【图像分类实用脚本】数据可视化以及高数量类别截断
图像分类时,如果某个类别或者某些类别的数量远大于其他类别的话,模型在计算的时候,更倾向于拟合数量更多的类别;因此,观察类别数量以及对数据量多的类别进行截断是很有必要的。
1.准备数据
数据的格式为图像分类数据集格式,根目录下分为train和val文件夹,每个文件夹下以类别名命名的子文件夹:
.
├── ./datasets
│ ├── ./datasets/train/A
│ │ ├── ./datasets/train/A/1.jpg
│ │ ├── ./datasets/train/A/2.jpg
│ │ ├── ./datasets/train/A/3.jpg
│ │ ├── …
│ ├── ./datasets/train/B
│ │ ├── ./datasets/train/B/1.jpg
│ │ ├── ./datasets/train/B/1.jpg
│ │ ├── ./datasets/train/B/1.jpg
│ │ ├── …
│ ├── ./datasets/val/A
│ │ ├── ./datasets/val/A/1.jpg
│ │ ├── ./datasets/val/A/2.jpg
│ │ ├── ./datasets/val/A/3.jpg
│ │ ├── …
│ ├── ./datasets/val/B
│ │ ├── ./datasets/val/B/1.jpg
│ │ ├── ./datasets/val/B/1.jpg
│ │ ├── ./datasets/val/B/1.jpg
│ │ ├── …
2.查看数据分布
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pddef count_images(directory, image_extensions):"""统计每个子文件夹中的图像数量。:param directory: 主目录路径(train或val):param image_extensions: 允许的图像文件扩展名元组:return: 一个字典,键为类别名,值为图像数量"""counts = {}if not os.path.exists(directory):print(f"目录不存在: {directory}")return countsfor class_name in os.listdir(directory):class_path = os.path.join(directory, class_name)if os.path.isdir(class_path):# 统计符合扩展名的文件数量image_count = sum(1 for file in os.listdir(class_path)if file.lower().endswith(image_extensions))counts[class_name] = image_countreturn countsdef count_images_in_single_directory(directory, image_extensions):"""统计单个目录下每个类别的图像数量。:param directory: 主目录路径:param image_extensions: 允许的图像文件扩展名元组:return: 一个字典,键为类别名,值为图像数量"""counts = {}if not os.path.exists(directory):print(f"目录不存在: {directory}")return countsfor class_name in os.listdir(directory):class_path = os.path.join(directory, class_name)if os.path.isdir(class_path):image_count = sum(1 for file in os.listdir(class_path)if file.lower().endswith(image_extensions))counts[class_name] = image_countreturn countsdef autolabel(ax, rects):"""在每个柱状图上方添加数值标签。:param ax: Matplotlib 的轴对象:param rects: 柱状图对象"""for rect in rects:height = rect.get_height()ax.annotate(f'{height}',xy=(rect.get_x() + rect.get_width() / 2, height),xytext=(0, 3), # 3 points vertical offsettextcoords="offset points",ha='center', va='bottom')def plot_distribution(all_classes, train_values, val_values, output_path, has_val=False):"""绘制并保存训练集和验证集中每个类别的图像数量分布柱状图。如果没有验证集数据,则只绘制训练集数据。:param all_classes: 所有类别名称列表:param train_values: 训练集中每个类别的图像数量列表:param val_values: 验证集中每个类别的图像数量列表(如果有的话):param output_path: 保存图表的文件路径:param has_val: 是否包含验证集数据"""x = np.arange(len(all_classes)) # 类别位置width = 0.35 # 柱状图的宽度fig, ax = plt.subplots(figsize=(12, 8))if has_val:rects1 = ax.bar(x - width/2, train_values, width, label='Train')rects2 = ax.bar(x + width/2, val_values, width, label='Validation')else:rects1 = ax.bar(x, train_values, width, label='Count')# 添加一些文本标签ax.set_xlabel('Category')ax.set_ylabel('Number of Images')title = 'Number of Images in Each Category for Train and Validation' if has_val else 'Number of Images in Each Category'ax.set_title(title)ax.set_xticks(x)ax.set_xticklabels(all_classes, rotation=45, ha='right')ax.legend() if has_val else ax.legend(['Count'])# 自动标注柱状图上的数值autolabel(ax, rects1)if has_val:autolabel(ax, rects2)fig.tight_layout()# 保存图表为图片文件plt.savefig(output_path, dpi=300, bbox_inches='tight')print(f"图表已保存到 {output_path}")def compute_and_display_statistics(counts_dict, dataset_name, save_csv=False):"""计算并展示统计数据,包括总图像数量、类别数量、平均每个类别的图像数量和类别占比。:param counts_dict: 类别名称与图像数量的字典:param dataset_name: 数据集名称(例如 'Train', 'Validation', 'Dataset'):param save_csv: 是否保存统计结果为 CSV 文件"""total_images = sum(counts_dict.values())num_classes = len(counts_dict)avg_per_class = total_images / num_classes if num_classes > 0 else 0# 计算每个类别的占比category_proportions = {cls: (count / total_images * 100) if total_images > 0 else 0 for cls, count in counts_dict.items()}# 创建 DataFramedf = pd.DataFrame({'类别名称': list(counts_dict.keys()),'图像数量': list(counts_dict.values()),'占比 (%)': [f"{prop:.2f}" for prop in category_proportions.values()]})# 排序 DataFrame 按图像数量降序df = df.sort_values(by='图像数量', ascending=False)print(f"\n===== {dataset_name} 数据统计 =====")print(df.to_string(index=False))print(f"总图像数量: {total_images}")print(f"类别数量: {num_classes}")print(f"平均每个类别的图像数量: {avg_per_class:.2f}")# 根据 save_csv 参数决定是否保存为 CSV 文件if save_csv:# 将数据集名称转换为小写并去除空格,以作为文件名的一部分sanitized_name = dataset_name.lower().replace(" ", "_").replace("(", "").replace(")", "")csv_filename = f"{sanitized_name}_statistics.csv"df.to_csv(csv_filename, index=False, encoding='utf-8-sig')print(f"统计表已保存为 {csv_filename}\n")def main():# ================== 配置参数 ==================# 设置数据集的根目录路径dataset_root = 'datasets/device_cls_merge_manual_with_21w_1218' # 替换为你的数据集路径# 定义train和val目录train_dir = os.path.join(dataset_root, 'train')val_dir = os.path.join(dataset_root, 'val')# 定义允许的图像文件扩展名image_extensions = ('.jpg', '.jpeg', '.png', '.bmp', '.gif')# 输出图表的路径output_path = 'dataset_distribution.png' # 你可以更改为你想要的文件名和路径# 是否保存统计结果为 CSV 文件(默认不保存)SAVE_CSV = False # 设置为 True 以启用保存 CSV# ================== 统计图像数量 ==================has_train = os.path.exists(train_dir) and os.path.isdir(train_dir)has_val = os.path.exists(val_dir) and os.path.isdir(val_dir)if has_train and has_val:print("检测到 'train' 和 'val' 目录。统计训练集和验证集中的图像数量...")train_counts = count_images(train_dir, image_extensions)val_counts = count_images(val_dir, image_extensions)# 获取所有类别的名称(确保train和val中的类别一致)all_classes = sorted(list(set(train_counts.keys()) | set(val_counts.keys())))# 准备绘图数据train_values = [train_counts.get(cls, 0) for cls in all_classes]val_values = [val_counts.get(cls, 0) for cls in all_classes]# ================== 计算并展示统计数据 ==================compute_and_display_statistics(train_counts, '训练集 (Train)', save_csv=SAVE_CSV)compute_and_display_statistics(val_counts, '验证集 (Validation)', save_csv=SAVE_CSV)# ================== 绘制并保存图表 ==================print("绘制并保存训练集和验证集的图表...")plot_distribution(all_classes, train_values, val_values, output_path, has_val=True)else:print("未检测到 'train' 和 'val' 目录。将统计主目录下的图像数量...")# 如果没有train和val目录,则统计主目录下的图像分布main_counts = count_images_in_single_directory(dataset_root, image_extensions)# 获取所有类别的名称all_classes = sorted(main_counts.keys())# 准备绘图数据main_values = [main_counts.get(cls, 0) for cls in all_classes]# 定义输出图表路径(可以区分不同的输出文件名)output_path_single = 'dataset_distribution_single.png' # 或者使用与train_val相同的output_path# ================== 计算并展示统计数据 ==================compute_and_display_statistics(main_counts, '数据集 (Dataset)', save_csv=SAVE_CSV)# ================== 绘制并保存图表 ==================print("绘制并保存主目录的图表...")plot_distribution(all_classes, main_values, [], output_path_single, has_val=False)if __name__ == "__main__":main()
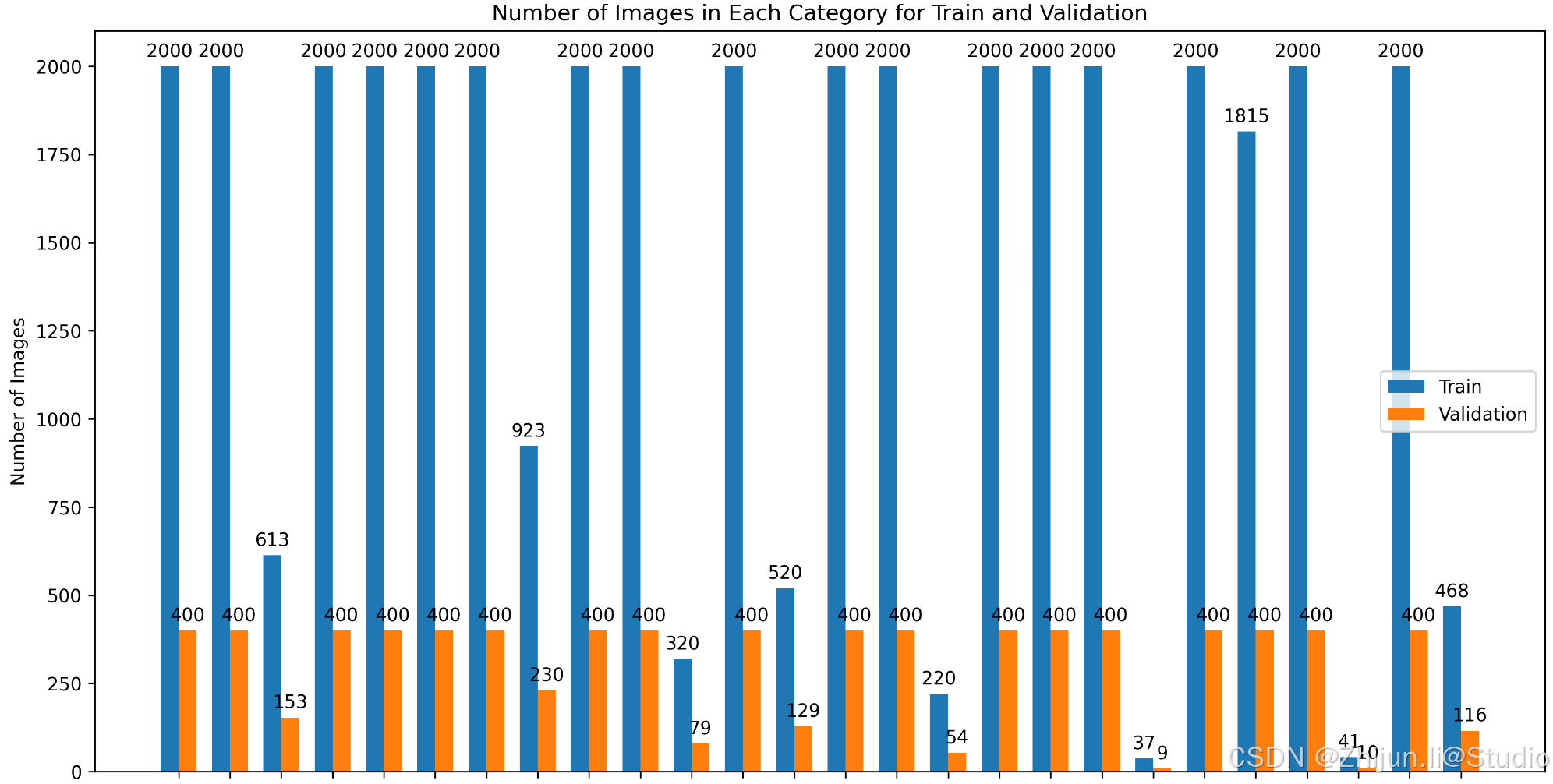
下图为原始数据集运行结果,可以看到数据存在严重不均衡问题

3.数据截断
import os
import shutil
import randomdef count_images(directory, image_extensions):"""统计每个子文件夹中的图像文件路径列表。:param directory: 主目录路径(train或val):param image_extensions: 允许的图像文件扩展名列表:return: 一个字典,键为类别名,值为图像文件路径列表"""counts = {}if not os.path.exists(directory):print(f"目录不存在: {directory}")return countsfor class_name in os.listdir(directory):class_path = os.path.join(directory, class_name)if os.path.isdir(class_path):# 获取符合扩展名的文件列表images = [file for file in os.listdir(class_path)if file.lower().endswith(tuple(image_extensions))]image_paths = [os.path.join(class_path, img) for img in images]counts[class_name] = image_pathsreturn countsdef truncate_dataset(class_images, threshold, seed=42):"""对每个类别的图像进行截断,如果超过阈值则随机选择一定数量的图像。:param class_images: 一个字典,键为类别名,值为图像文件路径列表:param threshold: 每个类别的图像数量阈值:param seed: 随机种子:return: 截断后的类别图像字典"""truncated = {}random.seed(seed)for class_name, images in class_images.items():if len(images) > threshold:truncated_images = random.sample(images, threshold)truncated[class_name] = truncated_imagesprint(f"类别 '{class_name}' 超过阈值 {threshold},已随机选择 {threshold} 张图像。")else:truncated[class_name] = imagesprint(f"类别 '{class_name}' 不超过阈值 {threshold},保留所有 {len(images)} 张图像。")return truncateddef copy_images(truncated_data, subset, output_root):"""将截断后的图像复制到输出目录,保持原有的目录结构。:param truncated_data: 截断后的类别图像字典:param subset: 'train' 或 'val':param output_root: 输出根目录路径"""for class_name, images in truncated_data.items():dest_dir = os.path.join(output_root, subset, class_name)os.makedirs(dest_dir, exist_ok=True)for img_path in images:img_name = os.path.basename(img_path)dest_path = os.path.join(dest_dir, img_name)shutil.copy2(img_path, dest_path)print(f"'{subset}' 子集已复制到 {output_root}")def main():"""主函数,执行数据集截断和复制操作。"""# ================== 配置参数 ==================# 原始数据集根目录路径input_dir = 'datasets/device_cls_merge_manual_with_21w_1218_train_val_224' # 替换为你的原始数据集路径# 截断后数据集的输出根目录路径output_dir = 'datasets/device_cls_merge_manual_with_21w_1218_train_val_224_truncate' # 替换为你希望保存截断后数据集的路径# 训练集每个类别的图像数量阈值train_threshold = 2000 # 设置为你需要的训练集阈值# 验证集每个类别的图像数量阈值val_threshold = 400 # 设置为你需要的验证集阈值# 允许的图像文件扩展名image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff']# 随机种子以确保可重复性random_seed = 42# ================== 脚本实现 ==================# 设置随机种子random.seed(random_seed)# 定义train和val目录路径train_input_dir = os.path.join(input_dir, 'train')val_input_dir = os.path.join(input_dir, 'val')# 统计train和val中的图像print("统计训练集中的图像数量...")train_counts = count_images(train_input_dir, image_extensions)print("统计验证集中的图像数量...")val_counts = count_images(val_input_dir, image_extensions)# 截断train和val中的图像print("\n截断训练集中的图像...")truncated_train = truncate_dataset(train_counts, train_threshold, random_seed)print("\n截断验证集中的图像...")truncated_val = truncate_dataset(val_counts, val_threshold, random_seed)# 复制截断后的图像到输出目录print("\n复制截断后的训练集图像...")copy_images(truncated_train, 'train', output_dir)print("复制截断后的验证集图像...")copy_images(truncated_val, 'val', output_dir)print("\n数据集截断完成。")if __name__ == "__main__":main()
再次查看已经符合截断后的数据分布了
相关文章:
【图像分类实用脚本】数据可视化以及高数量类别截断
图像分类时,如果某个类别或者某些类别的数量远大于其他类别的话,模型在计算的时候,更倾向于拟合数量更多的类别;因此,观察类别数量以及对数据量多的类别进行截断是很有必要的。 1.准备数据 数据的格式为图像分类数据集…...

python的is和==运算符
在py中,有两个特别的运算符,is和分别用来判断两个变量是不是相同的和两个变量的值是不是相同。 1. is运算符:用来比较两个对象的身份,即判断两个变量是否指向内存中的同一个对象。 应用场景:1)单例模式&a…...
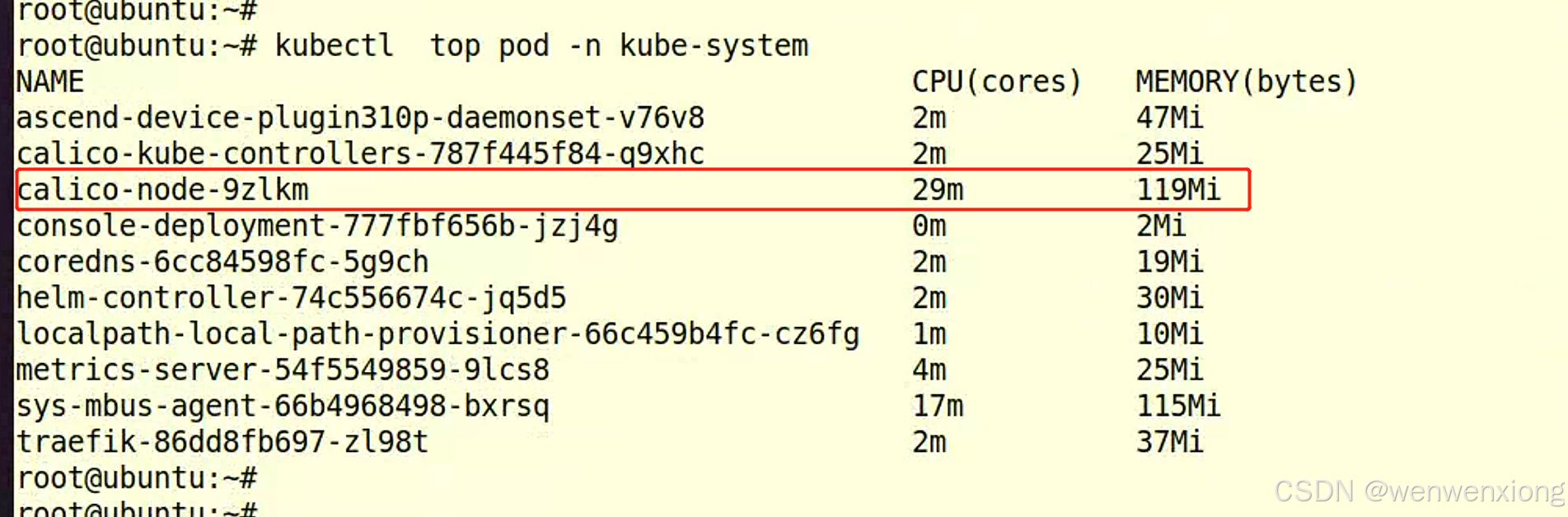
单节点calico性能优化
在单节点上部署calicov3273后,发现资源占用 修改calico以下配置是资源消耗降低 1、因为是单节点,没有跨节点pod网段组网需要,禁用overlay方式网络(ipip,vxlan),使用route方式网络 配置calico-node的环境变量 CALICO_IPV4POOL_I…...

React 19有哪些新特性?
写在前面 2024.12.5,React 团队在 react.dev/blog 上发表了帖子 react.dev/blog/2024/1… React 19 正式进入了 stable 状态 React 团队介绍了一些新的特性和 Breaking Changes,并提供了升级指南, React 19: 新更新、新特性和新Hooks Reac…...

视频生成缩略图
文章目录 视频生成缩略图使用ffmpeg 视频生成缩略图 最近有个需求,视频上传之后在列表和详情页需要展示缩略图 使用ffmpeg 首先引入jar包 <dependency><groupId>org.bytedeco</groupId><artifactId>javacpp</artifactId><vers…...

页面无滚动条,里面div各自有滚动条
一、双滚动条左右布局 实现效果 实现代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Doc…...

DIY-ESP8266移动PM2.5传感器-带屏幕-APP
本教程将指导您制作一台专业级的空气质量检测仪。这个项目使用经济实惠的ESP8266和PMS5003传感器,配合OLED显示屏,不仅能实时显示PM2.5数值,还能通过手机APP随时查看数据。总成本70元,相比几百的用的便宜,用的心理踏实…...
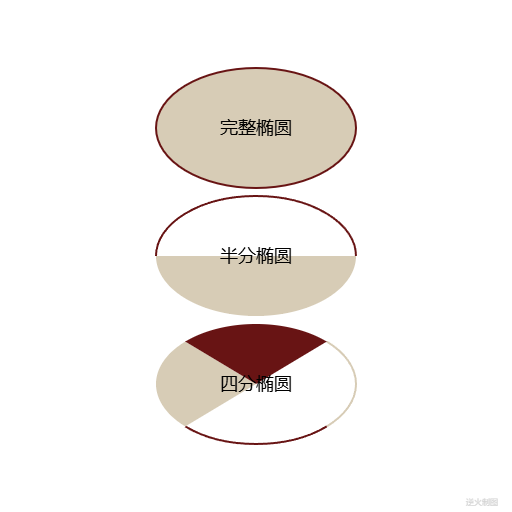
【Canvas与技法】椭圆画法
【成图】 【代码】 <!DOCTYPE html> <html lang"utf-8"> <meta http-equiv"Content-Type" content"text/html; charsetutf-8"/> <head><title>椭圆的画法 Draft2</title><style type"text/css&quo…...

多核CPU调度是咋搞的?
其实很多情况下都有 这样的疑问 为什么多核CPU用着用着会“躺平”? 为什么手机有 8 核,跑分时性能却不是核心数的翻倍? 答案的钥匙,就藏在多核CPU的调度机制里。 为了更直观地理解,以一个《王者荣耀》游戏服务器为例…...

【Jenkins】pipeline 的基础语法以及快速构建一个 jenkinsfile
Jenkins Pipeline 是 Jenkins 中的一个强大功能,可以帮助你实现自动化构建、测试、部署等流程。Jenkins Pipeline 使用一种名为 Pipeline DSL(Domain Specific Language)的脚本语言,通常以 Jenkinsfile 形式存在,用于定…...

工作中如何提高技术实力?
点击“硬核王同学”,选择“关注/三连” 福利干货第一时间送达 大家好,我是硬核王同学。 其实这个问题困扰了我很久啊,不知道你们有没有跟我一样。 如何在工作中如何提高技术实力? 随着时间的增加,越来越觉得工作上…...

画图,matlab,
clear;close all;clc;tic;dirOutput dir(*.dat); % 罗列所有后缀-1.dat的文件列表,罗列BDDATA的数据 filenames string({dirOutput.name}); % 提取文件名%% 丢包统计 FILENAMES [""]; LOSS_YTJ [ ]; LOSS_RAD [ ]; LOSS_ETH [ ]…...
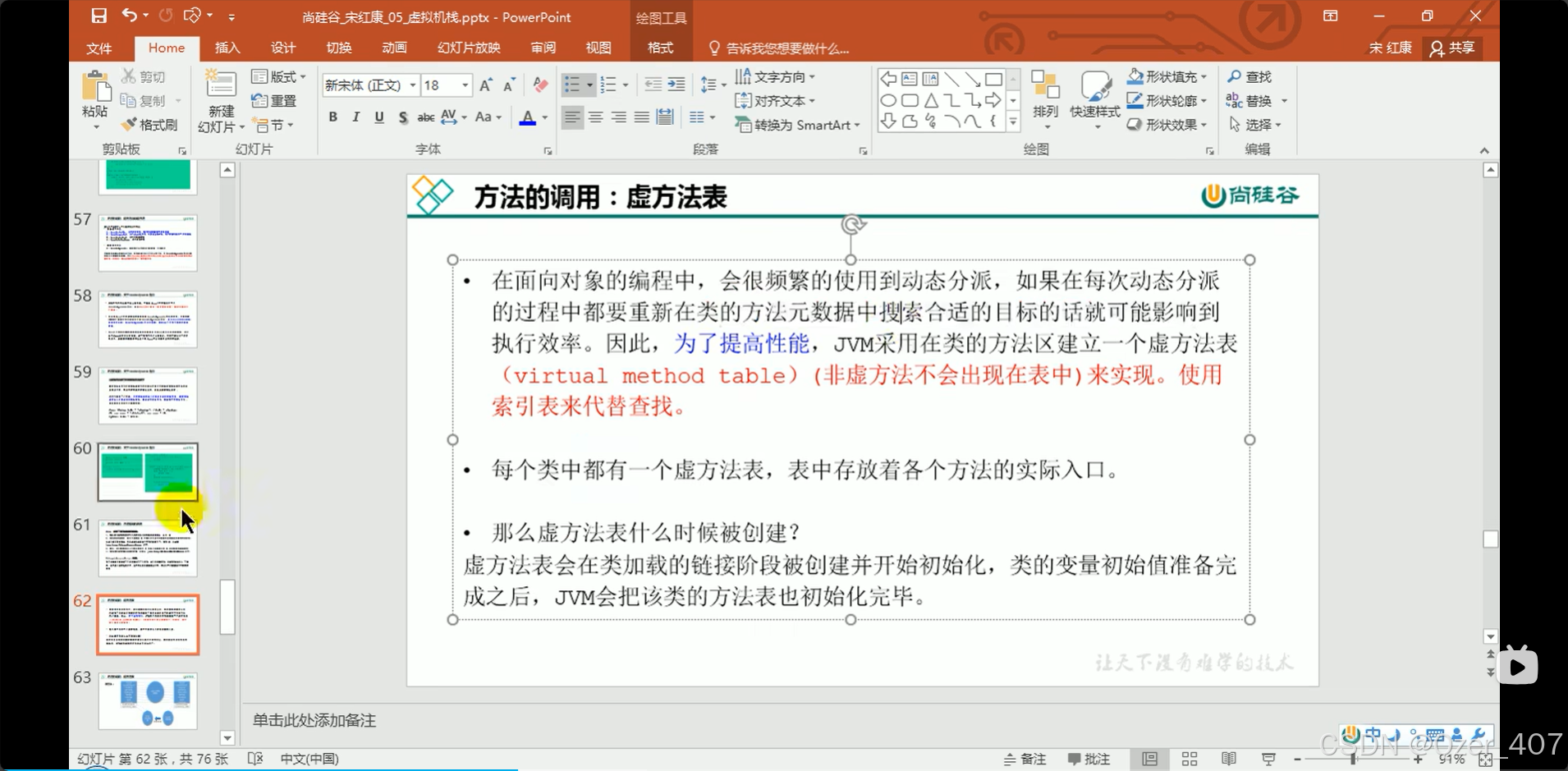
Java虚拟机类加载(解析阶段)[虚方法表的生成以及其存在意义]
class字节码文件中的常量池结构详解-CSDN博客Java虚拟机类加载(解析阶段)-CSDN博客...
电子元器件与电路之-MOS管的介绍和作用
一、基本概念 MOS 管,或MOSFET,全称是Metal-Oxide-Semiconductor Field-Effect Transistor(金属 - 氧化物 - 半导体场效应晶体管)。和三极管利用电流控制电流不同,它是一种利用电场效应来控制电流的半导体器件。和三级…...

python实现word转html
目录 使用mammoth库 使用spire.doc库 使用mammoth库 mammoth库支持将word转为HTML和markdown格式的文件。 import mammothdef word_html(word_file):html_save_name fr{word_file.split(.)[0]}.htmlwith open(word_file, rb) as f:data mammoth.convert_to_html(f)with o…...

nginx模块ngx-fancyindex 隐藏标题中的 / 和遇到的坑
首先下载nginx源码,编译时加上 --add-module/usr/local/src/ngx-fancyindex/ 例如 : ./configure --prefix/usr/local/nginx --with-select_module --with-poll_module --with-threads --with-file-aio --with-http_ssl_module --with-http_v2_module…...
LSTM与GRU)
第二十四天 循环神经网络(RNN)LSTM与GRU
LSTM(长短期记忆网络)和GRU(门控循环单元)是两种流行的循环神经网络变体,它们被设计来解决传统RNN在处理长序列数据时遇到的梯度消失和梯度爆炸问题。这两种网络都通过引入门控机制来控制信息的流动,从而能…...

RocketMQ如何保证消息顺序?
大家好,我是锋哥。今天分享关于【RocketMQ如何保证消息顺序?】面试题。希望对大家有帮助; RocketMQ如何保证消息顺序? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 RocketMQ 作为一个分布式消息中间件,提供了高吞吐、低延迟的…...

LabVIEW实现GSM/GPRS通信
目录 1、GSM/GPRS通信原理 2、硬件环境部署 3、程序架构 4、前面板设计 5、程序框图设计 6、测试验证 本专栏以LabVIEW为开发平台,讲解物联网通信组网原理与开发方法,覆盖RS232、TCP、MQTT、蓝牙、Wi-Fi、NB-IoT等协议。 结合实际案例,展示如何利用LabVIEW和常用模块实现物联…...

关于如何做技术文档
在技术的浩瀚海洋中,一份优秀的技术文档宛如精准的航海图。它是知识传承的载体,是团队协作的桥梁,更是产品成功的幕后英雄。然而,打造这样一份出色的技术文档并非易事。你是否在为如何清晰阐释复杂技术而苦恼?是否纠结…...

MPLAB Harmony 2.0固件框架:从MISRA-C合规到图形化开发的嵌入式开发新范式
1. 项目概述:为什么我们需要一个“全功能”的固件框架?如果你和我一样,在PIC32单片机的世界里摸爬滚打过几年,肯定经历过这样的场景:项目启动,面对Microchip提供的海量外设库、驱动代码和中间件,…...

苏峻:一个“产品偏执狂”的20年跨界史,从讲台到造车,他到底在疯什么?icar
苏峻:一个“产品偏执狂”的20年跨界史,从讲台到造车,他到底在疯什么?一个50岁的清华大学设计学博士,当过15年大学老师,做过空气净化器,卖过200万台,现在又跑去造车。有人说他是疯子&…...

LT6110远程电压补偿技术原理与应用
1. 远程负载电压补偿技术解析在工业自动化、数据中心等分布式供电系统中,工程师们经常面临一个经典难题:当电源与负载之间存在较长距离时,导线电阻导致的电压下降会显著影响负载端的供电质量。这种现象的本质是欧姆定律(VIR&#…...

嵌入式以太网模块WIZ5500应用指南:从SPI接口到物联网稳定连接
1. 项目概述:为什么你的物联网项目需要一个有线网络“锚点”无线网络(Wi-Fi)确实方便,但做过几个实际项目的朋友都知道,它的“方便”有时是建立在“不确定性”之上的。信号波动、信道拥堵、复杂的认证流程,…...

Cursor编辑器深度美化:CSS注入与动态特效实现全解析
1. 项目概述:当代码编辑器拥有了“皮肤”与“特效”如果你和我一样,每天有超过8小时的时间是在代码编辑器里度过的,那么你一定理解一个顺眼、顺手、甚至有点“酷”的编辑环境意味着什么。它不仅仅是生产力的工具,更是我们开发者思…...
从零实现大语言模型:Transformer架构、自注意力机制与PyTorch实战
1. 项目概述:从零构建大语言模型的实践指南 最近几年,大语言模型(LLM)无疑是技术领域最耀眼的存在。从ChatGPT的横空出世到各类开源模型的百花齐放,它们展现出的理解和生成能力令人惊叹。然而,对于许多开发…...

在OpenClaw中快速接入Taotoken实现AI助手功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中快速接入Taotoken实现AI助手功能 OpenClaw是一款功能强大的AI助手工具,能够帮助开发者进行代码生成、问题…...

网络出口IP管理工具ipman:原理、使用与实战指南
1. 项目概述与核心价值最近在折腾网络工具和代理配置时,发现了一个挺有意思的开源项目,叫twisker/ipman。乍一看这个名字,可能会联想到IP地址管理,但实际上,它的定位更偏向于一个轻量级的、用于在特定网络环境下管理和…...

对比直接购买与使用Taotoken Token Plan套餐的成本控制体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买与使用Taotoken Token Plan套餐的成本控制体验 1. 引言:个人开发者的成本困惑 作为个人开发者࿰…...

STM32F407 CCMRAM实战:释放LVGL图形库的RAM压力
1. 为什么需要CCMRAM优化LVGL性能 第一次用STM32F407做带屏项目时,我被RAM不足的问题折腾得够呛。当时用LVGL显示320x240的界面,刚加上第二个页面就频繁出现HardFault。用CubeMX生成的默认内存配置,128KB的RAM被各种变量瓜分后,留…...