Ubuntu24.04配置DINO-Tracker
一、引言
记录 Ubuntu 配置的第一个代码过程
二、更改conda虚拟环境的默认安装路径
鉴于不久前由于磁盘空间不足引发的重装系统的惨痛经历,在新系统装好后当然要先更改虚拟环境的默认安装路径。
输入指令:
conda info

可能因为我原本就没有把 Anacoda 安装在 home 文件夹下,所以我的默认安装路径都不是根目录?但是我还是想把下面那个根目录去掉。
打开根目录,点击左上角的三个横线标识,勾选“显示隐藏的文件”,打开 .condarc 文件。在文件末尾添加如下内容:
envs_dirs:- ...\envs
pkgs_dirs:- ...\pkgs
重新在命令行输入指令查看路径:

这里发现 pkgs 的路径更改成功了,但是 envs 的路径没有更改成功。我查看了两个文件夹的权限都是一样的。所以为什么有一个没改成功呢?
设置 envs 文件夹权限:

设置完还是没有变化。查看 base 环境的位置,发现也是我安装 anaconda 的位置,并不是根目录,所以这里我没有再更改了。
三、配置环境
1. 新建环境
按照 readme.md 中的要求:
conda create -n dino-tracker python=3.9
conda activate dino-tracker
(安装完成后发现路径没有问题)
在安装 requirements 文件中的包之前,我先安装了 CUDA+cudnn。
2. 安装 CUDA + CUDNN + torch
1)查看 CUDA 与 cudnn 的版本
在终端输入:
nvidia-smi

可以看到我能安装的最高版本为12.4。
打开 pytorch官网查看 cuda 对应版本。本项目所需的 torch 版本为 2.1.0:

可以选择的版本有11.8和12.1。这里我选择安装12.1。
2) 下载安装包
下载地址: https://developer.nvidia.com/cuda-toolkit
历史版本下载地址: https://developer.nvidia.com/cuda-toolkit-archive


这里说明一下,cuda11.8 和 cuda12.1 都没有对应的 ubuntu24.04 版本,所以我选择了 22.04 版本。
3)安装 CUDA
(1) 方法1(失败)
按照官网给出的命令依次执行。




由于我是 ubuntu24.04 版本,而我选择安装的是 cuda 对应的是 22.04 版本,这里需要安装一下 libtinfo5。
参考这位大佬和这位大佬的帖子,我需要执行下面这个命令安装 libtinfo5:
wget http://archive.ubuntu.com/ubuntu/pool/universe/n/ncurses/libtinfo5_6.4-2_amd64.deb
dpkg -i libtinfo5_6.4-2_amd64.deb

我打开这个网页:http://archive.ubuntu.com/ubuntu/pool/universe/n/ncurses

发现根本没有 libtinfo5_6.4-2 这个版本。。。。。。然后我选择安装了 libtinfo5_6.3-2 这个版本,重新执行安装 cuda 的命令。这次没有出现 libtinfo5 这个错误,但是在安装过程中也没有弹出选择是否安装驱动的选项,而是直接执行到最后一步,然后出问题了:


然后我再次输入nvidia-smi:

果然驱动出问题了。看到一些帖子的分享,说这个问题可能重启之后就会解决,于是我抱着试试的心态重启了一下,显然我不是那个幸运儿:

只好卸载驱动重新安装。
参考链接
移除所有关于 cuda 的内容:
sudo apt-get --purge -y remove 'cuda*'
# cuda10.1及以上的卸载
cd /usr/local/cuda-xx.x/bin/
sudo ./cuda-uninstaller
sudo rm -rf /usr/local/cuda-xx.x
这里我的 cuda 应该是压根就没安装成功,因为 /usr/local/cuda-12.1 文件夹下面根本没有 bin 文件夹。
移除所有关于 nvidia 的内容:
sudo apt-get --purge -y remove 'nvidia*'
查看cuda文件夹
ls /usr/local/ | grep cuda
此时再次在终端输入 nvidia-smi,显示如下:
找不到命令 “nvidia-smi”,但可以通过以下软件包安装它:
sudo apt install nvidia-utils-470 # version 470.256.02-0ubuntu0.24.04.1, or
sudo apt install nvidia-utils-470-server # version 470.256.02-0ubuntu0.24.04.1
sudo apt install nvidia-utils-535 # version 535.183.01-0ubuntu0.24.04.1
sudo apt install nvidia-utils-535-server # version 535.216.01-0ubuntu0.24.04.1
sudo apt install nvidia-utils-550 # version 550.120-0ubuntu0.24.04.1
sudo apt install nvidia-utils-525 # version 525.147.05-0ubuntu1
sudo apt install nvidia-utils-525-server # version 525.147.05-0ubuntu1
sudo apt install nvidia-utils-550-server # version 550.127.05-0ubuntu0.24.04.1
应该是卸载成功了。按照提示输入sudo apt install nvidia-utils-550,安装失败。
还好不是第一次安装 nvidia 驱动。详细过程不再赘述了,按照之前的笔记安装。
安装过程中我第一次安装的是 550.107 版本,但是不知道为什么nvidia-smi出来显示的是 550.120 版本。这次重装我选择的是最新的版本 550.135,但是安装完成后一直黑屏开不了机,不得已又卸载了重新安装的 550.120 版本,然后非常顺利,安装过程没有任何问题。
(2) 方法2(成功)

依次执行上面两条命令。


按下空格取消安装驱动。中途出现了这个问题:

搜索之后发现只需在命令后面加一个--override

添加环境变量:
export PATH=$PATH:/usr/local/cuda-12.1/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.1/lib64
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.1
source ~/ .bashrc

输入nvcc -V查看是否安装成功:

4) 安装 CUDNN
- 选择版本
在官网选择合适的版本安装。

为了选择与 ubuntu24.04 匹配的版本,我选择了9.3.0。

- 安装
依次执行上述命令:
wget https://developer.download.nvidia.com/compute/cudnn/9.3.0/local_installers/cudnn-local-repo-ubuntu2404-9.3.0_1.0-1_amd64.debsudo
dpkg -i cudnn-local-repo-ubuntu2404-9.3.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2404-9.3.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn-cuda-12
- 执行文件复制
sudo cp usr/include/cudnn* /usr/local/cuda-12.1/include
- 测试是否安装 cudnn 成功
cat /usr/local/cuda-12.1/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

- 查看版本信息
dpkg -l |grep cudnn
查看版本信息

5) 安装 torch
- 打开官网
- 选择合适的版本

输入指令:
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
检测是否安装成功:
pythonimport torch
print(torch.version.cuda)
print(torch.backends.cudnn.version())


输入命令:
conda install numpy==1.26
重新检测:

成功。
6) 安装其他包
pip install -r requirements.txt
查看是否安装成功:
conda list
这里我都安装成功了。
7) 配置环境变量
cd dino-tracker
export PYTHONPATH=`pwd`:$PYTHONPATH
8) 添加解释器
选择配置 Python 解释器,conda 路径为安装路径下的 anaconda3/bin/conda.bat,然后就可以找到自己创建的虚拟环境。

四、运行
1. 修改路径
preprocessing/main_preprocesseng.py
在 main 函数中添加 config 和 data-path 的路径。这里我直接下载的代码中原本写的是 configs,而实际代码中的文件夹名称为 config。
dat-path 直接改成项目中自带的 horsejump 即可。
2. 修改项目路径
我最开始只能在终端中输入python ./preprocessing/main_preprocessing.py时可以运行,直接点项目上方的绿色三角会报错误找不到./preprocessing/main_preprocessing.py 。此时需要修改工作目录。
点击绿色三角旁边的三个点->编辑->工作目录


现在的工作目录为dino-tracker-main/preprocessing,改为dino-tracker即可。
3. 下载预训练模型
运行代码时需要离线下载预训练模型,这里我提前下载一下。
下载地址:https://github.com/facebookresearch/dinov2?tab=readme-ov-file
相关文章:
Ubuntu24.04配置DINO-Tracker
一、引言 记录 Ubuntu 配置的第一个代码过程 二、更改conda虚拟环境的默认安装路径 鉴于不久前由于磁盘空间不足引发的重装系统的惨痛经历,在新系统装好后当然要先更改虚拟环境的默认安装路径。 输入指令: conda info可能因为我原本就没有把 Anacod…...

抓包之查看websocket内容
写在前面 本文看下websocket抓包相关内容。 1:正文 websocket基础环境搭建参考这篇文章。 启动后,先看chrome的network抓包,这里我们直接使用is:running来过滤出websocket的请求: 可以清晰的看到发送的内容以及响应的内容。在…...

【Leetcode Top 100】21. 合并两个有序链表
问题背景 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 数据约束 两个链表的节点数目范围是 [ 0 , 50 ] [0, 50] [0,50] − 100 ≤ N o d e . v a l ≤ 100 -100 \le Node.val \le 100 −100≤Node.val≤100 l 1 l_1 …...

账本模型
05-账本模型 1 账本模型 1.1 传统线性增长模型 传统的 MySQL 等系统采用线性增长的日志模型,通过一个 Leader 和多个 Follower 进行状态同步。这种方式有单点的带宽瓶颈问题。 1.2 区块链共享账本模型 共享账本:树形增长。在去中心化网络中,…...

openwrt利用nftables在校园网环境下开启nat6 (ipv6 nat)
年初写过一篇openwrt在校园网环境下开启ipv6 nat的文章,利用ip6tables控制ipv6的流量。然而从OpenWrt22版本开始,系统内置的防火墙变为nftables,因此配置方法有所改变。本文主要参考了OpenWRT使用nftables实现IPv6 NAT 这篇文章。 友情提示 …...

24.12.02 Element
import { createApp } from vue // 引入elementPlus js库 css库 import ElementPlus from element-plus import element-plus/dist/index.css //中文语言包 import zhCn from element-plus/es/locale/lang/zh-cn //图标库 import * as ElementPlusIconsVue from element-plus/i…...
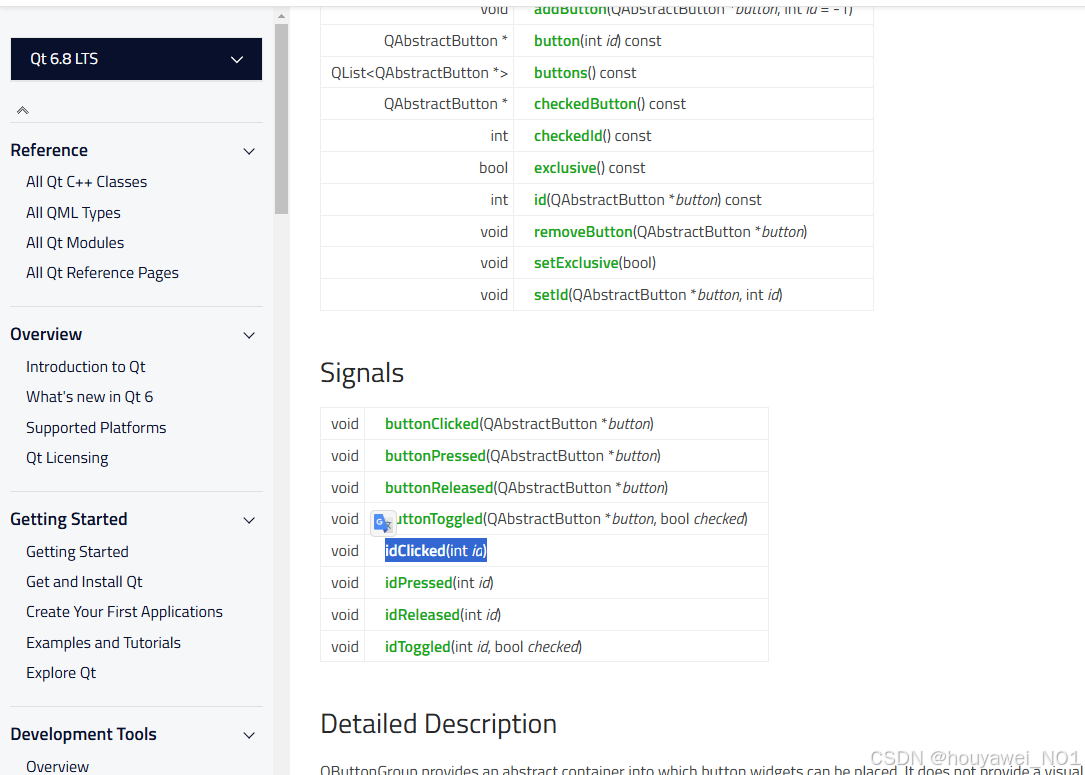
记录QT5迁移到QT6.8上的一些问题
经常看到有的同学说网上的教程都是假的,巴拉巴拉,看看人家发布时间,Qt官方的API都会有所变动,多搜索,多总结,再修改记录。 下次遇到问题多这样搜索 QT 4/5/6 xxx document,对比一下就知道…...

清理Linux/CentOS7根目录的思路
在使用Linux服务器过程中,经常会遇到磁盘空间不足的问题,好多应用默认安装在根目录下,记录一下如何找到问题所在,清理根目录(/) 1. 检查空间使用情况 1.1 查看分区占用: df -h输出࿱…...
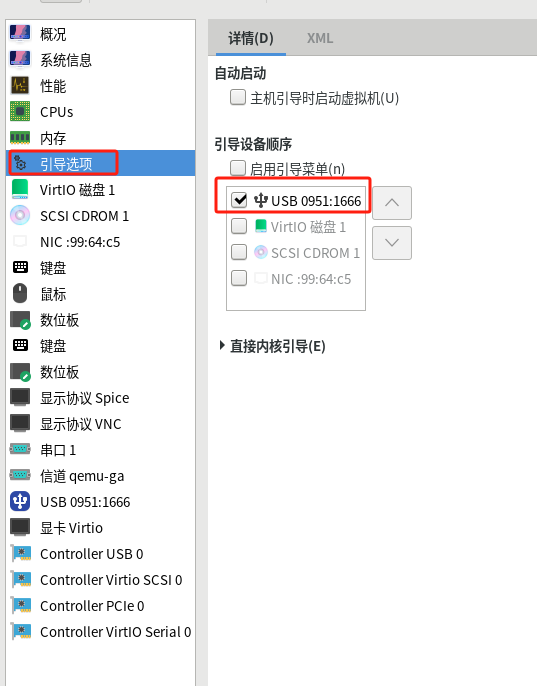
【LInux】kvm添加u盘启动引导
前提:要有一个u盘的启动盘 1、查看u盘设备信息 # lsusb ....忽略其他设备信息,查看到u盘设备 Bus 005 Device 005: ID 0951:1666 Kingston Technology DataTraveler 100 G3/G4/SE9 G2## 主要记住ID 0951:1666确认id为ID 0951:1666 2、修改配置文件 如…...
.net XSSFWorkbook 读取/写入 指定单元格的内容
方法如下: using NPOI.SS.Formula.Functions;using NPOI.SS.UserModel;using OfficeOpenXml.FormulaParsing.Excel.Functions.DateTime;using OfficeOpenXml.FormulaParsing.Excel.Functions.Numeric;/// <summary>/// 读取Excel指定单元格内容/// </summa…...

GaussDB(类似PostgreSQL)常用命令和注意事项
文章目录 前言GaussDB(类似PostgreSQL)常用命令和注意事项1. 连接到GaussDB数据库2. 查看当前数据库中的所有Schema3. 进入指定的Schema4. 查看Schema下的表、序列、视图5. 查看Schema下所有的表6. 查看表结构7. 开始事务8. 查询表字段注释9. 注意事项&a…...

【HM-React】02. React基础-下
React表单控制 受控绑定 概念:使用React组件的状态(useState)控制表单的状态 function App(){const [value, setValue] useState()return (<input type"text" value{value} onChange{e > setValue(e.target.value)}/>) …...
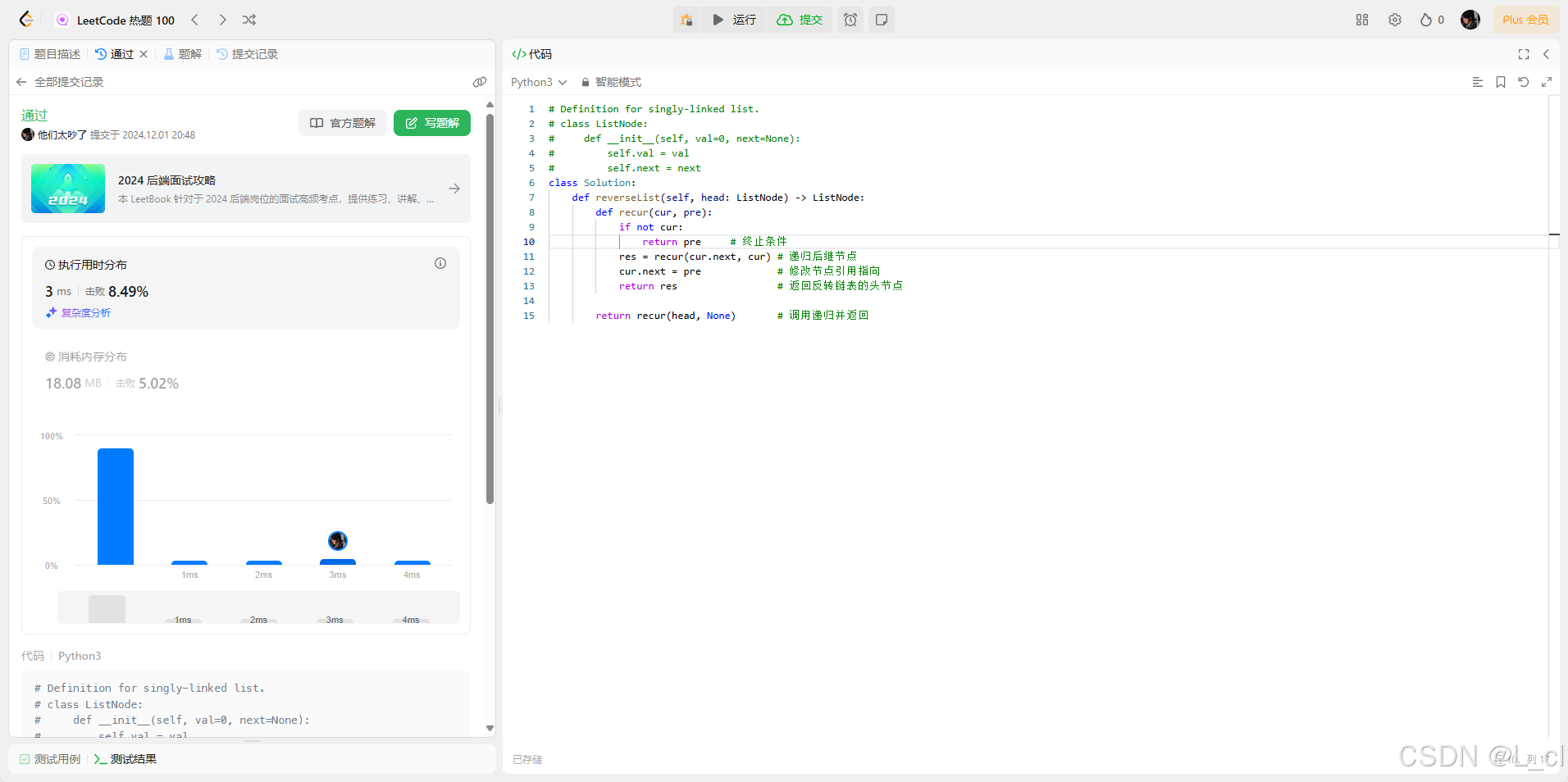
【力扣热题100】—— Day3.反转链表
你不会永远顺遂,更不会一直年轻,你太安静了,是时候出发了 —— 24.12.2 206. 反转链表 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入:head [1,2,3,4,5] 输出&…...
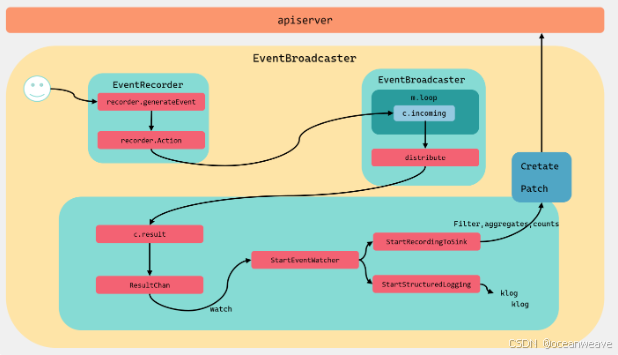
【k8s深入学习之 event 记录】初步了解 k8s event 记录机制
event 事件记录初始化 一般在控制器都会有如下的初始化函数,初始化 event 记录器等参数 1. 创建 EventBroadcaster record.NewBroadcaster(): 创建事件广播器,用于记录和分发事件。StartLogging(klog.Infof): 将事件以日志的形式输出。StartRecording…...

redhat 7.9配置阿里云yum源
1、mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/backup/ 2、添加dns vim/etc/resolv.conf nameserver 8.8.8.8 nameserver 8.8.4.4 nameserver 114.114.114.114 #配置完先检查下通不通 3、vi /etc/yum/pluginconf.d/subscription-manager.conf # 将 “enabled1” 改为 “ena…...

深入探索Flax:一个用于构建神经网络的灵活和高效库
深入探索Flax:一个用于构建神经网络的灵活和高效库 在深度学习领域,TensorFlow 和 PyTorch 作为主流的框架,已被广泛使用。不过,Flax 作为一个较新的库,近年来得到了越来越多的关注。Flax 是一个由Google Research团队…...
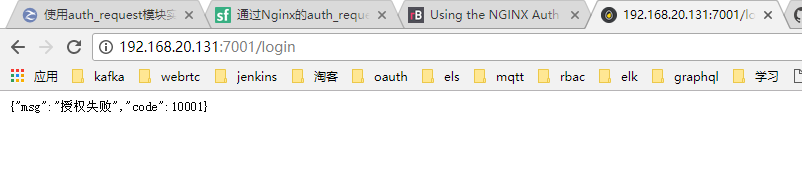
Nginx auth_request详解
网上看到多篇先关文章,觉得很不错,这里合并记录一下,仅供学习参考。 模块 nginx-auth-request-module 该模块是nginx一个安装模块,使用配置都比较简单,只要作用是实现权限控制拦截作用。默认高版本nginx(比…...

基于Java Springboot个人财务APP且微信小程序
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 微信…...
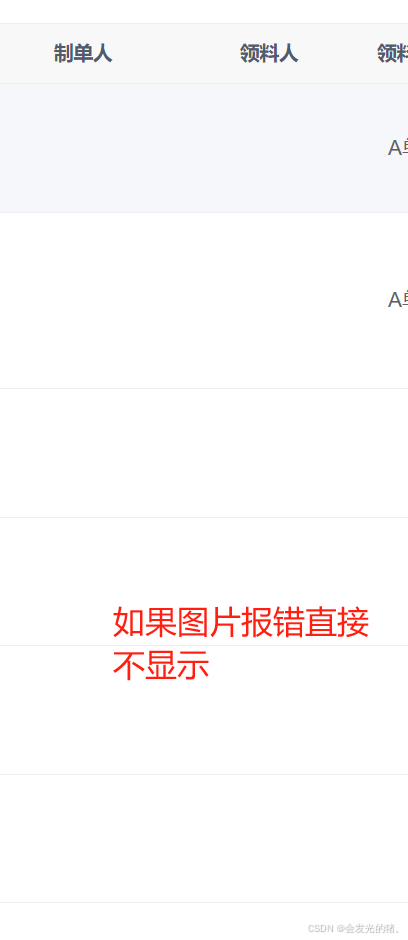
vue3图片报错转换为空白不显示的方法
vue3图片报错转换为空白不显示的方法 直接上代码: <el-table-column label"领料人" align"center"><template #default"scope"><el-imagev-if"scope.row.receiver":src"scope.row.receiver"style…...
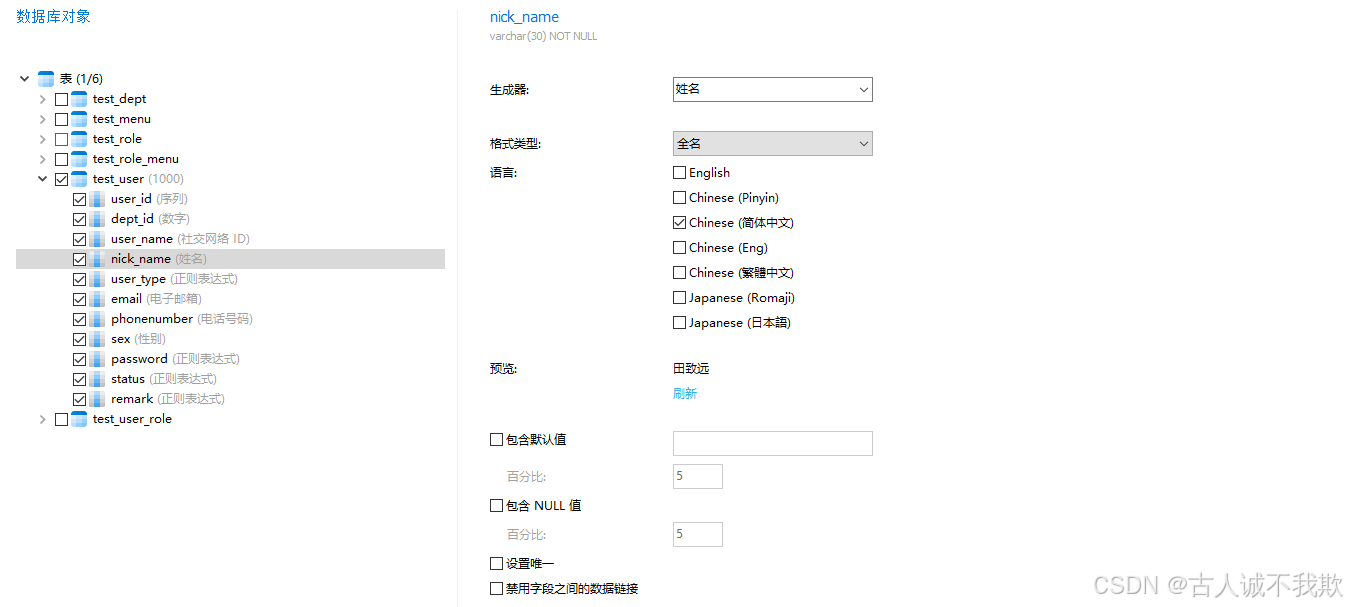
mysq之快速批量的插入生成数据
mysq之快速批量的插入生成数据 1.insert inot select2.存储过程3.借助工具 在日常测试工作时,有时候需要某张表有大量的数据,如:需要有几百个系统中的用户账号等情况;因此,记录整理,如何快速的在表中插入生…...

终极暗黑破坏神2存档编辑器:轻松修改单机角色的完整指南
终极暗黑破坏神2存档编辑器:轻松修改单机角色的完整指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2单机存档的管理而烦恼吗?d2s-editor是一款功能强大的暗黑破坏神2存档编辑器&…...

2026年5款AI声音克隆工具对比实测,短音频素材如何免训练生成口播声?
短视频团队卡在声音克隆这一步很多做矩阵账号的运营同学反馈:手头只有主播15秒的口播片段,想批量生成不同脚本的配音口播,但主流工具要么要求3分钟以上音频、要么克隆后口型错位、要么导出后还得手动配到视频里——整个链路断在‘声’上。更棘…...

工业无网智能诊断:可执行二维码与QRind语言深度解析
1. 项目概述:当二维码“活”起来,工业现场的无网智能诊断在工业现场,尤其是那些网络信号不稳定甚至完全隔绝的区域——比如大型石化厂的深处、地下矿井的作业面,或是某些对网络安全有严格管控的精密制造车间,我们常常面…...

Real-ESRGAN-GUI终极指南:免费AI图像增强工具,让模糊图片秒变高清
Real-ESRGAN-GUI终极指南:免费AI图像增强工具,让模糊图片秒变高清 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾经遇到过这样的情况&am…...

2026年湖南竟有10家高性价比智能家居服务商?是哪些呢?
引言随着智能家居行业的蓬勃发展,湖南地区的智能家居市场也日益繁荣。据预测,到2026年湖南将有10家高性价比的智能家居服务商崭露头角。今天我们就来深入了解一下,看看其中备受瞩目的华为鸿蒙智家株洲红星店以及其他一些可能上榜的服务商。华…...

终极指南:如何用novel-downloader轻松保存网络小说到本地
终极指南:如何用novel-downloader轻松保存网络小说到本地 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 你是否曾经遇到过心爱的小说突然从网站上消失的窘境?…...

Windows与Office智能激活终极指南:KMS_VL_ALL_AIO完整解决方案
Windows与Office智能激活终极指南:KMS_VL_ALL_AIO完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 在数字化工作环境中,稳定可靠的操作系统和办公软件是高效工…...

Nmap零基础实战:从安装配置到渗透测试全流程解析
1. 别再被“零基础”三个字骗了:Nmap不是点开就用的玩具,而是你第一把真正能切开网络的手术刀很多人点开“渗透测试零基础入门”这类标题,心里想的是:“装个软件,敲几行命令,扫出一堆IP和端口,就…...

创新方案:DouZero_For_HappyDouDiZhu - AI智能斗地主实战指南
创新方案:DouZero_For_HappyDouDiZhu - AI智能斗地主实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 你是否曾想过在斗地主游戏中拥有一个永…...

跨平台资源下载终极指南:轻松获取视频号、抖音、直播流等全网资源
跨平台资源下载终极指南:轻松获取视频号、抖音、直播流等全网资源 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...