【超详图文】多少样本量用 t分布 OR 正态分布
文章目录
- 相关教程
- 相关文献
- 预备知识
- Lindeberg-Lévy中心极限定理
- t分布的来历
- 实验
- 不同分布不同抽样次数的总体分布
- 不同自由度相同参数的t分布&正态分布
作者:小猪快跑
基础数学&计算数学,从事优化领域7年+,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法
选择使用t分布还是正态分布通常取决于样本量的大小以及是否知道总体的标准差。
-
正态分布:
- 当样本量较大(通常n > 30)时,根据中心极限定理,无论原始总体分布是什么形状,样本均值的分布将接近正态分布。
- 如果总体标准差已知,并且你对总体均值进行推断,也可以使用正态分布,即使样本量较小。
-
t分布:
- 当样本量较小(n ≤ 30),并且总体标准差未知时,应该使用t分布。t分布与正态分布相似,但具有更宽的尾部,以反映小样本时更大的不确定性。
- t分布依赖于自由度的概念,自由度等于样本量减一(df = n - 1)。随着样本量增加,t分布逐渐逼近正态分布。
总结来说,如果你有一个小样本,并且不知道总体标准差,那么你应该使用t分布来进行统计推断。如果你有一个大样本,或者你知道总体标准差,那么你可以使用正态分布。在实际应用中,如果样本量足够大,两种分布之间的差异变得很小,这时可以认为两者是等价的。
如有错误,欢迎指正。如有更好的算法,也欢迎交流!!!——@小猪快跑
相关教程
- 常用分布的数学期望、方差、特征函数
- 【推导过程】常用离散分布的数学期望、方差、特征函数
- 【推导过程】常用连续分布的数学期望、方差、特征函数
- Z分位数速查表
- 【概率统计通俗版】极大似然估计
- 【超详图文】多少样本量用 t分布 OR 正态分布
- 【机器学习】【通俗版】EM算法(待更新)
相关文献
- [1] 茆诗松,周纪芗.概率论与数理统计 (第二版)[M].中国统计出版社,2000.
- [2] Bessel’s correction - Wikipedia
- [3] The t-distribution: a key statistical concept discovered by a beer brewery
- [4] Student’s t distribution | A Blog on Probability and Statistics
- [5] Student’s t distribution | Properties, proofs, exercises
预备知识
Lindeberg-Lévy中心极限定理
设 $ { X_n } $ 是独立同分布的随机变量序列, 且 $ E (X_n) = \mu $, $\mathrm{Var} (X_n)= \sigma^2 > 0 $.
记
Y n ∗ = X 1 + X 2 + ⋯ + X n − n μ σ n Y_n^* = \frac{X_1 + X_2 + \dotsb + X_n - n \mu}{\sigma \sqrt{n}} Yn∗=σnX1+X2+⋯+Xn−nμ
则对任意实数 $ y $, 有
lim n → + ∞ P ( Y n ∗ ≤ y ) = Φ ( y ) = 1 2 π ∫ − ∞ y e − t 2 / 2 d t . \lim_{n \to +\infty} P ( Y_n ^* \leq y ) = \Phi (y) = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^y \mathrm{e}^{-t^2/2} \mathrm{d} t. n→+∞limP(Yn∗≤y)=Φ(y)=2π1∫−∞ye−t2/2dt.
t分布的来历
设 $ { X_n } $ 是独立同分布的随机变量序列, 且 $ E (X_n) = \mu $, $\mathrm{Var} (X_n)= \sigma^2 > 0 $
根据中心极限定理,我们知道
x ˉ − μ σ / n ∼ N ( 0 , 1 ) \frac{\bar{x}-\mu}{\sigma/\sqrt{n}} \sim N(0,1) σ/nxˉ−μ∼N(0,1)
但如果我们只有一些样本数据,其实无法知道准确的均值和方差,这时候就需要估计均值和方差。
我们来看一个例子。
设 $ { X_n } $ 是独立同分布的随机变量序列,且 $ \mu = 2500 $。抽样结果: 2051 , 2053 , 2055 , 2050 , 2051 2051,2053,2055,2050,2051 2051,2053,2055,2050,2051。则样本均值: 2052 2052 2052。
假如我们知道真实均值 $ \mu = 2500 $,则方差估计:
1 5 [ ( 2051 − 2050 ) 2 + ( 2053 − 2050 ) 2 + ( 2055 − 2050 ) 2 + ( 2050 − 2050 ) 2 + ( 2051 − 2050 ) 2 ] = 7.2 \frac{1}{5}[(2051-2050)^{2}+(2053-2050)^{2}+(2055-2050)^{2}+(2050-2050)^{2}+(2051-2050)^{2}]=7.2 51[(2051−2050)2+(2053−2050)2+(2055−2050)2+(2050−2050)2+(2051−2050)2]=7.2
假如我们使用样本均值 $ \mu = 2502 $,则方差估计:
1 5 [ ( 2051 − 2052 ) 2 + ( 2053 − 2052 ) 2 + ( 2055 − 2052 ) 2 + ( 2050 − 2052 ) 2 + ( 2051 − 2052 ) 2 ] = 3.2 \frac15[(2051-2052)^2+(2053-2052)^2+(2055-2052)^2+(2050-2052)^2+(2051-2052)^2]=3.2 51[(2051−2052)2+(2053−2052)2+(2055−2052)2+(2050−2052)2+(2051−2052)2]=3.2
我们发现样本均值计算的方差 << 实际均值计算的方差,下面我们将通过一个简单的数学恒等式 ( a + b ) 2 = a 2 + 2 a b + b 2 (a+b)^2=a^2+2ab+b^2 (a+b)2=a2+2ab+b2 证明
( 2053 − 2050 ⏟ 样本值与总体均值的偏差 ) 2 = [ ( 2053 − 2052 ⏟ 样本值与样本均值的偏差 ) ⏞ This is a . + ( 2052 − 2050 ⏟ 样本均值与总体均值的偏差 ) ⏞ This is b . ] 2 = ( 2053 − 2052 ) 2 ⏞ This is a 2 . + 2 ( 2053 − 2052 ) ( 2052 − 2050 ) ⏞ This is 2 a b . + ( 2052 − 2050 ) 2 ⏞ This is b 2 . \begin{aligned} (\underbrace{ \begin{array} {c}2053-2050 \end{array}}_{\text{样本值与总体均值的偏差}})^2 & =[\overbrace{(\underbrace{ \begin{array} {c}2053-2052 \end{array}}_{\text{样本值与样本均值的偏差}})}^{\text{This is }a.}+ \overbrace{(\underbrace{ \begin{array} {c}2052-2050 \end{array}}_{\text{样本均值与总体均值的偏差}})}^{\text{This is }b.}]^2 \\ & =\overbrace{\left(2053-2052\right)^2}^{\text{This is }a^2.}+\overbrace{2(2053-2052)(2052-2050)}^{\text{This is }2ab.}+\overbrace{\left(2052-2050\right)^2}^{\text{This is }b^2.} \end{aligned} (样本值与总体均值的偏差 2053−2050)2=[(样本值与样本均值的偏差 2053−2052) This is a.+(样本均值与总体均值的偏差 2052−2050) This is b.]2=(2053−2052)2 This is a2.+2(2053−2052)(2052−2050) This is 2ab.+(2052−2050)2 This is b2.
运用上面的公式,我们有
( 2051 − 2052 ) 2 ⏞ This is a 2 . + 2 ( 2051 − 2052 ) ( 2052 − 2050 ) ⏞ This is 2 a b . + ( 2052 − 2050 ) 2 ⏞ This is b 2 . ( 2053 − 2052 ) 2 + 2 ( 2053 − 2052 ) ( 2052 − 2050 ) + ( 2052 − 2050 ) 2 ( 2055 − 2052 ) 2 + 2 ( 2055 − 2052 ) ( 2052 − 2050 ) + ( 2052 − 2050 ) 2 ( 2050 − 2052 ) 2 + 2 ( 2050 − 2052 ) ( 2052 − 2050 ) + ( 2052 − 2050 ) 2 ( 2051 − 2052 ) 2 + 2 ( 2051 − 2052 ) ( 2052 − 2050 ) ⏟ 求和=0 + ( 2052 − 2050 ) 2 \overbrace{(2051-2052)^{2}}^{\text{This is }a^{2}.}+\overbrace{2(2051-2052)(2052-2050)}^{\text{This is }2ab.}+\overbrace{(2052-2050)^{2}}^{\text{This is }b^{2}.}\\ (2053-2052)^{2}+2(2053-2052)(2052-2050)+(2052-2050)^{2}\\ (2055-2052)^{2}+2(2055-2052)(2052-2050)+(2052-2050)^{2}\\ (2050-2052)^{2}+2(2050-2052)(2052-2050)+(2052-2050)^{2}\\ (2051-2052)^{2}+\underbrace{2(2051-2052)(2052-2050)}_{\text{求和=0}}+(2052-2050)^{2} (2051−2052)2 This is a2.+2(2051−2052)(2052−2050) This is 2ab.+(2052−2050)2 This is b2.(2053−2052)2+2(2053−2052)(2052−2050)+(2052−2050)2(2055−2052)2+2(2055−2052)(2052−2050)+(2052−2050)2(2050−2052)2+2(2050−2052)(2052−2050)+(2052−2050)2(2051−2052)2+求和=0 2(2051−2052)(2052−2050)+(2052−2050)2
实际均值计算的方差 a 2 + b 2 n \frac{a^2+b^2}n na2+b2 >= 样本均值计算的方差 a 2 n \frac{a^2}n na2
从例子中,我们知道样本均值计算的方差偏小,那我们现在来计算他的期望:
x ˉ = 1 n ∑ i = 1 n x i \bar{x}=\frac{1}{n}\sum_{i=1}^nx_i xˉ=n1i=1∑nxi
E [ 1 n ∑ k = 1 n ( x k − x ‾ ) 2 ] = n − 1 n ( E [ X 2 ] − E [ X ] 2 ) = n − 1 n V a r ( X ) \mathbb{E}\left[\frac{1}{n}\sum_{k=1}^n(x_k-\overline{x})^2\right]=\frac{n-1}{n}\left(\mathbb{E}[X^2]-\mathbb{E}[X]^2\right) = \frac{n-1}{n}\mathrm{Var}(X) E[n1k=1∑n(xk−x)2]=nn−1(E[X2]−E[X]2)=nn−1Var(X)
于是很自然的我们得到了无偏样本方差:
s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ‾ ) 2 s^2=\frac{1}{n-1}\sum_{i=1}^n\left(x_i-\overline{x}\right)^2 s2=n−11i=1∑n(xi−x)2
那我们代入到之前的公式:
x ˉ − μ s / n ∼ t ( n − 1 ) \frac{\bar{x}-\mu}{s/\sqrt{n}} \sim t(n-1) s/nxˉ−μ∼t(n−1)
就会呈现一个自由度为 n − 1 n-1 n−1 的 T T T 分布,其中 n n n 是样本的数量。
注: s s s 的计算过程中依赖 ( x i − x ˉ ) (x_{i}-\bar{x}) (xi−xˉ) 的值,而这就产生了一个隐藏的限制, ∑ i = 1 n ( x i − x ) = 0 \sum_{i=1}^{n}(x_{i}-x)=0 ∑i=1n(xi−x)=0。所以这使得一旦前 n − 1 n-1 n−1 个 ( x i − x ˉ ) (x_{i}-\bar{x}) (xi−xˉ) 确定后,第 n n n 个 ( x i − x ˉ ) (x_{i}-\bar{x}) (xi−xˉ) 立马被锁定。自由度因此变成了 n − 1 n-1 n−1。
实验
不同分布不同抽样次数的总体分布
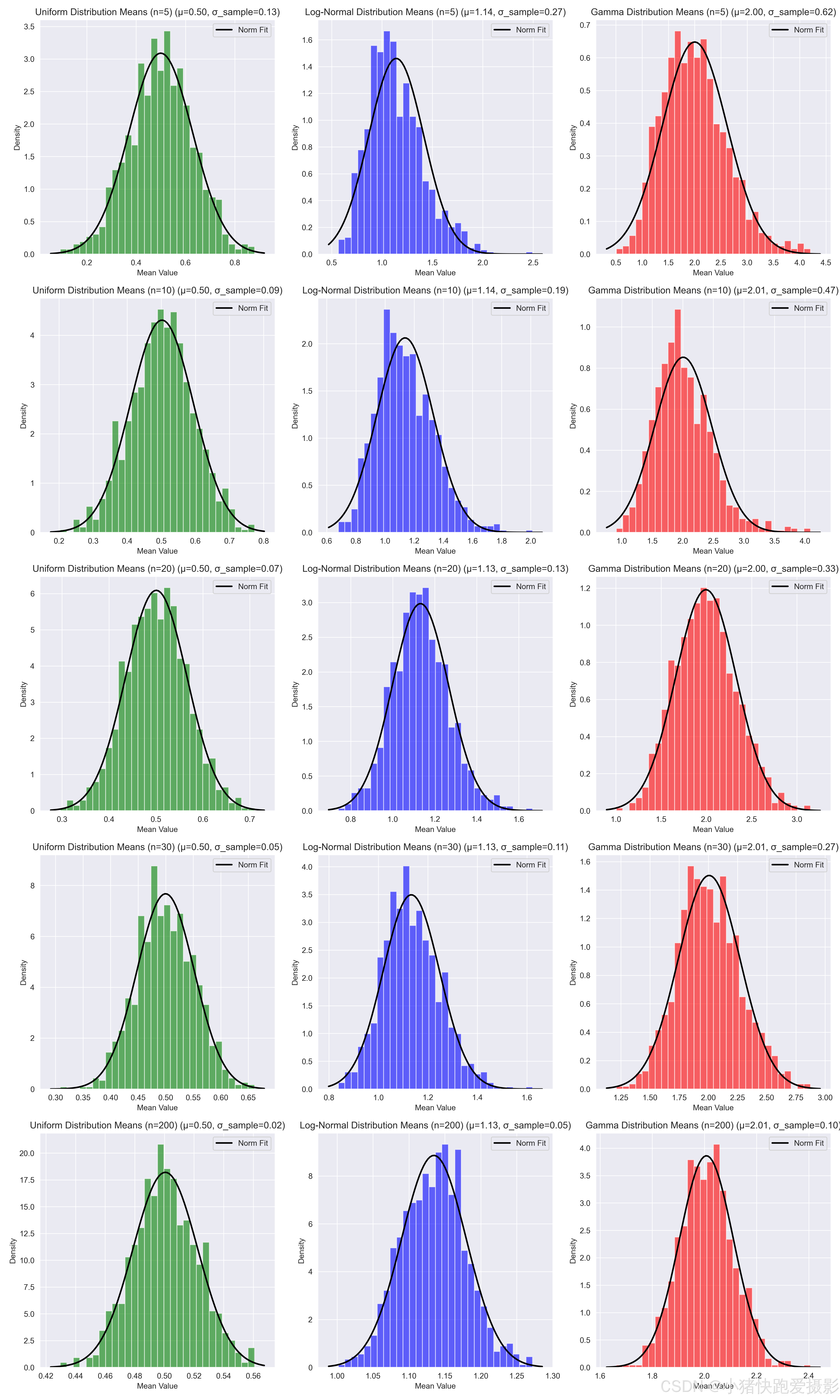
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import lognorm, gamma, norm, t# 设置重复次数
repeats = 1000 # 重复抽取样本的次数# 定义分布参数
uniform_low, uniform_high = 0, 1
lognorm_s = 0.5 # 对数正态分布形状参数
gamma_shape = 2 # 伽玛分布形状参数# 定义要测试的样本量
sample_sizes = [5, 10, 20, 30, 200]# 函数:绘制直方图和正态及t分布拟合曲线
def plot_distribution_with_fits(data, ax, color='b', title=''):# 计算样本均值和样本标准差mu = np.mean(data)std_sample = np.std(data, ddof=1) # 使用ddof=1来获得无偏样本标准差# 绘制直方图ax.hist(data, bins=30, density=True, alpha=0.6, color=color)# 绘制正态拟合曲线xmin, xmax = ax.get_xlim()x = np.linspace(xmin, xmax, 100)p_norm = norm.pdf(x, mu, std_sample)ax.plot(x, p_norm, 'k', linewidth=2, label='Norm Fit')title += f' (μ={mu:.2f}, σ_sample={std_sample:.2f})'ax.set_title(title)ax.set_xlabel('Mean Value')ax.set_ylabel('Density')ax.legend()# 创建子图并绘制图形
fig, axes = plt.subplots(len(sample_sizes), 3, figsize=(15, 25))for i, sample_size in enumerate(sample_sizes):# 初始化存储均值的列表means_uniform = []means_lognorm = []means_gamma = []# 抽取样本并计算均值for _ in range(repeats):# 均匀分布sample_uniform = np.random.uniform(uniform_low, uniform_high, sample_size)means_uniform.append(np.mean(sample_uniform))# 对数正态分布sample_lognorm = lognorm.rvs(s=lognorm_s, size=sample_size)means_lognorm.append(np.mean(sample_lognorm))# 伽玛分布sample_gamma = gamma.rvs(a=gamma_shape, size=sample_size)means_gamma.append(np.mean(sample_gamma))# 应用到每个分布plot_distribution_with_fits(means_uniform, axes[i, 0], color='g', title=f'Uniform Distribution Means (n={sample_size})')plot_distribution_with_fits(means_lognorm, axes[i, 1], color='b', title=f'Log-Normal Distribution Means (n={sample_size})')plot_distribution_with_fits(means_gamma, axes[i, 2], color='r', title=f'Gamma Distribution Means (n={sample_size})')# 展示图形
plt.tight_layout()
plt.savefig('figures/Distribution Means.png', dpi=300)
plt.show()
不同自由度相同参数的t分布&正态分布
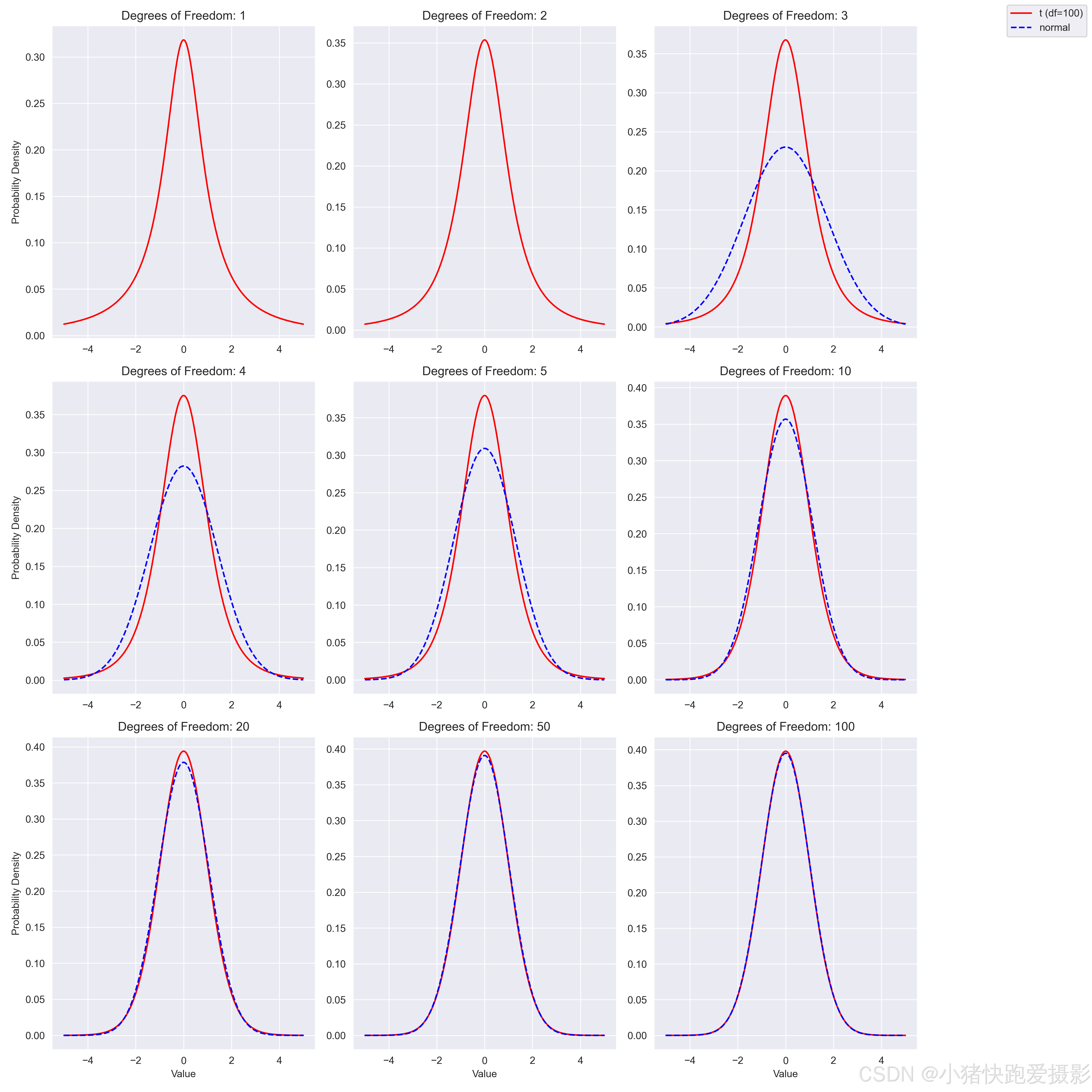
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import t, norm# 定义x轴的范围
x = np.linspace(-5, 5, 1000)# 定义要比较的t分布的不同自由度df列表
dfs = [1, 2, 3, 4, 5, 10, 20, 50, 100]# 创建一个3x3的子图网格
fig, axs = plt.subplots(3, 3, figsize=(15, 15))# 遍历不同的自由度并绘制对应的t分布和正态分布
for ax, df in zip(axs.flat, dfs):# 计算t分布的概率密度函数t_pdf = t.pdf(x, df)# 假设正态分布具有与t分布相同的均值(0)和标准差(sqrt(df/(df-2)),当df>2时)normal_pdf = norm.pdf(x, loc=0, scale=np.sqrt(df / (df - 2))) if df > 2 else None# 绘制t分布ax.plot(x, t_pdf, label=f't (df={df})', linestyle='-', color='red')# 如果df允许,绘制正态分布if normal_pdf is not None:ax.plot(x, normal_pdf, label='normal', linestyle='--', color='blue')# 添加标题ax.set_title(f'Degrees of Freedom: {df}')ax.grid(True)# 只在最下面一行添加xlabel,在最左边一列添加ylabel以保持整洁if ax.get_subplotspec().is_last_row():ax.set_xlabel('Value')if ax.get_subplotspec().is_first_col():ax.set_ylabel('Probability Density')# 添加一个总的图例到图表中
handles, labels = ax.get_legend_handles_labels()
fig.legend(handles, labels, loc='upper right')# 调整布局以防止重叠
plt.tight_layout(rect=[0, 0, 0.85, 1]) # 为图例留出空间plt.savefig('figures/t VS normal Distribution.png', dpi=300)# 显示图表
plt.show()
相关文章:
【超详图文】多少样本量用 t分布 OR 正态分布
文章目录 相关教程相关文献预备知识Lindeberg-Lvy中心极限定理 t分布的来历实验不同分布不同抽样次数的总体分布不同自由度相同参数的t分布&正态分布 作者:小猪快跑 基础数学&计算数学,从事优化领域7年,主要研究方向:MIP求…...

leetcode hot100【Leetcode 416.分割等和子集】java实现
Leetcode 416.分割等和子集 题目描述 给定一个非负整数的数组 nums ,你需要将该数组分割成两个子集,使得两个子集的元素和相等。如果可以分割,返回 true ,否则返回 false。 示例 1: 输入:nums [1,5,11,…...

《算法导论》英文版前言To the teacher第4段研习录:有答案不让用
【英文版】 Departing from our practice in previous editions of this book, we have made publicly available solutions to some, but by no means all, of the problems and exercises. Our Web site, http://mitpress.mit.edu/algorithms/, links to these solutions. Y…...

Laravel关联模型查询
一,多表关联 文章表articles 和user_id,category_id关联 //with()方法是渴求式加载,缓解了1N的查询问题,仅需11次查询就能解决问题,可以提升查询速度。with部分没有就以null输出,所以可以理解为 多表 left join 查…...

Clickhouse 数据类型
文章目录 字符串类型数值类型日期时间类型枚举类型数组类型元组类型映射类型其它类型 字符串类型 数据类型描述备注String可变长度字符串无长度限制,适用于存储任意字符FixedString固定长度字符串定长字符串,长度在创建时指定,如 FixedStrin…...

物联网智能项目如何实现设备高效互联与数据处理?
一、硬件(Hardware) 设备互联的基础,涵盖传感器、执行器、网关和边缘计算设备。 传感器与执行器 功能: 采集环境数据(如温度、湿度、运动等)并执行控制命令。优化方向: 低功耗、高精度传感器以…...

【云服务器】搭建博客服务
未完待续 一、云服务器二、1panel安装及其容器三、Halo博客 一、云服务器 选择了狗云服务器:狗云-高性价比的服务器 安装系统:Ubuntu22.04 前期配置: 修改ssh端口: 二、1panel安装及其容器 三、Halo博客 主题:butt…...

如何抽象策略模式
策略模式是什么 策略设计模式(Strategy Pattern)是一种面向对象设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以相互替换。这种模式使得算法可以独立于使用它们的客户端而变化。 策略设计模式包含三个主…...

BERT模型的输出格式探究以及提取出BERT 模型的CLS表示,last_hidden_state[:, 0, :]用于提取每个句子的CLS向量表示
说在前面 最近使用自己的数据集对bert-base-uncased进行了二次预训练,只使用了MLM任务,发现在加载训练好的模型进行输出CLS表示用于下游任务时,同一个句子的输出CLS表示都不一样,并且控制台输出以下警告信息。说是没有这些权重。…...

node.js实现分页,jwt鉴权机制,token,cookie和session的区别
文章目录 1. 分⻚功能2. jwt鉴权机制1.jwt是什么2.jwt的应用3.优缺点 3. cookie,token,session的对比 1. 分⻚功能 为什么要分页 如果数据量很⼤,⽐如⼏万条数据,放在⼀个⻚⾯显⽰的话显然不友好,这时候就需要采⽤分⻚…...

34 基于单片机的指纹打卡系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 基于STC89C52RC,采用两个按键替代指纹,一个按键按下,LCD12864显示比对成功,则 采用ULN2003驱动步进电机转动,表示开门,另一个…...

【Linux】用户操作命令
声明:以下内容均学习自《Linux就该这么学》一书 1、管理员root Linux系统的管理员之所以是root,并不是因为它的名字叫root,而是因为该用户的身份号码UID(User IDentification)的数值是0。UID相当于身份证号码&#x…...

Y20030018基于Java+Springboot+mysql+jsp+layui的家政服务系统的设计与实现 源代码 文档
家政服务系统的设计与实现 1.摘要2.开发目的和意义3.系统功能设计4.系统界面截图5.源码获取 1.摘要 随着人们生活水平的提高,老龄化、少子化等多重因素影响,我国对家政服务人群的需求与日俱增。家政服务行业对我国的就业和社会效益贡献也与日俱增&#…...

windows部署PaddleSpeech详细教程
windows安装paddlespeech步骤: 1. 安装vs c编译环境 对于 Windows 系统,需要安装 Visual Studio 来完成 C 编译环境的安装。 Microsoft C Build Tools - Visual Studio 2. 安装conda conda create -y -p paddlespeech python3.8 conda activate pad…...

线程条件变量 生产者消费者模型 Linux环境 C语言实现
只能用来解决同步问题,且不能独立使用,必须配合互斥锁一起用 头文件:#include <pthread.h> 类型:pthread_cond_t PTHREAD_COND_INITIALIZER 初始化 初始化:int pthread_cond_init(pthread_cond_t * cond, NULL);…...

C++ packaged_task
packaged_task 是 C11 标准库中引入的一个模板类,它用于将可调用对象(如函数、lambda 表达式、函数对象或绑定表达式)包装起来,并允许异步地获取其结果packaged_task 类提供了一种方便的方式来创建任务,这些任务可以被…...

【联表查询】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

嵌入式C编程:宏定义与typedef的深入对比与应用
目录 一、宏定义(Macro Definition) 1.1. 特点与应用 1.1.1 定义常量 1.1.2 定义函数式宏 1.1.3 条件编译 1.2. 作用范围和生命周期方面 1.3. 应用注意事项 二、typedef 2.1. 特点与应用 2.1.1 简化类型声明 2.1.2 提高代码可读性 2.1.3 实现…...

高级java每日一道面试题-2024年12月03日-JVM篇-什么是Stop The World? 什么是OopMap? 什么是安全点?
如果有遗漏,评论区告诉我进行补充 面试官: 什么是Stop The World? 什么是OopMap? 什么是安全点? 我回答: 在Java虚拟机(JVM)中,Stop The World、OopMap 和 安全点 是与垃圾回收(GC)和性能优化密切相关的概念。理…...

【openGauss︱PostgreSQL】openGauss或PostgreSQL查表、索引、序列、权限、函数
【openGauss︱PostgreSQL】openGauss或PostgreSQL查表、索引、序列、权限、函数 一、openGauss查表二、openGauss查索引三、openGauss查序列四、openGauss查权限五、openGauss或PostgreSQL查函数六、PostgreSQL查表七、PostgreSQL查索引八、PostgreSQL查序列九、PostgreSQL查权…...

Photoshop到URP的法线验证闭环:跨引擎法线贴图精准调试指南
1. 这不是个“一键生成法线”的玩具,而是一套跨引擎、跨工作流的材质验证闭环你有没有遇到过这样的情况:在 Photoshop 里辛苦调出一张完美的 Normal Map,导入 Unity 后却发现高光方向反了、边缘发灰、贴图在 Decal 上拉伸变形,甚至…...

3步轻松解锁Cursor Pro:告别试用限制,永久免费享受AI编程助手
3步轻松解锁Cursor Pro:告别试用限制,永久免费享受AI编程助手 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

开源依赖引发线上性能风暴:JVM内存泄漏排查与解决方案
1. 项目概述:一次由开源依赖引发的线上性能风暴那天下午,监控告警突然炸了。线上核心服务的响应时间从几十毫秒飙升到数秒,CPU使用率瞬间冲上90%,更致命的是,JVM的Full GC(垃圾回收)频率从一天几…...

抖音内容保存技术方案:开源下载工具深度解析与应用实践
抖音内容保存技术方案:开源下载工具深度解析与应用实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...
终极指南:如何利用Py Eddy Tracker实现海洋中尺度涡旋高效识别与追踪
终极指南:如何利用Py Eddy Tracker实现海洋中尺度涡旋高效识别与追踪 【免费下载链接】py-eddy-tracker Eddy identification and tracking 项目地址: https://gitcode.com/gh_mirrors/py/py-eddy-tracker 海洋涡旋识别与中尺度涡旋追踪是海洋科学研究中的核…...
)
2026最新版|程序员/小白大模型转行全攻略(零基础入门+路径规划+避坑指南,收藏必看)
2026年,AI大模型依旧是互联网技术圈的绝对核心风口,行业技术迭代速度持续加快,传统开发赛道内卷加剧、薪资封顶、岗位缩减等问题愈发凸显。无数基层程序员陷入职业瓶颈,零基础新手也苦于传统技术入门难、竞争大。 反观大模型赛道&…...

Agent 框架别急着乱学:先用 LangChain 搞懂 7 个基本模块
先说结论。 如果你想系统理解 Python Agent 框架,LangChain 仍然值得作为第一篇。它不是最轻的,也不是最“自动化”的,但它把 Agent 应用里的关键零件都摆出来了:模型、工具、状态、记忆、middleware、多 Agent 路由和 tracing。…...

WarcraftHelper终极教程:5分钟让魔兽争霸3焕发新生
WarcraftHelper终极教程:5分钟让魔兽争霸3焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电脑上运行不…...

如何用FARM框架在5分钟内搭建专业问答系统
如何用FARM框架在5分钟内搭建专业问答系统 【免费下载链接】FARM :house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering. 项目地址: https://gitcode.com/gh_mirrors/far/FARM F…...

Vibe Vibe 未来展望:Vibe Coding 如何彻底改变编程教育生态
Vibe Vibe 未来展望:Vibe Coding 如何彻底改变编程教育生态 【免费下载链接】vibe-vibe The First Systematic Vibe Coding Open-Source Tutorial | From Zero to Full-Stack, Empowering Everyone to Build Products with AI | Live at: www.vibevibe.cn ÿ…...