基于streamlit搭简易前端页面
前端小白第一次用streamlit搭简易页面,记录一下。
一些tips
每次与页面进行交互,如点击按钮、上传文件等,streamlit就会重新运行整个页面的所有代码。如果在页面渲染前需要对上传文件做很复杂的操作,重新运行所有代码就会重复这个过程,会导致页面加载内容较慢。因此可以把不会变化的内容存起来,避免重新对文件进行处理。
streamlit的渲染顺序和代码定义的分布一致,例如先在代码里写了一级标题就先渲染一级标题,先写占位符就先渲染占位符。所以排序在前的部分渲染时未渲染部分会是灰色。
一些命令
将页面分成两列
left_col, right_col = st.columns([1, 1])在占位符里动态渲染变化内容
left_content_placeholder = st.empty()with left_content_placeholder.container():st.components.v1.html(st.session_state['current_content'], height=600, scrolling=True)在页面加载时滚动到当前匹配的结果
scroll_script = """<script>document.addEventListener('DOMContentLoaded', function() {var element = document.getElementById('current_match');if(element) {element.scrollIntoView({ behavior: 'smooth', block: 'center' });}});</script>"""代码示例
import streamlit as st
from docx import Document
import mammoth
import os
from bs4 import BeautifulSoup
import re
from PIL import Image
import base64
import markdown# 解析Word文档的函数,保留原格式
def parse_word_document_for_table(file):try:# 使用Mammoth将文档转换为HTML以保留格式result = mammoth.convert_to_html(file)html_content = result.value# 使用python-docx处理表格部分document = Document(file)tables_html = ""# 存储所有表格的数据all_tables_data = []# 遍历文档中的所有段落和表格prev_paragraph = ""for element in document.element.body:if element.tag.endswith('tbl'): # 检查是否为表格元素# 获取当前表格table = document.tables[len(all_tables_data)] # 获取当前表格# 使用前一个段落作为表格标题table_title = prev_paragraph.strip() if prev_paragraph else "无标题"# 在表格前添加标题tables_html += f"<h3>{table_title}</h3>" # 这里使用<h3>标签来显示标题,或者根据需要使用其他标签tables_html += "<table border='1' style='border: 1px solid black; border-collapse: collapse; width: 100%;'>"for row in table.rows:tables_html += "<tr>"for cell in row.cells:cell_content = cell.text.replace('\n', '<br>') # 处理单元格内换行tables_html += f"<td style='padding: 5px; border: 1px solid black; text-align: left; vertical-align: top;'>{cell_content}</td>"tables_html += "</tr>"tables_html += "</table><br>"all_tables_data.append(1)elif element.tag.endswith('p'): # 检查是否为段落prev_paragraph = element.text # 获取当前段落的文本作为表格的标题# 将表格的HTML拼接到文档内容中# html_content += tables_htmlhtml_content = tables_html return html_contentexcept Exception as e:return f"Error: {str(e)}"def parse_word_document(file):try:# 使用Mammoth将文档转换为HTML以保留格式result = mammoth.convert_to_html(file)html_content = result.valuereturn html_contentexcept Exception as e:return f"Error: {str(e)}"def extract_markdown(file):content_bytes = file.read()content_text = content_bytes.decode('utf-8')html = markdown.markdown(content_text)return htmldef main():DOCUMENT_PATHS = {"标题验证": "./headings.md","表格信息提取": "./tables_information.md","表格验证结果": "./output.md"}# 设置页面为宽布局st.set_page_config(page_title="项目报告核验", layout="wide")logo_path = './logo.jpg'st.image(logo_path, width=200)st.markdown("<h1 style='text-align: center;'>项目报告核验</h1>", unsafe_allow_html=True)# 使用自定义 CSS 来居中标题st.markdown("""<style>.left-header {display: flex;justify-content: center;align-items: center;height: 100%;text-align: center;}.right-header {display: flex;justify-content: center;align-items: center;height: 100%;text-align: center;}</style>""", unsafe_allow_html=True)# 创建两列布局,左边显示上传文档,右边显示a、b、c文档left_col, right_col = st.columns([1, 1]) # 调整列的宽度比例,左边更宽# 初始化状态if 'first_doc_uploaded' not in st.session_state:st.session_state['first_doc_uploaded'] = Trueif 'left_doc_uploaded' not in st.session_state:st.session_state['left_doc_uploaded'] = Falseif 'right_doc_content' not in st.session_state:st.session_state['right_doc_content'] = ""if 'right_doc_error' not in st.session_state:st.session_state['right_doc_error'] = ""if 'matches' not in st.session_state:st.session_state['matches'] = []if 'current_index' not in st.session_state:st.session_state['current_index'] = -1if 'first_render' not in st.session_state:st.session_state['first_render'] = Truewith right_col: st.markdown('<div class="right-header"><h2>内容展示区域</h2></div>', unsafe_allow_html=True) tab_selection2 = st.selectbox("选择展示内容:",("标题验证", "表格信息提取", "表格验证结果")) # 上传文档部分(左列)with left_col:st.markdown('<div class="left-header"><h2>项目文件上传及原文展示</h2></div>', unsafe_allow_html=True)uploaded_file = st.file_uploader("上传Word文档", type=["docx"])search_keyword = st.text_input("输入要搜索的关键词")search_button = st.button("查找/查找下一个")left_content_placeholder = st.empty()# 处理文件上传逻辑if not uploaded_file:st.session_state['current_content'] = Nonest.session_state['left_doc_uploaded'] = Falseif not st.session_state['current_content'] and uploaded_file:try:# 解析上传的Word文档content = parse_word_document_for_table(uploaded_file)st.session_state['left_doc_uploaded'] = Truest.session_state['current_content'] = contentexcept Exception as e:st.error(str(e))# if st.session_state['left_doc_uploaded']:with left_content_placeholder.container():st.components.v1.html(st.session_state['current_content'], height=600, scrolling=True)# 处理搜索按钮点击事件,只有在文档已上传后才生效if st.session_state['left_doc_uploaded'] and search_button:if search_keyword!= st.session_state.get('last_search_keyword', ''):# 关键词变化了,重新执行搜索st.session_state['last_search_keyword'] = search_keywordst.session_state['matches'] = [] # 清空上次的匹配项st.session_state['current_index'] = -1 # 重置为-1,表示没有匹配项content = parse_word_document_for_table(uploaded_file)st.session_state['current_content'] = content # 重置为原始文档内容# 执行新的搜索if search_keyword:soup_new_search = BeautifulSoup(content, 'html.parser')paragraphs = soup_new_search.find_all(['p', 'span', 'div', 'td', 'h3'])pattern = re.compile(re.escape(search_keyword), re.IGNORECASE)matches = []for idx, paragraph in enumerate(paragraphs):if pattern.search(paragraph.get_text()):highlighted_text = pattern.sub(lambda match: f"<mark style='background-color: yellow;'>{match.group(0)}</mark>", paragraph.decode_contents())paragraph.clear()paragraph.append(BeautifulSoup(highlighted_text, 'html.parser'))matches.append(paragraph)st.session_state['matches'] = matchesst.session_state['current_index'] = 0 # 重新开始从第一个匹配项st.session_state['current_content'] = str(soup_new_search) # 更新文档内容为高亮后的内容if matches:for idx, paragraph in enumerate(matches):if idx == st.session_state['current_index']:paragraph['id'] = 'current_match'paragraph['style'] = 'background-color: orange;' # 当前匹配项用橙色高亮else:paragraph['id'] = ''paragraph['style'] = 'background-color: yellow;' # 其他匹配项用黄色高亮# 保存高亮后的内容st.session_state['current_content'] = str(soup_new_search)elif search_keyword == st.session_state.get('last_search_keyword', ''):# 关键词没有变化,查找下一个匹配项if st.session_state['matches']:# 只有在有匹配项时才进行查找st.session_state['current_index'] = (st.session_state['current_index'] + 1) % len(st.session_state['matches'])soup_repeat = BeautifulSoup(st.session_state['current_content'], 'html.parser')paragraphs = soup_repeat.find_all(['p', 'span', 'div', 'td', 'h3'])pattern = re.compile(re.escape(search_keyword), re.IGNORECASE)# 更新高亮颜色idx =-1for paragraph in paragraphs:# 对当前匹配项和上一项进行样式更新if pattern.search(paragraph.get_text()):idx +=1if idx == st.session_state['current_index']:# 当前匹配项用橙色高亮paragraph['id'] = 'current_match'paragraph['style'] = 'background-color: orange;'else:# 其他匹配项用黄色高亮paragraph['id'] = ''paragraph['style'] = 'background-color: yellow;'# 保存高亮后的内容st.session_state['current_content'] = str(soup_repeat)#在页面加载时滚动到当前匹配的结果scroll_script = """<script>document.addEventListener('DOMContentLoaded', function() {var element = document.getElementById('current_match');if(element) {element.scrollIntoView({ behavior: 'smooth', block: 'center' });}});</script>"""with left_content_placeholder.container():st.components.v1.html(st.session_state['current_content']+ scroll_script , height=600, scrolling=True)with right_col: right_content_placeholder = st.empty() if st.session_state['left_doc_uploaded']:selected_document = DOCUMENT_PATHS.get(tab_selection2)else:selected_document = Nonest.session_state['right_doc_content'] = ""right_content_placeholder.empty()if 'right_selected_doc' not in st.session_state:st.session_state['right_selected_doc'] = Noneif selected_document:try:with open(selected_document, "rb") as file:content = extract_markdown(file)if content.startswith("Error"):st.session_state['right_doc_error'] = contentelse:st.session_state['right_doc_content'] = contentst.session_state['right_selected_doc'] = selected_documentexcept Exception as e:st.error(str(e))if st.session_state["right_doc_content"]:with right_content_placeholder.container():st.markdown(f"""<div style="height: 750px; overflow-y: scroll; padding: 10px; border: 1px solid #ccc; border-radius: 5px;">{st.session_state["right_doc_content"]}</div>""", unsafe_allow_html=True)if __name__ == "__main__":main()相关文章:

基于streamlit搭简易前端页面
前端小白第一次用streamlit搭简易页面,记录一下。 一些tips 每次与页面进行交互,如点击按钮、上传文件等,streamlit就会重新运行整个页面的所有代码。如果在页面渲染前需要对上传文件做很复杂的操作,重新运行所有代码就会重复这…...

Harmony Next开发通过bindSheet绑定半模态窗口
示例概述 Harmony Next开发通过bindSheet绑定半模态窗口 知识点 半模态窗口父子组件传值 组件 LoginComponent Component struct LoginComponent {// Prop 父子单项绑定值Prop message:string // Link 父子双向绑定值Link userName:stringLink password:stringLink isSh…...

YOLOv11改进,YOLOv11添加DLKA-Attention可变形大核注意力,WACV2024 ,二次创新C3k2结构
摘要 作者引入了一种称为可变形大核注意力 (D-LKA Attention) 的新方法来增强医学图像分割。这种方法使用大型卷积内核有效地捕获体积上下文,避免了过多的计算需求。D-LKA Attention 还受益于可变形卷积,以适应不同的数据模式。 理论介绍 大核卷积(Large Kernel Convolu…...

【51单片机】矩阵按键快速上手
51单片机矩阵按键是一种在单片机应用系统中广泛使用的按键排列方式,特别适用于需要多个按键但I/O口资源有限的情况。以下是对51单片机矩阵按键的详细介绍: 一、矩阵按键的基本概念 定义:矩阵按键,又称行列键盘,是…...

一文说清:git reset HEAD原理
1 使用add命令,将文件添加到暂存区 命令如下: 对比结果如下: 2 使用reset HEAD命令 如下: 结果对比如下: 忽略logs目录下的内容。 发现只是修改了index暂存区的内容。删掉了原来添加到暂存区的对象ID&#x…...

【前端面试题】书、定位问题、困难
看过什么书 《JavaScript 高级程序设计(第 4 版)》(作者:Matt Frisbie) 这是一本深入学习 JavaScript 语言的经典书籍。它详细地涵盖了 JavaScript 的高级特性,包括原型链、闭包、异步编程等复杂概念。以闭…...

WADesk 升级 Webpack5 一些技术细节认识5和4的区别在哪里
背景 升级过程中发现有很多新的知识点,虽然未来可能永远都不会再遇到,但是仍然是一次学习的好机会,可以让自己知道,打包软件的进化之路,和原来 Webpack 4 版本的差异在哪里。 移除的依赖记录 babel/register: 在 Nod…...

学习 Dockerfile 常用指令
学习 Dockerfile 常用指令 在构建 Docker 镜像时,Dockerfile 文件是一份至关重要的配置文件,它定义了构建镜像的所有步骤。通过在 Dockerfile 中使用不同的指令(命令),我们可以控制镜像的构建过程、设置环境、指定执行…...

day11 性能测试(3)——Jmeter 断言+关联
【没有所谓的运气🍬,只有绝对的努力✊】 目录 1、复习 2、查看结果树 多个http请求原因分析 3、作业 4、Jmeter断言 4.1 响应断言 4.1.1 案例 4.1.2 小结 4.2 json断言 4.2.1 案例 4.2.2 小结 4.3 断言持续时间 4.3.1 案例 4.3.2 小结 4.…...

ES6中的map和set
Map JS的数据对象(Obejct),本质上是键值对的集合(Hash结构),但是传统上只能用字符串当作键(一定程度上对其的使用有限制) 比如下面代码 const data {} const element document.…...

UE5中实现Billboard公告板渲染
公告板(Billboard)通常指永远面向摄像机的面片,游戏中许多技术都基于公告板,例如提示拾取图标、敌人血槽信息等,本文将使用UE5和材质节点制作一个公告板。 Gif效果: 网格效果: 1.思路 通过…...

泊松编辑 possion editing图像合成笔记
开源地址: GitHub - kono-dada/Reproduction-of-possion-image-editing 掩码必须是矩形框...

#渗透测试#漏洞挖掘#红蓝攻防#SRC漏洞挖掘
免责声明 本教程仅为合法的教学目的而准备,严禁用于任何形式的违法犯罪活动及其他商业行为,在使用本教程前,您应确保该行为符合当地的法律法规,继续阅读即表示您需自行承担所有操作的后果,如有异议,请立即停…...

系列2:基于Centos-8.6Kubernetes 集成GPU资源信息
每日禅语 自省,就是自我反省、自我检查,自知己短,从而弥补短处、纠正过失。佛陀强调自觉觉他,强调以达到觉行圆满为修行的最高境界。要改正错误,除了虚心接受他人意见之外,还要不忘时时观照己身。自省自悟之…...

Coturn 实战指南:WebRTC 中的 NAT 穿透利器
1. 什么是 Coturn? Coturn 是一种开源的 TURN(Traversal Using Relays around NAT)服务器,用于解决 NAT 穿透问题。它帮助客户端在受限网络环境(例如防火墙或 NAT 后面)中实现双向通信,常用于 WebRTC 应用、VoIP、在线游戏等场景。 2. Cotur…...

基于卷积神经网络的Caser算法
将一段交互序列嵌入到一个以时间为纵轴的平面空间中形成“一张图”后,基于卷积序列嵌入的推荐(Caser)算法利用多个不同大小的卷积滤波器,来捕捉序列中物品间的点级(point-level)、联合的(union-…...

自闭症在学校:了解自闭症的特点,优化学校教育方式
在教育的广阔天地里,每一片叶子都承载着生命的独特韵律,每一朵花都在以自己的方式绽放。然而,在特殊教育的花园里,有一群孩子,他们或许不那么容易被看见,不那么容易与世界沟通,但他们同样拥有学…...

多线程的知识总结(8):用 thread 类 或全局 async (...) 函数,创建新线程时,谁才是在新线程里第一个被执行的函数
(40)用 thread 类 或全局 async (…) 函数,创建新线程时,谁才是在新线程里第一个被执行的函数? 弄清楚这个问题,有利于推测和理解线程中代码的执行流程。根据 thread 类 和 async (…࿰…...

ArcGIS地理空间平台manager存在任意文件读取漏洞
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...
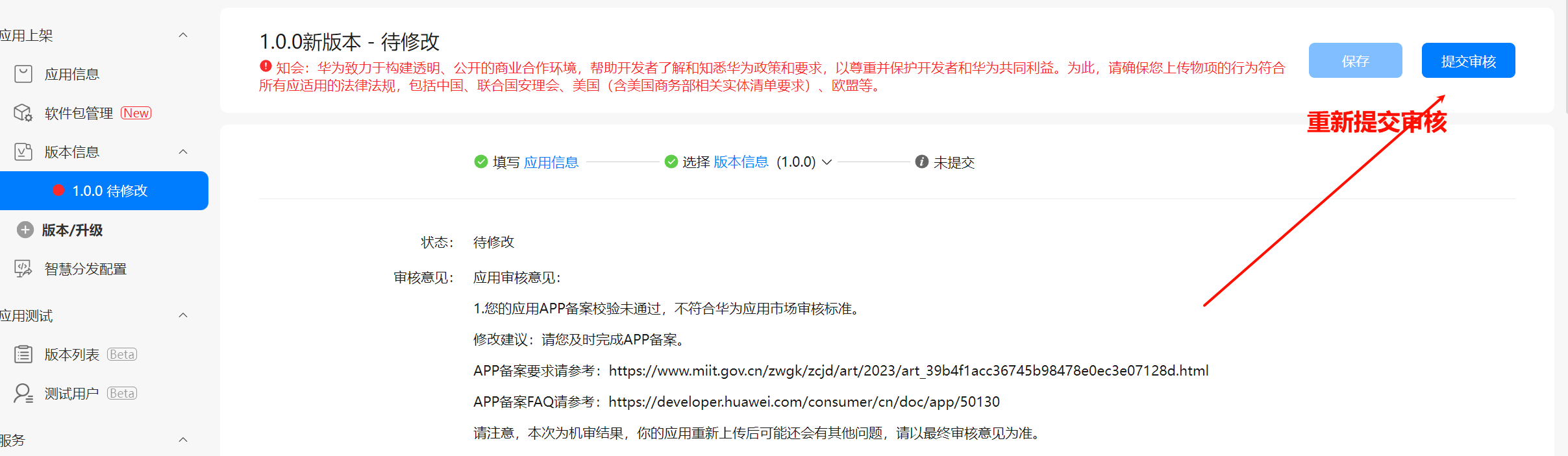
HarmonyOS Next 元服务新建到上架全流程
HarmonyOS Next 元服务新建到上架全流程 接上篇 这篇文章的主要目的是介绍元服务从新建到上家的完整流程 在AGC平台上新建一个项目 链接 一个项目可以多个应用 AGC新建一个元服务应用 新建一个本地元服务项目 如果成功在AGC平台上新建过元服务,那么这里会自动显…...

Logisim-evolution数字电路设计实战:从图形化设计到FPGA实现的完整工作流
Logisim-evolution数字电路设计实战:从图形化设计到FPGA实现的完整工作流 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution Logisim-evolution作为一款功能强大…...

完全自由操作系统的构建秘密:从可验证构建到信任链转移
1. 项目概述:探寻“完全自由”操作系统的内核秘密最近在技术社区里,一个话题反复被提起:“一套完全自由的操作系统都有这个秘密”。这听起来像是一个谜语,又像是一个宣言。作为一个在系统软件领域摸爬滚打了十几年的老手ÿ…...

C++函数对象与仿函数
C函数对象与仿函数函数对象是重载了函数调用运算符operator()的类对象,也称为仿函数。它们可以像函数一样被调用,但比普通函数更灵活,可以保存状态和配置。函数对象的基本实现通过重载operator()实现。#include #include #includeclass Multi…...

淮南家长必看:淮南哪里学少儿编程靠谱?原来这样选才不踩坑。
说实话,很多淮南家长送孩子学编程,心里是没底的。因为编程不像钢琴、画画,能当场弹一首或画一张给你看。孩子到底学了啥、学得怎么样,家长往往两眼一抹黑。今天我不推荐任何一家机构,只跟你分享三个普通人一眼就能看懂…...

别再只用默认端口了!在Ubuntu 22.04上安全配置SSH的进阶指南:改端口、密钥登录与Fail2ban
Ubuntu 22.04服务器SSH安全加固实战:从基础防护到企业级防御 当你把Ubuntu服务器暴露在公网环境中,默认的SSH配置就像把家门钥匙挂在门把手上——方便但极度危险。每天都有数以万计的自动化脚本在扫描互联网上的22端口,尝试用常见用户名和弱密…...
到CFS再到EEVDF)
Linux调度器演进:从O(1)到CFS再到EEVDF
Linux 进程调度演化史:从 O(n) 到 CFS 再到 EEVDF,30 年调度器的三次跃迁 进程调度是操作系统的脉搏。这篇文章不堆概念,带你从 Linux 0.01 走到内核 6.6,看懂调度器为什么这样设计,以及每次重构到底解决了什么问题。 …...

Closures实战指南:简化UITableView和UICollectionView数据绑定的终极教程 [特殊字符]
Closures实战指南:简化UITableView和UICollectionView数据绑定的终极教程 🚀 【免费下载链接】Closures Swifty closures for UIKit and Foundation 项目地址: https://gitcode.com/gh_mirrors/cl/Closures Closures是一个强大的iOS框架ÿ…...

10B小模型为何在真实业务中碾压百B大模型
1. 项目概述:小模型正在悄悄改写大模型的游戏规则最近在几个技术团队的内部分享会上,我连续三次被问到同一个问题:“你们还在追着百B参数的大模型跑吗?”——问话的人里,有刚从云厂商调来的架构师,有带AI产…...

scikit-learn自定义Pipeline:从接口契约到业务落地的完整实践
1. 项目概述:为什么需要自己动手定制 scikit-learn 的模型与流水线在真实的数据科学项目里,你几乎不可能靠from sklearn.ensemble import RandomForestClassifier一行代码就搞定所有事。我带过十几个工业级建模项目,从电商价格预测到医疗设备…...

RK3588 Android系统签名实战:为APK获取系统权限完整指南
1. 项目概述与核心价值在嵌入式Android开发领域,尤其是基于瑞芯微(Rockchip)平台如RK3588进行产品研发时,我们常常会遇到一个核心需求:如何让一个普通的第三方APK应用,获得系统级(System&#x…...