pytorch四种单机多卡分布式训练方法
文章目录
- 1、原生pytorch(mp.spawn)
- 2、pytorch ddp (torchrun)
- 3、lightning fabric
- 4、Hugging Face Accelerate
- 4、总结与对比
- 4.1 mp.spawn
- 4.2 torchrun
- 4.3 Lightning Fabric
- 4.4 Hugging face accelerate
pytorch 分布式训练的四种方法。
我将会产生一份伪数据0到19共20个数,batch size=10,使用两个GPU来训练,提前执行一下
export CUDA_VISIBLE_DEVICES="0,1"
1、原生pytorch(mp.spawn)
import os
import torch
import torch.distributed as dist
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDPclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def setup(rank, world_size):"""初始化分布式环境"""os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'dist.init_process_group("nccl", rank=rank, world_size=world_size)def cleanup():"""清理分布式环境"""dist.destroy_process_group()def run_demo(rank, world_size):print(f"Running on rank {rank}")# 设置分布式环境setup(rank, world_size)# 将进程绑定到GPU上torch.cuda.set_device(rank)# 创建数据集和分布式采样器dataset = CustomDataset()sampler = DistributedSampler(dataset, num_replicas=world_size,rank=rank,shuffle=False)# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本sampler=sampler, # 使用分布式采样器pin_memory=True)print(f"\nGPU {rank} 开始加载数据:")for batch_idx, data in enumerate(dataloader):# 将数据移到对应的GPU上data = data.cuda(rank)print(f'GPU {rank} - 批次 {batch_idx}: {data.tolist()}')# 清理分布式环境cleanup()def main():world_size = torch.cuda.device_count() # 获取可用的GPU数量print(f"发现 {world_size} 个GPU")if world_size < 2:print("需要至少2个GPU来运行此示例")return# 使用多进程启动mp.spawn(run_demo,args=(world_size,),nprocs=world_size,join=True)if __name__ == '__main__':main()执行结果:
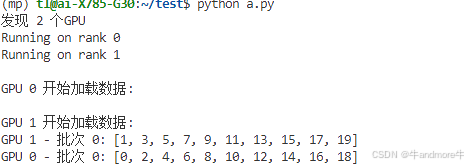
2、pytorch ddp (torchrun)
'''
Author: tianliang
Date: 2024-11-25 12:43:01
LastEditors:
LastEditTime: 2024-11-25 12:44:10
FilePath: /test/b.py
Description:
'''
import os
import torch
import torch.distributed as dist
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSamplerclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def main():# 初始化分布式环境local_rank = int(os.environ["LOCAL_RANK"])world_size = int(os.environ["WORLD_SIZE"])# 初始化进程组dist.init_process_group(backend="nccl")torch.cuda.set_device(local_rank)print(f"Running on GPU {local_rank} of {world_size} GPUs")# 创建数据集和分布式采样器dataset = CustomDataset()sampler = DistributedSampler(dataset,num_replicas=world_size,rank=local_rank,shuffle=False)# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本sampler=sampler, # 使用分布式采样器pin_memory=True)print(f"\nGPU {local_rank} 开始加载数据:")for batch_idx, data in enumerate(dataloader):# 将数据移到对应的GPU上data = data.cuda(local_rank)print(f'GPU {local_rank} - 批次 {batch_idx}: {data.tolist()}')# 清理分布式环境dist.destroy_process_group()if __name__ == '__main__':main()执行:
torchrun --nproc_per_node=2 dist_loader.py
结果

3、lightning fabric
使用前,需要安装
pip install lightning
代码:
'''
Author: tianliang
Date: 2024-11-25 12:47:44
LastEditors:
LastEditTime: 2024-11-25 12:54:12
FilePath: /test/c.py
Description:
'''
import torch
from torch.utils.data import Dataset, DataLoader
from lightning.fabric import Fabricclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def main():# 初始化 Fabricfabric = Fabric(accelerator="cuda", devices=2, strategy="ddp")fabric.launch()# 创建数据集dataset = CustomDataset()# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本shuffle=False)# 使用Fabric设置数据加载器dataloader = fabric.setup_dataloaders(dataloader)print(f"\nGPU {fabric.local_rank} 开始加载数据:")for batch_idx, data in enumerate(dataloader):# 数据已经自动移动到正确的设备上print(f'GPU {fabric.local_rank} - 批次 {batch_idx}: {data.tolist()}')if __name__ == '__main__':main()执行:
python fabric_loader.py
结果:

4、Hugging Face Accelerate
使用前要安装:
pip install accelerate
代码:
'''
Author: tianliang
Date: 2024-11-25 13:17:13
LastEditors:
LastEditTime: 2024-11-25 13:17:16
FilePath: /test/d.py
Description:
'''
import torch
from torch.utils.data import Dataset, DataLoader
from accelerate import Acceleratorclass CustomDataset(Dataset):"""自定义数据集类"""def __init__(self):# 创建0到19的数据self.data = torch.arange(20)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def main():# 初始化 acceleratoraccelerator = Accelerator()# 创建数据集dataset = CustomDataset()# 创建数据加载器dataloader = DataLoader(dataset=dataset,batch_size=10, # 每批次10个样本shuffle=False)# 使用 accelerator 准备数据加载器dataloader = accelerator.prepare(dataloader)# 获取当前进程的设备信息device = accelerator.deviceprocess_index = accelerator.process_indexnum_processes = accelerator.num_processesprint(f"\n进程 {process_index}/{num_processes-1} 在设备 {device} 上开始加载数据:")for batch_idx, data in enumerate(dataloader):# accelerator 已经自动将数据移动到正确的设备上print(f'进程 {process_index} - 批次 {batch_idx}: {data.tolist()}')# 确保所有进程都完成打印后再退出accelerator.wait_for_everyone()if __name__ == '__main__':main()有两种执行方式:
accelerate launch --multi_gpu accelerate_loader.py
torchrun --nproc_per_node=2 accelerate_loader.py
结果是一样的:

从结果上来看,这种方式和之前三个不同,交替分发策略可能更好,除非数成有时续性,或想保持数据局部性
4、总结与对比
4.1 mp.spawn
data_loader.py
mp.spawn(run_demo, args=(world_size,), nprocs=world_size, join=True)
优点:
- 完全控制分布式训练的每个细节
- 适合需要深度定制分布式策略的场景
- 便于调试和理解底层实现
缺点:
- 代码较为复杂
- 需要手动管理很多细节
- 容易出错
- 维护成本高
4.2 torchrun
# dist_loader.py
# 启动命令:torchrun --nproc_per_node=2 dist_loader.py
优点:
-
代码相对简洁
-
PyTorch官方推荐的方式
-
启动方式标准化
-
适合生产环境
-
便于在不同机器上部署
缺点: -
仍需要一定的分布式训练知识
-
调试相对困难
-
需要使用特定的启动命令
4.3 Lightning Fabric
# fabric_loader.py
fabric = Fabric(accelerator="cuda", devices=2, strategy="ddp")
优点:
-
代码最简洁
-
隐藏了大部分分布式训练的复杂性
-
提供了很多内置的优化和工具
-
适合快速开发和实验
-
容易扩展(可以方便地添加日志、检查点等功能)
-
调试友好
-
有完善的生态系统
缺点: -
需要额外依赖Lightning库
-
在某些特殊场景可能缺乏灵活性
-
可能会有一些性能开销
4.4 Hugging face accelerate
优点:
-
代码最简洁
-
配置系统灵活(通过accelerate config)
-
与Hugging Face生态完美集成
-
支持多种后端(DDP、DeepSpeed等)
-
适合transformer类模型
-
部署简单
缺点: -
依赖Accelerate库
-
某些PyTorch高级特性可能需要额外配置
选择:
对于算法开发和多GPU训练,我最推荐使用 Lightning Fabric,原因是:
1、开发效率
- 代码简洁,可以更专注于算法本身
- 快速实验和迭代
- 内置了很多有用的工具和优化
2、可扩展性
- 容易添加新功能(如日志记录、模型检查点等)
- 方便进行实验管理
- 支持各种训练策略的快速切换
3、调试友好
- 提供了很好的错误信息
- 有内置的调试工具
- 社区支持活跃
4、生产就绪
- 可以直接用于生产环境
- 性能优化已经内置
- 有很多最佳实践
具体的:
1、如果您的项目是:
- 研究导向
- 需要快速实验
- 需要完整的训练生态系统 → 选择 Lightning Fabric
2、如果您的项目是:
- 基于transformer架构
- 需要部署到生产环境
- 使用Hugging Face的其他工具 → 选择 Hugging Face Accelerate
3、如果您的项目是: - 需要深度定制化
- 对性能要求极高
不想引入额外依赖 → 选择 PyTorch DDP (torchrun)
如果您不确定: → 从 Lightning Fabric 开始,需要时可以轻松迁移到其他方案
总的来说,对于大多数现代深度学习项目,我最推荐 Lightning Fabric 和 Hugging Face Accelerate,它们提供了最好的开发体验和功能特性。只有在有特殊需求时,才考虑使用更底层的PyTorch DDP方案。
相关文章:
pytorch四种单机多卡分布式训练方法
文章目录 1、原生pytorch(mp.spawn)2、pytorch ddp (torchrun)3、lightning fabric4、Hugging Face Accelerate4、总结与对比4.1 mp.spawn4.2 torchrun4.3 Lightning Fabric4.4 Hugging face accelerate pytorch 分布式训练的四种方法。 我将会产生一份伪数据0到19共…...

archlinux 触摸板手势配置
文章目录 [toc]libinput-gestures安装 libinput-gestures加入 input 组创建配置文件可用手势 启动 libinput-gestures停止 libinput-gestures自启动 libinput-gestures Touchpad Synapticssynaptics.4 在 /etc/X11/xorg.conf.d/ 目录下会有默认的触摸板配置文件,如果…...

djinn:1 靶场学习小记
一、测试环境: kail攻击机:Get Kali | Kali Linux 靶场镜像:https://download.vulnhub.com/djinn/djinn.ova 描述: 该机器与 VirtualBox 和 VMWare 兼容。DHCP 将自动分配一个 IP。您将在登录屏幕上看到 IP。您必须找到并读取分…...

kafka消费者组和分区数之间的关系是怎样的?
消费者组和分区数之间的关系决定了Kafka中消息的消费方式和负载均衡。合理配置分区数和消费者数量对于优化Kafka的性能和资源利用率至关重要。以下是这种关系的几个关键点: 一个分区只能被同一组的一个消费者消费:这是为了保证消息的顺序性。在同一个消费…...

【go】查询某个依赖是否存在于这个代理
1. 使用 go list 命令 go list -m -versions github.com/gin-gonic/gin 如果模块存在,该命令会返回模块及其可用版本: github.com/gin-gonic/gin v1.7.0 v1.7.1 v1.8.0如果模块不存在或无法找到,会返回错误。 2. 使用 curl 查询代理服务 …...

如何从postman中导出所有集合Collection
项目场景: 有时候需要备份或迁移到其他平台,我们需要在postman中将这些集合数据导出。导出 Postman 集合是为了备份、团队共享或平台迁移等目的的重要步骤。此过程可分为导出单个集合和批量导出所有集合两部分,确保已保存和更新集合后&#x…...
的不正经指南)
在 Spring Boot 中实现多种方式登录(用户名、手机号、邮箱等)的不正经指南
欢迎来到一场技术与幽默交织的冒险!今天,我们将跳进 Spring Boot 的世界,探索如何通过 用户名、手机号、邮箱 等多种方式实现登录。想象一下,用户在登录时可以随心所欲地选择——就像你今天早上纠结到底是要喝美式咖啡还是拿铁&am…...

.NET平台用C#添加动作到PDF文档
使用C#语言在.NET框架下向PDF文档中添加动作,不仅能够提升文档的交互性和用户体验,还能够在自动化工作流中发挥关键作用,例如自动跳转至特定页面、链接外部资源或播放音频资源等操作。这种能力使得开发者能够根据具体需求定制PDF文档的互动操…...

大数据治理:概念、框架与实践应用
摘要: 随着大数据时代的到来,数据量呈爆炸式增长,数据来源和类型日益多样化。大数据治理作为确保数据质量、安全性、合规性以及有效利用数据资产的关键领域,已成为企业和组织在数字化转型过程中面临的重要挑战和机遇。本文深入探讨了大数据治理的概念,详细阐述了其涵盖的主…...

Vue.observable 全解析:Observable 是什么及使用场景剖析
Vue.observable 详解 Vue.observable 是 Vue 2.x 中的一个 API,用于将普通对象转化为响应式对象,类似于 Vue 组件中的 data 对象,可以实现数据的双向绑定。它允许你将任何普通对象转化为 Vue 响应式系统管理的对象,使得该对象的属性变化时能够自动触发视图更新。 什么是 …...

MySQL基础知识大总结
一,介绍 数据库是什么,我们在学习其他编程语言的时候会使用数组呀,链表,二叉树等等一些数据结构来存储我们的数据,但是大家有没有发现我们一旦关闭程序,所有的数据都没有了,这在发行的软件来看是…...

池化技术、Commons Pool介绍
概述 池化技术,一种通过重复利用对象实例而非频繁创建和销毁的技术。 常见的可池化对象: 数据库连接(Connection):数据库连接创建和销毁代价高,连接池广泛用于管理JDBC连接;线程(Thread):线程的创建和销…...

下载并安装Visual Studio 2017过程
一、下载 1、下载链接 下载链接:官方网址 先登录 往下滑找到较早的下载 2、进行搜索下载 或者直接点击🔗网站跳转 3、确认系统信息进行下载 二、安装 下载完成后右键使用管理员身份运行 1、点击同意后安装 2、若报错—设置失败 打开控制面板-&g…...
菊风视频能力平台开发服务正式入驻华为云云商店,成为华为云联营联运合作伙伴
日前,菊风视频能力平台开发服务正式入驻华为云云商店,成为华为云在实时音视频领域的联营联运合作伙伴。 菊风结合自身产品方案优势与华为云开放、共盈的生态优势强强联手,在推动金融行业数字化转型的路上又向前迈出了一大步。华为云云商店作为…...

springboot整合kafka
springboot整合kafka pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven…...

Python深度学习框架:PyTorch、Keras、Scikit-learn、TensorFlow如何使用?学会轻松玩转AI!
前言 我们先简单了解一下PyTorch、Keras、Scikit-learn和TensorFlow都是什么。 想象一下你要盖一座大房子。你需要砖头、水泥、工具等等,对吧?机器学习也是一样,需要一些工具来帮忙。PyTorch、Keras、Scikit-learn和TensorFlow就是四种不同的…...

【Linux】安装cuda
一、安装nvidia驱动 # 添加nvidia驱动ppa库 sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update# 查找推荐版本 sudo ubuntu-drivers devices# 安装推荐版本 sudo apt install nvidia-driver-560# 检验nvidia驱动是否安装 nvidia-smi 二、安装cudatoolkit&…...

为什么DDoS防御很贵?
分布式拒绝服务攻击(DDoS攻击)是一种常见的网络安全威胁,通过大量恶意流量使目标服务器无法提供正常服务。DDoS防御是一项复杂且昂贵的服务,本文将详细探讨为什么DDoS防御如此昂贵,并提供一些实用的代码示例和解决方案…...

将WPS的PPT 无损的用微软的PowerPoint打开
用WPS做了PPT,但是用用PowerPoint打开的时候,老是会有几张图错位。 解决方案:将wps做的PPT另存为PowerPoint的格式 参考博客:解决office的PPT和WPS的PPT不兼容的问题_office ppt和wps中代码不通用-CSDN博客 另存为的时候&#…...
【汇编】uniapp开发
UniApp是一款基于Vue.js构建的跨平台开发框架,可以用于快速开发同时运行在多个平台(包括iOS、Android、H5和小程序)的应用程序。UniApp的目标是提供一套代码即可在不同平台上运行的开发模式,从而节省开发者的时间和精力。本文将介…...

3大维度破解C盘空间困局:Windows Cleaner让系统重获新生的开源方案
3大维度破解C盘空间困局:Windows Cleaner让系统重获新生的开源方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 当你的电脑频繁弹出"磁盘空间…...

探索Demucs音频分离:当音乐遇见人工智能的魔法分解术
探索Demucs音频分离:当音乐遇见人工智能的魔法分解术 【免费下载链接】demucs Code for the paper Hybrid Spectrogram and Waveform Source Separation 项目地址: https://gitcode.com/gh_mirrors/de/demucs 想象一下,你正沉浸在一首复杂的交响乐…...

cv_unet_image-colorization效果展示:看AI如何为历史照片智能上色
cv_unet_image-colorization效果展示:看AI如何为历史照片智能上色 1. 引言:让历史重现色彩的魅力 黑白照片承载着珍贵的记忆,但缺乏色彩总让人感觉少了些什么。想象一下,如果能将祖辈的老照片恢复成彩色,看到他们当年…...

别再只盯着username了!CTF表单注入题中,用Sqlmap探测password等隐藏参数的高效技巧
突破思维定式:CTF表单注入中隐藏参数的高阶利用策略 在CTF竞赛的Web安全赛道上,SQL注入始终是选手们的必修课。但当我们反复练习username参数注入时,出题人早已在暗处微笑——他们知道大多数选手会形成路径依赖。我曾在一个省级CTF比赛中遇到…...

告别collect2.exe和ld报错:VSCode C语言环境从配置到避坑的完整指南
从零构建VSCode C语言开发环境:编译错误诊断与高效配置指南 当你在VSCode中按下F5期待看到第一个"C语言Hello World"程序运行时,却迎面撞上"undefined reference to WinMain"和"collect2.exe: error: ld returned 1 exit statu…...

如何用OBS Multi RTMP插件实现一键多平台直播:终极免费解决方案
如何用OBS Multi RTMP插件实现一键多平台直播:终极免费解决方案 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否曾经梦想过在YouTube、Twitch和Bilibili等平台上同时直…...

3步实现Axure RP 9-11全版本零障碍汉化:从诊断到优化的全方位解决方案
3步实现Axure RP 9-11全版本零障碍汉化:从诊断到优化的全方位解决方案 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/…...

OpenClaw+GLM-4.7-Flash:个人财务助手实践
OpenClawGLM-4.7-Flash:个人财务助手实践 1. 为什么需要本地化财务助手 去年整理年度账单时,我对着十几个Excel表格和银行导出的PDF文件发呆——这些数据分散在不同平台,格式混乱,分类标准不统一。更让我犹豫的是,有…...

OpenClaw+nanobot:个人学习计划智能生成与跟踪
OpenClawnanobot:个人学习计划智能生成与跟踪 1. 为什么需要AI驱动的学习计划助手 去年备考PMP认证时,我陷入了典型的学习规划困境:教材有600多页,模拟题库超过2000题,而我的备考时间只有8周。传统学习计划工具&…...

从协作机器人到手术刀:深入拆解阻抗/导纳控制在真实工业与医疗场景下的选型指南
从协作机器人到手术刀:深入拆解阻抗/导纳控制在真实工业与医疗场景下的选型指南 当UR10e协作机器人的机械臂以0.1毫米的重复定位精度在汽车底盘上完成螺栓锁付时,当达芬奇手术机器人的EndoWrist器械在跳动的心脏表面完成微米级血管缝合时,背后…...