显卡(Graphics Processing Unit,GPU)架构详细解读
显卡架构主要分为两大类:GPU 核心架构(也称为图形处理单元架构)和显卡的其他组件(如内存、控制器、输出接口等)。本篇文章将对显卡架构进行详细分析,重点介绍 GPU 核心架构、显卡计算单元、显存结构、显卡管线、以及显卡与主机系统的协同工作等。
1. 显卡架构的基本组成
显卡架构可以分为以下几个主要部分:
1.1 GPU 核心(计算单元)
GPU 核心是显卡的核心部分,负责执行图形渲染和计算任务。GPU 核心通常由多个 流处理器(Shader Processor) 和 多处理单元(SM,Streaming Multiprocessors) 组成。
- 流处理器(Shader Processor):流处理器是 GPU 中最基本的计算单元,负责执行各种图形运算和并行计算。每个流处理器处理多个数据流,并独立进行计算。
- 多处理单元(SM):SM 是由多个流处理器组成的单元,通常用于处理一个工作组的任务。每个 SM 拥有多个线程执行单元,这些线程能够同时进行计算,充分利用 GPU 的并行计算能力。
GPU 的计算能力不仅体现在流处理器的数量上,还体现在 指令集 和 并行性 的设计上。例如,NVIDIA 的 CUDA 架构与 AMD 的 GCN(Graphics Core Next)架构,在指令集和线程调度方面有所不同,但都极力优化并行计算。
1.2 显存(VRAM)
显存是专为显卡设计的内存,用于存储图形渲染数据、纹理、着色器代码、帧缓冲等。显存的带宽和容量对显卡性能至关重要。
显存的种类有:
- GDDR(Graphics Double Data Rate):是目前最常见的显存类型,用于高性能显卡。GDDR 的带宽较高,可以快速传输大数据量的图形和计算信息。
- HBM(High Bandwidth Memory):是新一代显存,采用堆叠技术,可以在更小的体积下提供更高的带宽和更低的功耗。HBM 广泛用于高端显卡和计算密集型任务中。
显存的带宽直接影响着显卡在图形渲染和计算任务中的速度,尤其是在高分辨率、复杂场景下,显存的容量与带宽决定了显卡的处理能力。
1.3 显卡控制器(调度器)
显卡控制器负责调度和协调不同硬件组件之间的工作,保证计算任务的顺利进行。GPU 控制器可以执行以下任务:
- 任务调度:控制各个流处理器、SM 单元执行的任务,并合理分配计算负载。
- 数据管理:管理显存中的数据流动,将需要的图形数据从显存加载到计算单元中,处理后再存回显存。
- 任务同步:确保并行计算过程中,多个线程的执行顺序和同步,避免冲突。
1.4 显卡管线
显卡管线是指 GPU 执行图形渲染任务的流程。显卡管线通常可以分为多个阶段,每个阶段都负责特定的计算任务。以下是常见的显卡渲染管线的几个主要阶段:
- 顶点处理:顶点处理阶段负责对输入的顶点数据进行变换和裁剪,计算顶点的最终位置。常见的操作包括坐标变换、透视变换等。
- 光栅化:将顶点处理后得到的几何数据转换为像素数据。此时,图形的三维数据被转换为二维图像。
- 纹理映射:将图像纹理应用到每个像素上,为每个像素增加细节信息。
- 光照计算:根据场景中的光源和材质信息计算每个像素的颜色和亮度。常见的算法包括 Phong 着色模型、Blinn-Phong 模型等。
- 像素着色(片段着色):最后通过像素着色器决定每个像素的最终颜色,可能还包括抗锯齿、阴影、反射等高级效果。
显卡管线的每个阶段都由专门的硬件单元执行,例如 顶点着色器(Vertex Shader)、片段着色器(Fragment Shader)、几何着色器(Geometry Shader) 等。现代 GPU 允许高度可编程的管线,使得开发者能够通过编写自定义着色器代码,控制图形渲染的每个细节。
1.5 显卡接口与输出
显卡通过 PCIe(Peripheral Component Interconnect Express) 接口与主板进行连接。PCIe 提供了高速数据传输通道,显卡通过该通道从系统内存中获取数据,传输图像信息到显示器。
显卡的输出端口可以包括 HDMI、DisplayPort、DVI 等,用于连接显示器或其他输出设备。现代显卡通常支持多显示器输出,可以驱动多个高分辨率显示器。
1.6 显卡的电源管理(VRM)
显卡的 VRM(电压调节模块)负责管理显卡各个部分的电压。显卡需要稳定的电力供应来保证性能,尤其在高负载情况下,VRM 会根据负载情况调整电压,保证显卡的稳定运行。
高端显卡通常配备更强大的 VRM,能够提供更高的电压和更大的功率,支持超频操作和长时间高负载运行。
2. 显卡架构实例
2.1 NVIDIA CUDA 架构
NVIDIA 的 CUDA(Compute Unified Device Architecture)架构是其 GPU 的核心架构,特别适用于并行计算。CUDA 架构将 GPU 分为多个 多处理单元(SM),每个 SM 包含多个流处理器。CUDA 架构使得开发者可以利用 GPU 进行通用计算(GPGPU,General-Purpose GPU Computing),如科学计算、深度学习等。
CUDA 架构的核心特点包括:
- 并行计算:每个流处理器可以同时处理多个数据流,使得 GPU 能够高效地执行大规模并行任务。
- 计算能力的提升:CUDA 支持高精度计算,适用于浮点运算和矩阵运算等计算密集型任务。
- 可编程性:通过 CUDA 编程模型,开发者可以编写自定义的核函数,并在 GPU 上高效执行。
2.2 AMD RDNA 架构
AMD 的 RDNA(Radeon DNA) 架构是其最新的显卡架构,旨在提高图形性能和计算能力。RDNA 架构继承了 AMD 早期的 GCN(Graphics Core Next)架构,但在性能、能效和可编程性上进行了优化。
RDNA 架构的主要特点包括:
- 改进的计算单元(CU):RDNA 将计算单元(CU)与早期的 GCN 架构相比进行了优化,减少了每个 CU 的资源占用,提高了性能。
- 更高的时钟频率:RDNA 架构支持更高的时钟频率,从而提升显卡的图形渲染能力。
- 增强的能效:RDNA 在图形性能提升的同时,显著改善了功耗效率,适用于高性能计算任务和长时间负载运行。
2.3 Intel Xe 架构
Intel 的 Xe 架构是其进军显卡市场的重要战略。Xe 架构旨在提供多用途的图形解决方案,不仅适用于游戏和娱乐,还包括深度学习和高性能计算。
Xe 架构的特点包括:
- 多核设计:Xe 架构采用多核设计,支持高效的并行计算。
- 集成显卡:Xe 架构的低功耗版本被集成到 Intel 的处理器中,提供优异的图形性能。
- 面向未来的可扩展性:Xe 架构支持大规模并行计算,并能够适应未来对显卡性能的更高需求。
3. 总结
显卡架构的设计直接影响着显卡的性能和应用范围。GPU 核心架构通过高度的并行性和灵活的计算能力,提供了强大的图形渲染和计算加速能力。随着显卡应用的多样化,显卡架构不断发展,从图形渲染到深度学习、科学计算等领域,显卡正在扮演越来越重要的角色。未来显卡的架构将继续朝着更高效、更强大、更灵活的方向发展,满足日益增长的计算需求。
相关文章:
架构详细解读)
显卡(Graphics Processing Unit,GPU)架构详细解读
显卡架构主要分为两大类:GPU 核心架构(也称为图形处理单元架构)和显卡的其他组件(如内存、控制器、输出接口等)。本篇文章将对显卡架构进行详细分析,重点介绍 GPU 核心架构、显卡计算单元、显存结构、显卡管…...

【大语言模型】ACL2024论文-24 图像化歧义:Winograd Schema 挑战的视觉转变
【大语言模型】ACL2024论文-24 图像化歧义:Winograd Schema 挑战的视觉转变 目录 文章目录 【大语言模型】ACL2024论文-24 图像化歧义:Winograd Schema 挑战的视觉转变目录摘要研究背景问题与挑战如何解决核心创新点算法模型实验效果(包含重要…...

AcWing 2868. 子串分值
文章目录 前言代码思路 前言 还是实力不允许啊,要是实力允许我就一道一道中等题刷了。简单题真够呛。有些题看题解都是看老半天看不懂,假设是这种我是真感觉没必要钻研。我现在大三,要是看一遍题解看不懂就算了,果断放弃。真可以…...

如何进行 JavaScript 性能优化?
要进行 JavaScript 性能优化,我们可以从多个角度进行思考,主要包括减少页面渲染时间、减少内存占用、优化代码执行效率等。以下是优化的一些方法,并结合实际项目代码示例讲解。 目录结构 减少 DOM 操作 缓存 DOM 元素批量更新 DOM 优化 Jav…...

使用TCP编程实现简单登录功能
在Java中,使用TCP编程实现登录功能通常涉及以下步骤: 创建服务器端,监听特定端口,等待客户端连接。创建客户端,连接到服务器端。客户端发送用户名和密码到服务器端。服务器端验证用户名和密码。服务器端返回验证结果给…...

卷积神经网络(CNN)的层次结构
卷积神经网络(CNN)是一种以其处理图像和视频数据的能力而闻名的深度学习模型,其基本结构通常包括以下几个层次,每个层次都有其特定的功能和作用: 1. 输入层(Input Layer): 卷积神经网…...

操作系统文件管理相关习题2
文件管理的任务和功能文件管理 任务:对用户文件和系统文件进行组织管理,以方便用户使用,并保证文件的安全 功能:文件存储空间的管理,目录管理,文件读写管理和保护 目录管理 对目录管理的要求 实现按名存…...

react 通过ref调用子组件的方法
背景 父组件内引入了一个弹窗组件,弹窗组件使用了完全内聚的开发方法; 实现思路 父组件内通过ref获取的子组件,通过current调用子组件的方法,子组件需要通过forwardRef进行“包装”导出,通过useImperativeHandle暴露…...

【计算机网络】 —— 数据链路层(壹)
文章目录 前言 一、概述 1. 基本概念 2. 数据链路层的三个主要问题 二、封装成帧 1. 概念 2. 帧头、帧尾的作用 3. 透明传输 4. 提高效率 三、差错检测 1. 概念 2. 奇偶校验 3. 循环冗余校验CRC 1. 步骤 2. 生成多项式 3. 例题 4. 总结 四、可靠传输 1. 基本…...

AcWing 93. 递归实现组合型枚举
文章目录 前言代码思路 前言 今天晚上还有三个小时,写一晚上简单题。划水。 代码 #include<bits/stdc.h> using namespace std; int n,m; void dfs(int u,int sum,int state){if(sumn-u<m){return;//sum 表示当前选了 sum 个数字,假设把所有…...

vscode 折叠范围快捷键
vscode 折叠范围快捷键 问答 原文网址:https://www.n.cn/search/c830b29cb76146d08cae5074acfd4785 VSCode 折叠范围快捷键 在使用Visual Studio Code(VSCode)进行代码编辑时,掌握一些快捷键可以大大提高工作效率。以下是关于VSCode中折叠和…...

RabbitMQ 实现分组消费满足服务器集群部署
实现思路 使用扇出交换机(Fanout Exchange):扇出交换机会将消息广播到所有绑定的队列,确保每个消费者组都能接收到相同的消息。为每个消费者组创建独立的队列:每个消费者组拥有自己的队列,所有属于该组的消…...

Chromium网络调试篇-Fiddler 5.21.0 使用指南:捕获浏览器HTTP(S)流量(二)
概述 在上一篇文章中,我们介绍了Fiddler的基础功能和如何安装它。今天我们将深入探讨如何使用Fiddler来捕获HTTP请求,这是Fiddler的一个核心能力,对于前端开发者、测试人员以及安全研究人员来说非常有用。捕获HTTP请求可以帮助我们更好地理解…...

个人IP建设:简易指南
许多个体创业者面临的一个关键挑战是如何为其企业创造稳定的需求。 作为个体创业者,您无法使用营销团队,因此许多人通过推荐和他们的网络来产生需求。因此,扩大您的网络是发展您的业务和产生持续需求的最佳策略。 这就是个人IP和品牌发挥作…...

智能指针【C++11】
文章目录 智能指针std::auto_ptr std::unique_ptrstd::shared_ptrstd::shared_ptr的线程安全问题std::weak_ptr 智能指针 std::auto_ptr 管理权转移 auto_ptr是C98中引入的智能指针,auto_ptr通过管理权转移的方式解决智能指针的拷贝问题,保证一个资源…...

【Linux 篇】Docker 启动和停止的精准掌舵:操控指南
文章目录 【Linux篇】Docker 启动和停止的精准掌舵:操控指南前言docker基本命令1. 帮助手册 2. 指令介绍 常用命令1. 查看镜像2. 搜索镜像3. 拉取镜像4. 删除镜像5. 从Docker Hub拉取 容器的相关命令1. 查看容器2. 创建与启动容器3. 查看镜像4. 启动容器5. 查看容器…...

Cursor vs VSCode:主要区别与优势分析
Cursor - The AI Code Editor 1. AI 集成能力 Cursor的优势 原生AI集成: # Cursor可以直接通过快捷键调用AI # 例如:按下 Ctrl K 可以直接获取代码建议 def complex_function():# 在这里,你可以直接询问AI如何实现功能# AI会直接在编辑器中…...

从单体到微服务:如何借助 Spring Cloud 实现架构转型
一、Spring Cloud简介 Spring Cloud 是一套基于 Spring 框架的微服务架构解决方案,它提供了一系列的工具和组件,帮助开发者快速构建分布式系统,尤其是微服务架构。 Spring Cloud 提供了诸如服务发现、配置管理、负载均衡、断路器、消息总线…...
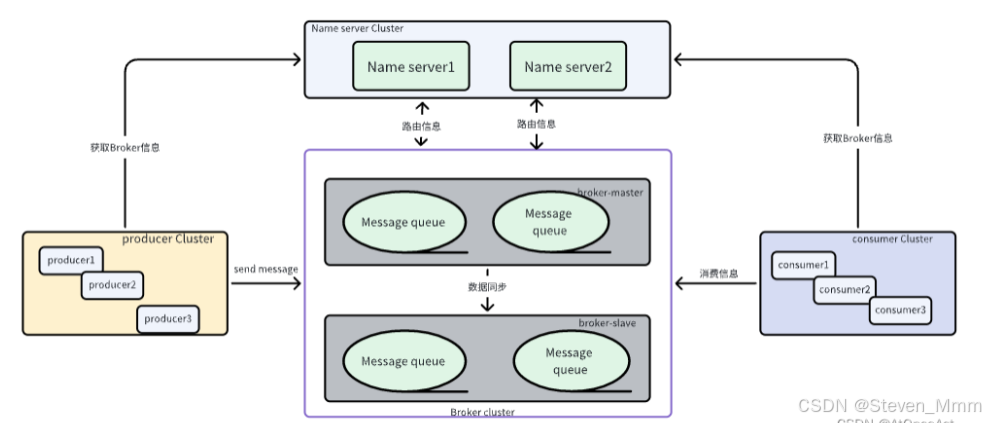
RocketMq基础学习+SpringBoot集成
学习贴:参考https://blog.csdn.net/zhiyikeji/article/details/138286088 文章目录 普通消息顺序消息延迟消息批量消息事务消息 SpringBoot整合RocketMQ 3.1 NameServer NameServer是一个简单的路由注册中心,支持Topic和Broker的动态注册和发现。作用主…...

分布式cap
P(分区安全)都能保证,就是在C(强一致)和A(性能)之间做取舍。 (即立马做主从同步,还是先返回写入结果等会再做主从同步。类似的还有,缓存和db之间的同步。&am…...

FastbootEnhance 完整指南:Windows 上最友好的 Fastboot 工具箱与 Payload 提取器
FastbootEnhance 完整指南:Windows 上最友好的 Fastboot 工具箱与 Payload 提取器 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 还在…...

大模型长对话记忆难题:LightMem轻量记忆系统原理与实战
1. 项目概述:当大模型遇上“记忆”瓶颈 最近在折腾大语言模型应用时,我遇到了一个挺典型的问题:想让模型记住更多、更长的对话历史,但无论是直接增加上下文窗口,还是用传统的向量数据库做检索增强,都感觉差…...

基于电阻分压网络的传感器复用与蓝牙报警系统设计
1. 项目概述 在物联网和智能家居领域,报警系统是一个经典且实用的入门项目。它不仅是学习嵌入式开发的绝佳起点,更能直接解决现实生活中的安防需求。市面上成熟的商业报警系统往往价格不菲且功能固化,而基于开源硬件和软件的自制方案…...

Linux主机资产标识实战指南
Linux主机资产标识实战指南本文面向具备一定 Linux 基础的技术人员,围绕主机资产标识展开,重点讨论主机命名、标签规范和资产映射。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

企业内如何通过Taotoken实现大模型API的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过Taotoken实现大模型API的统一管理与审计 对于需要将大模型能力集成到内部系统的企业而言,直接让各个团队…...

移动Git客户端:Android上的完整版本控制解决方案
移动Git客户端:Android上的完整版本控制解决方案 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 在移动开发日益普及的今天,开发者需要在不同场景下管理代码版本。移动Git客户端MGit为Andro…...

挑战 100ms 延迟极限:深度拆解 dograh,构建企业级开源 WebRTC 实时语音智能体平台
发布日期: 2026-05-18标签: #VoiceAgent #WebRTC #语音智能体 #dograh #大模型 #实时音视频一、 引言在 2026 年,随着大模型多模态能力的爆发,传统的“打字输入、文字输出”交互模式正迅速向“纯语音实时对讲”演进。然而…...

Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器
Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器 在仓储巡检、展厅导览等场景中,机器人需要频繁执行多目标点任务序列。传统编程方式每次修改路径都需要重新编译代码,而Rviz的Publish Point功能配合定制化开发,可以将…...

初创团队如何借助 Taotoken 实现低成本且灵活的大模型能力集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助 Taotoken 实现低成本且灵活的大模型能力集成 对于资源有限的初创技术团队而言,在开发新产品时集成 A…...
)
NotebookLM思维导图生成响应延迟超8秒?92%用户忽略的3个文档预处理致命陷阱(附自动化清洗脚本)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM思维导图生成响应延迟超8秒?现象复现与归因定位 在 NotebookLM v2.3.1 环境中,用户频繁反馈「思维导图生成」功能存在显著延迟——实测端到端响应时间普遍达 8.2–14.…...