nlp培训重点
1. SGD梯度下降公式
当梯度大于0时,变小,往左边找梯度接近0的值。
当梯度小于0时,减去一个负数会变大,往右边找梯度接近0的值,此时梯度从负数到0上升
2.Adam优化器实现原理

#coding:utf8import torch
import torch.nn as nn
import numpy as np
import copy"""
基于pytorch的网络编写
手动实现梯度计算和反向传播
加入激活函数
"""class TorchModel(nn.Module):def __init__(self, hidden_size):super(TorchModel, self).__init__()self.layer = nn.Linear(hidden_size, hidden_size, bias=False) #w = hidden_size * hidden_size wx+b -> wxself.activation = torch.sigmoidself.loss = nn.functional.mse_loss #loss采用均方差损失#当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):y_pred = self.layer(x)y_pred = self.activation(y_pred)if y is not None:return self.loss(y_pred, y)else:return y_pred#自定义模型,接受一个参数矩阵作为入参
class DiyModel:def __init__(self, weight):self.weight = weightdef forward(self, x, y=None):x = np.dot(x, self.weight.T)y_pred = self.diy_sigmoid(x)if y is not None:return self.diy_mse_loss(y_pred, y)else:return y_pred#sigmoiddef diy_sigmoid(self, x):return 1 / (1 + np.exp(-x))#手动实现mse,均方差lossdef diy_mse_loss(self, y_pred, y_true):return np.sum(np.square(y_pred - y_true)) / len(y_pred)#手动实现梯度计算def calculate_grad(self, y_pred, y_true, x):#前向过程# wx = np.dot(self.weight, x)# sigmoid_wx = self.diy_sigmoid(wx)# loss = self.diy_mse_loss(sigmoid_wx, y_true)#反向过程# 均方差函数 (y_pred - y_true) ^ 2 / n 的导数 = 2 * (y_pred - y_true) / n , 结果为2维向量grad_mse = 2/len(x) * (y_pred - y_true)# sigmoid函数 y = 1/(1+e^(-x)) 的导数 = y * (1 - y), 结果为2维向量grad_sigmoid = y_pred * (1 - y_pred)# wx矩阵运算,见ppt拆解, wx = [w11*x0 + w21*x1, w12*x0 + w22*x1]#导数链式相乘grad_w11 = grad_mse[0] * grad_sigmoid[0] * x[0]grad_w12 = grad_mse[1] * grad_sigmoid[1] * x[0]grad_w21 = grad_mse[0] * grad_sigmoid[0] * x[1]grad_w22 = grad_mse[1] * grad_sigmoid[1] * x[1]grad = np.array([[grad_w11, grad_w12],[grad_w21, grad_w22]])#由于pytorch存储做了转置,输出时也做转置处理return grad.T#梯度更新
def diy_sgd(grad, weight, learning_rate):return weight - learning_rate * grad#adam梯度更新
def diy_adam(grad, weight):#参数应当放在外面,此处为保持后方代码整洁简单实现一步alpha = 1e-3 #学习率beta1 = 0.9 #超参数beta2 = 0.999 #超参数eps = 1e-8 #超参数t = 0 #初始化mt = 0 #初始化vt = 0 #初始化#开始计算t = t + 1gt = gradmt = beta1 * mt + (1 - beta1) * gtvt = beta2 * vt + (1 - beta2) * gt ** 2mth = mt / (1 - beta1 ** t)vth = vt / (1 - beta2 ** t)weight = weight - (alpha * mth/ (np.sqrt(vth) + eps))return weightx = np.array([-0.5, 0.1]) #输入
y = np.array([0.1, 0.2]) #预期输出#torch实验
torch_model = TorchModel(2)
torch_model_w = torch_model.state_dict()["layer.weight"]
print(torch_model_w, "初始化权重")
numpy_model_w = copy.deepcopy(torch_model_w.numpy())
#numpy array -> torch tensor, unsqueeze的目的是增加一个batchsize维度
torch_x = torch.from_numpy(x).float().unsqueeze(0)
torch_y = torch.from_numpy(y).float().unsqueeze(0)
#torch的前向计算过程,得到loss
torch_loss = torch_model(torch_x, torch_y)
print("torch模型计算loss:", torch_loss)
# #手动实现loss计算
diy_model = DiyModel(numpy_model_w)
diy_loss = diy_model.forward(x, y)
print("diy模型计算loss:", diy_loss)# # #设定优化器
learning_rate = 0.1
# optimizer = torch.optim.SGD(torch_model.parameters(), lr=learning_rate)
optimizer = torch.optim.Adam(torch_model.parameters())
# optimizer.zero_grad()
# #
# # #pytorch的反向传播操作
torch_loss.backward()
print(torch_model.layer.weight.grad, "torch 计算梯度") #查看某层权重的梯度# # #手动实现反向传播
grad = diy_model.calculate_grad(diy_model.forward(x), y, x)
print(grad, "diy 计算梯度")
# #
# #torch梯度更新
optimizer.step()
# # #查看更新后权重
update_torch_model_w = torch_model.state_dict()["layer.weight"]
print(update_torch_model_w, "torch更新后权重")
# #
# # #手动梯度更新
# diy_update_w = diy_sgd(grad, numpy_model_w, learning_rate)
diy_update_w = diy_adam(grad, numpy_model_w)
print(diy_update_w, "diy更新权重")3. RNN
![]()
#coding:utf8import torch
import torch.nn as nn
import numpy as np"""
手动实现简单的神经网络
使用pytorch实现RNN
手动实现RNN
对比
"""class TorchRNN(nn.Module):def __init__(self, input_size, hidden_size):super(TorchRNN, self).__init__()self.layer = nn.RNN(input_size, hidden_size, bias=False, batch_first=True)def forward(self, x):return self.layer(x)#自定义RNN模型
class DiyModel:def __init__(self, w_ih, w_hh, hidden_size):self.w_ih = w_ihself.w_hh = w_hhself.hidden_size = hidden_sizedef forward(self, x):ht = np.zeros((self.hidden_size))output = []for xt in x:ux = np.dot(self.w_ih, xt)wh = np.dot(self.w_hh, ht)ht_next = np.tanh(ux + wh)output.append(ht_next)ht = ht_nextreturn np.array(output), htx = np.array([[1, 2, 3],[3, 4, 5],[5, 6, 7]]) #网络输入#torch实验
hidden_size = 4
torch_model = TorchRNN(3, hidden_size)# print(torch_model.state_dict())
w_ih = torch_model.state_dict()["layer.weight_ih_l0"]
w_hh = torch_model.state_dict()["layer.weight_hh_l0"]
print(w_ih, w_ih.shape)
print(w_hh, w_hh.shape)
#
torch_x = torch.FloatTensor([x])
output, h = torch_model.forward(torch_x)
print(h)
print(output.detach().numpy(), "torch模型预测结果")
print(h.detach().numpy(), "torch模型预测隐含层结果")
print("---------------")
diy_model = DiyModel(w_ih, w_hh, hidden_size)
output, h = diy_model.forward(x)
print(output, "diy模型预测结果")
print(h, "diy模型预测隐含层结果")
#coding:utf8import torch
import torch.nn as nn
import numpy as np"""
手动实现简单的神经网络
使用pytorch实现CNN
手动实现CNN
对比
"""
#一个二维卷积
class TorchCNN(nn.Module):def __init__(self, in_channel, out_channel, kernel):super(TorchCNN, self).__init__()self.layer = nn.Conv2d(in_channel, out_channel, kernel, bias=False)def forward(self, x):return self.layer(x)#自定义CNN模型
class DiyModel:def __init__(self, input_height, input_width, weights, kernel_size):self.height = input_heightself.width = input_widthself.weights = weightsself.kernel_size = kernel_sizedef forward(self, x):output = []for kernel_weight in self.weights:kernel_weight = kernel_weight.squeeze().numpy() #shape : 2x2kernel_output = np.zeros((self.height - kernel_size + 1, self.width - kernel_size + 1))for i in range(self.height - kernel_size + 1):for j in range(self.width - kernel_size + 1):window = x[i:i+kernel_size, j:j+kernel_size]kernel_output[i, j] = np.sum(kernel_weight * window) # np.dot(a, b) != a * boutput.append(kernel_output)return np.array(output)x = np.array([[0.1, 0.2, 0.3, 0.4],[-3, -4, -5, -6],[5.1, 6.2, 7.3, 8.4],[-0.7, -0.8, -0.9, -1]]) #网络输入#torch实验
in_channel = 1
out_channel = 3
kernel_size = 2
torch_model = TorchCNN(in_channel, out_channel, kernel_size)
print(torch_model.state_dict())
torch_w = torch_model.state_dict()["layer.weight"]
# print(torch_w.numpy().shape)
torch_x = torch.FloatTensor([[x]])
output = torch_model.forward(torch_x)
output = output.detach().numpy()
print(output, output.shape, "torch模型预测结果\n")
print("---------------")
diy_model = DiyModel(x.shape[0], x.shape[1], torch_w, kernel_size)
output = diy_model.forward(x)
print(output, "diy模型预测结果")
#coding:utf8import torch
import torch.nn as nn
import numpy as np
import random
import json
import matplotlib.pyplot as plt"""基于pytorch的网络编写
实现一个网络完成一个简单nlp任务
判断文本中是否有某些特定字符出现"""class TorchModel(nn.Module):def __init__(self, vector_dim, sentence_length, vocab):super(TorchModel, self).__init__()self.embedding = nn.Embedding(len(vocab), vector_dim, padding_idx=0) #embedding层self.pool = nn.AvgPool1d(sentence_length) #池化层self.classify = nn.Linear(vector_dim, 1) #线性层self.activation = torch.sigmoid #sigmoid归一化函数self.loss = nn.functional.mse_loss #loss函数采用均方差损失#当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):x = self.embedding(x) #(batch_size, sen_len) -> (batch_size, sen_len, vector_dim)x = x.transpose(1, 2) #(batch_size, sen_len, vector_dim) -> (batch_size, vector_dim, sen_len)x = self.pool(x) #(batch_size, vector_dim, sen_len)->(batch_size, vector_dim, 1)x = x.squeeze() #(batch_size, vector_dim, 1) -> (batch_size, vector_dim)x = self.classify(x) #(batch_size, vector_dim) -> (batch_size, 1) 3*5 5*1 -> 3*1y_pred = self.activation(x) #(batch_size, 1) -> (batch_size, 1)if y is not None:return self.loss(y_pred, y) #预测值和真实值计算损失else:return y_pred #输出预测结果#字符集随便挑了一些字,实际上还可以扩充
#为每个字生成一个标号
#{"a":1, "b":2, "c":3...}
#abc -> [1,2,3]
def build_vocab():chars = "你我他defghijklmnopqrstuvwxyz" #字符集vocab = {"pad":0}for index, char in enumerate(chars):vocab[char] = index+1 #每个字对应一个序号vocab['unk'] = len(vocab) #26return vocab#随机生成一个样本
#从所有字中选取sentence_length个字
#反之为负样本
def build_sample(vocab, sentence_length):#随机从字表选取sentence_length个字,可能重复x = [random.choice(list(vocab.keys())) for _ in range(sentence_length)]#指定哪些字出现时为正样本if set("你我他") & set(x):y = 1#指定字都未出现,则为负样本else:y = 0x = [vocab.get(word, vocab['unk']) for word in x] #将字转换成序号,为了做embeddingreturn x, y#建立数据集
#输入需要的样本数量。需要多少生成多少
def build_dataset(sample_length, vocab, sentence_length):dataset_x = []dataset_y = []for i in range(sample_length):x, y = build_sample(vocab, sentence_length)dataset_x.append(x)dataset_y.append([y])return torch.LongTensor(dataset_x), torch.FloatTensor(dataset_y)#建立模型
def build_model(vocab, char_dim, sentence_length):model = TorchModel(char_dim, sentence_length, vocab)return model#测试代码
#用来测试每轮模型的准确率
def evaluate(model, vocab, sample_length):model.eval()x, y = build_dataset(200, vocab, sample_length) #建立200个用于测试的样本print("本次预测集中共有%d个正样本,%d个负样本"%(sum(y), 200 - sum(y)))correct, wrong = 0, 0with torch.no_grad():y_pred = model(x) #模型预测for y_p, y_t in zip(y_pred, y): #与真实标签进行对比if float(y_p) < 0.5 and int(y_t) == 0:correct += 1 #负样本判断正确elif float(y_p) >= 0.5 and int(y_t) == 1:correct += 1 #正样本判断正确else:wrong += 1print("正确预测个数:%d, 正确率:%f"%(correct, correct/(correct+wrong)))return correct/(correct+wrong)def main():#配置参数epoch_num = 10 #训练轮数batch_size = 20 #每次训练样本个数train_sample = 500 #每轮训练总共训练的样本总数char_dim = 20 #每个字的维度sentence_length = 6 #样本文本长度learning_rate = 0.005 #学习率# 建立字表vocab = build_vocab()# 建立模型model = build_model(vocab, char_dim, sentence_length)# 选择优化器optim = torch.optim.Adam(model.parameters(), lr=learning_rate)log = []# 训练过程for epoch in range(epoch_num):model.train()watch_loss = []for batch in range(int(train_sample / batch_size)):x, y = build_dataset(batch_size, vocab, sentence_length) #构造一组训练样本optim.zero_grad() #梯度归零loss = model(x, y) #计算lossloss.backward() #计算梯度optim.step() #更新权重watch_loss.append(loss.item())print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))acc = evaluate(model, vocab, sentence_length) #测试本轮模型结果log.append([acc, np.mean(watch_loss)])#画图plt.plot(range(len(log)), [l[0] for l in log], label="acc") #画acc曲线plt.plot(range(len(log)), [l[1] for l in log], label="loss") #画loss曲线plt.legend()plt.show()#保存模型torch.save(model.state_dict(), "model.pth")# 保存词表writer = open("vocab.json", "w", encoding="utf8")writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))writer.close()return#使用训练好的模型做预测
def predict(model_path, vocab_path, input_strings):char_dim = 20 # 每个字的维度sentence_length = 6 # 样本文本长度vocab = json.load(open(vocab_path, "r", encoding="utf8")) #加载字符表model = build_model(vocab, char_dim, sentence_length) #建立模型model.load_state_dict(torch.load(model_path)) #加载训练好的权重x = []for input_string in input_strings:x.append([vocab[char] for char in input_string]) #将输入序列化model.eval() #测试模式with torch.no_grad(): #不计算梯度result = model.forward(torch.LongTensor(x)) #模型预测for i, input_string in enumerate(input_strings):print("输入:%s, 预测类别:%d, 概率值:%f" % (input_string, round(float(result[i])), result[i])) #打印结果if __name__ == "__main__":main()test_strings = ["fnvfee", "wz你dfg", "rqwdeg", "n我kwww"]predict("model.pth", "vocab.json", test_strings)
相关文章:
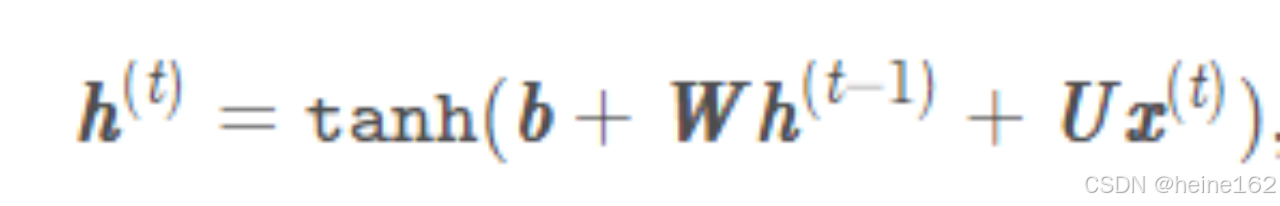
nlp培训重点
1. SGD梯度下降公式 当梯度大于0时,变小,往左边找梯度接近0的值。 当梯度小于0时,减去一个负数会变大,往右边找梯度接近0的值,此时梯度从负数到0上升 2.Adam优化器实现原理 #coding:utf8import torch import torch.n…...

什么是多模态和模态
文章目录 前言一、定义1. 模态 (Modal)2. 非模态 (Non-modal) 二、GUI中1. 模态(Modal)对话框2. 非模态(Modeless)对话框 三、模态 vs 非模态 的对比四、何时使用模态和非模态对话框?五、Qt 中 exec() 与 show() 的区别…...

apache中的Worker 和 Prefork 之间的区别是什么?
文章目录 内存使用稳定性兼容性适用场景 Apache中的Worker和Prefork两种工作模式在内存使用、稳定性以及兼容性等方面存在区别 内存使用 Worker:由于使用线程,内存占用较少。Prefork:每个进程独立运行,内存消耗较大。 稳定性 W…...
系统监控——分布式链路追踪系统
摘要 本文深入探讨了分布式链路追踪系统的必要性与实施细节。随着软件架构的复杂化,传统的日志分析方法已不足以应对问题定位的需求。文章首先解释了链路追踪的基本概念,如Trace和Span,并讨论了其基本原理。接着,文章介绍了SkyWa…...

【Python]深入Python日志管理:从logging到分布式日志追踪的完整指南
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 日志是软件开发中的核心部分,尤其在分布式系统中,日志对于调试和问题定位至关重要。本篇文章将从Python标准库的logging模块出发,逐步探讨日志管理的最佳实践,涵盖日志配置、日志分层、日志格式化等基…...

DHCP Client的工作方式
【运作方式】 一开始Client没有IP资料 DHCPDISCOVER Client发出DHCPDISCOVER广播封包(UDP port 67),寻找DHCP Server。 DHCPOFFER Client开始监听UDP port 68 (任何)DHCP Server收到DHCPDISCOVER封包后ÿ…...

docker-常用应用部署dockerfile模板
文章目录 概述Springboot-Djava.security.egdfile:/dev/./urandom参数说明 vue应用部署nginx.conf配置Dockerfile 概述 本文列举了Java开发中常用如SpringBoot、Vue前端等类型的应用Docker部署所需的DockerFile Springboot FROM anapsix/alpine-java:8_server-jre_unlimited…...

Unity3D学习FPS游戏(13)玩家血量控制
玩家血量控制 血条UI玩家Canvas下的Slider血量逻辑控制 子弹攻击掉血子弹发射者的区分玩家受伤逻辑子弹碰撞检测 效果 血条UI 和之前我们前面介绍的玩家武器弹夹UI的思路是一样的,跟详细的细节可以参考博客Unity3D装弹和弹夹UI显示。 玩家Canvas下的Slider 之前玩…...
TDesign:Switch开关
Switch 开关 文档地址 view TDSwitch(isOn: controller.isDefault, // 默认是否开启状态trackOnColor: AppColors.mainColor,onChanged: ((bool value){controller.onTapSwitch(value);return value;}), ),controller bool isDefault true; // 是否默认 void onTapSwitch(bool…...

AI在SEO中的应用与关键词优化探讨
内容概要 在当今数字化时代,人工智能(AI)技术为搜索引擎优化(SEO)带来了革命性的改变。传统的SEO主要依赖于人为的经验和判断,而AI则通过算法分析海量数据,提供更加精准和高效的方式优化关键词…...

[docker中首次配置git环境与时间同步问题]
11月没写东西,12月初赶紧水一篇。 刚开始搭建docker服务器时,网上找一堆指令配置好git后,再次新建容器后忘记怎么配了,,这次记录下。 一、git ssh指令法,该方法不用每次提交时输入密码 前期准备࿰…...

使用lumerical脚本语言创建绘制波导并进行数据分析(纯代码实现)(1)
使用lumerical脚本语言创建绘制波导、配置二维模式求解器、计算模式轮廓、计算有效折射率(neff)和群折射率(ng)随波长的变化关系、计算有效折射率(neff)随波导宽度的变化关系及针对有效折射率法进行相关数据处理(代码均有注释详解)。 一、绘制波导结构 1.1 代码实现 w…...

redis.conf
tracking-table-max-keys tracking-table-max-keys 是 Redis 中的一个配置选项,它与 Key Tracking 功能有关。Key Tracking 是 Redis 6.0 引入的一项功能,用于追踪哪些键在被客户端操作时发生了变化。 tracking-table-max-keys 的作用: 该配置…...

泷羽sec学习打卡-shell命令8
声明 学习视频来自B站UP主 泷羽sec,如涉及侵权马上删除文章 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都 与本人无关,切莫逾越法律红线,否则后果自负 关于shell的那些事儿-shell8 until循环(直到为止)case语句func函数定义实践是检验真理的唯一标准 别问&…...

割草机器人架构设计和技术应用
题目:割草机器人项目的系统架构设计与技术应用 摘要: 随着智能家居和自动化技术的发展,割草机器人作为一种便捷的园艺工具逐渐进入市场。本论文以我参与管理和开发的割草机器人项目为例,详细阐述了项目中采用的关键技术、系统架…...

基于SSM闪光点映像摄影工作室预约系统JAVA|VUE|Springboot计算机毕业设计源代码+数据库+LW文档+开题报告+答辩稿+部署教+代码讲解
源代码数据库LW文档(1万字以上)开题报告答辩稿 部署教程代码讲解代码时间修改教程 一、开发工具、运行环境、开发技术 开发工具 1、操作系统:Window操作系统 2、开发工具:IntelliJ IDEA或者Eclipse 3、数据库存储:…...

Windows 和 Linux 系统命令行操作详解:从文件管理到进程监控
1.切换盘符与目录操作 在命令行中,切换盘符和目录是最常见的操作。尽管 DOS 和 Linux 在这些操作上有所不同,但它们都能实现相似的功能。 (1)切换盘符 ①DOS命令:在 DOS 中,切换盘符非常简单,使用 盘符名:ÿ…...
【Calibre-Web】Calibre-Web服务器安装详细步骤(个人搭建自用的电子书网站,docker-compose安装)
文章目录 一、Calibre-Web和Calibre的区别是什么?使用场景分别是什么?二、服务器安装docker和docker-compose三、服务器安装Calibre-Web步骤1、安装完成后的目录结构2、安装步骤3、初始配置4、启动上传 四、安装Calibre五、docker-compose常用命令六、客…...

服务器数据恢复—服务器raid0阵列硬盘指示灯显示黄颜色的数据恢复案例
服务器数据恢复环境&故障情况: 某品牌服务器上有一组由两块SAS硬盘组建的raid0阵列,上层是windows server操作系统ntfs文件系统。服务器上一个硬盘指示灯显示黄颜色,该指示灯对应的硬盘离线,raid不可用。 服务器数据恢复过程…...

.nii.gz文件读取方式
".nii.gz"文件的介绍: ".nii.gz"文件是一种常见的用于存储神经影像数据的格式,它通常包含了三维或四维的图像体素数据,以及与磁共振扫描相关的一些重要元数据,比如扫描参数、特征描述等等。而".nii"表示未经压…...

5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器
5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint里输入复杂的数学公式而头疼吗?作为科研人员、教师或…...

3行代码实现语音检索:用FunASR从10万段音频中精准定位关键信息
3行代码实现语音检索:用FunASR从10万段音频中精准定位关键信息 【免费下载链接】FunASR A Fundamental End-to-End Speech Recognition Toolkit and Open Source SOTA Pretrained Models, Supporting Speech Recognition, Voice Activity Detection, Text Post-proc…...

告别645,聊聊698协议:面向对象的电表通信到底好在哪?
698协议深度解析:面向对象设计如何重塑电表通信生态 当电力行业从单向计量迈向双向互动时,传统645协议的数据标识系统开始显露出架构层面的局限性。某省级电网公司的技术团队在2020年做过一次压力测试:在使用645协议的场景下,要实…...

LabVIEW字符串处理保姆级教程:从长度计算到日期格式化,13个实例带你玩转
LabVIEW字符串处理实战指南:从基础操作到高级应用 在工业自动化、测试测量和仪器控制领域,LabVIEW作为图形化编程的标杆工具,其字符串处理能力直接影响着数据解析、通信协议实现等核心功能。本文将通过13个典型场景,系统讲解如何高…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

北京昌平浇筑阁楼测评:天顺诚达施工优但服务待提升,适合这类
本次测评聚焦于北京昌平区浇筑阁楼领域,旨在为对该服务感兴趣的人群提供客观、真实的数据和信息,帮助大家了解各相关企业的实际情况。参与本次测评的企业为北京天顺诚达建筑工程有限公司。需要声明的是,本次测评均基于真实数据与体验…...

碧蓝航线Alas脚本:解放双手的终极自动化解决方案
碧蓝航线Alas脚本:解放双手的终极自动化解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每…...

Python之vyvert包语法、参数和实际应用案例
一、vyvert 包概述(Python) vyvert(0.1.0)是一个轻量级依赖注入(DI)库,灵感来自 pytest 与 FastAPI,主打简洁注解式注入、自动依赖解析、异步兼容。 定位:非侵入式 DI&am…...

如何高效使用Alas:碧蓝航线自动化智能助手终极指南
如何高效使用Alas:碧蓝航线自动化智能助手终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 厌倦了每天重…...
: 丰富的序列 - deque高效应对高并发序列处理)
《流畅的Python》读书笔记03(补充02): 丰富的序列 - deque高效应对高并发序列处理
Python序列分类体系在高并发数据处理中的选型优化,需要综合考虑序列类型的内存模型、可变性、线程安全性以及操作性能。在高并发场景下,错误的选型可能导致性能瓶颈、数据竞争或内存溢出。以下是基于序列分类体系的详细选型策略与优化建议。 一、序列分类…...