Redis4——持久化与集群
Redis4——持久化与集群
本文讲述了1.redis在内存占用达到限制后的key值淘汰策略;2.redis主从复制原理;3.redis的哨兵模式;4.redis集群模式。
1. 淘汰策略
设置过期时间
expire key <timeout>
只能对主hash表中的键设置过期时间。
查看键的剩余存活时间
ttl key
淘汰策略
maxmemory
在redis.conf中设置maxmemory,规定redis所能占用的最大内存。
maxmemory <bytes>
一般这个阈值设置为机器内存大小的一半:
- 如果采用rdb持久化,需要fork一个子进程来将数据写入磁盘,导致内存占用翻倍。
maxmemory-policy
- noeviction:达到最大内存后,不淘汰key,而是直接返回错误
- volatile-lru
- allkeys-lru
- volatile-lfu
- allkeys-lfu
- volatile-random
- allkeys-random
volatile针对设置了过期时间的keys。
allkeys针对所有keys。
lru least recently used, 最长时间未使用
lfu least frequently used,最少使用频次
random 随机挑选keys
2. 持久化

2.1 fork与写时复制
数据流
fwrite将数据写入std库中建立的用户缓冲区,fflush将数据写入内核缓冲区,fsync最终将数据从内核缓冲区写入磁盘。
写时复制原理(Copy-On-Write, COW)
fork创建子进程后,并不立即复制父进程的内存空间,父子进程的虚拟内存空间会指向相同的物理内存,并全部标记为只读状态。
当子进程或者父进程执行写操作,触发写保护中断时,由操作系统复制相应的物理内存页,更新地址映射,并改为可读可写。
这么做的目的是提高fork的效率,并减少不必要的复制和内存占用。
redis持久化
fork子进程的写时复制机制,能够使redis在持久化过程中:
- 不阻碍期间数据的访问和更新。
- fork相当于生成了一个主进程内存空间的快照,子进程可以只持久化快照版本的数据,保证一致性。
- 不长时间阻塞主线程。
2.2 redis持久化策略
-
rdb,(Redis Database)
RDB 是 Redis 的快照持久化机制,它会在指定的时间间隔内将数据写入磁盘(fork子进程)。其工作原理是将 Redis 内存中的数据快照保存到一个二进制文件(默认为
dump.rdb)。RDB 是一种基于时间点的持久化方式,具有以下优点:- rdb文件小,数据恢复速度块
缺点:
- 数据丢失风险大,两次rdb快照之间的数据修改可能会丢失
- 持久化过程代价较高,因为每次将全部数据写入磁盘
-
aof,(Append Only File)
AOF 是 Redis 的一种写操作持久化机制,它通过记录所有写操作命令来实现持久化。每当 Redis 执行一个写命令时,AOF 会将该命令追加到日志文件(默认文件名为
appendonly.aof)。AOF 的特点如下:- 记录所有写操作:AOF 记录了所有对 Redis 数据库的写操作,重启时会根据 AOF 中的命令重新执行操作。
- AOF 提供三种同步策略:
- 每次写操作同步(always):每次写操作都会同步到磁盘(最安全,但性能最差)。
- 每秒同步(every-sec):每秒落盘一次(折衷方案,性能和安全性之间的平衡)。
- 不同步(no):不进行同步操作,由操作系统控制写入(性能最好,但数据丢失风险最大)。
- 日志文件较大:由于 AOF 记录了所有的写命令,它的日志文件会随着时间增加而增大。为了解决这个问题,Redis 提供了 AOF 文件重写机制,可以通过压缩日志文件来减少 AOF 文件的大小。
优点:
- 持久化过程代价低,不需要每次都fork子进程,只需记录新的写操作
- 数据丢失风险小
缺点:
- 数据恢复速度慢,需要把写入操作重新执行一遍
-
aof rewirte
append-only file可能记录了冗余的写操作,为了减少同一个key的历史冗 余,可以使用aof rewrite来基于当前内存中的数据重写aof。简单来说就是基于当前内存数据重写aof文件。也是通过fork子进程的尝试来重写,在重写期间发生的写操作,会被记录到重写缓冲区中,等重写完毕再附加到aof文件的末尾。
-
rdb-aof混用
每隔一段时间fork子进程,根据内存数据生成rdb文件;同时启用aof文件,记录写操作,并在rdb持久化期间将写操作写到重写缓冲区,当持久化结束后,附加到aof文件末尾。
2.3 配置持久化策略
都可以redis.conf中设置,例如设置是否开启aof持久化策略
# Please check https://redis.io/topics/persistence for more information.appendonly no# The name of the append only file (default: "appendonly.aof")appendfilename "appendonly.aof"# appendfsync always
appendfsync everysec
# appendfsync no
2.4 大key对持久化的影响
大key:kv中,value元素较大,例如容器类型的列表、集合、字典
- fsync压力更大。
- fork的时候,需要更多的写时复制操作,导致持久化过程更长。
3. Redis主从复制
3.1 原理
主要用来实现redis数据的可靠性;防止主redis所在磁盘损坏,造成数据永久丢失;主从之间采用异步复制方式。
解决了单点故障问题。
异步复制:数据写入主数据后直接返回,然后从数据库定时向主数据库请求增量的数据更新。
优点是高效,缺点是不能保证数据总是一致的。
# 连接主数据库127.0.0.1:6379
redis-server --replicaof 127.0.0.1 6379
或者在配置文件中指定
# redis.conf
replicaof 127.0.0.1 6379
info replication
3.2 数据同步
全量数据同步
全量数据同步一般发生在,从节点首次连接主节点时,或者从节点与主节点失去同步时。
过程:
- 从节点发送数据同步请求PSYNC
- 主节点生成 RDB 快照:
主节点调用BGSAVE命令生成 RDB 文件,同时将接收到的写命令暂存在复制积压缓冲区(Replication Buffer)。 - 发送 RDB 文件:
主节点将 RDB 文件传输到从节点。从节点接收并加载该 RDB 文件以重建内存中的数据。 - 发送缓冲区数据:
主节点将缓冲区中积累的写命令发送到从节点,从节点依次执行这些命令以完成数据的更新。
增量数据同步
触发条件:
- 从节点已完成全量同步,并且与主节点之间的连接正常。
- 从节点短时间断线,重新连接后仍然可以通过主节点的复制积压缓冲区(Replication Backlog Buffer)完成同步。
过程:
-
主节点记录写操作日志:
主节点将所有写操作记录在复制积压缓冲区中。 -
从节点请求增量数据:
从节点通过PSYNC命令发送自己的偏移量和replid(主节点的复制 ID),请求从主节点同步从最后的偏移量开始的数据。 -
主节点发送增量数据:
主节点根据从节点提供的偏移量,从复制积压缓冲区中提取增量写操作日志,并将其发送给从节点。从节点按顺序执行这些命令以完成数据同步。
服务器Replid
无论主库还是从库都有自己的Replid,启动时自动产生,由40个随机的十六进制字符组成;
- 当从库对主库初次复制时,主库将自身的Replid传送给从库,从库会将Replid保存;
- 当从库断线重连主库时,从库发送PSYNC带有主库的Replid和offset信息;
- 如果从库发送的Replid和主库Replid一致,说明从库断线前复制的就是当前的主库,主库尝试执行增量同步操作;
- 若不一致,说明从库断线前复制的主库并不时当前的主库,则主库将对从库执行全量同步操作;
复制偏移量Offset
主从都会维护一个复制偏移量:主库向从库发送N个字节后,将偏移量加N;从库从主库收到N个字节后,将偏移量加N;
通过比较主从偏移量得知主从之间数据是否一致;偏移量相同则数据一致;偏移量不同则数据不一致;
当从库进行增量同步时,会发送自身的复制偏移量到主库,主库会比较主从的复制偏移量:
- 如果从库offset还在复制积压缓冲区,则进行增量同步;
- 否则,主库将对从库执行全量同步;
复制积压缓冲区(环形缓冲区):
该缓冲区本质上是一个先进先出的队列,记录了主库的写操作,用于进行增量同步。
# 设置复制积压缓冲区大小
repl-backlog-size 1mb
# 所有从库断开连接3600秒后,释放环形缓冲区
repl-backlog-ttl 3600
4. Redis哨兵模式

4.1 哨兵模式原理
哨兵模式是实现Redis高可用性的解决方案,目的是监控主从节点的状态,必要时进行主从切换。
原理(发布-订阅模式):客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,并且通过 subscribe 监听主节点切换。然后再连接主节点进行数据交互。当主节点发生故障时,sentinel主动推送新的主库地址。通过这样客户端无须重启即可自动完成节点切换。
功能:哨兵节点用于监控 Redis 主从架构中的主库(Master)和从库(Replica),并在主库发生故障时自动执行故障切换(failover)。哨兵模式通过多个哨兵实例协作,提供监控、通知和自动化管理功能。
- 监控(Monitoring)
- 哨兵会定期检查主库和从库的运行状态。
- 使用
PING命令检测实例是否在线,判断是否失联。
- 通知(Notification)
- 当主库或从库出现问题时,哨兵会向管理员发送警报通知。
- 自动故障转移(Failover)
- 如果主库不可用,哨兵会在剩余从库中选出一个新的主库,并通知其他从库切换同步目标。
- 客户端也会被通知新的主库地址。
- 配置管理
- 哨兵会动态调整从库的配置,使其同步新的主库。
- 客户端可以通过哨兵获取当前的主库地址,无需手动修改。
缺点
不支持横向扩展,始终只有一个服务器向外提供服务。哨兵模式只是一种提高可用性的机制。
为什么实际项目中至少会部署3个以上的哨兵并且哨兵数量最好为奇数?
- 哨兵模式主要为了解决单点故障问题,如果哨兵只有一个,那如果哨兵发生故障就无法解决了。
- 为了避免多个哨兵同时执行切换操作,必须通过某种选举机制选出一个leader来执行切换操作。假设哨兵数量是偶数,则可能选不出来leader。
主从切换完成之后,客户端和其他哨兵如何知道现在提供服务的Redis Master是哪一个呢?
可以通过订阅__sentinel__:hello频道,知道当前提供服务的Master的IP和Port。
执行切换的哨兵发生了故障,切换操作是否会由其他哨兵继续完成呢?
执行切换的哨兵发生故障后,剩余哨兵会重新选主,并且重新开始执行切换流程。
故障Master恢复之后,会继续作为Master提供服务还是会作为Slave提供服务?
Redis中主从切换完成之后,当故障Master恢复之后,会作为新Master的一个Slave来提供服务。
4.2 主从切换
当Redis哨兵方案中的Master处于客观下线状态,为了保证Redis的高可用性,此时需要执行主从切换。即将其中一个Slave提升为Master,其他Slave从该提升的Slave继续同步数据。
4.3 如何设置哨兵模式
# sentinel.conf# 指定哨兵检测的主节点,quorum为2,表示至少两个哨兵的S_DOWN才能标记为O_DOWN,主从切换时至少获取2票才能被选为leader
sentinel monitor mymaster 127.0.0.1 6379 2
# 如果哨兵60s内未收到节点的有效ping回复,则认为节点处于down状态
sentinel down-after-milliseconds mymaster 60000
# 设置执行主从切换的超时时间为180s,超过这个时间,表示主从切换失败
sentinel failover-timeout mymaster 180000
# 切换完成后同时向新的master发起同步请求的slave的数量
sentinel parallel-sync mymaster 1
在哨兵节点的配置文件中,只需要配置与主节点的连接,哨兵节点会自动根据此连接建立与从节点的连接。
哨兵可以直接使用redis-server命令启动,如下:
redis-server /path/to/sentinel.conf --sentinel
5. Redis Cluster
前面介绍的主从服务器和哨兵集群都是始终只有一个节点在提供服务。而Cluster集群可以有多个节点同时对外提供服务。

5.1 集群原理
功能:Cluster的主要用来提供横向扩展能力,当数据量增多时,可以通过增加服务节点来扩展服务能力,并且当部分节点失效后仍然可以使用。
原理:集群的原理是通过分布式一致性hash算法,将数据均匀的放在不同的服务节点中,这样节点数量越多,单个节点的压力就越小。
通过分布式一致性hash算法将key和节点映射到一个拥有16384个槽位的环状空间。
客户端可以请求任意一个节点,每个节点中都会保存所有16384个slot对应到哪一个节点的信息。如果一个key所属的slot正好由被请求的节点提供服务,则直接处理并返回结果,否则返回MOVED重定向信息。
问:如何保证数据均衡地落在多个服务器中?
答:
-
分布式一致性hash:
- 将整个哈希空间组织成一个环状结构,在redis中,键空间共有2的14次方(16384)个槽位。
- 节点和键都通过哈希算法映射到这个环上,每个redis节点可以对应多个虚拟节点。
- 键存储在其顺时针方向的最近节点中。
-
虚拟节点
在一致性哈希中,如果物理节点数量较少,节点之间的距离可能不均匀,导致负载分布不均。一个改进是引入虚拟节点,用于解决节点分布不均的问题。
问:一致性hash的优点
答:
-
最小数据迁移。节点增减时,仅影响部分键,不会导致全局数据重分布。而传统hash算法,节点的变化会影响整个hash空间,导致缓存雪崩。
-
高扩展性。可以动态调整节点数量,适应集群规模变化。
-
负载均衡。借助虚拟节点技术,负载能够更均匀分布。
问:某个节点发生故障之后,该节点服务的数据该如何处理?
答:如果该节点是从节点,则不需要处理;如果该节点是主节点,则需要进行主从切换。
问:扩容,即向集群中添加新节点该如何操作?
答:首先需要通过一致性hash算法找到新节点所在的slot,然后将从slot到逆时针方向第一个节点之间key值从顺时针方向第一节点中迁移到该新节点。最后通知集群中所有的节点slot映射信息的变化。
问:同一条命令需要处理的key分布在不同的节点中(如Redis中集合取并集、交集的相关命令),如何操作?
答:需要由业务方用hash标签保证多个key在同一个节点中。
当一条命令需要操作的key分属于不同的节点时,Redis会报错。Redis提供了一种称为hash tags的机制,由业务方保证当需要进行多个key的处理时,将所有key分布到同一个节点,该机制实现原理如下:
如果一个key包括{substring}这种模式,则计算slot时只计算“{”和“}”之间的子字符串。即keys{sub}1、keys{sub}2、keys{sub}3计算slot时都会按照sub串进行。这样保证这3个字符串会分布到同一个节点。
5.2 主从切换
当集群中节点通过错误检测机制发现某个节点处于fail状态时,会自动执行主从切换。Redis中还提供一种手动执行切换的方法,即通过执行cluster failover命令。下面分别介绍这两种方式。
自动切换
集群之间会互相发送心跳包,心跳包中会包括从发送方视角所记录的关于其他节点的状态信息。当一个节点收到心跳包之后,如果检测到发送方(假设为A)标记某个节点(假设为B)处于pfail状态,则接收节点(假设为C)会检测B是否已经被大多数主节点标记为pfail状态。如果是,则C节点会向集群中所有节点发送一个fail包,通知其他节点B已经处于fail状态。
当一个主节点(假设为B)被标记为fail状态后,该主节点的所有Slave执行周期性函数clusterCron时,会从所有的Slave中选择一个复制偏移量最大的Slave节点(即数据最新的从节点,假设为D),然后D节点首先将其当前纪元(currentEpoch)加1,然后向所有的主节点发送failover授权请求包,当获得大多数主节点的授权后,开始执行主从切换。
切换流程如下(假设被切换的主节点为M,执行切换的从节点为S)。
1)S先更新自己的状态,将自己声明为主节点。并且将S从M中移除。
2)由于S需要切换为主节点,所以将S的同步数据相关信息清除(即不再从M同步数据)。
3)将M提供服务的slot都声明到S中。
4)发送一个PONG包,通知集群中其他节点更新状态。
手动切换
当一个从节点接收到cluster failover命令之后,执行手动切换,流程如下。
1)该从节点首先向对应的主节点发送一个mfstart包(见22.2.6的第8节)。通知主节点从节点要开始进行手动切换。
2)主节点会阻塞所有客户端命令的执行。之后主节点在周期性函数clusterCron中发送ping包时会在包头部分做特殊标记。
3)当从节点收到主节点的ping包并且检测到特殊标记之后,会从包头中获取主节点的复制偏移量。
4)从节点在周期性函数clusterCron中检测当前处理的偏移量与主节点复制偏移量是否相等,当相等时开始执行切换流程。
5)切换完成后,主节点会将阻塞的所有客户端命令通过发送+MOVED指令重定向到新的主节点。
通过该过程可以看到,手动执行主从切换时不会丢失任何数据,也不会丢失任何执行命令,只在切换过程中会有暂时的停顿。
5.3 副本重分配(Replica Rebalancing)
假设一对主从同时发生故障,则集群中的某些slot会处于不能提供服务的状态,从而导致集群失效。
为了提高可靠性,我们可以在每个主服务下边各挂载两个从服务实例。假设若集群中有100个主服务,为了更高的可靠性,就需要增加100个实例。有什么方法既能提高可靠性,又可以做到不随集群规模线性增加从服务实例的数量呢?
Redis中提供了一种副本重分配的方法,原理是将有多个从节点的主节点的从节点重新分配给缺少从节点的主节点。

我们只给其中一个主C增加两个从服务。假设主A发生故障,主A的从A1会执行切换,切换完成之后从A1变为主A1,此时主A1会出现单点问题。当检测到该单点问题后,集群会主动从主C的从服务中漂移一个给有单点问题的主A1做从服务。
5.4 分片迁移
Redis集群中分片的迁移,即slot的迁移,需要将一个slot中所有的key从一个节点迁移到另一个节点。
有很多情况下需要进行分片的迁移,例如增加一个新节点之后需要把一些分片迁移到新节点,或者当删除一个节点之后,需要将该节点提供服务的分片迁移到其他节点,甚至有些时候需要根据负载重新配置分片的分布。
具体迁移方式请看5.6。
5.5 redis集群的实现
如果开启了集群模式,在initServer函数中:
void initServer(void) {...if (server.cluster_enabled) clusterInit();...
}clusterInit函数会加载配置并且初始化一些状态指标,监听集群通信端口。
类似哨兵,Redis时间任务函数serverCron中会调度集群的周期性函数,如下:
serverCron()
{...if (server.cluster_enabled) clusterCron();...
}
该函数每1s会随机选择一个节点,发送ping消息,如果在超时时间之内未收到响应,则将其标记为pfail。当一个节点被大多数其它节点标记为pfail后,它就会被标记为fail,只有fail状态的节点需要执行主从切换。
然后该函数会检查是否需要进行主从切换和副本漂移。
Redis除了在serverCron函数中进行调度之外,在每次进入事件循环之前,会在before-Sleep函数中执行一些操作,主要是检查主从切换状态和更新集群状态。
beforeSleep()
{...if (server.cluster_enabled) clusterBeforeSleep();...
}
5.6 如何配置集群
一个典型的redis集群配置如下:
# 7000-cluster.conf
port 7000 //监听端口
cluster-enabled yes //是否开启集群模式
cluster-config-file nodes7000.conf //集群中该节点的配置文件
cluster-node-timeout 5000 //节点超时时间,超过该时间之后会认为处于故障状态
daemonize yes
7000端口用来处理客户端请求,除了7000端口,Redis集群中每个节点会起一个新的端口(默认为监听端口加10000,本例中为17000)用来和集群中其他节点进行通信。cluster-config-file指定的配置文件需要有可写权限,用来持久化当前节点状态。
假如集群中,有6个节点,则需要启动6个redis-server:
redis-server 7000-cluster.conf
redis-server 7001-cluster.conf
redis-server 7002-cluster.conf
redis-server 7003-cluster.conf
redis-server 7004-cluster.conf
redis-server 7005-cluster.conf
开启后,可以使用redis-cli工具来自动创建集群,指定1个主节点搭配1个从节点。
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
可以通过redis-cli -c -p 测试集群
redis-cli -c -p 7001
节点宕机
redis-cli -p 7001 shutdown
节点重启
redis-server 7001/7001.conf
扩容:先添加节点,再分配槽位
开启新节点并加入集群:
redis-server 7007/7007.conf
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
开启新节点作为一个salve
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id ed7cd35630c50c7f1bdcacbc5f910f835514c5cd
分配槽位
# 提示输入模式
redis-cli --cluster shard 127.0.0.1:7001
# 或者直接指定
redis-cli --cluster shard 127.0.0.1:7001 --cluster-from 07617e42f430fe61ce6238fd85fa1a6ff04ab486 --cluster-to 71e81275c71e8021bf080a1010d6f384cdc68e90 --cluster-slots 1000
缩容:先迁移槽位,再删除节点
还是使用redis-cli --cluster shard ip:port进行。
学习参考
学习更多相关知识请参考零声 github。
相关文章:
Redis4——持久化与集群
Redis4——持久化与集群 本文讲述了1.redis在内存占用达到限制后的key值淘汰策略;2.redis主从复制原理;3.redis的哨兵模式;4.redis集群模式。 1. 淘汰策略 设置过期时间 expire key <timeout>只能对主hash表中的键设置过期时间。 查…...

【LeetCode: 94. 二叉树的中序遍历 + 栈】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

Python系列 - MQTT协议
Python系列 - MQTT协议 资源连接 MQTT的介绍和应用场景的示例说明 一、什么是MQTT 百度关于MQTT的介绍如下: MQTT(消息队列遥测传输)是ISO 标准(ISO/IEC PRF 20922)下基于发布订阅范式的消息协议。它工作在 TCP/IP协议之上,是为硬件性能低下的远程设…...

同时在github和gitee配置密钥
同时在github和gitee配置密钥 1. 生成不同的 SSH 密钥 为每个平台生成单独的 SSH 密钥。 # 为 GitHub 生成密钥(默认文件路径为 ~/.ssh/github_id_rsa) ssh-keygen -t rsa -b 4096 -C "your_github_emailexample.com" -f ~/.ssh/github_id_…...
Runway 技术浅析(六):文本到视频(Text-to-Video)
1. 核心组件与工作原理 1.1 自然语言处理(NLP) 1.1.1 文本解析与语义理解 文本到视频的第一步是将用户输入的自然语言文本解析为机器可理解的语义信息。Runway 使用预训练的 NLP 模型,如 GPT-3 和 BERT,这些模型通过大规模文本数…...
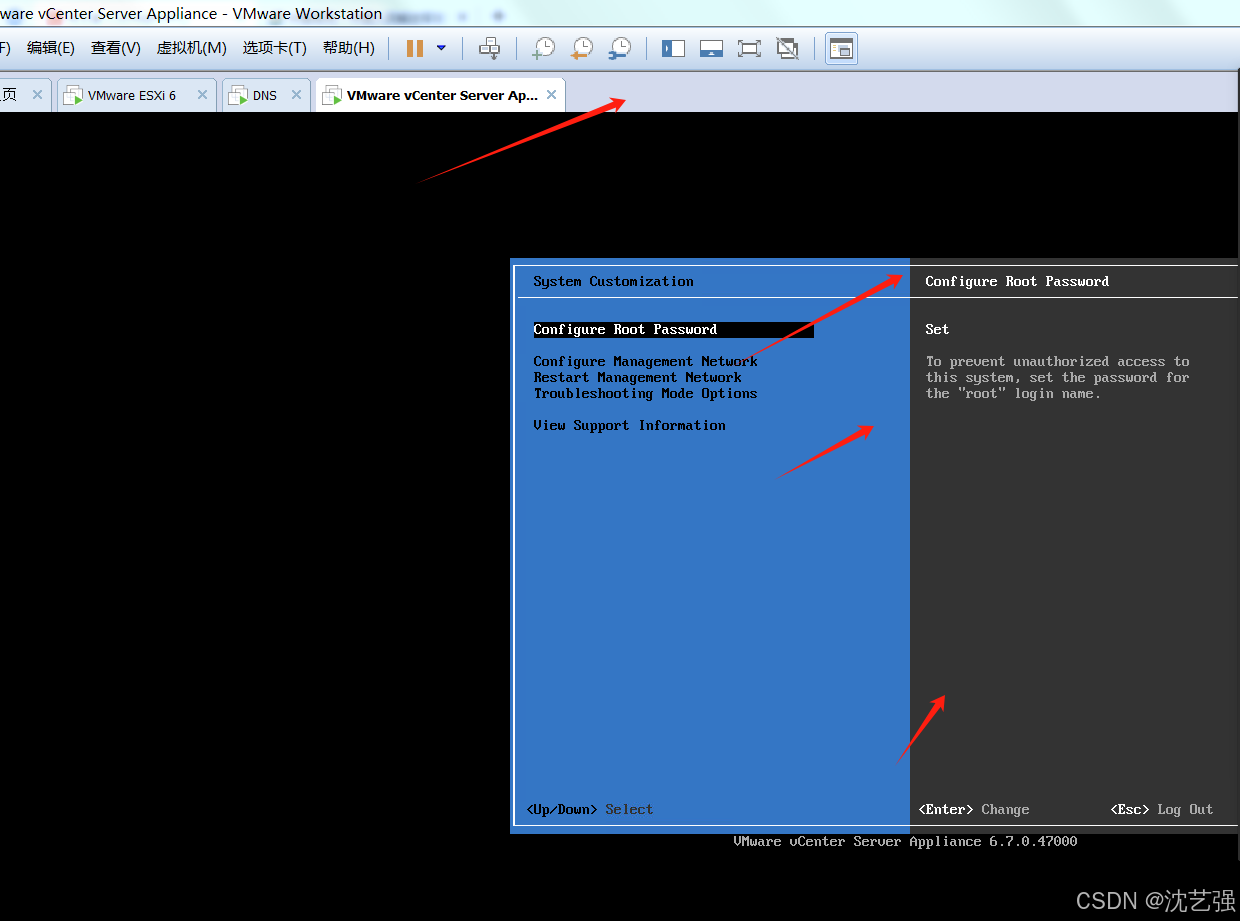
云计算vspere 安装过程
1 材料的准备 1 安装虚拟机 vmware workstation 2 安装esxi 主机 3 在esxi 主机上安装windows 2018 dns 服务器 4 在虚拟机上安装windows 2018 服务器 6 安装vcenter 5 登入界面测试 这里讲一下,由于部署vspere 需要在windows 2012 服务器上部…...

QT 实现QStackedWidget切换页面右移动画
1.实现效果 以下是一个QStackedWidget,放了两个QPushButton在上面,点击切换不同的界面。 为了方便查看动画特效,设置了每个界面的背景图片。 2.实现思路 首先截取当前界面的图片,渲染到一个QLabel上,然后设置QPropertyAnimation动画,动画的作用对象就是这个QLabel,不断…...
Android Camera2采集并编码为H.264
前言 本篇博文主要讲述的是基于Android原生MediaCodec通过Camera2 API进行图像数据采集并编码为H.264的实现过程,如果对此感兴趣的不妨驻足观看,也欢迎大家大家对本文中描述不当或者不正确的地方进行指正。如果对于Camera2预览还不熟悉的可以观看博主上…...

DHCP和DNS
DHCP(动态主机配置协议)和DNS(域名系统)是计算机网络中两个重要的协议,它们在网络的管理和使用中发挥着关键作用。 DHCP(动态主机配置协议) 基本功能 自动分配IP地址:DHCP允许网…...

ONES 功能上新|ONES Project 甘特图再度升级
ONES Project 甘特图支持展示工作项标题、进度百分比、依赖关系延迟时间等信息。 应用场景: 在使用甘特图规划项目任务、编排项目计划时,可以对甘特图区域进行配置,展示工作项的工作项标题、进度百分比以及依赖关系延迟时间等维度,…...

<工具 Claude Desktop> 配置 MCP server 连接本地 SQLite, 本机文件夹(目录) 网络驱动器 Windows 11 系统
也是在学习中... 起因: 抖音博客 艾克AI分享 他的视频 #143《Claude开源MCP彻底打破AI的信息孤岛》 提到: Claude开源的MCP太强了,视频后面是快速演示,反正看了好几遍也没弄明白。菜单都不一样,感觉用的不是同一家 Claude. 探…...

GIT的使用方法以及汉化方法
1.下载git软件,可以从官网下载 下载后默认安装即可。 2.找到一个文件夹,或者直接打开gitbash gitbash可以使用cd指令切换目录的 打开后输入 git clone https:[git仓库的网页]即可克隆仓库 就是这个地址 克隆后即可使用代码 如果忘记了命令可以使用 -…...

公因子的数目
给你两个正整数 a 和 b ,返回 a 和 b 的 公 因子的数目。 如果 x 可以同时整除 a 和 b ,则认为 x 是 a 和 b 的一个 公因子 。 输入:a 12, b 6 输出:4 解释:12 和 6 的公因子是 1、2、3、6 。 class Solution {pu…...
——双向链表的介绍以及实现)
数据结构(三)——双向链表的介绍以及实现
前言 前面两期数据结构的文章我们介绍了顺序表和单向链表,那么本篇博文我们将来了解双向链表,作为最好用的一种链表,双向链表有什么特殊之处呢,接下来就让我们一起了解一下吧。 下面是前两篇数据结构的文章: 数据结…...
Webpack开发模式及处理样式资源
一、开发模式介绍 开发模式顾名思义就是我们开发代码时使用的模式。 这个模式下我们主要做两件事: 编译代码,使浏览器能识别运行 开发时我们有样式资源、字体图标、图片资源、html 资源等,webpack 默认都不能处理这些资源,所以我…...

leetcode--设计链表
707.设计链表 你可以选择使用单链表或者双链表,设计并实现自己的链表。 单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。 如果是双向链表,则还需要属性 prev 以指示链表中的…...

【MySQL】:数据库操作
MySQL 数据库基础理论 2.1 数据库系统概述 介绍数据库系统的基本概念、发展历程、分类及 MySQL 在其中的地位与特点。 2.2 MySQL 数据库体系结构 解析 MySQL 的整体架构,包括服务器层与存储引擎层的功能与交互机制,重点探讨 InnoDB、MyISAM 等存…...
)
刷蓝桥杯历年考题(更新至15届~)
第十五届 CA组省赛 AcWing5980.训练士兵 方法一:树状数组:O(nlogn) self-complete /*先枚举组团,后分析每个士兵,有一个特点,组团费用是固定的,那当然是让所有士兵一块训练,训练完的士兵也不会有损失当还…...

AI与BI的火花:大语言模型如何重塑商业智能的未来
大家好,我是独孤风。 在当今这个数据驱动的时代,企业对于信息的需求如同对于氧气的需求一般至关重要。商业智能(BI)作为企业获取、分析和呈现数据的关键工具,正在经历一场深刻的变革,而这一变革的催化剂正是…...

Qt 详解QtNFC 读写模式
文章目录 Qt NFC 读写模式详解1. NFC 读写模式简介1.1 什么是 NFC 读写模式?主要功能: 1.2 常见应用场景 2. Qt NFC 读写模式原理3. 配置 QtNFC 模块4. NFC 读写操作实现4.1 NFC 标签读取代码示例功能解析 4.2 NFC 标签写入代码示例功能解析 5. 使用注意…...

RAG 检索到了还是答错:从一个线上事故讲透 RAG 数据工程全链路
一个合同问答系统的线上事故 某企业法务团队上线了一套合同问答系统。用户问:“渠道商季度返点的计算条件是什么?” 系统返回了三段参考文档,生成了一段看起来完整的回答。法务审核时发现:引用的是 2024 年旧版渠道政策…...

2026年四款主流 SaaS 收银系统:不同场景怎么选?
开店做生意,最让人头疼的往往不是选址或装修,而是每天打烊后对着乱糟糟的账本发愁。很多刚起步的老板为了省成本,初期只用纸笔或简单的 Excel 记账,一旦客流上来,库存对不上、会员积分算错、交接班混乱等问题接踵而至。…...

从被动响应到主动行动:AI Agent的自主性革命
从被动响应到主动行动:AI Agent的自主性革命 标题选项 《从被动响应到主动行动:AI Agent如何开启下一代人工智能的自主性革命》 《告别“一问一答”:拆解AI Agent的自主决策逻辑,看懂下一代AI的核心方向》 《从ChatGPT到自主Agent:人工智能的下一个拐点,到底革了谁的命?…...
3个核心功能:用HSTracker将炉石传说数据转化为你的制胜优势
3个核心功能:用HSTracker将炉石传说数据转化为你的制胜优势 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 在炉石传说的竞技场上,每一张卡牌的抽…...

通过 curl 命令直接测试 taotoken 大模型接口的响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令直接测试 taotoken 大模型接口的响应 在开发或调试大模型应用时,有时我们希望绕过 SDK,直接…...

Moonlight iOS/tvOS:在苹果设备上畅玩PC游戏的终极流媒体方案
Moonlight iOS/tvOS:在苹果设备上畅玩PC游戏的终极流媒体方案 【免费下载链接】moonlight-ios GameStream client for iOS/tvOS 项目地址: https://gitcode.com/gh_mirrors/mo/moonlight-ios Moonlight iOS/tvOS 是一款专为苹果生态系统设计的开源游戏流媒体…...

CameraFileCopy:创新实现手机摄像头离线文件传输的完整解决方案
CameraFileCopy:创新实现手机摄像头离线文件传输的完整解决方案 【免费下载链接】cfc Demo/test android app for libcimbar. Copy files over the cell phone camera! 项目地址: https://gitcode.com/gh_mirrors/cfc/cfc 在无线网络无处不在的今天ÿ…...

2026年盘点最好的5款许可优化工具
你有没有遇到过这种情况:研发部门天天喊许可证不够用,采购那边一年几百万的软件授权费还在往上涨,结果你一查,发现有人开着一个几万块的CAD软件,人已经去开了一个小时的会。钱就这么白白烧掉了。我今年专门把这行摸了一…...

深度解析EdiZon:Switch游戏存档管理与内存编辑的进阶实战指南
深度解析EdiZon:Switch游戏存档管理与内存编辑的进阶实战指南 【免费下载链接】EdiZon 💡 A homebrew save management, editing tool and memory trainer for Horizon (Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/ed/EdiZon 在…...

Win11Debloat终极指南:快速清理Windows系统臃肿的完整教程
Win11Debloat终极指南:快速清理Windows系统臃肿的完整教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...