
SERVER=server
CLIENT=client
CC=g++
SERVER_SRC=Server.cc
Client_SRC=Client.cc.PHONY:all
all:$(SERVER) $(CLIENT)$(SERVER):$(SERVER_SRC)$(CC) -o $@ $^ -std=c++11
$(CLIENT):$(Client_SRC)$(CC) -o $@ $^ -std=c++11.PHONY:clean
clean:rm -f $(SERVER) $(CLIENT)
Linux当中,我们可以使用ipcs命令查看有关进程间通信设施的信息。

单独使用ipcs命令时,会默认列出消息队列、共享内存以及信号量相关的信息,若只想查看它们之间某一个的相关信息,可以选择携带以下选项:
- -q:列出消息队列相关信息。
- -m:列出共享内存相关信息。
- -s:列出信号量相关信息。
例如,携带-m选项查看共享内存相关信息:

此时,根据ipcs命令的查看结果和我们的输出结果可以确认,共享内存已经创建成功了。
ipcs命令输出的每列信息的含义如下:
| 标题 | 含义 |
|---|---|
| key | 系统区别各个共享内存的唯一标识 |
| shmid | 共享内存的用户层id(句柄) |
| owner | 共享内存的拥有者 |
| perms | $1 |
| bytes | 共享内存的大小 |
| nattch | 关联共享内存的进程数 |
| status | 共享内存的状态 |
注意: key是在内核层面上保证共享内存唯一性的方式,而shmid是在用户层面上保证共享内存的唯一性,key和shmid之间的关系类似于fd和FILE*之间的的关系。
(5)共享内存的释放
通过上面创建共享内存的实验可以发现,当我们的进程运行完毕后,申请的共享内存依旧存在,并没有被操作系统释放。实际上,管道是生命周期是随进程的,而共享内存的生命周期是随内核的,也就是说进程虽然已经退出,但是曾经创建的共享内存不会随着进程的退出而释放。
这说明,如果进程不主动删除创建的共享内存,那么共享内存就会一直存在,直到关机重启(system V IPC都是如此),同时也说明了IPC资源是由内核提供并维护的。
此时我们若是要将创建的共享内存释放,有两个方法,一就是使用命令释放共享内存,二就是在进程通信完毕后调用释放共享内存的函数进行释放。
(i)使用命令释放共享内存资源—ipcrm
我们可以使用ipcrm -m shmid命令释放指定id的共享内存资源。

注意: 指定删除时使用的是共享内存的用户层id,即列表当中的shmid。
(ii)使用程序释放共享内存资源— shmctl
控制共享内存我们需要用shmctl函数,shmctl函数的函数原型如下:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
- shmctl函数的参数说明:
- 第一个参数shmid,表示所控制共享内存的用户级标识符。
- 第二个参数cmd,表示具体的控制动作。
- 第三个参数buf,用于获取或设置所控制共享内存的数据结构。
- shmctl函数的返回值说明:
- shmctl调用成功,返回0。
- shmctl调用失败,返回-1。
其中,作为shmctl函数的第二个参数传入的常用的选项有以下三个:
| 选项 | 作用 |
|---|---|
| IPC_ | STAT 获取共享内存的当前关联值,此时参数buf作为输出型参数 |
| IPC_SET | 在进程有足够权限的前提下,将共享内存的当前关联值设置为buf所指的数据结构中的值 |
| IPC_RMID | 删除共享内存段 |
例如,在以下代码当中,共享内存被创建,两秒后程序自动移除共享内存,再过两秒程序就会自动退出。
#include <iostream>
#include <unistd.h>
#include "Comm.hpp"int main()
{// 1. 创建Keykey_t k = ::ftok(gpath.c_str(), gprojId);if(k < 0){std::cerr << "ftok error" << std::endl;return 1;}std::cout << "k : " << ToHex(k) << std::endl;// 2. 创建共享内存 && 获取int shmid = ::shmget(k, gshmsize, IPC_CREAT | IPC_EXCL);if(shmid < 0){std::cerr << "shmget error" << std::endl;return 2;}std::cout << "shmid: " << shmid << std::endl;sleep(10);// 3. 删除共享内存shmctl(shmid, IPC_RMID, nullptr);return 0;
}
我们可以在程序运行时,使用以下监控脚本时刻关注共享内存的资源分配情况:
syc@VM-4-17-ubuntu:~/linux/lesson25$ while :; do ipcs -m;echo "###################################";sleep 1;done
通过监控脚本可以确定共享内存确实创建并且成功释放了。

(6)共享内存的关联—shmat
将共享内存连接到进程地址空间我们需要用shmat函数,shmat函数的函数原型如下:
void *shmat(int shmid, const void *shmaddr, int shmflg);
- shmat函数的参数说明:
- 第一个参数shmid,表示待关联共享内存的用户级标识符。
- 第二个参数shmaddr,指定共享内存映射到进程地址空间的某一地址,通常设置为NULL,表示让内核自己决定一个合适的地址位置。
- 第三个参数shmflg,表示关联共享内存时设置的某些属性。
- shmat函数的返回值说明:
- shmat调用成功,返回共享内存映射到进程地址空间中的起始地址。
- shmat调用失败,返回(void*)-1。
其中,作为shmat函数的第三个参数传入的常用的选项有以下三个:
| 选项 | 作用 |
|---|---|
| SHM_RDONLY | 关联共享内存后只进行读取操作 |
| SHM_RND | 若shmaddr不为NULL,则关联地址自动向下调整为SHMLBA的整数倍。公式:shmaddr-(shmaddr%SHMLBA) |
| 0 | 默认为读写权限项目 |
这时我们可以尝试使用shmat函数对共享内存进行关联。
#include <iostream>
#include <unistd.h>
#include "Comm.hpp"int main()
{// 1. 创建Keykey_t k = ::ftok(gpath.c_str(), gprojId);if(k < 0){std::cerr << "ftok error" << std::endl;return 1;}std::cout << "k : " << ToHex(k) << std::endl;// 2. 创建共享内存 && 获取int shmid = ::shmget(k, gshmsize, IPC_CREAT | IPC_EXCL);if(shmid < 0){std::cerr << "shmget error" << std::endl;return 2;}std::cout << "shmid: " << shmid << std::endl;sleep(5);shmat(shmid, nullptr, 0);std::cout << "attch done" << std::endl;sleep(5);// 3. 删除共享内存shmctl(shmid, IPC_RMID, nullptr);std::cout << "delete shm done" << std::endl;sleep(5);return 0;
}
nattch就是number attch,代表多少个进程和共享内存相关联。我们可以发现attch done了,但是nattch还还是0。

我们用ret接收一下shmat的返回也可以看到返回值为-1。
void *ret = shmat(shmid, nullptr, 0);
std::cout << "attch done" << (long long)ret << std::endl;
主要原因是我们使用shmget函数创建共享内存时,并没有对创建的共享内存设置权限,所以创建出来的共享内存的默认权限为0,即什么权限都没有,因此server进程没有权限关联该共享内存。
我们应该在使用shmget函数创建共享内存时,在其第三个参数处设置共享内存创建后的权限,权限的设置规则与设置文件权限的规则相同。
mode_t gmode = 0600;
int shmid = ::shmget(k, gshmsize, IPC_CREAT | IPC_EXCL | gmode);
此时再运行程序,即可发现关联该共享内存的进程数由0变成了1,而共享内存的权限显示也不再是0,而是我们设置的600权限。

(7)共享内存的去关联— shmdt
取消共享内存与进程地址空间之间的关联我们需要用shmdt函数,shmdt函数的函数原型如下:
int shmdt(const void *shmaddr);
- shmdt函数的参数说明:
- 待去关联共享内存的起始地址,即调用shmat函数时得到的起始地址。
- shmdt函数的返回值说明:
- shmdt调用成功,返回0。
- shmdt调用失败,返回-1。
现在我们就能够取消共享内存与进程之间的关联了。
#include <iostream>
#include <unistd.h>
#include "Comm.hpp"int main()
{// 1. 创建Keykey_t k = ::ftok(gpath.c_str(), gprojId);if(k < 0){std::cerr << "ftok error" << std::endl;return 1;}std::cout << "k : " << ToHex(k) << std::endl;// 2. 创建共享内存 && 获取int shmid = ::shmget(k, gshmsize, IPC_CREAT | IPC_EXCL | gmode);if(shmid < 0){std::cerr << "shmget error" << std::endl;return 2;}std::cout << "shmid: " << shmid << std::endl;sleep(5);//3. 共享内存挂接到自己的地址空间中void *ret = shmat(shmid, nullptr, 0);std::cout << "attch done: " << (long long)ret << std::endl;//这是不能用int强转ret因为系统64位,char*八个字节,int4个字节,强转有精度损失sleep(5);::shmdt(ret);std::cout << "detach done: "<<std::endl;sleep(5);// 4. 删除共享内存shmctl(shmid, IPC_RMID, nullptr);std::cout << "delete shm done" << std::endl;sleep(5);return 0;
}
运行程序,通过监控即可发现该共享内存的关联数由1变为0的过程,即取消了共享内存与该进程之间的关联。

注意: 将共享内存段与当前进程脱离不等于删除共享内存,只是取消了当前进程与该共享内存之间的联系。
(8)用共享内存实现serve&client通信
Client.cc:
#include <iostream>
#include "ShareMemory.hpp"
int main()
{shm.GetShm();shm.AttachShm();// 在这里进行IPCchar *strinfo = (char*)shm.GetAddr();// std::cout << "client 虚拟地址: " << strinfo << std::endl;// printf("server 虚拟地址: %p\n", strinfo);char ch = 'A';while(ch <= 'Z'){sleep(3);strinfo[ch-'A'] = ch;// 这里操作shm的时候,怎么没有用系统调用???用read或wrrite在文件缓冲区操作//因为管道用的文件描述符,没有指针概念,用的struct file那套,必须要用系统调用文件读写,因此这里没有必要ch++;// ch++;}shm.DetachShm();return 0;
}
Server.cc:
#include <iostream>
#include <unistd.h>
#include "ShareMemory.hpp"int main()
{shm.CreateShm();shm.AttachShm();// 在这里进行IPCchar *strinfo = (char*)shm.GetAddr();// std::cout << "server 虚拟地址: " << strinfo << std::endl;// printf("server 虚拟地址: %p\n", strinfo);while(true){printf("%s\n", strinfo);sleep(1);}shm.DetachShm();shm.DeleteShm();return 0;
}
ShareMemory.hpp:
#pragma once#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <stdalign.h>
#include <unistd.h>const std::string gpath = "/home/syc/linux/lesson25";
int gprojId = 0x6666;
// 操作系统,申请空间,是按照块为单位的:4KB,1KB, 2KB, 4MB
int gshmsize = 4096;
mode_t gmode = 0600;std::string ToHex(key_t k)
{char buffer[64];snprintf(buffer, sizeof(buffer), "0x%x", k);return buffer;
} class ShareMemory
{
private:void CreateShmHelper(int shmflg){ _key = ::ftok(gpath.c_str(), gprojId);if (_key < 0){std::cerr << "ftok error" << std::endl;return;}_shmid = ::shmget(_key, gshmsize, shmflg);if (_shmid < 0){std::cerr << "shmget error" << std::endl;return;}std::cout << "shmid: " << _shmid << std::endl;}public:ShareMemory():_shmid(-1),_key(0),_addr(nullptr){}~ShareMemory() {}void CreateShm(){if(_shmid == -1)CreateShmHelper(IPC_CREAT | IPC_EXCL | gmode);}void GetShm(){CreateShmHelper(IPC_CREAT);}void AttachShm(){_addr = shmat(_shmid, nullptr, 0); // 为什么会失败???if ((long long)_addr == -1){std::cout << "attach error" << std::endl;}}void DetachShm(){if(_addr != nullptr)::shmdt(_addr);std::cout << "detach done: " << std::endl;}void DeleteShm(){shmctl(_shmid, IPC_RMID, nullptr);}void *GetAddr(){return _addr;}void ShmMeta(){//TODO}private:int _shmid;key_t _key;void *_addr;
};//临时
ShareMemory shm;
Makefile:
SERVER=server
CLIENT=client
CC=g++
SERVER_SRC=Server.cc
Client_SRC=Client.cc.PHONY:all
all:$(SERVER) $(CLIENT)$(SERVER):$(SERVER_SRC)$(CC) -o $@ $^ -std=c++11
$(CLIENT):$(Client_SRC)$(CC) -o $@ $^ -std=c++11.PHONY:clean
clean:rm -f $(SERVER) $(CLIENT)
注意: 共享内存没有进⾏同步与互斥! 共享内存缺乏访问控制!会带来并发问题。
(9)借助管道实现访问控制版的共享内存
共享内存需要保护,但我们又没有学习锁。但管道具有保护机制,因此我们借助管道模拟进程间同步。
**原理:**利用两个管道完成进程间同步,一个管道的read端读,当管道里没东西时就会阻塞,此时write端就可以访问共享内存,等访问完,write内容进管道,此时的read端就类似被唤醒,轮到read端访问共享内存,此时的write端读取第二个管道,同样会阻塞,等待刚刚的read端读完共享内存write内容进第二个管道,完成同步。

2、System V —— 消息队列(了解)
(1)消息队列的基本原理
消息队列实际上就是在系统当中创建了一个队列,队列当中的每个成员都是一个数据块,这些数据块都由类型和信息两部分构成,两个互相通信的进程通过某种方式看到同一个消息队列,这两个进程向对方发数据时,都在消息队列的队尾添加数据块,这两个进程获取数据块时,都在消息队列的队头取数据块。

其中消息队列当中的某一个数据块是由谁发送给谁的,取决于数据块的类型。
总结一下:
- 消息队列提供了一个从一个进程向另一个进程发送数据块的方法。
- 每个数据块都被认为是有一个类型的,接收者进程接收的数据块可以有不同的类型值。
- 和共享内存一样,消息队列的资源也必须自行删除,否则不会自动清除,因为system V IPC资源的生命周期是随内核的。
(2)消息队列数据结构
当然,系统当中也可能会存在大量的消息队列,系统一定也要为消息队列维护相关的内核数据结构。
消息队列的数据结构如下:
struct msqid_ds {struct ipc_perm msg_perm;struct msg *msg_first; /* first message on queue,unused */struct msg *msg_last; /* last message in queue,unused */__kernel_time_t msg_stime; /* last msgsnd time */__kernel_time_t msg_rtime; /* last msgrcv time */__kernel_time_t msg_ctime; /* last change time */unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */unsigned long msg_lqbytes; /* ditto */unsigned short msg_cbytes; /* current number of bytes on queue */unsigned short msg_qnum; /* number of messages in queue */unsigned short msg_qbytes; /* max number of bytes on queue */__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
可以看到消息队列数据结构的第一个成员是msg_perm,它和shm_perm是同一个类型的结构体变量,ipc_perm结构体的定义如下:
struct ipc_perm{__kernel_key_t key;__kernel_uid_t uid;__kernel_gid_t gid;__kernel_uid_t cuid;__kernel_gid_t cgid;__kernel_mode_t mode;unsigned short seq;
};
记录一下:
共享内存的数据结构msqid_ds和ipc_perm结构体分别在/usr/include/linux/msg.h和/usr/include/linux/ipc.h中定义。
(3)接口
(i)消息队列的创建
创建消息队列我们需要用msgget函数,msgget函数的函数原型如下:
int msgget(key_t key, int msgflg);
说明一下:
- 创建消息队列也需要使用ftok函数生成一个key值,这个key值作为msgget函数的第一个参数。
- msgget函数的第二个参数,与创建共享内存时使用的shmget函数的第三个参数相同。
- 消息队列创建成功时,msgget函数返回的一个有效的消息队列标识符(用户层标识符)。
(ii)消息队列的释放
释放消息队列我们需要用msgctl函数,msgctl函数的函数原型如下:
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
说明一下:
msgctl函数的参数与释放共享内存时使用的shmctl函数的三个参数相同,只不过msgctl函数的第三个参数传入的是消息队列的相关数据结构。
(iii)向消息队列发送数据
向消息队列发送数据我们需要用msgsnd函数,msgsnd函数的函数原型如下:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
- msgsnd函数的参数说明:
- 第一个参数msqid,表示消息队列的用户级标识符。
- 第二个参数msgp,表示待发送的数据块。
- 第三个参数msgsz,表示所发送数据块的大小
- 第四个参数msgflg,表示发送数据块的方式,一般默认为0即可。
- msgsnd函数的返回值说明:
- msgsnd调用成功,返回0。
- msgsnd调用失败,返回-1。
其中msgsnd函数的第二个参数必须为以下结构:
struct msgbuf{long mtype; /* message type, must be > 0 */char mtext[1]; /* message data */
};
注意: 该结构当中的第二个成员mtext即为待发送的信息,当我们定义该结构时,mtext的大小可以自己指定。
(v)从消息队列获取数据
从消息队列获取数据我们需要用msgrcv函数,msgrcv函数的函数原型如下:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
- msgrcv函数的参数说明:
- 第一个参数msqid,表示消息队列的用户级标识符。
- 第二个参数msgp,表示获取到的数据块,是一个输出型参数。
- 第三个参数msgsz,表示要获取数据块的大小
- 第四个参数msgtyp,表示要接收数据块的类型。
- msgrcv函数的返回值说明:
- msgsnd调用成功,返回实际获取到mtext数组中的字节数。
- msgsnd调用失败,返回-1。
3、System V —— 信号量(了解)
(1)相关概念的铺垫
信号量主要用于同步和互斥的,下面先铺垫一些概念。信号量跟上面的内容也有一些关联,同时也为后面的多线程部分做铺垫。
进程通信的本质是让进程看到同一份资源,当同一份资源被多进程看到时,极有可能出现当 A 进程正在对空间进行写入时,B 进程就来读取了。如果像管道那样自带同步机制倒也不会产生什么影响,实际上前面所讲的共享内存就是一种读写错乱的机制。
将多个进程同时看到的那一份资源叫做临界资源。 我们仔细观察可以看到,在 server 和 client 中访问共享内存 / 临界资源的代码实际上只有少部分几行。换而言之,造成读写数据不一致问题的可能就是这一部分代码所引起的,我们将这部分访问临界资源的代码叫做临界区,所以为了必免数据不一致的问题,就需要保护临界资源,即对临界区代码进行某种保护,而这某种保护就被称为互斥。
所谓互斥就是有一块空间,在任何时候有且仅能有一个进程在进行访问(生活中最典型的互斥场景就是去上洗手间),互斥本身是一种串行化执行(也就是说,共享内存中就是因为并行读写执行才导致的数据不一致问题),而后面一般互斥是通过锁来完成的,这里可以提一种二元信号量来完成串行执行(我们也能猜到加锁和解锁是有代码的) 。所以串行化的过程本质是对临界区资源加锁和解锁,从而完成互斥操作。也就是说,client 和 server 都必须遵守 “要进入临界区就得加锁,退出临界区就得解锁” 这一原则。
这里再感性的理解一遍原子性概念,其实说白了,就是要么做了,要么没做。比如一个进程想往共享内存里写 “Hello World”,写完 “Hello” 时的这个状态叫做写入中,那么在写入过程中是不能被打搅的,得等到全部写完为止。也就是说,在其他人看来,这里写入过程的状态只有两种,其一是还没写,而其二是写完了,这就是原子性。
最典型的应用就是,假设我们在农商银行里有 1000 元,在建设银行里有 500 元,然后我们想进行转帐:农商账号 -= 200;建设账号 += 200。其中,当我们从农商账号转账到建设账号的时候,系统崩溃了,此时建设银行账号还是 500 元,但是农商银行账号少了 200 元。这个现象说白了就是当某个任务正在进行时,突然因为某些原因而导致任务中断,这就叫做不是原子性。所以这个转账的过程要不就不做,要不就必须得做成功,或者转账失败了也能保证农商账号的钱不受影响,这就是原子性。
我们也可以采用互斥的方案来保证原子性。
- 由于各个进程要求共享资源,而且有些资源需要互斥使用,那么各进程竞争使用这些资源,进程之间的这种关系就叫作进程的互斥。
- 系统中某些资源一次只允许一个进程使用,这样的资源被称为为临界资源或互斥资源。
- 在进程中涉及到互斥资源的程序段叫做临界区。
- 特性:IPC 资源必须删除,否则不会自己清除,除非重启,所以 System V IPC 资源的生命周期随内核。
(2)什么是信号量
信号量也叫做信号灯。举几个例子,假设我们买了一个房子,虽然我们没住在里面,但房子依旧是是属于我们的。在宿舍的时候,虽然没躺着,但是那个床位依旧是属于我们的。我们在网上买电影票看电影,虽然还没到时间去看,但我们很清楚,到了一定的时间我们就能看到。所以现实生活中存在很多 “预定机制”,因为不提前享受,所以在卖票的时候就得保证一人一座,不能超过电影院的承受能力。
这里有三个进程都要访问共享内存,这块共享内存就是这三个进程的临界资源,而要访问共享内存需要加锁,这里进程 A 先访问成功,然后解锁,紧接着进程 B,然后又进程 C,这就是互斥。

信号量的本质是一个计数器 int count(注意:这里的 int count 是错误的,先暂时这样理解,后面再详细解释),然后定义 int count = 3; 还有一段伪代码,任何进程想操作共享内存前必须先申请信号量。然后进程 A 要进来,所以 count- - 之后,count 是 2,而进程 A 要出去,也要对应进行释放信号量,也就是 count++。
这就类似于电影院的预订机制,电影院有 100 张票,我们预定了一张票,那么票数就变成 99 张,当我们看完离开电影院后,票数就变成 100 张。也就是说,申请信号量的本质就是:count- -,就是对临界资源的预定机制,count – 后就一定要有资源给我们预留,而不是 pause,这里一共有 3 个资源,我们已经申请了一个,即使我们还没有开始访问,但最终我们也能访问,这就是一种预订,这就是信号量。所以信号量本质就是计数器,是用来描述临界资源中资源数目的计数器。
(3)为什么要有信号量
有的时候进程并不是把共享内存全部使用,这里的共享内存被分为三块空间,有很多进程。如果想让不同的进程访问不同的共享内存区域,那么它们是不受影响的,但最怕的就是一个进程在访问一块空间的时候,另一个进程也来访问这块空间。这里想说明的是,进程不是对共享内存的整体进行访问,而是可能只使用共享内存中的一部分,所以只要多个进程访问的那部分共享内存是不重叠的,那么就可以并行访问。也就是说,有七八个进程,每个进程都把这个共享内存占有就是互斥,但这显然不太合理,所以允许在访问共享内存不重叠的前提下,可以允许少量进程同时访问,而这样的工作就是由信号量来完成的。

(4)如何使用信号量
每个进程想对共享内存访问都必须先申请信号量,我们称之为p 操作,而访问完之后要执行非临界区代码时要释放信号量,我们称之为 v 操作,所以信号量最重要的操作我们称之为 pv 原语 。


如果同时有 5 个进程都想访问共享内存,都想对计数器进行减减操作,那么下面有两个问题。
多个进程能不能操作同一个 count 值 ?
不能,因为有写时拷贝,我们定义全局变量,甚至 malloc。无论如何,只要子进程去进行操作时,不可能减减加加去影响其它进程的,count 一开始是 3,每个进程写时拷贝都认为是 3。所以信号量 != count,因为必须保证多个进程操作的是同一个信号量。
信号量是干什么的 ?
保护临界资源的安全性。
思考:
假设还认为信号量是一个类似全局变量,且多个进程能操作一个全局变量 count,那么每个进程去执行上面的伪代码不就行了吗 ?
不行。因为申请信号量过程中需要:
进行 if 判断
内存 --> cpu
cpu 执行计算
cpu --> 内存。
而此时进程 A 执行判断成功后,进程 B 已经减到 0 了,进程 A 再减就是 -1,相当于给别人多分配了资源,因为它是多条语句构成,有可能会导致操作乱序,有可能会多分配资源出去,所以就不是原子性的。
- 计算是在 CPU 内的,数据存储在内存的 count 变量里面。
- CPU 在执行指令的时候,首先将内存中的数据加载到 CPU 内的寄存器中(读指令),接着进行 count–(分析和执行指令),最后将 CPU 修改完毕的 count 写回内存中。
- 执行流在执行的任何时刻都有可能会被切换。
- 寄存器只有一套,被所有的执行流共享。但是寄存器里面的数据属于每一个执行流,属于该执行流的上下文数据。
每个进程都得先申请信号量,前提是每个进程都得先看到信号量。但如果每个进程都能看到信号量时,信号量本身就是一个临界资源,所以这样就变成了信号量原本是保护临界资源的,但自己却变成了临界资源。这当然有问题,你要保护其它人的前提是先保护好自己的安全,所以上面所讲的信号量 pv 操作,它本身就是原子的,所以它被称为 pv 原语,简单点来说,就是那个计数器本身就是原子的。在同一时间内,它只允许一个进程进行操作。
实现伪代码:假设这里有若干个进程要访问临界资源,那么首先只有进程 A 先申请锁成功,然后往下执行后 count = 2 解锁,进程 A 就可以访问共享内存的一部分了。另外进程 B 也在申请锁成功,然后往下执行后 count = 1 解锁,进程 B 就可以访问共享内存的一部分了。再另外进程 C … … count = 0 解锁,进程 C 就可以访问共享内存的一部分了。再另外进程 D 也申请锁成功,但是因为 count = 0,代表无多余的资源,此时就 goto 跳转到 begin,重复执行,此时就用这段代码,约束了访问临界资源的进程。接着进程 A 访问完毕,然后申请锁成功,count++ 变成 1,最后解锁成功。此时进程 D 申请锁成功,count 是 1 表示有资源可以访问,然后往下执行 count = 0 解锁,进程 D 就可以访问共享内存的一部分了。

在多进程环境下,如何保证信号量被多个进程看到 ?
只要使用系统提供的一批接口,就可以保证信号量被多个进程看到。
如果信号量计数器的值是 1,此时信号量的值无非就是 1 或 0,如果我们要申请信号量,但只让我们一个进程申请成功,这种信号量叫做二元信号量,其本质就是一种互斥语义。换而言之,信号量计数器的值 大于 1,它就是多元信号量。
(5)接口
(i)信号量集的创建
创建信号量集我们需要用semget函数,semget函数的函数原型如下:
int semget(key_t key, int nsems, int semflg);
说明一下:
创建信号量集也需要使用ftok函数生成一个key值,这个key值作为semget函数的第一个参数。
semget函数的第二个参数nsems,表示创建信号量的个数。
semget函数的第三个参数,与创建共享内存时使用的shmget函数的第三个参数相同。
信号量集创建成功时,semget函数返回的一个有效的信号量集标识符semid(用户层标识符)。
(ii)信号量集的删除
删除信号量集我们需要用semctl函数,semctl函数的函数原型如下:
int semctl(int semid, int semnum, int cmd, ...);
(iii)信号量集的操作
对信号量集进行pv操作我们需要用semop函数,semop函数的函数原型如下:
int semop(int semid, struct sembuf *sops, unsigned nsops);

semop 是需要对特定的信号量semid传入 sembuf 结构(表示操作形式),这个结构如上图,
sem_num就是信号量编号,就是下标,
sem_op 对应上面所说的 pv 操作,如果是 -1,就表示对计数器 -1,如果是 +1,就表示对计数器 +1,
sem_fg设为0就可以了,表示操作失败是否回滚,我们不关心。
nsops 是想对第几个信号量操作。
4、内核是如何组织管理IPC资源的

通过对system V系列进程间通信的学习,可以发现共享内存、消息队列以及信号量,虽然它们内部的属性差别很大,但是维护它们的数据结构的第一个成员确实一样的,都是ipc_perm类型的成员变量。

这样设计的好处就是,在操作系统内可以定义一个struct kern_ipc_perm类型的柔性数组,指向所有IPC资源,其实是指向第一个元素struct kern_ipc_perm q_perm就是指向整体元素整个结构体。此时每当我们申请一个IPC资源,就在该数组当中开辟一个这样的结构。


那他怎么区分柔性数组里存的是共享内存还是消息队列或者是信号量呢?
老内核:定义三个ids,分别指向这个ary,顺着就可以找到是哪个

新内核:给这三个放到数组里

相关文章:
进程间通信--详解
目录 前言一、进程间通信介绍1、进程间通信目的2、进程间通信发展3、进程间通信的分类4、进程间通信的必要性5、进程间通信的技术背景6、进程间通信的本质理解 二、管道1、什么是管道2、匿名管道pipe(1)匿名管道的原理(2)pipe函数…...
零基础上手WebGIS+智慧校园实例(1)【html by js】
请点个赞收藏关注支持一下博主喵!!! 等下再更新一下1. WebGIS矢量图形的绘制(超级详细!!),2. WebGIS计算距离, 以及智慧校园实例 with 3个例子!!…...
【Github】如何使用Git将本地项目上传到Github
【Github】如何使用Git将本地项目上传到Github 写在最前面1. 注册Github账号2. 安装Git工具配置用户名和邮箱仅为当前项目配置(可选) 3. 创建Github仓库4. 获取仓库地址5. 本地操作(1)进入项目文件夹(2)克隆…...

集合Queue、Deque、LinkedList、ArrayDeque、PriorityQueue详解
1、 Queue与Deque的区别 在研究java集合源码的时候,发现了一个很少用但是很有趣的点:Queue以及Deque; 平常在写leetcode经常用LinkedList向上转型Deque作为栈或者队列使用,但是一直都不知道Queue的作用,于是就直接官方…...

谈一下开源生态对 AI人工智能大模型的促进作用
谈一下开源生态对 AI人工智能大模型的促进作用 作者:开源呼叫中心系统 FreeIPCC,Github地址:https://github.com/lihaiya/freeipcc 开源生态对大模型的促进作用是一个多维度且深远的话题,它不仅加速了技术创新的速度,…...

基于python的机器学习(四)—— 聚类(一)
目录 一、聚类的原理与实现 1.1 聚类的概念和类型 1.2 如何度量距离 1.2.1 数据的类型 1.2.2 连续型数据的距离度量方法 1.2.3 离散型数据的距离度量方法 1.3 聚类的基本步骤 二、层次聚类算法 2.1 算法原理和实例 2.2 算法的Sklearn实现 2.2.1 层次聚类法的可视化实…...

实时数据开发 | 怎么通俗理解Flink容错机制,提到的checkpoint、barrier、Savepoint、sink都是什么
今天学Flink的关键技术–容错机制,用一些通俗的比喻来讲这个复杂的过程。参考自《离线和实时大数据开发实战》 需要先回顾昨天发的Flink关键概念 检查点(checkpoint) Flink容错机制的核心是分布式数据流和状态的快照,从而当分布…...

C++设计模式-策略模式-StrategyMethod
动机(Motivation) 在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,将会使对象变得异常复杂;而且有时候支持不使用的算法也是一个性能负担。 如何在运…...

小程序免备案:快速部署与优化的全攻略
小程序免备案为开发者提供了便捷高效的解决方案,省去繁琐的备案流程,同时通过优化网络性能和数据传输,保障用户体验。本文从部署策略、应用场景到技术实现,全面解析小程序免备案的核心优势。 小程序免备案:快速部署与优…...
Jmeter中的定时器
4)定时器 1--固定定时器 功能特点 固定延迟:在每个请求之间添加固定的延迟时间。精确控制:可以精确控制请求的发送频率。简单易用:配置简单,易于理解和使用。 配置步骤 添加固定定时器 右键点击需要添加定时器的请求…...
C++自动化测试:GTest 与 GitLab CI/CD 的完美融合
在现代软件开发中,自动化测试是保证代码质量和稳定性的关键手段。对于C项目而言,自动化测试尤为重要,它能有效捕捉代码中的潜在缺陷,提高代码的可维护性和可靠性。本文将重点介绍如何在C项目中结合使用Google Test(GTe…...

vscode连接远程开发机报错
远程开发机更新,vscode连接失败 报错信息 "install" terminal command done Install terminal quit with output: Host key verification failed. Received install output: Host key verification failed. Failed to parse remote port from server ou…...
神经网络12-Time-Series Transformer (TST)模型
Time-Series Transformer (TST) 是一种基于 Transformer 架构的深度学习模型,专门用于时序数据的建模和预测。TST 是 Transformer 模型的一个变种,针对传统时序模型(如 RNN、LSTM)在处理长时间依赖、复杂数据关系时的限制而提出的…...
IDEA 2024安装指南(含安装包以及使用说明 cannot collect jvm options 问题 四)
汉化 setting 中选择插件 完成 安装出现问题 1.可能是因为之前下载过的idea,找到连接中 文件,卸载即可。...
Fakelocation Server服务器/专业版 Centos7
前言:需要Centos7系统 Fakelocation开源文件系统需求 Centos7 | Fakelocation | 任务一 更新Centos7 (安装下载不再赘述) sudo yum makecache fastsudo yum update -ysudo yum install -y kernelsudo reboot//如果遇到错误提示为 Another app is curre…...
oracle的静态注册和动态注册
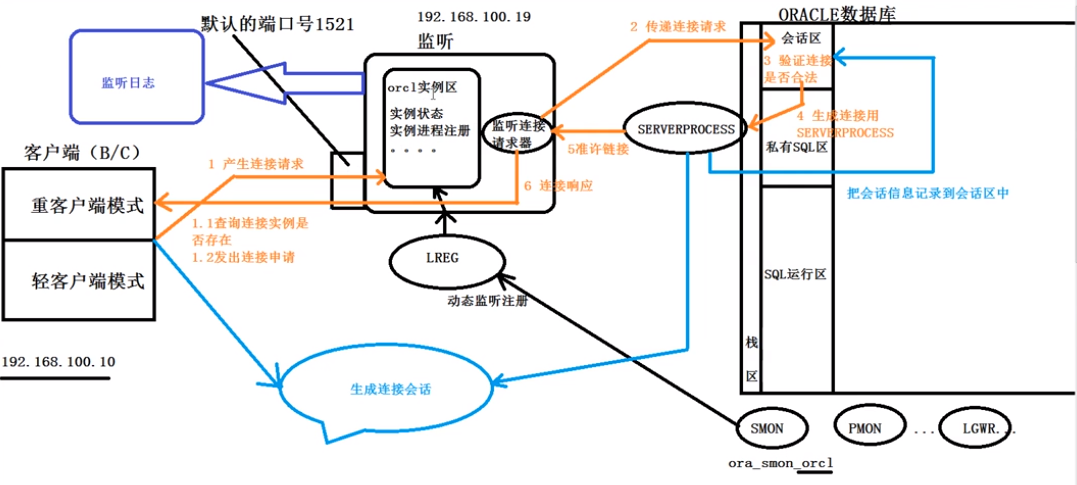
oracle的静态注册和动态注册 静态注册: 静态注册 : 指将实例的相关信息手动告知 listener 侦 听 器 , 可以使用netmgr,netca,oem 以及直接 vi listener.ora 文件来实现静态注册,在动态注册不稳定时使用,特点是:稳定&…...
机器翻译基础与模型 之四:模型训练
1、开放词表 1.1 大词表和未登陆词问题 理想情况下,机器翻译应该是一个开放词表(Open Vocabulary)的翻译任务。也就是,无论测试数据中包含什么样的词,机器翻译系统都应该能够正常翻译。 现实的情况是即使不断扩充词…...

Vue——响应式数据,v-on,v-bind,v-if,v-for(内含项目实战)
目录 响应式数据 ref reactive 事件绑定指令 v-on v-on 鼠标监听事件 v-on 键盘监听事件 v-on 简写形式 属性动态化指令 v-bind iuput标签动态属性绑定 img标签动态属性绑定 b标签动态属性绑定 v-bind 简写形式 条件渲染指令 v-if 遍历指令 v-for 遍历对象的值 遍历…...

ceph 18.2.4二次开发,docker镜像制作
编译环境要求 #需要ubuntu 22.04版本 参考https://docs.ceph.com/en/reef/start/os-recommendations/ #磁盘空间最好大于200GB #内存如果小于100GB 会有OOM的情况发生,需要重跑 目前遇到内存占用最高为92GB替换阿里云ubuntu 22.04源 将下面内容写入/etc/apt/sources.list 文件…...

产品经理的项目管理课
各位产品经理,大家下午好,今天我给大家分享的主题是“产品经理如何做好项目管理”。 其实,我是不想分享这个主题的,是因为在周会中大家投票对这个议题最感兴趣,11个同学中有7个投了这个主题,所以才有了这次…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...