深度学习4
一、手动构建模型
epoch 一次完整数据的训练过程(可细分多次训练),称为 一代训练
Batch 小部分样本对权重的更新,称为 一批数据
iteration 使用一个 Batch 的过程,称为 一次训练
步骤:
1、生成 x,y 的数据
2、初始化 w,b 的值
3、拆分 x,y 的数据
4、传入小批量数据到一个函数, 函数为关系表达式(y = x@w+b),(得到一个损失函数值,表达式)
5、根据真实损失值和表达式结果得到均方差(显示结果为值传递,隐藏函数表达式的传递,为梯度下降使用)
6、对损失函数反向传递(第五步的结果),对 w,b 求梯度值
7、更新梯度值到小变化
1、基础数据 x,y
使用 sklearn 的数据集方法 make_regression
from sklearn.datasets import make_regression
make_regression :创建一个具有线性关系的数据集,包含一定的噪声和异常值
参数:n_samples 样本数量,默认100
n_features 每个样本的特征数量,默认100
n_targets 回归目标的数量,默认1
bais 偏置,默认0.0
coef 系数值,设置为True,则返回数据的真实系数
shuffle 打乱样本
noise 高斯噪声的标准差,默认0.0
属性:x 样本形状,
y 实际目标值
coef 真实系数
import torch
import sklearn.datasets import make_regression
def data_build():noise = 14.6 n_sample=1000 # 样本数量x,y,coef = make_regression(n_samples=n_sample,n_features=4,coef=True,bias=15.9,n_informative=1,noise=noise,random_state=666)x = torch.tensor(x, dtype=torch.float32, requires_grad=True) # 根据make_regression函数生成的数据,x的shape为(n_sample,n_features),需要梯度更新y = torch.tensor(y, dtype=torch.float32) # 函数生成特征值 n_features return x,y,coef # coef 为真实的函数系数2、初始化 w,b
也就是随机产生两个tensor值,requires_grad =True 可梯度更新
import torch
# 初始化 w,b
def initialize(n_features):torch.manual_seed(666) # 保证每一次初始化的值都一样,验证模型训练w = torch.randn(n_features,requires_grad=True)b = torch.tensor(1.,requires_grad=True)return w,b3、拆分x,y的数据
设定多代训练(完整数据),每代多次训练(小批量)
import torchdef data_loader(x,y):"""description: 数据加载器param {type}"""# 配置参数batch_size = 16 # 设定一次为16个数据n_samples = x.shape[0] # 根据x的形状得到总数据量n_batch = math.ceil(n_samples / batch_size) # 总数据量除以批次大小得到总共需要多少次训练完整个数据indexs = [i for i in range(x.shape[0])] # 生成总样本的数据量,为打乱数据准备random.shuffle(indexs) # 打乱下标数据for i in range(0, n_batch, batch_size): # 循环训练次数,步长为设定的批次大小index = indexs[i*batch_size: (i+1)*batch_size] # 根据打乱的下标得到数据打乱效果yield x[index],y[index] # yeild 生成器 获得数据,与训练模型搭配4、损失函数
传递为是损失函数表达式,损失结果值;计算预测结果
import torch# 损失函数表达式
def myresreser(x,w,b):return x@w+b # 一个容器中装了每一条样本的预测值5、计算均方差
根据预测值和前面生成的真实值得到均方差
import torch# 根据预测值和真实值得到均方差,损失函数结果
def mse(y_pred,y_true):return torch.mean((y_true-y_pred)**2) # 求误差均值6、更新(优化)
根据传递grad梯度,修改 w,b的值
import torchw.data = w.data - lr * w.grad
b.data = b.data - lr * b.grad7、训练
调用数据生成、数据划分、初始值w,b、损失函数、均方差、更新的函数;
定义epoch 完成多代训练、batch 单词训练数据大小、iteration 完整训练次数
import torch# 训练函数
def train():# 调用生成数据函数产生 x,y 和真实的系数x,y,coef = data_build()# 初始化参数 w,bw,b = initialize(x.shape[1])# 训练参数lr = 0.01 # 学习率epoch = 100 # 训练次数for i in range(epoch): # 循环训练次数(完整数据为一代)for batch_x,y_true in data_loader(x,y): # 调用数据加载器得到一次小训练的数据y_pred = myresreser(batch_x,w,b) # 根据表达式函数船射出预测值 ,返回值是一个tensory_true = torch.tensor(y_true,requires_grad=True) # 跟据真实值创建一个 tensorloss = mse(y_pred,y_true) # 根据真实值和预测值得到损失函数# 判断第一次不需要清零,后面需要更新梯度,所以需要梯度清零if w.grad is not None:w.grad.data.zero_()if b.grad is not None:b.grad.data.zero_()# 反向传播loss.backward()# 更新梯度w.data = w.data - lr * w.gradb.data = b.data - lr * b.grad完整流程:
from sklearn.datasets import make_regression
import torch
import math
import random# 创建 x,y 的数据 返回一个数据真实的系数
def data_build():noise = 14.6n_sample=1000 # 样本数量x,y,coef = make_regression(n_samples=n_sample,n_features=4,coef=True,bias=15.9,n_informative=1,noise=noise,random_state=666)x = torch.tensor(x, dtype=torch.float32, requires_grad=True) # 根据make_regression函数生成的数据,x的shape为(n_sample,n_features),需要梯度更新y = torch.tensor(y, dtype=torch.float32) # 函数生成特征值 n_features return x,y,coef # coef 为真实的函数系数# 初始化 w,b
def initialize(n_features):torch.manual_seed(666)w = torch.randn(n_features,requires_grad=True)b = torch.tensor(1.,requires_grad=True)return w,b# 加载 x,y 数据,进行划分为 明确批量大小和次数的多个小批量数据
def data_loader(x,y):"""description: 数据加载器param {type}"""# 配置参数batch_size = 16 # 设定一次为16个数据n_samples = x.shape[0] # 根据x的形状得到总数据量n_batch = math.ceil(n_samples / batch_size) # 总数据量除以批次大小得到总共需要多少次训练完整个数据indexs = [i for i in range(x.shape[0])] # 生成总样本的数据量,为打乱数据准备random.shuffle(indexs) # 打乱下标数据for i in range(0, n_batch, batch_size): # 循环训练次数,步长为设定的批次大小index = indexs[i*batch_size: (i+1)*batch_size] # 根据打乱的下标得到数据打乱效果yield x[index],y[index] # yeild 生成器 获得数据,与训练模型搭配# 损失函数表达式
def myresreser(x,w,b):return x@w+b # 一个容器中装了每一条样本的预测值# 根据预测值和真实值得到均方差,损失函数结果
def mse(y_pred,y_true):return torch.mean((y_true-y_pred)**2) # 求误差均值# 训练函数
def train():# 调用生成数据函数产生 x,y 和真实的系数x,y,coef = data_build()# 初始化参数 w,bw,b = initialize(x.shape[1])# 训练参数lr = 0.01 # 学习率epoch = 100 # 训练次数for i in range(epoch): # 循环训练次数(完整数据为一代)e = 0count=0for batch_x,y_true in data_loader(x,y): # 调用数据加载器得到一次小训练的数据y_pred = myresreser(batch_x,w,b) # 根据表达式函数船射出预测值 ,返回值是一个tensory_true = torch.tensor(y_true,requires_grad=True) # 跟据真实值创建一个 tensorloss = mse(y_pred,y_true) # 根据真实值和预测值得到损失函数e+=losscount +=1# 判断第一次不需要清零,后面需要更新梯度,所以需要梯度清零if w.grad is not None:w.grad.data.zero_()if b.grad is not None:b.grad.data.zero_()# 反向传播loss.backward()print(w.grad)print(b.grad)# 更新梯度w.data = w.data - lr * w.gradb.data = b.data - lr * b.grad
train()
print()二、模型组件
就是将第一点所用的函数内容封装为官方组件,使用时直接调用,无需再次定义。
1、基础组件
1.1、线性层组件
import torch.nn as nn
nn.Linear :根据参数内容常见线性对象,在对象传入样本数据,返回预测结果
参数:in_features:输入特征数量
out_features:输出特征数量
bais:是否使用偏置,默认True
属性:weights:权重
bais:偏置
import torch
import torch.nn as nn
# x 数据
x = torch.tensor([[1,2,3,4]],dtype=torch.float32) model = nn.Linear(4,1) # 创建一个线性对象,输入特征值与x保持一致,输出一个特征print("Weights:", model.weight) # 权重
print("Bias:", model.bias) # 偏置y = model(x) # 使用线性对象预测 y
print(y)1.2、损失函数组件
import torch.nn as nn
nn.MSELoss:可无参数使用,返回一个损失函数对象,在对象中传入预测值和真实值(由于求均方差,故顺序不重要)
import torch
import torch.nn as nn
model = nn.MSELoss()
y_true = torch.randn(5, 3)
y_pred = torch.randn(5, 3, requires_grad=True)
print(model(y_true, y_pred)) 1.3、优化器组件
import torch.optim as optim
optim.SGD():根据传入的线性对象、学习率,实现随机梯度下降,配合循环使用
参数:params:需要进行优化的模型,一般使用线性对象
lr:学习率,默认0.1
weight_decay:权重衰减(L2正则化),放置过拟合,默认0
属性:optimizer.zero_grad() 清零梯度,不需要进行空值判断
optimizer.step() 更新参数 相当于 w.data = w.data- lr*w.grad
import torch
import torch.optim as optim
x = torch.randint(1,10,(400,5)).type(torch.float32) # 创建x值
target = torch.randint(1,10,(400,1)).type(torch.float32) # 创建实际y值model = nn.Linear(5, 1) # 线性对象,5个传入特征,1个输出特征
# 优化器对象
sgd = optim.SGD(model.parameters(), lr=0.01) # 学习率为0.01y_pred = model(x) # 预测值loss_fn = nn.MSELoss() # 创建损失函数 均方差 对象
loss = loss_fn(y_pred,target) # 使用 预测值 和真实值 计算损失print(loss)
sgd.zero_grad() # 梯度清零
loss.backward() # 反向传播
sgd.step() # 更新参数
import torch
import torch.optim as optimx = torch.randint(1,10,(400,5)).type(torch.float32) # 创建x值
target = torch.randint(1,10,(400,1)).type(torch.float32) # 创建实际y值# 线性对象,5个传入特征,1个输出特征
model = nn.Linear(5, 1) # 优化器对象
sgd = optim.SGD(model.parameters(), lr=0.001) # 学习率为0.01# 创建损失函数 均方差 对象
loss_fn = nn.MSELoss() # 创建循环训练
batch = 50
for j in range(int(400/batch)):x_batch = x[j*batch:(j+1)*batch]target_batch = target[j*batch:(j+1)*batch]y_pred = model(x_batch) # 预测值loss = loss_fn(y_pred,target_batch) # 使用 预测值 和真实值 计算损失sgd.zero_grad() # 梯度清零loss.backward() # 反向传播sgd.step() # 更新参数print("损失函数值的变化:",loss)
2、数据加载器
2.1、构建数据和加载数据
构建自定义数据加载类通常需要继承 torch.utils.data.Dataset ,实现以下三个方法:
__init__(self,data,lables): data 表示数据(x),lables表示特征(y)
__len__(self):获取自定义数据集大小的方法
__getitem__(self,index):index表示下标,根据下标获取data 或 lables的数据
# 数据加载器 数据集和加载器
import torch
from torch.utils.data import Dataset,DataLoaderclass my_dataset(Dataset): # 继承Datasetsdef __init__(self,x,y):super(my_dataset,self).__init__() self.data = x # 实例化对象传入的x数据self.label = y # 实例化对象传入的特征数据def __getitem__(self, index):return self.data[index], self.label[index]def __len__(self):return len(self.data)# 随机创建 x,y 的数据
x = torch.randn(100, 3)
y = torch.randn(100, 1)# 实例化对象 返回数据类
data = my_dataset(x,y) # 使用其方法
print("len:",len(data))
print("getitem:",data[1])# 创建一个数据加载对象 loader batch_size=16 每次训练16个数据,随机打乱
loader = DataLoader(data, batch_size=16, shuffle=True)
for x, y in loader:print(x.shape,y.shape)2.2、数据集加载-excel
加载本地案例
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pdclass my_excel_dataset(Dataset):def __init__(self, path):super(my_excel_dataset,self).__init__()"""把excel文件读取,数据放入data,目标值放入labels"""data_pd = pd.read_excel(path) # 读取数据,使用pandas优化data_pd.dropna(axis=1, how='all')# 对每一类加上特征描述,方便后续使用data_pd.columns = ['zubie','st_id','st_name','fengong','expresion','ppt_make','answer','code_show','score','demo']# 删除无用数据列data_pd = data_pd.drop(['zubie','st_id','st_name','fengong','score'], axis=1)# 创建 dada 和 lablesself.data = torch.tensor(data_pd.iloc[:,:-1].to_numpy(), dtype=torch.float32)self.lables = torch.tensor(data_pd.iloc[:,:-1].to_numpy(), dtype=torch.float32)def __getitem__(self, index):return self.data[index],self.lables[index]def __len__(self):return len(self.data)path = f"../../data/21级大数据答辩成绩表.xlsx"
data = my_excel_dataset(path) # 通过本地文件实例化数据类
datasets = DataLoader(data, batch_size=10,shuffle=True) # 加载数据
for x,y in datasets:print(x,y)2.4、数据集加载-图片
需要使用os的API:
# 目录,该目录下的根文件夹(如存在,一层目录结束后进入),该目录下的根文件
for root, dir, files in os.walk("../../data"):
pass
# 拼接
path = os.path.join("../../data","1.png")
print(path)
# 取出完整文件名,默认分割最后一个斜杠
str = os.path.split("../../data/1.png")
print(str)
# 取出完整文件后缀名
str = os.path.splitext("../../data/1.png")
print(str)
import os
from torch.utils.data import Dataset,DataLoader
import cv2
import torchclass My_Image_Dataset(Dataset):def __init__(self,path):self.path = path self.data = [] # 存放图片路径self.lables =[] # 存放图片标签self.classname =[] # 存放图片标签名称for roots , dirs, files in os.walk(path):if roots == path: # 判断是根目录self.classname = dirs # 获取所有文件夹名称else:for file in files: # 进入内层目录后遍历所有文件file_path = os.path.join(roots,file) # 拼接该文件所在目录和文件名称,得到完整路径self.data.append(file_path) # 添加到dataclass_id = self.classname.index(os.path.split(roots)[1]) # 拆分目录得到该文件所在文件夹名称(标签),并在列表中返回对应下标self.lables.append(class_id) # 将下表添加到lables ,这样labels就可以和data一一对应def __len__(self):return len(self.lables) # 根据标签得到总共数据长度def __getitem__(self, index):img_path = self.data[index] # 根据下标返回图片路径lable = self.lables[index] # 根据下标返回标签img = cv2.imread(img_path) # 根据路径获取图片数据cv2.imshow("img",img) # 展示图片,保证获取数据无问题cv2.waitKey(0) img = cv2.resize(img,(336,336)) # 调整图片大小为统一格式img = torch.from_numpy(img) # 转化为numpy格式img = img.permute(2,0,1) # 进行通道调整,维度个数交换return img,lable # 返回图片数据,标签path = f"../../data/animal" # 数据集路径
my_image_dataset = My_Image_Dataset(path) # 实例化数据集对象
print(len(my_image_dataset)) # 数据集大小
print(my_image_dataset[1]) # 根据下标1 返回对应图片数据和标签
print(my_image_dataset.classname) # 输出所有类别名称2.5、数据集加载-官方
官方地址:Datasets — Torchvision 0.20 documentation
from torchvision import transforms,datasets
使用 transforms 对数据进行调整
使用 datasets 加载数据
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 创建一个数据转换器,将numpy或图片转成为tensor,Compose为组合器
transform = transforms.Compose([transforms.ToTensor()])
# 加载 MNIST 数据集到 data地址
data = datasets.MNIST(root='../../data', # 数据集的存储路径train=True, #是否加载训练数据集transform=transform, # 加载数据转化器download=True # 是否从互联网下载数据集。如果设置为 True,并且数据集不存在于指定路径,将会自动下载数据集。)
for (x,y) in DataLoader(data, batch_size=16,shuffle=True): # 循环数据加载器,循环返回16个数据print(x.shape, y.shape)
相关文章:

深度学习4
一、手动构建模型 epoch 一次完整数据的训练过程(可细分多次训练),称为 一代训练 Batch 小部分样本对权重的更新,称为 一批数据 iteration 使用一个 Batch 的过程,称为 一次训练 步骤: 1、生成 x,y 的…...

跳绳视觉计数方案
产品概述 提供基于摄像头视觉技术的跳绳计数解决方案,可精准完成跳绳动作的实时计数,效果完全满足考试水平的要求。方案采用先进的计算机视觉算法,结合高效的模型架构,确保计数的准确性和稳定性。适用场景 学校体育考试ÿ…...

TEA加密逆向
IDA伪代码 do{if ( v15 )v17 v38; // x120x0->0x79168ba790, 输入字符串经过check1处理后字符串elsev17 v40;v18 (unsigned int *)&v17[v16]; // 0x78cbbd47fc add x12, x12, x8 ; x120x79168ba790->…...

LeetCode 404.左叶子之和
题目:给定二叉树的根节点 root ,返回所有左叶子之和。 思路:一个节点为「左叶子」节点,当且仅当它是某个节点的左子节点,并且它是一个叶子结点。因此我们可以考虑对整 node 时,如果它的左子节点是一个叶子…...
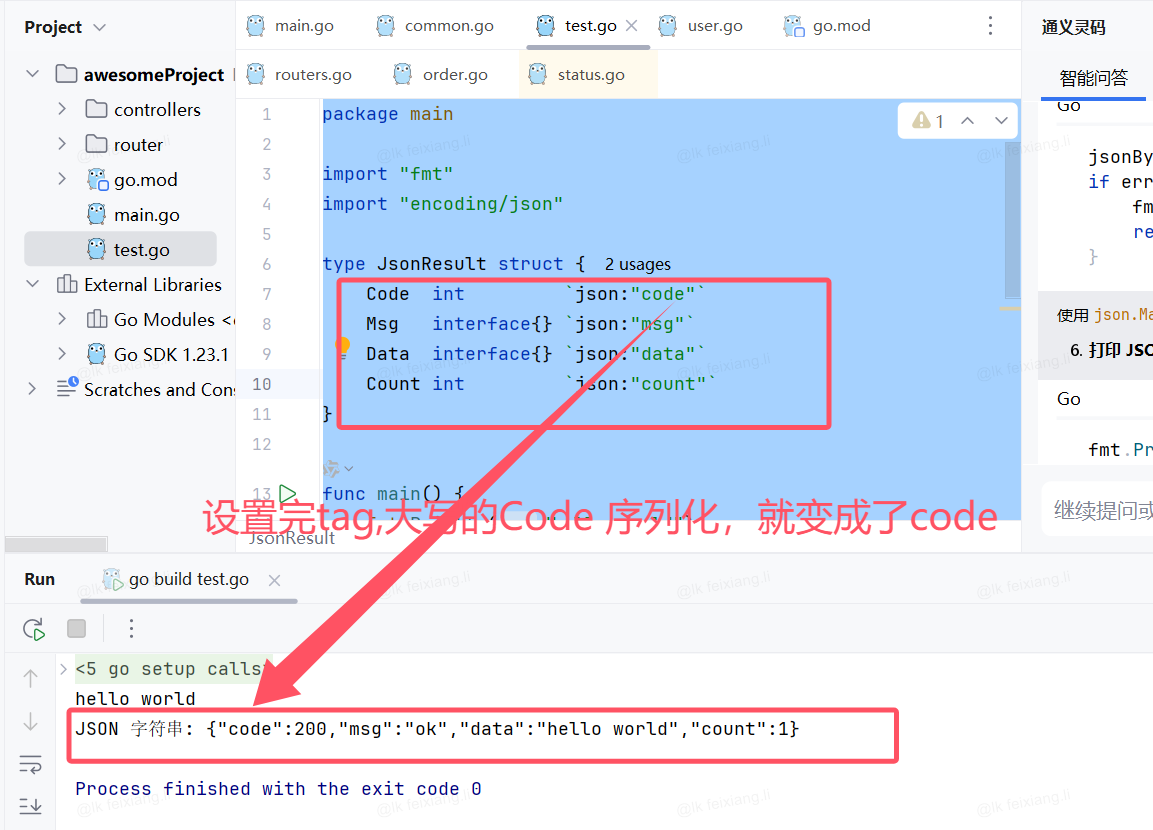
01-go入门
文章目录 Go语言学习1. 简介安装windows安装linux安装编译工具安装-goland 2. 入门2.1 Helloworld注释 2.2 变量初始化打印内存地址变量交换匿名变量作用域局部变量全局变量 2.3 常量iota 2.4 数据类型布尔整数浮点类型复数字符串定义字符串字符串拼接符定义多行字符串 map数据…...

【经典】抽奖系统(HTML,CSS、JS)
目录 1、添加参与者 2、多次添加 3、点击抽奖 功能介绍: 使用方法: 完整代码: 一个简单但功能强大的抽奖系统的示例,用于在网页上实现抽奖。 1、添加参与者 2、多次添加 3、点击抽奖 功能介绍: 参与者添加&…...

GoF设计模式——结构型设计模式分析与应用
文章目录 UML图的结构主要表现为:继承(抽象)、关联 、组合或聚合 的三种关系。1. 继承(抽象,泛化关系)2. 关联3. 组合/聚合各种可能的配合:1. 关联后抽象2. 关联的集合3. 组合接口4. 递归聚合接…...
Java后端如何进行文件上传和下载 —— 本地版
简介: 本文详细介绍了在Java后端进行文件上传和下载的实现方法,包括文件上传保存到本地的完整流程、文件下载的代码实现,以及如何处理文件预览、下载大小限制和运行失败的问题,并提供了完整的代码示例。 大体思路 1、文件上传 …...

json格式数据集转换成yolo的txt格式数据集
这个代码是参考了两个博客 我是感觉第一篇博客可能有问题,然后自己做了改进,如果我是错误的或者正确的,请各位评论区说一下,感谢 Json格式的数据集标签转化为有效的txt格式(data_coco)_train.json-CSDN博客 COCO(.j…...

什么是Three.js,有什么特点
什么是 Three.js? Three.js 是一个基于 WebGL 技术的 JavaScript 3D 库。它允许开发者在网页上创建和展示 3D 图形内容,而无需用户安装任何额外的插件或软件。Three.js 简化了 WebGL 的复杂性,使得即便是对图形编程不太熟悉的人也能快速上手…...

Linux笔记--基于OCRmyPDF将扫描件PDF转换为可搜索的PDF
1--官方仓库 https://github.com/ocrmypdf/OCRmyPDF 2--基本步骤 # 安装ocrmypdf库 sudo apt install ocrmypdf# 安装简体中文库 sudo apt-get install tesseract-ocr-chi-sim# 转换 # -l 表示使用的语言 # --force-ocr 防止出现以下错误:ERROR - PriorOcrFoundE…...

Unity 导出 Xcode 工程 修改 Podfile 文件
Unity 导出 Xcode 工程 修改 Podfile 文件 在 Editor 文件夹下新建 xxx.cs 脚本 实现静态方法 [PostProcessBuild]public static void OnPostprocessBuild(BuildTarget target, string pathToBuiltProject){// Unity 导出 Xcode 工程自动调用这个方法 }using System.IO; using…...

UE5 slate BlankProgram独立程序系列
源码版Engine\Source\Programs\中copy BlankProgram文件夹,重命名为ASlateLearning,修改所有文件命名及内部名称。 ASlateLearning.Target.cs // Copyright Epic Games, Inc. All Rights Reserved.using UnrealBuildTool; using System.Collections.Ge…...
内存不足引发C++程序闪退崩溃问题的分析与总结
目录 1、内存不足一般出现在32位程序中 2、内存不足时会导致malloc或new申请内存失败 2.1、malloc申请内存失败,返回NULL 2.2、new申请内存失败,抛出异常 3、内存不足项目实战案例中相关细节与要点说明 3.1、内存不足导致malloc申请内存失败&#…...
C++ —— 以真我之名 如飞花般绚丽 - 智能指针
目录 1. RAII和智能指针的设计思路 2. C标准库智能指针的使用 2.1 auto_ptr 2.2 unique_ptr 2.3 简单模拟实现auto_ptr和unique_ptr的核心功能 2.4 shared_ptr 2.4.1 make_shared 2.5 weak_ptr 2.6 shared_ptr的缺陷:循环引用问题 3. shared_ptr 和 unique_…...

Linux中安装InfluxDB
什么是InfluxDB InfluxDB是一个开源的时间序列数据库,专为处理时间序列数据而设计。时间序列数据是指带有时间戳的数据点,例如传感器数据、应用程序日志、服务器指标等。InfluxDB 由 InfluxData 公司开发,广泛应用于物联网(IoT&am…...

nginx服务器实现上传文件功能_使用nginx-upload-module模块
目录 conf文件内容如下html文件内容如下上传文件功能展示 conf文件内容如下 #user nobody; worker_processes 1;error_log /usr/logs/error.log; #error_log /usr/logs/error.log notice; #error_log /usr/logs/error.log info;#pid /usr/logs/nginx.pid;events …...

ORB-SLAM2源码学习:Initializer.cc:Initializer::ComputeF21地图初始化——计算基础矩阵
前言 在平面场景我们通过求解单应矩阵H来求解位姿,但是我们在实际中常见的都是非平面场景, 此时需要用基础矩阵F求解位姿。 1.函数声明 cv::Mat Initializer::ComputeF21(const vector<cv::Point2f> &vP1, const vector<cv::Point2f>…...

C# 读取多条数据记录导出到 Word标签模板之图片输出改造
目录 应用需求 设计 范例运行环境 配置Office DCOM 实现代码 组件库引入 核心代码 调用示例 小结 应用需求 在我的文章《C# 读取多条数据记录导出到 Word 标签模板》里,讲述读取多条数据记录结合 WORD 标签模板输出文件的功能,原有输出图片的…...

NSSCTF web刷题
1 虽然找到了flag,但是我要怎么去改他的代码,让他直接输出flag呢? (好像是要得到他的json代码,这题不让看) 2 wllm应该就是他的密码,进入许可了 意思是服务器可以执行通过POST的请求方式传入参数为wllm的命令,那这就是典型的命令执行,当然,…...

NVIDIA vGPU许可服务器HA配置避坑指南:从环境准备到故障切换测试
NVIDIA vGPU许可服务器高可用配置实战:从零搭建到容灾验证 在虚拟化与AI计算融合的今天,NVIDIA vGPU技术已成为图形工作站、云游戏和机器学习平台的核心支撑。但许多团队在享受显卡虚拟化红利时,往往忽略了许可服务的高可用保障——当单点故障…...

PT-Plugin-Plus:极简高效的PT种子下载辅助工具
PT-Plugin-Plus:极简高效的PT种子下载辅助工具 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。 项目地址: h…...

从理论到实践:几何完备扩散模型GCDM在SBDD任务中的实战评测与性能剖析
1. 几何完备扩散模型GCDM的核心原理 GCDM(Geometry-Complete Diffusion Model)作为新一代3D分子生成模型,其核心创新在于解决了传统方法无法有效学习分子几何特性的痛点。想象一下搭积木的场景:普通模型只能看到积木的颜色&#x…...

前端测试:别让你的代码在上线后崩溃
前端测试:别让你的代码在上线后崩溃 毒舌时刻这代码写得跟定时炸弹似的,不知道什么时候就炸了。各位前端同行,咱们今天聊聊前端测试。别告诉我你还在手动测试,那感觉就像在没有安全网的情况下走钢丝——能走,但随时可能…...

别让你的 Coding Agent 瞎忙活,你最缺的可能是这套 Harness 规则
别让你的 Coding Agent 瞎忙活,你最缺的可能是这套 Harness 规则 团队把 Claude Code、Codex、Cursor 这类工具接进日常开发后,最先暴露出的瓶颈通常在协作环节。 一个简单的 bug fix 任务,agent 可能会扩出十几个文件的改动。 跑了一行测试…...
)
DanKoe 视频笔记:一人企业构建指南:从零到百万美元的教育业务(每日工作2-4小时)
在本课程中,我们将学习如何构建一个单人教育业务,实现从零到年收入百万美元的目标,同时将每日工作时间控制在2-4小时。我们将探讨其核心理念、实施步骤以及背后的进化逻辑。 概述 传统的创业路径往往伴随着高风险、高投入和漫长的工作时间。…...

MATLAB 2018B语音信号降噪与盲源分离GUI系统,多维滤波技术展示与实时外放体验
2-6 基于matlab 2018B的语音信号降噪和盲源分离GUI界面,包括维纳滤波,小波降噪、高通、低通、带通滤波,及提出的滤波方法。 每个功能均展示降噪前后声音效果并外放出来。 程序已调通,可直接运行。直接双击运行main.m,耳…...

基于SpringBoot+Vue的招生宣传管理系统管理系统设计与实现【Java+MySQL+MyBatis完整源码】
💡实话实说:用最专业的技术、最实惠的价格、最真诚的态度服务大家。无论最终合作与否,咱们都是朋友,能帮的地方我绝不含糊。买卖不成仁义在,这就是我的做人原则。摘要 随着教育信息化的快速发展,高校招生宣…...

模型微调加速:OpenClaw对接nanobot的LoRA训练
模型微调加速:OpenClaw对接nanobot的LoRA训练 1. 为什么选择OpenClawnanobot进行模型微调 去年我在尝试用Qwen3-4B模型处理专业领域任务时,发现直接使用基础模型的效果总差强人意。模型要么对专业术语理解不到位,要么生成的回答缺乏领域特性…...

告别文件传输烦恼:用aliyunpan快传链接实现秒级大文件分享
告别文件传输烦恼:用aliyunpan快传链接实现秒级大文件分享 【免费下载链接】aliyunpan 阿里云盘命令行客户端,支持JavaScript插件,支持同步备份功能。 项目地址: https://gitcode.com/GitHub_Trending/ali/aliyunpan 你是否也曾经历过…...