开源数据同步中间件(Dbsyncer)简单玩一下 mysql to mysql 的增量,全量配置
一、什么是Dbsyncer
1、介绍

Dbsyncer是一款开源的数据同步中间件,提供MySQL、Oracle、SqlServer、PostgreSQL、Elasticsearch(ES)、Kafka、File、SQL等同步场景,支持上传插件自定义同步转换业务,提供监控全量和增量数据统计图、应用性能预警等。
2、特点
1、组合驱动,自定义库同步到库组合,关系型数据库与非关系型之间组合,任意搭配表同步映射2、关系实时监控,驱动全量或增量实时同步运行状态、结果、同步日志和系统日
项目地址:
https://gitee.com/ghi/dbsyncer
应用场景

3、下载安装包
- 安装JDK 1.8(省略详细)
- 下载安装包dbsyncer-x.x.x.zip(也可手动编译)
- 解压安装包,Window执行bin/startup.bat,Linux执行bin/startup.sh
- 打开浏览器访问:http://127.0.0.1:18686
- 账号和密码:admin/admin
4、阿里云镜像地址
docker pull registry.cn-hangzhou.aliyuncs.com/xhtb/dbsyncer:latest
docker pull registry.cn-hangzhou.aliyuncs.com/xhtb/dbsyncer-enterprise:latest
docker pull registry.cn-hangzhou.aliyuncs.com/lifewang/dbsyncer:latest
5、手动编译
先确保环境已安装JDK和Maven
$ git clone https://gitee.com/ghi/dbsyncer.git
$ cd dbsyncer
$ chmod u+x build.sh
$ ./build.sh
二、Dbsyncer的安装(这里只演示虚拟机的,java代码的这里不演示)
1.下载好安装包后,把安装包放在虚拟机的 /opt/momodules
然后在Linux执行bin/startup.sh,就可以进去web界面
2.然后解压到 /opt/installs下,不需要配置文件就可以启动他的web界面
3.进去web界面,地址为
http://192.168.150.120:18686
端口号为虚拟机的ip地址
账号密码为:admin
然后就能进入界面

三、mysql to mysql 的全量配置和数据演示
前期准备,在虚拟机的mysql创建一个库(这里为testmysql)然后创建表,导入数据,大概100万调数据
drop table if exists t;
CREATE TABLE t(id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';insert into testmysql values(1,1, 25, 'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');set @i=1;
select * from t;
#==================此处拷贝反复执行,直接符合预想的数据量===================
#执行20次即2的20次方=1048576 条记录
#执行23次即2的23次方=8388608 条记录
#执行24次即2的24次方=16777216 条记录
#......
insert into t(dept, age, name, create_time, last_login_time)
select left(rand()*10,1) as dept, #随机生成1~10的整数FLOOR(20+RAND() *(50 - 20 + 1)) as age, #随机生成20~50的整数concat('user_',@i:=@i+1), #按序列生成不同的namedate_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), #生成有时间大顺序随机注册时间date_add(date_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), interval + cast(rand()*1000000 as signed) SECOND) #生成有时间大顺序的随机的最后登录时间
from t;
select count(1) from t;
#==================此处结束反复执行=====================
然后再建一个数据库接收数据test02(要提前建好表)
drop table if exists t1;
CREATE TABLE t1 (id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';
创建好库后,需要给库单独一个用户授权,否则web界面链接不上去
CREATE USER 'ae86'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'ae86'@'%';
GRANT SELECT ON test03.* TO 'ae86'@'%';
flush privileges;grant process on *.* to ae86;
flush privileges;
show processlist
如果第一步执行不了的话,需要修改mysql的密码规则,然后修改
再开始数据同步之前,需要设置mysql的设置
官方使用手册:
介绍 - Wiki - Gitee.com
这里需要修改mysql的my.ini 或 my.cnf配置文件
我的my.cnf的位置在 /etc/my.cnf
然后把以下代码加进去
#log日志开启
log_bin=ON
#服务唯一ID
server_id=1
log-bin=mysql_bin
binlog-format=ROW
max_binlog_cache_size = 256M
max_binlog_size = 512M
expire_logs_days = 7
#监听同步的库, 多个库使用英文逗号“,”拼接
replicate-do-db=test03,testmysql,test02
下一步进去web界面添加链接
添加ip和库名

分别将对应的库添加进去
然后添加驱动,创建链接

先择对应的库,然后选择对应的表

按照图片位置,一次点击,配置是默认配置
点击右上角齿轮,启动数据同步
 在界面可以看见进度,也可以看监控界面
在界面可以看见进度,也可以看监控界面


在监控界面可以看到之间的操作

任务成功,这时候可以去MySQL中就可以看到已经同步的数据

四、mysql to mysql 的增量配置和演示
和全量配置一样,但是有不同的是,在增量配置之前要把,mysql的binlog开启
此操作在 /etc/my.cnf 下加入
3先查看是否开启
SHOW VARIABLES LIKE 'log_bin';
#开启
log_bin=ON
数据准备
常见test03库,创建t3和t3—ord表
drop table if exists t3;
CREATE TABLE t3 (id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';insert into t3 values(1,1, 25, 'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
insert into t3 values(2,2, 26, '测试同步', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
insert into t3 values(3,3, 26, '测试同步', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
insert into t3 values(4,4, 26, '测试同步', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
select * from t3;drop table if exists t3_ord;
CREATE TABLE t3_ord (id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',dept tinyint not null comment '部门id',age tinyint not null comment '年龄',name varchar(30) comment '用户名称',create_time datetime not null comment '注册时间',last_login_time datetime comment '最后登录时间') comment '测试表';
insert into t3_ord values(1,1, 25, 'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
select * from t3_ord;
创建表之后进入web界面,添加驱动
按照顺序一次点点点

更改定时任务(我这里是5秒一次)

正则表达式



开启任务后,向t3添加数据后,t3的数据可以同步到t3—ord中
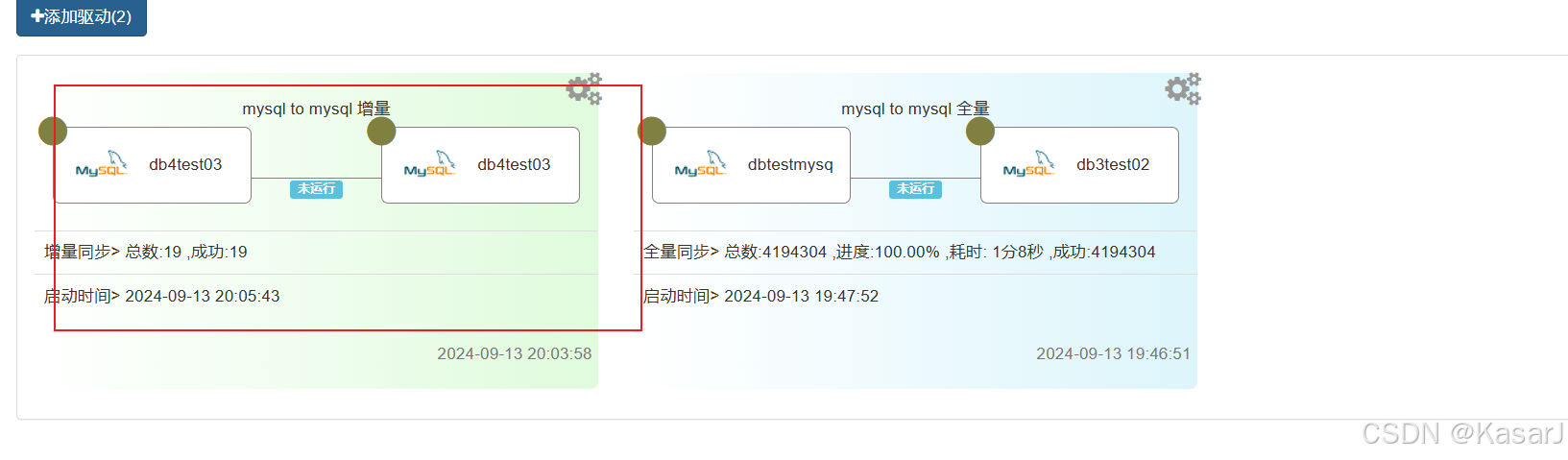
定时任务要手动关闭,不关闭会一直执行。
相关文章:
开源数据同步中间件(Dbsyncer)简单玩一下 mysql to mysql 的增量,全量配置
一、什么是Dbsyncer 1、介绍 Dbsyncer是一款开源的数据同步中间件,提供MySQL、Oracle、SqlServer、PostgreSQL、Elasticsearch(ES)、Kafka、File、SQL等同步场景,支持上传插件自定义同步转换业务,提供监控全量和增量数据统计图、应用性能预警…...

虚幻引擎开发命名规则
UE的命名规则如下: 模版类以T作为前缀,例如TArray, TMap, TSet。UObject派生类都以U前缀。AActor派生类都以A前缀。SWidget派生类都以S前缀。全局对象使用G开头,如GEngine。抽象接口以I前缀。枚举以E开头。bool变量以b前缀,如bPe…...

解释强化学习中的batch, epoch, episode有什么区别与联系,分别有什么作用
强化学习中的batch, epoch, episode 1.Batch1.1 最后一个batch不足32该怎么处理?1.1.1 方法一:丢弃最后一个不完整的 batch1.1.2 方法二:填充最后一个不完整的 batch1.1.3 选择哪种方法? 2.Epoch3.Episode4.区别与联系4.1 区别4.2…...

MVC基础——市场管理系统(一)
文章目录 项目地址一、创建项目结构1.1 创建程序以及Controller1.2 创建View1.3 创建Models层,并且在Edit页面显示1.4 创建Layou模板页面1.5 创建静态文件css中间件二、Categories的CRUD2.1 使用静态仓库存储数据2.2 将Categorie的列表显示在页面中(List)2.3 创建_ViewImport.…...

使用docker-compose安装Milvus向量数据库及Attu可视化连接工具
首先确保系统已经安装上了docker 然后去https://github.com/docker/compose/releases/下载安装docker-compose 跟随自己下系统和服务器情况下载 上传到服务器 mv docker-compose-linux-aarch64 docker-compose chmod x docker-compose2.dockr-compose命令 docker-compose …...
或current_timestamp的异同)
PostgreSQL函数中使用now()或current_timestamp的异同
在PostgreSQL函数中使用now()或current_timestamp可以获取当前的日期和时间。 now()函数返回当前的日期和时间,包括时区信息。它可以用于记录操作的时间戳或在查询中进行时间比较。 current_timestamp函数也返回当前的日期和时间,但不包括时区信息。它…...

开发类似的同款小程序系统制作流程
很多老板想要开发一款和别人家类似的同款小程序系统,但是不知道该怎么开发制作,本文就为大家详细介绍一下开发类似的同款小程序的流程为大家做参考。 一、前期准备找到对标小程序:首先,需要找到你想要模仿的同款小程序࿰…...

bsp是板级支持包
里面有很多的针对该型号的板子的函数,可以直接调用,也可以直接在里面。 也可以在vivado的sdk上,看到很多相关文档和寄存器偏移等等。...

P1784 数独 C语言(普遍超时写法)
题目: https://www.luogu.com.cn/problem/P1784 题目描述 数独是根据 99 盘面上的已知数字,推理出所有剩余空格的数字,并满足每一行、每一列、每一个粗线宫内的数字均含 1−9 ,不重复。每一道合格的数独谜题都有且仅有唯一答案…...

基于最新的Apache StreamPark搭建指南
一、StreamPark 的介绍 官方文档:Apache StreamPark (incubating) | Apache StreamPark (incubating) 中文文档:Apache StreamPark (incubating) | Apache StreamPark (incubating)Github地址:https://github.com/apache/incubator-streampark Apache StreamPark™ 是一个…...

思科模拟器路由器的基本配置
一、实验目的 了解路由器的作用掌握路由器的基本配置方法 3、掌握路由器模块的使用和互连方式 二、实验环境 2811路由器一台,计算机两台,Console配置线一根,网线若干;本实验拓扑图如图8-1所示;计算机IP地址规划如表8-…...

vue3 computed watch 拓展reduce函数
computed computed 计算属性计算属性 就是当依赖的属性的值发生变化的时候,才会触发他的更改,如果依赖的值,不发生变化的时候,使用的是缓存中的属性值。 import {reactive,ref,computed} from "vue"//price 改变&…...

MyBatis 中 SQL 片段复用
MyBatis 中 SQL 片段复用:提升代码效率与可维护性 在使用 MyBatis 进行数据库操作时,常常会遇到一些 SQL 语句的部分内容重复出现的情况,比如多个查询语句都涉及相同的字段列表。这时,MyBatis 的 SQL 片段复用功能就派上用场了。…...

【实操GPT-SoVits】声音克隆模型图文版教程
项目github地址:https://github.com/RVC-Boss/GPT-SoVITS.git官方教程:https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e/tkemqe8vzhadfpeu本文旨在迅速实操GPT-SoVits项目,不阐述技术原理(后期如果有时间研究&#…...

用HTML和CSS实现3D圣诞树效果
简介 随着圣诞节的临近,许多开发者喜欢在自己的项目中加入一些节日氛围。今天,我们将学习如何使用HTML和CSS来实现一个简单的3D圣诞树效果。通过这些基本的前端技术,我们可以制作出富有创意的视觉效果,并为网站增添节日气氛。 本…...

Burp入门(10)-IP伪造插件
声明:学习视频来自b站up主 泷羽sec,如涉及侵权马上删除文章 感谢泷羽sec 团队的教学 视频地址:IP伪造和爬虫审计_哔哩哔哩_bilibili 本文详细介绍IP伪造插件Burp Fake IP使用。 一、插件安装 打开Burp Suite。进入扩展标签页。点击添加&…...

Mac软件推荐
Mac软件推荐 截图SnipasteXnipBob 快捷启动Raycast 系统检测Stats 解压缩The UnarchiverKeka(付费) 视频播放IINA 视频下载Downie(付费) 屏幕刘海TopNotchMediaMate(付费)NotchDrop(付费&#x…...

实验14 RNN的记忆能力和梯度爆炸实验
一 循环神经网络的记忆能力 1.数据集构建 创建了一个DigitSumDataset 类,包括初始化函数init、数据生成函数 generate_data、数据加载函数 load_data、__len__ 方法、__getitem__ 方法。 init函数:接受的参数是data_path( 存放数据集的目录…...
LeetCode面试题04 检查平衡性
题目: 实现一个函数,检查二叉树是否平衡。在这个问题中,平衡树的定义如下:任意一个节点,其两棵子树的高度差不超过 1。 一、平衡树定义: 二叉树,一种由节点组成的树形数据结构,每…...

oracle归档模式下的快速热备方法-适合小库
在我们的一些小型的oracle生产库中,有些时候我们可以在不停库且不使用rman的情况下实现数据库的热备。该热备的原理是通过控制数据文件块头的scn号在备份时候不变化,进而保证备份的数据文件数据一致性。 一、环境 数据库版本: 数据库需要开启…...

从MWC 2016看5G与物联网:技术演进、产业博弈与生态构建
1. 从巴塞罗那看2016年移动通信的十字路口 时间回到2016年初,如果你身处通信行业,那么2月底的日程表上,巴塞罗那的“移动世界大会”绝对是一个绕不开的焦点。那不是一个普通的展会,更像是一个行业在技术迭代、市场转型和地缘政治多…...

基于Refine框架的企业级后台管理系统实战开发指南
1. 项目概述与核心价值最近在梳理企业内部后台管理系统的技术栈时,我又一次把目光投向了refine这个框架。如果你也和我一样,长期被各种业务后台的重复性开发工作所困扰——比如没完没了的增删改查(CRUD)界面、复杂的权限控制、数据…...

从ARM到FPGA:手把手教你用Vivado双口RAM IP核搭建跨芯片通信桥
从ARM到FPGA:构建高性能双口RAM通信桥的工程实践 在异构计算架构中,FPGA与处理器的协同工作已成为提升系统性能的关键方案。Xilinx Vivado工具链中的双口RAM IP核,为解决跨芯片数据交换提供了硬件级的优雅实现。本文将深入探讨如何将这一技术…...

【Midjourney 2026审美趋势白皮书】:基于127万组V6–V7生成样本的AI视觉演化模型预测
更多请点击: https://intelliparadigm.com 第一章:Midjourney 2026审美趋势白皮书导论 人工智能图像生成正从“可用”迈向“可策展”阶段。Midjourney v6.5 及其预发布的 Beta-2026 引擎已展现出对文化语境、跨媒介质感与时间性美学的深层建模能力——这…...

AJV $data引用:10个终极动态验证规则实现指南 [特殊字符]
AJV $data引用:10个终极动态验证规则实现指南 🚀 【免费下载链接】ajv The fastest JSON schema Validator. Supports JSON Schema draft-04/06/07/2019-09/2020-12 and JSON Type Definition (RFC8927) 项目地址: https://gitcode.com/gh_mirrors/aj/…...

电池创新如何跨越量产鸿沟:从实验室到工厂的工程化实践
1. 从实验室到工厂:电池创新的“量产魔咒”最近几年,电池行业绝对是资本和媒体眼中的“香饽饽”。动辄数十亿、上百亿美元的投资砸向新的生产设施和前沿技术,目标直指电动汽车、智能电网乃至整个智慧城市的能源基石。新闻稿里,我们…...

本地化AI编码助手codex-assistant:部署、实战与安全指南
1. 项目概述:一个本地化的AI编码助手最近在折腾一个挺有意思的开源项目,叫codex-assistant。简单来说,它就是一个能让你用自然语言直接驱动本地代码任务的工具。想象一下,你对着一个命令行窗口说“给我写个Python函数,…...

Cursor-Buddy:基于AI的Web界面语音交互与视觉引导助手
1. 项目概述与核心价值最近在捣鼓一个挺有意思的开源项目,叫cursor-buddy。简单来说,它是一个能“住”在你鼠标光标里的AI助手,专门为Web应用设计。想象一下,你在浏览一个复杂的后台管理系统或者一个数据看板,突然想找…...

可视化监控大盘构建:Grafana搭配Prometheus的艺术
在软件测试领域,我们早已不满足于“功能正确”这一单一维度。性能表现、资源消耗、服务稳定性、异常预警……这些非功能质量属性正逐渐成为衡量系统成熟度的关键标尺。而要将这些隐性的、动态的指标转化为可感知、可决策的信息,一套高效、灵活的可视化监…...
)
别再死记硬背关键帧了!用Blender 2.83.9的Rigify,带你拆解走路动画的物理原理(附膝跳问题修复)
别再死记硬背关键帧了!用Blender 2.83.9的Rigify,带你拆解走路动画的物理原理(附膝跳问题修复) 当你第一次尝试用Blender制作走路动画时,是否遇到过这样的困境:明明按照教程一步步设置了关键帧,…...