【算法】动态规划中01背包问题解析
📢博客主页:https://blog.csdn.net/2301_779549673
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、01 背包问题概述
- 🏳️🌈二、问题分析与解法
- ❤️(一)表示状态
- 🧡(二)状态转移方程
- 🧡(三)代码实现
- 🏳️🌈三、多种实现方式与优化
- ❤️(一)暴力搜索
- 🧡(二)记忆化搜索
- 💛(三)动态规划
- 💚(四)空间优化
- 🏳️🌈四、01背包例题
- ❤️[DP42 【模板】完全背包](https://www.nowcoder.com/practice/fd55637d3f24484e96dad9e992d3f62e?tpId=230&tqId=2032484&ru=/exam/oj&qru=/ta/dynamic-programming/question-ranking&sourceUrl=%2Fexam%2Foj%3Fpage%3D1%26tab%3D%25E7%25AE%2597%25E6%25B3%2595%25E7%25AF%2587%26topicId%3D196)
- 🧡[416. 分割等和子集](https://leetcode.cn/problems/partition-equal-subset-sum/)
- 💛[1049. 最后一块石头的重量 II](https://leetcode.cn/problems/last-stone-weight-ii/)
- 👥总结
🏳️🌈一、01 背包问题概述

01 背包问题是一个非常经典的动态规划问题,其场景设定为:给定一个背包,它有一定的容量限制,同时有若干种物品,每种物品都有对应的重量和价值,且每种物品只能选择放入背包一次(即选择 0 个或者 1 个),目标是在满足背包容量限制的条件下,求出能够装入背包的物品的最大价值总和。
这类问题最基本的解法就是利用二维数组动态规划。利用 f[i][j] 表示前i个物品中,在背包使用量为j ``时所能容纳的最大价值,最终结果在f[n][v]` 中。
具体情况可以分为两种,即不选择 i 位置的物品,结果为 f[i - 1][j] ,
以及选择 i 位置的物品,结果为 f[i][j - v[i]] + w[i],当然这是有前提条件的,即当前背包容量的最大值比这个物品的体积大,不然会越界

🏳️🌈二、问题分析与解法
❤️(一)表示状态
我们通常会建立相应的数组来存储各个子问题的解。首先,用两个数组分别来表示物品的重量和价值,例如weight[n]表示 n 个物品各自的重量,value[n]表示 n 个物品各自的价值(这里 n 为物品的总数量)。
然后,定义动态规划的状态表示,一般会使用 dp[i][j],它的含义是将前 i 件物品放入容量为 j 的背包里所能获得的最大价值。这里 i 的取值范围是从 0 到物品总数量,j 的取值范围是从 0 到背包的最大容量。
🧡(二)状态转移方程
对于dp[i][j]这个状态,需要考虑第 i 件物品的选择情况,主要分为两种:
不选第i 件物品:此时背包里的最大价值就等于前 i - 1 件物品放入容量为 j 的背包里的最大价值,即 dp[i][j] = dp[i - 1][j]。
选择第 i 件物品:前提是背包的容量 j 要大于等于第 i 件物品的重量 weight[i],那么此时背包里的最大价值就是前 i - 1 件物品放入容量为 j - weight[i] 的背包里的最大价值,再加上第 i 件物品本身的价值 value[i],即 dp[i][j] = dp[i - 1][j - weight[i]] + value[i](前提满足容量条件)。
综合这两种情况,状态转移方程可以表示为:
dp[i][j] = max(dp[i - 1][j], j >= weight[i]? dp[i - 1][j - weight[i]] + value[i] : 0);
🧡(三)代码实现
- 未优化版代码
以下是使用二维数组来实现的未优化的 01 背包问题代码示例:
#include <iostream>
#include <vector>
using namespace std;int knapsack(vector<int>& weight, vector<int>& value, int capacity) {int n = weight.size();vector<vector<int>> dp(n + 1, vector<int>(capacity + 1, 0));for (int i = 1; i <= n; ++i) {for (int j = 0; j <= capacity; ++j) {dp[i][j] = dp[i - 1][j];if (j >= weight[i - 1]) {dp[i][j] = max(dp[i][j], dp[i - 1][j - weight[i - 1]] + value[i - 1]);}}}return dp[n][capacity];
}int main() {vector<int> weight = {2, 3, 4};vector<int> value = {3, 4, 5};int capacity = 5;cout << "背包能装的最大价值为: " << knapsack(weight, value, capacity) << endl;return 0;
}
在上述代码中:
- 首先定义了
dp二维数组并初始化,外层循环遍历物品数量,内层循环遍历背包的不同容量情况。 - 在每次循环中,先默认不选当前物品,然后判断如果背包容量够放当前物品,就比较放和不放当前物品哪种情况能得到更大价值,更新
dp[i][j]的值。 - 最后返回将所有物品考虑完后,给定背包容量下能得到的
最大价值。
- 最终版代码(空间优化)
我们可以发现,在计算dp[i][j]时,只用到了dp[i - 1][...]的值,所以可以将二维数组压缩成一维数组来优化空间复杂度。以下是优化后的代码示例:
#include <iostream>
#include <vector>
using namespace std;int knapsack(vector<int>& weight, vector<int>& value, int capacity) {int n = weight.size();vector<int> dp(capacity + 1, 0);for (int i = 0; i < n; ++i) {// 注意这里要倒序遍历背包容量,防止同一个物品被多次放入背包for (int j = capacity; j >= weight[i]; --j) {dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);}}return dp[capacity];
}int main() {vector<int> weight = {2, 3, 4};vector<int> value = {3, 4, 5};int capacity = 5;cout << "背包能装的最大价值为: " << knapsack(weight, value, capacity) << endl;return 0;
}
这里关键在于内层循环倒序遍历背包容量,这样就能保证每个物品只会被考虑放入背包一次,利用了之前已经计算好的状态,同时节省了空间,只用了一个一维数组 dp 来记录不同背包容量下的最大价值情况,最后返回对应背包容量下的最大价值即可。
🏳️🌈三、多种实现方式与优化
❤️(一)暴力搜索
暴力搜索的思路就是通过递归的方式去尝试所有可能的物品组合放入背包的情况,然后找出其中能得到最大价值的组合。以下是简单的代码示例思路(实际完整代码可自行完善细节):
#include <iostream>
#include <vector>
using namespace std;// 递归计算选择当前物品后的最大价值
int bruteForce(vector<int>& weight, vector<int>& value, int index, int capacity) {if (index == 0 || capacity == 0) {return 0;}int res = bruteForce(weight, value, index - 1, capacity);if (weight[index - 1] <= capacity) {res = max(res, bruteForce(weight, value, index - 1, capacity - weight[index - 1]) + value[index - 1]);}return res;
}int main() {vector<int> weight = {2, 3, 4};vector<int> value = {3, 4, 5};int capacity = 5;cout << "通过暴力搜索背包能装的最大价值为: " << bruteForce(weight, value, weight.size(), capacity) << endl;return 0;
}
这种方法虽然简单直接,但是效率非常低,因为它会有大量的重复计算,随着物品数量和背包容量的增加,时间复杂度会呈指数级增长。
🧡(二)记忆化搜索
为了避免暴力搜索中大量的重复计算问题,可以采用记忆化搜索的方式。其核心思路是创建一个记忆化数组,用来记录已经计算过的子问题的解,下次再遇到同样的子问题时,直接从记忆化数组中获取结果,而不用重新计算。以下是示例代码:
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;unordered_map<int, unordered_map<int, int>> memo;// 记忆化搜索计算最大价值
int memoizedSearch(vector<int>& weight, vector<int>& value, int index, int capacity) {if (index == 0 || capacity == 0) {return 0;}if (memo.count(index) && memo[index].count(capacity)) {return memo[index][capacity];}int res = memoizedSearch(weight, value, index - 1, capacity);if (weight[index - 1] <= capacity) {res = max(res, memoizedSearch(weight, value, index - 1, capacity - weight[index - 1]) + value[index - 1]);}memo[index][capacity] = res;return res;
}int main() {vector<int> weight = {2, 3, 4};vector<int> value = {3, 4, 5};int capacity = 5;cout << "通过记忆化搜索背包能装的最大价值为: " << memoizedSearch(weight, value, weight.size(), capacity) << endl;return 0;
}
通过使用 unordered_map 来作为记忆化的数据结构,记录不同 index(物品索引)和 capacity(背包容量)组合下的最大价值,大大减少了重复计算,提高了效率,但相较于动态规划,代码结构上还是相对复杂些,并且空间复杂度也会因为记忆化数据结构的使用有所增加。
💛(三)动态规划
前面介绍的用二维数组或者优化后的一维数组实现的其实就是标准的动态规划解法。动态规划的核心就是通过记录子问题的解,避免重复计算,利用状态转移方程逐步构建出整个问题的最优解。它的时间复杂度相对暴力搜索有了极大的优化,对于 n 个物品和背包容量为 W 的情况,时间复杂度一般是 O(nW),空间复杂度在未优化时是 O(nW),优化后可以达到 O(W)。
💚(四)空间优化
除了前面提到的将二维数组压缩成一维数组这种常见的空间优化方式外,还可以进一步采用滚动数组等技巧来优化空间。比如在一些动态规划问题中,如果状态转移只依赖于相邻的几个状态,就可以通过巧妙地复用数组空间来进一步减少空间的占用,不过这需要根据具体问题的特点来合理设计和实现。
🏳️🌈四、01背包例题
❤️DP42 【模板】完全背包

整体思路:
本题通过动态规划的方法解决背包问题,针对两个不同的问题要求分别进行了两次动态规划计算。
利用 dp 数组存储中间结果,通过状态转移方程逐步推导出在不同物品数量和背包容量情况下的最大价值。
第一问解题思路:
定义 dp[i][j] 表示在前 i 个物品中,背包容量不超过 j 时能装下的最大价值。
状态转移方程为:dp[i][j] = max(dp[i - 1][j], (j >= v[i])? dp[i - 1][j - v[i]] + w[i] : dp[i - 1][j]),即考虑不选第 i 个物品(直接继承前 i - 1 个物品在当前容量的最大价值)和选第 i 个物品(前提是背包容量够放,此时价值是前 i - 1 个物品在剩余容量的最大价值加上第 i 个物品的价值)这两种情况取最大值。
通过两层循环,外层遍历物品,内层遍历背包容量,逐步填充 dp 数组,最终得到第一问的答案 dp[n][V]。
第二问解题思路:
重新定义 dp[i][j] 表示在前 i 个物品中,背包容量恰好为 j 时能装下的最大价值。
初始化时,对于没有物品可选但背包有容量的情况标记为不可能装满(设为 -1)。
状态转移方程类似第一问,但多了一个限制条件,即只有在前 i - 1 个物品、背包容量为 j - v[i] 时的状态是可以恰好装满背包(不是 -1 标记的情况)时,才考虑选择第 i 个物品来更新 dp[i][j] 的值,同样通过两层循环填充 dp 数组,最后根据 dp[n][V] 的值判断是否能恰好装满背包并输出相应结果。
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<vector>
#include<stdio.h>
#include<string.h>using namespace std;// 定义一个较大的常量,用于表示数组的最大长度,这里假设最多有1010个物品或背包容量最大为1010等情况
const int N = 1010;
int v[N], w[N]; // 分别用于存储每个物品的体积和价值的数组,索引对应物品编号(从1开始)
int n, V; // n表示物品的个数,V表示背包能容纳的最大体积// dp数组用于存储动态规划过程中的中间结果,dp[i][j]有两种含义:
// 1. 对于第一问:表示在前i个物品中,背包容量不超过j时能装下的最大价值。
// 2. 对于第二问:表示在前i个物品中,背包容量恰好为j时能装下的最大价值。
int dp[N][N]; int main() {// 输入物品个数和背包的最大体积cin >> n >> V; // 循环读取每个物品的体积和价值,注意这里索引从1开始,符合常规的计数习惯(第1个物品、第2个物品等)for (int i = 1; i <= n; ++i) scanf("%d %d", &v[i], &w[i]);// 以下是求解第一问的动态规划过程// 外层循环遍历每个物品,从第1个物品开始,逐步考虑到所有的n个物品for (int i = 1; i <= n; ++i++) { // 内层循环遍历背包的不同容量情况,从容量为1开始,到最大容量Vfor (int j = 1; j <= V; ++j) { // 初始化dp[i][j],先默认不选第i个物品时的情况,此时最大价值等于前i - 1个物品在容量为j时的最大价值dp[i][j] = dp[i - 1][j]; // 判断背包当前容量j是否能够容纳第i个物品(即体积是否够放)if (j >= v[i]) // 如果能放,就需要比较放和不放第i个物品哪种情况能让背包中物品的价值更大// 不放就是dp[i - 1][j],放的话就是在前i - 1个物品、背包容量为j - v[i]时的最大价值基础上,加上第i个物品的价值w[i]dp[i][j] = max(dp[i][j], dp[i - 1][j - v[i]] + w[i]); }}// 完成动态规划计算后,输出第一问的结果,即在前n个物品、背包容量为V时能装下的最大价值cout << dp[n][V] << endl; // 以下是求解第二问的动态规划过程// 先将整个dp数组初始化为0,用于重新计算第二问的情况memset(dp, 0, sizeof dp); // 对于容量大于0且没有物品可选(即前0个物品)的情况,将其价值设为 -1,表示这种情况不可能恰好装满背包,是一种特殊的标记for (int j = 1; j <= V; ++j) dp[0][j] = -1; // 外层循环同样遍历每个物品,从第1个物品开始考虑for (int i = 1; i <= n; ++i) { // 内层循环遍历不同的背包容量情况,从容量为1到最大容量Vfor (int j = 1; j <= V; ++j) { // 先默认不选第i个物品时的情况,和第一问类似,此时最大价值等于前i - 1个物品在容量为j时的最大价值dp[i][j] = dp[i - 1][j]; // 判断背包当前容量j是否能容纳第i个物品,并且在前i - 1个物品、背包容量为j - v[i]时的状态是可以恰好装满背包的(不是 -1标记的那种不可能装满的情况)if (j >= v[i] && dp[i - 1][j - v[i]]!= -1) // 如果满足条件,同样比较放和不放第i个物品哪种情况能让背包恰好装满时的价值更大dp[i][j] = max(dp[i][j], dp[i - 1][j - v[i]] + w[i]); }}// 判断最终在前n个物品、背包容量为V时,如果得到的结果是 -1,表示这种情况下无法恰好装满背包,按照要求输出0if (dp[n][V] == -1) cout << 0; // 如果不是 -1,说明能恰好装满背包,输出此时的最大价值else cout << dp[n][V];
}
// 64 位输出请用 printf("%lld")
🧡416. 分割等和子集

整体思路:
本题将能否分割数组成两个和相等子集的问题转化为一个 0/1 背包问题的变形来解决,通过动态规划的方式记录状态并进行状态转移,判断是否能从给定数组中选出一些元素,使其和等于数组总和的一半。
步骤详解:
- 计算数组总和并判断可行性:
首先遍历输入的数组nums,计算出所有元素的总和sum。
如果总和sum是奇数,那无论怎么划分都不可能得到两个和相等的子集,直接返回false。
若总和是偶数,则将其除以2,得到目标和,后续的操作就是围绕能否凑出这个目标和来进行判断。 - 初始化动态规划数组 dp:
创建二维布尔类型的dp数组,dp[i][j]的含义是在数组nums的前 i 个元素中(实际对应nums[0]到nums[i - 1]),是否存在一些元素的和等于 j。
对于没有元素可选(i = 0)但目标和 j 大于 0 的情况,显然是无法凑出目标和的,所以将dp[0][j](j > 0)设为false,而dp[0][0]设为true,表示和为 0 不需要任何元素就可以达到,这是边界情况的设定。 - 动态规划状态转移过程:
通过两层嵌套循环来填充 dp 数组,外层循环变量 i 从 1 到 n(n 是数组 nums 的元素个数),表示逐步考虑数组中的每个元素。
内层循环变量 j 从 1 到 sum(前面计算得到的目标和),表示不同的目标和情况。
对于dp[i][j],先默认不选第 i 个元素时的情况,其值等于前 i - 1 个元素能否凑出和为 j 的情况,即dp[i][j] = dp[i - 1][j]。
然后判断当前目标和 j 是否大于等于第 i 个元素的值(因为索引的对应关系,实际判断 j >= nums[i - 1]),并且在前 i - 1 个元素中已经能够凑出和为j - nums[i - 1]的情况(即dp[i - 1][j - nums[i - 1]]为true),如果满足这两个条件,说明选了第 i 个元素后能凑出和为 j,则将dp[i][j]更新为 true。 - 得出最终结论:
当完成整个动态规划的状态转移后,最终查看dp[n][sum]的值,若其为 true,就意味着可以从数组 nums 中选出一些元素凑出目标和,也就是可以将数组分割成两个子集,使得两个子集的元素和相等;若为 false,则表示无法做到这样的分割。
class Solution {const int N = 20010;
public:bool canPartition(vector<int>& nums) {// 获取输入数组nums的元素个数int n = nums.size(); int sum = 0;// 计算数组nums中所有元素的总和for (auto& x : nums) sum += x; // 如果总和是奇数,那么肯定无法分割成两个和相等的子集,直接返回falseif (sum % 2!= 0) return false; // 如果总和是偶数,将总和除以2,得到目标和,后续就是看能否从数组中选出一些元素凑出这个目标和else sum /= 2; // dp数组用于动态规划过程中的状态记录,dp[i][j]表示在nums数组的前i个元素(即nums[0]到nums[i - 1],注意索引偏移)中,是否存在一些元素的和等于j// 初始化dp数组大小为(n + 1) * (sum + 1),并将所有元素初始值设为false,这里vector<bool>在初始化时会进行默认的初始化,不过为了清晰明确逻辑,我们显式地进行初始化vector<vector<bool>> dp(n + 1, vector<bool>(sum + 1, false)); // 当没有元素可选(即i = 0),但目标和j大于0时,肯定是无法凑出目标和的,所以将这部分设为false,不过dp[0][0]设为true,表示和为0时不需要任何元素就可以达到(边界情况)for (int j = 1; j <= sum; ++j) dp[0][j] = false; // 以下开始动态规划的状态转移过程for (int i = 1; i <= n; ++i) { for (int j = 1; j <= sum; ++j) {// 初始化dp[i][j],先默认不选第i个元素时的情况,此时是否能凑出和为j就取决于前i - 1个元素的情况,所以直接继承dp[i - 1][j]的值dp[i][j] = dp[i - 1][j]; // 判断当前目标和j是否大于等于第i个元素的值nums[i - 1](索引偏移,因为循环里i从1开始,对应nums里的索引是i - 1)// 并且在前i - 1个元素中已经能够凑出和为j - nums[i - 1]的情况(即dp[i - 1][j - nums[i - 1]]为true)if (j >= nums[i - 1] && dp[i - 1][j - nums[i - 1]]) // 如果满足上述条件,说明选了第i个元素后能凑出和为j,将dp[i][j]设为truedp[i][j] = true; }}// 最终返回在前n个元素中能否凑出目标和sum的结果,即dp[n][sum]的值,如果为true表示可以将数组分割成两个子集使得元素和相等,否则不行return dp[n][sum]; }
};
💛1049. 最后一块石头的重量 II
整体思路:
本题的核心思路是利用动态规划来解决类似于背包问题的优化场景,通过合理地划分石头,使得两堆石头的重量差值尽可能小,进而得到最后剩下石头的最小重量。关键在于将问题转化为求在一定容量限制下能装入的最大重量问题。
具体步骤:
- 计算石头总重量并确定目标容量:
首先通过循环遍历输入的石头重量数组stones,累加计算出所有石头的总重量sum。
然后将总重量sum除以 2 得到 t,这里把问题抽象成一个类似背包容量的概念,目标是从这些石头中选取一些石头,使其重量之和尽量接近 t,这样就能让两堆石头的重量尽可能均衡,最终剩下的石头重量最小。 - 初始化动态规划数组 dp:
创建一维整数数组 dp,长度为t + 1,并将所有元素初始化为0。dp[j]表示在容量为j的情况下(类比背包容量),所能装入的石头重量的最大值(即从石头中挑选部分石头组成的最大重量和)。 - 动态规划状态转移过程:
外层循环使用变量i 从 0 到 n - 1(n 为石头数组 stones 的元素个数),依次遍历每一块石头,考虑将每块石头放入 “背包” 的情况。
内层循环使用变量 j 从目标容量 t 开始,倒序遍历到当前石头的重量 stones[i]。倒序遍历是非常关键的一点,它保证了在计算 dp[j] 时,每个石头只会被考虑放入 “背包” 一次,避免了重复选取同一块石头的错误情况。
在每次内层循环中,对于dp[j]的更新,需要比较两种情况:一是不选当前这块石头,那么dp[j]的值保持之前的状态不变;二是选当前这块石头,此时它的值应该是在前容量为j - stones[i]时的最大重量dp[j - stones[i]]的基础上,再加上当前石头的重量stones[i],取这两种情况的最大值来更新dp[j]的值,即dp[j] = max(dp[j], dp[j - stones[i]] + stones[i])。 - 计算最后剩下石头的最小重量:
经过上述动态规划过程,dp[t]就表示在容量为 t 的情况下能装入的最大重量。由于我们希望两堆石头重量尽可能接近总重量的一半,所以最后剩下的石头重量可以通过总重量 sum 减去两倍的dp[t]来得到。如果总重量能被 2 整除且正好能平均分成两堆,那么结果就是 0;否则就得到了最后剩下那块石头的最小可能重量。
class Solution {
public:int lastStoneWeightII(vector<int>& stones) {// 获取石头数组的元素个数int n = stones.size(); int t = 0, sum = 0;// 计算所有石头的总重量for (auto& x : stones) sum += x; // 将总重量除以2,得到一个目标值t,这里的思路是把问题转化为尽量装满一个容量为t的“背包”// 目的是让分成的两堆石头重量尽可能接近,这样最后剩下的石头重量就最小t = sum / 2; // 创建动态规划数组dp,dp[j]表示在容量为j的情况下,能装入“背包”(这里可以理解为从石头中选取一些石头组成的重量和)的最大重量vector<int> dp(t + 1, 0); // 开始动态规划的状态转移过程,外层循环遍历每一块石头for (int i = 0; i < n; ++i) { // 内层循环从目标容量t开始,倒序遍历到当前石头的重量stones[i],倒序遍历是为了保证每个石头只被使用一次(避免重复使用同一块石头)for (int j = t; j >= stones[i]; --j) { // 对于dp[j],需要比较两种情况取最大值来更新其值:// 1. 不选当前这块石头,即维持之前dp[j]的值不变。// 2. 选当前这块石头,此时需要在前容量为j - stones[i]的最大重量基础上,加上当前石头的重量stones[i],即dp[j - stones[i]] + stones[i]。dp[j] = max(dp[j], dp[j - stones[i]] + stones[i]); }}// 根据前面的思路,将所有石头分成两堆,使得两堆重量尽可能接近总重量的一半t,那么最后剩下的石头重量就是总重量sum减去两倍的能装入容量为t的“背包”的最大重量dp[t]return sum - 2 * dp[t]; }
};
👥总结
本篇博文对 动态规划中01背包问题解析 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~

相关文章:
【算法】动态规划中01背包问题解析
📢博客主页:https://blog.csdn.net/2301_779549673 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! 📢本文由 JohnKi 原创,首发于 CSDN🙉 📢未来很长&#…...

选择WordPress和Shopify:搭建对谷歌SEO友好的网站
在建设网站时,不仅要考虑它的美观和功能性,还要关注它是否对谷歌SEO友好。如果你希望网站能够获得更好的搜索排名,WordPress和Shopify是两个值得推荐的建站平台。 WordPress作为最流行的内容管理系统,其强大的灵活性和丰富的插件…...

代理IP与生成式AI:携手共创未来
目录 代理IP:网络世界的“隐形斗篷” 1. 隐藏真实IP,保护隐私 2. 突破网络限制,访问更多资源 生成式AI:创意与效率的“超级大脑” 1. 提高创作效率 2. 个性化定制 代理IP与生成式AI的协同作用 1. 网络安全 2. 内容创作与…...

iOS 应用的生命周期
Managing your app’s life cycle | Apple Developer Documentation Performance and metrics | Apple Developer Documentation iOS 应用的生命周期状态是理解应用如何在不同状态下运行和管理资源的基础。在 iOS 开发中,应用生命周期管理的是应用从启动到终止的整…...

Elasticsearch 集群快照的定期备份设置指南
Elasticsearch 集群快照的定期备份设置指南 概述 快照: 在给定时刻对整个集群或者单个索引进行备份,以便在之后出现故障时可以基于之前备份的快照进行快速恢复。 前提条件: 准备一个备份存储盘,本指南采用的是AWS EFS文件系统做…...

Docker--Docker Image(镜像)
什么是Docker Image? Docker镜像(Docker Image)是Docker容器技术的核心组件之一,它包含了运行应用程序所需的所有依赖、库、代码、运行时环境以及配置文件等。 简单来说,Docker镜像是一个轻量级、可执行的软件包&…...

C++ 中的序列化和反序列化
一、C 中的序列化和反序列化 (一)基本概念 在 C 中,序列化是将对象转换为字节流的过程,反序列化则是从字节流重新构建对象的过程。这对于存储对象状态到文件、网络传输等场景非常有用。 (二)简单的序列化…...

我的Github学生认证申请过程
先说结论:很简单。 学生认证链接:GitHub Education GitHub 1. 首先你得绑定edu邮箱。这个应该没什么问题,Github也会提示。 2. 我是在学校里面、使用流量而非WiFi申请的,听说地理位置很重要,该给的权限(…...

信奥题解:勾股数计算中的浮点数精度问题
来源:GESP C++ 二级模拟题 本文给出官方参考答案的详细解析,包括每一部分的功能和关键点,以及与浮点数精度相关的问题的分析。 题目描述 勾股数是很有趣的数学概念。如果三个正整数a 、b 、c ,满足 a 2 + b 2 = c 2 a^2 + b^2 = c^2 a2+b2=c2 ,而且1 ≤ a ≤ b ≤ c ,…...

重生之我在学Vue--第2天 Vue 3 Composition API 与响应式系统
重生之我在学Vue–第2天 Vue 3 Composition API 与响应式系统 文章目录 重生之我在学Vue--第2天 Vue 3 Composition API 与响应式系统前言一、Composition API 核心概念1.1 什么是 Composition API?1.2 Composition API 的核心工具1.3 基础用法示例 二、响应式系统2…...

【AI知识】逻辑回归介绍+ 做二分类任务的实例(代码可视化)
1. 分类的基本概念 在机器学习的有监督学习中,分类一种常见任务,它的目标是将输入数据分类到预定的类别中。具体来说: 分类任务的常见应用: 垃圾邮件分类:判断一封电子邮件是否是垃圾邮件 。 医学诊断:…...

Mysql 笔记2 emp dept HRs
-- 注意事项 -- 1.给数据库和表起名字时尽量选择全小写 -- 2.作为筛选条件的字符串是否区分大小写看设置的校对规则utf8_bin 区分 drop database if exists hrs; create database hrs default charset utf8 collate utf8_general_ci;use hrs; drop table if exists tb_emp; dro…...

MySQL和Oracle的区别
MySQL和Oracle的区别 MySQL是轻量型数据库,并且免费,没有服务恢复数据。 Oracle是重量型数据库,收费,Oracle公司对Oracle数据库有任何服务。 1.对事务的提交 MySQL默认是自动提交,而Oracle默认不自动提交࿰…...

实验12 C语言连接和操作MySQL数据库
一、安装MySQL 1、使用包管理器安装MySQL sudo apt update sudo apt install mysql-server2、启动MySQL服务: sudo systemctl start mysql3、检查MySQL服务状态: sudo systemctl status mysql二、安装MySQL开发库 sudo apt-get install libmysqlcli…...

09篇--图片的水印添加(掩膜的运用)
如何添加水印? 添加水印其实可以理解为将一张图片中的某个物体或者图案提取出来,然后叠加到另一张图片上。具体的操作思想是通过将原始图片转换成灰度图,并进行二值化处理,去除背景部分,得到一个类似掩膜的图像。然后…...

sql-labs(21-25)
第21关 第一步 可以发现cookie是经过64位加密的 我们试试在这里注入 选择给他编码 发现可以成功注入 爆出表名 爆出字段 爆出数据 第22关 跟二十一关一模一样 闭合换成" 第 23 关 第二十三关重新回到get请求,会发现输入单引号报错,但是注释符…...
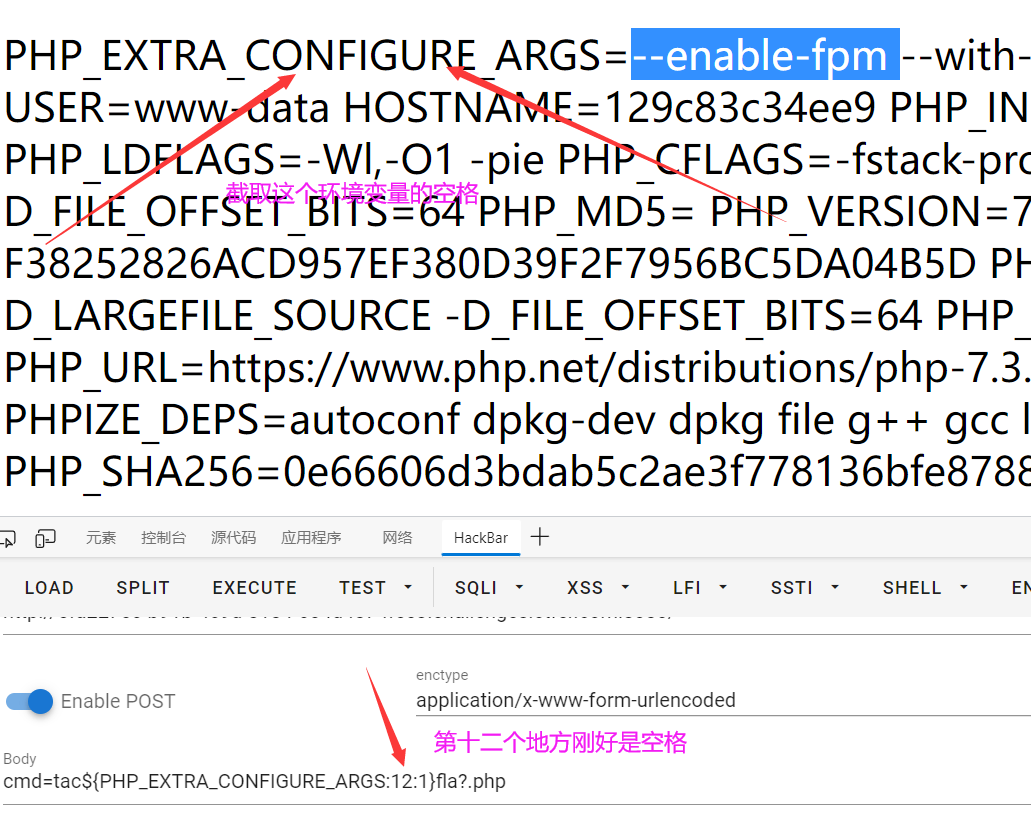
CTF知识集-命令执行
CTF知识集-命令执行 写在开头可能会用到的提醒 ;可以用%0a来替换 是shell_exec的缩写 ls | tee 1 把ls的输出内容存入1这个文件 shell查看文件的几种方式,tac | more | less | tail | sort | tac | cat | head | od | expand 针对flag 可以用grep { flag.php来…...

基于米尔全志T527开发板的OpenCV进行手势识别方案
本文将介绍基于米尔电子MYD-LT527开发板(米尔基于全志T527开发板)的OpenCV手势识别方案测试。 摘自优秀创作者-小火苗 米尔基于全志T527开发板 一、软件环境安装 1.安装OpenCV sudo apt-get install libopencv-dev python3-opencv 2.安装pip sudo apt…...
、get请求)
Htpp中web通讯发送post(上传文件)、get请求
一、正常发送post请求 1、引入pom文件 <dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5</version></dependency>2、这个是发送至正常的post、get请求 import org…...

【论文阅读笔记】HunyuanVideo: A Systematic Framework For Large Video Generative Models
HunyuanVideo: A Systematic Framework For Large Video Generative Models 前言引言Overview数据预处理数据过滤数据注释 模型架构设计3D Variational Auto-encoder Designtraininginference 统一的图像和视频生成架构Text encoderModel ScalingImage model scaling lawvideo …...

KityMinder:可视化思维的协作引擎 | 高效工作者必备工具
KityMinder:可视化思维的协作引擎 | 高效工作者必备工具 【免费下载链接】kityminder 百度脑图 项目地址: https://gitcode.com/gh_mirrors/ki/kityminder 在信息爆炸的时代,如何将零散的想法系统化、复杂的项目结构化?作为一款开源免…...

Zotero Actions Tags:自动化文献管理,告别手动标签整理
Zotero Actions & Tags:自动化文献管理,告别手动标签整理 【免费下载链接】zotero-actions-tags Customize your Zotero workflow. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-actions-tags 你是否还在为Zotero文献库中杂乱无章的标…...

终极指南:免费开源fSpy相机匹配工具,3分钟实现2D图像到3D场景的完美转换
终极指南:免费开源fSpy相机匹配工具,3分钟实现2D图像到3D场景的完美转换 【免费下载链接】fSpy A cross platform app for quick and easy still image camera matching 项目地址: https://gitcode.com/gh_mirrors/fs/fSpy 还在为将2D照片转换为精…...

如何高效使用Zettlr:开源写作工具的实用配置与技巧指南
如何高效使用Zettlr:开源写作工具的实用配置与技巧指南 【免费下载链接】Zettlr Your One-Stop Publication Workbench 项目地址: https://gitcode.com/GitHub_Trending/ze/Zettlr 还在为学术写作和知识管理寻找一个功能全面、界面简洁的跨平台工具吗&#x…...

AUTOSAR NM实战避坑:从CANoe仿真到实车调试,搞定ECU异常唤醒与睡眠失败
AUTOSAR NM实战避坑指南:从仿真到实车的异常唤醒与睡眠失败解决方案 当ECU在深夜本该沉睡时突然"睁眼",消耗的不仅是电量,更是工程师的睡眠时间。这种场景在AUTOSAR网络管理(NM)开发中屡见不鲜——某个节点异…...

m4s-converter:打破B站缓存限制,永久保存珍贵视频内容
m4s-converter:打破B站缓存限制,永久保存珍贵视频内容 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容时代&am…...

利用kimi与快马平台,十分钟搭建个人博客web应用原型
最近想快速验证一个个人博客的创意,但自己从头写代码太费时间。尝试用InsCode(快马)平台的Kimi模型生成原型,没想到十分钟就搞定了可运行的Web应用,分享下这个高效流程: 明确需求梳理结构 先花2分钟在纸上画了博客的基本框架&…...

3个核心模块揭秘:Python量化投资如何免费获取通达信专业数据
3个核心模块揭秘:Python量化投资如何免费获取通达信专业数据 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 你是否在量化投资中为数据获取而烦恼?商业接口太贵,…...

从零开始:使用ecCodes库高效解析GRIB文件
1. 为什么需要ecCodes库处理GRIB文件 第一次接触气象数据时,我被GRIB文件搞得一头雾水。这种二进制格式就像个黑盒子,明明知道里面装着宝贵的温度、气压、风速数据,却不知道怎么取出来。后来发现ecCodes库就像开罐器,能轻松打开这…...

Awoo Installer深度解析:破解Switch游戏安装困境的全能工具
Awoo Installer深度解析:破解Switch游戏安装困境的全能工具 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 在Nintendo Switch破解社区…...