循环神经网络:从基础到应用的深度解析
🍛循环神经网络(RNN)概述
循环神经网络(Recurrent Neural Network, RNN)是一种能够处理时序数据或序列数据的深度学习模型。不同于传统的前馈神经网络,RNN具有内存单元,能够捕捉序列中前后信息之间的依赖关系。RNN在自然语言处理、语音识别、时间序列预测等领域中具有广泛的应用。
RNN的核心思想是通过循环结构使网络能够记住前一个时刻的信息。每一个时间步,输入不仅依赖于当前的输入数据,还依赖于前一时刻的状态,从而使得RNN能够处理时序信息。
🍛循环神经网络的基本单元
RNN的基本单元由以下部分组成:
- 输入(Input):在每个时间步,输入当前时刻的数据。
- 隐藏状态(Hidden State):每个时间步都有一个隐藏状态,代表对当前输入及前一时刻信息的记忆。
- 输出(Output):根据当前输入和隐藏状态生成输出。
在数学上,RNN的计算可以表示为以下公式:
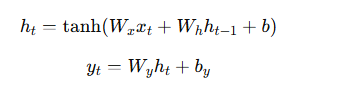
🍛循环神经网络的网络结构
RNN的网络结构可以分为以下几种类型:
- 单层RNN:最简单的RNN结构,只包括一个隐藏层。
- 多层RNN(堆叠RNN):通过堆叠多个RNN层,增加模型的复杂性和表达能力。
- 双向RNN(BiRNN):双向RNN同时考虑了从前往后和从后往前的时序信息,能够获得更加丰富的上下文信息。
- 深度循环神经网络(DRNN):通过增加网络的深度(堆叠多个RNN层)来提高模型的表示能力。
🍛长短时记忆网络(LSTM)
传统的RNN在处理长序列数据时存在梯度消失和梯度爆炸的问题,长短时记忆网络(LSTM)通过引入门控机制来解决这一问题。
LSTM通过使用三个门(输入门、遗忘门和输出门)来控制信息的流动。LSTM的更新过程如下:
- 遗忘门:决定忘记多少旧的信息。
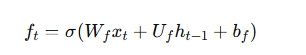
输入门:决定当前时刻的输入信息有多少更新到记忆单元。
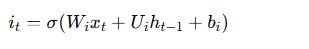
输出门:决定记忆单元的多少信息输出到当前的隐藏状态。
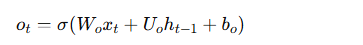
记忆更新:根据遗忘门和输入门更新记忆单元的状态。
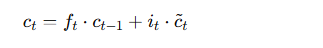
🍛双向循环神经网络(BiRNN)和深度循环神经网络(DRNN)
- 双向RNN(BiRNN):为了捕捉从前到后的信息,双向RNN通过在两个方向上运行两个独立的RNN来获取完整的上下文信息。通过这种结构,BiRNN能够更好地处理具有复杂依赖关系的时序数据。
公式如下:
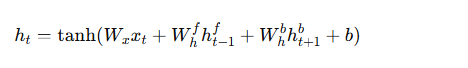
深度循环神经网络(DRNN):通过堆叠多个RNN层,形成深度结构,DRNN能够捕捉更高层次的特征和时序依赖。多层的RNN允许网络从更抽象的层次进行学习。
🍛序列标注与应用
RNN在序列标注任务中的应用非常广泛,尤其是在自然语言处理(NLP)领域。常见的任务包括:
- 命名实体识别(NER):识别文本中的人物、地点、组织等实体。
- 词性标注(POS Tagging):标注每个单词的词性(如名词、动词等)。
- 语音识别:将语音信号转化为文字。
- 情感分析:分析文本的情感倾向。
通过在RNN的输出层使用Softmax激活函数,可以实现多分类任务,如对每个时间步的输入数据进行分类。
🍛代码实现与示例
以下是一个简单的基于PyTorch的RNN模型实现,用于文本分类任务,代码仅供参考
import torch
import torch.nn as nn
import torch.optim as optim# 定义RNN模型
class RNNModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNNModel, self).__init__()self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# x: 输入的序列数据out, _ = self.rnn(x) # 获取RNN的输出out = out[:, -1, :] # 只取最后一个时间步的输出out = self.fc(out)return out# 参数设置
input_size = 10 # 输入特征的维度
hidden_size = 50 # 隐藏层的维度
output_size = 2 # 输出的类别数(例如,二分类问题)# 创建模型
model = RNNModel(input_size, hidden_size, output_size)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 示例输入数据
inputs = torch.randn(32, 5, input_size) # 32个样本,每个样本有5个时间步,输入特征维度为10
labels = torch.randint(0, 2, (32,)) # 随机生成标签,2类# 训练过程
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()print(f"Loss: {loss.item()}")
🍛实战(IMDB影评数据集)
环境准备
pip install torch torchvision torchaudio torchtext
完整源码
代码仅供参考
import torch
import torch.nn as nn
import torch.optim as optim
import torchtext
from torchtext.datasets import IMDB
from torchtext.data import Field, BucketIterator# 数据预处理
TEXT = Field(sequential=True, tokenize='spacy', include_lengths=True)
LABEL = Field(sequential=False, use_vocab=True, is_target=True)# 下载IMDB数据集
train_data, test_data = IMDB.splits(TEXT, LABEL)# 构建词汇表并用预训练的GloVe词向量初始化
TEXT.build_vocab(train_data, vectors='glove.6B.100d', min_freq=10)
LABEL.build_vocab(train_data)# 创建训练和测试数据迭代器
train_iterator, test_iterator = BucketIterator.splits((train_data, test_data),batch_size=64,device=torch.device('cuda' if torch.cuda.is_available() else 'cpu'),sort_within_batch=True,sort_key=lambda x: len(x.text)
)# 定义RNN模型
class RNNModel(nn.Module):def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, dropout):super(RNNModel, self).__init__()self.embedding = nn.Embedding(input_dim, embedding_dim)self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, dropout=dropout, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, text, text_lengths):embedded = self.embedding(text)packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths, batch_first=True, enforce_sorted=False)packed_output, hidden = self.rnn(packed_embedded)output = self.dropout(hidden[-1])return self.fc(output)# 超参数设置
input_dim = len(TEXT.vocab)
embedding_dim = 100
hidden_dim = 256
output_dim = len(LABEL.vocab)
n_layers = 2
dropout = 0.5# 初始化模型、损失函数和优化器
model = RNNModel(input_dim, embedding_dim, hidden_dim, output_dim, n_layers, dropout)
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()# 将模型和数据转移到GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)# 训练模型
def train(model, iterator, optimizer, criterion):model.train()epoch_loss = 0epoch_acc = 0for batch in iterator:text, text_lengths = batch.textlabels = batch.labeloptimizer.zero_grad()# 预测predictions = model(text, text_lengths).squeeze(1)# 计算损失和准确率loss = criterion(predictions, labels)acc = binary_accuracy(predictions, labels)# 反向传播loss.backward()optimizer.step()epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)# 计算二分类准确率
def binary_accuracy(predictions, labels):preds = torch.argmax(predictions, dim=1)correct = (preds == labels).float()return correct.sum() / len(correct)# 测试模型
def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0epoch_acc = 0with torch.no_grad():for batch in iterator:text, text_lengths = batch.textlabels = batch.labelpredictions = model(text, text_lengths).squeeze(1)loss = criterion(predictions, labels)acc = binary_accuracy(predictions, labels)epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)# 训练过程
N_EPOCHS = 5
for epoch in range(N_EPOCHS):train_loss, train_acc = train(model, train_iterator, optimizer, criterion)test_loss, test_acc = evaluate(model, test_iterator, criterion)print(f'Epoch {epoch+1}/{N_EPOCHS}')print(f'Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
-
数据预处理:
- 我们使用了torchtext库来下载和处理IMDB影评数据集。
- 通过
Field定义了文本和标签的预处理方法。tokenize='spacy'表示使用Spacy库进行分词。 build_vocab方法用来建立词汇表,并加载GloVe预训练词向量。
-
模型定义:
-
RNNModel
类定义了一个基础的循环神经网络模型。它包含:
- 一个嵌入层(Embedding),将词汇映射为向量。
- 一个RNN层,处理序列数据。
- 一个全连接层,将隐藏状态映射为最终的输出(情感分类)。
-
我们在RNN层中使用了
pack_padded_sequence来处理不同长度的序列。
-
-
训练和评估:
- 训练和评估函数
train和evaluate分别用于训练和评估模型。 - 使用
Adam优化器和CrossEntropyLoss损失函数进行训练。
- 训练和评估函数
-
准确率计算:
binary_accuracy函数计算预测结果的准确率,适用于二分类问题。
模型评估
模型会输出每个epoch的训练损失和准确率,以及测试损失和准确率,具体结果可以参考下图
注意:en_core_web_sm模型配置下载
🍛总结
循环神经网络(RNN)及其变种如LSTM、BiRNN和DRNN在处理时序数据和序列标注任务中表现出色。尽管RNN存在梯度消失问题,但通过改进的结构(如LSTM和GRU)和双向结构,我们可以更好地捕捉时序数据中的长期依赖。随着深度学习技术的不断进步,RNN及其变种将在更多的实际应用中展现出强大的性能
🍛参考文献
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
结果可以参考下图
注意:en_core_web_sm模型配置下载
🍛总结
循环神经网络(RNN)及其变种如LSTM、BiRNN和DRNN在处理时序数据和序列标注任务中表现出色。尽管RNN存在梯度消失问题,但通过改进的结构(如LSTM和GRU)和双向结构,我们可以更好地捕捉时序数据中的长期依赖。随着深度学习技术的不断进步,RNN及其变种将在更多的实际应用中展现出强大的性能
🍛参考文献
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Graves, A., & Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks, 18(5-6), 602-610.

相关文章:
循环神经网络:从基础到应用的深度解析
🍛循环神经网络(RNN)概述 循环神经网络(Recurrent Neural Network, RNN)是一种能够处理时序数据或序列数据的深度学习模型。不同于传统的前馈神经网络,RNN具有内存单元,能够捕捉序列中前后信息…...

从扩散模型开始的生成模型范式演变--SDE
SDE是在分数生成模型的基础上,将加噪过程扩展时连续、无限状态,使得扩散模型的正向、逆向过程通过SDE表示。在前文讲解DDPM后,本文主要讲解SDE扩散模型原理。本文内容主要来自B站Up主deep_thoughts分享视频Score Diffusion Model分数扩散模型…...

【python使用kazoo连ZooKeeper基础使用】
from kazoo.client import KazooClient, KazooState from kazoo.exceptions import NoNodeError,NodeExistsError,NotEmptyError import json# 创建 KazooClient 实例,连接到 ZooKeeper 服务器 zk KazooClient(hosts127.0.0.1:2181) zk.start()# 定义节点路径 path…...

【设计模式系列】解释器模式(十七)
一、什么是解释器模式 解释器模式(Interpreter Pattern)是一种行为型设计模式,它的核心思想是分离实现与解释执行。它用于定义语言的文法规则,并解释执行语言中的表达式。这种模式通常是将每个表达式抽象成一个类,并通…...

只出现一次的数字
只出现一次的数字 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。 示例 1 ÿ…...

SpringMVC-08-json
8. Json 8.1. 什么是Json JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式,目前使用特别广泛。采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。易于人阅读和编写…...

技术文档的语言表达
技术文档的语言表达 在这个瞬息万变的技术世界中,了解如何撰写有效的技术文档显得尤为重要。无论是开发团队还是最终用户,清晰、简洁且有条理的文档都是连接各方的桥梁。本文将深入探讨技术文档的语言表达,从其重要性、写作原则到各种类型&a…...

UEFI 事件
UEFI 不再支持中断(准确地说,UEFI 不再为开发者提供中断支持,但在UEFI内部还是使用了时钟中断),所有的异步操作都要通过事件(Event)来完成。 启动服务为开发者提供了用于操作事件、定时器及TPL…...

大师开讲-图形学领域顶级专家王锐开讲Vulkan、VSG开源引擎
王锐,毕业于清华大学,图形学领域顶级专家,开源技术社区的贡献者与推广者。三维引擎OpenSceneGraph的核心基石开发者与维护者,倾斜摄影数据格式osgb的发明人。著有《OpenSceneGraph 3 Cookbook》,《OpenSceneGraph 3 Beginers Guid…...

小F的矩阵值调整
问题描述 小F得到了一个矩阵。如果矩阵中某一个格子的值是偶数,则该值变为它的三倍;如果是奇数,则保持不变。小F想知道调整后的矩阵是什么样子的。 测试样例 样例1: 输入:a [[1, 2, 3], [4, 5, 6]] 输出:…...

ORB-SLAM2 ----- LocalMapping::SearchInNeighbors()
文章目录 一、函数意义二、函数讲解三、函数代码四、本函数使用的匹配方法ORBmatcher::Fuse()1. 函数讲解2. 函数代码 四、总结 一、函数意义 本函数是用于地图点融合的函数,前面的函数生成了新的地图点,但这些地图点可能在前面的关键帧中已经生成过了&a…...

给UE5优化一丢丢编辑器性能
背后的原理 先看FActorIterator的定义 /*** Actor iterator* Note that when Playing In Editor, this will find actors only in CurrentWorld*/ class FActorIterator : public TActorIteratorBase<FActorIterator> {//..... }找到基类TActorIteratorBase /*** Temp…...

【Docker】常用命令汇总
Docker 是1个开源的应用容器引擎,基于Go 语言并遵从 Apache2.0 协议开源。 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全使用沙箱机制,相…...

Mybatis:CRUD数据操作之多条件查询及动态SQL
Mybatis基础环境准备请看:Mybatis基础环境准备 本篇讲解Mybati数据CRUD数据操作之多条件查询 1,编写接口方法 在 com.itheima.mapper 包写创建名为 BrandMapper 的接口。在 BrandMapper 接口中定义多条件查询的方法。 而该功能有三个参数,…...

【笔记】轻型民用无人驾驶航空器安全操控
《轻型民用无人驾驶航空器安全操控》 理论考试培训材料 法规部分 【民用无人驾驶航空器的分类】 1、如何定义微型、轻型无人驾驶航空器? 微型无人驾驶航空器,是指空机重量小于0.25千克,最大平飞速度不超过40千米/小时,无线电发…...

TouchGFX设计模式代码实例说明
一)Model - View - Presenter (MVP) 模式在 TouchGFX 中的应用 1)Model(模型): 模型代表应用程序的数据和业务逻辑。例如,在一个简单的计数器应用中,模型可以是一个包含计数器当前值的类。 class CounterModel { pri…...

flink学习(7)——window
概述 窗口的长度(大小): 决定了要计算最近多长时间的数据 窗口的间隔: 决定了每隔多久计算一次 举例:每隔10min,计算最近24h的热搜词,24小时是长度,每隔10分钟是间隔。 窗口的分类 1、根据window前是否调用keyBy分为键控窗口和非键控窗口…...

restTemplate get请求
报错解释: 这个报错信息表明在使用RestTemplate进行GET请求时,需要提供一个请求类型(reqType),但是传入的值为空。这通常意味着在构建请求或者调用方法时,没有正确设置请求的Content-Type头部,…...

ffmpeg 预设的值 加速
centos 安装ffmpeg 编译安装 官网获取最新的linux ffmpeg 代码 https://ffmpeg.org//releases/ mkdir -p /data/app/ffmpeg cd /data/app/ffmpeg wget http://www.ffmpeg.org/releases/ffmpeg-7.1.tar.gz tar -zxvf ffmpeg-7.1.tar.gz#安装所需的编译环境 yum install -y \…...

maven <scope>compile</scope>作用
在 Maven 项目中, 元素用于定义依赖项的作用范围。 元素可以有多个值,每个值表示不同的作用范围。其中,scope compile scope 是默认的作用范围,表示该依赖项在编译、测试和运行时都需要。 scope compile scope 的含义 1、编译时…...
)
别再死记硬背了!用Pointer Network搞定NLP里的OOV难题(附代码实战)
Pointer Network实战:如何优雅解决NLP中的OOV难题 在电商客服机器人开发中,你是否遇到过这样的尴尬场景:当用户询问"冰墩墩什么时候补货"时,机器人却回复"该商品暂无库存"——它完全没理解"冰墩墩"…...
)
别再折腾源码编译了!Ubuntu 22.04 LTS下用apt-get一键部署Asterisk PBX(附SIP账号配置详解)
别再折腾源码编译了!Ubuntu 22.04 LTS下用apt-get一键部署Asterisk PBX(附SIP账号配置详解) 在开源通信领域,Asterisk作为功能最强大的PBX系统之一,长期困扰初学者的不是其丰富的功能,而是复杂的编译安装过…...

终极指南:用FanControl轻松掌控Windows电脑风扇,告别噪音烦恼
终极指南:用FanControl轻松掌控Windows电脑风扇,告别噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/…...

深入解析:NRF24L01如何“伪装”成蓝牙设备?STM32实战代码拆解
深入解析:NRF24L01如何“伪装”成蓝牙设备?STM32实战代码拆解 在物联网设备爆炸式增长的今天,2.4GHz频段已成为无线通信的主战场。NRF24L01作为一款经典的射频芯片,以其低廉的价格和稳定的性能赢得了大量开发者的青睐。而蓝牙技术…...

xAI解散并入SpaceX,马斯克AI战略转向卖算力,太空AI之梦能否实现?
一、败者食尘xAI解散了?马斯克的Grok难道要凉凉?最近几天,这则新闻在科技圈里刷屏了,消息来源就是马斯克本人,他在社交账号上公布消息称,“xAI将解散并停止作为独立公司运营,会并入SpaceX AI&am…...

iOS 27 开放 AI 生态@ACP#专业视频处理新标杆 ——GSV9001E/S 赋能 iPhone AI 多屏智能显示
一、iOS 27 开放 AI:引爆专业视频处理与多屏显示刚需iOS 27 全面开放第三方 AI 模型,iPhone 成为 AI 内容生成、多源信号整合、智能交互核心,直接催生AI 多屏拼接、无缝切换、画中画、HDR/SDR 转换、车载 / 工控多视图、医疗 AI 显示六大专业…...

为什么92%参会者在P3东区绕行超4分钟?2026大会停车动线算法白皮书首度披露
更多请点击: https://intelliparadigm.com 第一章:2026年AI技术大会停车指引概览 2026年AI技术大会主会场设于上海张江科学城国际会展中心,周边共开放3个智能停车场(P1–P3),全部支持车牌自动识别、无感支…...

AI编程工具全景指南:从CLI到智能体,构建高效开发工作流
1. 项目概述:一份为“氛围编码”时代量身定制的开发者地图如果你是一名开发者,最近几个月一定被“氛围编码”这个词刷屏了。从Cursor、Claude Code到各种AI原生IDE和代理工具,我们仿佛一夜之间进入了一个新的编程范式。但问题也随之而来&…...

IDEA进阶指南:巧用Changelist实现多任务并行开发
1. 为什么你需要Changelist功能 作为一个长期使用IDEA进行开发的程序员,我深刻理解多任务并行开发时的痛苦。想象一下这样的场景:你正在开发一个新功能,突然产品经理跑过来说有个紧急bug需要立即修复。这时候你会怎么做?传统做法可…...

KeyMapper终极指南:重新定义Android设备按键功能的完整教程
KeyMapper终极指南:重新定义Android设备按键功能的完整教程 【免费下载链接】KeyMapper An Android app to remap the buttons on your devices 项目地址: https://gitcode.com/gh_mirrors/ke/KeyMapper 你是否曾想过自定义Android设备的按键功能?…...