Python 网络爬虫进阶:动态网页爬取与反爬机制应对
在上一篇文章中,我们学习了如何使用 Python 构建一个基本的网络爬虫。然而,在实际应用中,许多网站使用动态内容加载或实现反爬机制来阻止未经授权的抓取。因此,本篇文章将深入探讨以下进阶主题:
- 如何处理动态加载的网页内容
- 应对常见的反爬机制
- 爬虫性能优化
通过具体实例,我们将探讨更复杂的网络爬虫开发技巧。
一、动态网页爬取
现代网页通常通过 JavaScript 加载动态内容。直接使用 requests 获取的 HTML 可能不包含目标数据。这时,我们可以使用 selenium 模拟浏览器行为来抓取动态内容。
1. 安装与配置 Selenium
安装 Selenium 和浏览器驱动
pip install selenium
下载对应浏览器的驱动程序(如 ChromeDriver),并将其路径添加到系统变量中。
初始化 WebDriver
以下是一个基本的 Selenium 配置:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
import time# 设置浏览器驱动路径
driver_path = "path/to/chromedriver"
service = Service(driver_path)# 初始化 WebDriver
driver = webdriver.Chrome(service=service)# 打开网页
driver.get("http://quotes.toscrape.com/js/")
time.sleep(2) # 等待动态内容加载# 获取网页内容
print(driver.page_source)# 关闭浏览器
driver.quit()
2. 爬取动态加载的名言
通过 Selenium 提取动态内容:
# 初始化 WebDriver
driver = webdriver.Chrome(service=Service("path/to/chromedriver"))
driver.get("http://quotes.toscrape.com/js/")# 等待内容加载
time.sleep(2)# 提取名言和作者
quotes = driver.find_elements(By.CLASS_NAME, "quote")
for quote in quotes:text = quote.find_element(By.CLASS_NAME, "text").textauthor = quote.find_element(By.CLASS_NAME, "author").textprint(f"名言: {text}\n作者: {author}\n")driver.quit()
3. 处理翻页
动态页面通常通过点击“下一页”按钮加载更多内容。我们可以模拟用户操作实现翻页爬取。
# 自动翻页爬取
while True:quotes = driver.find_elements(By.CLASS_NAME, "quote")for quote in quotes:text = quote.find_element(By.CLASS_NAME, "text").textauthor = quote.find_element(By.CLASS_NAME, "author").textprint(f"名言: {text}\n作者: {author}\n")# 点击下一页按钮try:next_button = driver.find_element(By.CLASS_NAME, "next")next_button.click()time.sleep(2) # 等待页面加载except:print("已到最后一页")breakdriver.quit()
二、应对反爬机制
很多网站会通过检测 IP、User-Agent 或频繁访问行为来阻止爬虫。以下是一些常见反爬机制和应对策略:
1. 模拟真实用户行为
设置请求头
在 HTTP 请求中,添加 User-Agent 模拟浏览器。
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.199 Safari/537.36"
}response = requests.get("http://example.com", headers=headers)
随机延迟
为避免触发频率限制,爬取时可以随机添加延迟。
import time
import randomtime.sleep(random.uniform(1, 3)) # 随机延迟 1 到 3 秒
2. 使用代理 IP
通过代理 IP 隐藏爬虫的真实 IP,防止被封禁。
proxies = {"http": "http://your_proxy:port","https": "http://your_proxy:port"
}response = requests.get("http://example.com", proxies=proxies)
自动获取免费代理
可以使用爬虫定期抓取免费代理(如西刺代理),并动态切换 IP。
3. 验证码处理
部分网站使用验证码拦截爬虫。应对策略包括:
- 手动输入:提示用户输入验证码。
- 验证码识别服务:如 平台 提供的 API。
- 避开验证码:尝试通过 API 或其他无需验证码的接口获取数据。
三、性能优化
当需要爬取大量数据时,爬虫的性能优化尤为重要。
1. 多线程或多进程
使用多线程或多进程提高爬取效率:
多线程示例
import threadingdef fetch_data(url):response = requests.get(url)print(f"{url} 完成")urls = ["http://example.com/page1", "http://example.com/page2"]threads = []
for url in urls:thread = threading.Thread(target=fetch_data, args=(url,))threads.append(thread)thread.start()for thread in threads:thread.join()
2. 异步爬取
使用 aiohttp 和 asyncio 实现异步爬取。
import aiohttp
import asyncioasync def fetch(session, url):async with session.get(url) as response:return await response.text()async def main():urls = ["http://example.com/page1", "http://example.com/page2"]async with aiohttp.ClientSession() as session:tasks = [fetch(session, url) for url in urls]results = await asyncio.gather(*tasks)for content in results:print(content)asyncio.run(main())
3. 数据去重
避免重复爬取相同数据,可以使用哈希或数据库记录已访问 URL。
visited = set()if url not in visited:visited.add(url)# 执行爬取
四、实战案例:动态商品价格爬取
以下示例演示如何抓取电商网站动态加载的商品价格,并应对翻页和反爬机制。
from selenium import webdriver
from selenium.webdriver.common.by import By
import timedriver = webdriver.Chrome(service=Service("path/to/chromedriver"))
driver.get("https://example-ecommerce.com")# 等待加载
time.sleep(3)# 爬取商品信息
while True:items = driver.find_elements(By.CLASS_NAME, "product-item")for item in items:name = item.find_element(By.CLASS_NAME, "product-title").textprice = item.find_element(By.CLASS_NAME, "product-price").textprint(f"商品: {name}, 价格: {price}")# 尝试翻页try:next_button = driver.find_element(By.CLASS_NAME, "next-page")next_button.click()time.sleep(2) # 等待页面加载except:print("已到最后一页")breakdriver.quit()
五、总结
通过本篇文章,你学习了以下进阶爬虫技巧:
- 使用 Selenium 处理动态网页。
- 应对常见反爬机制,如设置代理、随机延迟等。
- 提升爬取性能的方法,包括多线程和异步爬取。
下一步,建议尝试构建一个完整的爬虫项目,如爬取新闻网站、商品价格监控等,并学习如何处理复杂的反爬场景。祝你爬虫之路越走越远!
相关文章:

Python 网络爬虫进阶:动态网页爬取与反爬机制应对
在上一篇文章中,我们学习了如何使用 Python 构建一个基本的网络爬虫。然而,在实际应用中,许多网站使用动态内容加载或实现反爬机制来阻止未经授权的抓取。因此,本篇文章将深入探讨以下进阶主题: 如何处理动态加载的网…...

创建可直接用 root 用户 ssh 登陆的 Docker 镜像
有时候我们在 Mac OS X 或 Windows 平台下需要开发以 Linux 为运行时的应用,IDE 或可直接使用 Docker 容器,或 SSH 远程连接。本地命令行下操作虽然可以用 docker exec 连接正在运行的容器,但 IDE 远程连接的话 SSH 总是一种较为通用的连接方…...

wordpress 中添加图片放大功能
功能描述 使用 Fancybox 实现图片放大和灯箱效果。自动为文章内容中的图片添加链接,使其支持 Fancybox。修改了 header.php 和 footer.php 以引入必要的 CSS 和 JS 文件。在 functions.php 中通过过滤器自动为图片添加 data-fancybox 属性。 最终代码 1. 修改 hea…...

数据结构 (7)线性表的链式存储
前言 线性表是一种基本的数据结构,用于存储线性序列的元素。线性表的存储方式主要有两种:顺序存储和链式存储。链式存储,即链表,是一种非常灵活和高效的存储方式,特别适用于需要频繁插入和删除操作的场景。 链表的基本…...

库的操作.
创建、删除数据库 创建语法: CREATE DATABASE [IF NOT EXISTS] db_name[ ]是可选项,IF NOT EXISTS 是表明如果不存在才能创建数据库 //查看数据库,假设7行 show databases; //创建数据库 --- 本质在Linux创建一个目录 create database databa…...
Vue进阶之Vue CLI服务—@vue/cli-service Vuex
Vue CLI服务—vue/cli-service & Vuex vue/cli-service初识bin/vue-cli-service.js代码执行解读 Vuexgenerator/index.jsstore/index.js插件化的能力怎么引入呢? vue/cli-service 初识 第一块是上一个讲述的cli是把我们代码的配置项,各种各样的插件…...

导入100道注会cpa题的方法,导入试题,自己刷题
一、问题描述 复习备考的小伙伴们,往往希望能够利用零碎的时间和手上的试题,来复习和备考 用一个能够导入自己试题的刷题工具,既能加强练习又能利用好零碎时间,是一个不错的解决方案 目前市面上刷题工具存下这些问题 1、要收费…...

数据库操作、锁特性
1. DML、DDL和DQL是数据库操作语言的三种主要类型 1.1 DML(Data Manipulation Language)数据操纵语言 DML是用于检索、插入、更新和删除数据库中数据的SQL语句。 主要的DML语句包括: SELECT:用于查询数据库中的数据。 INSERT&a…...

学习笔记039——SpringBoot整合Redis
文章目录 1、Redis 基本操作Redis 默认有 16 个数据库,使用的是第 0 个,切换数据库添加数据/修改数据查询数据批量添加批量查询删除数据查询所有的 key清除当前数据库清除所有数据库查看 key 是否存在设置有效期查看有效期 2、Redis 数据类型String追加字…...

(笔记)简单了解ZYNQ
1、zynq首先是一个片上操作系统(Soc),结合了arm(PS)和fpga(PL)两部分组成 Zynq系统主要由两部分组成:PS(Processing System)和PL(Programmable L…...

大众点评小程序mtgsig1.2算法
测试效果: var e function _typeof(o) {return "function" typeof Symbol && "symbol" typeof Symbol.iterator? function (o) {return typeof o;}: function (o) {return o && "function" typeof Symbol &…...

七牛云AIGC内容安全方案助力企业合规创新
随着人工智能生成内容(AIGC)技术的飞速发展,内容审核的难度也随之急剧上升。在传统审核场景中,涉及色情、政治、恐怖主义等内容的标准相对清晰明确,但在AIGC的应用场景中,这些界限变得模糊且难以界定。用户可能通过交互性引导AI生成违规内容,为审核工作带来了前所未有的不可预测…...

.net的winfrom程序 窗体透明打开窗体时出现在屏幕右上角
窗体透明, 将Form的属性Opacity,由默认的100% 调整到 80%,这个数字越小越透明(尽量别低于50%,不信你试试看)! 打开窗体时出现在屏幕右上角 //构造函数 public frmCalendarList() {InitializeComponent();//打开窗体&…...
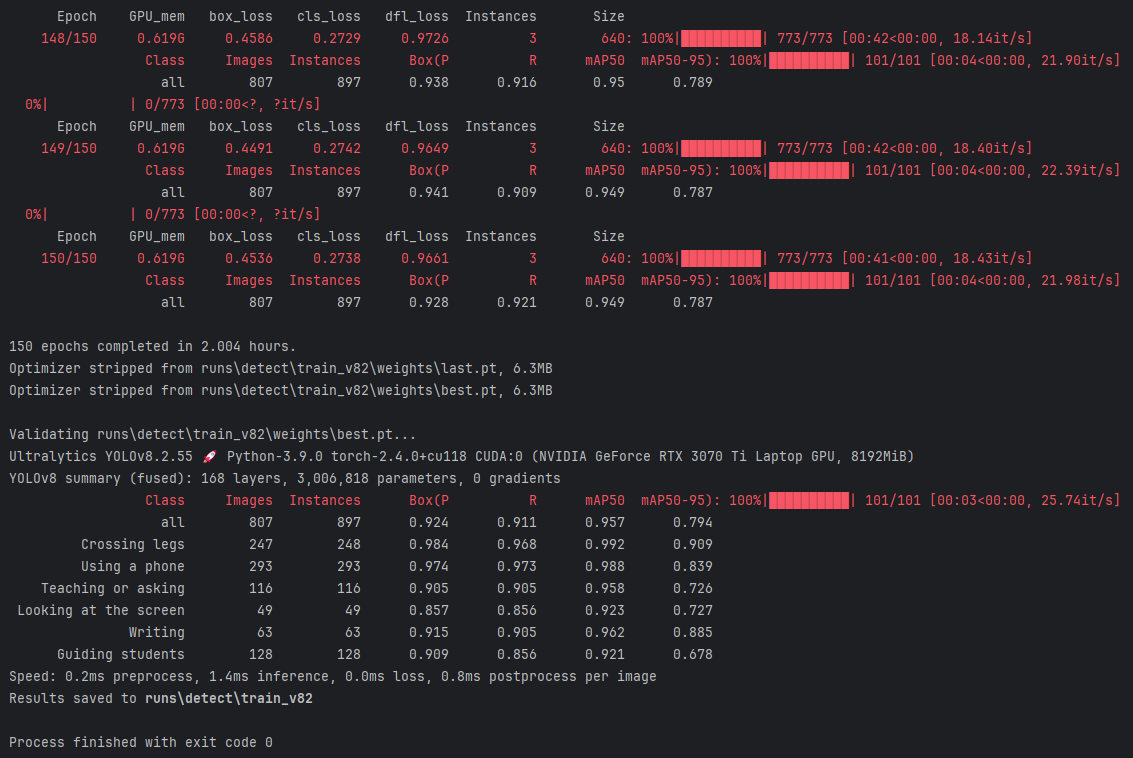
基于YOLOv8深度学习的智慧课堂教师上课行为检测系统研究与实现(PyQt5界面+数据集+训练代码)
随着人工智能技术的迅猛发展,智能课堂行为分析逐渐成为提高教学质量和提升教学效率的关键工具之一。在现代教学环境中,能够实时了解教师的课堂表现和行为,对于促进互动式教学和个性化辅导具有重要意义。传统的课堂行为分析依赖于人工观测&…...

使用 Tkinter 创建一个简单的 GUI 应用程序来合并视频和音频文件
使用 Tkinter 创建一个简单的 GUI 应用程序来合并视频和音频文件 Python 是一门强大的编程语言,它不仅可以用于数据处理、自动化脚本,还可以用于创建图形用户界面 (GUI) 应用程序。在本教程中,我们将使用 Python 的标准库模块 tkinter 创建一…...

【C++笔记】模板进阶
前言 各位读者朋友们大家好!上一期我们讲了stack、queue以及仿函数。先前我们讲过模板的初阶内容,这一期我们来更深入的学习一下模板。 一. 非类型模板参数 1.1 非类型模板参数 模板参数分为类型形参和类类型形参: 类型形参:…...

Soul App创始人张璐团队亮相GITEX GLOBAL 2024,展示多模态AI的交互创新
随着全球AI领域的竞争加剧,越来越多的科技巨头和创新企业纷纷致力于多模态AI的开发。2024年10月14日至18日,GITEX GLOBAL海湾信息技术博览会在迪拜举行,吸引了超过6700家全球科技巨头和创新公司参与,展示了智能互联、人工智能等领域的新成果。 此次展会中,Soul App创始人张璐团…...

ffmpeg.wasm 在浏览器运行ffmpeg操作视频
利用ffmpeg.wasm,可以在浏览器里运行ffmpeg,实现对音视频的操作 参考链接: https://blog.csdn.net/jchsgwbr/article/details/143252044 https://gitee.com/CXBalCai/ffmpeg-template 其他参考 https://github.com/ffmpegwasm/ffmpeg.wasm https://b…...

用Python爬虫“偷窥”1688商品详情:一场数据的奇妙冒险
引言:数据的宝藏 在这个信息爆炸的时代,数据就像是一座座等待挖掘的宝藏。而对于我们这些电商界的探险家来说,1688上的商品详情就是那些闪闪发光的金子。今天,我们将化身为数据的海盗,用Python这把锋利的剑࿰…...

CentOS上如何离线批量自动化部署zabbix 7.0版本客户端
CentOS上如何离线批量自动化部署zabbix 7.0版本客户端 管理的服务器大部分都是CentOS操作系统,版本主要是CentOS 7。因为监控服务器需要,要在前两天搭建的Zabbix 7.0系统上把这些CentOS 7系统都监控起来。因为服务器数量众多,而且有些服务器…...

Android App原生指令通道doCommandNative深度解析与Frida Hook实战
1. 这不是“逆向教程”,而是一次真实App通信链路的解剖现场你有没有遇到过这样的情况:在某A系头部电商App里,点击一个商品卡片,页面秒开;但用常规WebView调试或抓包工具去观察,却看不到任何明显的HTTP请求发…...

微信M4A文件打不开怎么办?m4a转MP3只需一招,小白也能操作
很多人会遇到这种情况:别人通过微信发来一段录音、会议音频、课程音频或者采访素材,文件后缀是.m4a,在微信里可能能播放,但保存到手机本地、发到电脑、导入剪辑软件或者复制到U盘后,就可能出现打不开、无法识别、格式不…...

Unity Android打包卡在detecting sdk tools version的根因与四套解决方案
1. 这个卡在“detecting current sdk tools version”的坑,我踩了三次才摸清门道 Unity打包时卡在“detecting current sdk tools version”这行日志上,光标静止、进度条不动、CPU占用率忽高忽低——你点开Android SDK目录,发现tools文件夹里…...

2026校招人才整体素质洞察
导读:这份《2026 校招人才素质洞察报告》由前程无忧发布,围绕 AI 时代校招变局,依托 800 万 测评数据,系统剖析应届毕业生的素质特征,提出人才筛选新坐标,为企业校招提供战略方向与实操参考。关注公众号&a…...

如何在SketchUp中实现STL文件导入导出:完整3D打印解决方案指南
如何在SketchUp中实现STL文件导入导出:完整3D打印解决方案指南 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你…...

PotPlayer字幕翻译插件:5步实现免费自动化双语字幕体验
PotPlayer字幕翻译插件:5步实现免费自动化双语字幕体验 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 观看外语影视时&…...

百度网盘直链解析:5分钟实现全速下载的终极指南
百度网盘直链解析:5分钟实现全速下载的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的非会员限速而烦恼吗?每次下载大文件都…...

trae之mcp服务初体验 完美实现某视频请求头参数x-ca-sign值逆向
问题提问: 请通过 MCP 服务分析 https://m.yichengwlkj.com/pc?channel=CHANNEL_USK 网站中的 https://api.rrmj.plus/m-station/app/page?position=CHANNEL_USK&pageNum=1&personalRecommend=0 请求链接。该请求的请求头中包含一个名为 x-ca-sign 的参数,该参数的…...

Python HTTPS请求SSL证书验证失败排查指南
1. 这不是requests的bug,是TLS握手失败在敲门你刚写完一行requests.get("https://api.example.com"),回车一按,终端却甩出一长串红色报错:HTTPSConnectionPool(hostapi.example.com, port443): Max retries exceeded wi…...

零起点Python机器学习快速入门【1.0】
第 1 章 从阿尔法狗开始说起1.1 阿尔法狗的前世今生百度百科的“阿尔法狗”词条是:阿尔法狗( AlphaGo)是一款围棋人工智能程序,由谷歌( Google)旗下 DeepMind 公司的戴密斯哈萨比斯、大卫席尔瓦、黄士杰与他…...