Milvus×Florence:一文读懂如何构建多任务视觉模型


近两年来多任务学习(Multi-task learning)正取代传统的单任务学习(single-task learning),逐渐成为人工智能领域的主流研究方向。其原因在于,多任务学习可以让我们以最少的人力投入,获得尽可能多的AI能力。比如ChatGPT,就是一种基于多任务学习的自然语言生成模型。通过海量的数据训练,以及针对特定任务的模型微调,ChatGPT可以拥有极高的性能以及广泛的通用性。
这种单任务向多任务的转变趋势在计算机视觉领域体现的尤为明显。传统的计算机视觉算法框架下我们往往需要针对不同的任务去创建不同的模型,比如人脸识别需要特定的算法,猫脸识别需要特定算法,花草识别又需要另一套算法。这就导致整体的训练效率低下不说,算法的可扩展性也受到了极大的限制。
针对这一问题,除了典型的ChatGPT的解法之外,微软推出了一种名叫Florence的新的计算机视觉基础模型。Florence是一种典型的多任务学习计算机视觉模型,可以完成包括图像分类、目标检测、视觉问答和视频分析在内的多种类型的视觉任务,并且在每一个子任务中的表现通常都优于传统的单任务学习模型,与此同时,scaling law也适用于Florence模型,数据规模越大,模型的智能程度也就越高。
接下来我们将重点解读Florence 模型的结构、训练方法、能力,以及对未来的AI和计算机视觉的潜在影响。
01.
传统单任务计算机视觉模型的缺陷
将各种计算机视觉任务的类型进行总结,我们可以将其简单概括为三大维度:时间、空间、模态。
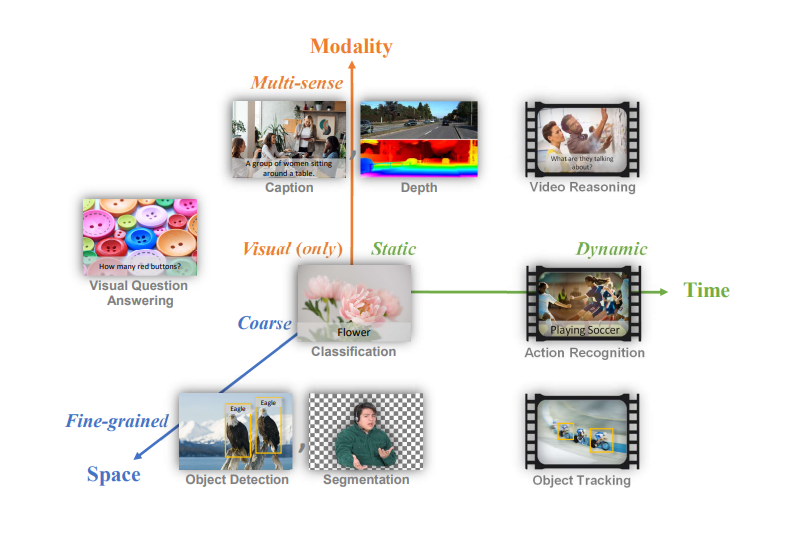
图1:映射到时空模态空间的常见计算机视觉任务
空间:既包括粗粒度的场景理解,也包括细粒度的目标检测和分割。在粗粒度层面上,有图像分类这样的任务,旨在识别图像的主要主题。细粒度分析,则包括了目标检测等任务,需要识别并定位图像中的多个目标并分割任务,这要求精确描绘目标边界。
时间:计算机视觉任务涉及静态图像和动态视频。静态任务包括图像分类、目标检测和视觉问答。动态任务涉及分析随时间变化的图像序列,例如视频中的动作识别或目标跟踪。
模态:纯视觉任务包括图像分类和目标检测,而多模态任务,则会将视觉数据与其他类型的信息相结合,例如文本(在图像描述或视觉问答中)、深度信息,甚至是一些视频分析任务中的音频。
传统意义上,我们需要针对不同任务训练不同的模型,但这种单任务学习的模式存在三大问题:
开发和部署效率低下:为每个任务创建和维护单独的模型需要大量资源且耗时。
知识迁移的困难:为一项任务优化的模型通常难以将学到的知识应用于其他的相关任务。
处理新情况的能力有限:当面对与训练数据显著不同的场景时,专用模型可能表现不佳。
02.
Florence 简介
与上文提到的单任务模型形成对比,Florence 旨在开发一个通用的基础模型,并在架构中集成了多个组件,每个组件分别解决包括图像识别、目标检测以及视觉问答和图像描述、视觉理解等不同方面任务。其最大特色是该模型利用视觉和语言理解的组合来处理和解释文本和视觉数据,使其特别适合需要多模态能力的应用。
具体来说,Florence 的多功能性源于其统一的架构,其架构有两个主要组件:Florence预训练模型(Pretrained Models)和Florence适配模型(Adaptation Models)。
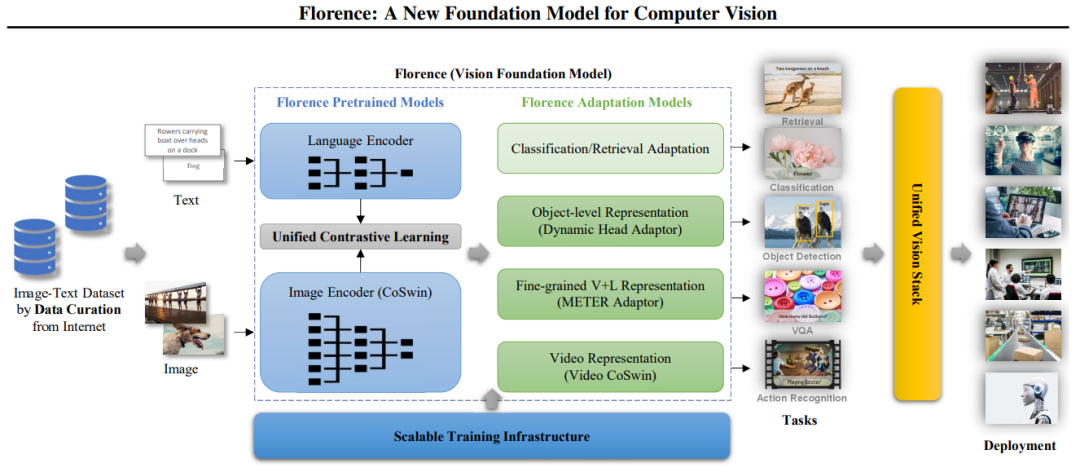
图2:构建Florence的工作流程:从数据管理到部署
2.1 Florence 预训练模型
Florence预训练模型由几个关键组件组成,用于有效处理和对齐视觉和文本数据。
语言编码器:该组件处理文本输入,允许模型理解和生成与视觉内容相关的语言。它类似于BERT或GPT等模型,但能与视觉信息一起工作。
图像编码器(CoSwin):基于CoSwin的分层视觉转换器,该编码器处理视觉信息,将原始像素数据转换为有意义的表示。它建立在自然语言处理中 transformer 的架构基础上,使其适用于图像处理。
统一对比学习:该模块对齐视觉和文本表示,使模型能够理解图像及其描述之间的关系,帮助模型学习哪些文本对应哪些图像,反之亦然。
2.2 Florence 任务适配模型
该模型旨在通过小样本和零样本迁移学习来有效适配各种不同类型任务,并通过很少的 epoch 训练进行有效部署。具体来说,该组件支持:
1. 分类/检索适配:该组件允许Florence执行图像分类和跨模态检索任务。例如,它可以将图像分类为预定义的类别,或查找与给定文本描述相匹配的图像。
2. 对象级表示 (Dynamic Head 适配器):该适配器支持细粒度的目标检测和分割任务,允许模型对图像中的内容进行分类,并定位和勾勒特定对象。
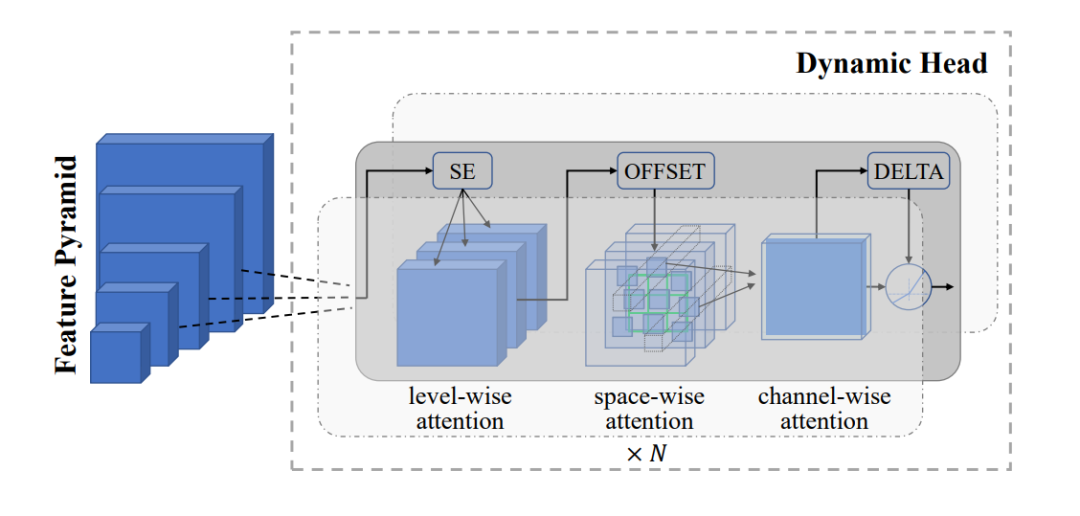
图3:用于对象级视觉表示学习的 Dynamic Head 适配器
如上图所示, Dynamic Head 适配器通过一系列注意力机制处理视觉信息:
输入是一个包含不同尺度视觉信息的特征金字塔。例如,在繁忙街景的图像中:
最大的块可能代表建筑物和道路的整体布局。
中间的街区可能会捕捉到单独的汽车和行人。
最小的块可以专注于细节,如车牌或面部特征。
适配器采用三种类型的注意力:
层次注意力(Level-wise attention, SE):侧重于金字塔不同层次的重要特征。在我们的街景中,SE可能会强调车辆检测任务中的汽车层次,或人物识别任务中的面部特征层次。
空间注意力(Space-wise attention):这涉及每个级别内的相关空间位置,由3D网格表示。例如,当寻找行人时,它可能会关注人行道区域,当检测车辆时,它可能会关注道路区域。
通道注意力(Channel-wise attention):强调了重要的特征通道,显示为最后一个块。一些通道可能更适合检测形状,而其他通道可能更适合检测颜色信息。
OFFSET和DELTA组件微调空间边界。它们有助于精确定位目标边界,例如准确勾勒街景中的汽车或人物。
这种多阶段注意力过程使模型能够通过关注不同尺度和空间位置上最相关的信息来检测和分割对象。例如,它可以同时检测像公交车这样的大型物体,像汽车这样的中型物体,以及像街景中的交通标志这样的小型物体。
3. 细粒度V+L表示(METER适配器):该模块支持视觉-语言任务,如视觉问答和图像描述。它使模型能够理解视觉和文本信息之间的复杂关系。
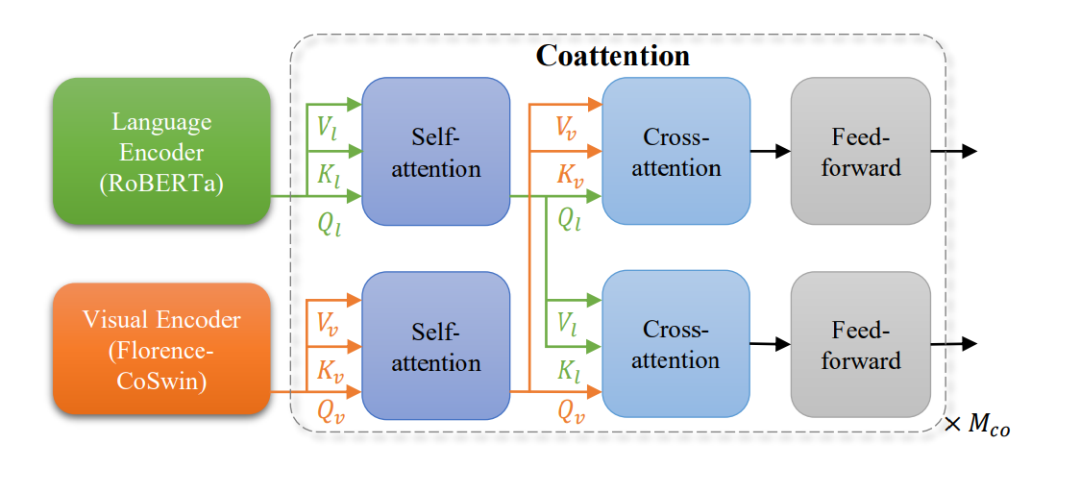
图4:用作Florence V+L适配模型的METER适配器
上图所示的METER适配器使用共同注意力机制来融合视觉和文本信息。让我们看看它的工作原理:
语言编码器(RoBERTa)处理文本输入。例如,它可能会处理以下问题:“停在消防栓旁边的汽车是什么颜色的?”
视觉编码器(Florence-CoSwin)处理视觉输入。这将分析街景的图像。
两个输入都经过单独的自注意力层,允许每种模态独立处理其信息。文本自注意力可能集中在颜色、汽车和消防栓等关键词上,而视觉自注意力可能突出显示图像中包含汽车和消防栓的区域。
这些自我注意层的输出然后输入到交叉注意层,这是视觉和文本信息结合的地方。
文本特征关注图像的相关部分(Vl、Kl、Ql箭头指向下方)。对于我们的例子,这可能会将汽车和消防栓这两个词与图像中的视觉表示联系起来。
图像特征与文本的相关部分相关(Vv、Kv、Qv箭头指向上方)。这可能涉及将汽车的视觉特征与问题中的单词颜色相关联。
最后,两个流都经过前馈层,进一步处理这些组合信息。
此过程重复Mco次,允许进行多轮细化。
这种架构允许模首先分别处理文本和图像,然后逐渐组合信息,使其能够理解视觉和文本内容之间的复杂关系。举个例子,在街景识别中,模型会显根据其靠近消防栓的位置识别正确的汽车,然后确定其颜色,并形成一个答案,例如:停在消防栓旁边的汽车是蓝色的。
4. 视频表示(Video CoSwin):该适配器扩展了Florence处理视频数据的能力,使动作识别等任务成为可能。它建立在图像处理能力上,以理解随时间变化的图像序列。
这种统一的结构使Florence只需一个基础模型和特定任务的适配器,就能处理图像分类、视频识别等一系列任务。
03.
Florence 的能力:“多才多艺”的视觉AI
Florence 的适应性在执行以下任务的能力中显而易见。
零样本图像分类
Florence 在12个数据集中展现了强大的零样本分类能力,在大多数情况下优于CLIP和FLIP等模型。它在细粒度任务上表现尤为出色,如在Standford Cars上获得93.2%的分数,在Oxford Pets上获得95.9%的分数,并以83.7%的准确率处理ImageNet等大规模数据集。这一表现表明,Florence 可以利用其对语言和视觉特征的理解,泛化识别未见类别。
线性探测分类
当在冻结特征之上使用线性分类器时,Florence 在大多数数据集上超过了 SimCLRv2、ViT 和 EfficientNet 等模型。这种在多样化和细粒度分类任务上的多功能性表明,Florence 学到的表示非常丰富且适用于新任务。
目标检测
Florence 的目标检测性能在多个数据集上进行了评估,在COCO上得分为62.4 mAP,在Object365上得分为39.3 mAP,在Visual Genome上得分为16.2 AP50。这些结果突出了它在复杂场景中分类、定位和识别多个对象的能力。
视觉问答(VQA)
Florence 在 VQAv2 数据集上取得了80.36%的准确率,显示了其整合视觉和文本信息的能力。
图文检索
Florence 在跨模态检索方面表现出色,Flickr30K数据集的结果显示图像到文本的R@1为97.2%,文本到图像的R@1为87.9%,MSCOCO数据集的图像到文本的R@1为81.8%,文本到图像的R@1为63.2%。这种对齐视觉和文本表示的能力支持强大的跨模态搜索功能。
视频动作识别
虽然是在静态图像上训练的,但 Florence 能够很好地适应视频任务,在Kinetics-400上取得了86.5%的top-1准确率,在Kinetics-600上的top-1准确率为87.8%。这表明,Florence 可以捕捉视频中的时间信息并识别动作,处理动作和序列,而无需对视频数据进行特定的训练。
有关更多评估和实验结果,请查看Florence的论文(https://arxiv.org/abs/2111.11432)。
04.
Florence和向量数据库如何增强多模态搜索
Florence 在图像-文本检索和零样本分类方面的能力,与向量数据库的优势可以互相结合,来最大化它们的潜力,创建强大的多媒体搜索和分析系统。
4.1 了解向量数据库
向量数据库是专门用于存储、索引和查询高维向量的系统,这些向量表示图像、文本或音频等复杂数据。这些向量通常由Florence等模型生成,允许在庞大的数据集中进行高效的相似性搜索。这种能力使得向量数据库非常适合应用于基于语义或内容相似性的快速准确的数据匹配。
4.2 Milvus:为规模而建的开源向量数据库
Milvus是GitHub上拥有超过30,000颗星的开源向量数据库,特别适合构建AI驱动的应用。它具有可扩展性、强大的性能和灵活的索引,非常适合管理像Florence这样的模型生成的大型复杂数据集。它提供广泛的功能,例如:
混合和多模态搜索:Milvus支持混合稀疏和密集搜索,将向量相似性搜索与标量过滤器相结合,并允许多模态搜索。
可扩展性:Milvus可以水平扩展,管理数十亿个向量,确保其与Florence处理庞大数据集的能力保持同步。
多种索引类型:Milvus拥有15种索引类型,为用户提供了优化查询速度、准确性或内存的灵活性,适合一系列应用需求。
GPU加速:Milvus利用GPU加速索引和搜索,这与Florence基于GPU的推理非常一致,并最大限度地提高了端到端系统效率。
实时更新:Milvus支持实时数据插入和更新,允许基于Florence的系统能够无缝整合新数据,而不会出现重大中断。
Florence 和 Milvus 的组合有许多应用,包括:
多模态RAG:传统的RAG系统专注于检索文本,以增强LLM的生成过程,产生更准确、更个性化的响应。多模态RAG通过使用Florence和Milvus等多模态AI模型,将图像、音频、视频等其他数据类型集成到嵌入、检索和生成过程中。
大规模视觉搜索引擎:用户可以根据详细的文本描述查找图像,或上传图像以在海量数据集中查找类似的图像。
内容推荐系统:通过存储各种内容项(图像、视频、文章)的Florence嵌入,Milvus可以根据用户偏好和行为提供个性化推荐。
自动标记和分类:Florence的零样本能力与Milvus的快速检索相结合,可以通过在数据库中找到类似的、已经标记的项目,来实现新图像的自动标记。
大规模视觉问答:在Milvus中存储image-question-answer三元组的嵌入,能快速检索有关图像的新问题的相关信息。
随着技术的发展,我们期望看到更先进的视觉AI系统,可以增强人机交互,简化AI驱动的助手。这些发展还可能导致各行各业更好的自动化,并引入新的创意和内容生产工具。
更多资源
Paper: Florence: A New Foundation Model for Computer Vision(https://arxiv.org/pdf/2111.11432)
Paper: Dynamic Head: Unifying Object Detection Heads with Attentions(https://arxiv.org/abs/2106.08322)
Paper: What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models(https://arxiv.org/abs/2405.15668)
Blog: Using Vector Search to Better Understand Computer Vision Data(https://zilliz.com/blog/use-vector-search-to-better-understand-computer-vision-data)
Demo: Similarity Search Demos Powered by Milvus(https://milvus.io/milvus-demos)
本文作者:Denis Kuria
推荐阅读



相关文章:
Milvus×Florence:一文读懂如何构建多任务视觉模型
近两年来多任务学习(Multi-task learning)正取代传统的单任务学习(single-task learning),逐渐成为人工智能领域的主流研究方向。其原因在于,多任务学习可以让我们以最少的人力投入,获得尽可能多…...

DAPP
02-DAPP 1 啥是 DApp? DApp,部署在链上的去中心化的应用。 DApp 是开放源代码,能运行在分布式网络上,通过网络中不同对等节点相互通信进行去中心化操作的应用。 DAPP 开放源代码,才能获得人的信任。如比特币ÿ…...

生产环境中,nginx 最多可以代理多少台服务器,这个应该考虑哪些参数 ?怎么计算呢
生产环境中,nginx 最多可以代理多少台服务器,这个应该考虑哪些参数 ?怎么计算呢 关键参数计算方法评估步骤总结 在生产环境中,Nginx最多可以代理的服务器数量并没有一个固定的限制,它取决于多个因素,包括Ng…...

【深度学习|目标跟踪】StrongSORT 详解(以及StrongSORT++)
StrongSort详解 1、论文及源码2、DeepSORT回顾3、StrongSORT的EMA4、StrongSORT的NSA Kalman5、StrongSORT的MC6、StrongSORT的BOT特征提取器7、StrongSORT的AFLink8、StrongSORT的GSI模块 1、论文及源码 论文地址:https://arxiv.org/pdf/2202.13514 源码地址&#…...

23种设计模式-原型(Prototype)设计模式
文章目录 一.什么是原型设计模式?二.原型模式的特点三.原型模式的结构四.原型模式的优缺点五.原型模式的 C 实现六.原型模式的 Java 实现七. 代码解析八.总结 类图: 原型设计模式类图 一.什么是原型设计模式? 原型模式(Prototype…...

Qt—QLineEdit 使用总结
文章参考:Qt—QLineEdit 使用总结 一、简述 QLineEdit是一个单行文本编辑控件。 使用者可以通过很多函数,输入和编辑单行文本,比如撤销、恢复、剪切、粘贴以及拖放等。 通过改变 QLineEdit 的 echoMode() ,可以设置其属性,比如以密码的形式输入。 文本的长度可以由 m…...

go-zero使用自定义模板实现统一格式的 body 响应
前提 go环境的配置、goctl的安装、go-zero的基本使用默认都会 需求 go-zero框架中,默认使用goctl命令生成的代码并没有统一响应格式,现在使用自定义模板实现统一响应格式: {"code": 0,"msg": "OK","d…...

BUGKU printf
整体思路 实现循环-->获取libc版本和system函数地址->将strcpy的got表项修改为system并获得shell 第一步:实现循环 从汇编语句可以看出,在每次循环结束时若0x201700处的值是否大于1则会继续循环。 encode1会将编码后的结果保存至0x2015c0处&am…...

深度学习:梯度下降法
损失函数 L:衡量单一训练样例的效果。 成本函数 J:用于衡量 w 和 b 的效果。 如何使用梯度下降法来训练或学习训练集上的参数w和b ? 成本函数J是参数w和b的函数,它被定义为平均值; 损失函数L可以衡量你的算法效果&a…...

`console.log`调试完全指南
大家好,这里是 Geek技术前线。 今天我们来探讨 Console.log() 的一些优点。并分析一些基本概念和实践,这些可以让我们的调试工作变得更加高效。 理解前端 log 与后端 log 的区别 前端 log 与后端 log 有着显著的不同,理解这一点至关重要。…...

ROS VSCode调试方法
VSCode 调试 Ros文档 1.编译参数设置 cd catkin_ws catkin_make -DCMAKE_BUILD_TYPEDebug2.vscode 调试插件安装 可在扩展中安装(Ctrl Shift X): 1.ROS 2.C/C 3.C Intelliense 4.Msg Language Support 5.Txt Syntax 3.导入已有或者新建ROS工作空间 3.1 导入工作…...

16 —— Webpack多页面打包
需求:把 黑马头条登陆页面-内容页面 一起引入打包使用 步骤: 准备源码(html、css、js)放入相应位置,并改用模块化语法导出 原始content.html代码 <!DOCTYPE html> <html lang"en"><head&…...

微服务即时通讯系统的实现(服务端)----(3)
目录 1. 消息存储子服务的实现1.1 功能设计1.2 模块划分1.3 模块功能示意图1.4 数据管理1.4.1 数据库消息管理1.4.2 ES文本消息管理 1.5 接口的实现1.5.1 消息存储子服务所用到的protobuf接口实现1.5.2 最近N条消息获取接口实现1.5.3 指定时间段消息搜索接口实现1.5.4 关键字消…...
)
.net6.0 mvc 传递 model 实体参数(无法对 null 引用执行运行时绑定)
说一下情况: 代码没问题,能成功从数据库里查到数据,能将数据丢给ViewBag.XXXX, 在View页面也能获取到 ViewBag.XXXX的值,但是发布到线上后报这个错: Microsoft.CSharp.RuntimeBinder.RuntimeBinderException: 无法对 …...

VUE 入门级教程:开启 Vue.js 编程之旅
一、Vue.js 简介 Vue.js 是一套构建用户界面的渐进式 JavaScript 框架。它专注于视图层的开发,能够轻松地与其他库或现有项目进行整合。Vue.js 的核心库只关注视图层,通过简洁的 API 实现数据绑定和 DOM 操作的响应式更新,让开发者可以高效地…...

Ubantu系统docker运行成功拉取失败【成功解决】
解决docker运行成功拉取失败 失败报错 skysky-Legion-Y7000-IRX9:~$ docker run hello-world docker: permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Head “http://%2Fvar%2Frun%2Fdocker.sock/_ping”: dial uni…...

mvn-mac操作小记
1.安装brew 如果报错,Warning: /opt/homebrew/bin is not in your PATH. vim ~/.zshrc,最后一行追加 export PATH“/opt/homebrew/bin:$PATH” source ~/.zshrc 2.安装brew install maven mvn -version查看路径 Maven home: /opt/homebrew/Cellar/mav…...

机器学习——生成对抗网络(GANs):原理、进展与应用前景分析
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一. 生成对抗网络的基本原理二. 使用步骤2.1 对抗性训练2.2 损失函数 三. GAN的变种和进展四. 生成对抗网络的应用五. 持续挑战与未来发展方向六. 小结 前言 生…...

「Mac畅玩鸿蒙与硬件33」UI互动应用篇10 - 数字猜谜游戏
本篇将带你实现一个简单的数字猜谜游戏。用户输入一个数字,应用会判断是否接近目标数字,并提供提示“高一点”或“低一点”,直到用户猜中目标数字。这个小游戏结合状态管理和用户交互,是一个入门级的互动应用示例。 关键词 UI互…...

Ps:存储 Adobe PDF
在 Adobe Photoshop 中,将图像保存为 PDF 文件时, 会弹出“存储 Adobe PDF” Save Adobe PDF对话框。在此对话框中提供了多个选项,用于控制 PDF 文件的输出,包括一般设置(选择预设、兼容性和保留编辑功能)、…...

忆阻器神经形态计算与模块化建模技术解析
1. 忆阻器与神经形态计算基础忆阻器(Memristor)作为继电阻、电容、电感之后的第四种基本电路元件,其核心特性在于阻值会"记忆"过往通过的电荷量。这种记忆特性源于器件内部的可逆物理变化,例如离子迁移、氧空位形成或聚…...

CANN/ge ACL内存加载模型API
aclmdlLoadFromMemWithQ 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率,减少模型内存占用。 GE 提供对 PyTorch、Te…...

Starknet智能体经济基础设施:构建自主安全的链上AI代理
1. 项目概述:构建自主、安全的 Starknet 智能体经济基础设施如果你正在探索如何让 AI 智能体(Agent)在区块链上真正“活”起来,而不仅仅是作为一个调用 API 的脚本,那么starknet-agentic这个项目就是你一直在找的答案。…...

Python开发者必备:Awesome清单高效选型与实战指南
1. 项目概述:一份Python开发者的“藏宝图”如果你是一名Python开发者,无论是刚入门的新手,还是摸爬滚打多年的老手,我相信你都曾有过这样的时刻:面对一个具体的开发需求,比如想找一个好用的Web框架、一个高…...

作业4:独立按键+数码管实操
文章目录 1.测试代码视频2.流水灯视频3.独立按键视频(点亮四个灯)4.独立按键视频(思考题点亮8个灯)5.数码管显示“111111”6.数码管显示“123456”7.数码管显示“11.12.13”8.数码管显示“HH8800.” 1.测试代码视频 测试2.流水灯视频 流水灯#include <reg51.h> // 包含…...

Anthropic研究院议程:不止做AI大模型,更要定义AI时代的全球规则
当大模型竞赛进入白热化,多数科技公司都在比拼参数、速度、模型能力时,OpenAI竞品Anthropic走出了一条完全不同的路。 近期,Anthropic 正式公布 Anthropic Institute(Anthropic研究院)全新研究议程,不再只埋头做模型研发,而是站在行业顶层视角,深度拆解AI对经济、安全、…...

Scroll Reverser终极指南:5分钟解决macOS多设备滚动方向混乱问题
Scroll Reverser终极指南:5分钟解决macOS多设备滚动方向混乱问题 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否经常在MacBook触控板和鼠标之间切换ÿ…...

N_m3u8DL-RE终极实战指南:三步破解流媒体下载技术难题
N_m3u8DL-RE终极实战指南:三步破解流媒体下载技术难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

终极指南:用Python实现微信自动化,告别重复操作!
终极指南:用Python实现微信自动化,告别重复操作! 【免费下载链接】wxauto Windows版本微信客户端(非网页版)自动化,可实现简单的发送、接收微信消息,简单微信机器人 项目地址: https://gitcod…...

QMCDecode:如何在3分钟内破解QQ音乐加密格式限制?
QMCDecode:如何在3分钟内破解QQ音乐加密格式限制? 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录࿰…...