【论文笔记】Editing Models with Task Arithmetic

🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: Editing Models with Task Arithmetic
作者: Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, Ali Farhadi
发表: ICLR 2023
arXiv: https://arxiv.org/abs/2212.04089

摘要
改变预训练模型的行为——例如,提高其在下游任务上的性能或减轻在预训练过程中学习的偏差——是开发机器学习系统时的常见做法。
在本工作中,我们提出了一种以任务向量为中心的新范式来引导神经网络的行为。
任务向量指定了预训练模型权重空间中的一个方向,使得在该方向上的移动可以改善任务性能。
我们通过从在任务上微调后的模型权重中减去预训练模型的权重来构建任务向量。
我们表明,这些任务向量可以通过如取反和加法等算术运算进行修改和组合,并且相应地引导结果模型的行为。
取反任务向量会降低目标任务上的性能,而对控制任务上的模型行为影响很小。
此外,将任务向量相加可以同时提高多个任务上的性能。
最后,当任务通过形式为“ A A A 对于 B B B 正如 C C C 对于 D D D”的类比关系相联系时,结合来自三个任务的向量可以改善第四个任务的性能,即使没有使用第四个任务的数据进行训练。
总的来说,我们在多个模型、模态和任务上的实验表明,任务算术是一种简单、高效且有效的编辑模型的方法。
任务向量
为了我们的目的,一个任务通过用于微调的数据集和损失函数实例化。
设 θ pre ∈ R d \theta_{\text{pre}} \in \mathbb{R}^d θpre∈Rd 为预训练模型的权重, θ ft t ∈ R d \theta_{\text{ft}}^t \in \mathbb{R}^d θftt∈Rd 为在任务 t t t 上微调后的相应权重。
任务向量 τ t ∈ R d \tau_t \in \mathbb{R}^d τt∈Rd 由 θ ft t \theta_{\text{ft}}^t θftt 和 θ pre \theta_{\text{pre}} θpre 的逐元素差给出,即 τ t = θ ft t − θ pre \tau_t = \theta_{\text{ft}}^t - \theta_{\text{pre}} τt=θftt−θpre。
当任务从上下文中明确时,我们省略标识符 t t t,简单地将任务向量称为 τ \tau τ。
任务向量可以应用于来自相同架构的任何模型参数 θ \theta θ,通过逐元素加法,带有可选的缩放项 λ \lambda λ,使得生成的模型具有权重 θ new = θ + λ τ \theta_{\text{new}} = \theta + \lambda \tau θnew=θ+λτ。
在我们的实验中,缩放项是使用留出的验证集确定的。
请注意,将单个任务向量添加到预训练模型中,其中 λ = 1 \lambda = 1 λ=1,结果是该任务上微调的模型。
Editing models with task arithmetic

我们重点关注三种任务向量上的算术表达式,如图1所示:对任务向量取反、将任务向量相加,以及组合任务向量以形成类比。
所有操作都是逐元素应用于权重向量的。
当对任务向量 τ \tau τ 取反时,应用得到的向量 τ new = − τ \tau_{\text{new}} = -\tau τnew=−τ 对应于在微调模型和预训练模型之间进行外推。得到的模型在目标任务上表现更差,对控制任务的性能几乎没有变化。
将两个或多个任务向量 τ i \tau_i τi 相加得到 τ new = ∑ i τ i \tau_{\text{new}} = \sum_i \tau_i τnew=∑iτi,结果是一个在所有任务上都表现出色的多任务模型,有时甚至比在单个任务上微调的模型表现更好。
最后,当任务 A A A、 B B B、 C C C 和 D D D 形成类比形式“ A A A 对于 B B B 正如 C C C 对于 D D D”时,任务向量 τ new = τ C + ( τ B − τ A ) \tau_{\text{new}} = \tau_C + (\tau_B - \tau_A) τnew=τC+(τB−τA) 提升了任务 D D D 的性能,即使该任务的数据很少或没有数据。
对于所有操作,通过应用 τ new \tau_{\text{new}} τnew 得到的模型权重由 θ new = θ + λ τ new \theta_{\text{new}} = \theta + \lambda \tau_{\text{new}} θnew=θ+λτnew 给出,其中缩放项 λ \lambda λ 是使用留出的验证集确定的。
Forgetting via negation
在这部分中,我们展示对任务向量取反是一种有效的方法,可以在不显著影响其他任务性能的情况下降低其在目标任务上的表现。
遗忘或“反学习”可以帮助缓解预训练时学到的不希望有的偏差;完全遗忘任务可能是为了遵守法规或出于伦理原因,比如防止图像分类器识别面部,或通过OCR“读取”个人信息。
这些干预措施不应显著影响模型在处理编辑范围之外的数据时的行为。
因此,我们在控制任务上测量准确率,除了评估任务向量来源的目标任务。
我们的实验展示了对任务向量取反在编辑图像分类和文本生成模型中的有效性。
图像分类
对于图像分类,我们使用了CLIP模型和Ilharco等人研究的八个任务的任务向量,这些任务从卫星图像识别到交通标志分类:Cars、DTD、EuroSAT、GTSRB、MNIST、RESISC45、SUN397和SVHN。
对于控制任务,我们使用ImageNet。我们通过在每个目标任务上进行微调来生成任务向量。
我们与两个额外的基线进行比较:通过向增加损失的方向进行微调(即,使用梯度上升),如Golatkar等人和Tarun等人所做;以及使用一个随机向量,其中每一层的幅度与任务向量的相应层相同。

如表1所示,对任务向量取反是在减少目标任务准确率的同时对控制任务影响最小的有效编辑策略。
例如,负任务向量将ViT-L/14的平均目标任务准确率降低了45.8个百分点,而对控制任务的准确率几乎没有变化。
相比之下,使用随机向量对目标任务准确率影响不大,而使用梯度上升进行微调则严重恶化了控制任务的性能。
文本生成
我们研究了是否可以通过对训练出特定行为的任务向量取反来缓解该模型的特定行为。
具体而言,我们的目标是减少由各种大小的GPT-2模型生成的有毒内容的数量。
我们通过在Civil Comments中毒性分数高于0.8的数据上微调来生成任务向量,然后对这个任务向量取反。
与上节一样,我们还比较了在微调时使用梯度上升的基线,以及使用相同幅度的随机任务向量。
此外,我们还与从Civil Comments(毒性分数小于0.2)的非有毒样本上进行微调进行了比较,类似于Liu等人。
我们使用Detoxify测量了一千个模型生成的毒性。
对于控制任务,我们测量了语言模型在WikiText-103上的困惑度。

如表2所示,使用负任务向量进行编辑是有效的,将分类为有毒的生成量从4.8%减少到0.8%,同时在控制任务上保持困惑度在预训练模型的0.5个百分点以内。
相比之下,使用梯度上升进行微调通过将控制任务的性能降低到不可接受的水平来减少有毒生成,而在非有毒数据上进行微调在减少任务生成和控制任务上都比任务向量差。
作为实验对照,添加一个随机向量对有毒生成或在WikiText-103上的困惑度几乎没有影响。
Learning via addition
我们现在将注意力转向添加任务向量,无论是构建能够在多个任务上同时表现出色的多任务模型,还是改进单任务性能。
这一操作使我们能够在不进行额外训练或访问训练数据的情况下,重用和转移来自内部模型或大量公开可用的微调模型的知识。
我们探索了在各种图像分类和自然语言处理任务上添加任务向量的应用。
图像分类
我们开始使用与上文相同的八个模型,这些模型在一系列多样化的图像分类任务(Cars、DTD、EuroSAT、GTSRB、MNIST、RESISC45、SUN397和SVHN)上进行了微调。

如图2所示,我们展示了通过添加这些任务中所有成对的任务向量所获得的准确性。
为了考虑任务难度的差异,我们通过在该任务上微调的模型的准确率来归一化每个任务的准确率。
在归一化后,微调模型在其各自任务上的性能均为1,因此使用多个专用模型的平均性能也为1。
如图2所示,添加成对的任务向量得到一个单一模型,其性能大幅超越零样本模型,并且与使用两个专用模型相当(平均归一化准确率为98.9%)。
除了任务对之外,我们还探索了为所有可能的子集(总共 2 8 2^8 28 个)添加任务向量。

在图3中,我们展示了最终模型的归一化准确性,这些准确性是通过对所有八个任务进行平均得到的。
随着可用任务向量数量的增加,可以生成更好的多任务模型。当所有任务向量都可用时,通过添加任务向量生成的最佳模型达到了91.2%的平均性能,尽管将多个模型压缩成了一个。
自然语言处理
除了构建多任务模型外,我们还探讨了添加任务向量是否是提高单个目标任务性能的有效方法。
为此,我们首先在GLUE基准中的四个任务上微调T5-base模型,如Wortsman等人所做。
然后,我们在Hugging Face Hub上搜索兼容的检查点,共找到427个候选者。
我们尝试将每个对应的任务向量添加到我们的微调模型中,基于留出的验证数据选择最佳的检查点和缩放系数。

如表3所示,添加任务向量可以提高目标任务的性能,相比微调。
Task analogies
在本节中,我们探讨了以“ A A A 对于 B B B 正如 C C C 对于 D D D”形式的任务类比,并展示使用前三个任务的向量进行任务算术可以提高任务D的性能,即使对于该任务的数据很少或根本没有数据。
Domain generalization
对于许多目标任务,收集未标记的数据比收集人工注释更容易且成本更低。
当目标任务的标记数据不可用时,我们可以使用任务类比来提高目标任务的准确性,利用有标记数据的辅助任务和无监督学习目标。
例如,考虑使用Yelp数据进行情感分析的目标任务。
使用任务类比,我们可以构建一个任务向量 τ ^ yelp; sent = τ amazon; sent + ( τ yelp; lm − τ amazon; lm ) \hat{\tau}_{\text{yelp; sent}} = \tau_{\text{amazon; sent}} + (\tau_{\text{yelp; lm}} - \tau_{\text{amazon; lm}}) τ^yelp; sent=τamazon; sent+(τyelp; lm−τamazon; lm),其中 τ amazon; sent \tau_{\text{amazon; sent}} τamazon; sent 是通过在来自Amazon的标记数据上进行微调获得的(情感分析使用来自Amazon的数据;McAuley & Leskovec),而 τ yelp; lm \tau_{\text{yelp; lm}} τyelp; lm 和 τ amazon; lm \tau_{\text{amazon; lm}} τamazon; lm 是通过在两个数据集的输入上进行(无监督)语言建模获得的任务向量。

在表4中,我们展示了使用此类任务类比可以提高T5模型在多个尺度上的准确性,无论是将Amazon还是Yelp二元情感分析作为目标任务。
我们经验性地发现,给情感分析任务向量更高的权重可以提高准确性,因此我们在这些实验中使用了两个独立的缩放系数——一个用于情感分析任务向量,另一个用于两个语言建模任务向量。
使用任务向量在所有模型和数据集上都优于在剩余的辅助情感分析任务上进行微调,接近在目标任务上进行微调的性能。
Subpopulations with little data
在某些数据子群体中通常存在一些固有的稀缺性——例如,室内环境中的狮子图像比户外环境中的狮子图像或一般情况下的狗(无论室内还是室外)图像更为罕见。
每当这些子群体与数据更为丰富的其他群体存在类比关系时(如本例所示),我们可以应用任务类比,例如, τ ^ lion indoors = τ lion outdoors + ( τ dog indoors − τ dog outdoor ) \hat{\tau}_{\text{lion indoors}} = \tau_{\text{lion outdoors}} + (\tau_{\text{dog indoors}} - \tau_{\text{dog outdoor}}) τ^lion indoors=τlion outdoors+(τdog indoors−τdog outdoor)。
我们通过创建四个子群体来探索这一情景,使用ImageNet和人类素描数据集之间的125个重叠类别。
我们将这些类别分为大致相等的两个子集,创建四个子群体A、B、C和D,其中(A, C)和(B, D)共享相同的类别,而(A, B)和(C, D)共享相同的风格(照片逼真图像或素描)。
尽管这些子群体在我们的实验中有许多类别,但我们使用简化的子集 “real dog”, “real lion”, “sketch dog” and “sketch lion” 作为运行示例。
给定一个目标子群体,我们通过在剩余的子群体上独立微调三个模型来创建任务向量,然后通过任务算术将它们组合起来,例如,对于目标子群体“sketch lion”, τ ^ sketch lion = τ sketch dog + ( τ real lion − τ real dog ) \hat{\tau}_{\text{sketch lion}} = \tau_{\text{sketch dog}} + (\tau_{\text{real lion}} - \tau_{\text{real dog}}) τ^sketch lion=τsketch dog+(τreal lion−τreal dog)。
我们在图4中展示了结果,这些结果是对四个目标子群体的平均值。

与预训练模型相比,任务向量平均提高了3.4个百分点的准确性。
此外,当目标子群体的一些数据可用于微调时,从编辑后的模型开始始终比从预训练模型开始获得更高的准确性。
仅从类比中获得的收益(没有额外的数据)大致相当于为目标子群体收集和标注大约一百个训练样本的效果。
讨论
在这一节中,我们通过探讨不同任务的任务向量之间的相似性,以及不同学习率和随机种子的影响,对先前结果进行了进一步的分析。
我们最后讨论了我们方法的一些局限性。
Similarity between task vectors
在图5中,我们探讨了不同任务的任务向量之间的余弦相似度,旨在了解如何通过加法将多个模型合并为单个多任务模型。
我们观察到来自不同任务的向量通常接近正交,并推测这允许通过加法组合任务向量,干扰最小。
我们还观察到当任务在语义上彼此相似时,余弦相似度更高。

例如,图5中最大的余弦相似度出现在MNIST、SVHN和GTSRB之间,这些任务的关键是识别数字,以及EuroSAT和RESISC45之间,它们都是卫星图像识别数据集。
这种“任务空间”中的相似性可能有助于解释Ilharco等人中的某些结果,其中在单个任务上微调的模型权重与预训练模型权重之间进行插值——用我们的术语来说,就是应用单个任务向量——有时可以提高没有数据的不同任务的准确性(例如,应用MNIST任务向量可以提高SVHN的准确性)。
The impact of the learning rate
在图6中,我们观察到增加学习率会降低使用任务向量和微调单个模型时的准确性,但对于单个模型,这种下降更为平缓。

这些发现与的研究结果一致,该研究观察到在使用较大的学习率时,两个微调模型之间的线性路径上的准确性会降低。
因此,虽然较大的学习率在微调单个模型时可能可以接受,但我们建议在使用任务向量时更加谨慎。
此外,我们假设较大的学习率可以解释在添加来自自然语言处理任务的向量时的一些方差,其中我们采用社区中其他人微调的模型。
The evolution of task vectors throughout fine-tuning
图7展示了任务向量在微调过程中的演变。

中间任务向量迅速收敛到微调结束时获得的最终任务向量方向。
此外,通过添加两个图像分类任务的中间任务向量获得的模型精度在仅几百步后就趋于饱和。
这些结果表明,使用中间任务向量可以是一种在精度损失很小的情况下节省计算的有用方法。
Limitations
任务向量仅限于具有相同架构的模型,因为它们依赖于模型权重上的逐元素操作。
此外,在我们所有的实验中,我们仅在从同一预训练初始化微调的模型上执行算术运算,尽管有研究表明放宽这一假设是有希望的。
我们还注意到,一些架构非常流行,并且有“标准”初始化——例如,在撰写本文时,Hugging Face Hub上有超过3000个模型是从同一BERT-base初始化微调的,还有超过800个模型是从同一T5-small初始化微调的。
总结
在这篇论文中,我们介绍了一种基于任务向量算术运算的编辑模型新范式。
对于各种视觉和NLP模型,添加多个专用任务向量可以导致一个在所有目标任务上表现良好的单一模型,甚至可以提升单个任务的表现。
取反任务向量允许用户移除不希望的行为,例如,有毒生成,甚至完全忘记特定任务,同时保持其他方面的性能。
最后,任务类比利用现有数据来提高数据稀缺的领域或子群体的性能。
在任务向量上的算术运算仅涉及添加或减去模型权重,因此计算效率高,尤其是与涉及额外微调的替代方案相比。
因此,用户可以轻松尝试各种模型编辑,从大量公开可用的微调模型中回收和转移知识。
由于这些操作导致单个模型大小不变,因此不会产生额外的推理成本。
我们的代码可在https://github.com/mlfoundations/task_vectors上获取。
相关文章:
【论文笔记】Editing Models with Task Arithmetic
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: Editing Models with Task…...

ESP32外设学习部分--UART篇
前言 在我们学习嵌入式的过程中,uart算是我们用的非常多的一个外设了,我们可以用串口打印信息,也可以用于设备通信,总之串口的作用非常多,我们也非常有必要熟练地去掌握这个外设。 uart的配置 uart的参数配置 uart_…...

ssm-day04 mybatis
mybatis是一个持久层框架,针对的是JDBC的优化 简化数据库操作,能进行单表、多表操作,在这个框架下,需要我们自己写SQL语句 Mapper接口和MapperXML文件就相当于Dao和Dao层的实现 通常将xml文件放在resources包下 ,放在…...

es中段是怎么合并的
文章目录 1. 段合并的背景2. 合并的方式2.1TieredMergePolicy 的层次结构2.2 层次的基本规则2.3 如何理解层次(tier)2.4. 合并过程中的层次示例2.5. TieredMergePolicy 的优势2.6. 小结 3. 合并过程中的优化4. 合并的性能考虑5. 使用 API 手动合并6. 合并…...

5、可暂停的线程控制模型
一、需求 在做播放器的时候,很多的模块会创建一个线程,然后在这个线程上跑单独的功能,同时,需要对这个线程进行控制,比如暂停,继续等,如播放器的解码,解封装等,都需要对…...

sql优化--mysql隐式转换
sql隐式转换 在SQL中,隐式转换是数据库自动进行的类型转换,隐式转换可以帮助我们处理不同类型的数据。 比如,数据表的字段是字符串类型的,传入一个整型的数据,也能够运行sql。 sql隐式转换的弊端 sql隐式转换&…...

Scratch021(画笔)
画笔模块 可以这么理解,画笔模块是Scratch的拓展模块,用它可以完成很多的功能,非常有趣! 案例要求 点击绿旗运行程序,页面显示需要绘制的背景。 可以使用鼠标移动画笔角色,按照顺序点击连线,…...

Leetcode 3387. Maximize Amount After Two Days of Conversions
Leetcode 3387. Maximize Amount After Two Days of Conversions 1. 解题思路2. 代码实现 题目链接:3387. Maximize Amount After Two Days of Conversions 1. 解题思路 这一题思路上其实就是要分别求出day 1以及day 2中原始货币与其他各个货币之间的成交价&…...

机器视觉与OpenCV--01篇
计算机眼中的图像 像素 像素是图像的基本单位,每个像素存储着图像的颜色、亮度或者其他特征,一张图片就是由若干个像素组成的。 RGB 在计算机中,RGB三种颜色被称为RGB三通道,且每个通道的取值都是0到255之间。 计算机中图像的…...

简单的Java小项目
学生选课系统 在控制台输入输出信息: 在eclipse上面的超级简单文件结构: Main.java package experiment_4;import java.util.*; import java.io.*;public class Main {public static List<Course> courseList new ArrayList<>();publi…...

使用layui的table提示Could not parse as expression(踩坑记录)
踩坑记录 报错图如下 原因: 原来代码是下图这样 上下俩中括号都是连在一起的,可能导致解析问题 改成如下图这样 重新启动项目,运行正常!...

区块链共识机制详解
一.共识机制简介 在区块链的交流和学习中,「共识算法」是一个很频繁被提起的词汇,正是因为共识算法的存在,区块链的可信性才能被保证。 1.1 为什么需要共识机制? 所谓共识,就是多个人达成一致的意思。我们生活中充满…...
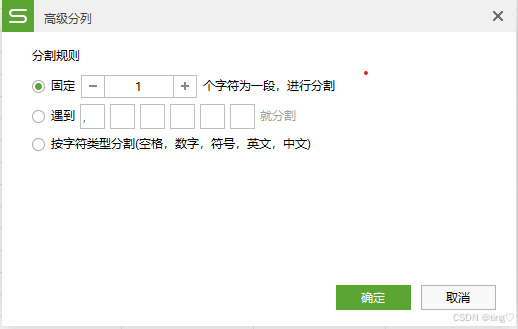
【Excel】单元格分列
目录 分列(新手友好) 1. 选中需要分列的单元格后,选择 【数据】选项卡下的【分列】功能。 2. 按照分列向导提示选择适合的分列方式。 3. 分好就是这个样子 智能分列(进阶) 高级分列 Tips: 新手推荐基…...

【含开题报告+文档+PPT+源码】基于微信小程序的旅游论坛系统的设计与实现
开题报告 近年来,随着互联网技术的迅猛发展,人们的生活方式、消费习惯以及信息交流方式都发生了深刻的变化。旅游业作为国民经济的重要组成部分,其信息化、网络化的发展趋势也日益明显。旅游论坛作为旅游信息交流和分享的重要平台࿰…...

微软 Phi-4:小型模型的推理能力大突破
在人工智能领域,语言模型的发展日新月异。微软作为行业的重要参与者,一直致力于推动语言模型技术的进步。近日,微软推出了最新的小型语言模型 Phi-4,这款模型以其卓越的复杂推理能力和在数学领域的出色表现,引起了广泛…...

操作系统课后习题2.2节
操作系统课后习题2.2节 第1题 CPU的效率指的是CPU的执行速度,这个是由CPU的设计和它的硬件来决定的,具体的调度算法是不能提高CPU的效率的; 第3题 互斥性: 指的是进程之间的同步互斥关系,进程是一个动态的过程&#…...
[小白系列]安装sentence-transformers
python环境为3.13.1执行 pip install sentence-transformers 总是报以下问题 ERROR: Cannot install sentence-transformers0.1.0, sentence-transformers0.2.0, sentence-transformers0.2.1, sentence-transformers0.2.2, sentence-transformers0.2.3, sentence-transformers…...

Python字符串format方法全面解析
在Python中,format方法是一种用于格式化字符串的强大工具。它允许你构建一个字符串,其中包含一些“占位符”,这些占位符将被format方法的参数替换。以下是对format方法用法的详细解释: 基本用法 format方法的基本语法如下&#…...

【Reading Notes】Favorite Articles from 2024
文章目录 1、January2、February3、March4、April5、May6、June7、July8、August9、September10、October11、November12、December 1、January 2、February 3、March Sora外部测试翻车了!3个视频都有Bug( 2024年03月01日) 不仔细看还真看不…...

Python爬虫之Scrapy框架基础入门
Scrapy 是一个用于Python的开源网络爬虫框架,它为编写网络爬虫来抓取网站数据并提取结构化信息提供了一种高效的方法。Scrapy可以用于各种目的的数据抓取,如数据挖掘、监控和自动化测试等。 【1】安装 pip install scrapy安装成功如下所示:…...

基于Sakura实验板的STM32流水灯项目实战:从GPIO控制到模式切换
1. 项目概述:从零到一,点亮你的第一串“流水”如果你刚拿到一块单片机开发板,面对一堆引脚和代码感到无从下手,那么“流水灯”几乎就是所有嵌入式开发者的“Hello World”。它简单、直观,却能让你快速理解GPIO…...

单片机编程规范1 ---阮丁远 20260509
单片机编程规范1 ---阮丁远 20260509 :1.只用静态数组is被占用的标志位来 分配内存,不用malloc2.读写带下标的参数前先验证下标大小范围是否对,比如有的下标只能1开始,因为0的话里面 0-1 就变为负数了3.可以建立 参数 范围 监控…...
)
用51单片机和HC-SR04超声波模块,手把手教你做个倒车防撞提醒器(附完整代码和立创EDA原理图)
51单片机与超声波模块实战:打造高精度倒车防撞系统 引言 在智能交通与汽车电子领域,距离检测技术扮演着越来越重要的角色。对于电子爱好者而言,掌握超声波测距原理并实现实际应用,不仅能提升硬件开发能力,还能为日常生…...
)
【限时解密】Perplexity未公开的“诗眼定位算法”:仅0.3秒锁定《春江花月夜》中17处意象跃迁节点(内附可复现Prompt模板)
更多请点击: https://intelliparadigm.com 第一章:Perplexity诗词歌赋搜索 Perplexity 作为一款以推理深度见长的 AI 搜索工具,其在古典文学领域的检索能力尤为突出。不同于传统关键词匹配引擎,Perplexity 能够理解“孤帆远影碧空…...
)
告别手动Excel!用Plink 1.9快速搞定GWAS数据杂合度分析(附实战代码)
群体遗传学实战:用Plink高效完成GWAS数据杂合度分析 在生物信息学研究中,杂合度分析是评估基因型数据质量的重要环节。传统手动Excel处理方式不仅耗时耗力,还容易引入人为错误。本文将详细介绍如何利用Plink 1.9这一专业工具,快速…...

这个AI助手不让你教它,它自己来了解你
这个AI助手不让你教它,它自己来了解你OpenHuman:9700 Star,GitHub霸榜的秘密最近GitHub Trending上冒出来一个项目,连续霸榜多天,Star数蹭蹭往上涨。我点进去看了一眼,思路跟之前那些Agent工具完全不一样。…...
)
统信UOS离线部署实战:手把手教你用yum缓存提取sshpass等软件包(附完整命令)
统信UOS离线部署全流程指南:从缓存提取到依赖解析 在高度安全隔离的内网环境中,统信UOS系统管理员常面临一个核心挑战:如何将联网环境获取的软件包完整迁移到离线机器。与常见的/var/cache/yum路径不同,统信UOS的缓存机制有其特殊…...
)
【计算机组成原理】无符号整数乘法原理(基于移位累加,零基础看懂CPU乘法)
前言在数字电路与计算机组成原理中,加法是最基础的运算,而乘法是高频常用运算。很多初学者疑惑:计算机没有专门的乘法口诀,到底怎么实现二进制乘法?而在数字运算中,乘法是比加法更复杂、但底层逻辑完全依托…...

WinCC flexible 2008报警组态:离散量与模拟量报警原理与工业应用
1. 报警系统在工业自动化中的核心价值在工业自动化领域,尤其是像果汁搅拌系统这样的食品加工产线,稳定、可靠、安全是生命线。想象一下,如果某个阀门意外关闭导致原料配比失衡,或者搅拌电机转速异常导致产品混合不均,轻…...

告别传统知识蒸馏:用CVPR2022的‘逆向蒸馏’在PyTorch里玩转工业异常检测
工业级异常检测实战:基于CVPR2022逆向蒸馏的PyTorch实现指南 当传统知识蒸馏在工业缺陷检测中遭遇瓶颈——学生网络对异常样本产生"幻觉响应"、模型对微小缺陷敏感度不足、复杂纹理场景下误报率飙升——CVPR2022提出的逆向蒸馏架构犹如一剂精准的手术刀。…...