【面试笔记】CPU 缓存机制
CPU 缓存机制
- 1. CPU Cache 与 MMU
- 1.1 MMU 是什么?TLB 又是什么?他们是怎么工作的?
- 2.2 简述 Cache 与 MMU 的协作关系?
- 2.3 简述 Cache 与 MMU 的协作工作流程?
- 2. CPU 多层次缓存
- 2.1 什么是 CPU 的多层次缓存结构?
- 2.2 为什么 CPU 缓存要分级?
- 2.3 L1、L2 和 L3 缓存在设计上有何不同?
- 2.4 为什么 L1 cache 采用分离缓存的方式,而 L2、L3 采用统一缓存的形式?
- 3. CPU 缓存的工作原理
- 3.1 缓存组织结构(映射方式)有哪几种类型?
- 3.2 Set-Associative Cache(组相联缓存)的结构是什么样的?
- 3.3 简述 Set-Associative Cache(组相联缓存)的工作流程?
- 3.4 Cache 体系结构有哪几种?
- 3.5 Cache 替换策略有哪几种?
- 3.6 详细描述 CPU 从发出内存请求到得到返回过程中,Cache 和内存执行的完整流程?
- 3.7 写操作中 Cache 分配策略有哪些?最常用的策略是什么?
- 3.8 读操作中 Cache 分配策略有哪些?最常用的策略是什么?
- 4. 缓存一致性(Cache Coherence)
- 4.1 缓存一致性(Cache Coherence)问题是怎么发生的?如何解决?
- 4.2 MESI 协议是什么?他是如何保证缓存一致性的?
众所周知,CPU是计算机的"大脑",负责处理指令并执行任务。但是,在我们日常的计算和程序执行中,有一个不可或缺的部分,那就是CPU缓存。在当今的计算机架构中,CPU缓存起到了至关重要的作用,尤其是对于程序性能的优化。为了更好地理解它,我们需要深入了解它的设计和工作原理。
1. CPU Cache 与 MMU
1.1 MMU 是什么?TLB 又是什么?他们是怎么工作的?
MMU(Memory Management Unit)和TLB(Translation Lookaside Buffer)在现代计算机体系结构中起到关键作用,它们与内存访问和虚拟内存管理有关。以下是关于它们工作原理和流程的详细描述。
MMU (Memory Management Unit):
- MMU是计算机中的一个硬件单元,负责将虚拟地址转换为物理地址。
- 在有虚拟内存的系统中,程序并不直接与物理内存进行通信,而是通过虚拟地址。
- 这种方式为每个程序提供了一个看似连续的地址空间,而实际上,这些地址可能分散在物理内存和磁盘(页面文件或交换区)中。
MMU 工作原理:
- 当程序尝试访问虚拟内存地址时,这个地址首先传递给MMU。
- MMU使用页表来查找与虚拟地址相关联的物理地址。
- 页表可能非常大,不可能完全存储在快速存取的硬件内,所以通常存储在主内存中。
- MMU转换虚拟地址为物理地址,并将其发送到物理内存以进行访问。
TLB (Translation Lookaside Buffer):
- 由于频繁地从页表中查找地址转换是非常耗时的,因此TLB被引入作为一个小型的、快速的缓存。
- 用于存储最近的虚拟到物理的地址转换。
TLB 工作原理:
- 当虚拟地址需要被转换时,MMU首先检查TLB。
- 如果TLB中存在所需的转换(称为TLB命中),那么从TLB中直接获取物理地址,跳过完整的页表查找。
- 如果TLB没有所需的转换(称为TLB缺失),MMU必须在页表中进行查找。
- 一旦找到了转换,它通常会被添加到TLB中,替换一个旧的条目。
- 在某些情况下,所需的页面可能不在物理内存中,导致页面错误。这时,操作系统需要从磁盘中加载所需的页面,并更新页表和TLB。
MMU 与 TLB 工作流程:
- CPU生成虚拟地址并发送给MMU。
- MMU检查TLB以查找地址转换。
- 如果TLB命中,MMU直接得到物理地址。如果TLB缺失,MMU查找页表。
- 更新TLB(如果发生了TLB缺失)。
- 如果发生页面错误,操作系统介入,从磁盘加载页面,并再次尝试地址转换。
2.2 简述 Cache 与 MMU 的协作关系?
Cache 和 MMU(Memory Management Unit)是两个主要的硬件组件,它们在现代计算机体系结构中起到关键作用。尽管它们有不同的功能和目的,但它们之间有一定的关系,特别是在处理存储访问和优化性能时。
功能与目的:
- Cache:主要目的是提供一个比主存更快速的存储层次,从而缩短 CPU 和主存之间的延迟差距。它存储了最近或最常访问的数据和指令,以便快速获取。
- MMU:它的主要功能是虚拟内存管理,即将虚拟地址转换为物理地址。这样,程序可以认为它们在一个连续的地址空间中运行,而不用关心数据或指令实际存储的物理位置。
关系:
- 当 CPU 请求某个地址的数据或指令时,这通常是一个虚拟地址。在访问 cache 之前,这个地址需要被 MMU 转换为物理地址。
- 对于某些 cache 结构(例如 VIPT,Virtually Indexed, Physically Tagged),部分虚拟地址用于索引 cache,而转换为的物理地址用于标记匹配。
- 在发生 cache 缺失的情况下,MMU 的地址转换过程变得尤为重要,因为现在需要访问主存,而主存访问基于物理地址。
互动:
TLB(Translation Lookaside Buffer)是 MMU 的一个组件,它是一个特殊的、小型的 cache,用于缓存最近使用的地址转换。这样,对于连续的访问,不需要每次都在主页表中查找地址转换。
当 cache 和 MMU 连续工作时,如上所述,首先是 TLB 的查找(为了地址转换),然后是 cache 的查找。如果两者都缺失,那么将需要从主存中获取数据,并可能需要完整的页表查找。
总之,Cache 和 MMU 都是为了优化性能而存在的。缓存旨在减少存储访问的延迟,而 MMU 则允许更灵活和高效的内存管理和保护。
2.3 简述 Cache 与 MMU 的协作工作流程?
Cache 和 MMU 基本上都是一起使用的,会同时开启或同时关闭。因为 MMU 页表中的 entry 属性,控制着内存的权限和 cache 缓存的策略。对于物理高速缓存与虚拟高速缓存,Cache 与 MMU 协同工作流程会有所不同。
物理高速缓存的工作流程:(图源 知乎@黑客与摄影师)
- CPU 在访问 DDR 的时候用的地址是虚拟地址,需要经由 MMU 转换为物理地址。
- MMU 会先查询 TLB 获取物理地址,若 TLB 未命中则需要访问页表来查询物理地址。
- 通过物理地址查询 Cache,若 Cache 未命中,则CPU 需要从 DDR 中获取数据。
虚拟高速缓存的工作流程:(图源 知乎@黑客与摄影师)
- CPU 在寻址时,先把虚拟地址发送到 Cache,若命中则直接返回。
- 若 Cache 未命中,则经由 MMU 转换为物理地址去查询 DDR。


2. CPU 多层次缓存
如下图所示为常见的 CPU 多级缓存架构示意图(图源 知乎@努力的码农):

2.1 什么是 CPU 的多层次缓存结构?
CPU的多层次缓存结构是为了平衡存取速度和大小的关系,提供了多个层级的缓存。随着制程技术的进步,CPU的运行速度远远超过了主存(RAM)的速度,导致CPU经常等待数据。为了缓解这种情况,CPU设计者引入了多层次的缓存,每一层的速度和大小都是一个折衷。下面是常见的多层次缓存结构:
L1缓存 (Level 1):
- 通常嵌入在CPU核心内部。
- 速度最快,但容量相对较小,通常在几十KB到几百KB之间。
- 有时分为指令缓存(用于存储即将执行的指令)和数据缓存。
L2缓存 (Level 2):
- 速度比L1缓存慢,但容量更大,通常在几百KB到几MB之间。
- 可以嵌入在CPU核心内,或者与一组核心共享。
L3缓存 (Level 3):
- 比L2缓存慢,但容量更大,可以达到几十MB。
- 通常是所有CPU核心共享的,位于CPU芯片上,但不嵌入在核心内。
L4缓存 (Level 4) 和更高层缓存:
- 不是所有系统都有这些高级的缓存。
- 通常位于特定的高性能计算系统或集成了eDRAM的CPU中。
- 其容量可以非常大,但访问速度相对较慢。
随着层次的提高,每一层缓存的访问时间逐渐增加,但容量也随之增大。目的是捕获不同的局部性:L1缓存捕获时间局部性,即最近用过的数据可能很快再次被使用;L2和L3缓存捕获空间局部性,即如果某个地址被访问,那么其附近的地址可能也会很快被访问。
2.2 为什么 CPU 缓存要分级?
缓存的分级设计主要是为了解决存储器的速度与容量之间的矛盾。这是因为,在存储技术中,通常速度快的存储器成本较高并且容量较小,而速度慢的存储器成本较低且容量较大。以下是将缓存分级的主要原因:
成本与性能的平衡: 最接近CPU的缓存级别(如L1)由于其高速特性通常是最昂贵的。为了使整个系统的成本效益最大化,设计者会选择较小但非常快速的L1缓存,然后使用更大、稍慢、但成本效益更高的L2和L3缓存来补充。
减少访问延迟: L1缓存设计得非常接近CPU,从而实现非常低的数据访问延迟。如果L1未命中,L2和可能的L3会作为后备,这些缓存的访问时间虽然较长,但仍然比直接从主内存中获取数据要快得多。
有效利用空间与带宽: 缓存分级意味着较高级别的缓存可以更有效地利用其存储空间,因为它们主要缓存下一级缓存中的热点数据。这也意味着高级缓存更有可能命中,从而减少对主内存的访问并节省带宽。
工作负载隔离: 不同的应用和工作负载可能会对不同级别的缓存产生不同的压力。通过分级,可以确保一些核心或线程不会完全填满缓存,从而使其他核心或线程饿死。
增加并发性: 通过有多级缓存,同时发出的多个数据请求可以在不同的缓存级别上被同时服务,这增加了处理器的并发数据访问能力。
节省能量: 访问L1缓存通常比访问L2或L3缓存更省电。因此,如果数据可以在L1中找到,则可以避免更多的能源消耗。
总的来说,缓存的分级是为了在速度、成本、功耗和容量之间找到最佳的平衡。这种平衡允许系统达到接近最速存储器性能的速度,同时保持较大的缓存大小和合理的成本。
2.3 L1、L2 和 L3 缓存在设计上有何不同?
L1 采用分离缓存(Harvard 架构)
- 在这种架构下,指令和数据被存储在物理上分离的两个缓存中。
- 这意味着有一个专门的指令缓存 (I-Cache) 和一个专门的数据缓存 (D-Cache)。
- 优势:可以同时访问指令和数据,这有助于提高处理速度。
并且可以独立地优化每个缓存来适应其使用模式。- 劣势:需要更多的硅面积实现物理上的分离。
如果其中一个缓存使用得不多,但另一个缓存面临压力,则不能动态地重新分配空间。
L2/L3 采用统一缓存(Von Neumann 架构)
- 在这种架构下,指令和数据共享同一个物理缓存。
- 优势:缓存的总体使用更为灵活,因为它可以动态地为指令和数据分配空间。
设计和实现上更简单,需要的硅面积可能更少。- 劣势:不能同时从缓存中取指令和访问数据,这可能降低处理速度。
指令和数据争用相同的缓存空间,可能导致更频繁的缓存失效。
2.4 为什么 L1 cache 采用分离缓存的方式,而 L2、L3 采用统一缓存的形式?
缓存的设计受到多种因素的影响:
访问速度:
- L1缓存:因为它位于CPU非常近的位置,L1缓存的设计目标是最大限度地减少延迟。分离的指令和数据缓存可以允许同时进行指令取址和数据访问,从而加快执行速度。
- L2/L3缓存:相对于L1来说,L2和L3的延迟较高,但它们主要是为了提供更大的容量,从而减少对主内存的访问。因为延迟已经存在,所以设计上可以稍微复杂一些,合并指令和数据在同一缓存中。
面积和复杂性:
- L1缓存:分离的指令和数据缓存意味着每个缓存可以被优化为其特定的访问模式。此外,由于L1缓存的大小相对较小,所以分离不会造成太大的面积开销。
- L2/L3缓存:这些缓存级别通常比L1缓存大得多。将指令和数据合并在一个统一的缓存中可以简化设计并节省硅面积。
局部性:
- L1缓存:分离缓存可以更好地利用指令和数据的局部性,因为它们不会相互驱逐彼此的条目。
- L2/L3缓存:在这些级别,数据和指令的访问模式变得更加混合,所以合并在一个统一的缓存中可以更好地利用总体的局部性。
功耗:
- L1缓存:由于L1缓存频繁地被访问,所以它的功耗是一个重要考虑因素。分离的设计可以减少不必要的访问,例如当CPU只需要数据时,只访问数据缓存,而不是同时访问指令缓存。
总的来说,L1、L2 和 L3 缓存之间的设计差异是由于它们在 CPU 存储器层次结构中的角色和目标所导致的。L1 缓存的主要目标是速度,而 L2 和 L3 缓存的主要目标是容量和减少对主内存的访问。
3. CPU 缓存的工作原理
3.1 缓存组织结构(映射方式)有哪几种类型?
缓存组织结构一般有以下三种类型:
- Direct-mapped Cache (直接映射缓存):
- 在这种结构中,每个主存中的块只能映射到缓存的一个特定位置。这是通过将主存块地址除以缓存的块数量来决定的。由于这种直接映射方法,查找速度非常快。但是,这种方法可能会导致许多缓存冲突,尤其是如果两个经常被访问的主存块被映射到同一个缓存位置时。
- Fully Associative Cache (全相联缓存):
- 在全相联缓存中,主存中的任何块都可以放在缓存的任何位置。当CPU查找一个块时,它会在缓存的每个位置上进行查找(通常使用并行搜索)。这消除了由于冲突导致的缓存未命中,但是查找速度可能较慢,并且实现上更加复杂和昂贵。
- Set-Associative Cache (组相联缓存):
- 这是前两种类型的折中。缓存被分为几个集合,每个集合包含一定数量的缓存行。一个主存块可以映射到一个特定的集合,但在那个集合中,它可以放在任何缓存行中。例如,在 2-way set-associative 缓存中,每个集合有两个缓存行。查找时,只需要在指定的集合中搜索,这大大减少了搜索的时间和复杂性。
这三种类型都有其利弊,选择哪种类型取决于实际应用的需求。例如,高性能的处理器可能会使用 2-way 或 4-way 组相联缓存作为其 L1 缓存,因为这提供了良好的折中方案,而 L2 或 L3 缓存可能有更高的相联度,因为它们更大并且查找速度可以稍微慢一些。
3.2 Set-Associative Cache(组相联缓存)的结构是什么样的?
Set-associative(组相联)缓存的基本结构如下图所示:
- 组(Set):
在 set-associative 缓存中,缓存被分成了多个集合。每个集合都包含一个或多个缓存行。
当 CPU 尝试从缓存中查找数据时,它会根据该数据的地址来确定要查找哪个集合。
- 缓存块/行(Cache Block/Line):
缓存块是缓存的最小单元。
一个缓存块的常见大小为 32 字节、64 字节或 128 字节,与系统内存块的大小是一致的。
当主存储器的一部分数据被加载到缓存中时,它会被加载到一个缓存行中。
每个缓存行不仅包含数据,还包含该数据在主存储器中的地址的一部分(通常称为标签)。
- 路(Way 或 Slot):
指 set-associative 缓存中每个集合的缓存行数。
例如上图中,如果一个缓存是 4-way set-associative 的,那么每个集合有 4 个缓存行或槽位。
这意味着,当数据从主存加载到这个集合时,它可以放在 4 个可能的缓存行中的任何一个。
- 缓存地址(Cache address):
CPU 访问 cache 时的地址编码;
包含 3 个部分:偏移量(Block Offset)域、索引(Set Index)域和标记(Tag)域。
- 块内偏移(Block Offset):
- 这部分地址用于在缓存块内部选择特定的字节数据。
- 这部分的位数决定了一个缓存块(或称为缓存行)的大小。
- 例如,如果一个缓存块是32字节,那么你需要5位来表示这32字节中的每一个字节(因为2^5 = 32)。
- 组索引(Set Index)
- 主存地址的某一部分被用作索引,以确定数据应该放在缓存的哪个集合中。
- 这部分的位数取决于缓存中组的数量。
- 例如,如果缓存有128组,那么需要7位来索引这些组(因为2^7 = 128)。
- 标签(Tag):
- 这部分包含了地址的其余部分,并存储在标签存储器中。
- 当检索缓存时,这部分与标签存储器中的标签进行比较,以确定所请求的数据是否在缓存中。
- 标签存储器(Tag memory):
对于每个数据块,都有一个与之对应的条目在标签存储器中。
它用于存储每个缓存块中数据的源地址信息。当 CPU 查找缓存时,它会检查标签存储器来确定缓存中是否包含所需的数据。
每个条目通常包含 3 部分:标签(Tag)、有效位(Valid Bit)、脏位/读写位(Dirty Bit or R/W Bit)
- 有效位(Valid Bit):
- 这个位表示缓存中的一个特定块是否包含有效数据。
- 当进行缓存清除或初始化时,这个位通常被设置为0。
- 修改位/脏位(Dirty Bit):
- 这个位表示数据是否被修改。
- 如果脏位被设置,意味着该缓存行的数据与主内存中的数据不匹配,并且在某个时刻需要将其写回主内存。

3.3 简述 Set-Associative Cache(组相联缓存)的工作流程?
组相联缓存尝试在直接映射的确定性和全相联的灵活性之间找到一个平衡。通过允许每个内存块映射到多个但不是全部的缓存行,它提供了更高的命中率而不牺牲太多的复杂性或成本。以下是组相联缓存的工作流程:
- 地址解码:
- 当 CPU 生成一个地址以检索某些数据时,这个地址被分解成三部分:标签(Tag)、组索引(Set Index)和块内偏移(Block Offset)。
- 选择缓存组:
- 使用组索引(Set Index)来选择对应的缓存组。
- 标签比较:
- 在选定的缓存组中,每个缓存行的标签都与请求地址的标签进行比较。
- 这是并行进行的,因为我们需要快速地确定数据是否存在于任何给定的行中。
- 数据检索/存储:
- 命中:如果任何行的标签与请求地址的标签匹配,并且有效位表示该行是有效的,那么这就是一个缓存命中。从该行中的块内偏移位置检索数据。
- 未命中:如果没有行的标签与请求地址匹配,或者匹配的行无效,那么这是一个缓存未命中。处理器将从主内存中获取数据,可能会替换掉缓存组中的一个旧行。
- 替换策略:
- 对于缓存未命中,需要从主内存中加载数据到缓存。
- 如果所选的缓存组已满,我们需要选择一个缓存行来替换。
- 常用的替换策略有:最近最少使用(LRU)、随机替换、FIFO 等。具体使用哪种策略取决于缓存的设计。
- 写策略:
- 当 CPU 需要将数据写回到一个地址时,缓存需要决定是立即写回到主内存(写回策略)还是仅当该行被替换时才写回(写通过策略)。
- 考虑到写分配策略和不写分配策略的选择,可以决定在写操作未命中时是否加载一个新的缓存行。
3.4 Cache 体系结构有哪几种?
缓存体系结构有多种设计策略,主要涉及到如何处理虚拟地址和物理地址之间的映射。这些策略对于CPU的性能和复杂性都有重要影响。下面列举的三种缓存策略是最常见的:
- VIVT (Virtually Indexed, Virtually Tagged)
- 索引: 使用虚拟地址进行缓存行索引。
- 标签: 使用虚拟地址进行缓存行标签比较。
- 优点:
- 低延迟:不需要等待地址转换(从虚拟地址到物理地址)完成就可以进行缓存访问。
- 简单:没有必要进行地址转换。
- 缺点:
- 需要处理地址空间的重叠,因为不同的进程可能会有相同的虚拟地址但不同的物理地址。
- 当上下文切换发生时,可能需要刷新缓存或使用其他机制来解决潜在的地址冲突。
- PIPT (Physically Indexed, Physically Tagged)
- 索引: 使用物理地址进行缓存行索引。
- 标签: 使用物理地址进行缓存行标签比较。
- 优点:
- 没有虚拟地址空间重叠的问题。可以确保缓存的一致性和正确性。
- 更适合多处理器系统,因为它们共享同一物理内存空间。
- 缺点:
- 更高的延迟,因为在进行缓存访问之前必须完成地址转换。
- **VIPT (Virtually Indexed, Physically Tagged) **
- 索引: 使用虚拟地址进行缓存行索引。
- 标签: 使用物理地址进行缓存行标签比较。
- 优点:
- 由于使用虚拟地址进行索引,所以在某些情况下可以比PIPT更快。
- 通过使用物理地址进行标签比较,可以避免VIVT中的地址空间重叠问题。
- 缺点:
- 更复杂,因为它结合了虚拟和物理地址的使用。
- 仍然需要等待部分地址转换完成才能确定是否命中。
注意在 ARM 架构中,仅仅 L1 是 VIPT,L2 和 L3 都是 PIPT。所以当有一个虚拟地址送进来,MMU 在开始进行地址翻译的时候,Virtual Index 就可以去 L1 cache 中查询了,MMU 查询和 L1 cache 的 index 查询是同时进行的。如果 L1 Miss 了,则再去查询 L2,L2 还找不到则再去查询 L3。
3.5 Cache 替换策略有哪几种?
缓存替换策略决定了当缓存行需要被替换时,哪一个缓存行会被选中。这是为了在缓存中保持最有可能被使用的数据。以下是一些常见的缓存替换策略:
最近最少使用 (LRU, Least Recently Used):
- LRU 策略替换最近最少使用的缓存行。
- 该策略基于的思想是如果一个数据在过去没有被使用,那么在未来很可能也不会被使用。
随机替换 (Random Replacement):
- 这种策略简单地随机选择一个缓存行来替换,不基于任何数据的历史访问模式。
先进先出 (FIFO, First In First Out):
- FIFO 策略替换在缓存中存在时间最长的缓存行。
- 但是,它并不总是效果很好,因为老数据可能仍然经常被访问。
最近未使用 (LFU, Least Frequently Used):
- LFU策略是替换在缓存中被访问次数最少的缓存行。
- 这需要缓存持续跟踪每个缓存行的访问次数,这可能会增加其实现的复杂性。
伪 LRU (Pseudo-LRU):
- 真正的 LRU 实现在硬件中可能会很复杂和昂贵。
- 伪 LRU 是一种简化版本,它试图近似 LRU 的行为但实现起来更简单。
OPT (Optimal Replacement Policy):
这是一种理论上的策略,它总是选择将在未来最长时间内不被访问的缓存行进行替换。
在实际的系统中,这是不可能的,因为它需要对未来的数据访问有完美的知识。
其中,LRU 和它的变种是最常用的缓存替换策略,因为它通常能提供很好的性能。然而,在硬件实现时,真正的LRU可能会有些复杂和昂贵,因此伪LRU和其他简化版本在某些情况下可能会更受欢迎。
3.6 详细描述 CPU 从发出内存请求到得到返回过程中,Cache 和内存执行的完整流程?
当使用 VIPT 的 L1 缓存和 PIPT 的 L2/L3 缓存时,内存访问和管理过程会涉及多个步骤和组件。以下是从 CPU 发出内存请求到得到返回的所有环节的详细描述:
CPU发出内存请求:
- 当CPU需要访问某个内存地址时,它首先发出一个虚拟地址,因为现代系统使用虚拟内存来隔离进程和管理内存。
L1 Cache (VIPT) 访问:
- 使用虚拟地址的部分索引L1缓存。
- 同时,地址转换(从虚拟地址到物理地址)开始。为此,CPU查询TLB。
TLB查询:
- TLB(Translation Lookaside Buffer)是一个小而快速的缓存,它存储最近使用过的虚拟到物理地址的映射。
- 如果TLB命中,即如果需要的映射存在于TLB中,则转换过程非常快,物理地址立即可用。
- 如果TLB未命中,则需要访问页表。
页表访问:
- 页表存储在主内存中,并存储虚拟到物理地址的映射。
- 如果所需的页面在物理内存中(即页表中有一个有效的物理地址条目),则地址转换完成。
- 如果页面不在物理内存中,会发生缺页中断。
缺页中断处理:
- 当发生缺页中断时,操作系统需要从磁盘中获取所需的页面。
- 为了腾出空间,操作系统可能需要选择一个物理内存中的页面进行置换(即将其移出物理内存并保存到磁盘上)。
- 一旦页面被加载到物理内存中,页表被更新,并且缺页中断返回。
L1缓存标签比较:
- 一旦有了物理地址,就进行 L1 缓存的标签比较。
- 如果 L1 命中,数据从 L1 返回到 CPU。
- 如果 L1 未命中,请求传递到 L2。
L2 Cache (PIPT) 访问:
- 使用物理地址索引和标记 L2。
- 如果 L2 命中,数据从 L2 返回到 CPU。
- 如果 L2 未命中,请求传递到 L3。
L3 Cache (PIPT) 访问:
- 使用物理地址索引和标记 L3。
- 如果 L3 命中,数据从 L3 返回到 CPU。
- 如果 L3 未命中,请求传递到主内存。
主内存访问:
- 如果数据不在任何缓存中,它一定在主内存中。
- CPU 从主内存中读取数据,并返回。
缓存行加载:
- 当从更高层次的缓存或主内存中获取数据时,通常会加载一个完整的缓存行而不仅仅是所需的数据。
- 这是因为空间局部性原理,即当某个数据项被访问时,其附近的数据在不久的将来很可能也会被访问。
- 当 L1 未命中,但 L2 或 L3 命中时,不仅会将数据返回到 CPU,还会更新 L1 的缓存行。
- 如果所有缓存级别都未命中,当数据从主内存加载到 CPU 时,所有级别的缓存都可能被更新。
缓存的替换:
- 当缓存中没有可用空间来存储新的缓存行时,需要决定哪一个旧的缓存行将被替换或丢弃。
- 常见的策略有:最近最少使用(LRU)、随机替换和先进先出(FIFO)。
在整个过程中,虚拟到物理的地址转换和内存访问是两个主要的步骤。虚拟内存提供了进程隔离和内存管理的优势,但也引入了地址转换的额外步骤。缓存尝试减少从主内存获取数据的时间,因为这通常比从缓存获取数据要慢得多。

3.7 写操作中 Cache 分配策略有哪些?最常用的策略是什么?
缓存写策略决定了当处理器需要修改一个在缓存中存在的条目时应如何处理。写策略主要涉及两个关键问题:
写命中(Write Hit): 当需要写的数据在缓存中找到时怎么办?
写未命中(Write Miss): 当需要写的数据未在缓存中找到时怎么办?
以下是几种常见的写策略:
写命中时缓存的写策略:
写回(Write-Back):
- 当缓存行被修改时,它仅在缓存中被标记为“已修改”,但不立即写入到主内存。
- 只有当缓存行被替换出去时,它才被写回到主内存。
写通(Write-Through):
- 一旦缓存行被修改,数据也立即被写入到主内存中。
写未命中时缓存的写策略:
写分配(Write-Allocate):
- 如果写操作未命中,那么首先将相关的缓存行加载到缓存中,然后再更新该缓存行。
不写分配(No Write-Allocate):
- 写未命中时,数据直接被写入到主内存,而不加载该缓存行。
“写回” 与 “写分配” 会结合使用(最常用的策略)
优点:
- 降低了带宽需求,因为只有在替换时才写回主内存。
缺点:
更复杂的一致性管理,因为主内存可能包含过时的数据。
在缓存替换时需要额外的写操作。
“写通” 与 “不写分配” 会结合使用
- 优点:
- 主内存中的数据始终是最新的,简化了缓存一致性的处理。
- 缺点:
- 每次写都需要访问主内存,可能导致较高的带宽需求和延迟。
3.8 读操作中 Cache 分配策略有哪些?最常用的策略是什么?
读操作的策略相对简单:
- 总是分配(Always Allocate):
- 当发生读未命中时,总是从主存中加载数据块到缓存。
- 这是最常用的策略,因为当一次读操作未命中时,很有可能后续的读写操作会访问相同的数据块。
- 不分配(Never Allocate on a read miss):
- 读操作未命中时,数据从主存返回到处理器,但不存储在缓存中。
- 这种策略在某些特定应用中可能有用,其中连续读取的数据块只读取一次。
对于大多数常规应用和系统,总是分配(Always Allocate) 策略是最常用和最有效的,因为它利用了空间局部性原理:如果一个数据项被访问,那么其邻近的数据项在不久的将来可能也会被访问。
4. 缓存一致性(Cache Coherence)
4.1 缓存一致性(Cache Coherence)问题是怎么发生的?如何解决?
缓存一致性(Cache Coherence)问题主要发生在多处理器或多核系统中,当多个处理器拥有对同一内存位置的本地缓存副本时。以下是问题的起源和示例场景:
起源:
- 多处理器或多核系统中,每个处理器可能有自己的缓存。
- 当多个处理器并行执行,并且访问同一块内存时,每个处理器可能在其缓存中维护这块内存的一个副本。
- 如果一个处理器修改了其缓存中的值,其他处理器的缓存中的副本就会变得过时或不一致。
示例场景:
假设我们有两个处理器,P1 和 P2,它们都从同一个内存位置 M 读取数据并将其缓存。
时间 t0:P1 和 P2 都读取 M 的值,假设为 5,并将其缓存在它们的本地缓存中。
时间 t1:P1 修改 M 的值为 10,并更新其本地缓存。
时间 t2:如果没有适当的缓存一致性机制,当 P2 再次读取 M 的值时,它可能会从其本地缓存中读取旧值 5,而不是更新后的值 10。
此种不一致性可能导致程序错误、难以追踪的行为以及性能下降。要解决缓存一致性问题,需要确保以下两个条件满足:
写入一致性(Write Propagation)
- 当一个值被一个处理器写入时,这个写入操作需要在某个时间点传播到其他处理器的缓存。
事务串行性(Transaction Serialization)
如果两个处理器尝试在同一时间写入同一位置,写入应该是串行的,确保所有的处理器看到这两个写入的相对顺序是一致的。
为了维护缓存一致性,多数现代多处理器系统实现了一致性协议,如 MESI、MOESI、MSI 等,这些协议通过定义缓存行的状态并规定在各种情况下的行为来确保一致性。
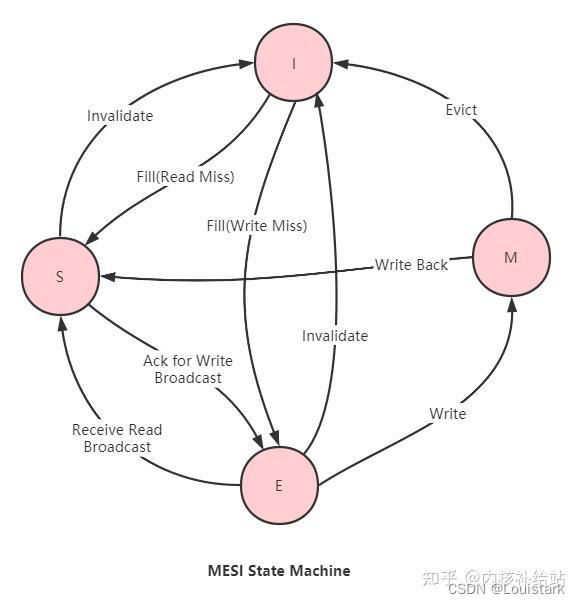
4.2 MESI 协议是什么?他是如何保证缓存一致性的?
MESI 协议是一个用于保证多处理器系统中缓存一致性的协议。名字MESI代表该协议定义的四个状态:Modified(M)、Exclusive(E)、Shared(S) 和 Invalid(I)。这四个状态描述了一个缓存行相对于主内存和其他处理器的缓存的状态。
如下图所示为 MESI 状态机(图源 知乎@内核补给站):
以下是每个状态的解释和如何维护缓存一致性:
Modified (M):
- 缓存行已被当前处理器修改,并且与主存中的值不同。
- 当其他处理器请求这个地址时,拥有该地址的处理器将响应并提供更新后的值,并将其状态更改为Invalid。
Exclusive (E):
- 缓存行未被修改,与主存中的值匹配。
- 该缓存行只在当前处理器的缓存中存在,其他处理器的缓存中不存在这个地址。
- 当处理器写入此缓存行时,其状态会变为Modified。
Shared (S):
- 缓存行未被修改,与主存中的值匹配。
- 该缓存行可能存在于多个处理器的缓存中。
- 当一个处理器写入一个Shared状态的缓存行时,该行在该处理器的缓存中变为Modified,而其他处理器的缓存中的该行变为Invalid。
Invalid (I):
缓存行无效或不一致。
当其他处理器写入同一内存地址时,该缓存行将变为Invalid。
MESI 协议如何工作:
- 当一个处理器想要读取或写入一个地址时,它会在其本地缓存中查找该地址。如果找不到,它会在总线上发出请求。
- 根据该地址在其他处理器缓存中的状态和该处理器的请求类型(读或写),其他处理器会响应,可能提供数据,也可能使其缓存行无效。
- 通过监听总线并根据其他处理器的请求和自己缓存中数据的状态更改自己缓存的状态,每个处理器确保其缓存的一致性。
相关文章:
【面试笔记】CPU 缓存机制
CPU 缓存机制 1. CPU Cache 与 MMU1.1 MMU 是什么?TLB 又是什么?他们是怎么工作的?2.2 简述 Cache 与 MMU 的协作关系?2.3 简述 Cache 与 MMU 的协作工作流程? 2. CPU 多层次缓存2.1 什么是 CPU 的多层次缓存结构&…...

MySQL基础函数使用
目录 简介 1. 单行函数 1.1 字符串函数 1.2 日期函数 1.3 数值函数 1.4 转换函数 1.5 其他函数 2. 多行函数 示例: 3. 数据分组 示例: 4. DQL单表关键字执行顺序 示例: 5. 多表查询 示例: 6. 表与表的外连接 示例…...

解决docker环境下aspose-words转换word成pdf后乱码问题
描述 环境:docker 部署工具:Jenkins 需求:本地上传的word文档需要转换成pdf 问题:转换之后的pdf文档出现小框框(乱码) 转换成PDF的操作 pom: <dependency><groupId>org.apach…...

C# 生成随机数的方法
C# 提供了一种强大而方便的工具类 Random ,用于生成随机数。这里将分类讨论如何通过 C# 实现随机数生成,以及应用于实际情况中的一些具体方案。 一、Random 类概述 Random 类表示一个伪随机数生成器,用于生成满足随机性统计要求的数字序列。…...

ip_done
文章目录 路由结论 IP分片 数据链路层重谈Mac地址MAC帧报头局域网的通信原理MSS,以及MAC帧对上层的影响ARP协议 1.公司是不是这样呢? 类似的要给运营商交钱,构建公司的子网,具有公司级别的入口路由器 2.为什么要这样呢?? IP地…...

3D可视化引擎HOOPS Visualize与HOOPS Luminate Bridge的功能与应用
HOOPS Visualize HPS / HOOPS Luminate Bridge为开发者提供了强大的工具,用于在CAD应用中集成逼真的渲染能力。本文旨在梳理该桥接产品的核心功能、使用方法及应用场景,为用户快速上手并充分利用产品特性提供指导。 桥接产品的核心功能概述 HOOPS Lumi…...

Docder 搭建Redis分片集群 散片插槽 数据分片 故障转移 Java连接
介绍 使多个 Redis 实例共同工作,实现数据的水平扩展。通过将数据分片到多个节点上,Redis 集群能够在不牺牲性能的前提下扩展存储容量和处理能力,从而支持更高并发的请求。Redis 集群不仅支持数据分片,还提供了自动故障转移和高可…...

校园交友app/校园资源共享小程序/校园圈子集合二手物品交易论坛、交友等综合型生活服务社交论坛
多客校园社交圈子系统搭建 校园交友多功能系统源码: 1、更改学校为独立的模块。整体UI改为绿色,青春色,更贴近校园风格。2、圈子归纳到学校去进行运营。每个学校可建立多个圈子。和其他学校圈子互不干扰。3、增加用户绑定学校,以后进入将默认…...
Chaos Mesh云原生的混沌测试平台搭建
Chaos Mesh云原生的混沌测试平台搭建 一.环境准备 确认已经安装helm,如要查看 Helm 是否已经安装,请执行如下命令: helm version二.使用helm安装 1.添加 Chaos Mesh 仓库 在 Helm 仓库中添加 Chaos Mesh 仓库: helm re…...

Vue3之组合式API详解
Vue 3引入了一种新的API风格——组合式API(Composition API),旨在提升组件的逻辑复用性和可维护性。本文将详细阐述Vue 3中的组合式API,包括其定义、特点、使用场景、优势等,并给出具体的示例代码。 一、定义 组合式…...

大模型的构建与部署(3)——数据标注
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl1. 数据标注的重要性 1.1 增强数据可解释性 数据标注通过为原始数据添加标签或注释,显著增强了数据的可解释性。在机器学习和深度学习领域,模型的训练依赖于大量带标签的数据。这些标签不仅帮助…...

AI发展与LabVIEW程序员就业
人工智能(AI)技术的快速发展确实对许多行业带来了变革,包括自动化、数据分析、软件开发等领域。对于LabVIEW程序员来说,AI的崛起确实引发了一个值得关注的问题:AI会不会取代他们的工作,导致大量失业&#x…...

本地事务 + 消息队列事务方案设计
Spring Boot 和 RocketMQ 在Spring Boot项目中实现“本地事务 消息队列事务”的方案,可以按照以下步骤实现: 先执行MySQL本地事务操作(未提交)随后发送消息到消息队列(如RocketMQ事务消息)等待消息队列确…...

pinctrl子系统学习笔记
一、背景 cpu的gpio引脚可以复用成多个功能,如可以配置成I2C或者普通GPIO模式。配置方式一般是通过写引脚复用的配置寄存器,但是不同芯片厂商配置寄存器格式内容各不相同,设置引脚复用无法做到通用且自由的配置,只能在启动初始化…...

使用vue-element 的计数器inputNumber,传第三个参数
使用vue-element 的计数器inputNumber。 其中的change 事件中,默认自带两个参数,currentValue和oldValue,分别代表改变后的数和改变前的数, 如果想要传第三个参数, change"(currentValue, oldValue) > numCha…...

如何从0构建一个flask项目,直接上实操!!!
项目结构 首先,创建一个项目目录,结构如下: flask_app/ │ ├── app.py # Flask 应用代码 ├── static/ # 存放静态文件(如CSS、JS、图片等) │ └── style.css # 示例…...

Mongoose连接数据库操作实践
文章目录 介绍特点:Mongoose 使用:创建项目并安装:连接到 MongoDB:定义 Schema:创建模型并操作数据库:创建文档:查询文档:更新文档:删除文档:使用钩子&#x…...

centos 7.9 freeswitch1.10.9环境搭建
亲测版本centos 7.9系统–》 freeswitch1.10.9 一、下载插件 yum install -y git alsa-lib-devel autoconf automake bison broadvoice-devel bzip2 curl-devel libdb4-devel e2fsprogs-devel erlang flite-devel g722_1-devel gcc-c++ gdbm-devel gnutls-devel ilbc2...

Gitlab服务管理和仓库项目权限管理
Gitlab服务管理 gitlab-ctl start # 启动所有 gitlab 组件; gitlab-ctl stop # 停止所有 gitlab 组件; gitlab-ctl restart # 重启所有 gitlab 组件; gitlab-ctl status …...

LLMs之Llama-3:Llama-3.3的简介、安装和使用方法、案例应用之详细攻略
LLMs之Llama-3:Llama-3.3的简介、安装和使用方法、案例应用之详细攻略 目录 相关文章 LLMs之LLaMA:LLaMA的简介、安装和使用方法、案例应用之详细攻略 LLMs之LLaMA-2:LLaMA 2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途…...

从Prompt到成稿|像素剧本圣殿输入剧情大纲→输出标准剧本全流程
从Prompt到成稿|像素剧本圣殿输入剧情大纲→输出标准剧本全流程 1. 工具介绍:像素剧本圣殿 像素剧本圣殿是一款基于Qwen2.5-14B-Instruct大模型深度优化的专业剧本创作工具。它将先进的AI文本生成能力与独特的8-Bit复古视觉风格相结合,为编…...

AssetStudio终极指南:快速免费提取Unity游戏模型、纹理与音频资源
AssetStudio终极指南:快速免费提取Unity游戏模型、纹理与音频资源 【免费下载链接】AssetStudio 项目地址: https://gitcode.com/gh_mirrors/asse/AssetStudio AssetStudio是一款功能强大的开源工具,专为Unity游戏资源提取设计,能够轻…...

Java毕业设计实战:基于SpringBoot的社区健康档案管理系统开发指南
1. 为什么选择SpringBoot开发健康档案管理系统 作为一个带过上百个Java毕业设计的导师,我强烈推荐用SpringBoot来开发社区健康档案管理系统。去年我带的学生小张就用这个框架完成了他的毕设,不仅顺利通过答辩,还被当地社区卫生服务中心看中直…...

深入理解Java AQS:抽象队列同步器的核心原理与实战指南
深入理解Java AQS:抽象队列同步器的核心原理与实战指南 【免费下载链接】JavaGuide Java 面试 & 后端通用面试指南,覆盖计算机基础、数据库、分布式、高并发、系统设计与 AI 应用开发 项目地址: https://gitcode.com/gh_mirrors/ja/JavaGuide …...
Gemma-3 Pixel Studio参数详解:max_new_tokens与图像理解深度关系实测
Gemma-3 Pixel Studio参数详解:max_new_tokens与图像理解深度关系实测 1. 引言 在当今多模态AI应用领域,Gemma-3 Pixel Studio以其独特的视觉理解能力和流畅的对话体验脱颖而出。作为基于Google Gemma-3-12b-it模型构建的专业工具,它不仅继…...

小爱音箱音乐自由播放器:解锁无限听歌体验的完整指南
小爱音箱音乐自由播放器:解锁无限听歌体验的完整指南 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否厌倦了音乐平台的各种限制?是否想…...
GPU算力高效利用:Pixel Language Portal在单卡多实例部署中的资源隔离与负载均衡教程
GPU算力高效利用:Pixel Language Portal在单卡多实例部署中的资源隔离与负载均衡教程 1. 引言:为什么需要单卡多实例部署 在AI应用开发中,GPU资源往往是稀缺且昂贵的。Pixel Language Portal作为一款基于Tencent Hunyuan-MT-7B的高端翻译工…...

租车宝 token、payload算法分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 部分python代码 url "/queryOr…...

Phi-3-mini-4k-instruct-gguf效果实测:128ms首token延迟+98%中文基础任务通过率
Phi-3-mini-4k-instruct-gguf效果实测:128ms首token延迟98%中文基础任务通过率 1. 开篇:轻量级文本生成新选择 最近测试了微软Phi-3系列中的轻量级选手——Phi-3-mini-4k-instruct-gguf模型,结果让人惊喜。这个专门优化过的GGUF版本&#x…...

AutoHotkey脚本编译指南:3步将.ahk文件转为独立可执行程序
AutoHotkey脚本编译指南:3步将.ahk文件转为独立可执行程序 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否曾想过将精心编写的AutoHotkey自动化…...