MySQL聚合查询分组查询联合查询
#对应代码练习
-- 创建考试成绩表
DROP TABLE IF EXISTS exam;
CREATE TABLE exam (
id bigint,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);
1.聚合函数
| 函数 | 说明 |
| count() | 返回查到数据的数量 |
| sum() | 返回查到数据的总和 |
| avg() | 返回查到数据的平均值 |
| max() | 返回查到数据的最大值 |
| min() | 返回查到数据的最小值 |
注释:不是数字没有意义,聚合函数只能对数字型进行运算
1.1count函数:统计所有的行
select count(*) from 表名;
select count(1) from 表名;
select count(指定列) from 表名;

注释:在日常工作中,推荐大家使用count(*),这种写法是sql中规定
NULL 值不参与统计
1.2sum函数:求和
把查询结果中所有行中的指定列进行相加
注意:列的数据必须是数值型,不能是字符型,日期型等等,如果对非数值型计算,会报警告!
select sum(指定列) from 表名;
示例:所有学生语文成绩的总和

NULL值不参与运算
1.3avg函数:求平均值
select avg(指定列/表达式) as 别名 from 表名;
示例:所有学生语文成绩的总和 的平均值

示例:所有语文,英语,数学三门成绩总和的平均分

1.4max函数,min函数:求最大值,最小值
select max(指定列) as 别名,min(指定列) as 别名 from 表名;
示例:语文最高分,英语最低分

注释:同一列可以用不同的聚合函数
2.分组查询:group by子句
select 中使用group by子句可以对指定列进行分组查询。需要满足:使用group by子句进行分组长训时,select 指定的字段必须是“分组依据字段(需要分组的列)”,其他列想出现,必须包含在聚合函数中
#相关代码练习
create table emp (
id bigint primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary decimal(10, 2) not null
);insert into emp values (null, '马云', '老板', 1500000.00);
insert into emp values (null, '马化腾', '老板', 1800000.00);
insert into emp values (null, 'a哥', '讲师', 10000.00);
insert into emp values (null, 'b哥', '讲师', 12000.00);
insert into emp values (null, 'c姐', '学管', 9000.00);
insert into emp values (null, 'd姐', '学管', 8000.00);
insert into emp values (null, '猪悟能', '游戏角色', 700.5);
insert into emp values (null, '沙和尚', '游戏角色', 333.3);
语法:select 分组的列名,聚合函数(指定列),... from 表名 group by 分组的列;
示例:计算不同角色工资的平均值

注意:round(数值,小数点位数)
示例:round(avg(salary),2)

注意:group by之后可以跟order by子句

3.having 关键字
group by子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用where语句,而是用having语句
where是对表每一行的真实数据进行过滤,where在from之后
having是对分组后,计算出来的结果进行过滤的,having在group by之后
示例:每种角色的平均工资大于1万小于10万

4.联合查询(MySQL中重点内容)
#相关代码练习
CREATE TABLE `class` (
`class_id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`class_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of class
-- ----------------------------
INSERT INTO `class` VALUES (1, '计算机系2019级1班');
INSERT INTO `class` VALUES (2, '中文系2019级3班');
INSERT INTO `class` VALUES (3, '自动化2019级5班');-- ----------------------------
-- Table structure for course
-- ----------------------------CREATE TABLE `course` (
`course_id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`course_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of course
-- ----------------------------
INSERT INTO `course` VALUES (1, 'Java');
INSERT INTO `course` VALUES (2, '中国传统文化');
INSERT INTO `course` VALUES (3, '计算机原理');
INSERT INTO `course` VALUES (4, '语文');
INSERT INTO `course` VALUES (5, '高阶数学');
INSERT INTO `course` VALUES (6, '英文');-- ----------------------------
-- Table structure for student
-- ----------------------------CREATE TABLE `student` (
`student_id` bigint NOT NULL AUTO_INCREMENT,
`sn` varchar(6) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`mail` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`class_id` bigint NULL DEFAULT NULL,
PRIMARY KEY (`student_id`) USING BTREE,
UNIQUE INDEX `sn`(`sn` ASC) USING BTREE,
INDEX `class_id`(`class_id` ASC) USING BTREE,
CONSTRAINT `student_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `class` (`class_id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB AUTO_INCREMENT = 9 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '09982', '黑旋风李逵', 'xuanfeng@qq.com', 1);
INSERT INTO `student` VALUES (2, '00835', '菩提老祖', NULL, 1);
INSERT INTO `student` VALUES (3, '00391', '白素贞', NULL, 1);
INSERT INTO `student` VALUES (4, '00031', '许仙', 'xuxian@qq.com', 1);
INSERT INTO `student` VALUES (5, '00054', '不想毕业', NULL, 1);
INSERT INTO `student` VALUES (6, '51234', '好好说话', 'say@qq.com', 2);
INSERT INTO `student` VALUES (7, '83223', 'tellme', NULL, 2);
INSERT INTO `student` VALUES (8, '09527', '老外学中文', 'foreigner@qq.com', 2);-- ----------------------------
-- Table structure for score
-- ----------------------------CREATE TABLE `score` (
`score_id` bigint NOT NULL AUTO_INCREMENT,
`student_id` bigint NULL DEFAULT NULL,
`course_id` bigint NULL DEFAULT NULL,
`score` decimal(5, 2) NULL DEFAULT NULL,
PRIMARY KEY (`score_id`) USING BTREE,
INDEX `student_id`(`student_id` ASC) USING BTREE,
INDEX `course_id`(`course_id` ASC) USING BTREE,
CONSTRAINT `score_ibfk_1` FOREIGN KEY (`student_id`) REFERENCES `student` (`student_id`) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT `score_ibfk_2` FOREIGN KEY (`course_id`) REFERENCES `course` (`course_id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB AUTO_INCREMENT = 21 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES (1, 1, 1, 70.50);
INSERT INTO `score` VALUES (2, 1, 3, 98.50);
INSERT INTO `score` VALUES (3, 1, 5, 33.00);
INSERT INTO `score` VALUES (4, 1, 6, 98.00);
INSERT INTO `score` VALUES (5, 2, 1, 60.00);
INSERT INTO `score` VALUES (6, 2, 5, 59.50);
INSERT INTO `score` VALUES (7, 3, 1, 33.00);
INSERT INTO `score` VALUES (8, 3, 3, 68.00);
INSERT INTO `score` VALUES (9, 3, 5, 99.00);
INSERT INTO `score` VALUES (10, 4, 1, 67.00);
INSERT INTO `score` VALUES (11, 4, 3, 23.00);
INSERT INTO `score` VALUES (12, 4, 5, 56.00);
INSERT INTO `score` VALUES (13, 4, 6, 72.00);
INSERT INTO `score` VALUES (14, 5, 1, 81.00);
INSERT INTO `score` VALUES (15, 5, 5, 37.00);
INSERT INTO `score` VALUES (16, 6, 2, 56.00);
INSERT INTO `score` VALUES (17, 6, 4, 43.00);
INSERT INTO `score` VALUES (18, 6, 6, 79.00);
INSERT INTO `score` VALUES (19, 7, 2, 80.00);
INSERT INTO `score` VALUES (20, 7, 6, 92.00);
4.1内连接
语法:
#标准写法
select 列名 from 表名1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;#个人习惯写法
select 列名 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件
注释:习惯哪种用哪种!
示例:查询“许仙”同学的成绩(分步骤做这道题)
1.首先确定哪几张表参与查询:成绩表和学生表;
select *from student,score;

2.根据表与表之间的主外键关系,确定过滤条件
student_id作为主外键关联字段
select *from student,score where student.student_id=score.student_id;

3.确定过滤条件
在where中添加student.name='许仙'的过滤条件
select *from student,score where student.student_id=score.student_id and student.`name`='许仙';

4.精简信息
只需要姓名和分数
select student.`name`,score.score from student,score where student.student_id=score.student_id and student.`name`='许仙';

注释:联合查询详细步骤
1.确定查询中涉及到有那些表。2.对目标表取笛卡尔积。3.确定连接条件。4.确定对整个结果集的过滤条件。5.精减查询字段
示例:查询所有同学的总成绩和个人信息
select st.student_id,st.`name`,sum(sc.score) as 总分 from student st,score sc where st.student_id=sc.student_id group by sc.student_id;

4.2外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示就是左外连接,右侧的表全部显示就是右外连接
语法:
select*from 表1 left(right) join 表2 on 连接条件;
示例:查询没有考试的同学
select*from student st left join score sc on st.student_id=sc.student_id where sc.score_id is NULL;

4.3自链接
实现行与行之间的比较功能
注意:自连接时,因为同一张表需要用到两次,所以得起不一样的别名,否则会报错
示例:显示所有计算机原理成绩比Java成绩高的信息(分步骤演示)
1.确定涉及的表:课程表和成绩表
2.取笛卡尔积:select*from score sc1,score sc2;

3.连接条件就是student_id相同
select*from score sc1,score sc2 where sc1.student_id=sc2.student_id;

4.观察结果集,确定过滤条件

1 是Java ,3是计算机原理
要么sc1.course_id=1 and sc2.course_id=3
要么sc1.course_id=3 and sc2.course_id=1
5.加入条件
select*from score sc1,score sc2 where sc1.student_id=sc2.student_id and sc1.course_id=3 and sc2.course_id=1 and sc1.score>sc2.score ;

5.子查询(嵌套查询)
5.1单行子查询
示例:查询与“不想毕业”的同班同学
select *from student where class_id=(select class_id FROM student where `name`='不想毕业');

5.2多行子查询
示例:查询语文和英文成绩信息 (使用到in关键词)
select *from score where course_id in (select course_id from course where `name`='语文' or `name`='英文');

6.exists关键字
语法:select*from 表名 where exists (查询语句);
exists 后面括号中的查询语句,如果有结果正常返回,则执行外层语句;如果返回空,则不执行
相当于if语句的判断条件,有结果返回true,没结果返回false
1.正常返回,因为学号有1的同学

2.返回为空,因为学号没有100的同学
7.合并查询
关键词 union ,union all
语法:select *from 表名1 union/ union all select *from 表名2;
union 会去重,union all不会去重
在单表查询推荐使用 or,多表查询不能用or ,就必须用union来连接
相关文章:

MySQL聚合查询分组查询联合查询
#对应代码练习 -- 创建考试成绩表 DROP TABLE IF EXISTS exam; CREATE TABLE exam ( id bigint, name VARCHAR(20), chinese DECIMAL(3,1), math DECIMAL(3,1), english DECIMAL(3,1) ); -- 插入测试数据 INSERT INTO exam (id,name, chinese, math, engli…...
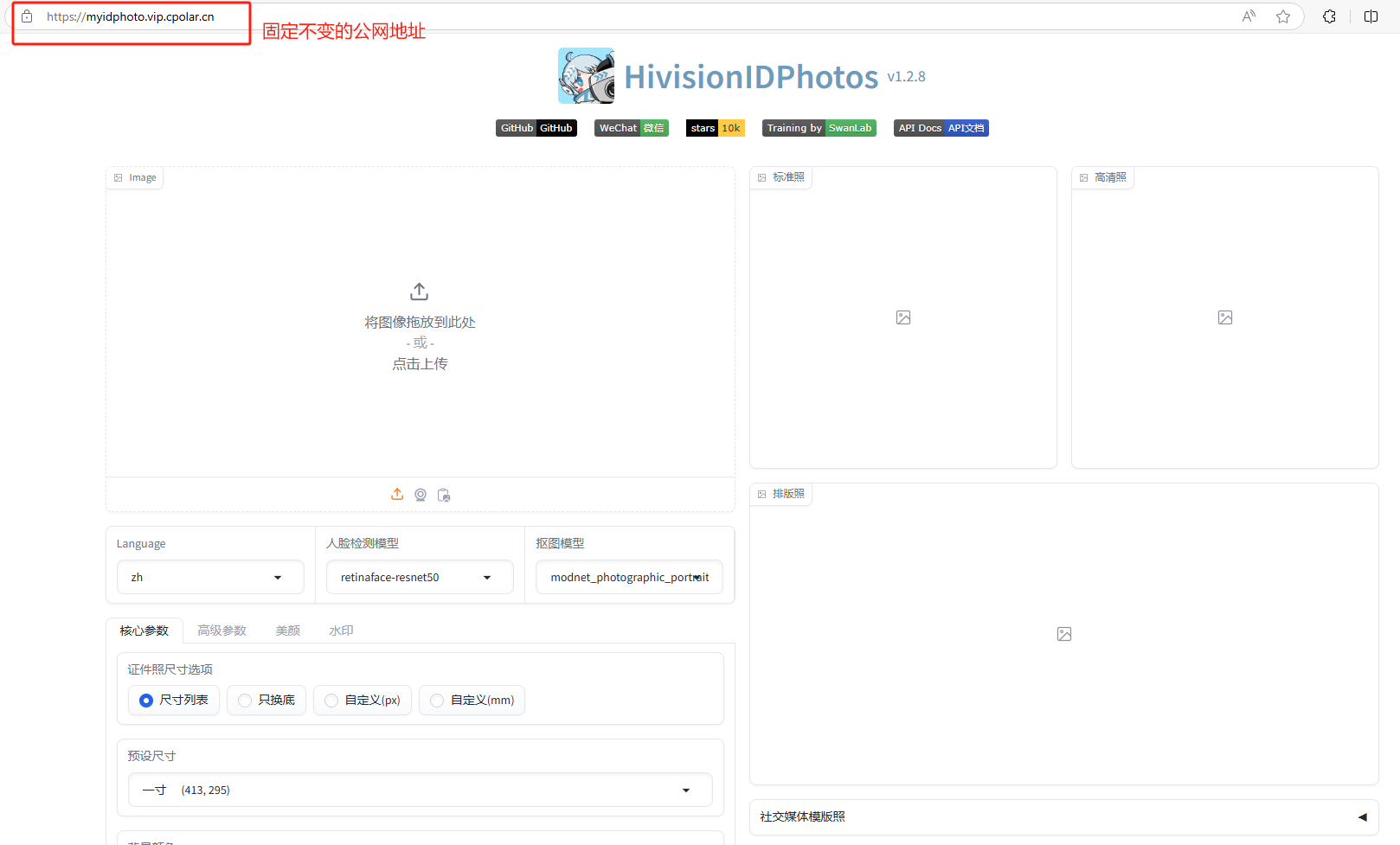
告别照相馆!使用AI证件照工具HivisionIDPhotos打造在线证件照制作软件
文章目录 前言1. 安装Docker2. 本地部署HivisionIDPhotos3. 简单使用介绍4. 公网远程访问制作照片4.1 内网穿透工具安装4.2 创建远程连接公网地址 5. 配置固定公网地址 前言 本文主要介绍如何在Linux系统使用Docker快速部署一个AI证件照工具HivisionIDPhotos,并结合…...

通信原理第三次实验
实验目的与内容 实验操作与结果 5.1 刚开始先不加入白噪声,系统设计如下: 正弦波参数设置如下: FM设计如下: 延迟设计如下: 两个滤波器设计参数如下: 输出信号频谱为(未加入噪声)&a…...

【halcon】Metrology工具系列之 get_metrology_object_result_contour
get_metrology_object_result_contour (操作员) 名称 get_metrology_object_result_contour — 查询测量对象的结果轮廓。 签名 get_metrology_object_result_contour( : Contour : MetrologyHandle, Index, Instance, Resolution : ) 描述 get_metrology_object_result_…...

A052-基于SpringBoot的酒店管理系统
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 赠送计算机毕业设计600…...

NLP信息抽取大总结:三大任务(带Prompt模板)
信息抽取大总结 1.NLP的信息抽取的本质?2.信息抽取三大任务?3.开放域VS限定域4.信息抽取三大范式?范式一:基于自定义规则抽取(2018年前)范式二:基于Bert下游任务建模抽取(2018年后&a…...
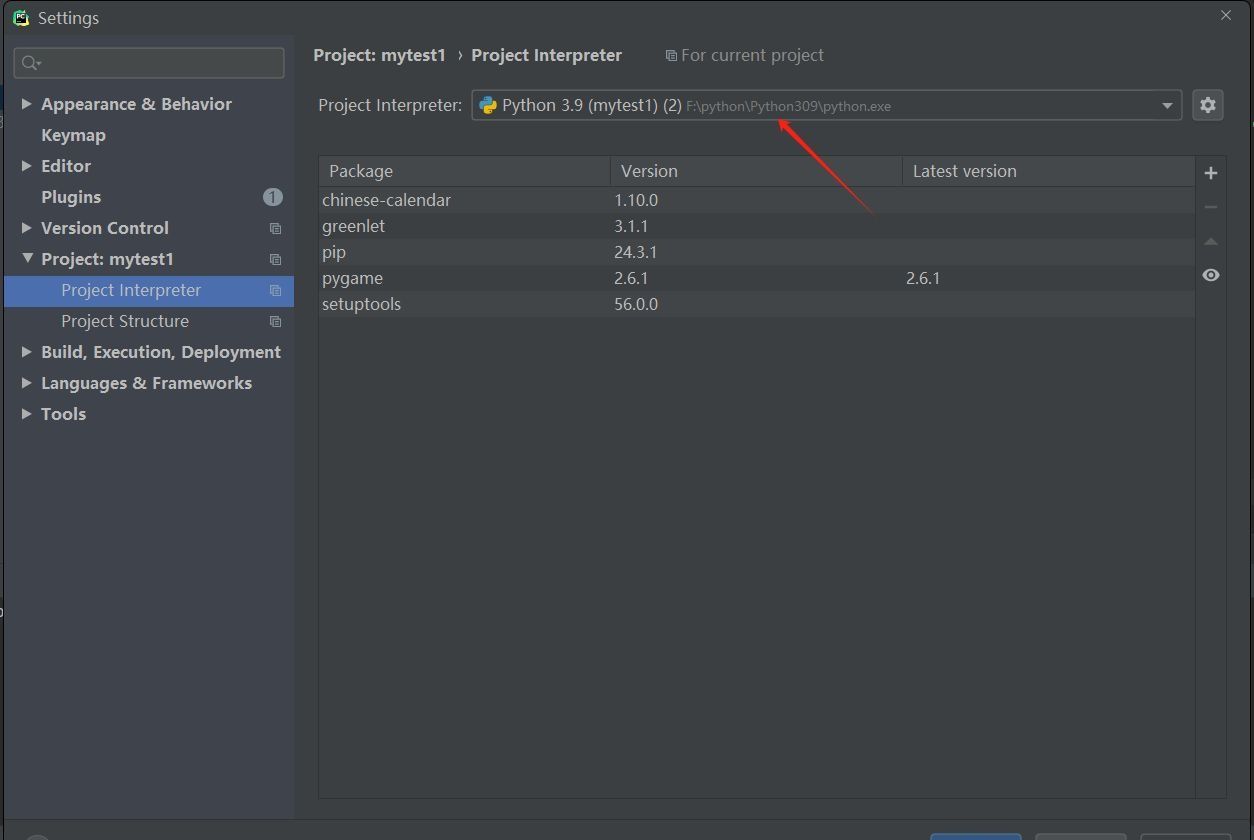
python常见问题-pycharm无法导入三方库
1.运行环境 python版本:Python 3.9.6 需导入的greenlet版本:greenlet 3.1.1 2.当前的问题 由于需要使用到greenlet三方库,所以进行了导入,以下是我个人导入时的全过程 ①首先尝试了第1种导入方式:使用pycharm进行…...

迅为RK3588开发板Android系统开发笔记-使用ADB工具
1 使用 ADB 工具 ADB 英文名叫 Android debug bridge ,是 Android SDK 里面的一个工具,用这个工具可以操作管理 Android 模拟器或者真实的 Android 设备,主要的功能如下所示: 在 Android 设备上运行 shell 终端,用命…...

什么是分布式数据库?
随着现代互联网应用和大数据时代的到来,分布式数据库成为了解决大规模数据存储和高并发处理的核心技术之一。本文将通过深入浅出的方式,带你全面理解分布式数据库的概念、工作原理以及底层实现技术。无论你是刚刚接触分布式数据库的开发者,还…...

Leetcode 3363. Find the Maximum Number of Fruits Collected
Leetcode 3363. Find the Maximum Number of Fruits Collected 1. 解题思路2. 代码实现 题目链接:3363. Find the Maximum Number of Fruits Collected 1. 解题思路 这一题是一道陷阱题…… 乍一眼看过去,由于三人的路线完全可能重叠,因此…...

【数据仓库 | Data Warehouse】数据仓库的四大特性
1. 前言 数据仓库是用于支持管理和决策的数据集合,它汇集了来自不同数据源的历史数据,以便进行多维度的分析和报告。数据仓库的四大特点是:主题性,集成性,稳定性,时变性。 2. 主题性(Subject-Oriented) …...

springboot配置多数据源mysql+TDengine保姆级教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pom文件二、yamlDataSourceConfigServiceMapper.xml测试总结 前言 Mybatis-plus管理多数据源,数据库为mysql和TDengine。 一、pom文件 <de…...

dns实验2:反向解析
启动服务: 给虚拟机网卡添加IP地址: 查看有几个IP地址: 打开配置文件: 重启服务,该宽松模式,关闭防火墙: 本机测试: windows测试:(本地shell)...

ZooKeeper 基础知识总结
先赞后看,Java进阶一大半 ZooKeeper 官网这样介绍道:ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。 各位hao,我是南哥,相信对你通关面试、拿下Offer有所帮助。 ⭐⭐⭐一份南哥编写…...

npm库xss依赖的使用方法和vue3 中Web富文本编辑器 wangeditor 使用xss库解决 XSS 攻击的方法
npm库xss依赖的使用方法和vue3 中Web富文本编辑器 wangeditor 使用xss库解决 XSS 攻击的方法 1. npm库xss依赖的使用方法1.1 xss库定义1.2 xss库功能 2. vue3 中 wangeditor 使用xss库解决 XSS 攻击的方法和示例2.1 在终端执行如下命令安装 xss 依赖2.2 在使用 wangeditor 的地…...

微信小程序蓝牙writeBLECharacteristicValue写入数据返回成功后,实际硬件内信息查询未存储?
问题:连接蓝牙后,调用小程序writeBLECharacteristicValue,返回传输数据成功,查询硬件响应发现没有存储进去? 解决:一直以为是这个write方法的问题,找了很多相关贴,后续进行硬件日志…...

5G NR:带宽与采样率的计算
100M 带宽是122.88Mhz sampling rate这是我们都知道的,那它是怎么来的呢? 采样率 子载波间隔 * 采样长度 38.211中对于Tc的定义, 在LTE是定义了Ts,在NR也就是5G定义了Tc。 定义这个单位会对我们以后工作中的计算至关重要。 就是在…...

go 和java 编写方式的理解
1. go 推荐写流水账式的代码(非贬义),自己管自己。java喜欢封装各种接口供外部调用,让别人来管自己。 2. 因为协程的存在, go的变量作用域聚集在方法内部,即函数不可重入,而java线程的限制&…...

C# 7.1 .Net Framwork4.7 VS2017环境下,方法的引用与调用
方法的调用比较好理解,就是给方法传递实参,执行方法代码。 方法引用涉及委托,委托签名与其引用的方法必须一致。以下demo说明方法调用与引用在写程序时的区别: using System; using System.Collections.Generic; using System.L…...

etcd、kube-apiserver、kube-controller-manager和kube-scheduler有什么区别
在我们部署K8S集群的时候 初始化master节点之后(在master上面执行这条初始化命令) kubeadm init --apiserver-advertise-address10.0.1.176 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.16.0 --service…...

《QGIS空间数据处理与高级制图》004:内置地理处理工具箱
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

5分钟掌握ViGEmBus:Windows游戏控制器模拟终极指南
5分钟掌握ViGEmBus:Windows游戏控制器模拟终极指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款强大的Windows内核级驱动程序&…...

从FastCAE到你的项目:深度解析SARibbon控件在工业软件中的实战应用与避坑指南
从FastCAE到你的项目:深度解析SARibbon控件在工业软件中的实战应用与避坑指南 工业软件界面开发从来不是简单的UI堆砌,而是对工程效率与用户体验的极致追求。在CAE、CAD等专业领域,一个优秀的Ribbon控件往往能成为提升工程师工作效率的隐形利…...
PyVideoTrans视频翻译AI配音全攻略:从零开始掌握多语言视频创作
PyVideoTrans视频翻译AI配音全攻略:从零开始掌握多语言视频创作 【免费下载链接】pyvideotrans Translate the video from one language to another and embed dubbing & subtitles. 项目地址: https://gitcode.com/gh_mirrors/py/pyvideotrans PyVideoT…...

软工大学生亲测:用 Claude Code 武装自己,从学渣到 offer 收割机
大家好,我是一个既研究过 K 线、又写过几十万行代码的老学姐。最近一个软件工程大三的实习生问我:"师姐,我感觉自己什么都不会,投了 300 份简历,石沉大海……"我当时差点把咖啡喷出来——不是因为他惨&#…...

终极指南:如何用SMUDebugTool免费深度调校你的AMD Ryzen处理器 [特殊字符]
终极指南:如何用SMUDebugTool免费深度调校你的AMD Ryzen处理器 🚀 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. …...

Java源码学习:深入剖析Java的concurrent包源码之`ReentrantLock` 的精妙设计与云原生演进
引言:从 synchronized 到可编程的锁 在 Java 并发编程的演进史上,synchronized 关键字曾是开发者控制线程同步的唯一选择。它简单、易用,并由 JVM 保证其正确性。然而,随着应用复杂度的提升,其固有的局限性——如无法中…...

8.4.3 开始屏幕和任务栏的优化:StartAllBack 找回高效 Windows 11 使用体验
🔥 个人主页: 杨利杰YJlio ❄️ 个人专栏: 《Sysinternals实战教程》 《Windows PowerShell 实战》 《WINDOWS教程》 《IOS教程》 《微信助手》 《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》 🌟 让…...
给你的数据曲线做个‘美容’)
别再只用Matplotlib画图了!用Python这3个库(SciPy, NumPy, Scikit-learn)给你的数据曲线做个‘美容’
Python数据平滑三剑客:用Savitzky-Golay、插值与滑动平均打造专业级图表 当你面对满是噪点的折线图时,是否想过这些锯齿状的波动正在掩盖数据的真实故事?就像摄影师不会直接发布未经修饰的RAW格式照片,数据科学家也需要掌握图表美…...

Linux超级计算机Roadrunner的设计与优化实践
1. Linux超级计算机Roadrunner的设计背景与核心理念在1990年代末期,高性能计算领域正处于一个关键的转折点。传统超级计算机如Cray系列虽然性能强大,但价格昂贵且维护成本极高,使得大多数研究机构难以负担。与此同时,个人计算机性…...