【Python技术】同花顺wencai涨停分析基础上增加连板分析
周末,有读者加我, 说 之前的涨停分析 是否可以增加连板分析。 这个可以加上。
先看效果
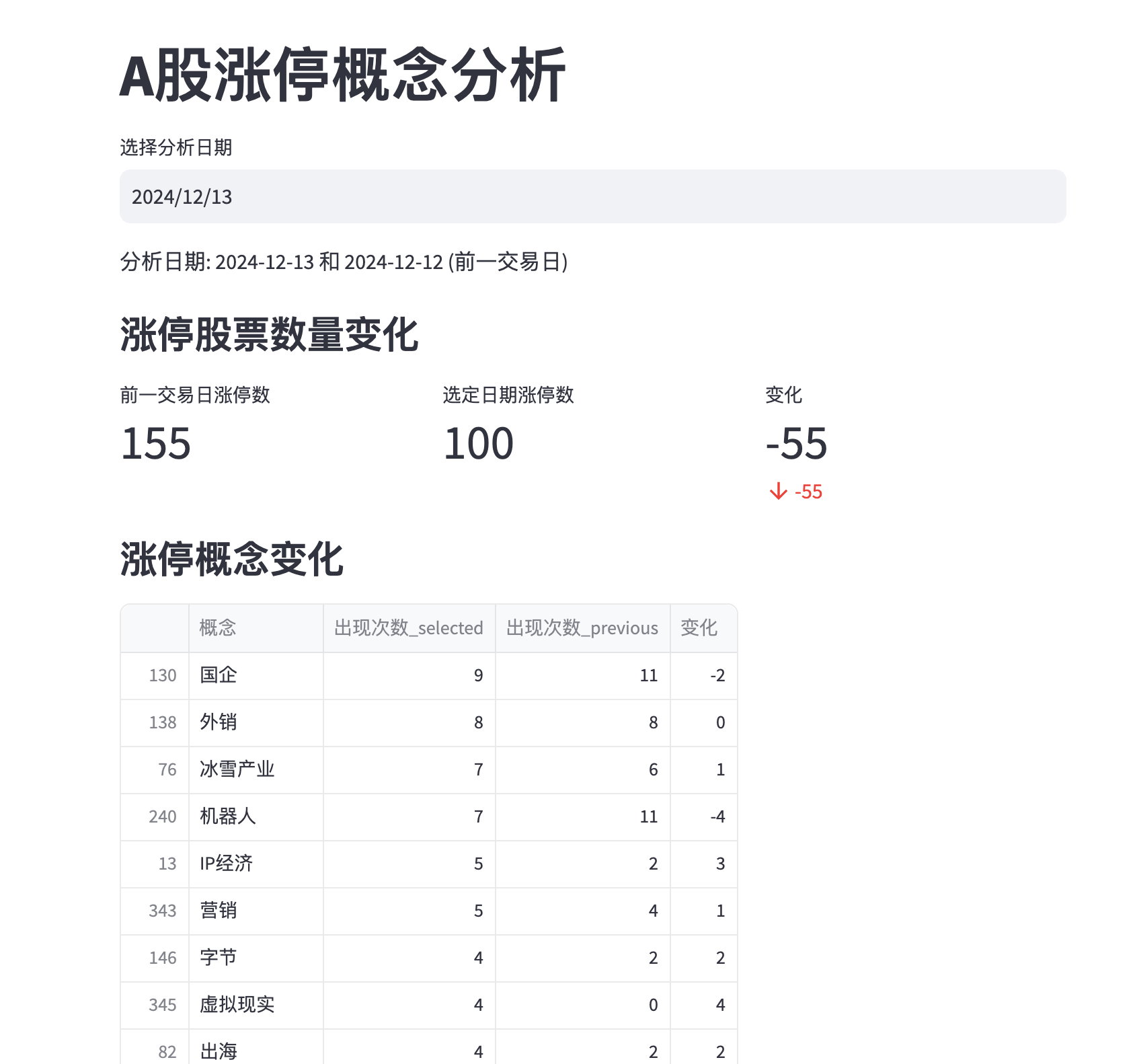


这里附上完整代码:
import streamlit as st
import pywencai
import pandas as pd
from datetime import datetime, timedelta
import plotly.graph_objects as go
from chinese_calendar import is_workday, is_holiday# Setting up pandas display options
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('display.max_colwidth', 100)def get_previous_trading_day(date):previous_date = date - timedelta(days=1)while not is_workday(previous_date) or is_holiday(previous_date):previous_date -= timedelta(days=1)return previous_datedef get_limit_up_data(date):param = f"{date.strftime('%Y%m%d')}涨停,成交金额排序"df = pywencai.get(query=param, sort_key='成交金额', sort_order='desc', loop=True)return dfdef analyze_continuous_limit_up(df, date):# 提取连续涨停天数列和涨停原因类别列continuous_days_col = f'连续涨停天数[{date.strftime("%Y%m%d")}]'reason_col = f'涨停原因类别[{date.strftime("%Y%m%d")}]'# 确保涨停原因类别列存在if reason_col not in df.columns:df[reason_col] = '未知'# 按连续涨停天数降序排序,然后按涨停原因类别排序df_sorted = df.sort_values([continuous_days_col, reason_col], ascending=[False, True])# 创建结果DataFrameresult = pd.DataFrame(columns=['连续涨停天数', '股票代码', '股票简称', '涨停原因类别'])# 遍历排序后的DataFrame,为每只股票创建一行for _, row in df_sorted.iterrows():new_row = pd.DataFrame({'连续涨停天数': [row[continuous_days_col]],'股票代码': [row['股票代码']],'股票简称': [row['股票简称']],'涨停原因类别': [row[reason_col]]})result = pd.concat([result, new_row], ignore_index=True)return resultdef get_concept_counts(df, date):concepts = df[f'涨停原因类别[{date.strftime("%Y%m%d")}]'].str.split('+').explode().reset_index(drop=True)concept_counts = concepts.value_counts().reset_index()concept_counts.columns = ['概念', '出现次数']return concept_countsdef calculate_promotion_rates(current_df, previous_df, current_date, previous_date):"""Calculate promotion rates between consecutive days"""current_days_col = f'连续涨停天数[{current_date.strftime("%Y%m%d")}]'previous_days_col = f'连续涨停天数[{previous_date.strftime("%Y%m%d")}]'promotion_data = []# Calculate for each level (from 1 to max consecutive days)max_days = max(current_df[current_days_col].max(), previous_df[previous_days_col].max())for days in range(1, int(max_days)):# Previous day count for current levelprev_count = len(previous_df[previous_df[previous_days_col] == days])# Current day count for next levelcurr_count = len(current_df[current_df[current_days_col] == days + 1])if prev_count > 0:promotion_rate = f"{curr_count}/{prev_count}={round(curr_count / prev_count * 100 if prev_count > 0 else 0)}%"else:promotion_rate = "N/A"# Get stocks that promotedpromoted_stocks = current_df[current_df[current_days_col] == days + 1][['股票简称', f'涨停原因类别[{current_date.strftime("%Y%m%d")}]']]promotion_data.append({'连板数': f"{days}板{days + 1}",'晋级率': promotion_rate,'股票列表': promoted_stocks})return pd.DataFrame(promotion_data)def app():st.title("A股涨停概念分析")# Date selectionmax_date = datetime.now().date()selected_date = st.date_input("选择分析日期", max_value=max_date, value=max_date)if not is_workday(selected_date) or is_holiday(selected_date):st.write("所选日期不是A股交易日,请选择其他日期。")returnprevious_date = get_previous_trading_day(selected_date)st.write(f"分析日期: {selected_date} 和 {previous_date} (前一交易日)")# Fetch data for both daysselected_df = get_limit_up_data(selected_date)previous_df = get_limit_up_data(previous_date)# Analyze continuous limit-up for both daysselected_continuous = analyze_continuous_limit_up(selected_df, selected_date)previous_continuous = analyze_continuous_limit_up(previous_df, previous_date)# Get concept counts for both daysselected_concepts = get_concept_counts(selected_df, selected_date)previous_concepts = get_concept_counts(previous_df, previous_date)# Merge concept countsmerged_concepts = pd.merge(selected_concepts, previous_concepts, on='概念', how='outer',suffixes=('_selected', '_previous'))merged_concepts = merged_concepts.fillna(0)# Calculate changemerged_concepts['变化'] = merged_concepts['出现次数_selected'] - merged_concepts['出现次数_previous']# Sort by '出现次数_selected' in descending ordersorted_concepts = merged_concepts.sort_values('出现次数_selected', ascending=False)# Display total limit-up stocks for both daysst.subheader("涨停股票数量变化")selected_total = len(selected_continuous)previous_total = len(previous_continuous)change = selected_total - previous_totalcol1, col2, col3 = st.columns(3)col1.metric("前一交易日涨停数", previous_total)col2.metric("选定日期涨停数", selected_total)col3.metric("变化", change, f"{change:+d}")# Display concept changesst.subheader("涨停概念变化")st.dataframe(sorted_concepts)# Create a bar chart for top 10 conceptstop_10_concepts = sorted_concepts.head(10)fig = go.Figure(data=[go.Bar(name='选定日期', x=top_10_concepts['概念'], y=top_10_concepts['出现次数_selected']),go.Bar(name='前一交易日', x=top_10_concepts['概念'], y=top_10_concepts['出现次数_previous'])])fig.update_layout(barmode='group', title='Top 10 涨停概念对比')st.plotly_chart(fig)# Display continuous limit-up analysisst.subheader("连续涨停天数分析")st.dataframe(selected_continuous)# Create a bar chart for continuous limit-up days distributioncontinuous_days_count = selected_continuous['连续涨停天数'].value_counts().sort_index()fig_continuous = go.Figure(data=[go.Bar(x=continuous_days_count.index, y=continuous_days_count.values)])fig_continuous.update_layout(title='连续涨停天数分布',xaxis_title='连续涨停天数',yaxis_title='股票数量',xaxis=dict(tickmode='linear'))st.plotly_chart(fig_continuous)# Display raw datast.subheader("选定日期涨停股票详情")st.dataframe(selected_df)st.subheader("连板晋级率分析")promotion_rates = calculate_promotion_rates(selected_df, previous_df, selected_date, previous_date)# Display promotion rates in a custom formatfor _, row in promotion_rates.iterrows():col1, col2 = st.columns([1, 3])with col1:st.write(f"**{row['连板数']}**")st.write(f"晋级率: {row['晋级率']}")with col2:if not row['股票列表'].empty:for _, stock in row['股票列表'].iterrows():concept = stock[f'涨停原因类别[{selected_date.strftime("%Y%m%d")}]']st.write(f"{stock['股票简称']} ({concept})")st.markdown("---")# Create visualization for promotion ratespromotion_rates_fig = go.Figure()# Extract numeric values from promotion ratesrates = []labels = []for _, row in promotion_rates.iterrows():if row['晋级率'] != 'N/A':rate = int(row['晋级率'].split('=')[1].replace('%', ''))rates.append(rate)labels.append(row['连板数'])promotion_rates_fig.add_trace(go.Bar(x=labels,y=rates,text=[f"{rate}%" for rate in rates],textposition='auto',))promotion_rates_fig.update_layout(title='连板晋级率分布',xaxis_title='连板数',yaxis_title='晋级率 (%)',yaxis_range=[0, 100])st.plotly_chart(promotion_rates_fig)if __name__ == "__main__":app()
在原来代码基础上增加了 根据连板天数排序, 每支个股的涨停原因分析。 这个我之前没加, 是因为我很少关注连续涨停股, 毕竟我不是龙头选手。
另外增加了连板晋级率, 比如1进2,2进3 可以分析涨停板晋级概率。对于龙头选手有一定的辅助效果。
另外交易日判断,我之前肤浅了,主要是脑子短路了。根据读者提醒,改为引入日历控件chinese_calendar的is_workday, is_holiday 判断工作日、节假日。
原文链接:
【Python技术】同花顺wencai涨停分析基础上增加连板分析
相关文章:
【Python技术】同花顺wencai涨停分析基础上增加连板分析
周末,有读者加我, 说 之前的涨停分析 是否可以增加连板分析。 这个可以加上。 先看效果 这里附上完整代码: import streamlit as st import pywencai import pandas as pd from datetime import datetime, timedelta import plotly.graph_o…...

《拉依达的嵌入式\驱动面试宝典》—C/CPP基础篇(五)
《拉依达的嵌入式\驱动面试宝典》—C/CPP基础篇(五) 你好,我是拉依达。 感谢所有阅读关注我的同学支持,目前博客累计阅读 27w,关注1.5w人。其中博客《最全Linux驱动开发全流程详细解析(持续更新)-CSDN博客》已经是 Linux驱动 相关内容搜索的推荐首位,感谢大家支持。 《拉…...

【LeetCode】3356、零数组变换 II
【LeetCode】3356、零数组变换 II 文章目录 一、数据结构-差分-一维差分、二分1.1 数据结构-差分-一维差分、二分1.1.1 题意复述1.1.2 思路1.1.3 手写二分1.1.4 sort.Search() 二分1.1.5 sort.Find() 二分 二、多语言解法 一、数据结构-差分-一维差分、二分 1.1 数据结构-差分…...

Vue 子组件修改父组件传过来的值的三种方式
方式1:子组件发送emit,触发父组件修改 父组件 <template><div><son :count"count" updateCount"updateCount" /></div> </template><script> import son from "./son"; export def…...

4.Python 数字类型
Python 数字类型总结 文章目录 Python 数字类型总结1. 数字类型概述特点 2. 数字类型的创建与赋值3. 数字类型转换4. 数学运算与函数math 模块cmath 模块 5. 随机数生成6. 三角函数7. 数学常量 总结 Python 提供了多种数字类型来存储和操作数值数据。这些类型包括整数、浮点数、…...

MacOs 日常故障排除troubleshooting
1. 关闭开机自启动 app X macOs 15.1 System settings -> General -> Login Items & Extensions->Open at Login -> Select app X and click -...

(补)算法刷题Day19:BM55 没有重复项数字的全排列
题目链接 给出一组数字,返回该组数字的所有排列 例如: [1,2,3]的所有排列如下 [1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2], [3,2,1]. (以数字在数组中的位置靠前为优先级,按字典序排列输出。) 思路: 使用回…...

golang中的值传递与引用传递,如何理解结构体的方法?
先从一个例子说起 type Counter struct {count int }func (c Counter) Inc() {c.count }func test1() {c : Counter{}do : func() {for i : 0; i < 10; i {c.count}fmt.Println("done")}go do()go do()time.Sleep(3 * time.Second)fmt.Println(c.count) }func te…...
linux部署ansible自动化运维
ansible自动化运维 1,编写ansible的仓库(比赛已经安装,无需关注) 1、虚拟机右击---设置---添加---CD/DVD驱动器---完成---确定 2、将ansible.iso的光盘连接上(右下角呈绿色状态) 3、查看光盘挂载信息 df -h…...

docker—私有仓库搭建
docker—私有仓库搭建 HTTP 部署 docker run -d \-p 5000:5000 \--restartalways \--name registry \-v /opt/data/registry:/var/lib/registry \registry:2使用官方的 registry 镜像来启动私有仓库。默认情况下,仓库会被创建在容器的 /var/lib/registry 目录…...

【SpringAOP】深入浅出SpringAOP从原理到源码
AOP对象是如何创建的 对于熟悉Spring IOC流程源码的同学来说,一定了解bean的整个生命周期,也就是从实例化、属性填充、初始化三个过程。那么对于Bean 工厂来说,是如何保证需要创建代理的对象创建代理的呢。 从图中可以看到,本质…...

Java 从查询超时到性能提升 (实战讲解)
目录 1. 问题所示2. 原理分析3. 解决方法3.1 代码优化3.2 索引优化3.3 删数据 1. 问题所示 查询返回速度慢,导致前端页面无数据显示 前端和后端均未报错,但后端未能在合理时间内返回结果到前端 后端没有报错日志 2. 原理分析 单独分析代码中的对算法…...

《C 语言携手 PaddlePaddle C++ API:开启深度学习开发新征程》
在深度学习领域,PaddlePaddle 作为一款强大的深度学习框架,为开发者提供了丰富的功能和高效的计算能力。而 C 语言,凭借其高效性和广泛的应用场景,与 PaddlePaddle 的 C API 相结合,能够为深度学习开发带来独特的优势。…...

Mysql之存储过程
MySQL 存储过程(Stored Procedure) 1. 概念 存储过程是一组预编译的 SQL 语句集合,可以通过调用名称来执行。存储过程可以接收参数,并支持复杂的业务逻辑(如条件语句、循环、异常处理等)。它们可以提高代…...

XV6 开发环境搭建
Step 1 搭建ubuntu 20.04 虚拟机 注意:一定要使用ubuntu 20.04,该版本可以直接通过deb安装gnu编译工具链。 安装完虚拟机后,换apt源。 ubuntu20.04镜像下载链接 设置root账户密码: sudo passwd root Step 2 下载解压qemu 5.1.0 wget ht…...

Windows 系统下 Python 环境安装
一、引言 Python 作为一种广泛应用的编程语言,在数据分析、人工智能等领域发挥着重要作用。本文将详细介绍在 Windows 系统上安装 Python 环境的步骤。 二、安装前准备 系统要求 Windows 7 及以上版本一般都能支持 Python。硬件方面,通常 2GB 内存、几…...

VMware Workstation的有线连接消失了
进入/var/lib目录下 cd /var/lib 查看是否存在NetworkManager 文件 ls 将其删除,然后虚拟机reboot一下。 sudo rm -r NetworkManager reboot 解决了,可以联网...

73页车企大数据平台规划与数据价值挖掘应用咨询项目方案解读
该项目旨在帮助乘用车公司规划大数据平台并提高数据挖掘应用水平,以满足业务部门对数据的需求,同时保证数据完整性和真实性。数据应用体系现状存在数据孤岛和数据关注维度不统一的问题,导致业务部门无法便捷使用数据并无法进行业务预测。大数…...

MIF格式详解,javascript加载导出 MIF文件示例
MIF 格式详解 MIF(MapInfo Interchange Format)是由Pitney Bowes Software开发的一种文本格式,用于存储地理空间数据。它通常与地图可视化和地理信息系统(GIS)相关联。MIF文件通常成对出现,一个.mif文件用…...

若依实现图片上传时自动添加水印
文章目录 总体思路1. 修改通用上传方法2. 去除文件路径前两级目录3. 添加水印方法运行效果总结 为了解决图盗用,并有效保护图片版权,若依项目需要实现一个功能:上传图片时,自动在图片上添加水印。这不仅可以有效防止盗用ÿ…...

2026.5.12【芯片设计面试经验分享】上海车载芯片设计公司
一、主管面试 1、介绍下负责的cpu的九级流水线都有哪级? 指令预取、PC取指、指令译码、发射(双发射)、执行1(alu、运算)、执行2(乘法、移位)、访存、写回、提交/重排 2、负责的spyglass cdc 一般…...

FPGA硬件加速架构设计与AXI Stream优化实践
1. FPGA硬件加速架构设计解析在当今高性能计算领域,FPGA因其可重构特性和并行计算能力,已成为硬件加速的重要选择。我们基于Xilinx Alveo U50 FPGA平台构建的加速系统,采用了分层通道设计和AXI Stream高速互联技术,实现了网络数据…...

高性价比塑料链板输送机厂家排行适配指南
随着2026年《工业输送设备安全生产通用规范》正式落地,国内输送设备行业的准入门槛和生产标准迎来新一轮调整,新规对各领域使用的输送设备提出了更明确的合规要求,也给中小企业选购设备提供了清晰的参考标准。2026年输送设备安全生产新规核心…...

通过 API 实时监听企业微信外部群变更事件并同步本地数据库
能力介绍 在企业微信外部群的协同管理中,群聊的名称修改、群主变更、新成员加入或老成员退群等状态变更,往往无法仅靠主动拉取来感知。该能力通过配置接收事件服务器(Callback),利用标准的 HTTP POST 请求实时接收企微…...

fastapi · FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 本文整理自 GitHub,经重新整理编辑。 FastAPI framework, high performance, easy to learn, fast to code, ready for production Documentation: https://fas…...

2026毕业答辩PPT模板实测:三个平台的真实体验与避坑建议
又到毕业答辩季,不少同学论文写完了,却被PPT卡住:排版乱、配色杂、结构不清,明明内容扎实,呈现效果却大打折扣。作为经常接触办公工具的博主,我实测了几个常见的PPT模板与制作平台,重点针对本科…...

Midjourney新艺术风格突然失效?92%用户忽略的--stylize冲突机制与3步回滚修复法
更多请点击: https://codechina.net 第一章:Midjourney新艺术风格突然失效?92%用户忽略的--stylize冲突机制与3步回滚修复法 近期大量用户反馈:在 Midjourney v6.1 中启用高 stylize 值(如 --stylize 1000࿰…...

3分钟完成Excel批量查询:智能多文件搜索工具完整指南
3分钟完成Excel批量查询:智能多文件搜索工具完整指南 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 还在为处理海量Excel文件而烦恼吗?面对成百上千个表格文件,传统…...

RAG 和 NotebookLM 都试过后,我才发现数据库知识库真正缺的不是搜索
很多数据库知识库不好用,不是模型不会答,而是知识没有被整理成可调用、可校验、可维护的资产。 前面几篇一直在聊 DB Agent。 聊 Skill,聊记忆,聊告警风暴,聊编排,也聊到了系统画像、历史案例和当前证据。…...

淘金币自动化脚本:每天节省20分钟,解放双手的终极指南
淘金币自动化脚本:每天节省20分钟,解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinb…...