Redis 之持久化
目录
介绍
RDB
RDB生成方式
自动触发
手动触发
AOF(append-only file)
Redis 4.0 混合持久化
Redis主从工作原理
总结
介绍
Redis提供了两个持久化数据的能力,RDB Snapshot 和 AOF(Append Only FIle)日志,RDB快照能够在指定的时间间隔内生成数据快照,而AOF日志则记录了所有的写操作命令。RDB做镜像全量持久化,AOF做增量持久化。
RDB
RDB全称Redis Database Backup file (Redis数据备份⽂件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。
当Redis实例故障重启后,从磁盘读取快照⽂件,恢复数据。这样一来即使故障宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。它会在特定的时间点对数据库的全部数据进行快照,这个快照⽂件称为 RDB文件(dump.rdb),默认是保存在当前运⾏⽬录。其中,RDB就是Redis DataBase的缩写,是一个二进制文件。
RDB生成方式
-
自动触发
1. 配置文件中满足默认备份配置条件(实际上执行的是bgsave命令)
save 900 1 #900 秒之内,对数据库进行了至少 1 次修改;save 300 10 #300 秒之内,对数据库进行了至少 10 次修改save 60 10000 #60 秒之内,对数据库进行了至少 10000 次修改# The filename where to dump the DBdbfilename dump.rdb #默认的rdb文件名dir ./ #指定rdb目录,这里代表的是当前目录
2. 执行flushall/flushdb命令也会产生dump.rdb文件,只不过生成的是空文件,无意义
3. 执行shutdown且没有开启 AOF 持久化也会触发 RDB 持久化
4. 主从复制时,主节点自动触发。
-
手动触发
在客户端手动执行 save/bgsave,会触发 RDB 持久化。save会阻塞当前Redis服务,不推荐使用,bgsave会fork出子线程执行 RDB 持久化,不会阻塞,推荐使用;
执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程,导致Redis不能处理其他命令,因此线上禁止使用。

命令bgsave执行后,会立刻返回OK,Redis 会fork一个子进程,原来的redis主进程继续执行后续操作,新fork的子进程负责将数据保存到磁盘,然后退出,如下图:


Copy-on-write 写时复制,多更改条件下,内存被大量复制,重写完成后,数据如何释放?
本质来说,这是一个进程的内存资源管理问题:
- 内核提供的写时复制机制避免了大量内存拷贝以及占用过多内存
- 子进程fork操作只是拷贝了父进程的页表数据,当fork完成后,对于一个父进程引用的内存页,其引用值从1变成2.
- 当父进程进行写操作时,会申请一份新的内存页,并从原内存页copy所有数据,之后父进程就在新的内存页上进行操作。而原内存页就变成了子进程的专属内存页,引用值变成了1
- 子进程重写完成并退出后,内核会对资源进行回收,包括占用的内存资源
- 回收:对于页表来说,是进程专属,直接清理即可;而关联的内存页会将其引用值减1,如果引用值变成了0,该内存页就会被回收
- 也就是复制之前的页(原内存页),变成了子进程的专属页,当子进程结束后就会被回收掉
save与bgsave对比:

AOF(append-only file)
appendonly yes
- 命令追加(append) :所有的写命令会追加到 AOF 缓冲区中。
- ⽂件写⼊(write) :将 AOF 缓冲区的数据写⼊到 AOF ⽂件中。这⼀步 需要调⽤write函数(系统调⽤),write将数据写⼊到了系统内核缓冲区之 后直接返回了(延迟写)。注意!此时并没有同步到磁盘。
- ⽂件同步(fsync) :AOF 缓冲区根据对应的持久化⽅式( fsync 策略) 向硬盘做同步操作。这⼀步需要调⽤ fsync 函数(系统调⽤), fsync 针 对单个⽂件操作,对其进⾏强制硬盘同步,fsync 将阻塞直到写⼊磁盘完 成后返回,保证了数据持久化。
- ⽂件重写(rewrite) :随着 AOF ⽂件越来越⼤,需要定期对 AOF ⽂件 进⾏重写,达到压缩的⽬的。
- 重启加载(load) :Redis 重启时,可以加载 AOF ⽂件进⾏数据恢复。
- write :写⼊系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会⽴即同步到硬盘。虽然提⾼了效率,但也带来了数据丢失的⻛险。同步硬盘操作通 常依赖于系统调度机制,Linux 内核通常为 30s 同步⼀次,具体值取决于写出 的数据量和 I/O 缓冲区的状态。
- fsync : fsync⽤于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
- appendfsync always:主线程调⽤ write 执⾏写操作后,后台线程( aof_fsync 线程)⽴即会调⽤ fsync 函数同步 AOF ⽂件(刷盘),fsync 完成后线程返回,这样会严重降低 Redis 的性能

- appendfsync everysec :主线程调⽤ write 执⾏写操作后⽴即返回,由后台线程( aof_fsync 线程)每秒钟调⽤ fsync 函数(系统调⽤)同步⼀次 AOF ⽂件

- appendfsync no :主线程调⽤ write 执⾏写操作后⽴即返回,让操作系统决定何时进⾏同步,Linux 下⼀般为 30 秒⼀次

推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
AOF重写
AOF文件里可能有太多没用指令,所以AOF会定期根据内存的最新数据生成aof文件
如下两个配置可以控制AOF自动重写频率
auto‐aof‐rewrite‐min‐size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
auto‐aof‐rewrite‐percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
当然AOF还可以手动重写,进入redis客户端执行命令bgrewriteaof重写AOF
由于 AOF 重写会进⾏⼤量的写⼊操作,为了避免对 Redis 正常处理命令请求造成影响,Redis 将 AOF 重写程序放到⼦进程⾥执⾏。
图 1 展示的是 AOFRW 的实现原理。当 AOFRW 被触发执行时,Redis 首先会 fork 一个子进程进行后台重写操作,该操作会将执行 fork 那一刻 Redis 的数据快照全部重写到一个名为 temp-rewriteaof-bg-pid.aof 的临时 AOF 文件中。
由于重写操作为子进程后台执行,主进程在 AOF 重写期间依然可以正常响应用户命令。因此,为了让子进程最终也能获取重写期间主进程产生的增量变化,主进程除了会将执行的写命令写入 aof_buf,还会写一份到 aof_rewrite_buf 中进行缓存。在子进程重写的后期阶段,主进程会将 aof_rewrite_buf 中累积的数据使用 pipe 发送给子进程,子进程会将这些数据追加到临时 AOF 文件中(详细原理可参考[1])。
当主进程承接了较大的写入流量时,aof_rewrite_buf 中可能会堆积非常多的数据,导致在重写期间子进程无法将 aof_rewrite_buf 中的数据全部消费完。此时,aof_rewrite_buf 剩余的数据将在重写结束时由主进程进行处理。
当子进程完成重写操作并退出后,主进程会在 backgroundRewriteDoneHandler中处理后续的事情。首先,将重写期间 aof_rewrite_buf 中未消费完的数据追加到临时 AOF 文件中。其次,当一切准备就绪时,Redis 会使用 rename 操作将临时AOF 文件原子的重命名为 server.aof_filename,此时原来的 AOF 文件会被覆盖。至此,整个 AOFRW 流程结束。
图1:

AOF重写存在的问题
- 内存开销
由图 1 可以看到,在 AOFRW 期间,主进程会将 fork 之后的数据变化写进aof_rewrite_buf 中,aof_rewrite_buf 和 aof_buf 中的内容绝大部分都是重复的,因此这将带来额外的内存冗余开销。
- CPU 开销
CPU 的开销主要有三个地方,分别解释如下:
1) 在 AOFRW 期间,主进程需要花费 CPU 时间向 aof_rewrite_buf 写数据,并使用 eventloop 事件循环向子进程发送 aof_rewrite_buf 中的数据。
2) 在子进程执行重写操作的后期,会循环读取 pipe 中主进程发送来的增量数据,
然后追加写入到临时 AOF 文件。
3) 在子进程完成重写操作后,主进程会在 backgroundRewriteDoneHandler 中进
行收尾工作。其中一个任务就是将在重写期间 aof_rewrite_buf 中没有消费完
成的数据写入临时 AOF 文件。如果 aof_rewrite_buf 中遗留的数据很多,这里
也将消耗 CPU 时间。
- 磁盘 IO 开销
如前文所述,在 AOFRW 期间,主进程除了会将执行过的写命令写到 aof_buf 之外,
还会写一份到 aof_rewrite_buf 中。aof_buf 中的数据最终会被写入到当前使用的旧 AOF 文件中,产生磁盘 IO。同时,aof_rewrite_buf 中的数据也会被写入重写生成的新 AOF 文件中,产生磁盘 IO。因此,同一份数据会产生两次磁盘 IO。
- BASE:表示基础 AOF,它一般由子进程通过重写产生,该文件最多只有一个;
- INCR:表示增量 AOF,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个;
- HISTORY:表示历史 AOF,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。

图 2 展示的是在 MP-AOF 中执行一次 AOFRW 的大致流程。在开始时我们依然会fork 一个子进程进行重写操作,在主进程中,我们会同时打开一个新的 INCR 类型的 AOF 文件,在子进程重写操作期间,所有的数据变化都会被写入到这个新打开的INCR AOF 中。子进程的重写操作完全是独立的,重写期间不会与主进程进行任何的数据和控制交互,最终重写操作会产生一个 BASE AOF。新生成的 BASE AOF 和新打开的 INCR AOF 就代表了当前时刻 Redis 的全部数据。AOFRW 结束时,主进程会负责更新 manifest 文件,将新生成的 BASE AOF 和 INCR AOF 信息加入进去,并将之前的 BASE AOF 和 INCR AOF 标记为 HISTORY(这些 HISTORY AOF 会被 Redis 异步删除)。一旦 manifest 文件更新完毕,就标志整个 AOFRW 流程结束。
由图 2 可以看到,我们在 AOFRW 期间不再需要 aof_rewrite_buf,因此去掉了对应的内存消耗。同时,主进程和子进程之间也不再有数据传输和控制交互,因此对应的 CPU 开销也全部去掉。
Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。
通过如下配置可以开启混合持久化(必须先开启aof):
# aof‐use‐rdb‐preamble yes
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的AOF 全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如下

Redis主从工作原理
Redis主从架构

Redis主从工作原理
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。
master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。
当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送给多个并发连接的slave。
主从复制(全量复制)流程图:

数据部分复制
当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分数据复制(断点续传)。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
主从复制(部分复制,断点续传)流程图:

如果有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做如下架构,让部分从节点与从节点(与主节点同步)同步数据

总结
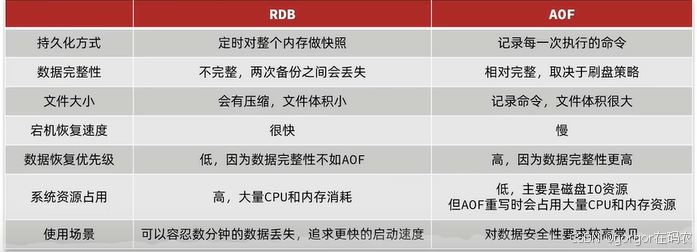
RDB和AOF对比
相关文章:
Redis 之持久化
目录 介绍 RDB RDB生成方式 自动触发 手动触发 AOF(append-only file) Redis 4.0 混合持久化 Redis主从工作原理 总结 介绍 Redis提供了两个持久化数据的能力,RDB Snapshot 和 AOF(Append Only FIle)…...
视频监控汇聚平台:Liveweb安防监控平台实现接入监控视频集中管理方案
随着各行业数字化转型的不断推进,视频监控技术在行业内的安防应用及管理支撑日益增多。然而,由于前期规划不清晰、管理不到位等问题,视频监管系统普遍存在以下问题: 1. 各部门单位在视频平台建设中以所属领域为单位,导…...
ABAP - 系统集成之SAP的数据同步到OA(泛微E9)服务器数据库
需求背景 项目经理说每次OA下单都需要调用一次SAP的接口获取数据,导致效率太慢了,能否把SAP的数据保存到OA的数据库表里,这样OA可以直接从数据库表里获取数据效率快很多。思来想去,提供了两个方案。 在集群SAP节点下增加一个SQL S…...

uniapp使用ucharts修改Y、X轴标题超出换行
找到ucharts里面的u-charts.js。 Y轴的话找到drawYAxis方法。然后找到方法里面绘制文字的context.fillText方法。先把这个代码注释掉,然后加上下面代码 let labelLines item.split(\n); let currentY pos yAxisFontSize / 2 - 3 * opts.pix; labelLines.forEac…...

三分钟详细解读什么是Ecovadis认证?
Ecovadis认证,这一源自法国的全球性企业可持续性评估体系,宛如一面明镜,映照出企业在环境、社会和治理(ESG)领域的真实面貌。它不仅仅是一项简单的认证,更是一个推动全球企业和供应链向更加绿色、公正、透明…...

spring6:4、原理-手写IoC
目录 4、原理-手写IoC4.1、回顾Java反射4.2、实现Spring的IoC 4、原理-手写IoC 我们都知道,Spring框架的IOC是基于Java反射机制实现的,下面我们先回顾一下java反射。 4.1、回顾Java反射 Java反射机制是在运行状态中,对于任意一个类&#x…...

爬取的数据能实时更新吗?
在当今数字化时代,实时数据更新对于企业和个人都至关重要。无论是市场分析、商品类目监控还是其他需要实时数据的应用场景,爬虫技术都能提供有效的解决方案。本文将探讨如何利用PHP爬虫实现数据的实时更新,并提供相应的代码示例。 1. 实时数…...

Linux 下使用飞鸽传书实现与Windows飞秋的通信
最近把单位的办公电脑换成Linux系统,但是其他同事们都使用飞秋2013进行局域网通信和文件传输,经过一番尝试,发现飞鸽传书For Linux 2014能够实现两者的互相通信。 飞鸽传书ForLINUXLinux版下载_飞鸽传书ForLINUX免费下载_飞鸽传书ForLINUX1.2…...

MongoDB分片集群搭建及扩容
分片集群搭建及扩容 整体架构 环境准备 3台Linux虚拟机,准备MongoDB环境,配置环境变量。一定要版本一致(重点),当前使用 version4.4.9 配置域名解析 在3台虚拟机上执行以下命令,注意替换实际 IP 地址 e…...

qt QSettings详解
1、概述 QSettings是Qt框架中用于应用程序配置和持久化数据的一个类。它提供了一种便捷的方式来存储和读取应用程序的设置,如窗口大小、位置、用户偏好等。QSettings支持多种存储格式,包括INI文件、Windows注册表(仅限Windows平台࿰…...

【Linux】ubuntu下一键配置vim
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:Linux权限(超详细彻底搞懂Linux的权限) 🔖流水不争,争的是滔滔…...

【NLP 9、实践 ① 五维随机向量交叉熵多分类】
目录 五维向量交叉熵多分类 规律: 实现: 1.设计模型 2.生成数据集 3.模型测试 4.模型训练 5.对训练的模型进行验证 调用模型 你的平静,是你最强的力量 —— 24.12.6 五维向量交叉熵多分类 规律: x是一个五维(索引)向量ÿ…...
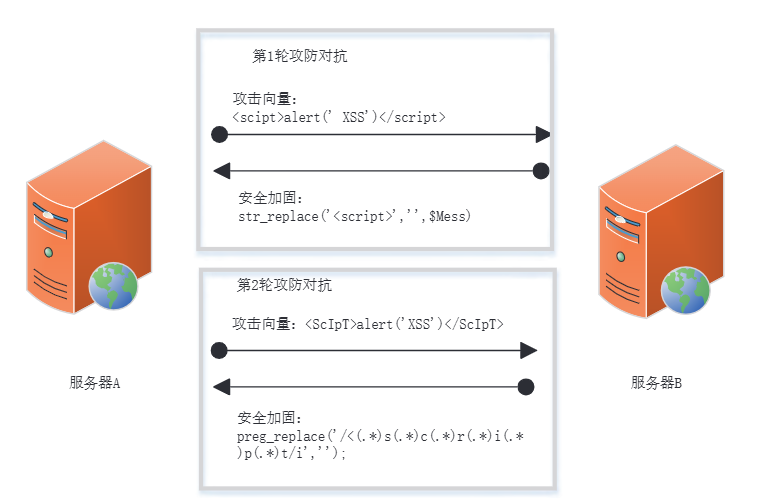
信息系统安全防护攻防对抗式实验教学解决方案
一、引言 在网络和信息技术迅猛发展的今天,信息系统已成为社会各领域的关键基础设施,它支撑着电子政务、电子商务、科学研究、能源、交通和社会保障等多个方面。然而,信息系统也面临着日益严峻的网络安全威胁,网络攻击手段层出不…...

【笔记2-4】ESP32:freertos任务创建
主要参考b站宸芯IOT老师的视频,记录自己的笔记,老师讲的主要是linux环境,但配置过程实在太多问题,就直接用windows环境了,老师也有讲一些windows的操作,只要代码会写,操作都还好,开发…...

2024年12月6日Github流行趋势
项目名称:lobe-chat 项目维护者:arvinxx, semantic-release-bot, canisminor1990, lobehubbot, renovate项目介绍:一个开源的现代化设计的人工智能聊天框架。支持多AI供应商(OpenAI / Claude 3 / Gemini / Ollama / Qwen / DeepSe…...

matlab读取NetCDF文件
matlab对NetCDF文件进行信息获取和读取数据 文章目录 前言一、什么是NetCDF文件二、读取NetCDF文件数据 1.引入库 2.读入数据总结 前言 在气象学中,许多气象数据存储在NetCDF文件中,后缀为.nc,通常可以用NCL、python和MATLAB等对该…...
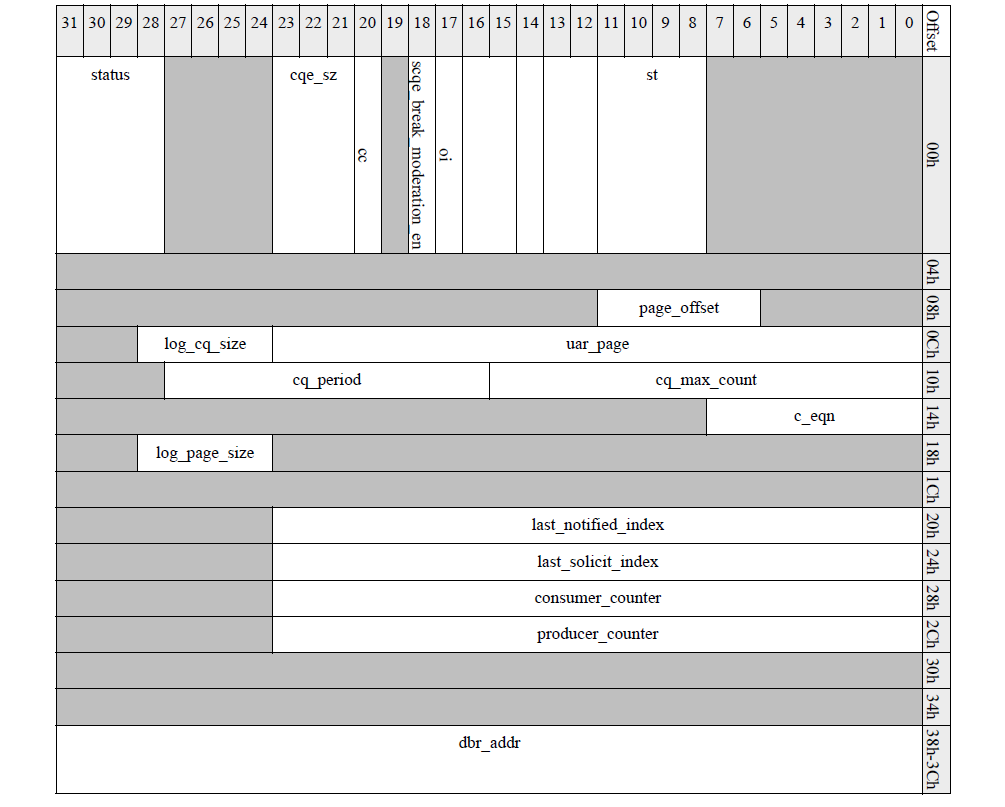
RDMA驱动学习(三)- cq的创建
用户通过ibv_create_cq接口创建完成队列,函数原型和常见用法如下,本节以该用法为例看下cq的创建过程。 struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe,void *cq_context,struct ibv_comp_channel *channel,int comp_vector); cq …...
(subprocess))
Flask使用Celery与多进程管理:优雅处理长时间任务与子进程终止技巧(multiprocessing)(subprocess)
在许多任务处理系统中,我们需要使用异步任务队列来处理繁重的计算或长时间运行的任务,如模型训练。Celery是一个广泛使用的分布式任务队列,而在某些任务中,尤其是涉及到调用独立脚本的场景中,我们需要混合使用multipro…...

Django模板系统
1.常用语法 Django模板中只需要记两种特殊符号: {{ }}和 {% %} {{ }}表示变量,在模板渲染的时候替换成值,{% %}表示逻辑相关的操作。 2.变量 {{ 变量名 }} 变量名由字母数字和下划线组成。 点(.)在模板语言中有…...

15. 文件操作
一、什么是文件 文件(file)通常是磁盘或固态硬盘上的一段已命名的存储区。它是指一组相关数据的有序集合。这个数据集合有一个名称,叫做文件名。文件名 是文件的唯一标识,以便用户识别和引用。文件名包括 3 个部分:文件…...

ARM中断控制器架构与配置实践详解
1. ARM中断控制器架构解析在嵌入式系统设计中,中断控制器作为处理器与外围设备间的关键枢纽,其性能直接影响系统的实时性和可靠性。ARM1176JZF-S处理器采用了两级中断控制架构:位于开发芯片中的TrustZone中断控制器(TZIC)和通用中断控制器(GI…...

你的Type-C设备为什么容易坏?可能是静电防护没做对!从手机到笔记本的防护方案拆解
Type-C设备静电防护全指南:从原理到实战的完整解决方案 每次插拔Type-C数据线时,那个微小的火花可能正在悄悄摧毁你的设备。我拆解过上百台因静电损坏的电子产品,发现90%的Type-C接口故障都始于那个看似无害的瞬间放电现象。这种现象在干燥季…...

【2026年5月16日最新】别再用Cursor了!这5款AI编程神器让我效率暴涨300%
2026年5月,AI编程工具迎来了史诗级更新潮。OpenAI发布GPT-5.5后,代码理解和工程重构能力达到历史最强;字节跳动Trae凭借全链路AI原生IDE和免费无限制政策迅速崛起;DeepSeek V4更是用极致算法效率撕开了算力铁幕 。作为一名每天和代…...

MCP服务器构建指南:安全连接AI与外部工具的核心架构与实战
1. 项目概述:MCP服务器生态的构建者如果你最近在关注AI智能体开发,尤其是围绕Claude、Cursor这类工具的生态,那么“MCP”这个词大概率已经在你耳边出现了无数次。ViswaSrimaan/mcp_servers这个项目,正是这个新兴浪潮中的一个关键基…...

对比Taotoken与直接购买官方API在账单清晰度上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比Taotoken与直接购买官方API在账单清晰度上的差异 效果展示类,从个人开发者或小团队的实际使用经历出发,…...

Windows和Office激活难题?3分钟永久激活的智能方案
Windows和Office激活难题?3分钟永久激活的智能方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成只读模…...

5分钟实现专业级3D高斯泼溅渲染:Unity场景重建终极指南
5分钟实现专业级3D高斯泼溅渲染:Unity场景重建终极指南 【免费下载链接】UnityGaussianSplatting Toy Gaussian Splatting visualization in Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityGaussianSplatting 想象一下,你花费数小时扫…...

预训练+微调实现TVA模型快速部署
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
实现代码))
告别暴力枚举:用‘换根DP’思想5步拆解GDCPC L题‘启航者’(附O(n)实现代码)
从暴力枚举到换根DP:5步拆解树上路径极值问题 在算法竞赛中,树形结构上的动态规划(DP)问题一直是考察重点,而"换根DP"作为一种高效解决树上路径相关问题的技巧,能帮助我们将O(n)的暴力枚举优化到…...

终极Switch游戏安装指南:5分钟掌握Awoo Installer的完整教程
终极Switch游戏安装指南:5分钟掌握Awoo Installer的完整教程 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装而烦…...