摩尔线程 国产显卡 MUSA 并行编程 学习笔记-2024/12/04
Learning Roadmap:
Section 1: Intro to Parallel Programming & MUSA
- Deep Learning Ecosystem(摩尔线程 国产显卡 MUSA 并行编程 学习笔记-2024/11/30-CSDN博客)
- Ubuntu+Driver+Toolkit+conda+pytorch+torch_musa环境安装(2024/11/24-Ubuntu Windows双系统安装 | 2024/11/30-GPU驱动&MUSA Toolkit安装)
- C/C++ Review(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/22-CSDN博客)
- GPU intros(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/25-CSDN博客)
- GPU硬件架构 (摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/26-CSDN博客)
- Write First Kernels (Here) (2024/11/27-线程层级 | 2024/11/28-First MUSA Kernel to Count Thread | 2024/12/02-向量相加 | 2024/12/03-向量相加(3D))
- MUSA API
- Faster Matrix Multiplication
- Triton
- Pytorch Extensions(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/21-CSDN博客)
- MNIST Multilayer Perceptron
Section 2: Parallel Programming & MUSA in Depth
- Analyzing Parallel Program Performance on a Quad-Core CPU
- Scheduling Task Graphs on a Multi-Core CPU
- A Simple Renderer in MUSA
- Optimizing DNN Performance on DNN Accelerator Hardware
- llm.c
Ref:摩尔学院 | High-Performance Computing with GPUs | Stanford CS149 - Video | Stanford CS149 - Syllabus
Kernel to Multiply Matrix
Ref: High-Performance Computing with GPUs Chapter 5 | 摩尔学院 - MUSA基础
下面的代码将用CPU与GPU分别对两个矩阵(Matrix A: 256 * 512, Matrix B: 512 * 256)进行相乘,并计算对应的平均耗时
代码地址
MUSA PLAY GROUND - Github
代码
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <musa_runtime.h>#define M 256 // Number of rows in A and C
#define K 512 // Number of columns in A and rows in B
#define N 256 // Number of columns in B and C
#define BLOCK_SIZE 32// Example 3x2 @ 2x4 = 3x4 -> (M x K) @ (K x N) = (M x N)
// A = [[1, 2],
// [3, 4],
// [5, 6]]// B = [[7, 8, 9, 10],
// [11, 12, 13, 14]]// C = A * B = [[1*7 + 2*11, 1*8 + 2*12, 1*9 + 2*13, 1*10 + 2*14],
// [3*7 + 4*11, 3*8 + 4*12, 3*9 + 4*13, 3*10 + 4*14],
// [5*7 + 6*11, 5*8 + 6*12, 5*9 + 6*13, 5*10 + 6*14]]// C = [[29, 32, 35, 38],
// [65, 72, 79, 86],
// [101, 112, 123, 134]]// CPU matrix multiplication
void matmul_cpu(float *A, float *B, float *C, int m, int k, int n) {for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {float sum = 0.0f;for (int l = 0; l < k; l++) {sum += A[i * k + l] * B[l * n + j];}C[i * n + j] = sum;}}
}// MUSA kernel for matrix multiplication
__global__ void matmul_gpu(float *A, float *B, float *C, int m, int k, int n) {int row = blockIdx.y * blockDim.y + threadIdx.y;int col = blockIdx.x * blockDim.x + threadIdx.x;if (row < m && col < n) {float sum = 0.0f;for (int l = 0; l < k; l++) {sum += A[row * k + l] * B[l * n + col];}C[row * n + col] = sum;}
}// Initialize matrix with random values
void init_matrix(float *mat, int rows, int cols) {for (int i = 0; i < rows * cols; i++) {mat[i] = (float)rand() / RAND_MAX;}
}// Function to measure execution time
double get_time() {struct timespec ts;clock_gettime(CLOCK_MONOTONIC, &ts);return ts.tv_sec + ts.tv_nsec * 1e-9;
}int main() {float *h_A, *h_B, *h_C_cpu, *h_C_gpu;float *d_A, *d_B, *d_C;int size_A = M * K * sizeof(float);int size_B = K * N * sizeof(float);int size_C = M * N * sizeof(float);// Allocate host memoryh_A = (float*)malloc(size_A);h_B = (float*)malloc(size_B);h_C_cpu = (float*)malloc(size_C);h_C_gpu = (float*)malloc(size_C);// Initialize matricessrand(time(NULL));init_matrix(h_A, M, K);init_matrix(h_B, K, N);// Allocate device memorymusaMalloc(&d_A, size_A);musaMalloc(&d_B, size_B);musaMalloc(&d_C, size_C);// Copy data to devicemusaMemcpy(d_A, h_A, size_A, musaMemcpyHostToDevice);musaMemcpy(d_B, h_B, size_B, musaMemcpyHostToDevice);// Define grid and block dimensionsdim3 blockDim(BLOCK_SIZE, BLOCK_SIZE);dim3 gridDim((N + BLOCK_SIZE - 1) / BLOCK_SIZE, (M + BLOCK_SIZE - 1) / BLOCK_SIZE);// Warm-up runsprintf("Performing warm-up runs...\n");for (int i = 0; i < 3; i++) {matmul_cpu(h_A, h_B, h_C_cpu, M, K, N);matmul_gpu<<<gridDim, blockDim>>>(d_A, d_B, d_C, M, K, N);musaDeviceSynchronize();}// Benchmark CPU implementationprintf("Benchmarking CPU implementation...\n");double cpu_total_time = 0.0;for (int i = 0; i < 20; i++) {double start_time = get_time();matmul_cpu(h_A, h_B, h_C_cpu, M, K, N);double end_time = get_time();cpu_total_time += end_time - start_time;}double cpu_avg_time = cpu_total_time / 20.0;// Benchmark GPU implementationprintf("Benchmarking GPU implementation...\n");double gpu_total_time = 0.0;for (int i = 0; i < 20; i++) {double start_time = get_time();matmul_gpu<<<gridDim, blockDim>>>(d_A, d_B, d_C, M, K, N);musaDeviceSynchronize();double end_time = get_time();gpu_total_time += end_time - start_time;}double gpu_avg_time = gpu_total_time / 20.0;// Print resultsprintf("CPU average time: %f microseconds\n", (cpu_avg_time * 1e6f));printf("GPU average time: %f microseconds\n", (gpu_avg_time * 1e6f));printf("Speedup: %fx\n", cpu_avg_time / gpu_avg_time);// Free memoryfree(h_A);free(h_B);free(h_C_cpu);free(h_C_gpu);musaFree(d_A);musaFree(d_B);musaFree(d_C);return 0;
}编译
mcc '02 matmul.mu' -o matmul -mtgpu -O2 -lmusart./matmul输出结果
如图所示,GPU提速明显

Notes
同步函数
musaDeviceSynchronize()
确保kernel相关的任务都执行完毕。执行完成后方可安全的执行下一个kernel
__syncthreads()
用途:在同一个block内,同步所有线程的执行。在线程块内所有线程到达此命令前,所有线程都不会执行其后的指令
典型用例:当有多个线程要访问SharedMemory的同一地址,而这个地址存储的值被修改,则需要用__syncthreads同步
注意事项:调用_syncthreads时,必须保证block内所有线程都会调用到这个函数,否则会出错
相关文章:
摩尔线程 国产显卡 MUSA 并行编程 学习笔记-2024/12/04
Learning Roadmap: Section 1: Intro to Parallel Programming & MUSA Deep Learning Ecosystem(摩尔线程 国产显卡 MUSA 并行编程 学习笔记-2024/11/30-CSDN博客)UbuntuDriverToolkitcondapytorchtorch_musa环境安装(2024/11/24-Ubunt…...

【FAQ】HarmonyOS SDK 闭源开放能力 —Remote Communication Kit
1.问题描述: DynamicDnsRule有没有示例?这个地址是怎么解析出来 https://developer.huawei.com/consumer/cn/doc/harmonyos-references/remote-communication-rcp-0000001770911890#section8160554134811 解决方案: ‘DynamicDnsRule’&a…...

【日常记录-Mybatis】PageHelper导致语句截断
1. 简介 PageHelper是Mybatis-Plus中的一个插件,主要用于实现数据库的分页查询功能。其核心原理是将传入的页码和条数赋值给一个Page对象,并保存到本地线程ThreadLocal中,接下来,PageHelper会进入Mybatis的拦截器环节,…...

随时随地掌控数据:如何使用手机APP远程访问飞牛云NAS
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

JVM 类加载器有哪些?双亲委派机制的作用是什么?如何自定义类加载器?
类加载器分类 大家好,我是码哥,可以叫我靓仔,《Redis 高手心法》畅销书作者。 先回顾下,在 Java 中,类的初始化分为几个阶段: 加载、链接(包括验证、准备和解析)和 初始化。 而 类加载器&#x…...
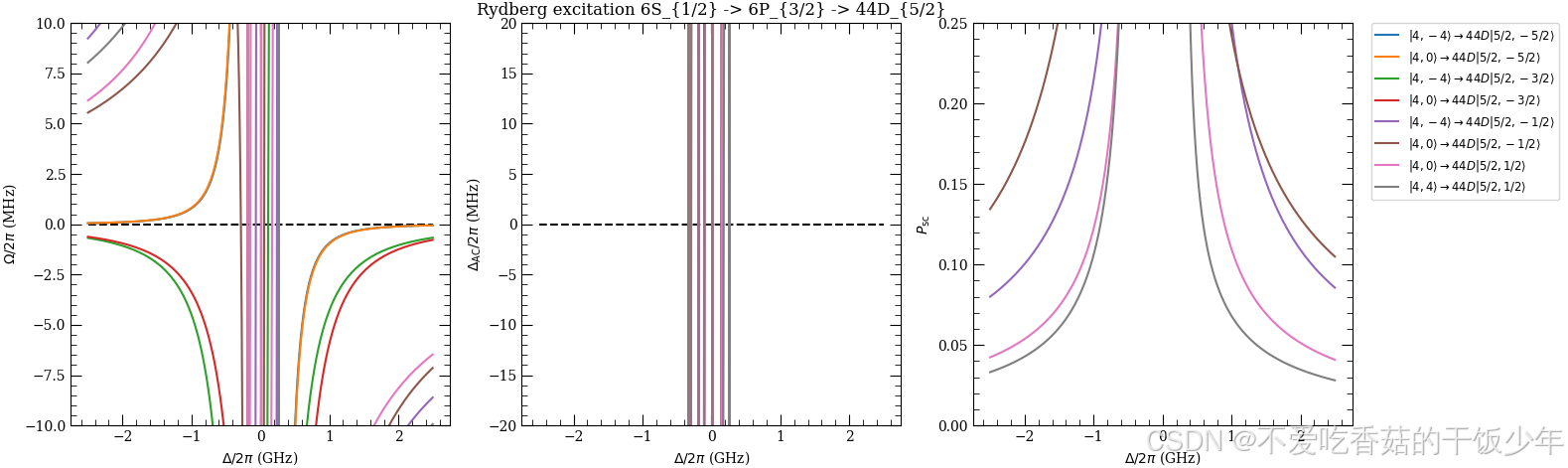
从基态到激发态再到里德伯态的双光子激发过程
铯原子(Cs)从基态6S1/2到激发态6P3/2再到里德伯态44D5/2的双光子激发过程, 并通过数值计算和图形化展示来研究不同失谐条件下的拉比频率、AC Stark位移差以及散射概率的变化 结果显示,在给定的实验参数下,拉比频率较低…...

Clickhouse 外部存储引擎
文章目录 外部存储引擎分类MySQL引擎PostgreSQL引擎MongoDB引擎JDBC引擎ODBC引擎Kafka引擎RabbitMQ引擎File引擎URL引擎HDFS引擎 外部存储引擎分类 引擎类型描述特点MySQL从 MySQL 数据库中读取数据用于与 MySQL 数据库共享数据,支持读取 MySQL 表中的数据 支持 SQ…...

eclipse怎么配置jdk路径?
在Eclipse中配置JDK路径是一个简单的步骤,以下是配置JDK路径的步骤: 打开Eclipse:启动Eclipse IDE。 访问首选项: 在Eclipse的菜单栏中,选择 Window > Preferences(对于Mac OS X用户,选择 E…...

【前端】JavaScript 中的创建对象模式要点
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: 前端 文章目录 💯前言💯对象属性值中的引号规则💯对象属性换行与尾随逗号的使用💯工厂模式:灵活高效的对象创建💯自定义构造函数:通过…...

GWAS分析先做后学
大家好,我是邓飞。 GWAS分析是生物信息和统计学的交叉学科,上可以学习编程,下可以学习统计。对于Linux系统,R语言,作图,统计学,机器学习等方向,都是一个极好的入门项目。生物信息如…...

【系统设计】高可用之缓存基础
缓存的缘起 使用缓存的主要原因包括提高系统性能、降低数据库负载、提升用户体验和保证系统可用性。 在计算机体系结构中,由于处理器和存储器的处理时间不匹配,在处理器和一个较大较慢的设备之间插入一个更小更快的存储设备(如高速缓存&a…...

《Java核心技术I》volatile字段
volatile字段 有多处理器的计算机能够暂时在寄存器或本地内存缓存中保存内存值,其结果是,运行在不同处理器上的线程可能看到同一个内存位置上有不同的值。编译器可以改变指令执行的顺序以使吞吐量更大化,编译器不会选择可能改变代码语义的顺…...

2024运维故障记 | 12/2 网易云音乐崩了
#运维故障记# 前两天看到网易云音乐崩了的新闻,回想了一下,今年从网易云音乐到支付宝、还有微软,近期就发生了好几起运维届的故障。 今年来不及计数了,先做个记录。 明年看看运维届的大故障会发生多少,什么原因&…...

架构设计读后——微服务
1 微服务历史 2005年:Dr. Peter Rodgers提出"Micro-Web-Services"概念2011年:一个软件架构工作组使用"microservice"来描述一中架构模式2012年;这个工作组正式使用"microservice"来代表这个架构2012年&#x…...

软考高级架构-9.4.4-双机热备技术 与 服务器集群技术
一、双机热备 1、特点: 软硬件结合:系统由两台服务器(主机和备机)、一个共享存储(通常为磁盘阵列柜)、以及双机热备软件(提供心跳检测、故障转移和资源管理功能的核心软件)组成。 …...

聊聊前端工程化
深度解析前端工程化 近年来,随着前端技术的快速迭代和项目复杂度的增加,前端开发已经从简单的页面搭建演变为专业的工程化体系。前端工程化通过工具链、标准化和流程化手段,不仅提高了开发效率,也大幅提升了项目的可维护性和协…...

“放弃Redis Desktop Manager使用Redis Insight”:日常使用教程(Redis可视化工具)
文章目录 更新Redis Insight连接页面基础解释自动更新key汉化暂时没有找到方法, Redis Desktop Manager在连接上右键在数据库上右键在key上右键1、添加连接2、key过期时间 参考文章 更新 (TωT)ノ~~~ βyё βyё~ 现在在维护另一…...

mmdection配置-yolo转coco
基础配置看我的mmsegmentation。 也可以参考b站 :https://www.bilibili.com/video/BV1xA4m1c7H8/?vd_source701421543dabde010814d3f9ea6917f6#reply248829735200 这里面最大的坑就是配置coco数据集。我一般是用yolo,这个yolo转coco格式很难搞定&#…...

聚合支付系统/官方个人免签系统/三方支付系统稳定安全高并发 附教程
聚合支付系统/官方个人免签系统/三方支付系统稳定安全高并发 附教程 系统采用FastAdmin框架独立全新开发,安全稳定,系统支持代理、商户、码商等业务逻辑。 针对最近一些JD,TB等业务定制,子账号业务逻辑API 非常详细,方便内置…...

力扣67. 二进制求和
给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a "11", b "1" 输出:"100" 示例 2: 输入:a "1010", b "1011" 输出&#…...
)
别急着加内存!PyTorch报错‘DefaultCPUAllocator: not enough memory’的另类解法(附一键修复脚本)
别急着加内存!PyTorch报错‘DefaultCPUAllocator: not enough memory’的另类解法 当你看到PyTorch抛出RuntimeError: DefaultCPUAllocator: not enough memory时,第一反应可能是检查任务管理器——然后发现物理内存明明还剩大半,这个报错就显…...

【权威实测】Perplexity vs PubMed vs Scite:在结构生物学领域,它为何将文献召回率提升68%?
更多请点击: https://codechina.net 第一章:Perplexity生物知识搜索 Perplexity 是一款以实时网络检索与引用溯源为核心能力的 AI 搜索工具,其在生命科学领域的应用正迅速拓展。不同于传统大模型依赖静态训练数据,Perplexity 在执…...

高级音频解密技术实现:ncmdump模块化架构解析与自动化工作流
高级音频解密技术实现:ncmdump模块化架构解析与自动化工作流 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐版权保护日益严格的今天,网易云音乐的NCM加密格式为用户带来了设备兼容性的技术挑战。n…...

勒索病毒防线与数据恢复能力:四家云厂商安全水位线横向测评
对于制造业等行业的内部核心业务(MES、WMS、ERP、HIS等)上云,深信服托管云凭借其“资源专属全栈托管主动服务”三位一体的模式,在业务连续性保障、就近部署低时延以及贴身服务响应等方面,表现出比主流公有云方案更强的…...

Python点云数据处理避坑指南:pypcd与pypcd4库在Ubuntu下的安装与实战对比
Python点云数据处理避坑指南:pypcd与pypcd4库在Ubuntu下的安装与实战对比 在3D视觉、自动驾驶和机器人开发领域,点云数据处理是基础而关键的环节。Ubuntu作为主流的开发环境,配合Python生态中的pypcd和pypcd4库,为工程师提供了高…...

数科OFD阅读历史清理全攻略:统信UOS/麒麟KYLINOS下图形界面与命令行两种方法实测
数科OFD阅读历史清理全攻略:统信UOS/麒麟KYLINOS下图形界面与命令行两种方法实测 在国产化办公环境中,数科OFD作为主流的版式文档阅读工具,其使用痕迹管理常被忽视却至关重要。无论是个人用户希望保护阅读隐私,还是企业IT管理员需…...

从IMC层到应力点:手把手教你用SEM/EDS给BGA焊点做一次‘体检’
从IMC层到应力点:手把手教你用SEM/EDS给BGA焊点做一次‘体检’ 当一块电路板上的BGA焊点出现异常时,往往就像人体某个关节出了问题——表面看不出明显伤痕,但功能已经受限。这时候,我们需要像医生一样,用专业设备给焊…...

Taotoken控制台提供的API Key管理与访问控制功能详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台提供的API Key管理与访问控制功能详解 对于团队管理者或项目负责人而言,如何安全、高效地分发和管理大模…...

56、CAN总线RC低通滤波器截止频率计算与实战
CAN总线RC低通滤波器截止频率计算与实战 一、一个让我熬夜三天的CAN通信故障 去年做某车载ECU项目,CAN总线在电机启动瞬间频繁丢帧。示波器抓波形,CAN_H对地毛刺高达8V,持续时间约200ns。团队里有人提议“加磁珠”,有人喊“上共模扼流圈”。我翻出TI的AN-2298应用笔记,发…...

Linux设备模型核心数据结构解析:从kobject到sysfs的驱动开发指南
1. 项目概述:从“黑盒”到“白盒”的设备认知之旅在Linux的世界里,我们每天都在和各种设备打交道:一块硬盘、一张网卡、一个USB摄像头。对于普通用户或应用开发者而言,这些设备可能只是/dev/sda、eth0这样的一个文件节点或接口名。…...