【NLP 9、实践 ① 五维随机向量交叉熵多分类】
目录
五维向量交叉熵多分类
规律:
实现:
1.设计模型
2.生成数据集
3.模型测试
4.模型训练
5.对训练的模型进行验证
调用模型
你的平静,是你最强的力量
—— 24.12.6
五维向量交叉熵多分类
规律:
x是一个五维(索引)向量,对x做五分类任务
改用交叉熵实现一个多分类任务,五维随机向量中最大的数字在哪维就属于哪一类
实现:
1.设计模型
Linear():模型函数中定义线性层
activation = nn.Softmax(dim=1):定义激活层为softmax激活函数
nn.CrossEntropyLoss() / nn.functional.cross_entropy:定义交叉熵损失函数
pyTorch中定义的交叉熵损失函数内部封装了softMax函数, 而使用交叉熵必须使用softMax函数,对数据进行归一化
经过 Softmax 归一化后,输出向量的每个元素可以被解释为样本属于相应类别的概率。这使得我们能够直接比较不同类别上的概率大小,并且与真实的类别概率分布(如one-hot编码)进行合理的对比。
例如,在一个三分类问题中,经过 Softmax 后的输出可能是[0.2,0.3,0.5],我们可以直观地说样本属于第三类的概率是 0.5,这是一个符合概率意义的解释
forward函数,前向计算,定义网络的使用方式,声明模型计算过程
# 1.设计模型
class TorchModel(nn.Module):def __init__(self, input_size):super(TorchModel, self).__init__()# 预测出一个五维的向量,五维向量代表五个类别上的概率分布self.linear = nn.Linear(input_size, 5) # 线性层# 类交叉熵写法:CrossEntropyLoss() 函数交叉熵写法:cross_entropy# nn.CrossEntropyLoss() pycharm交叉的熵损失函数内部封装了softMax函数, 而使用交叉熵必须使用softMax函数self.loss = nn.functional.cross_entropy # loss函数采用交叉熵损失self.activation = nn.Softmax(dim=1)# 当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):# 输入过第一个网络层y_pred = self.linear(x) # (batch_size, input_size) -> (batch_size, 1)if y is not None:return self.loss(y_pred, y) # 预测值和真实值计算损失else:return self.activation(y_pred) # 输出预测结果# return y_pred2.生成数据集
由于题目要求,要在一个五维随机向量中查找标量最大的数所在维度,所以用np.random函数随机生成一个五维向量,然后通过np.argmax函数找出生成向量中最大标量所对应的维度,并将其作为数据 x 的标注 y 返回
当我们输出一串数字,要告诉模型输出的是一串单独的数而不是一串样本时,需要用到 "[ ]",换句话说当y是单独的一个数(标量)时,才需要加“[ ]”
而该模型输出的预测结果是一个向量,而不是一个数(标量的概率)时,不需要拼在一起
# 2.生成数据集标签label 数据构建
# 生成一个样本, 样本的生成方法,代表了我们要学习的规律,随机生成一个5维向量,如果第一个值大于第五个值,认为是正样本,反之为负样本
def build_sample():x = np.random.random(5)# 获取最大值对应的索引max_index = np.argmax(x)return x, max_index# 随机生成一批样本
# 正负样本均匀生成
def build_dataset(total_sample_num):X = []Y = []# 随机生成样本,total_sample_num 生成的随机样本数for i in range(total_sample_num):x, y = build_sample()X.append(x)# 当我们输出一串数字,要告诉模型输出的是一串单独的数而不是一串样本时,需要用到"[]",换句话说当y是单独得一个数(标量)时,才需要加“[]”# 而该模型输出的预测结果是一个向量,而不是一个数(标量的概率)时,不需要拼在一起Y.append(y)X_array = np.array(X)Y_array = np.array(Y)# 一般torch中的Long整形类型用来判定类型return torch.FloatTensor(X_array), torch.LongTensor(Y_array)3.模型测试
用来测试每轮模型预测的精确度
model.eval():声明模型框架在这个函数中不做训练
with torch.no_grad():在模型测试的部分中,声明是测试函数,不计算梯度,增加模型训练效率
zip():zip 函数是一个内置函数,用于将多个可迭代对象(如列表、元组、字符串等)中对应的元素打包成一个个元组,然后返回由这些元组组成的可迭代对象(通常是一个 zip 对象)。如果各个可迭代对象的长度不一致,那么 zip 操作会以最短的可迭代对象长度为准。
# 3.模型测试
# 用来测试每轮模型的准确率
def evaluate(model):model.eval()test_sample_num = 100x, y = build_dataset(test_sample_num)print("本次预测集中共有%d个正样本,%d个负样本" % (sum(y), test_sample_num - sum(y)))correct, wrong = 0, 0with torch.no_grad():y_pred = model(x) # 模型预测 model.forward(x)for y_p, y_t in zip(y_pred, y): # 与真实标签进行对比# np.argmax是求最大数所在维,max求最大数,torch.argmax是求最大数所在维if torch.argmax(y_p) == int(y_t):correct += 1 # 正确预测加一else:wrong += 1 # 错误预测加一print("正确预测个数:%d, 正确率:%f" % (correct, correct / (correct + wrong)))return correct / (correct + wrong)4.模型训练
① 配置参数
② 建立模型
③ 选择优化器(Adam)
④ 读取训练集
⑤ 训练过程
Ⅰ、model.train():设置训练模式
Ⅱ、对训练集样本开始循环训练(循环取出训练数据)
Ⅲ、根据模型函数和损失函数的定义计算模型损失
Ⅳ、计算梯度
Ⅴ、通过梯度用优化器更新权重
Ⅵ、计算完一轮训练数据后梯度进行归零,下一轮重新计算
torch.save(model.state_dict(), "model.pt"):将模型保存为model.pt文件
一般任务不同只需更改数据读取(步骤③)和模型构建(步骤①)内容,训练过程一般无需更改,evaluate测试代码可能也需更改,因为不同模型测试正确率的方式不同
# 4.模型训练
def main():# 配置参数epoch_num = 20 # 训练轮数batch_size = 20 # 每次训练样本个数train_sample = 5000 # 每轮训练总共训练的样本总数input_size = 5 # 输入向量维度learning_rate = 0.001 # 学习率# ① 建立模型model = TorchModel(input_size)# ② 选择优化器optim = torch.optim.Adam(model.parameters(), lr=learning_rate)log = []# ③ 创建训练集,正常任务是读取训练集train_x, train_y = build_dataset(train_sample)# 训练过程# 轮数进行自定义for epoch in range(epoch_num):model.train()watch_loss = []# ④ 读取数据集for batch_index in range(train_sample // batch_size):x = train_x[batch_index * batch_size : (batch_index + 1) * batch_size]y = train_y[batch_index * batch_size : (batch_index + 1) * batch_size]# ⑤ 计算lossloss = model(x, y) # 计算loss model.forward(x,y)# ⑥ 计算梯度loss.backward() # 计算梯度# ⑦ 权重更新optim.step() # 更新权重# ⑧ 梯度归零optim.zero_grad() # 梯度归零watch_loss.append(loss.item())# 一般任务不同只需更改数据读取(步骤③)和模型构建(步骤①)内容,训练过程一般无需更改,evaluate测试代码可能也需更改,因为不同模型测试正确率的方式不同print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))acc = evaluate(model) # 测试本轮模型结果log.append([acc, float(np.mean(watch_loss))])# 保存模型torch.save(model.state_dict(), "model.pt")# 画图print(log)plt.plot(range(len(log)), [l[0] for l in log], label="acc") # 画acc曲线plt.plot(range(len(log)), [l[1] for l in log], label="loss") # 画loss曲线plt.legend()plt.show()return5.对训练的模型进行验证
调用main函数
if __name__ == "__main__":main()

调用模型
model.eval():声明模型框架在这个函数中不做训练
predict("model.pt", test_vec):调用模型存储的文件model.pt,通过调用模型对数据进行预测
# 使用训练好的模型做预测
def predict(model_path, input_vec):input_size = 5model = TorchModel(input_size)# 加载训练好的权重model.load_state_dict(torch.load(model_path, weights_only=True))# print(model.state_dict())model.eval() # 测试模式,不计算梯度with torch.no_grad():# 输入一个真实向量转成Tensor,让模型forward一下result = model.forward(torch.FloatTensor(input_vec)) # 模型预测for vec, res in zip(input_vec, result):# python中,round函数是对浮点数进行四舍五入print("输入:%s, 预测类别:%s, 概率值:%s" % (vec, torch.argmax(res), res)) # 打印结果if __name__ == "__main__":test_vec = [[0.97889086,0.15229675,0.31082123,0.03504317,0.88920843],[0.74963533,0.5524256,0.95758807,0.95520434,0.84890681],[0.00797868,0.67482528,0.13625847,0.34675372,0.19871392],[0.09349776,0.59416669,0.92579291,0.41567412,0.1358894]]predict("model.pt", test_vec)
相关文章:
【NLP 9、实践 ① 五维随机向量交叉熵多分类】
目录 五维向量交叉熵多分类 规律: 实现: 1.设计模型 2.生成数据集 3.模型测试 4.模型训练 5.对训练的模型进行验证 调用模型 你的平静,是你最强的力量 —— 24.12.6 五维向量交叉熵多分类 规律: x是一个五维(索引)向量ÿ…...
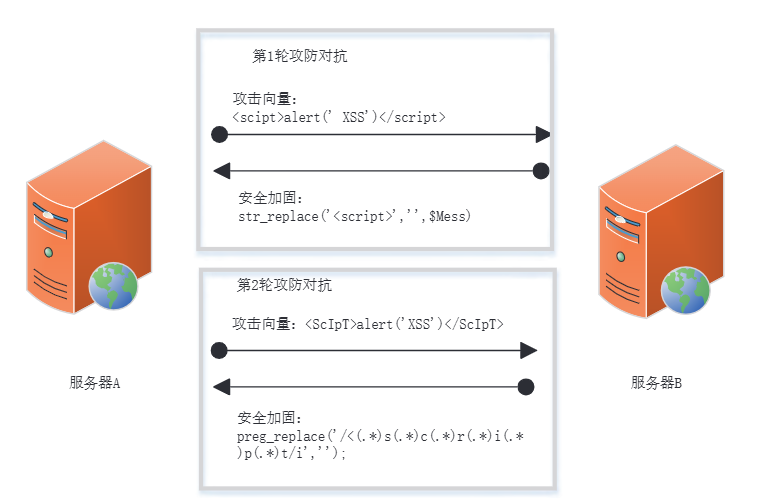
信息系统安全防护攻防对抗式实验教学解决方案
一、引言 在网络和信息技术迅猛发展的今天,信息系统已成为社会各领域的关键基础设施,它支撑着电子政务、电子商务、科学研究、能源、交通和社会保障等多个方面。然而,信息系统也面临着日益严峻的网络安全威胁,网络攻击手段层出不…...

【笔记2-4】ESP32:freertos任务创建
主要参考b站宸芯IOT老师的视频,记录自己的笔记,老师讲的主要是linux环境,但配置过程实在太多问题,就直接用windows环境了,老师也有讲一些windows的操作,只要代码会写,操作都还好,开发…...

2024年12月6日Github流行趋势
项目名称:lobe-chat 项目维护者:arvinxx, semantic-release-bot, canisminor1990, lobehubbot, renovate项目介绍:一个开源的现代化设计的人工智能聊天框架。支持多AI供应商(OpenAI / Claude 3 / Gemini / Ollama / Qwen / DeepSe…...

matlab读取NetCDF文件
matlab对NetCDF文件进行信息获取和读取数据 文章目录 前言一、什么是NetCDF文件二、读取NetCDF文件数据 1.引入库 2.读入数据总结 前言 在气象学中,许多气象数据存储在NetCDF文件中,后缀为.nc,通常可以用NCL、python和MATLAB等对该…...
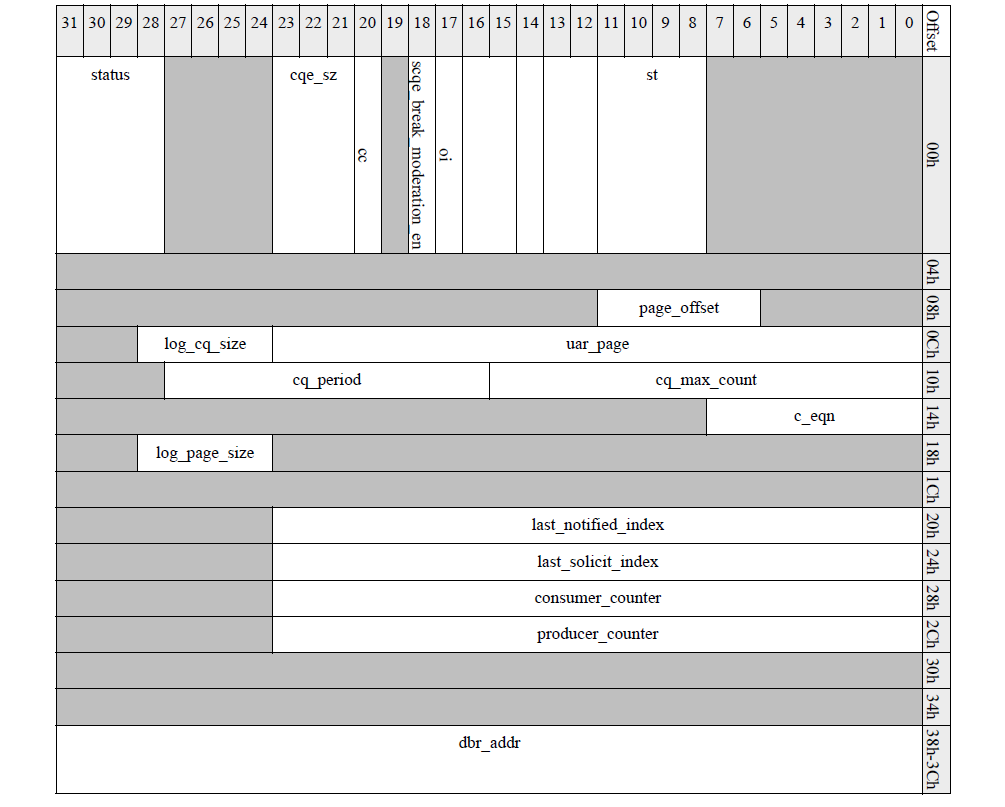
RDMA驱动学习(三)- cq的创建
用户通过ibv_create_cq接口创建完成队列,函数原型和常见用法如下,本节以该用法为例看下cq的创建过程。 struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe,void *cq_context,struct ibv_comp_channel *channel,int comp_vector); cq …...
(subprocess))
Flask使用Celery与多进程管理:优雅处理长时间任务与子进程终止技巧(multiprocessing)(subprocess)
在许多任务处理系统中,我们需要使用异步任务队列来处理繁重的计算或长时间运行的任务,如模型训练。Celery是一个广泛使用的分布式任务队列,而在某些任务中,尤其是涉及到调用独立脚本的场景中,我们需要混合使用multipro…...

Django模板系统
1.常用语法 Django模板中只需要记两种特殊符号: {{ }}和 {% %} {{ }}表示变量,在模板渲染的时候替换成值,{% %}表示逻辑相关的操作。 2.变量 {{ 变量名 }} 变量名由字母数字和下划线组成。 点(.)在模板语言中有…...

15. 文件操作
一、什么是文件 文件(file)通常是磁盘或固态硬盘上的一段已命名的存储区。它是指一组相关数据的有序集合。这个数据集合有一个名称,叫做文件名。文件名 是文件的唯一标识,以便用户识别和引用。文件名包括 3 个部分:文件…...

清风数学建模学习笔记——Topsis法
数模评价类(2)——Topsis法 概述 Topsis:Technique for Order Preference by Similarity to Ideal Solution 也称优劣解距离法,该方法的基本思想是,通过计算每个备选方案与理想解和负理想解之间的距离,从而评估每个…...

组合总和习题分析
习题:(leetcode39) 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 c…...

基于eFramework车控车设中间件介绍
车设的发展,起源于汽车工业萌芽之初,经历了机械式操作的原始粗犷,到电子式调控技术的巨大飞跃,到如今智能化座舱普及,远程车控已然成为汽车标配,车设功能选项也呈现出爆发式增长,渐趋多元繁杂。…...

L17.【LeetCode笔记】另一棵树的子树
目录 1.题目 代码模板 2.分析 3.代码 4.提交结果 1.题目 https://leetcode.cn/problems/subtree-of-another-tree/description/ 给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ÿ…...

BGP通过route-policy路由策略调用ip-prefix网络前缀实现负载均衡与可靠性之AS-path属性
一、实验场景 1、loopback0与loopback1模拟企业实际环境中的某个网段。 2、本例目标总公司AR3的1.1.1.1/32网段到分公司AR4的3.3.3.3/32的流量从上方的AS500自治系统走。 3、本例目标总公司AR3的4.4.4.4/32网段到分公司AR4的2.2.2.2/32的流量从下面的AS300、AS400自治系统走。…...

每日速记10道java面试题14-MySQL篇
其他资料 每日速记10道java面试题01-CSDN博客 每日速记10道java面试题02-CSDN博客 每日速记10道java面试题03-CSDN博客 每日速记10道java面试题04-CSDN博客 每日速记10道java面试题05-CSDN博客 每日速记10道java面试题06-CSDN博客 每日速记10道java面试题07-CSDN博客 每…...

内存图及其画法
所有的文件都存在硬盘上,首次使用的时候才会进入内存 进程:有自己的Main方法,并且依赖自己Main运行起来的程序。独占一块内存区域,互不干扰。内存中有一个一个的进程。 操作系统只认识c语言。操作系统调度驱动管理硬件࿰…...

Ansys Maxwell:Qi 无线充电组件
Qi 无线充电采用感应充电技术,无需物理连接器或电缆,即可将电力从充电站传输到兼容设备。由 WPC 管理的 Qi 标准确保了不同无线充电产品之间的互操作性。以下是 Qi v1.3 标准的核心功能: Qi v1.3 标准的主要特点 身份验证:确保充…...

【Shell 脚本实现 HTTP 请求的接收、解析、处理逻辑】
以下是一个实现客户端对 Shell HTTP 服务发起 POST 请求并传入 JSON 参数的完整示例。Shell 服务会解析收到的 JSON 数据,根据内容执行操作。 服务端脚本:http_server.sh 以下脚本使用 netcat (nc) 来监听 HTTP 请求,并通过 jq 工具解析 JSO…...

【北京迅为】iTOP-4412全能版使用手册-第六十七章 USB鼠标驱动详解
iTOP-4412全能版采用四核Cortex-A9,主频为1.4GHz-1.6GHz,配备S5M8767 电源管理,集成USB HUB,选用高品质板对板连接器稳定可靠,大厂生产,做工精良。接口一应俱全,开发更简单,搭载全网通4G、支持WIFI、蓝牙、…...

【青牛科技】拥有两个独立的、高增益、内部相位补偿的双运算放大器,可适用于单电源或双电源工作——D4558
概述: D4558内部包括有两个独立的、高增益、内部相位补偿的双运算放大器,可适用于单电源或双电源工作。该电路具有电压增益高、噪声低等特点。主要应用于音频信号放大,有源滤波器等场合。 D4558采用DIP8、SOP8的封装形式 主要特点ÿ…...

开源硬件性能遥测工具openclaw_telemetry:从数据采集到可视化实战
1. 项目概述:从开源遥测数据中洞察硬件性能在硬件开发和性能调优的领域,数据是驱动决策的基石。我们常常需要实时监控CPU、GPU、内存、温度、功耗等一系列关键指标,以评估系统稳定性、定位性能瓶颈或验证优化效果。然而,构建一套稳…...

Claude新政,抛弃最忠实的Agent用户
Anthropic 过河拆桥,终将遭反噬。 Anthropic 将 Agent SDK 用量从订阅中剥离,按 API 零售价另给固定额度。重度用户的可用量缩水近十倍。同一周,OpenAI 向企业用户推出 Codex 两个月免费迁移。ASI 决赛圈的第一场定价战,开打了。 …...

2026年靠谱物联网供应商榜
作为深耕物联网领域五年的工程师,我见过太多“看起来很美好”的技术方案——设备接入率低、数据延迟高、多协议适配困难,尤其当项目涉及复杂环境时,这些问题会被无限放大。我们团队在实践中发现,许多物联网平台在核心算法层面缺乏…...

【CTF】【Misc 文件类型】工具与流程
工具准备 本人为方便 CTF 部分 Misc 类型的解题,制作如下集成软件。本软件集成常用功能,能一站式解决大多数 Misc 文件类问题,省去切换工具的繁琐流程,大大提高解题效率,且界面简洁易用。且预留了拓展接口,…...

Adafruit IO物联网平台:从零构建环境监测与报警系统
1. 项目概述:为什么你需要一个像Adafruit IO这样的物联网平台?如果你玩过Arduino、树莓派或者任何单片机,肯定遇到过这样的场景:费了老大劲写代码让传感器读出数据,结果这些数据要么在串口监视器里一闪而过,…...

【NotebookLM图书馆学研究实战指南】:20年图情专家亲授AI时代知识管理新范式
更多请点击: https://codechina.net 第一章:NotebookLM图书馆学研究的范式革命 传统图书馆学研究长期依赖人工文献综述、卡片目录索引与线性知识组织方式,而NotebookLM的引入正从根本上重构知识发现、关联与推理的底层逻辑。作为Google推出的…...

如何彻底移除Windows Defender:13项核心服务完整卸载与系统性能优化终极指南
如何彻底移除Windows Defender:13项核心服务完整卸载与系统性能优化终极指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitco…...

别让电流倒灌毁了你的MCU!手把手教你用肖特基二极管和MOS管搞定电平转换电路
嵌入式系统电平转换电路设计实战:阻断电流倒灌的5种硬件方案 当3.3V单片机需要驱动5V传感器时,或者5V逻辑器件要与1.8V处理器通信时,电平转换电路就成了系统稳定的关键屏障。去年我在工业控制器项目中就曾遇到一个典型问题:当5V外…...

ThinkPad嵌入式控制器深度解析:TPFanCtrl2散热优化实践方案
ThinkPad嵌入式控制器深度解析:TPFanCtrl2散热优化实践方案 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 在移动工作站领域,ThinkPad以其卓越…...

Loop窗口管理:终极Mac多窗口高效布局指南
Loop窗口管理:终极Mac多窗口高效布局指南 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是不是经常在Mac上同时打开十几个窗口,然后迷失在层层叠叠的界面中?写代码…...