差异基因富集分析(R语言——GOKEGGGSEA)
接着上次的内容,上篇内容给大家分享了基因表达量怎么做分组差异分析,从而获得差异基因集,想了解的可以去看一下,这篇主要给大家分享一下得到显著差异基因集后怎么做一下通路富集。
1.准备差异基因集
我就直接把上次分享的拿到这边了。我们一般都把差异基因分为上调基因和下调基因分别做通路富集分析。下面上代码,可能包含我的一些个人习惯,勿怪。显著差异基因的筛选条件根据个人需求设置哈。
##载入所需R包
library(readxl)
library(DOSE)
library(org.Hs.eg.db)
library(topGO)
library(pathview)
library(ggplot2)
library(GSEABase)
library(limma)
library(clusterProfiler)
library(enrichplot)##edger
edger_diff <- diff_gene_Group
edger_diff_up <- rownames(edger_diff[which(edger_diff$logFC > 0.584962501),])
edger_diff_down <- rownames(edger_diff[which(edger_diff$logFC < -0.584962501),])##deseq2
deseq2_diff <- diff_gene_Group2
deseq2_diff_up <- rownames(deseq2_diff[which(deseq2_diff$log2FoldChange > 0.584962501),])
deseq2_diff_down <- rownames(deseq2_diff[which(deseq2_diff$log2FoldChange < -0.584962501),])##将差异基因集保存为一个list
gene_diff_edger_deseq2 <- list()
gene_diff_edger_deseq2[["edger_diff_up"]] <- edger_diff_up
gene_diff_edger_deseq2[["edger_diff_down"]] <- edger_diff_down
gene_diff_edger_deseq2[["deseq2_diff_up"]] <- deseq2_diff_up
gene_diff_edger_deseq2[["deseq2_diff_down"]] <- deseq2_diff_down
2.进行通路富集分析
这里主要介绍普通的GO&KEGG&GSEA的简单富集。筛选显著富集通路的筛选条件也是根据自己的需求决定,一般是矫正后P值小于0.05。我这里是省事,写了各list循环。
for (i in 1:length(gene_diff_edger_deseq2)){keytypes(org.Hs.eg.db)entrezid_all = mapIds(x = org.Hs.eg.db, keys = gene_diff_edger_deseq2[[i]], keytype = "SYMBOL", #输入数据的类型column = "ENTREZID")#输出数据的类型entrezid_all = na.omit(entrezid_all) #na省略entrezid_all中不是一一对应的数据情况entrezid_all = data.frame(entrezid_all) ##GO富集##GO_enrich = enrichGO(gene = entrezid_all[,1],OrgDb = org.Hs.eg.db, keyType = "ENTREZID", #输入数据的类型ont = "ALL", #可以输入CC/MF/BP/ALL#universe = 背景数据集我没用到它。pvalueCutoff = 1,qvalueCutoff = 1, #表示筛选的阈值,阈值设置太严格可导致筛选不到基因。可指定 1 以输出全部readable = T) #是否将基因ID映射到基因名称。GO_enrich_data = data.frame(GO_enrich)write.csv(GO_enrich_data,paste('GO_enrich_',names(gene_diff_edger_deseq2)[i], '.csv', sep = ""))GO_enrich_data <- GO_enrich_data[which(GO_enrich_data$p.adjust < 0.05),]write.csv(GO_enrich_data,paste('GO_enrich_',names(gene_diff_edger_deseq2)[i], '_filter.csv', sep = ""))###KEGG富集分析###KEGG_enrich = enrichKEGG(gene = entrezid_all[,1], #即待富集的基因列表keyType = "kegg",pAdjustMethod = 'fdr', #指定p值校正方法organism= "human", #hsa,可根据你自己要研究的物种更改,可在https://www.kegg.jp/brite/br08611中寻找qvalueCutoff = 1, #指定 p 值阈值(可指定 1 以输出全部)pvalueCutoff=1) #指定 q 值阈值(可指定 1 以输出全部)KEGG_enrich_data = data.frame(KEGG_enrich)write.csv(KEGG_enrich_data, paste('KEGG_enrich_',names(gene_diff_edger_deseq2)[i], '.csv', sep = ""))KEGG_enrich_data <- KEGG_enrich_data[which(KEGG_enrich_data$p.adjust < 0.05),]write.csv(KEGG_enrich_data, paste('KEGG_enrich_',names(gene_diff_edger_deseq2)[i], '_filter.csv', sep = ""))
}
3.通路富集情况可视化
这里只介绍一种简单的气泡图,当然还有其他的自己去了解吧。
##GO&KEGG富集BPCCMFKEGG分面绘图需要分开处理一下,富集结果里的ONTOLOGYL列修改
GO_enrich_data_BP <- subset(GO_enrich_data, subset = GO_enrich_data$ONTOLOGY == "BP")
GO_enrich_data_CC <- subset(GO_enrich_data, subset = GO_enrich_data$ONTOLOGY == "CC")
GO_enrich_data_MF <- subset(GO_enrich_data, subset = GO_enrich_data$ONTOLOGY == "MF")##提取GO富集BPCCMF的top5
GO_enrich_data_filter <- rbind(GO_enrich_data_BP[1:5,], GO_enrich_data_CC[1:5,], GO_enrich_data_MF[1:5,])##重新整合进富集结果
GO_enrich@result <- GO_enrich_data_filter##处理KEGG富集结果
KEGG_enrich@result <- KEGG_enrich_data
ncol(KEGG_enrich@result)
KEGG_enrich@result$ONTOLOGY <- "KEGG"
KEGG_enrich@result <- KEGG_enrich@result[,c(10,1:9)]##整合GO KEGG富集结果
ego_GO_KEGG <- GO_enrich
ego_GO_KEGG@result <- rbind(ego_GO_KEGG@result, KEGG_enrich@result[1:5,])
ego_GO_KEGG@result$ONTOLOGY <- factor(ego_GO_KEGG@result$ONTOLOGY, levels = c("BP", "CC", "MF","KEGG"))##规定分组顺序##简单画图
pdf("edger_diff_up_dotplot.pdf", width = 7, height = 7)
dotplot(ego_GO_KEGG, split = "ONTOLOGY", title="UP-GO&KEGG", label_format = 60, color = "pvalue") + facet_grid(ONTOLOGY~., scale = "free_y")+theme(plot.title = element_text(hjust = 0.5, size = 13, face = "bold"), axis.text.x = element_text(angle = 90, hjust = 1))
dev.off()
4.气泡图如图所示

做了些处理,真实图片,左侧pathway是跟后面气泡一一对应的,当然还有其他可视化方式那就需要各位自己去探索了,谢谢!
5.GSEA富集分析
这里也是做一下简单的GSEA
##GSEA官方网站下载背景gmt文件并读入
geneset <- list()
geneset[["c2_cp"]] <- read.gmt("c2.cp.v2023.2.Hs.symbols.gmt")
geneset[["c2_cp_kegg_legacy"]] <- read.gmt("c2.cp.kegg_legacy.v2023.2.Hs.symbols.gmt")
geneset[["c2_cp_kegg_medicus"]] <- read.gmt("c2.cp.kegg_medicus.v2023.2.Hs.symbols.gmt")
geneset[["c2_cp_reactome"]] <- read.gmt("c2.cp.reactome.v2023.2.Hs.symbols.gmt")
geneset[["c3_tft"]] <- read.gmt("c3.tft.v2023.2.Hs.symbols.gmt")
geneset[["c4_cm"]] <- read.gmt("c4.cm.v2023.2.Hs.symbols.gmt")
geneset[["c5_go_bp"]] <- read.gmt("c5.go.bp.v2023.2.Hs.symbols.gmt")
geneset[["c5_go_cc"]] <- read.gmt("c5.go.cc.v2023.2.Hs.symbols.gmt")
geneset[["c5_go_mf"]] <- read.gmt("c5.go.mf.v2023.2.Hs.symbols.gmt")
geneset[["c6"]] <- read.gmt("c6.all.v2023.2.Hs.symbols.gmt")
geneset[["c7"]] <- read.gmt("c7.all.v2023.2.Hs.symbols.gmt")##进行GSEA富集分析,这里也是写了个循环
gsea_results <- list()
for (i in names(gene_diff)){geneList <- gene_diff[[i]]$logFCnames(geneList) <- toupper(rownames(gene_diff[[i]]))geneList <- sort(geneList,decreasing = T)for (j in names(geneset)){listnames <- paste(i,j,sep = "_")gsea_results[[listnames]] <- GSEA(geneList = geneList,TERM2GENE = geneset[[j]],verbose = F,pvalueCutoff = 0.1,pAdjustMethod = "none",eps=0)}
}##批量绘图,注意这里如果有空富集通路,会报错!
for (j in 1:nrow(gsea_results[[i]]@result)) {p <- gseaplot2(x=gsea_results[[i]],geneSetID=gsea_results[[i]]@result$ID[j], title = gsea_results[[i]]@result$ID[j]) pdf(paste(paste(names(gsea_results)[i], gsea_results[[i]]@result$ID[j], sep = "_"),".pdf",sep = ""))print(p)dev.off()}
6.GSEA富集最简单图形如下
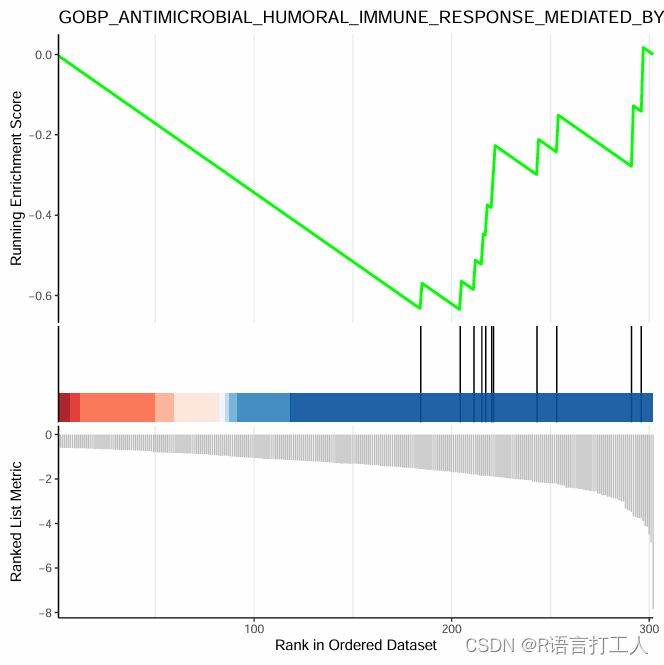
分享到此结束了,希望对大家有所帮助。
相关文章:
差异基因富集分析(R语言——GOKEGGGSEA)
接着上次的内容,上篇内容给大家分享了基因表达量怎么做分组差异分析,从而获得差异基因集,想了解的可以去看一下,这篇主要给大家分享一下得到显著差异基因集后怎么做一下通路富集。 1.准备差异基因集 我就直接把上次分享的拿到这…...

scrapy对接rabbitmq的时候使用post请求
之前做分布式爬虫的时候,都是从push url来拿到爬虫消费的链接,这里提出一个问题,假如这个请求是post请求的呢,我观察了scrapy-redis的源码,其中spider.py的代码是这样写的 1.scrapy-redis源码分析 def make_request_from_data(self, data):"""Returns a Reques…...
vue+elementUI+transition实现鼠标滑过div展开内容,鼠标划出收起内容,加防抖功能
文章目录 一、场景二、实现代码1.子组件代码结构2.父组件 一、场景 这两天做项目,此产品提出需求 要求详情页的顶部区域要在鼠标划入后展开里面的内容,鼠标划出要收起部分内容,详情底部的内容高度要自适应,我这里运用了鼠标事件t…...

大模型语料库的构建过程 包括知识图谱构建 垂直知识图谱构建 输入到sql构建 输入到cypher构建 通过智能体管理数据生产组件
以下是大模型语料库的构建过程: 一、文档切分语料库构建 数据来源确定: 首先,需要确定语料库的数据来源。这些来源可以是多种多样的,包括但不限于: 网络资源:利用网络爬虫技术从各种网站(如新闻…...

阿里云ECS服务器域名解析
阿里云ECS服务器域名解析,以前添加两条A记录类型,主机记录分别为www和,这2条记录都解析到服务器IP地址。 1.进入阿里云域名控制台,找到域名 ->“解析设置”->“添加记录” 2.添加一条记录类型为A,主机记录为www,…...

牛客周赛71:A:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 \hspace{15pt}对于给定的两个正整数 nnn 和 kkk ,是否能构造出 kkk 对不同的正整数 (x,y)(x,y)(x,y) ,使得 xynxynxyn 。 \hspace{15pt}我们认为两对正整数 (…...
查询产品所涉及的表有(product、product_admin_mapping)
文章目录 1、ProductController2、AdminCommonService3、ProductApiService4、ProductCommonService5、ProductSqlService1. 完整SQL分析可选部分(条件筛选): 2. 涉及的表3. 总结4. 功能概述 查询指定管理员下所有产品所涉及的表?…...
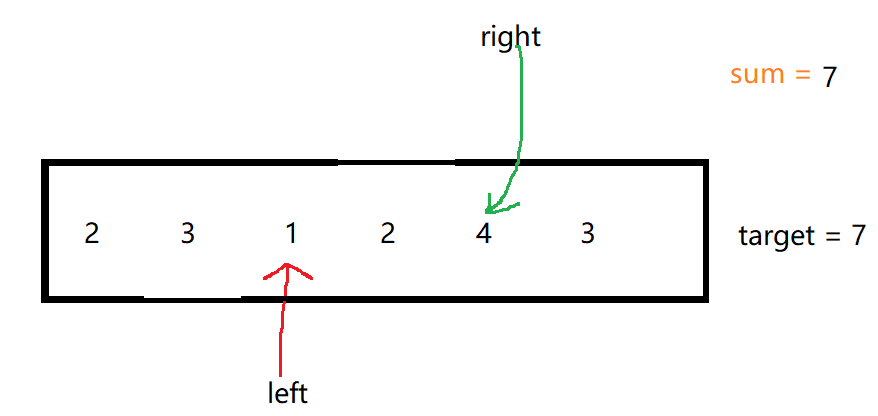
算法基础学习Day5(双指针、动态窗口)
文章目录 1.题目2.题目解答1.四数之和题目及题目解析算法学习代码提交 2.长度最小的子数组题目及题目解析滑动窗口的算法学习方法一:单向双指针(暴力解法)方法二:同向双指针(滑动窗口) 代码提交 1.题目 18. 四数之和 - 力扣(LeetCode&#x…...
docker 部署 mysql 9.0.1
docker 如何部署 mysql 9 ,请看下面步骤: 1. 先看 mysql 官网 先点进去 8 版本的 Reference Manual 。 选择 9.0 版本的。 点到这里来看, 这里有一些基础的安装步骤,可以看一下。 - Basic Steps for MySQL Server Deployment wit…...

关于小标join大表,操作不当会导致笛卡尔积,数据倾斜
以前总是说笛卡尔积,笛卡尔积,没碰到过,今天在跑流程调度时,就碰到笛卡尔积了,本来,就是查询几个编码的信息,然后由于使用的是with tmp as,没使用where in ,所以跑的很慢 现象&#…...

SpringMVC全局异常处理
一、Java中的异常 定义:异常是程序在运行过程中出现的一些错误,使用面向对象思想把这些错误用类来描述,那么一旦产生一个错误,即创建某一个错误的对象,这个对象就是异常对象。 类型: 声明异常࿱…...

出海服务器可以用国内云防护吗
随着企业国际化进程的加速,越来越多的企业选择将业务部署到海外服务器上,以便更贴近国际市场。然而,海外服务器也面临着来自全球各地的安全威胁和网络攻击。当出海服务器遭受攻击时,是否可以借助国内的云服务器来进行有效的防护呢…...

从零开始的使用SpringBoot和WebSocket打造实时共享文档应用
在现代应用中,实时协作已经成为了非常重要的功能,尤其是在文档编辑、聊天系统和在线编程等场景中。通过实时共享文档,多个用户可以同时对同一份文档进行编辑,并能看到其他人的编辑内容。这种功能广泛应用于 Google Docs、Notion 等…...

Ant Design Pro实战--day01
下载nvm https://nvm.uihtm.com/nvm-1.1.12-setup.zip 下载node.js 16.16.0 //非此版本会报错 nvm install 16.16.0 安装Ant Design pro //安装脚手架 npm i ant-design/pro-cli -g //下载项目 pro create myapp //选择版本 simple 安装依赖 npm install 启动umi yarn add u…...

pcl点云库离线版本构建
某天在摸鱼的小邓接到任务需要进行点云数据的去噪,在万能的github中发现如下pcl库非常好使,so有了此, 1.下载vs2017连接如下: ed2k://|file|mu_visual_studio_community_2017_version_15.1_x86_x64_10254689.exe|1037144|12F5C1…...

字节高频算法面试题:小于 n 的最大数
问题描述(感觉n的位数需要大于等于2,因为n的位数1的话会有点问题,“且无重复”是指nums中存在重复,但是最后返回的小于n最大数是可以重复使用nums中的元素的): 思路: 先对nums倒序排序 暴力回…...

ElasticSearch常见面试题汇总
一、ElasticSearch基础: 1、什么是Elasticsearch: Elasticsearch 是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。 全文检索是指对每一个词建立一个索引…...

Spring Boot如何实现防盗链
一、什么是盗链 盗链是个什么操作,看一下百度给出的解释:盗链是指服务提供商自己不提供服务的内容,通过技术手段绕过其它有利益的最终用户界面(如广告),直接在自己的网站上向最终用户提供其它服务提供商的…...

工作中常用springboot启动后执行的方法
前言: 工作中难免会遇到一些,程序启动之后需要提前执行的需求。 例如: 初始化缓存:在启动时加载必要的缓存数据。定时任务创建或启动:程序启动后创建或启动定时任务。程序启动完成通知:程序启动完成后通…...

力扣-图论-3【算法学习day.53】
前言 ###我做这类文章一个重要的目的还是给正在学习的大家提供方向和记录学习过程(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非…...

SRWE终极指南:5分钟学会游戏窗口分辨率自定义技巧
SRWE终极指南:5分钟学会游戏窗口分辨率自定义技巧 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 想要在游戏中获得超高清截图,却受限于系统预设的分辨率?想要在窗口模式下享…...

字节投2000亿、DeepSeek募500亿:国产AI算力军备竞赛进入“核弹级“对决
一、一条被低估的新闻2026年5月,当大多数人还在关注GPT-5.5的幻觉率降了多少个百分点时,中国AI产业发生了一件更具战略意义的大事——字节跳动宣布2026年AI基础设施资本支出超2000亿元,几乎同时,DeepSeek传出拟募资最高500亿元&am…...

Encounter/Innovus GIFT TCL 脚本流程索引清单
目录 一、 布局阶段 (Placement) 二、 布线阶段 (Routing) 三、 时序阶段 (Timing) 四、 电源阶段 (Power) 五、 IO 与端口处理 六、 调试与辅助工具 一、 布局阶段 (Placement) 脚本名称 核心用途 调用场景 userAddAllHInsts.tcl 为源模块中的每个扇出添加缓冲器 解决高扇…...

2026程序员危机:AI岗位暴涨12倍,传统开发即将“毕业”?转型AI大模型开发,才是破局关键!
2026年技术圈将面临巨大变革,AI岗位需求激增,传统编程岗位面临淘汰风险。企业更看重懂AI、能提效的复合型人才。程序员需转型AI大模型开发,掌握系统设计、代码审查及AI工具应用能力。北大青鸟推出AI大模型开发实战营,聚焦落地开发…...

欲取全国第一先取北京第一,CSDN 博客排名现在是郑州第一
欲取全国第一先取北京第一,CSDN 博客排名现在是郑州第一 首先,必须得说,郑州第一,太牛了! 这绝对是对你技术输出和持续分享的高度认可,含金量十足。 不过,关于“欲取全国第一先取北京第一”这个…...

国家级数据仓库构建:从爬取到应用的全流程实践指南
1. 项目概述与核心价值最近在整理一个数据项目时,我偶然发现了一个名为“national_data”的仓库,作者是Ddhjx。这个项目名听起来平平无奇,但点进去之后,我发现它远不止是一个简单的数据集合。它本质上是一个结构化的、持续更新的国…...

天气图片分类模型:基于迁移学习与GPU资源优化
天气图片分类模型:基于迁移学习与GPU资源优化 1. 引言 天气识别在自动驾驶、户外监控、气象服务等领域具有重要应用价值。传统方法依赖于手工设计的特征(如纹理、颜色直方图),鲁棒性不足。深度学习尤其是卷积神经网络(CNN)能够自动从图像中学习层次化特征,显著提升分类…...

如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题
如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否厌倦了炉石传说中重复性的…...

动物森友会岛屿设计终极指南:用Happy Island Designer轻松规划你的梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer轻松规划你的梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会…...

RedwoodJS熔断器:构建高可用应用的熔断机制与故障隔离终极指南 [特殊字符]
RedwoodJS熔断器:构建高可用应用的熔断机制与故障隔离终极指南 🔧 【免费下载链接】redwood RedwoodGraphQL 项目地址: https://gitcode.com/gh_mirrors/re/redwood 在当今微服务架构盛行的时代,应用的高可用性成为了开发者的首要关注…...