【服务器监控】grafana+Prometheus+node exporter详细部署文档
我们在进行测试时,不可能一直手动看着服务器的性能消耗,这时候就需要有个工具替我们监控服务器的性能消耗。这里记录下grafana+Prometheus+nodeExporter的组合用于监控服务器。
简单介绍:
grafana:看板工具,所有采集的性能数据都会展示在这个看板上,官网: link
Prometheus: 监控系统,数据的采集、存储、查询等主要功能都是在它这里,参考文档: link
node_exporter:其是Prometheus的一个采集组件,可以用来采集机器上的数据,并暴露接口给Prometheus,以此将数据传过去。
这是prometheus官网的架构图,可以参考这个看一下

我这里简单概述一下我们使用到的功能,即node_exporter采集机器节点上的性能数据,并将数据传给Prometheus处理,grafana再从Prometheus那里获取数据展示在看板上。(exporter有多种类型,比如采集容器的,mysql的,这里node_exporter直接是采集整个机器的)
本文grafana和Prometheus是使用docker安装部署的,如果机器上未装docker,可参考链接: link
本文为最新的安装流程,可直接按照该流程安装部署。
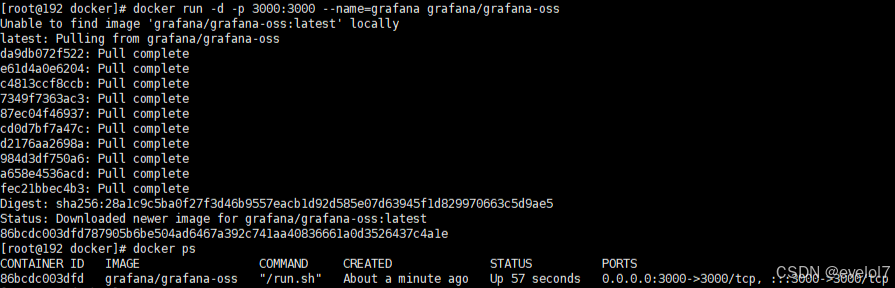
1.安装grafana
命令为:
docker run -d -p 3000:3000 --name=grafana grafana/grafana-oss
2.安装Prometheus
1.配置Prometheus的配置文件
mkdir -p /opt/monitor/prometheus
tee /opt/monitor/prometheus/prometheus.yml <<- 'EOF'
global:# 拉取规则scrape_interval: 10s# 执行规则频率evaluation_interval: 10sscrape_configs:- job_name: prometheus # 任务名static_configs:- targets: ['localhost:9100'] # 地址和端口,注意如果是docker安装的话,这个loalhost要替换成ip地址
EOF
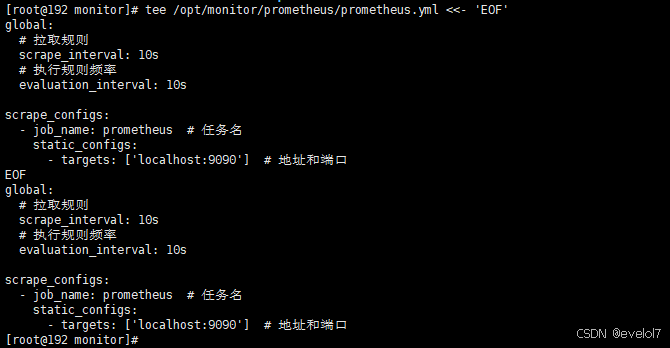
这里的地址如果是采集本机的,写localhost即可,要是采集其它机器的,可以填对应的ip(这里的端口不是9090,而是9100,与下面的node_exporter对应的;而且如果是docker安装的话,这个loalhost要替换成机器的ip地址,不然容器内部根据localhost可识别不了机器实际的ip)
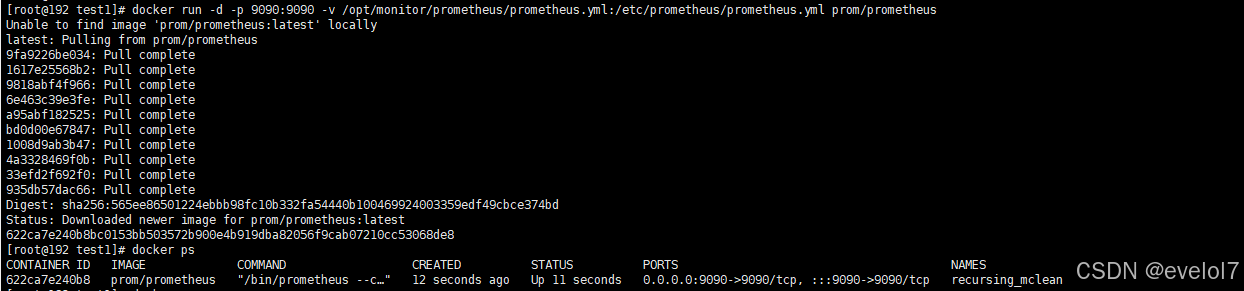
2.用配置文件部署启动Prometheus
docker run -d -p 9090:9090 -v /opt/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml --name=prometheus prom/prometheus
3.安装node_exporter
这里安装node_exporter是手动安装的,为什么不用docker直接安装呢,这是因为docker安装的exporter是在容器里面的,从容器里采集机器本机的数据的时候并不完全,有时会导致和实际数据相差较大(本人已踩过坑),这里建议手动安装到机器上。
下载地址: link

直接下载下来传到机器上并解压

然后我们配置服务启动项
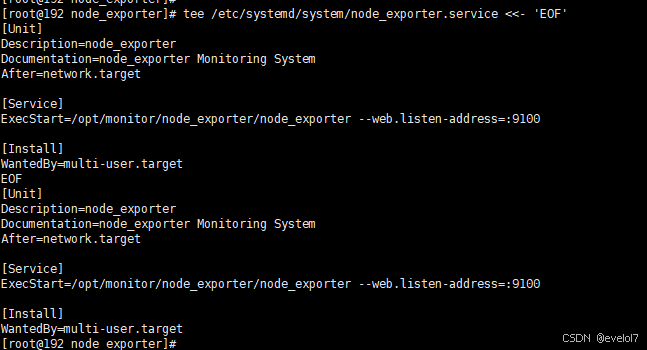
tee /etc/systemd/system/node_exporter.service <<- 'EOF'
[Unit]
Description=node_exporter
After=network.target[Service]
ExecStart=/opt/monitor/node_exporter/node_exporter --web.listen-address=:9100[Install]
WantedBy=multi-user.target
EOF
配置完成后,我们启动服务
systemctl enable node_exporter # 不是root用户前面都加一下sudo
systemctl start node_exporter
systemctl status node_exporter
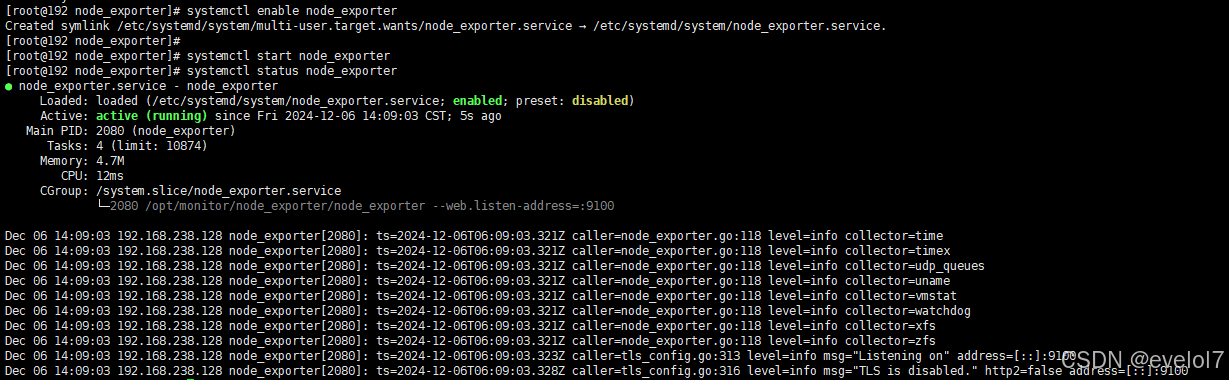
4.监控服务串联
至此,我们各个模块都是各自安装完了,接下来我们把它们连成一个整体,首先看下node_exporter和Prometheus能否正常访问。
node exporter和Prometheus
查看node_exporter:可以浏览器直接访问http://192.168.238.128:9100/,这里192.168.238.128就是我linux机器的地址

显示无法访问。。。排查了一下,防火墙忘记关了。自己内网用的机器平时可以把防火墙关了(docker安装的服务端口未被防火墙限制,手动安装的服务端口会被限制)

这时再重新访问下


这里就是其采集的信息,可以看出采集服务已正常可用了。
然后我们看下Prometheus,浏览器直接访问http://192.168.238.128:9090/

也没问题,我们在上面输入框输点东西试一下数据能不能传上来
100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))
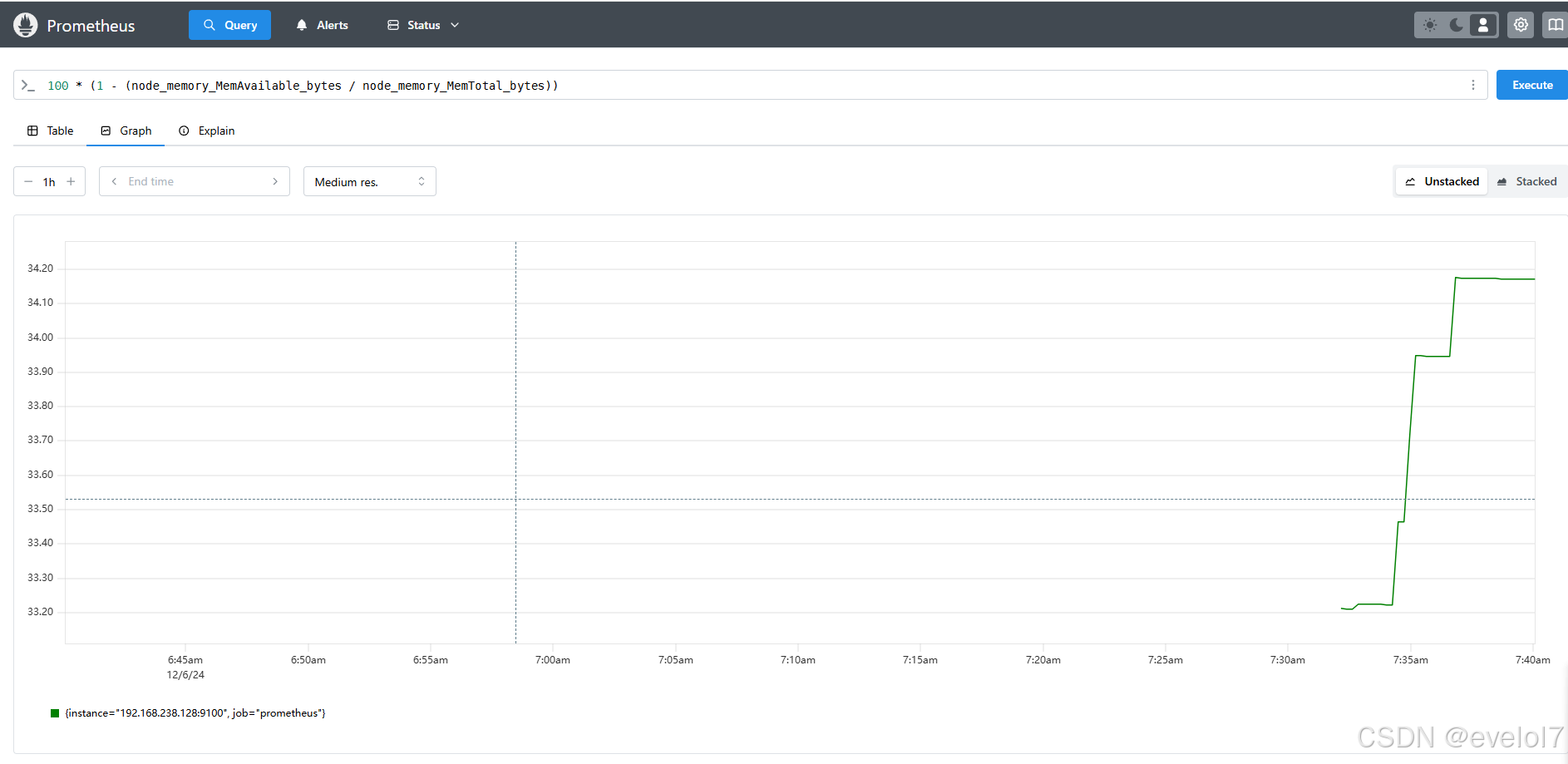
可以看出数据已经传上来了,这里时间不太对,应该是时区的问题吗,暂时不用管。至此,node exporter和Prometheus的对接正常了。
grafana配置
然后我们登录grafana:http://192.168.238.128:3000/

这里初始用户名密码是admin/admin,登录后可以修改下密码,grafana这里我们主要是配置下数据源以及展示模版,因为Prometheus那里的数据还没有和grafana对接,而且展示的数据也未经进一步处理,展示效果一般。
配置数据源:
进去找一下data sources,几个版本的grafana位置是不一样的,这个自己找一下即可
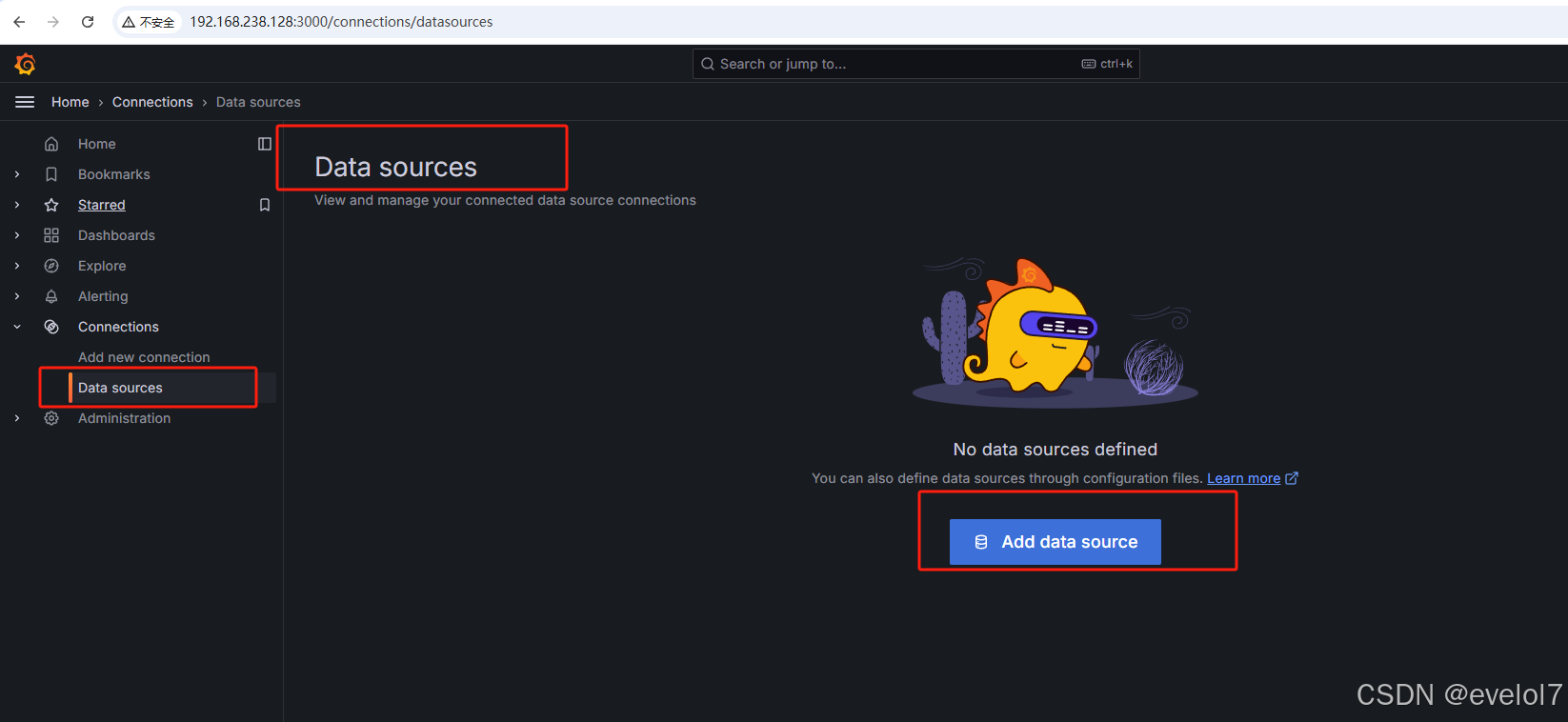
这里选择Prometheus

配置页面配置下名称(可使用默认的),以及连接的url,这个就是Prometheus的地址和端口,即我们上面访问的http://192.168.238.128:9090/

其他的默认即可,最后点击这个save&test,连接正常会弹出绿色的提示

到这里数据源就配置完成了。
导入监控模版:
这时候的数据都是Prometheus处理过的,虽然也有图表,但是比较简单,我们可以导入一个看板的模版,使其展示更加丰富,更加友好。(也可以自己写新的)
我们访问https://grafana.com/grafana/dashboards/这个网址,上面有已有的模版,可以查看下哪个适合我们
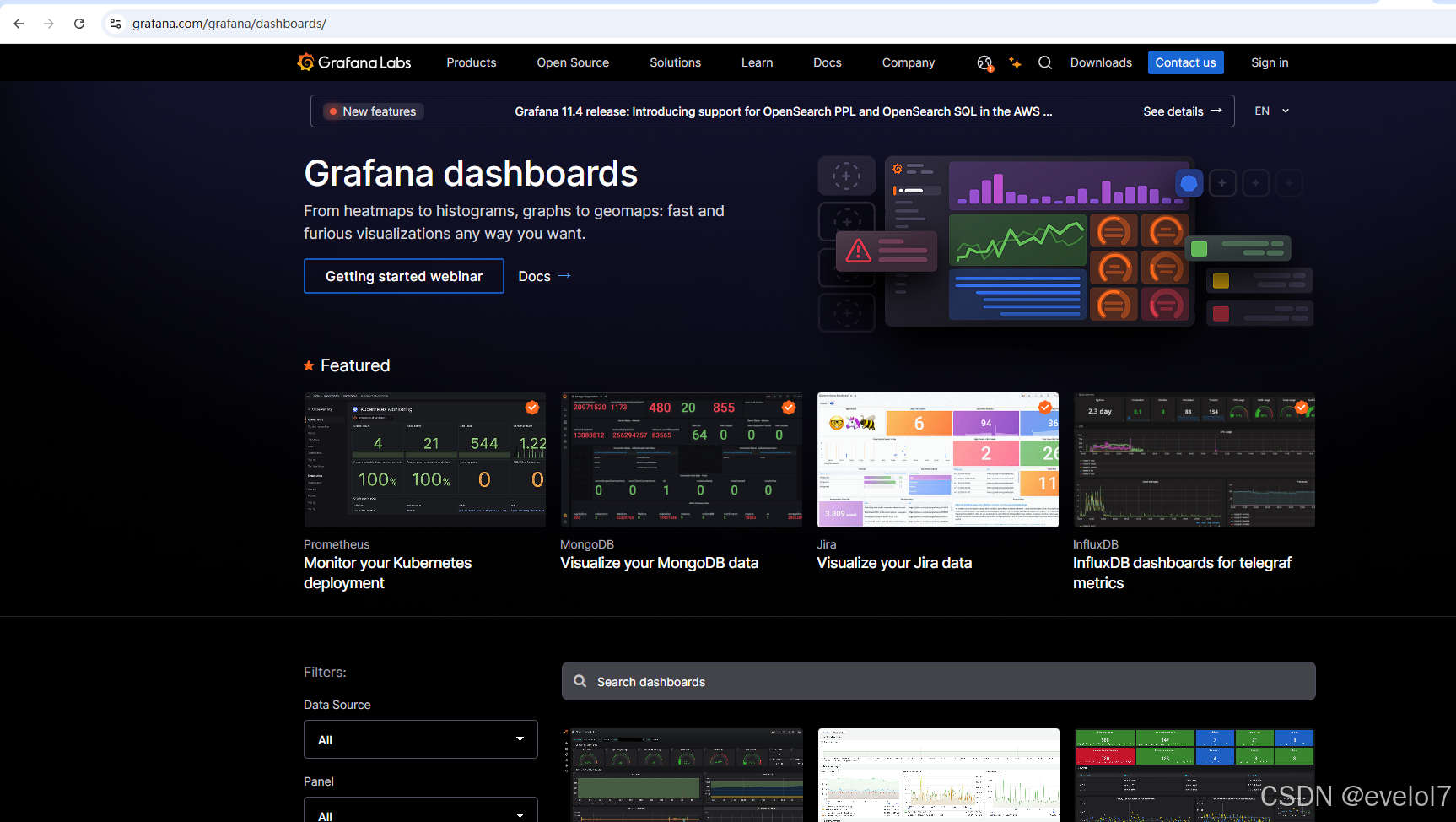
在这边搜索node exporter可以搜索出所有node exporter的模版

这里我们就选用第一个,点击进去

这里有两个选项,一个是复制id,一个是下载json,这里我们直接复制id好了。这个json其实就是模版文件了,但是我们也可以用id来自动导入。
然后我们进入自己搭建的grafana页面,点击这个import(各个版本的UI略有不同,按键位置可能也不同)

这里输入刚刚复制的id,然后点击load

加载完成后进入这个页面

这里选我们刚刚配好的数据源

然后点击import,就跳转到看板页面了,如果页面没有数据,可查看左上角这几个选项是不是正确;或者可以等一会,也有可能数据还没有上传上来。

至此,监控服务就部署好了,无论是做性能还是可靠性,我们可以对服务器进行长时间监测了。
问题记录:
实际部署时,也遇到了一些其他问题,这里记录下:
1.导入Node Exporter Full监控模版(id为1860)时,grafana一直报找不到方法,这个主要是1860这个模板和grafana当前版本不兼容,更新grafana即可。
2.监控数据不准确的问题,这个上面已经提到,解决办法是node_exporter手动直接安装在服务器上。
3.Prometheus可添加多个监控节点,网络能正常连通即可,修改Prometheus配置文件后需重启下服务。
相关文章:
【服务器监控】grafana+Prometheus+node exporter详细部署文档
我们在进行测试时,不可能一直手动看着服务器的性能消耗,这时候就需要有个工具替我们监控服务器的性能消耗。这里记录下grafanaPrometheusnodeExporter的组合用于监控服务器。 简单介绍: grafana:看板工具,所有采集的…...

JavaScript中todolist操作--待办事项的添加 删除 完成功能
效果图 在文本框中输入内容点击添加按钮会在下面生成 添加功能 html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0&qu…...
Windows中MySQL8.3.4 MSI版本——详细安装教程
一、下载MySQL安装文件。 下载地址:MySQL官网 进入后点击下面的MySQL社区版下载 点击MySQL Comunity Server。 我这里选择的是版本8.4.3LTS版本,在线对应的msi文件。 点击No thanks,直接下载。 二、安装MySQL 2.1、双击刚刚下载好的msi文件,…...

MySQL-DDL之数据库操作
文章目录 一. 创建数据库1. 直接创建数据库,如果存在则报错2. 如果数据库不存在则创建3. 创建数据库时设置字符集4. 栗子 二. 查看数据库1. 查看数据库 三. 删除数据库1. 删除数据库 四. 使用数据库1. 使用数据库2. 查看正在使用的数据库 数据定义语言:简…...

Python 笔记之进程通信
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态生成多个进程 但是如果是上百个或者上千个目标,手动去创建进程的工作量很大,此时就可以利用到Multiprocessing模块提供的Pool方法 初始化pool时,可以指定…...

【Transformer序列预测】Pytorch中构建Transformer对序列进行预测源代码
Python,Pytorch中构建Transformer进行序列预测源程序。包含所有的源代码和数据,程序能够一键运行。此程序是完整的Transformer,即使用了Encoder、Decoder和Embedding所有模块。源程序是用jupyterLab所写,建议分块运行。也整理了.p…...

生产者-消费者模式:多线程并发协作的经典案例
生产者-消费者模式是多线程并发编程中一个非常经典的模式,它通过解耦生产者和消费者的关系,使得两者可以独立工作,从而提高系统的并发性和可扩展性。本文将详细介绍生产者-消费者模式的概念、实现方式以及应用场景。 1 生产者-消费者模式概述…...

数据库-mysql(基本语句)
演示工具:navicat 连接:mydb 一.操作数据库 1.创建数据库 ①create database 数据库名称 //普通创建 ②create database if not exists 数据库名称 //创建数据库,判断不存在,再创建: 使用指定数据库 use 数据库…...

android12L super.img 解压缩及其挂载到ubuntu18.04
本文介绍如何在Ubuntu18.04上解压缩高通平台Android12L的super.img,并将其挂载到系统中查看内容。 在源码的根目录下,执行如下命令: out/host/linux-x86/bin/simg2img out/target/product/msmnile_gvmq/super.img super.img_rawmkdir super…...
)
flask简易版的后端服务创建接口(python)
1.pip install安装Flask和CORS 2.创建http_server.py文件,内容如下 """ ============================ 简易版的后端服务 ============================ """ from flask import Flask, request, jsonify from flask_cors import CORS app = F…...

小程序入门学习(四)之全局配置
一、 全局配置文件及常用的配置项 小程序根目录下的 app.json 文件是小程序的全局配置文件。常用的配置项如下: pages:记录当前小程序所有页面的存放路径 window:全局设置小程序窗口的外观 tabBar:设置小程序底部的 tabBar 效…...

PHP使用RabbitMQ(正常连接与开启SSL验证后的连接)
代码中包含了PHP在一般情况下使用方法和RabbitMQ开启了SSL验证后的使用方法(我这边消费队列是使用接口请求的方式,每次只从中取出一条) 安装amqp扩展 PHP使用RabbitMQ前,需要安装amqp扩展,之前文章中介绍了Windows环…...

轻量级视觉骨干网络 MobileMamba: Lightweight Multi-Receptive Visual Mamba Network
MobileMamba 快速链接解决问题:视觉模型在移动设备端性能和效果的平衡性解决方法:改进网络结构训练和测试策略网络结构改进训练和测试策略 实验支撑:图像分类、分割,目标检测等图像分类结果对比目标检测和实例分割结果对比语义分割…...

科技云报到:数智化转型风高浪急,天翼云如何助力产业踏浪而行?
科技云报到原创。 捷径消亡,破旧立新,是今年千行百业的共同底色。 穿越产业周期,用数字化的力量重塑企业经营与增长的逻辑,再次成为数字化技术应用的主旋律,也是下一阶段产业投资的重点。 随着数字化转型行至“深水区…...

dockerfile部署前后端(vue+springboot)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言0.环境说明和准备1.前端多环境打包1.1前端多环境设置1.2打包 2.后端项目多环境配置以及打包2.1后端多环境配置2.2项目打包 3.文件上传4.后端镜像制作4.1dockerf…...

c语言的思维导图
之前已经全部学完c语言了,所以为了更好的复习回顾,我做了一份c语言超详细的思维导图,帮助实现一张图就可以复习,避免盲目, 由于平台不支持直接发上图,有想要的小伙伴,可以私信找我要原件...
)
Android 拍照(有无存储权限两种方案,兼容Q及以上版本)
在某些行业,APP可能被禁止使用存储权限,或公司在写SDK功能,不方便获取权限 所以需要有 无存储权限拍照方案。这里两种方案都列出里。 对于写入权限,在高版本中,已经废弃, 不可用文件写入读取权限…...

MongoDB在自动化设备上的应用示例
发现MongoDB特别适合自动化检测数据的存储。。。 例如一个晶圆检测项目,定义其数据结构如下 #pragma once #include <vector> #include <QString> #include <QRectF> #include <string> #include <memory>class tpoWafer; class tp…...

draggable插件——实现元素的拖动排序——拖动和不可拖动的两种情况处理
最近在写后台管理系统的时候,遇到一个需求,就是关于拖动排序的功能。 我之前是写过一个关于拖动表格的功能,此功能可以实现表格中的每一行数据上下拖动实现排序的效果。 vue——实现表格的拖拽排序功能——技能提升 但是目前我这边的需求是…...

Redux的使用
到如今redux的已经不是react程序中必须的一部分内容了, 我们应该在本地需要大量更新全局变量时才使用它! redux vs reducer reducer的工作机制: 手动构造action对象传入dispatch函数中 dispatch函数将 action传入reducer当中 reducer结合当前state与a…...

基于Docker部署OpenOffice无头服务实现文档自动化处理
1. 项目概述与核心价值最近在折腾文档处理自动化流程,发现很多老项目或者特定场景下,对Office文档的兼容性要求极高,尤其是那些需要处理.doc、.xls、.ppt等老格式的场景。直接用现代办公套件(比如LibreOffice)去处理&a…...

CircuitPython Web Workflow实战:无线开发Yoto Mini与I2C硬件验证
1. 项目概述与核心价值如果你玩过像树莓派Pico或者ESP32这类微控制器,肯定对“插拔-编程-调试”这个循环不陌生。每次改几行代码,就得拔下USB线,重新上电,然后盯着串口监视器看输出。这个过程在项目初期调试硬件时,尤其…...

品牌声音技能化:从模糊概念到可执行AI内容策略
1. 项目概述:品牌声音的“技能化”构建最近在和一些做品牌营销、内容运营的朋友聊天,发现一个挺普遍的现象:大家手里都有一堆品牌手册、VI规范,但一到具体执行,比如写一篇公众号推文、拍一条短视频,或者回复…...

OpenClaw实战教程:声明式配置驱动的高效数据抓取方案
1. 项目概述:一个关于“OpenClaw”的实战教程 最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看名字,你可能会有点摸不着头脑,这“OpenClaw”到底是个啥?是某种开源机械爪?还是一个代号&…...

AI智能体记忆系统设计:从RAG到长期记忆的工程实践
1. 项目概述:从“记忆”到“智能”的跨越在AI智能体(Agent)的开发浪潮中,我们常常面临一个核心挑战:如何让智能体在复杂的、多轮次的交互中,表现得像一个真正有“记忆”和“经验”的专家?传统的…...

React轻量级代码编辑器组件:基于Textarea的语法高亮方案
1. 项目概述:一个为React开发者量身打造的代码编辑器组件 如果你在React项目中需要嵌入一个代码编辑器,并且希望它轻量、美观、开箱即用,那么 uiwjs/react-textarea-code-editor 这个组件库很可能就是你一直在寻找的解决方案。它不是一个像…...

基于Node.js的Markdown文档自动化转换工具:从原理到CI/CD集成实战
1. 项目概述:一个被低估的文档转换利器如果你和我一样,日常工作中需要处理大量不同格式的文档,比如把Markdown写的技术文档转成Word给产品经理看,或者把项目README转成PDF存档,那你肯定也经历过格式错乱、样式丢失的烦…...

在济宁,随着设备搬运服务需求的持续增长,市面上涌现出众多设
在济宁,设备搬运服务需求不断增加,众多厂家纷纷涌现,选择一家口碑良好的设备搬运厂家成为不少人的关注焦点。本次测评旨在通过客观的评估,为对济宁设备搬运厂家感兴趣的人群提供有价值的参考。参与本次测评的厂家为山东荣上机械设…...
)
别再满世界找Kettle了!手把手教你定位最新官方下载源(附版本选择建议)
开源工具下载困境突围指南:以Kettle为例构建高效溯源方法论 在开源工具的使用过程中,最令人头疼的莫过于某天突然发现熟悉的下载链接失效,官网改版后找不到下载入口,或是搜索引擎返回的结果全是过时的教程。这种情况不仅发生在Ke…...
)
Automa实战:除了循环数字,这两种更高效的网页数据抓取方法你知道吗?(附避坑指南)
Automa进阶实战:突破循环数字的网页抓取高效方法论 当你在深夜盯着屏幕上那个不断转圈的Automa工作流,第37次尝试抓取动态加载的电商商品列表却依然失败时,或许该重新思考自动化抓取的本质了。循环数字就像用螺丝刀当锤子——在某些场景下能勉…...