RNN与LSTM,通过Tensorflow在手写体识别上实战

简介:本文从RNN与LSTM的原理讲起,在手写体识别上进行代码实战。同时列举了优化思路与优化结果,都是基于Tensorflow1.14.0的环境下,希望能给您的神经网络学习带来一定的帮助。如果您觉得我讲的还行,希望可以得到您的点赞收藏关注。
RNN与LSTM,通过Tensorflow在手写体识别上实战
- 1 RNN理论基础
- 1.1网络结构
- 1.2 RNN存在的问题
- 1.3衍生出LSTM
- 2 代码实现
- 2.1 导包
- 2.2 导入数据集
- 2.3 变量准备
- 2.4 准备占位符
- 2.5 初始化权重和偏置值
- 2.6 RNN网络
- 2.7 损失函数Loss
- 2.8 计算准确率
- 2.9Session训练
- 2.10运行结果
- 3 优化
- 3.1 网络结构优化
- 3.2学习率的变化
- 致谢
1 RNN理论基础
1.1网络结构
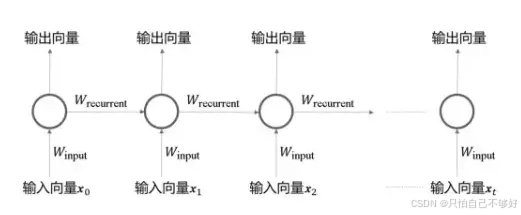
上一个神经元的输出Wrecurrent会作为下一个神经元的输入的一部分。
1.2 RNN存在的问题
第一个神经元的输出对第五个神经元的决策影响较少,存在梯度消失的问题。可以使用线性的激活函数,不会减弱。但是这个网络就没有选择性,靠谱和不靠谱的结果都会被记录
1.3衍生出LSTM
下面是LSTM的结果,看不懂没关系,下面会拆解成三个部分具体讲解,耐心看完就懂了

分为三个门,第一个门是遗忘门

第二个门是输入门

第三个门是输出门:

2 代码实现
2.1 导包
因为我是使用的jupyter运行的,所以我导入了import warnings避免一些不必要的警告,如果你使用的是pycharm就不用加跟warings相关的包了
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
2.2 导入数据集
mnist = input_data.read_data_sets("MNIST_DATA",one_hot=True)
2.3 变量准备
因为手写体数据集的图片大小是 28*28,他放在RNN中相当输入层一行序列有28个神经元,有28行输入
n_inputs =28 # 一行有28个数据
max_time = 28 # 一共有28行
设计隐藏层单元100,十个分类,每批次50个样本,计算批次数
lstm_size = 100
n_classes = 10
batch_size = 50
n_batch = mnist.train.num_examples // batch_size
2.4 准备占位符
x = tf.compat.v1.placeholder(tf.float32,[None,784])
y = tf.compat.v1.placeholder(tf.float32,[None,10])
2.5 初始化权重和偏置值
为了训练效果,采取生成正态分布标准差为0.1的初始权重
weights = tf.Variable(tf.random.truncated_normal([lstm_size,n_classes],stddev=0.1))
biases = tf.Variable(tf.constant(0.1,shape=[n_classes]))
2.6 RNN网络
这个函数的作用是定义网络,有几个知识点需要讲
- tf.nn.dynamic_rnn这个构建循环神经网络的函数的输入inputs 需要满足的格式[batch_size,max_time,n_inputs]
- tf.nn.dynamic_rnn返回值有两个第一个outputs他是每一次的输出,如果参数time_major = False,他的内容为[batch_size,max_time,cell.output_size],反之为[max_time,batch_size,cell.output_size]
- 另一个是final——state,他有三个维度[state,batch_size,cell.state_size]
- final_state[0] = cell state 中间信号,final_state[1] = hidden_state 一次时间序列的最后一次输出的结果,在这里就是28次时间序列因为图片是28*28
def RNN(X,weights,biases):inputs = tf.reshape(X,[-1,max_time,n_inputs])lstm_cell =tf.contrib.rnn.BasicLSTMCell(lstm_size, reuse=tf.compat.v1.AUTO_REUSE)# inputs = [batch_size,max_time,n_inputs]# final_state[state,batch_size,cell.state_size]# final_state[0] = cell state 中间信号# final_state[1] = hidden_state 一次时间序列的最后一次输出的结果,在这里就是28次时间序列# outputs # if time_major = False# [batch_size,max_time,cell.output_size]# if time_major = True# [max_time,batch_size,cell.output_size]# outputs是所有的结果outputs,final_state = tf.nn.dynamic_rnn(lstm_cell,inputs,dtype = tf.float32)results = tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)return results
2.7 损失函数Loss
prediction = RNN(x,weights,biases)
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction,labels=y))
2.8 计算准确率
使用adam优化器 学习率设置为0.0001然后比对正确结果在计算均值化为准确率
train_step = tf.compat.v1.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
2.9Session训练
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:sess.run(init)for epoch in range(6):for batch in range(n_batch):batch_xs,batch_ys = mnist.train.next_batch(batch_size)sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})print(f"第{epoch+1}次epoch,Accuracy = {str(acc)}")
2.10运行结果
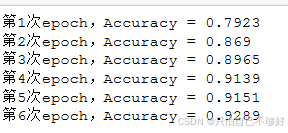
效果一般不是很理想,我们优化一下
3 优化
3.1 网络结构优化
原本只有一层lstm,现在多加一层看看,效果有没有提升
def RNN(X, weights, biases):inputs = tf.reshape(X, [-1, max_time, n_inputs])num_layers = 2 # 可以自行调整层数,比如设置为2、3等cells = [tf.contrib.rnn.BasicLSTMCell(lstm_size, reuse=tf.compat.v1.AUTO_REUSE) for _ in range(num_layers)]stacked_lstm = tf.contrib.rnn.MultiRNNCell(cells)outputs, final_state = tf.nn.dynamic_rnn(stacked_lstm, inputs, dtype=tf.float32)results = tf.nn.softmax(tf.matmul(final_state[-1][1], weights) + biases) # 注意这里取最后一层的 hidden_statereturn results

3.2学习率的变化
每经过一百步降低学习率到原来的0.96,经过20个epoch看看效
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.compat.v1.train.exponential_decay(1e-4, global_step, decay_steps=100, decay_rate=0.96)with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE):train_step = tf.compat.v1.train.AdamOptimizer(learning_rate).minimize(cross_entropy,global_step=global_step)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
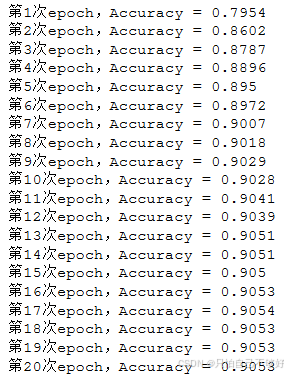
发现后面基本上学不到东西,学习率太低了 调高到 1e-3试试

相比于之前的百分之90已经算较为满意了,还是存在改良的提升空间,可以对衰减的步长decay_steps进行调整。当然了可以通过演化计算的算法去进行参数调优获得更好的结果,我推荐使用 哈里斯鹰,因为我大学做的毕业设计就是基于支持向量机和LSTM结合的使用哈里斯鹰优化参数的情感极性分析,所以我对这个比较拿手,但是这又不是毕业设计,没必要话这么多时间进行参数调优,主要就是太麻烦了。
致谢
本文参考了一些博主的文章,博取了他们的长处,也结合了我的一些经验,对他们表达诚挚的感谢,使我对 LSTM 的使用有更深入的了解,也推荐大家去阅读一下他们的文章。纸上学来终觉浅,明知此事要躬行:
LSTM从入门到精通(形象的图解,详细的代码和注释,完美的数学推导过程)
相关文章:
RNN与LSTM,通过Tensorflow在手写体识别上实战
简介:本文从RNN与LSTM的原理讲起,在手写体识别上进行代码实战。同时列举了优化思路与优化结果,都是基于Tensorflow1.14.0的环境下,希望能给您的神经网络学习带来一定的帮助。如果您觉得我讲的还行,希望可以得到您的点赞…...

Docker部署FastAPI实战
在现代 Web 开发领域,FastAPI 作为一款高性能的 Python 框架,正逐渐崭露头角,它凭借简洁的语法、快速的执行速度以及出色的类型提示功能,深受开发者的喜爱。而 Docker 容器化技术则为 FastAPI 应用的部署提供了便捷、高效且可移植…...

【Python数据分析五十个小案例】电影评分分析:使用Pandas分析电影评分数据,探索评分的分布、热门电影、用户偏好
博客主页:小馒头学python 本文专栏: Python数据分析五十个小案例 专栏简介:分享五十个Python数据分析小案例 在现代电影行业中,数据分析已经成为提升用户体验和电影推荐的关键工具。通过分析电影评分数据,我们可以揭示出用户的…...

Vue2学习记录
前言 这篇笔记,是根据B站尚硅谷的Vue2网课学习整理的,用来学习的 如果有错误,还请大佬指正 Vue核心 Vue简介 Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。 它基于标准 HTML、CSS 和 JavaScr…...

TMS FNC UI Pack 5.4.0 for Delphi 12
TMS FNC UI Pack是适用于 Delphi 和 C Builder 的多功能 UI 控件的综合集合,提供跨 VCL、FMX、LCL 和 TMS WEB Core 等平台的强大功能。这个统一的组件集包括基本工具,如网格、规划器、树视图、功能区和丰富的编辑器,确保兼容性和简化的开发。…...

Redis主从架构
Redis(Remote Dictionary Server)是一个开源的、高性能的键值对存储系统,广泛应用于缓存、消息队列、实时分析等场景。为了提高系统的可用性、可靠性和读写性能,Redis提供了主从复制(Master-Slave Replication…...

logback动态获取nacos配置
文章目录 前言一、整体思路二、使用bootstrap.yml三、增加环境变量四、pom文件五、logback-spring.xml更改总结 前言 主要是logback动态获取nacos的配置信息,结尾完整代码 项目springcloudnacosplumelog,使用的时候、特别是部署的时候,需要改环境&#…...

KETTLE安装部署V2.0
一、前置准备工作 JDK:下载JDK (1.8),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到 PATH 环境变量中。如果你的环境中已存在,可以跳过这步。KETTLE(8.2)压缩包:LHR提供关闭防火墙…...

[RabbitMQ] 保证消息可靠性的三大机制------消息确认,持久化,发送方确认
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
介绍和使用)
aws服务--机密数据存储AWS Secrets Manager(1)介绍和使用
一、介绍 1、简介 AWS Secrets Manager 是一个完全托管的服务,用于保护应用程序、服务和 IT 资源中的机密信息。它支持安全地存储、管理和访问应用程序所需的机密数据,比如数据库凭证、API 密钥、访问密钥等。通过 Secrets Manager,你可以轻松管理、轮换和访问这些机密信息…...

Java设计模式笔记(一)
Java设计模式笔记(一) (23种设计模式由于篇幅较大分为两篇展示) 一、设计模式介绍 1、设计模式的目的 让程序具有更好的: 代码重用性可读性可扩展性可靠性高内聚,低耦合 2、设计模式的七大原则 单一职…...

Unity3d C# 实现一个基于UGUI的自适应尺寸图片查看器(含源码)
前言 Unity3d实现的数字沙盘系统中,总有一些图片或者图片列表需要点击后弹窗显示大图,这个弹窗在不同尺寸分辨率的图片查看处理起来比较麻烦,所以,需要图片能够根据容器的大小自适应地进行缩放,兼容不太尺寸下的横竖图…...

【es6进阶】vue3中的数据劫持的最新实现方案的proxy的详解
vuejs中实现数据的劫持,v2中使用的是Object.defineProperty()来实现的,在大版本v3中彻底重写了这部分,使用了proxy这个数据代理的方式,来修复了v2中对数组和对象的劫持的遗留问题。 proxy是什么 Proxy 用于修改某些操作的默认行为࿰…...

w~视觉~3D~合集3
我自己的原文哦~ https://blog.51cto.com/whaosoft/12538137 #SIF3D 通过两种创新的注意力机制——三元意图感知注意力(TIA)和场景语义一致性感知注意力(SCA)——来识别场景中的显著点云,并辅助运动轨迹和姿态的预测…...

IT服务团队建设与管理
在 IT 服务团队中,需要明确各种角色。例如系统管理员负责服务器和网络设备的维护与管理;软件工程师专注于软件的开发、测试和维护;运维工程师则保障系统的稳定运行,包括监控、故障排除等。通过清晰地定义每个角色的职责࿰…...

一文学习开源框架OkHttp
OkHttp 是一个开源项目。它由 Square 开发并维护,是一个现代化、功能强大的网络请求库,主要用于与 RESTful API 交互或执行网络通信操作。它是 Android 和 Java 开发中非常流行的 HTTP 客户端,具有高效、可靠、可扩展的特点。 核心特点 高效…...

自研芯片逾十年,亚马逊云科技Graviton系列芯片全面成熟
在云厂商自研芯片的浪潮中,亚马逊云科技无疑是最早践行这一趋势的先驱。自其迈出自研芯片的第一步起,便如同一颗石子投入平静的湖面,激起了层层涟漪,引领着云服务和云上算力向着更高性能、更低成本的方向演进。 早在2012年&#x…...

Stable Diffusion 3 部署笔记
SD3下载地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium comfyui 教程: 深度测评:SD3模型表现如何?实用教程助你玩转Stabl…...

微信小程序WXSS全局样式与局部样式的使用教程
微信小程序WXSS全局样式与局部样式的使用教程 引言 在微信小程序的开发中,样式的设计与实现是提升用户体验的关键部分。WXSS(WeiXin Style Sheets)作为微信小程序的样式表语言,不仅支持丰富的样式功能,还能通过全局样式与局部样式的灵活运用,帮助开发者构建美观且易于维…...

Docker 部署 MongoDB
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🍃 vue-uniapp-template 🌺 仓库主页: GitCode💫 Gitee …...

终极飞书文档迁移方案:25分钟批量导出700+文档的完整指南
终极飞书文档迁移方案:25分钟批量导出700文档的完整指南 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 你是否曾因公司办公软件切换或数据备份而面临飞书文档迁移的困境?…...

十年后,编程还会是人类的工作吗?
一个正在被重写的职业剧本站在2026年的中点眺望2036年,没有人能准确预言未来。但作为软件测试从业者,我们或许是离“编程工作是否会被取代”这个答案最近的一群人。因为我们每天的工作,就是审视代码的边界、挖掘逻辑的漏洞、评估系统的风险。…...

妙趣AI:开源Agent工具链与AI导航平台的工程实践
1. 妙趣AI:一个AI工具导航与开源Agent生态的实践如果你和我一样,每天被各种新冒出来的AI工具、模型和概念搞得眼花缭乱,同时又对“AI Agent”这个听起来很酷但落地很虚的东西充满好奇,那么“妙趣AI”这个项目可能正是你需要的。它…...

浏览器运行Cursor AI编辑器:Docker+KasmVNC部署全攻略
1. 项目概述:在浏览器中运行 Cursor AI 编辑器如果你是一名开发者,大概率听说过或者正在使用 Cursor——这款集成了强大 AI 辅助编程能力的编辑器。它基于 VS Code,但深度整合了类似 ChatGPT 的对话和代码生成功能,能极大提升编码…...

Windows安卓开发环境一键配置:告别繁琐驱动的终极解决方案
Windows安卓开发环境一键配置:告别繁琐驱动的终极解决方案 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/l…...

告别SVN提交冲突!手把手教你配置TortoiseSVN 1.10.5的忽略列表与清理功能
告别SVN提交冲突!手把手教你配置TortoiseSVN 1.10.5的忽略列表与清理功能 团队协作开发中,版本控制系统是必不可少的工具。Subversion(SVN)作为一款经典的集中式版本控制系统,至今仍在许多项目中发挥着重要作用。然而&…...
完整移植方案)
正点原子 RK3562 Android14 集成 GStreamer 1.24.13(CLI + V4L2 插件)完整移植方案
RK3562 Android 系统中集成 GStreamer CLI V4L2 插件的完整移植方案,重点难点在于:预编译产物整理、Android.bp 自动生成、vendor 路径安装、运行时环境变量注入,以及 Android 动态链接 namespace 限制的排查。 正点原子RK3562J开发板瑞芯微…...

CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案
CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 宏基因组研究正经历着从短读长测序到长读长技术的深刻变…...

AI写作净化器:识别与消除AI文本痕迹的实用指南
1. 项目概述:为什么我们需要一个“AI写作净化器”? 如果你和我一样,每天都要和AI助手打交道,无论是用它写邮件、生成报告,还是草拟技术文档,那你一定对那种“AI味儿”深有体会。那种感觉就像喝了一杯过度调…...

Gemma 4大模型实战:从架构解析到生产部署与微调
1. 项目概述:为什么我们需要深入理解Gemma 4?如果你最近在关注开源大模型领域,一定绕不开“Gemma”这个名字。从年初Gemma 2B/7B的惊艳亮相,到如今关于下一代架构的种种猜测,Google的Gemma系列正以一种稳健而有力的姿态…...