Hadoop、Hbase使用Snappy压缩
1. 前期准备
系统环境:centos7.9
配置信息:8C8G100G
hadoop和hbase为单节点部署模式
jdk版本jdk1.8.0_361
1.1. 修改系统时间
timedatectl set-timezone <TimeZone>
1.2. 修改主机名以及主机名和IP的映射
vim /etc/hosts
#将自己的主机名以及ip映射添加进去
1.3. 关闭防火墙
临时关闭防火墙
systemctl stop firewalld.service
永久关闭
systemctl disable firewalld.service
2. hadoop部署
2.1. 下载安装包
mkdir /u01
cd /u01
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
tar -zxvf hadoop-3.3.6.tar.gz
2.2. 修改配置文件
2.2.1. 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.68.129:9000</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/u01/hadoop-3.3.6/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
</configuration>
2.2.2. 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/u01/hadoop-3.3.6/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/u01/hadoop-3.3.6/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>192.168.68.129:50070</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2.2.3. 修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.2.4. 修改hadoop-env.sh
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
export HADOOP_MAPRED_HOME=/u01/hadoop-3.3.6
export HDFS_NAMENODE_USER=hadoop:
设置NameNode进程以hadoop用户身份运行。NameNode是HDFS中的主节点,负责管理文件系统的命名空间和客户端对文件的访问。
export HDFS_DATANODE_USER=hadoop:
设置DataNode进程以hadoop用户身份运行。DataNode是HDFS中的从节点,负责存储实际的数据块,并执行读写操作。
export HDFS_SECONDARYNAMENODE_USER=hadoop:
设置Secondary NameNode进程以hadoop用户身份运行。Secondary NameNode不是NameNode的备份,而是辅助NameNode进行检查点操作,帮助保持NameNode的运行状态。
export YARN_RESOURCEMANAGER_USER=hadoop:
设置ResourceManager进程以hadoop用户身份运行。ResourceManager是YARN的一部分,负责整个集群的资源管理和分配。
export YARN_NODEMANAGER_USER=hadoop:
设置NodeManager进程以hadoop用户身份运行。NodeManager是YARN的一部分,负责单个节点上的资源管理以及容器的生命周期管理。
export HADOOP_MAPRED_HOME=/u01/hadoop-3.3.6:
指定MapReduce框架的安装目录。这通常指向Hadoop发行版的根目录,在这个例子中是/u01/hadoop-3.3.6。
2.2.5. 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/u01/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/u01/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/u01/hadoop-3.3.6</value>
</property>
<!-- 这个参数设为true启用压缩 -->
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<!-- 使用编解码器 -->
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
</configuration>
2.2.6. 修改环境变量
vim /etc/profile
export HADOOP_HOME=/u01/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.3. 启动hadoop服务
2.3.1. 格式化namenode
hdfs namenode -format
2.3.2. 启动服务
./sbin/start-all.sh
启动成功后,使用jps命令查看服务
显示有NameNode、DataNode、SecondaryNameNode、ResourceManager、NodeManager这5个服务
则为启动成功
查看hdfs和yarn的web界面,端口分别是50070和8088
2.4. 验证snappy压缩
验证方法:运行Hadoop的hadoop-mapreduce-examples-3.3.6.jar测试包进行wordcount,查看生成的文件大小
创建一个文件,input,键入以下内容或其它内容,把这个文件上传到hdfs,当然也可以使用本地文件
jakchquihfquhdqwhcn9eiuhcf198fh8chquihfquhdqwhcwqhdb9uchquihfquhdqwhch91ugh2ufgb92ufb2ufsfcd
2.4.1. 未开启压缩
把mapred-site.xml和core-site.xml相关的snappy配置去掉,重启hadoop服务,执行以下命令行
./bin/hadoop jar /u01/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /u01/input /u01/output-n
查看生成的文件大小,验证结果
2.4.2. 开启压缩
执行以下命令行
./bin/hadoop jar /u01/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /u01/input /u01/output-y4
查看生成的文件大小,验证结果
3. hbase部署
3.1. 下载安装包
cd /u01
wget https://dlcdn.apache.org/hbase/2.6.1/hbase-2.6.1-bin.tar.gz
tar -zxvf hbase-2.6.1-bin.tar.gz
cd hbase-2.6.1
3.2. 修改配置文件
3.2.1. 修改hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master2:9000/hbase</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/u01/hbase-2.6.1/tmp</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.io.compress.snappy.codec</name>
<value>org.apache.hadoop.hbase.io.compress.xerial.SnappyCodec</value>
</property>
</configuration>
3.2.2. 修改hbase-env.xml
如果启动出现SLF4J: Found binding in [jar:file:/u01/hbase-2.6.1/lib/client-facing-thirdparty/log4j-slf4j-impl-2.17.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
则添加以下配置
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true 这个命令的作用是设置环境变量 HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP 为 true。这意味着在启动 HBase 时,将禁用 Hadoop 类路径查找功能。
通常情况下,HBase 在启动时会尝试查找 Hadoop 的类路径,以便能够与 Hadoop 集成。但是,在某些环境中,例如在不使用 Hadoop 或者希望使用自定义配置的情况下,禁用这个功能是有意义的。通过设置此环境变量为 true,可以避免 HBase 自动查找 Hadoop 类路径,从而可能解决一些依赖性问题或者提高启动速度。
3.2.3. 添加环境变量
vim /etc/profile 或者 在/home目录中的.bashrc文件中 添加
export HBASE_HOME=/u01/hbase-2.6.1
export PATH=$PATH:$HBASE_HOME/bin
3.3. 启动hbase服务
./bin/start-hbase.sh
启动成功后,使用jps查看启动的服务有有HQuorumPeer、HMaster、HRegionServer
3.4. 验证snappy压缩
验证方法:使用hbase shell创建两张表compress_1219_3和no_compress_1219_3,一张指定使用snappy压缩,另一张不指定,然后使用hbase java api往这两张表写入相同的数据,观察表的存储大小情况
3.4.1. 建表
使用hbase shell
create'compress_1219_3',{ NAME =>'cf', COMPRESSION =>'SNAPPY'}
create'no_compress_1219_3',{ NAME =>'cf'}
3.4.2. 生成数据
执行两次,依次向compress_1219_3和no_compress_1219_3写数据
packagecom.easipass;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.hbase.HBaseConfiguration;
importorg.apache.hadoop.hbase.TableName;
importorg.apache.hadoop.hbase.client.Connection;
importorg.apache.hadoop.hbase.client.ConnectionFactory;
importorg.apache.hadoop.hbase.client.Put;
importorg.apache.hadoop.hbase.client.Table;
importorg.apache.hadoop.hbase.util.Bytes;
importjava.io.IOException;
publicclassMain {
publicstaticvoidmain(String[] args)throwsIOException {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.property.clientPort","2181");
// 如果是集群 则主机名用逗号分隔
configuration.set("hbase.zookeeper.quorum","192.168.68.129");
Connection connection = ConnectionFactory.createConnection(configuration);
//修改为compress_1219_3和no_compress_1219_3,分别执行
Table table = connection.getTable(TableName.valueOf("compress_1219_2"));
//rowkey
for(inti =1; i <200000; i++) {
Put put =newPut(Bytes.toBytes("H5000000"+i));
//列簇,列名,列值
put.addColumn(
Bytes.toBytes("cf"),
Bytes.toBytes("name"),
Bytes.toBytes("AAAAAAABBBB中文Hadoop、hbase使用snappy压缩"+"5000000"+i)
);
put.addColumn(
Bytes.toBytes("cf"),
Bytes.toBytes("age"),
Bytes.toBytes("AAAAAAABBBB中age文Hadoop、hbase使用snappy压缩"+"5000000"+i)
);
table.put(put);
}
table.close();
connection.close();
}
}
3.4.3. 从内存flush到磁盘
使用hbase shell的flush命令手动将两张表的数据从内存写到磁盘
flush'compress_1219_3'
flush'no_compress_1219_3'
3.4.4. 未开启压缩
查看表配置
查看region大小和表存储大小
再来查看hdfs的存储情况
第一列为一个副本的大小,第二列为3个副本占用的总存储大小
3.4.5. 开启压缩
查看表配置
查看region大小和表存储大小
共产生了一个region
再来查看hdfs的存储情况
第一列为一个副本的大小,第二列为3个副本占用的总存储大小
相关文章:

Hadoop、Hbase使用Snappy压缩
1. 前期准备 系统环境:centos7.9 配置信息:8C8G100G hadoop和hbase为单节点部署模式 jdk版本jdk1.8.0_361 1.1. 修改系统时间 timedatectl set-timezone <TimeZone> 1.2. 修改主机名以及主机名和IP的映射 vim /etc/hosts #将自己的主机名以及…...

【python】OpenCV—Image Moments
文章目录 1、功能描述2、图像矩3、代码实现4、效果展示5、完整代码6、涉及到的库函数cv2.moments 7、参考 1、功能描述 计算图像的矩,以质心为例 2、图像矩 什么叫图像的矩,在数字图像处理中有什么作用? - 谢博琛的回答 - 知乎 https://ww…...
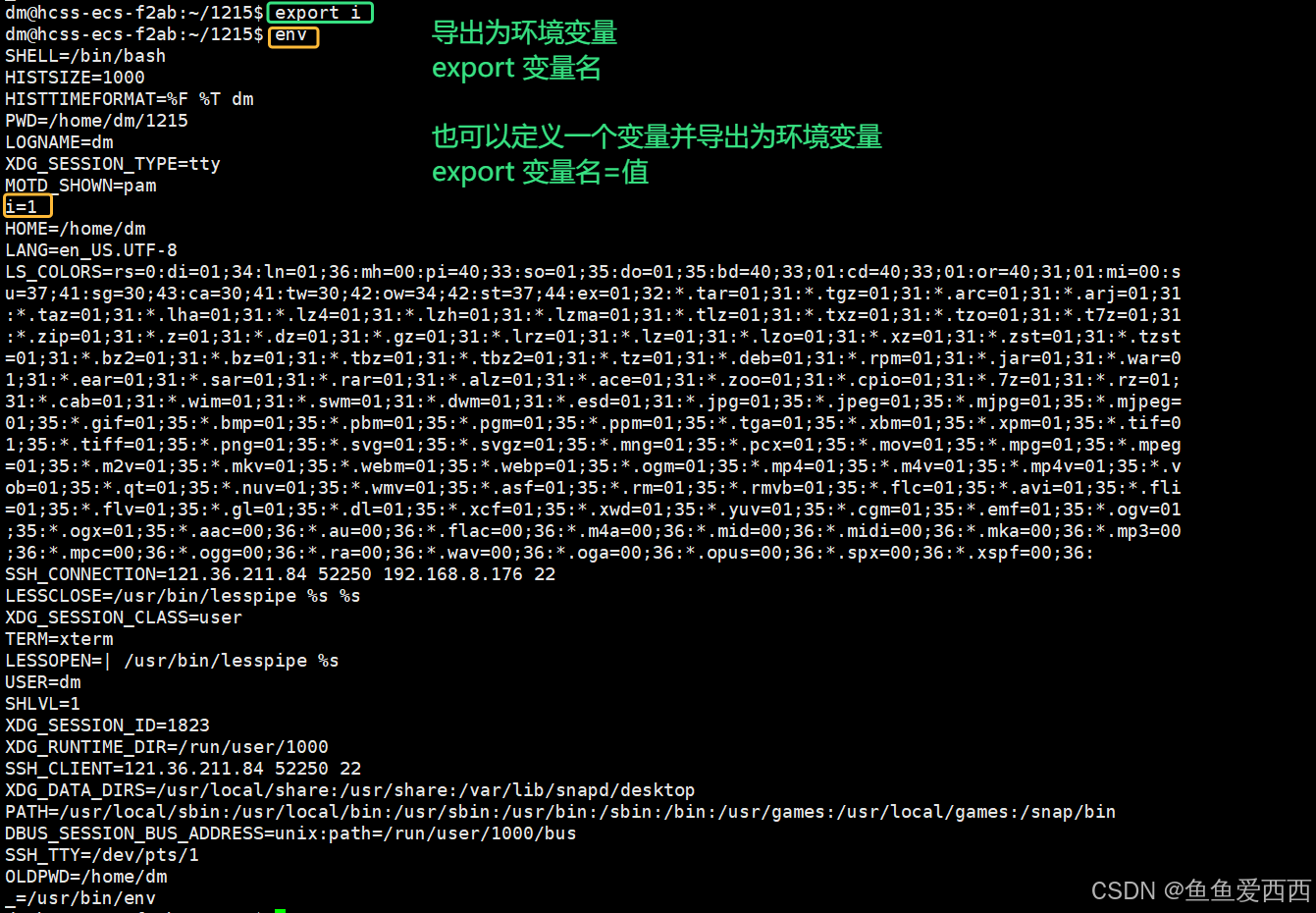
环境变量的知识
目录 1. 环境变量的概念 2. 命令行参数 2.1 2.2 创建 code.c 文件 2.3 对比 ./code 执行和直接 code 执行 2.4 怎么可以不带 ./ 2.4.1 把我们的二进制文件拷贝到 usr/bin 路径下,也不用带 ./ 了 2.4.2 把我们自己的路径添加到环境变量里 3. 认识PATH 3.…...
ATECLOUD测试平台有哪些功能?
测试方案搭建 可视化拖拽编程:采用零代码的图文拖拽形式,用户通过鼠标拖拽节点和连线,即可可视化地构建测试模型,无需懂得代码开发,15 分钟左右就能快速搭建项目,大大降低了上手门槛。 子项目多层嵌套&am…...
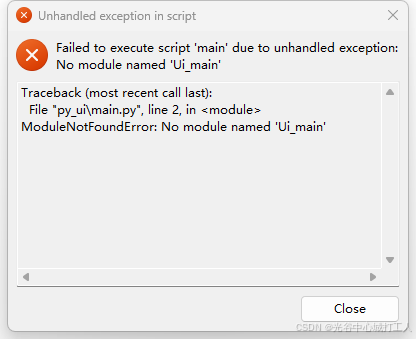
使用pyinstaller打包pyqt的程序,运行后提示ModuleNotFoundError: No module named ‘Ui_main‘
环境:windowpython3.9pyqt6 使用pyqt UI编辑器生成了main.ui ,main.ui编译成了Ui_main.py main.py 使用当前目录下的Ui_main.py。 打包过程没报错,运行报错。 错误如下: 解决方法:pyinstaller -Fw main.py --paths. 使…...

搭建分布式Spark集群
title: 搭建分布式Spark集群 date: 2024-11-29 12:00:00 categories: - 服务器 tags: - Spark - 大数据搭建分布式Spark集群 本次实验环境:Centos 7-2009、Hadoop-3.1.4、JDK 8、Zookeeper-3.6.3、scala-2.11.5、Spark-3.2.1 功能规划 MasterSlave1Slave2主节点…...

Django基础 - 01入门简介
一、 基本概念 1.1 Django说明 Django发布于2005年, 网络框架, 用Python编写的开源的Web应用框架。采用了MVC框架模式,也称为MTV模式。官网: https://www.djangoproject.com1.2 MVC框架 Model: 封装和数据库相关…...

简单的bytebuddy学习笔记
简单的bytebuddy学习笔记 此笔记对应b站bytebuddy学习视频进行整理,此为视频地址,此处为具体的练习代码地址 一、简介 ByteBuddy是基于ASM (ow2.io)实现的字节码操作类库。比起ASM,ByteBuddy的API更加简单易用。开发者无需了解class file …...

【服务端】Redis 内存超限问题的深入探讨
在 Java 后端开发中,Redis 内存超限是一个常见的问题,可能由多种原因引起。理解这些原因以及如何处理已经超出限制的数据对于保持系统的稳定性和性能至关重要。 一、Redis 内存超限的原因分析 Redis 是一个高性能的内存键值对存储系统,它在…...
)
Springboot logback 日志打印配置文件,每个日志文件100M,之后滚动到下一个日志文件,日志保留30天(包含traceid)
全部配置 logback.xml <?xml version"1.0" encoding"UTF-8"?> <configuration debug"false"><property name"LOG_HOME" value"log"/><property name"LOG_NAME" value"admin"/&g…...

《计算机组成及汇编语言原理》阅读笔记:p1-p8
《计算机组成及汇编语言原理》学习第 1 天,p1-p8 总结,总计 8 页。 一、技术总结 1.Intel 8088 microprocessor(微处理器), 1979-1988。 2.MS-DOS Microsoft Disk Operating System的缩写,是一个操作系统(operating system)。…...

【游戏中orika完成一个Entity的复制及其Entity异步落地的实现】 1.ctrl+shift+a是飞书下的截图 2.落地实现
一、orika工具使用 1)工具类 package com.xinyue.game.utils;import ma.glasnost.orika.MapperFactory; import ma.glasnost.orika.impl.DefaultMapperFactory;/*** author 王广帅* since 2022/2/8 22:37*/ public class XyBeanCopyUtil {private static MapperFactory mappe…...

在 Ubuntu 上安装 MySQL 的详细指南
在Ubuntu环境中安装 mysql-server 以及 MySQL 开发包(包括头文件和动态库文件),并处理最新版本MySQL初始自动生成的用户名和密码,可以通过官方的APT包管理器轻松完成。以下是详细的步骤指南,包括从官方仓库和MySQL官方…...

Java 优化springboot jar 内存 年轻代和老年代的比例 减少垃圾清理耗时 如调整 -XX:NewRatio
-XX:NewRatio 是 Java Virtual Machine (JVM) 的一个选项,用于调整 年轻代(Young Generation)和 老年代(Old Generation)之间的内存比例。 1. 含义 XX:NewRatioN 用于指定 老年代 与 年轻代 的内存比例。 N 的含义&…...

嵌入式驱动RK3566 HDMI eDP MIPI 背光 屏幕选型与调试提升篇-eDP屏
eDP是嵌入式显示端口,具有高数据传输速率,高带宽,高分辨率、高刷新率、低电压、简化接口数量等特点。现大多数笔记本电脑都是用的这种接口。整个eDP是很复杂的,这里我们不讲底层原理,我们先掌握如何用泰山派来驱动各种…...

在Java虚拟机(JVM)中,方法可以分为虚方法和非虚方法。
在Java虚拟机(JVM)中,方法可以分为虚方法和非虚方法。以下是关于这两种方法的详细解释: 一、虚方法(Virtual Method) 定义:虚方法是指在运行时由实例的实际类型决定的方法。在Java中,所有的非私有、非静态、非final方法都是虚方法。当调用一个虚方法时,JVM会根据实…...

【windows】sonarqube起不来的问题解决
1. 现象与本质 因JDK的问题(比如版本太低或者太高,推荐JDK17)或者其他环境因素,导致sonarqube启动后自动关闭了。 从日志来看,根本看不出来什么,只有警告,没有ERROR,警告也不是本质问题&#…...

golang异常
panic如果不处理会导致应用进程挂掉 defer recover可以处理这种情况 一个recover只处理自己协程 产生panic的情况 空指针 数组越界 空map中添加键值对 错误,error接口,不严重 error.wrapof解决嵌套问题或者error.unwrap erroe.is方法,判断是…...

搭建MongoDB
title: 搭建MongoDB date: 2024-11-30 23:30:00 categories: - 服务器 tags: - MongoDB - 大数据搭建MongoDB 环境:Centos 7-2009 1. 创建MongoDB的国内yum源 # 下载Centos7对应最新版7.0.15的安装包 cat >> /etc/yum.repos.d/mongodb.repo << &quo…...

Android中坐标体系知识超详细讲解
说来说去都不如画图示意简单易懂啊!!!真是的! 来吧先上张图! (一)首先明确一下android 中的坐标系统: 屏幕的左上角是坐标系统原点(0,0) 原点向右延伸是X轴正…...

SpringBatch学习
/*** 示例一:Tasklet 方式*/ Configuration EnableBatchProcessing public class TaskletBatchConfig {private static final Logger logger LoggerFactory.getLogger(TaskletBatchConfig.class);Autowiredprivate JobBuilderFactory jobBuilderFactory;Autowiredp…...

【技术底稿 35】低配单机混跑 Dev/Test 微服务环境,Jenkins 部署包错乱踩坑全复盘
一、核心背景在不新增服务器、沿用现有 7G 低配开发机前提下,同时承载:开发环境(2 个 admin 节点)测试环境(1 个 admin 节点)Jenkins 打包编译MySQL / Redis / Zookeeper / Milvus 等全套中间件机器硬件资源…...

深度解析网易游戏NPK文件解包:从二进制迷宫到资源提取的完整实战指南
深度解析网易游戏NPK文件解包:从二进制迷宫到资源提取的完整实战指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾经好奇网易热门游戏如《阴阳师》…...

Flyway实战:从零到一构建数据库版本管理流水线
1. 为什么你的项目需要Flyway 第一次接触数据库版本管理这个概念时,我正面临一个典型的开发困境:团队里有5个开发人员在同时修改数据库结构,每次发布新版本都像在玩俄罗斯轮盘赌——永远不知道谁会忘记执行哪个SQL脚本。直到生产环境出现数据…...

Driver Store Explorer:彻底清理Windows驱动存储,让你的系统运行如新的专业工具
Driver Store Explorer:彻底清理Windows驱动存储,让你的系统运行如新的专业工具 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间越来…...

Prisma AI插件OpenClaw:用自然语言智能查询数据库
1. 项目概述:一个为Prisma生态注入AI能力的开源插件如果你正在使用Prisma作为你的Node.js或TypeScript项目的ORM(对象关系映射)工具,并且对如何将生成式AI的能力无缝集成到数据库操作中感到好奇,那么你很可能已经听说过…...

LZ4并行压缩:线程池设计与性能瓶颈突破的终极指南
LZ4并行压缩:线程池设计与性能瓶颈突破的终极指南 【免费下载链接】lz4 Extremely Fast Compression algorithm 项目地址: https://gitcode.com/GitHub_Trending/lz/lz4 LZ4作为一款Extremely Fast Compression algorithm,其并行压缩能力是提升处…...

AI驱动的计划驱动开发:Gemini Plan Commands深度解析与实践指南
1. 项目概述:当AI工程师遇上“计划指挥官” 如果你是一名开发者,尤其是经常和AI模型打交道的工程师,你肯定遇到过这样的场景:面对一个复杂的代码库,你想快速理解它的架构;或者接到一个新功能需求ÿ…...

别再手动搬数据了!STM32CubeMX配置SDIO DMA,让FatFs文件读写性能翻倍
STM32CubeMX实战:用DMA解锁SD卡与FatFs的终极性能 在嵌入式系统开发中,存储性能往往是制约整体效率的关键瓶颈。想象一下这样的场景:你的设备正在以最高优先级处理传感器数据,同时需要将采集结果实时写入SD卡。此时如果采用传统的…...

如何轻松获取九大网盘直链下载地址:LinkSwift完整使用指南
如何轻松获取九大网盘直链下载地址:LinkSwift完整使用指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...