深入了解架构中常见的4种缓存模式及其实现
4种缓存模式
随着应用程序的复杂性日益增加,缓存管理变得至关重要。缓存不仅能有效减轻数据库负载,还能显著提升数据访问速度。选择合适的缓存模式能够在不同的业务场景下发挥出最佳效果。
本文将详细介绍四种常见的缓存模式:Cache-Aside (旁路缓存)、Read-Through (透读缓存)、Write-Through (透写缓存) 和 Write-Back / Write-Behind (写后缓存),并通过代码示例深入剖析它们的实现。
1.Cache-Aside (旁路缓存)
概述
Cache-Aside(旁路缓存)模式,又叫 Lazy-Loading(懒加载)模式,在这种模式下,缓存的读取和写入由应用程序直接管理。应用程序首先尝试从缓存中读取数据,若缓存未命中,则从数据库中加载数据并将其存储在缓存中;对于更新操作,应用程序直接更新数据库,并更新或删除缓存中的相关数据。
工作流程:
- 读取数据:
- 应用程序查询缓存。
- 如果缓存命中,返回缓存数据。
- 如果缓存未命中,应用程序从数据库加载数据,并将其存入缓存。
- 更新数据:
- 应用程序直接更新数据库。
- 然后,应用程序更新或删除缓存中的数据。
优缺点:
优点:
- 灵活:开发者可以根据需求选择从缓存或数据库读取数据。
- 减少数据库负载,提高访问速度。
- 简单易于实现,开发者可以完全控制缓存管理。
缺点:
- 需要手动管理缓存,增加了开发和维护的复杂度。
- 存在缓存一致性问题,需要小心处理缓存的清除和更新。
适用场景
适用于读取频繁但更新较少的数据。例如,用户信息、商品详情、广告推荐等。
代码示例
import java.util.HashMap;
import java.util.Map;public class CacheAside {private Map<String, String> cache = new HashMap<>();private Map<String, String> database = new HashMap<>();public String getFromCacheOrDatabase(String key) {String data = cache.get(key);if (data == null) {data = database.get(key);cache.put(key, data);}return data;}
}
2. Read-Through (透读缓存)
概述
Read-Through 模式下,缓存层自动管理数据的读取。当应用程序请求数据时,缓存层会先检查缓存,如果缓存命中则直接返回数据;如果缓存未命中,则缓存层自动从数据库加载数据,并将数据存入缓存。
工作流程:
- 应用程序请求数据。
- 如果缓存中存在数据,直接返回数据。
- 如果缓存中没有数据,缓存系统会从数据库加载数据,并将数据存入缓存。
独立设计缓存层
- 缓存层实现:需要一个独立的缓存系统(如 Redis、Memcached)。缓存系统需要能够在数据未命中时,自动从数据库加载数据,并缓存这些数据。
- 缓存一致性:通常需要通过缓存管理器来控制数据过期、更新和一致性。
优缺点:
优点:
- 简化了应用程序的逻辑,应用程序无需关心数据是从缓存还是数据库加载。
- 减少了数据库的负担,提升了系统性能。
缺点:
- 增加了对缓存层的依赖,缓存层需要具备高可用性和强大的扩展性。
- 当缓存未命中时,可能会造成缓存层和数据库的负载增加。
适用场景
适用于需要快速访问并且能够容忍一定程度缓存一致性问题的应用场景,比如商品数据、用户会话等。
代码示例
import java.util.HashMap;
import java.util.Map;public class ReadThrough {private Map<String, String> cache = new HashMap<>();private Map<String, String> database = new HashMap<>();public String getFromCacheOrReadThroughDatabase(String key) {String data = cache.get(key);if (data == null) {data = database.get(key);cache.put(key, data);}return data;}
}
Cache-Aside(旁路缓存)和Read-Through(透读缓存)的区别
Cache-Aside (旁路缓存)
数据访问方式:
- 在Cache-Aside模式中,应用程序首先查询缓存,如果缓存中不存在所需数据,则从数据库中获取数据,并将数据存储到缓存中。应用程序负责直接操作缓存。
缓存更新策略: - 数据更新时,应用程序负责更新缓存。这意味着数据的写入和更新操作会首先更新数据库,然后再更新缓存。缓存中的数据通常在需要时才会被更新。
Read-Through (透读缓存)
数据访问方式:
- 在Read-Through模式中,应用程序直接查询缓存,如果缓存中不存在所需数据,则缓存系统会负责从数据库中获取数据,并将数据存储到缓存中。应用程序并不直接操作缓存。
缓存更新策略: - 数据更新时,缓存系统会负责更新缓存。当数据发生变化时,缓存系统会自动更新缓存,确保缓存中的数据与数据库中的数据保持一致。
区别总结
- Cache-Aside模式中,应用程序负责读取和写入缓存,而Read-Through模式中,缓存系统负责从数据库中读取数据并更新缓存。
- 在Cache-Aside中,数据更新时需要应用程序负责更新缓存,而在Read-Through中,缓存系统会自动更新缓存以保持数据一致性。
- Cache-Aside适用于读取频率高、写入频率低的场景,而Read-Through适用于需要保证数据一致性的场景。
3. Write-Through (透写缓存)
概述
Write-Through 模式要求数据在写入时同时更新缓存和数据库。当应用程序写入数据时,数据首先写入缓存,然后立即写入数据库。这种模式保证了缓存中的数据始终与数据库中的数据一致。
工作流程:
- 应用程序写入数据。
- 数据首先写入缓存。
- 然后,数据被同步写入数据库。
独立设计缓存层:
- 缓存层实现:需要一个缓存层,在写数据时同步更新缓存和数据库。这样可以确保缓存中的数据与数据库中的数据保持一致。
优缺点:
优点:
- 保证了缓存和数据库中的数据一致性。
- 每次数据更新时,都会更新缓存,避免了缓存过期问题。
缺点:
- 写操作会增加缓存层和数据库的负担,可能影响性能。
- 相对于其他模式,写入操作的延迟较高。
适用场景
适用于数据一致性要求较高的场景,如库存管理、金融交易等。
代码示例
import java.util.HashMap;
import java.util.Map;public class WriteThrough {private Map<String, String> cache = new HashMap<>();private Map<String, String> database = new HashMap<>();public void writeToCacheAndDatabase(String key, String value) {cache.put(key, value);database.put(key, value);}
}
4. Write-Back / Write-Behind (写后缓存)
概述
Write-Back(写后缓存)模式下,应用程序先将数据写入缓存,而不立即写入数据库。数据在缓存中更新后,定期或按需将更新后的数据异步写入数据库。这种模式的好处是减少了写操作的延迟,提高了性能,但需要处理数据同步的问题。
工作流程:
- 应用程序将数据写入缓存。
- 数据更新首先写入缓存,而不直接写入数据库。
- 缓存会定期或异步地将数据写入数据库。
独立设计缓存层:
- 缓存层实现:需要一个独立的缓存层,该层不仅处理数据读取,还负责缓存数据的写入。为了确保数据最终一致性,通常会使用异步操作将缓存中的数据写回数据库。
优缺点:
优点:
- 提高了写操作的性能,减少了对数据库的写入压力。
- 写操作的延迟较低,因为数据只写入缓存。
缺点:
- 需要处理缓存与数据库的数据同步问题,确保最终一致性。
- 如果缓存数据未及时写入数据库,可能导致数据丢失。
适用场景
适用于不需要即时写入数据库的场景,例如日志收集、批量数据更新等。
代码示例
import java.util.HashMap;
import java.util.Map;public class WriteBack {private Map<String, String> cache = new HashMap<>();private Map<String, String> database = new HashMap<>();private Map<String, Boolean> dirtyMap = new HashMap<>();public void writeToCache(String key, String value) {cache.put(key, value);dirtyMap.put(key, true);}public void writeToDatabase(String key) {if (dirtyMap.getOrDefault(key, false)) {String data = cache.get(key);database.put(key, data);dirtyMap.put(key, false);}}
}
Read-Through(透读缓存)与 Write-Through(透写缓存)和 Write-Back(写后缓存)相比的优势和劣势
Read-Through(透读缓存)的优势:
- 数据一致性:Read-Through模式可以确保缓存中的数据与数据库中的数据保持一致。
- 简化应用逻辑:应用程序无需关心缓存的更新,缓存系统负责从数据库中读取数据并更新缓存,简化了应用的逻辑。
- 减少数据库负载:通过缓存数据,可以减少对数据库的频繁访问,降低数据库负载,提高系统性能。
Read-Through(透读缓存)的劣势:
- 读取延迟:如果数据不在缓存中,需要从数据库中获取数据并更新缓存,可能会增加读取数据的延迟。
- 频繁读取场景下不够高效:对于频繁读取的数据,如果每次都要从数据库中获取数据,可能会降低系统性能。
- 数据更新时的一致性延迟:数据更新后,缓存中的数据需要等到下一次读取时才会被更新,可能导致一段时间内的数据不一致。
总结:
Read-Through适合对数据一致性要求较高的场景,但可能存在读取延迟和频繁读取效率不高的问题。在选择缓存模式时,应根据具体业务需求和系统特点来权衡各种因素,选择最适合的缓存模式。
总结
除了 **Cache-Aside (旁路缓存) **模式外,其他三种模式(Read-Through (透读缓存)、Write-Through (透写缓存) 和 Write-Back / Write-Behind (写后缓存))通常需要独立设计缓存层,或者通过专门的服务来封装缓存的读写操作。具体来说,这三种模式都需要一个完整的封装机制来处理数据的访问和缓存的一致性问题。
缓存策略是优化系统性能的重要工具,不同的缓存模式适用于不同的场景。理解这些模式的工作原理、优缺点和适用场景有助于在开发中选择最合适的缓存策略。
- Cache-Aside:适合读取频繁但更新较少的场景,开发者需要手动管理缓存。
- Read-Through:适合对数据一致性要求不高的场景,缓存系统自动处理数据加载。
- Write-Through:适合对一致性要求较高的场景,每次写操作都会同步更新缓存和数据库。
- Write-Back:适合可以容忍延迟的场景,数据更新异步写入数据库,减少写操作的压力。
选择合适的缓存模式,能够在提高性能的同时,确保系统的稳定性和数据一致性。
相关文章:

深入了解架构中常见的4种缓存模式及其实现
4种缓存模式 随着应用程序的复杂性日益增加,缓存管理变得至关重要。缓存不仅能有效减轻数据库负载,还能显著提升数据访问速度。选择合适的缓存模式能够在不同的业务场景下发挥出最佳效果。 本文将详细介绍四种常见的缓存模式:Cache-Aside (…...

Hermes engine on React Native 0.72.5,function无法toString转成字符串
问题描述 Hermes engine on React Native 0.72.5,function无法toString转成字符串 环境 npm6.14.18 node16.17.1项目依赖 "react": "18.2.0", "react-dom": "18.2.0", "react-native": "0.72.5", …...

Spring Boot + MySQL 多线程查询与联表查询性能对比分析
Spring Boot MySQL: 多线程查询与联表查询性能对比分析 背景 在现代 Web 应用开发中,数据库性能是影响系统响应时间和用户体验的关键因素之一。随着业务需求的不断增长,单表查询和联表查询的效率问题日益凸显。特别是在 Spring Boot 项目中࿰…...

Java 设计模式~工厂模式
在java开发,工厂模式应用场景有哪些?在Spring boot原码中 有哪些工厂类,并做相应的代码介绍。 工厂模式 工厂模式(Factory Pattern)是Java中一种常用的创建型设计模式,它提供了一种创建对象的最佳方式。此…...
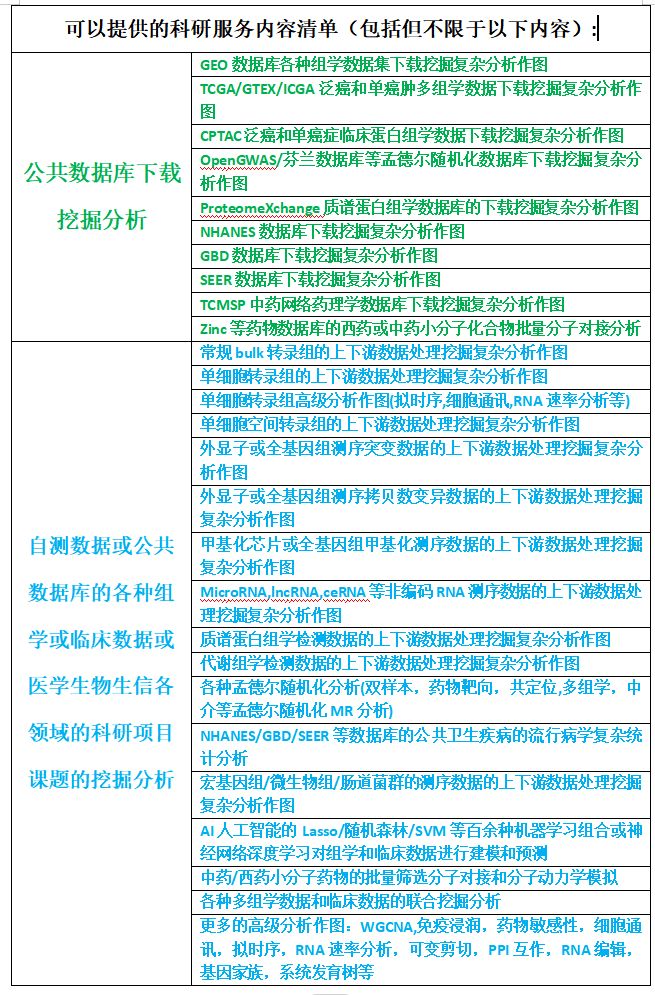
OmicsTools生信环境全自动化安装配置教程,代做生信分析和辅导
OmicsTools软件介绍和下载安装配置 软件介绍 我开发了一款本地电脑无限使用的零代码生信数据分析作软图神器电脑软件OmicsTools,旨在成为可以做各种医学生物生信领域科研数据分析作图的的全能科研软件,欢迎大家使用OmicsTools进行生物医学科研数据分析…...

鸿蒙HarmonyOS应用开发 探索 HarmonyOS Next-从开发到实战掌握 HarmonyOS Next 的分布式能力
鸿蒙心路旅程:探索 HarmonyOS Next-从开发到实战掌握 HarmonyOS Next 的分布式能力 HarmonyOS Next 是华为推出的全新一代操作系统,旨在进一步推动分布式技术的深度应用和生态融合。本文将从技术特点、应用场景入手,通过实战案例与代码示例&…...

二分模板题
题目传送门 主要思路: 暴力会tle n的3次方了然后 二分可以找中间然后去二分枚举两边 最后结果 ansa小于它的数*c大于它的数 注意要判断是否符合条件 即如果a的小于它的数还大于它就不成立 或者c的数小于它也不成立结果 要注意转long long ans(long long)tp1*tp2; …...

一篇文章掌握Git的基本原理与使用
目录 一、创建仓库 1.1 git init 1.2 git clone 二、工作区域与文件状态 三、添加和提交文件 3.1 git status 3.2 git add git rm --cached 3.3 git commit git log 四、版本回退 soft hard mixed 总结 五、查看差异 工作区与暂存区 工作区与本地仓库 暂存区…...

「Mac畅玩鸿蒙与硬件43」UI互动应用篇20 - 闪烁按钮效果
本篇将带你实现一个带有闪烁动画的按钮交互效果。通过动态改变按钮颜色,用户可以在视觉上感受到按钮的闪烁效果,提升界面互动体验。 关键词 UI互动应用闪烁动画动态按钮状态管理用户交互 一、功能说明 闪烁按钮效果应用实现了一个动态交互功能…...

朗新科技集团如何用云消息队列 RocketMQ 版“快、准、狠”破解业务难题?
作者:邹星宇、刘尧 朗新科技集团:让数字化的世界更美好 朗新科技集团股份有限公司是领先的能源科技企业,长期深耕电力能源领域,通过新一代数字化、人工智能、物联网、电力电子技术等新质生产力,服务城市、产业、生活中…...
和Bit版本(工作))
【Ubuntu】Ubuntu的Desktop(学习/用户使用)和Bit版本(工作)
这篇文章似乎没什么必要写,但想了想还是决定记录一下,也许对新手入坑Ubuntu会有帮助, 事实上也很简单,一个是桌面版本,另一个是字符界面版本。 桌面版:拥有图形桌面 字符界面,易上手ÿ…...

cmake CMAKE_CURRENT_SOURCE_DIR和CMAKE_CURRENT_LIST_DIR的区别
在 CMake 中,CMAKE_CURRENT_LIST_DIR 和 CMAKE_CURRENT_SOURCE_DIR 都是指代当前 CMake 文件所在的路径,但它们的含义和用途有所不同: CMAKE_CURRENT_LIST_DIR: 表示 当前处理的 CMake 文件(例如 CMakeLists.txt&#…...

学会用VSCode debug
本文主要介绍了 VS Code 的调试功能,包括其强大的内置调试器,支持多种语言,如 JavaScript、TypeScript 等。通过简单项目示例展示调试过程,还介绍了运行面板和菜单、启动配置、调试操作、断点、记录点等功能,以及三种调…...

C语言专题之结构体的使用
结构体(struct)是一种用户自定义的数据类型,它允许将不同类型的数据组合在一起,形成一个新的数据类型。结构体在编程中非常常见,尤其是在需要处理复杂数据结构的情况下。以下是结构体的基本使用方法: 一、结…...

python中的高阶函数
1、什么是高阶函数? 高阶函数是指将函数作为参数传入。就是高阶函数 2、高阶函数有哪些? map 映射函数 >>> print(list(map(lambda x:x*x,range(1,11)))) [1, 4, 9, 16, 25, 36, 49, 64, 81, 100] >>> print(list(map(lambda x:st…...

学习笔记063——通过使用 aspose-words 将 Word 转 PDF 时,遇到的字体改变以及乱码问题
文章目录 1、问题描述:2、解决方法: 1、问题描述: Java项目中,有个需要将word转pdf的需求。本人通过使用aspose-words来转换的。在Windows中,转换是完全正常的。但是当部署到服务器时,会出现转换生成的pdf…...

SpringBoot整合Mockito进行单元测试超全详细教程 JUnit断言 Mockito 单元测试
Mock概念 Mock叫做模拟对象,即用来模拟未被实现的对象可以预先定义这个对象在特定调用时的行为(例如返回值或抛出异常),从而模拟不同的系统状态。 导入Mock依赖 pom文件中引入springboot测试依赖,spring-boot-start…...

【AI知识】过拟合、欠拟合和正则
一句话总结: 过拟合和欠拟合是机器学习中的两个相对的概念,正则化是用于解决过拟合的方法。 1. 欠拟合: 指模型在训练数据上表现不佳,不能充分捕捉数据的潜在规律,导致在训练集和测试集上的误差都很高。欠拟合意味着模…...

MacOS编译webRTC源码小tip
简单记录一下,本人在编译webRTC时,碰到了一下比较烦人的问题,在MacOS终端下,搭建科学上网之后,chromium的depot_tools仓库成功拉下来了,紧接着,使用fetch以及gclient sync始终都返回curl相关的网…...
:文件压缩及解压缩命令)
Linux基础命令(三):文件压缩及解压缩命令
文件压缩及解压缩命令 tar — 打包和压缩 tar 是一个用于打包文件的工具,常常用来将多个文件或目录打包成一个单独的文件。它本身不进行压缩,但可以与压缩工具(如 gzip 或 bzip2)一起使用。 用法: 打包文件࿰…...

实测Qwen3-4B:256K超长上下文,处理长文档、写长文真实案例
实测Qwen3-4B:256K超长上下文,处理长文档、写长文真实案例 1. 引言:为什么关注长上下文能力 在日常工作和创作中,我们经常遇到需要处理超长文档的场景:分析上百页的PDF报告、阅读整本电子书、编写长篇技术文档等。传…...

Ubuntu 虚拟机 Python3 + pip 完整安装教程
文章目录一、先检查系统是否自带 Python3二、安装 Python3 和 pip(必装)1. 更新软件源2. 安装 python3 和 pip3. 验证安装成功三、最简单的使用方法1. 运行 Python2. 用 pip 安装第三方库(如 requests、numpy)3. 运行 .py 文件四、…...

告别插件!保姆级教程:用Nginx反向代理搞定海康威视Web无插件视频预览
海康威视Web无插件视频预览的Nginx反向代理实战指南 引言 在现代安防监控系统集成中,海康威视设备因其稳定性和广泛兼容性成为行业首选。然而,传统Web集成方案往往依赖浏览器插件,这不仅增加了部署复杂度,也带来了安全风险。随着H…...

Agent能实现7×24小时无人值守运营吗?——深度拆解AI Agent端到端自动化落地路径
随着大模型技术的演进,AI Agent(人工智能体)已不再局限于简单的对话交互,而是进化为能够自主规划、调用工具并执行复杂任务的数字员工。针对“Agent能实现724小时无人值守运营吗?”这一核心疑问,答案是肯定…...

Kindle Comic Converter:漫画电子书制作的专业工具
Kindle Comic Converter:漫画电子书制作的专业工具 【免费下载链接】kcc KCC (a.k.a. Kindle Comic Converter) is a comic and manga converter for ebook readers. 项目地址: https://gitcode.com/gh_mirrors/kc/kcc Kindle Comic Converter(简…...
)
OpenCV实战:3种图像降噪滤波器的Python代码对比(附效果图)
OpenCV实战:3种图像降噪滤波器的Python代码对比(附效果图) 在数字图像处理中,噪声是影响图像质量的主要因素之一。无论是来自传感器的不完美,还是传输过程中的干扰,噪声都会降低图像的清晰度和可用性。对于…...

事件驱动视觉革命:EVS技术如何重塑机器感知的未来格局
1. EVS技术:重新定义机器视觉的游戏规则 想象一下你正坐在高速行驶的列车上,窗外风景飞速掠过。传统相机就像每隔几秒才按下一次快门的游客,拍到的全是模糊不清的照片;而EVS(事件驱动视觉传感器)则像专业摄…...

[语音转文字工具] AsrTools:让音频转写效率提升300%的开源解决方案
[语音转文字工具] AsrTools:让音频转写效率提升300%的开源解决方案 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn your audio in…...
ostringstream清空缓存的正确姿势:str()与clear()的深度解析
1. 为什么ostringstream清空缓存这么让人困惑? 第一次用ostringstream的时候,我也被它坑过。记得当时写了个日志记录功能,反复往同一个ostringstream对象里写入内容,结果发现每次输出的日志都越积越长。我本能地调用了clear()&…...

mbed OS双极性步进电机驱动库设计与应用
1. 项目概述BipoarStepperMotor 是一个面向 ARM Cortex-M 系统、专为 mbed OS 平台设计的双极性步进电机驱动库。该库不依赖特定硬件抽象层(HAL)变体,而是基于 mbed OS 提供的标准 DigitalOut 和 PwmOut 接口构建,具备良好的跨平台…...