【Linux测试题】
1. 选择题
题目: 如果想将电脑中Windows C盘(hd1)安装在Linux文件系统的/winsys目录下,请问正确的命令是()。
选项:
A. root@104.123.123.123:~# mount dev/hd1 /winsys
B. root@104.123.123.123:~# mount /dev/hd1 /winsys
C. root@104.123.123.123:~# mount /dev/hd1 /winsys/
D. root@104.123.123.123:~# mount /dev/C /winsys
解答:
要将Windows C盘挂载到Linux的/winsys目录下,正确的命令格式应该是:mount /dev/hd1 /winsys。这里需要注意,/dev/hd1是Windows C盘的设备文件,而/winsys是Linux中要挂载的目录。
答案: b
1. mount命令详解
mount是 Linux 中用来将文件系统挂载到某个目录的命令。- 格式:
mount [设备文件] [挂载点]- 设备文件:表示需要挂载的存储设备(比如硬盘分区)。
- 挂载点:表示将设备文件关联到文件系统的目录,访问此目录就等于访问设备内容。
2. 选项中命令的详细拆解
- 命令:
mount /dev/hdal /winsys/dev/hdal:/dev/是 Linux 中的设备文件路径,所有硬盘设备和分区都以文件形式表示。hda代表主 IDE 接口的第一块硬盘设备。l表示具体的分区号。- 示例:
/dev/hda1代表第一块 IDE 硬盘的第一个分区。
- 示例:
- 题目中写作
hdal,可视为一个通用占位符,指代 Windows 系统所在的硬盘分区。
/winsys:- Linux 系统的目录路径,挂载点必须是一个已存在的目录。
- 挂载后,访问
/winsys实际上访问的是C:盘内容。
3. 关于“Windows C:盘 (hdal)”
- C:盘:
- 在 Windows 系统中,C:盘通常是系统盘,存储操作系统和相关文件。
- (hdal):
- 题目用
(hdal)表示一个 Linux 下的设备文件。 - 这里暗示的是 Windows 的 C:盘(系统盘)在 Linux 中的设备文件路径,比如
/dev/sda1(SATA硬盘)或/dev/nvme0n1p1(NVMe固态硬盘)。
- 题目用
- 作用:
- 通过挂载命令,可以从 Linux 系统直接访问 Windows 文件系统。
4. 实际应用场景
- 使用此命令时,需确保:
hdal的文件系统类型(如 NTFS)已安装相应的支持工具(比如ntfs-3g)。- 挂载点
/winsys已创建(通过mkdir /winsys)。
5. 完整示例
假设 Windows 系统分区是 /dev/sda1,挂载命令如下:
mount /dev/sda1 /winsys
如果分区是 NTFS 文件系统,可以用以下方式:
mount -t ntfs /dev/sda1 /winsys
或:
ntfs-3g /dev/sda1 /winsys
在 Linux 系统中,能够访问 Windows 的 C:盘,是因为 Linux 提供了对多种文件系统的支持,包括 Windows 常用的 NTFS 文件系统。以下从基本原理到命令细节逐步解答你的问题。
1. 为什么 Linux 能识别和挂载 Windows 的 C:盘?
a) 硬件统一接口
- 在计算机中,硬盘上的数据是独立于操作系统的。无论是 Windows 还是 Linux,它们都使用相同的硬盘分区格式(如 MBR 或 GPT)。
- Linux 将所有设备(包括硬盘)抽象成特殊的文件,保存在
/dev目录下,比如/dev/sda1或/dev/hd1。
b) 文件系统支持
- Windows 使用 NTFS 或 FAT32 文件系统。
- Linux 通过内核模块和工具(如
ntfs-3g)支持读取和写入这些文件系统。 - 这使得在 Linux 下访问 Windows 的 C:盘成为可能。
c) 挂载概念
- Linux 的文件系统是统一的树形结构,通过挂载点(如
/winsys)将其他存储设备(包括 Windows 的 C:盘)整合进来。 - 挂载后,用户在 Linux 系统中访问
/winsys,实际上是在访问 Windows 的 C:盘。
2. mount /dev/hd1 /winsys 命令每个字符的意义
示例命令:
mount /dev/hd1 /winsys
各部分详解:
-
mount:- Linux 的挂载命令,用于将设备文件(如硬盘分区)挂载到某个目录。
- 语法格式:
mount [设备文件] [挂载点]
-
/dev/hd1:/dev/:- 系统的设备文件目录,包含所有硬件设备(如硬盘、键盘、鼠标等)的表示形式。
hd1:- 硬盘设备文件:
hd表示硬盘设备。1可能是硬盘的第一个分区(或整块硬盘,视上下文而定)。- 实际上,现代 Linux 更常用
/dev/sdX(SATA 硬盘)或/dev/nvmeXn1pX(NVMe 硬盘)命名。
- 硬盘设备文件:
-
/winsys:- 挂载点:
- 指定一个已存在的目录作为挂载点,访问此目录就等同于访问挂载的设备内容。
- 挂载点必须在命令执行前创建(如
mkdir /winsys)。
- 挂载点:
完整执行流程:
- Linux 检查设备
/dev/hd1是否存在。 - Linux 确认
/winsys是否为一个有效目录。 - 如果
/dev/hd1文件系统兼容,系统会将它的内容映射到/winsys下。
3. 为什么说“Windows C:盘”会出现在 Linux 系统中?
a) 双系统场景
- 如果一台计算机安装了 Windows 和 Linux 双系统:
- Windows 的 C:盘是实际存在的一个硬盘分区。
- 在 Linux 中,这个分区以设备文件(如
/dev/sda1)的形式存在。 - Linux 用户可以通过
mount命令访问这个分区。
b) 网络存储场景
- 在某些云或虚拟化环境中,Linux 系统可能会通过网络文件系统(如 SMB 或 CIFS)访问 Windows 共享资源。
- 从用户角度看,这个网络挂载可以被理解为 Windows 的 C:盘。
4. 扩展命令说明
a) mount 添加文件系统类型
如果设备的文件系统需要指定类型,可以使用 -t 参数:
mount -t ntfs /dev/hd1 /winsys
-t ntfs:指定挂载的是 NTFS 文件系统。
b) 使用 ntfs-3g
NTFS 是 Windows 的专用文件系统,需要 ntfs-3g 工具实现完全的读写支持:
ntfs-3g /dev/hd1 /winsys
c) 自动挂载
为了在系统启动时自动挂载,可以在 /etc/fstab 文件中添加条目:
/dev/hd1 /winsys ntfs defaults 0 0
总结
- **Linux 和 Windows 的文件系统并不是互相隔绝的。**通过 Linux 的挂载机制,Windows 的硬盘分区(如 C:盘)可以直接被访问。
- 命令详解:
mount:挂载设备。/dev/hd1:表示 Windows C:盘的设备文件(实际路径需根据环境调整)。/winsys:Linux 系统中的挂载点。
- Linux 对其他文件系统的兼容性让其非常灵活,可以跨系统访问存储资源。
在 Linux 系统中,root@104.123.123.123:~# 是一个命令提示符(prompt),用于告诉用户当前的会话信息和环境。以下是它每一部分的含义:
1. root
-
意义:
- 当前登录的用户是
root用户。 root是 Linux 中的超级用户(管理员用户),拥有对系统的最高权限。- 在 Linux 系统中,不同用户的权限不同,这部分表示当前用户的身份。
- 当前登录的用户是
-
相关扩展:
- 如果是普通用户,提示符可能会显示用户名称,比如
user1。 - 用
whoami命令可以查看当前用户:whoami
- 如果是普通用户,提示符可能会显示用户名称,比如
2. @
- 意义:
- 分隔符,将当前登录用户和主机名称或 IP 地址分开。
- 格式:
[当前用户]@[主机名或 IP 地址]。
3. 104.123.123.123
-
意义:
- 当前会话连接的主机的 主机名 或 IP 地址。
- 在本例中,是一个 IPv4 地址(104.123.123.123),表明用户通过网络登录到这个主机。
-
可能的替代:
- 主机名(如
server1):- 如果主机名已被配置,提示符中可能显示主机名而非 IP 地址。
- 配置文件
/etc/hostname决定主机名。
- 本地机器:
- 如果直接在本地机器操作,这部分可能显示为
localhost或主机名。
- 如果直接在本地机器操作,这部分可能显示为
- 主机名(如
4. :
- 意义:
- 分隔符,将用户与主机的信息部分和后续的目录路径部分分开。
5. ~
-
意义:
- 表示当前所在的工作目录。
~是 home 目录 的简写:- 对于
root用户,~通常代表/root。 - 对于普通用户,
~通常代表/home/username。
- 对于
-
工作目录的变化:
- 如果切换目录(如
cd /etc),这里会显示具体路径:root@104.123.123.123:/etc#
- 如果切换目录(如
6. #
- 意义:
- 命令提示符的标志,表示当前用户的权限级别:
#:超级用户(root 用户)。$:普通用户。
- 命令提示符的标志,表示当前用户的权限级别:
7. 扩展:提示符的自定义
提示符通常可以通过环境变量 PS1 自定义,比如:
-
默认结构:
PS1='\u@\h:\w\$ '\u:当前用户。\h:主机名。\w:当前目录路径。\$:#或$,根据权限显示。
-
示例:
- 修改提示符为简单模式:
结果:PS1='\w\$ '/etc$
- 修改提示符为简单模式:
示例分解:
完整提示符:
root@104.123.123.123:~#
分解含义:
| 部分 | 含义 |
|---|---|
root | 当前登录用户是超级用户 root |
@ | 分隔符 |
104.123.123.123 | 当前登录主机的 IP 地址 |
: | 分隔符 |
~ | 当前所在的 home 目录 |
# | 提示符,表示超级用户身份 |
总结:
root@104.123.123.123:~# 代表:
- 用户:
root(超级用户)。 - 登录主机:IP 地址为
104.123.123.123。 - 当前目录:用户的 home 目录(
~)。 - 权限:
#表示超级用户(相对于普通用户的$)。
2. 选择题
题目: 下列关于任务上下文切换的描述中,不正确的是()。
选项:
A. 任务上下文是任务控制块(TCB)的组成部分
B. 上下文切换由一个特殊的任务完成
C. 上下文切换时间是影响RTOS性能的重要指标
D. 上下文切换由RTOS内部完成
解答:
- A项:任务上下文是任务控制块(TCB)的组成部分,这是正确的,因为TCB包含了任务的所有相关信息,包括上下文。
- B项:上下文切换通常由操作系统的内核完成,而不是由一个特殊的任务完成。
- C项:上下文切换时间确实是影响实时操作系统(RTOS)性能的重要指标。
- D项:上下文切换是由操作系统(包括RTOS)内部完成的,这是正确的。
答案: B
什么是上下文切换?
上下文切换是计算机中一个技术概念,用简单的话来说,它是操作系统用来“换人干活”的方法。以下是一步步的解释:
1. 操作系统运行多个任务
假设你的电脑或设备正在同时运行多个任务,比如:
- 播放音乐(任务A)。
- 打开一个文档编辑器(任务B)。
- 运行一个下载软件(任务C)。
由于计算机的 CPU(中央处理器)只能在同一时刻执行一个任务,操作系统需要快速地在这些任务之间切换,给每个任务一点时间让它运行。这样,用户就感觉多个任务是在同时进行的。
2. 上下文是每个任务的“状态”
“上下文”指的就是每个任务在 CPU 中的状态,包括:
- 当前运行到哪了(程序计数器)。
- 用的数据是什么(寄存器内容、内存地址等)。
- 正在使用的资源(比如打开的文件、网络连接等)。
上下文就像任务的“记忆”,告诉 CPU “这个任务的工作停在哪了,等会儿继续从这里开始”。
3. 上下文切换是什么?
上下文切换是指操作系统把当前任务的状态保存下来,然后切换到另一个任务,恢复那个任务的状态,让它继续运行。
比如:
- 任务A暂停时,系统记下“任务A运行到第10行代码,寄存器值是多少,打开了哪些文件”。
- 切换到任务B,系统加载“任务B停在第20行代码,用了哪些数据”。
解答问题:
题目问的是上下文切换的“不正确描述”,我们逐项分析:
A. 任务上下文是任务控制块(TCB)的组成部分
- 正确。
- 每个任务的状态(上下文)都被存储在任务控制块(Task Control Block, TCB)中,方便系统管理。
B. 上下文切换由一个特殊的任务完成
- 不正确。
- 上下文切换并不是由一个特殊任务完成的,而是由操作系统内核根据优先级或时间片等规则动态完成的。
C. 上下文切换时间是影响 RTOS 性能的重要指标
- 正确。
- 实时操作系统(RTOS)的性能很大程度上取决于上下文切换的快慢,因为切换慢会浪费时间。
D. 上下文切换由 RTOS 内部完成
- 正确。
- 上下文切换是由操作系统(比如 RTOS)的内核负责的。
答案:
B. 上下文切换由一个特殊的任务完成
总结:
上下文切换是操作系统让多个任务“轮流工作”的关键技术,具体工作由操作系统内核完成,不需要特殊任务。
好的!我们再通俗地拆解一下,帮助你理解。
什么是“特殊任务”?
特殊任务指的是一个专门的任务,专门负责执行某种特定工作。
比如,你可能想象成有一个专门的“小助手”,负责在任务之间来回切换。
但实际上,上下文切换不是由一个“特殊任务”完成的,而是操作系统本身就有这个功能。
那么,实际是怎么完成的呢?
操作系统的内核(核心部分)就像一个“管理者”,它会:
- 决定谁先运行:比如哪个任务更重要(优先级高)或者哪个任务已经运行了太久,需要换下。
- 保存当前任务的状态:比如它运行到哪儿了,用了哪些数据。
- 恢复另一个任务的状态:把另一个任务的“记忆”加载回来,让它接着运行。
这个切换过程是自动发生的,由操作系统内核负责,而不是一个特定的任务去做的。
为什么不是“特殊任务”完成的?
如果上下文切换依赖于某个“特殊任务”,那就会出现矛盾:
- 切换任务本身也需要切换(因为它也是任务)。
- 这样就形成了一个“无限循环”问题。
所以,上下文切换是内核的一个功能,而不是专门由某个“特殊任务”来完成。
举个生活例子:
-
误解的场景(错误描述):
假如你是个老师,班里有3个学生(任务)。有人以为会有一个专门的“助手”来告诉你该叫哪个学生回答问题。
但是这个“助手”自己也是学生,可能也需要被管理,那么就没法高效切换了。 -
实际的场景(正确描述):
老师(内核)自己决定叫谁回答问题,同时记住上一个学生回答到哪里了,这样就能高效安排每个人的任务。老师不需要依赖任何一个学生来决定。
总结一下:
“上下文切换”是操作系统内核的一个功能,它根据规则(比如任务优先级)自动切换任务,而不是由某个单独的任务来负责完成切换。
3. 选择题
题目: 大端存储方式各有其特点,下面描述不正确的是()。
选项:
A. 大端存储中,数据的最高字节存储在低字节地址中
B. 小端存储中,数据的最高字节存储在高字节地址中
C. 80X86处理器采用大端或小端的存储方式,可以通过硬件输入引脚配置
D. 80X86处理器的存储方式是小端存储格式
解答:
- A项:大端存储中,数据的最高字节存储在低字节地址中,这是正确的。
- B项:小端存储中,数据的最高字节存储在高字节地址中,这也是正确的。
- C项:80X86处理器采用小端存储方式,而不是大端存储方式,所以不能通过硬件输入引脚配置为大端存储方式。
- D项:80X86处理器的存储方式确实是小端存储格式。
答案: C
这道题目涉及到大端存储(Big-Endian)和小端存储(Little-Endian)的概念。下面我会先用通俗的语言解释这些概念,再一一分析选项并给出正确答案。
什么是大端存储和小端存储?
在计算机中,数据是以字节(byte)为单位存储的。假设有一个多字节的数据(比如一个4字节的整数 0x12345678),存储时每个字节都需要一个地址。那么,这些字节的排列顺序可能有两种方式:
1. 大端存储方式(Big-Endian)
- 特点:高位字节存储在低地址,低位字节存储在高地址。
- 示例:
数据:0x12345678 地址:0x100 0x101 0x102 0x103 存储:0x12 0x34 0x56 0x78
2. 小端存储方式(Little-Endian)
- 特点:低位字节存储在低地址,高位字节存储在高地址。
- 示例:
数据:0x12345678 地址:0x100 0x101 0x102 0x103 存储:0x78 0x56 0x34 0x12
3. 区别总结
- 大端存储:从“左到右”排列,高位字节优先。
- 小端存储:从“右到左”排列,低位字节优先。
分析选项
A. 大端存储中,数据的最高字节存储在低字节地址中
- 正确。
- 大端存储的特点就是高位字节存储在低地址,符合定义。
B. 小端存储中,数据的最高字节存储在高字节地址中
- 正确。
- 小端存储的特点就是低位字节存储在低地址,因此最高字节自然会存储在高地址。
C. 80X86处理器采用大端或小端的存储方式,可以通过硬件输入引脚配置
- 不正确。
- 80x86(即 x86 架构的处理器)只能使用小端存储,不支持通过硬件配置为大端存储。
D. 80X86处理器的存储方式是小端存储格式
- 正确。
- x86 架构处理器使用的是小端存储格式。
正确答案
C. 80X86处理器采用大端或小端的存储方式,可以通过硬件输入引脚配置
为什么是 C?
- x86 架构固定使用小端存储,没有大端存储的选项。
- 硬件输入引脚不能改变存储方式,这种说法是错误的。
进一步说明
其他一些处理器(如 PowerPC、ARM)可能支持同时使用大端或小端存储方式,并允许通过配置选择。但 x86 处理器的设计是固定的,因此选项 C 是错误的描述。
关于使用大端存储还是小端存储,其实没有绝对的规律,而是与历史背景、硬件设计和应用场景相关。下面从实际应用角度总结它们的常见用途和特点:
1. 大端存储(Big-Endian)常见的情况
大端存储的特点是:高位字节优先存储在低地址,这种方式与人类的书写习惯更接近(从左到右)。因此,在一些特定场景中,它更为自然。
使用场景:
-
网络通信(网络字节序)
- 在网络协议(如 TCP/IP)中,数据传输使用的就是大端存储方式,称为网络字节序。
- 这是因为在协议设计之初,通信设备大多采用大端存储,大端序便成了标准。
-
嵌入式系统和部分处理器
- 一些大端架构的处理器(如早期的 PowerPC、SPARC)设计为大端存储。
- 在多平台设备中,如果数据需要与大端架构的设备兼容,大端存储可能是更好的选择。
-
文件格式和跨平台标准
- 一些数据格式(如 JPEG 图像、某些音频格式)采用大端序,因为在设计时需要考虑跨平台兼容性。
2. 小端存储(Little-Endian)常见的情况
小端存储的特点是:低位字节优先存储在低地址,更符合计算机中处理器的运行逻辑(从低地址开始读取数据)。
使用场景:
-
x86 及相关处理器架构
- x86 架构的处理器(Intel、AMD)使用小端存储,这使得在 PC 平台上,几乎所有的软件和系统默认使用小端存储。
-
内存访问效率更高
- 小端存储使得处理器在读取小数值时更加高效:
- 比如,一个 32 位的数值存储在内存中时,如果只需要读取低 8 位(1 字节),小端存储可以直接从低地址读取,不需要额外操作。
- 小端存储使得处理器在读取小数值时更加高效:
-
嵌入式系统中的通用平台
- 许多嵌入式设备使用 ARM 处理器,ARM 处理器在默认配置下通常也是小端存储(虽然 ARM 支持两种存储方式)。
3. 如何选择大端还是小端?
选择依据:
-
平台和架构:
- 如果使用的是 x86 或默认小端的架构(如 ARM),小端存储是标准。
- 如果使用大端架构的处理器(如部分 PowerPC),则使用大端。
-
协议和数据传输:
- 网络通信或需要与网络协议兼容时,使用大端存储(网络字节序)。
-
跨平台兼容性:
- 在设计跨平台数据格式时,通常优先考虑大端存储,因为它的排列方式更直观。
-
性能需求:
- 如果对性能要求较高,小端存储可能更合适,特别是与小端架构配合时。
4. 总结规律
| 存储方式 | 使用场景/特点 |
|---|---|
| 大端存储 | 网络通信、跨平台文件格式、早期嵌入式系统,强调跨平台兼容性和直观性。 |
| 小端存储 | x86 及 ARM 默认架构、内存读取高效场景,特别是在低地址优先访问的系统中。 |
实际开发中的注意事项
-
转换工具:
- 在编程中,常需要在大端和小端之间转换(如处理网络数据时)。函数如
htonl(host to network long)和ntohl(network to host long)用于完成这种转换。
- 在编程中,常需要在大端和小端之间转换(如处理网络数据时)。函数如
-
检查存储方式:
- 确认当前处理器使用的是哪种存储方式,可以通过代码测试:
int num = 1; if (*(char *)&num == 1) {printf("Little-Endian\n"); } else {printf("Big-Endian\n"); }
- 确认当前处理器使用的是哪种存储方式,可以通过代码测试:
总之,大端更通用,小端更高效,两者的选择多半取决于历史和环境。
4. 选择题
题目: 关于BootLoader,下列理解错误的是()。
选项:
A. BootLoader是在操作系统内核运行之前运行的一小段程序
B. BootLoader是通用的
C. 有些BootLoader支持多CPU
D. BootLoader的功能之一是初始化硬件
解答:
- A项:BootLoader是在操作系统内核运行之前运行的一小段程序,这是正确的。
- B项:BootLoader通常不是通用的,不同的计算机系统可能有不同的BootLoader。
- C项:有些BootLoader确实支持多CPU系统。
- D项:BootLoader的功能之一是初始化硬件,这是正确的。
答案: B
BootLoader 属于以下部分:
各部分的职责总结
| 阶段 | 执行位置 | 角色 | 是否属于 BootLoader |
|---|---|---|---|
| ROM Code (BROM) | ROM | 加载 BootLoader 的第一阶段(如 SPL)。 | 否 |
| SPL | SRAM | BootLoader 的精简版本,初始化关键硬件,加载完整的 U-Boot Proper。 | 是 |
| U-Boot Proper | LDDR | 完整的 BootLoader,进行更深入的硬件初始化并加载操作系统内核。 | 是 |
| 操作系统内核 | LDDR | 接管系统后,负责所有用户程序和服务的执行。 | 否 |
简化理解
- BootLoader 通常指 SPL + U-Boot Proper。
- 它们的任务是:逐步初始化系统硬件,为操作系统的运行创建稳定环境,并最终将控制权交给内核。
补充说明
-
BROM 不属于 BootLoader:
BROM 是出厂时固化在硬件中的代码,功能固定且无法更改,主要负责加载 BootLoader 的第一部分(如 SPL)。 -
U-Boot 是 BootLoader 的典型代表:
U-Boot 是一种开源的通用 BootLoader,广泛应用于嵌入式系统。 -
BootLoader 是系统启动的桥梁:
它在硬件和操作系统之间起承上启下的作用,确保操作系统能够正确运行。
5. 选择题
题目: 对于两个并发进程,设互斥信号量为mutex,若mutex=1,则()。
选项:
A. 表示没有进程进入临界区
B. 表示有一个进程进入临界区
C. 表示有一个进程进入临界区,另一个进程等待进入
D. 表示有两个进程进入临界区
解答:
在互斥信号量(mutex)中,如果mutex的值为1,表示当前有一个进程已经进入了临界区,而其他进程则需要等待。这是正确的实现互斥的一种方式。
答案: B
6. 选择题
题目: 安装了2GB内存,在其上运行的某支持MMU的32位Linux发行版中,一共运行了X、Y、Z三个进程,下面关于三个内存使用程序的方式,哪个是可行的?
选项:
A. X、Y、Z的虚拟地址空间都映射到0~4G虚拟地址上
B. X在堆上分配总大小为1GB的空间,Y在堆上分配200MB,Z在堆上分配500MB,并且内存映射访问一个1GB的磁盘文件
C. X在堆上分配1GB,Y在堆上分配800MB,Z在堆上分配400MB
D. 以上的访问方式都是可行的
解答:
- A项:所有进程的虚拟地址空间都映射到0~4G虚拟地址上是不可行的,因为这会导致地址空间冲突。
- B项:X、Y、Z进程在堆上分配的内存大小加上磁盘文件映射的大小超过了2GB的物理内存限制,这是不可行的。
- C项:X、Y、Z进程在堆上分配的内存大小总和为1GB + 800MB + 400MB = 2.2GB,超过了2GB的物理内存限制,这是不可行的。但是如果考虑到内存映射和磁盘文件映射,这个选项是可行的。因为磁盘文件映射可以作为虚拟内存的一部分,从而允许进程使用超过物理内存大小的内存。
- D项:并不是所有的访问方式都是可行的,因为物理内存的限制是实际存在的。但是选项C是可行的。
答案: C
7. 选择题
题目: 在Linux平台下,C语言的内存空间分为哪些区域?( )
选项:
A. 堆、栈、代码段、数据段
B. 堆、栈、代码段、数据段、未初始化数据段、初始化数据段
C. 堆、栈、代码段、数据段、未初始化数据段、初始化数据段、共享库代码段
D. 堆、栈、代码段、数据段、未初始化数据段、初始化数据段、共享库代码段、共享库数据段
解答:
在Linux平台下,C语言的内存空间主要分为以下几个区域:
- 堆(heap):用于动态内存分配。
- 栈(stack):用于函数调用时的局部变量存储。
- 代码段(text segment):包含程序的机器码。
- 数据段(data segment):包含已初始化的全局变量和静态变量。
- 未初始化数据段(bss segment):包含未初始化的全局变量和静态变量。
因此,正确的选项是B。
答案: B
8. 选择题
题目: 请问以下五种关于动态库、静态库的说法,哪些是错误的,并说明原因?
选项:
- 动态链接库可以升级而不需要重新编译应用程序。
- 运行时加载动态库会比静态库更快。
- 调用动态库中的函数会比静态库更快。
- 动态库可以节省大量的内存,因为多个应用程序可以使用相同的库。
- 动态链接库可以在运行时显式加载/卸载,这有助于应用程序提供可选功能。
解答:
- 说法1:正确。动态链接库可以升级而不需要重新编译应用程序,因为应用程序在运行时会加载新的动态库版本。
- 说法2:错误。运行时加载动态库通常比静态库更慢,因为需要额外的时间来加载和链接动态库。
- 说法3:错误。调用动态库中的函数通常不会比静态库更快,因为需要额外的时间来解析函数地址。
- 说法4:正确。动态库可以节省大量的内存,因为多个应用程序可以使用相同的库,从而减少内存占用。
- 说法5:正确。动态链接库可以在运行时显式加载/卸载,这有助于应用程序提供可选功能。
答案: 说法2和说法3是错误的。
9. 选择题
题目: 下列关于Linux系统的说法中,正确的是( )。
选项:
A. Linux系统使用虚拟内存来管理物理内存,以提高内存利用率。
B. Linux系统使用分页机制来管理内存,以实现内存保护和地址映射。
C. Linux系统使用分段机制来管理内存,以实现内存保护和地址映射。
D. Linux系统使用分页和分段机制来管理内存,以实现内存保护和地址映射。
解答:
Linux系统使用虚拟内存来管理物理内存,以提高内存利用率。同时,Linux系统使用分页机制来管理内存,以实现内存保护和地址映射。分页机制将内存划分为固定大小的页,并使用页表将虚拟地址映射到物理地址。
因此,正确的选项是A和B。但是,由于题目要求选择一个最正确的选项,所以我们选择A作为答案。
答案: A
10. 选择题
题目: 在Linux下,如何将一个C语言源代码文件编译成可执行文件?( )
选项:
A. gcc filename.c -o filename
B. gcc filename.c
C. gcc -o filename filename.c
D. gcc filename
解答:
在Linux下,使用GCC编译器将一个C语言源代码文件编译成可执行文件的命令是:gcc filename.c -o filename。其中,filename.c是源代码文件名,-o filename是指定输出的可执行文件名。
因此,正确的选项是A。
答案: A
11. 选择题
题目: 在Linux下,如何将一个C语言源代码文件编译成共享库?( )
选项:
A. gcc filename.c -o libfilename.so
B. gcc filename.c -shared -o libfilename.so
C. gcc -shared filename.c -o libfilename.so
D. gcc filename.c -fPIC -shared -o libfilename.so
解答:
在Linux下,使用GCC编译器将一个C语言源代码文件编译成共享库的命令是:gcc filename.c -fPIC -shared -o libfilename.so。其中,filename.c是源代码文件名,-fPIC是指定生成位置无关代码,-shared是指定生成共享库,-o libfilename.so是指定输出的共享库文件名。
因此,正确的选项是D。
答案: D
大题一
题目要求
我们需要实现一个函数 insert,它将字符串 t 插入到字符串 s 中的指定位置 i,并确保 s 字符串有足够的空间存放插入后的结果。
函数原型:
void insert(char *s, const char *t, int i);
实现思路
-
明确插入规则:
- 把字符串
t插入到s中第i个位置(i是从 0 开始计数)。 - 插入后,
s的内容要包含t并保持其原始顺序。
- 把字符串
-
实现步骤:
- 检查输入:
确保插入位置i是有效的(0 ≤ i ≤ strlen(s))。 - 移动字符串
s的部分内容:
从插入位置开始,把字符串s的后半部分向后移动,为t让出空间。 - 将字符串
t插入:
把t的内容复制到s中对应位置。 - 添加结束符:
确保字符串s的末尾有正确的\0结束符。
- 检查输入:
实现代码
#include <stdio.h>
#include <string.h>void insert(char *s, const char *t, int i) {int len_s = strlen(s); // 原始字符串 s 的长度int len_t = strlen(t); // 插入字符串 t 的长度// 检查插入位置是否有效if (i < 0 || i > len_s) {printf("插入位置无效!\n");return;}// 从插入点开始,向后移动 s 的内容for (int j = len_s; j >= i; j--) {s[j + len_t] = s[j]; // 向后移动 len_t 个位置}// 把 t 插入到 s 的第 i 个位置for (int j = 0; j < len_t; j++) {s[i + j] = t[j];}// 无需手动添加 '\0',因为移动和插入操作已经保持了结束符的位置
}int main() {char s[100] = "HelloWorld"; // 确保 s 有足够的空间存放插入后的内容char t[] = "Beautiful";printf("原始字符串: %s\n", s);insert(s, t, 5); // 在索引 5 位置插入字符串 tprintf("插入后的字符串: %s\n", s);return 0;
}
代码详细解释
-
strlen函数:strlen(s)用于获取字符串s的实际长度,不包括结束符\0。
-
检查插入位置:
- 判断
i是否超出范围。如果i比s的长度大,插入将是非法操作。
- 判断
-
向后移动内容:
- 把字符串
s中从索引i开始的部分向后移动strlen(t)个位置,为插入t腾出空间。 - 这个过程从后向前进行,避免覆盖数据。
- 把字符串
-
插入字符串
t:- 把
t的每个字符复制到s中的目标位置(i到i + strlen(t))。
- 把
-
输出结果:
- 插入操作完成后,
s包含了插入后的结果。
- 插入操作完成后,
运行结果
假设:
s = "HelloWorld"t = "Beautiful"- 插入位置
i = 5
运行结果:
原始字符串: HelloWorld
插入后的字符串: HelloBeautifulWorld
总结
- 函数的核心逻辑:
- 后移内容,让出空间。
- 插入字符串。
- 特点:
- 插入操作在原字符串中完成,不需要额外的内存。
- 注意事项:
- 保证
s的空间足够大(可以使用动态分配内存来避免这个限制)。
- 保证
大题二
下面是一个基于 Linux 平台的 Socket 套接字的简单示例,它包括 服务端(server) 和 客户端(client) 的实现,以及对应的流程图和详细解释。
一、服务端和客户端通信基本流程
服务端流程:
- 创建一个 socket(网络通信的工具)。
- 绑定(bind)到一个 IP 地址和端口号。
- 监听(listen)客户端连接。
- 接受(accept)一个客户端的连接请求。
- 接收数据并发送响应数据。
- 关闭连接。
客户端流程:
- 创建一个 socket。
- 连接(connect)到服务端。
- 发送数据并接收服务端响应数据。
- 关闭连接。
二、服务端代码示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h> // 包含 socket 相关函数的头文件#define PORT 8080
#define BUFFER_SIZE 1024int main() {int server_fd, new_socket;struct sockaddr_in address;int addrlen = sizeof(address);char buffer[BUFFER_SIZE] = {0};const char *hello = "Hello from server";// 1. 创建 socketif ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0) {perror("Socket failed");exit(EXIT_FAILURE);}// 2. 绑定到 IP 和端口address.sin_family = AF_INET; // IPv4address.sin_addr.s_addr = INADDR_ANY; // 绑定到本地所有可用的 IPaddress.sin_port = htons(PORT); // 端口号,网络字节序if (bind(server_fd, (struct sockaddr *)&address, sizeof(address)) < 0) {perror("Bind failed");close(server_fd);exit(EXIT_FAILURE);}// 3. 监听客户端连接if (listen(server_fd, 3) < 0) {perror("Listen failed");close(server_fd);exit(EXIT_FAILURE);}printf("Server is listening on port %d...\n", PORT);// 4. 接受客户端连接if ((new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t *)&addrlen)) < 0) {perror("Accept failed");close(server_fd);exit(EXIT_FAILURE);}// 5. 处理客户端请求int valread = read(new_socket, buffer, BUFFER_SIZE); // 接收客户端消息printf("Received from client: %s\n", buffer);send(new_socket, hello, strlen(hello), 0); // 发送消息给客户端printf("Hello message sent\n");// 6. 关闭连接close(new_socket);close(server_fd);return 0;
}
三、客户端代码示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>#define PORT 8080
#define BUFFER_SIZE 1024int main() {int sock = 0;struct sockaddr_in serv_addr;char buffer[BUFFER_SIZE] = {0};const char *hello = "Hello from client";// 1. 创建 socketif ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {perror("Socket creation error");exit(EXIT_FAILURE);}// 2. 设置服务端地址serv_addr.sin_family = AF_INET;serv_addr.sin_port = htons(PORT);// 将服务端地址转为网络字节序if (inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr) <= 0) {perror("Invalid address/ Address not supported");close(sock);exit(EXIT_FAILURE);}// 3. 连接到服务端if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {perror("Connection failed");close(sock);exit(EXIT_FAILURE);}// 4. 发送数据send(sock, hello, strlen(hello), 0);printf("Hello message sent to server\n");// 5. 接收服务端的响应int valread = read(sock, buffer, BUFFER_SIZE);printf("Received from server: %s\n", buffer);// 6. 关闭连接close(sock);return 0;
}
四、服务端和客户端运行步骤
- 先启动服务端:它会监听特定端口并等待客户端连接。
- 再启动客户端:它会连接服务端并与其通信。
五、流程图
服务端流程图
+-----------------------+
| 创建 socket | socket()
+-----------------------+|v
+-----------------------+
| 绑定到 IP 和端口 | bind()
+-----------------------+|v
+-----------------------+
| 监听客户端连接 | listen()
+-----------------------+|v
+-----------------------+
| 接受客户端连接 | accept()
+-----------------------+|v
+-----------------------+
| 接收/发送数据 | read()/send()
+-----------------------+|v
+-----------------------+
| 关闭连接 | close()
+-----------------------+
客户端流程图
+-----------------------+
| 创建 socket | socket()
+-----------------------+|v
+-----------------------+
| 设置服务端地址 | sockaddr_in
+-----------------------+|v
+-----------------------+
| 连接服务端 | connect()
+-----------------------+|v
+-----------------------+
| 发送/接收数据 | send()/read()
+-----------------------+|v
+-----------------------+
| 关闭连接 | close()
+-----------------------+
六、代码实现的通俗解释
-
socket:
- 就像现实中的插座,是网络通信的基本接口。
- 服务端和客户端都需要插座来连接。
-
bind(服务端特有):
- 把插座绑定到特定的 IP 和端口,就像在门上挂上门牌号,方便客户端找到。
-
listen(服务端特有):
- 等待客户端敲门(连接请求)。
-
accept(服务端特有):
- 打开门,接受客户端的连接。
-
connect(客户端特有):
- 客户端主动去敲服务端的门。
-
send 和 read:
- 双方发送和接收数据。
-
close:
- 通信结束,关闭插座。
七、总结
- 服务端和客户端的 Socket 通信是通过创建套接字、连接、发送/接收数据来完成的。
- 优点:高效、灵活,支持多种协议。
- 适用场景:网络通信、分布式系统、实时数据传输等。
大题三
单链表倒置问题
在单链表中,节点通过指针连接,每个节点包含数据和一个指向下一个节点的指针。将单链表倒置的任务就是让链表的指针方向反转,使链表从尾部到头部逐步排列。
实现思路
1. 定义数据结构:
- 每个节点由两个部分组成:
- 数据域(存储数据)。
- 指针域(指向下一个节点)。
2. 反转单链表步骤:
- 遍历链表,同时调整每个节点的指针指向上一个节点。
- 保存当前节点的下一个节点,避免断链。
- 将当前节点的指针指向上一个节点。
- 更新“上一个节点”和“当前节点”,继续处理。
- 遍历到链表末尾后,将新头节点更新。
实现代码
#include <stdio.h>
#include <stdlib.h>// 定义单链表节点结构体
typedef struct Node {int data; // 数据域struct Node* next; // 指针域
} Node;// 创建新节点
Node* createNode(int data) {Node* newNode = (Node*)malloc(sizeof(Node));newNode->data = data;newNode->next = NULL;return newNode;
}// 打印链表
void printList(Node* head) {Node* temp = head;while (temp != NULL) {printf("%d -> ", temp->data);temp = temp->next;}printf("NULL\n");
}// 反转单链表
Node* reverseList(Node* head) {Node* prev = NULL; // 用于存储上一个节点Node* current = head; // 当前节点Node* next = NULL; // 用于存储下一个节点while (current != NULL) {next = current->next; // 保存下一个节点current->next = prev; // 反转指针方向prev = current; // 更新 prev 为当前节点current = next; // 更新 current 为下一个节点}return prev; // 新的头节点
}int main() {// 构建链表 1 -> 2 -> 3 -> 4 -> NULLNode* head = createNode(1);head->next = createNode(2);head->next->next = createNode(3);head->next->next->next = createNode(4);printf("Original List: ");printList(head);// 反转链表head = reverseList(head);printf("Reversed List: ");printList(head);return 0;
}
代码运行流程
-
创建链表:
- 用
createNode函数动态分配节点,并通过next指针连接。 - 构建链表
1 -> 2 -> 3 -> 4 -> NULL。
- 用
-
打印链表:
- 遍历链表并打印节点数据。
-
反转链表:
- 使用
reverseList函数,逐步反转每个节点的指针。 prev、current和next三个指针配合完成链表倒置。
- 使用
-
打印结果:
- 最终链表变为
4 -> 3 -> 2 -> 1 -> NULL。
- 最终链表变为
通俗易懂解释
-
原链表:
[1] -> [2] -> [3] -> [4] -> NULL- 每个节点都指向下一个节点。
-
倒置过程:
- 第一步:将
1的指针改为NULL,使其成为尾节点。 - 第二步:将
2的指针改为指向1。 - 第三步:将
3的指针改为指向2。 - 第四步:将
4的指针改为指向3,使其成为头节点。
- 第一步:将
-
结果链表:
[4] -> [3] -> [2] -> [1] -> NULL
流程图
原链表结构
Head -> [1] -> [2] -> [3] -> [4] -> NULL
反转过程(逐步调整指针方向)
Step 1: [1] <- NULL [2] -> [3] -> [4]
Step 2: [1] <- [2] [3] -> [4]
Step 3: [1] <- [2] <- [3] [4]
Step 4: [1] <- [2] <- [3] <- [4] NULL
最终结果
Head -> [4] -> [3] -> [2] -> [1] -> NULL
总结
- 关键点:
- 反转链表时需保存“下一个节点”的指针以防丢失。
- 每次更新指针方向后,更新“当前节点”和“前一节点”。
- 复杂度:
- 时间复杂度:O(n),需要遍历整个链表。
- 空间复杂度:O(1),只使用了固定数量的指针变量。
相关文章:

【Linux测试题】
1. 选择题 题目: 如果想将电脑中Windows C盘(hd1)安装在Linux文件系统的/winsys目录下,请问正确的命令是()。 选项: A. root104.123.123.123:~# mount dev/hd1 /winsys B. root104.123.123.12…...
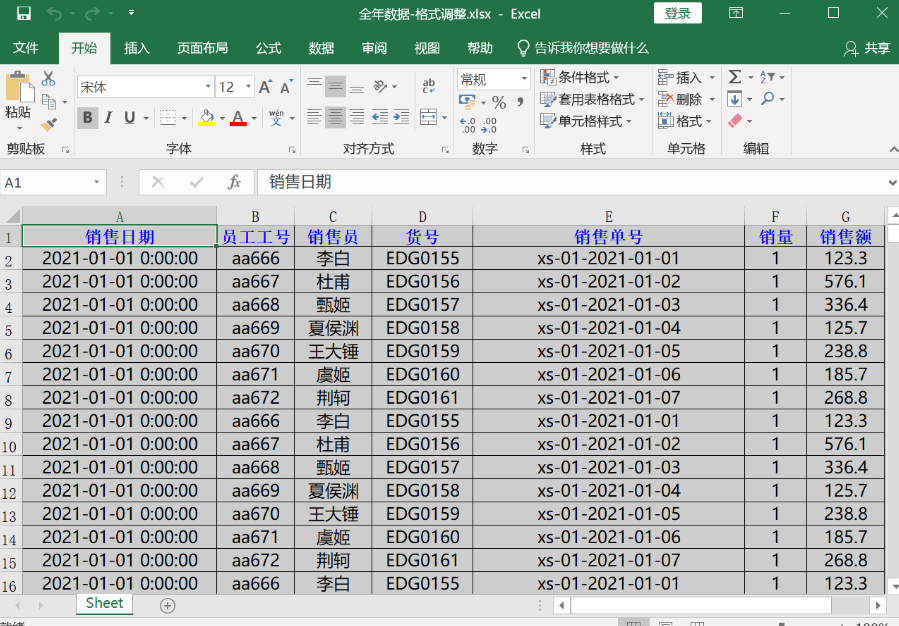
python使用openpyxl处理excel
文章目录 一、写在前面1、安装openpyxl2、认识excel窗口 二、基本使用1、打开excel2、获取sheet表格3、获取sheet表格 尺寸4、获取单元格数据5、获取区域单元格数据6、sheet.iter_rows()方法7、修改单元格的值8、向表格中插入行数据9、实战:合并多个excel 三、获取E…...

【JavaWeb后端学习笔记】Mybatis基础操作以及动态SQL(增、删、改、查)
Mybatis 0、环境准备0.1 准备数据库表emp;0.2 准备SpringBoot工程0.3 配置文件中引入数据库连接信息0.4 创建对应的实体类0.5 准备Mapper接口 1、MyBatis基础操作1.1 删除1.2 新增(主键返回)1.3 更新1.4 查询(解决字段名与类属性名…...
基于MATLAB野外观测站生态气象数据处理分析实践应用
1.本课程基于MATLAB语言 2.以实践案例为主,提供所有代码 3.原理与操作结合 4.布置作业,答疑与拓展 示意图: 以野外观测站高频时序生态气象数据为例,基于MATLAB开展上机操作: 1.不同生态气象要素文件的数据读写与批处理…...

IP 地理位置定位技术原理概述
本文深入探讨 IP 地理位置定位技术的原理。介绍了 IP 地址的基本概念及其在网络中的作用,随后阐述了基于数据库查询、基于网络拓扑分析以及基于机器学习算法的三种主要 IP 地理位置定位技术原理中的基于IP数据库查询。 IP 地址基础 IP 地址是互联网协议࿰…...
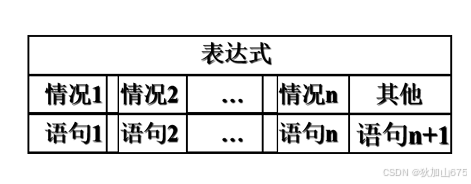
C语言(分支结构)
问题引出 我们在程序设计往往会遇到如下的问题,比如下的函数的计算。 也就是我们是必须要通过一个条件的结果来选择下一步的操作,算法上属于一个分支结构,C语言中实现分支结构主要使用if语句。 条件判断 根据某个条件成立与否,…...

批量将不同的工作簿合并到同一个Excel文件
批量将不同的工作簿合并到同一个Excel文件 下面是一个示例,展示如何批量将不同的工作簿合并到同一个Excel文件,并生成模拟数据。我们将使用 Python 的 pandas 库来完成这个任务。具体步骤如下: 步骤 1: 安装必要的库 首先确保你已安装 pan…...

详解AI网关助力配电房实现智能化管控应用
对于一些建设年份久远的老旧配电房,由于配套降温散热设施设备不完善、线路设备老化等因素,极易出现因环境过热而影响设备正常稳定运行,进而导致电气故障甚至火灾等事故产生。 基于AI网关的配电房智能监控及管理 针对配电房的实时安全监测及…...

2025美赛数学建模常用数据库网站大全
优秀模板写作红宝书数学模型获取——更多资料请点击下方名片进群获取。 一、可以查询美国各个领域经济指标的网站: olap.epsnet.com.cnhttps://www.ers.usda.gov/data-products/rice-yearbook/www.ers.usda.govU.S. Energy Information Administration (EIA) www.eia.govhttp…...
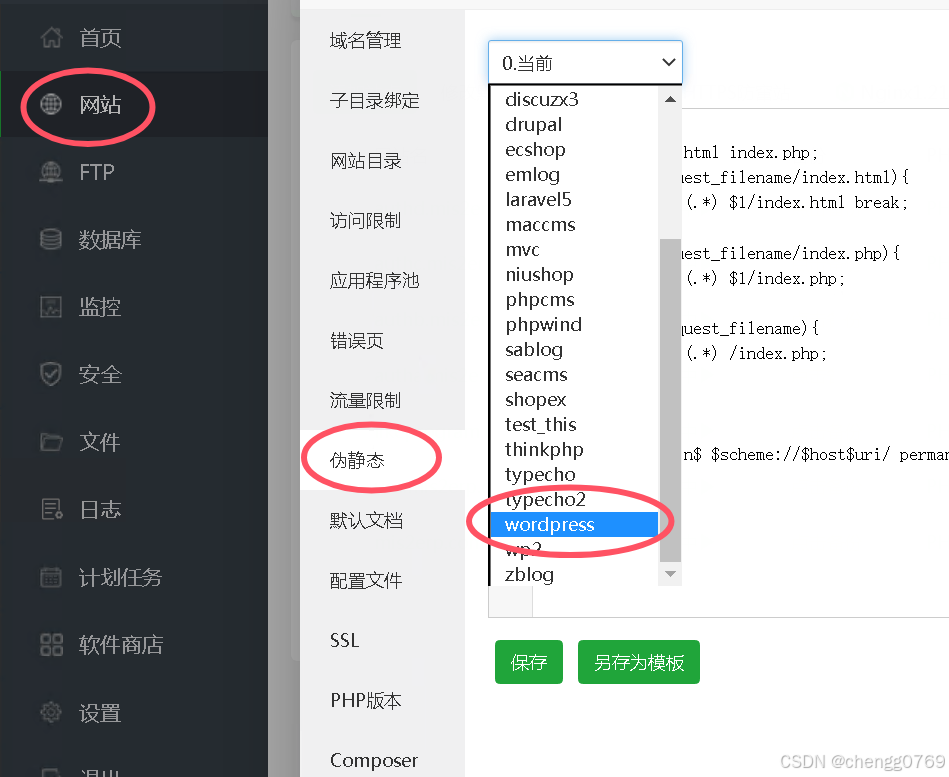
Wordpress设置固定链接形式后出现404错误
比如固定连接设置为 /archives/%post_id%.html 这种形式,看起来比较舒服。对搜索引擎也友好。 出现404需要设置伪静态...

我最近在干什么【1】
前言 打算开一个新系列,偏休闲点的,不是完整全面的技术分享,话题还是聚焦个人成长(学的技术、了解到的信息、看的书……) 方面。文章偏意识流点,单纯分享我最近在干什么,不定期更新,…...

[Vue3]computed原理
Computed原理 不管在是 Vue 2 还是在 Vue 3 中,对 computed 本身的实现原理基本都是一样的。当使用 computed 计算属性时,组件初始化会对每一个计算属性都创建对应的 watcher , 然后在第一次调用自己的 getter 方法时,收集计算属性依赖的所有…...
Vue工程化开发中各文件的作用
1.main.js文件 main.js文件的主要作用:导入App.vue,基于App.vue创建结构渲染index.html。...
)
【c++笔试强训】(第三十一篇)
目录 最⻓回⽂⼦序列(动态规划-区间dp) 题目解析 讲解算法原理 编写代码 添加字符(字符串) 题目解析 讲解算法原理 编写代码 最⻓回⽂⼦序列(动态规划-区间dp) 题目解析 1.题目链接:最…...
Go 1.19.4 HTTP编程-Day 20
1. HTTP协议 1.1 基本介绍 HTTP协议又称超文本传输协议,属于应用层协议,在传输层使用TCP协议。HTTP协议属是无状态的,对事务处理没有记忆能力,如果需要保存状态需要引用其他技术,如Cookie。HTTP协议属是无连接的&…...
)
MySQL 8.0 的主主复制(双向复制)
在 Windows Server 2022 Datacenter 上配置 MySQL 8.0 的主主复制(双向复制),步骤与 Linux 类似,但有一些特定的配置和路径需要注意。以下是详细的简化步骤: 1. 使用 root 用户登录 确保你以 root 用户登录到 MySQL …...
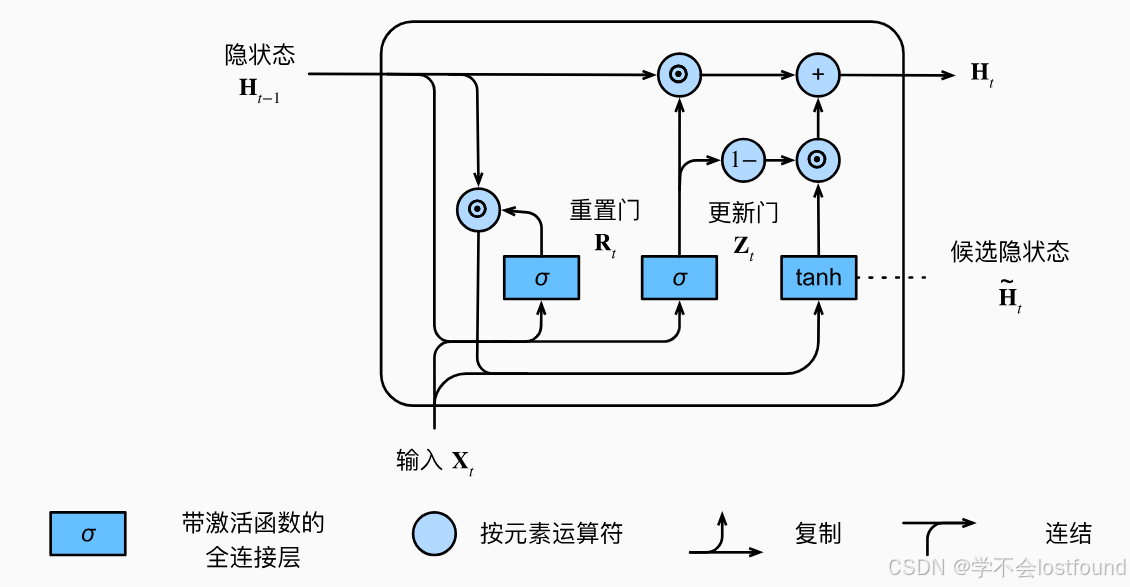
四、自然语言处理_03LSTM与GRU
0、前言 随着循环神经网络(RNN)在各种序列数据处理任务中被广泛应用,研究人员逐渐发现了其在处理长序列数据时会容易出现梯度消失(vanishing gradient)和梯度爆炸(exploding gradient)问题&…...
:硬盘;IDE;ATA;SATA;AHCI;SCSI;SAS)
磁盘系列基础知识(一):硬盘;IDE;ATA;SATA;AHCI;SCSI;SAS
磁盘系列基础知识(一)硬盘 IDE ATA SATA AHCI SCSI SAS 硬盘厂家 西部数据Western Digital/WD. 希捷 SEAGATE、三星 SAMSUNG、东之 Toshiba、英特尔 Intel、金士顿 Kingston、闪迪 SanDisk、 英睿达 Crucial、浦科特 Plextor 硬盘类别 HDD (…...

taro小程序进入腾讯验证码
接入原因 昨天突然晚上有人刷我们公司的登录发送短信接口,紧急将小程序的验证码校验更新上去了 接下来就是我们的接入方法,其实很简单,不过有时候可能大家着急就没有仔细看文档,腾讯验证码文档微信小程序地址,注意这里…...

原子类相关
原子引用 JUC 并发包提供了: AtomicReferenceAtomicMarkableReferenceAtomicStampedReference AtomicReference 使用举例 public interface DecimalAccount {// 获取余额BigDecimal getBalance();// 取款void withdraw(BigDecimal amount);/*** 方法内会启动 10…...

用数据校准方向,让实习招聘更有章法
为什么盲目投流不如精准的搜索曝光? 在校招实习的日常招募中,HR常常面临一个困惑:明明岗位薪资和公司平台都不错,为什么搜索量和投递量却迟迟上不去?这往往是因为在信息密度极高的春招季,企业的校招信息被…...

eLabFTW:开源电子实验笔记本如何重塑科研数据管理流程
eLabFTW:开源电子实验笔记本如何重塑科研数据管理流程 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw 在数字化科研时代&…...

北京UPS不间断电源经销商推荐名录
一、推荐公司概览中伟博信(北京)电子科技有限公司山特电子(深圳)有限公司北京办事处施耐德电气(中国)有限公司北京分公司科华数据股份有限公司北京分公司深圳科士达科技股份有限公司北京子公司二、北京地区…...

Input Leap跨设备键盘鼠标共享3步配置指南
Input Leap跨设备键盘鼠标共享3步配置指南 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap Input Leap是一款功能强大的开源KVM软件,能够帮助用户在不同操作系统和设备之间实现键盘鼠标的完美…...

【实战指南】用DistroAV构建企业级网络视频协作系统:从零到专业部署
【实战指南】用DistroAV构建企业级网络视频协作系统:从零到专业部署 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否曾为传统视频制作中的复杂线缆连接…...

Kindle Comic Converter:漫画爱好者的终极电子阅读器优化工具
Kindle Comic Converter:漫画爱好者的终极电子阅读器优化工具 【免费下载链接】kcc KCC (a.k.a. Kindle Comic Converter) is a comic and manga converter for ebook readers. 项目地址: https://gitcode.com/gh_mirrors/kc/kcc 你是否曾经尝试在Kindle或其…...

Hitboxer:终极免费SOCD按键重映射工具,3分钟彻底解决游戏输入冲突
Hitboxer:终极免费SOCD按键重映射工具,3分钟彻底解决游戏输入冲突 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为游戏中同时按下相反方向键导致角色卡顿而烦恼吗?Hitb…...

为内部工具集成 AI 能力时选择 Taotoken 作为中间层的考量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成 AI 能力时选择 Taotoken 作为中间层的考量 当企业计划为内部管理系统、数据分析工具等引入大模型能力时࿰…...

从Dubbo超时到内存锯齿:高并发服务JVM调优与大对象排查实战
1. 项目背景与问题初现做后端服务开发,尤其是高并发场景下的核心服务,最怕的就是线上服务“抽风”——平时跑得好好的,一到业务高峰期就出现各种超时、失败。最近我就遇到了一个典型的案例,我们团队负责的一个音乐核心服务&#x…...

CANN ops-fft未来规划:51+接口路线图与社区发展蓝图
CANN ops-fft未来规划:51接口路线图与社区发展蓝图 【免费下载链接】ops-fft ops-fft 是 CANN (Compute Architecture for Neural Networks)算子库中提供 FFT 类计算的基础算子库,采用模块化设计,支持灵活的算子开发和…...