【数理统计】参数估计
文章目录
- 点估计
- 矩估计法
- 最大似然估计法
- 区间估计
- 单个正态总体参数的区间估计
- 两个正态总体参数的区间估计(略)
- 补充:单侧置信区间
点估计
矩估计法
【定义】设 X X X 是随机变量,若 E ( X k ) ( k = 1 , 2 , . . . ) E(X^k) (k=1,2,...) E(Xk)(k=1,2,...) 存在,则称其为 X X X 的 k k k 阶矩。
【方法】设待估计的参数 θ 1 , θ 2 , . . . , θ n \theta_1,\theta_2,... ,\theta_n θ1,θ2,...,θn,设
{ μ 1 = μ 1 ( θ 1 , θ 2 , . . . , θ n ) = E ( X 1 ) μ 2 = μ 2 ( θ 1 , θ 2 , . . . , θ n ) = E ( X 2 ) . . . μ n = μ n ( θ 1 , θ 2 , . . . , θ n ) = E ( X n ) \begin{cases} \mu_1 = \mu_1 (\theta_1,\theta_2,... ,\theta_n) = E(X^1) \\ \mu_2 = \mu_2 (\theta_1,\theta_2,... ,\theta_n) = E(X^2) \\ ... \\ \mu_n = \mu_n (\theta_1,\theta_2,... ,\theta_n) = E(X^n) \end{cases} ⎩ ⎨ ⎧μ1=μ1(θ1,θ2,...,θn)=E(X1)μ2=μ2(θ1,θ2,...,θn)=E(X2)...μn=μn(θ1,θ2,...,θn)=E(Xn)
这是关于 θ i \theta_i θi 的方程组,解该方程组可得
{ θ 1 = θ 1 ( μ 1 , μ 2 , . . . , μ n ) θ 2 = θ 2 ( μ 1 , μ 2 , . . . , μ n ) . . . θ n = θ n ( μ 1 , μ 2 , . . . , μ n ) \begin{cases} \theta_1 = \theta_1 (\mu_1,\mu_2,... ,\mu_n) \\ \theta_2 = \theta_2 (\mu_1,\mu_2,... ,\mu_n) \\ ... \\ \theta_n = \theta_n (\mu_1,\mu_2,... ,\mu_n) \end{cases} ⎩ ⎨ ⎧θ1=θ1(μ1,μ2,...,μn)θ2=θ2(μ1,μ2,...,μn)...θn=θn(μ1,μ2,...,μn)
以 A l = 1 n ∑ i = 1 n X i l A_l = \frac{1}{n} \sum_{i=1}^n X_i^l Al=n1∑i=1nXil 代替上式中的 μ l ( l = 1 , 2 , . . . , n ) \mu_l(l=1,2,...,n) μl(l=1,2,...,n) 即可得到矩估计量。
注意:
- A 1 = 1 n ∑ i = 1 n X i = X ˉ A_1 = \frac{1}{n} \sum_{i=1}^n X_i = \bar{X} A1=n1∑i=1nXi=Xˉ
- A 2 = 1 n ∑ i = 1 n X i 2 A_2 = \frac{1}{n} \sum_{i=1}^n X_i^2 A2=n1∑i=1nXi2
- A 2 − A 1 2 = D ( X ) A_2 - A_1^2 = D(X) A2−A12=D(X)
【举例】
- 当 n = 1 n=1 n=1 时,即待估计参数有一个,令 μ 1 = E ( X ) \mu_1 = E(X) μ1=E(X),然后解出 θ 1 \theta_1 θ1,最后用 A 1 A_1 A1 代替 μ 1 \mu_1 μ1 即可。
- 当 n = 2 n=2 n=2 时,即待估计参数有两个,令
{ μ 1 = E ( X ) μ 2 = E ( X 2 ) = D ( X ) + [ E ( X ) ] 2 \begin{cases} \mu_1 = E(X) \\ \mu_2 = E(X^2) = D(X) + [E(X)]^2 \end{cases} {μ1=E(X)μ2=E(X2)=D(X)+[E(X)]2
然后解出 θ 1 , θ 2 \theta_1, \theta_2 θ1,θ2,最后用 A 1 , A 2 A_1, A_2 A1,A2 代替 μ 1 , μ 2 \mu_1, \mu_2 μ1,μ2 即可。
最大似然估计法
【定义】若总体 X X X 的概率密度函数为 f ( x ; θ ) f(x;\theta) f(x;θ),其中 θ ∈ Θ \theta \in \Theta θ∈Θ 为参数向量( Θ \Theta Θ 为参数 θ \theta θ 可能取值的范围), X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn 为来自 X X X 的一个样本,则联合概率密度函数记为
L ( x 1 , x 2 , . . . , x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) L(x_1,x_2,...,x_n; \theta) = \prod_{i=1}^{n} f(x_i; \theta) L(x1,x2,...,xn;θ)=i=1∏nf(xi;θ)
称为参数 θ \theta θ 的似然函数。
【思想】求参数 θ \theta θ 的估计值,使得似然函数取得最大值。
【方法】求极大似然估计的一般步骤如下:
- 写出似然函数:
L ( x 1 , x 2 , . . . , x n ; θ ) = ∏ i = 1 n f ( x i ; θ 1 , θ 2 , . . . , θ m ) L(x_1,x_2,...,x_n; \theta) = \prod_{i=1}^{n} f(x_i; \theta_1, \theta_2,..., \theta_m) L(x1,x2,...,xn;θ)=i=1∏nf(xi;θ1,θ2,...,θm)
- 对似然函数取对数:
ln L = ∑ i = 1 n ln f ( x i ; θ 1 , θ 2 , . . . , θ m ) \ln L = \sum_{i=1}^{n} \ln f(x_i; \theta_1, \theta_2,..., \theta_m) lnL=i=1∑nlnf(xi;θ1,θ2,...,θm)
- 对 θ j ( j = 1 , 2 , . . . , m ) \theta_j (j=1,2,...,m) θj(j=1,2,...,m) 分别求偏导,建立似然方程组:
∂ ln L ∂ θ j = 0 ( j = 1 , 2 , . . . , m ) \frac{\partial \ln L}{\partial \theta_j} = 0 \ \ (j=1,2,...,m) ∂θj∂lnL=0 (j=1,2,...,m)
- 解得 θ j ^ \hat{\theta_j} θj^ 为 θ j \theta_j θj 的极大似然估计量(不是估计量!)
区间估计
【定义】设总体的未知参数为 θ \theta θ,由样本 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn 确定两个统计量
θ 1 ^ = θ 1 ^ ( X 1 , X 2 , . . . , X n ) , θ 2 ^ = θ 2 ^ ( X 1 , X 2 , . . . , X n ) \hat{\theta_1} = \hat{\theta_1} (X_1,X_2,...,X_n), \hat{\theta_2} = \hat{\theta_2} (X_1,X_2,...,X_n) θ1^=θ1^(X1,X2,...,Xn),θ2^=θ2^(X1,X2,...,Xn)
对于给定的实数 α ( o < α < 1 ) \alpha(o<\alpha<1) α(o<α<1),满足
P { θ 1 ^ < θ < θ 2 ^ } ≥ 1 − α P\{ \hat{\theta_1} < \theta < \hat{\theta_2} \} \geq 1-\alpha P{θ1^<θ<θ2^}≥1−α
则称随机区间 ( θ 1 ^ , θ 2 ^ ) (\hat{\theta_1}, \hat{\theta_2}) (θ1^,θ2^) 是 θ \theta θ 的置信水平为 1 − α 1-\alpha 1−α 的置信区间, 1 − α 1-\alpha 1−α 为置信水平, α \alpha α 为显著性水平,通常取值 0.1 或 0.05。
【枢轴量法】
- 选取待估参数 θ \theta θ 的估计量:遵从估计量的优良性准则,如 X ˉ → μ \bar{X} \rightarrow \mu Xˉ→μ, S 2 → σ 2 S^2 \rightarrow \sigma^2 S2→σ2
- 建立枢轴量: W = W ( X 1 , X 2 , . . . , X n ; θ ) W = W(X_1,X_2,...,X_n; \theta) W=W(X1,X2,...,Xn;θ),使得 W W W 不依赖于 θ \theta θ 及其他未知参数
- 确定 W W W 的分布,通常选取经典分布
- 根据 W W W 的分布,建立概率等式:
P { W 1 − α / 2 < W < W α / 2 } = 1 − α P\{ W_{1-\alpha/2} < W < W_{\alpha/2} \} = 1-\alpha P{W1−α/2<W<Wα/2}=1−α
- 将上式等价变形为:
P { a < θ < b } = 1 − α P\{ a < \theta < b \} = 1-\alpha P{a<θ<b}=1−α
( a , b ) (a,b) (a,b) 即为 θ \theta θ 的一个置信水平为 1 − α 1-\alpha 1−α 的置信区间。
单个正态总体参数的区间估计
均值 μ \mu μ 的区间估计
(1) σ 2 \sigma^2 σ2 已知
根据中心极限定理,选取枢轴量
X ˉ − μ σ / n ∼ N ( 0 , 1 ) \frac{\bar{X} - \mu}{\sigma/\sqrt{n}} \sim N(0,1) σ/nXˉ−μ∼N(0,1)
注意右边的枢轴量(即标准正态分布)并不依赖于任何未知参数,因此有
P { − u α / 2 < X ˉ − μ σ / n < u α / 2 } = 1 − α P\left\{ -u_{\alpha/2} < \frac{\bar{X} - \mu}{\sigma/\sqrt{n}} < u_{\alpha/2} \right\} = 1-\alpha P{−uα/2<σ/nXˉ−μ<uα/2}=1−α
注:对于标准正态分布,有 u α = − u 1 − α u_{\alpha} = -u_{1-\alpha} uα=−u1−α
等价变形为
P { X ˉ − σ n u α / 2 < μ < X ˉ + σ n u α / 2 } = 1 − α P\left\{ \bar{X} - \frac{\sigma}{\sqrt{n}} u_{\alpha/2} < \mu < \bar{X} + \frac{\sigma}{\sqrt{n}} u_{\alpha/2} \right\} = 1-\alpha P{Xˉ−nσuα/2<μ<Xˉ+nσuα/2}=1−α
因此 μ \mu μ 的一个置信水平为 1 − α 1-\alpha 1−α 的置信区间为
( X ˉ − σ n u α / 2 , X ˉ + σ n u α / 2 ) \left(\bar{X} - \frac{\sigma}{\sqrt{n}} u_{\alpha/2}, \bar{X} + \frac{\sigma}{\sqrt{n}} u_{\alpha/2} \right) (Xˉ−nσuα/2,Xˉ+nσuα/2)
注:有些教科书上用的不是 u u u,而是 z z z,其实两者表示的意思是一样的。
(2) σ 2 \sigma^2 σ2 未知
考虑 S 2 S^2 S2 为 σ 2 \sigma^2 σ2 的无偏估计,根据抽样分布定理,应选取枢轴量
X ˉ − μ S / n ∼ t ( n − 1 ) \frac{\bar{X} - \mu}{S/\sqrt{n}} \sim t(n-1) S/nXˉ−μ∼t(n−1)
注意右边的枢轴量(即自由度为 n − 1 n-1 n−1 的 t t t 分布)并不依赖于任何未知参数,因此有
P { − t α / 2 ( n − 1 ) < X ˉ − μ S / n < t α / 2 ( n − 1 ) } = 1 − α P\left\{ -t_{\alpha/2}(n-1) < \frac{\bar{X} - \mu}{S/\sqrt{n}} < t_{\alpha/2}(n-1) \right\} = 1-\alpha P{−tα/2(n−1)<S/nXˉ−μ<tα/2(n−1)}=1−α
注:对于自由度为 n n n 的 t t t 分布,有 t α ( n ) = − t 1 − α ( n ) t_{\alpha}(n) = -t_{1-\alpha}(n) tα(n)=−t1−α(n)
等价变形为
P { X ˉ − S n t α / 2 ( n − 1 ) < μ < X ˉ + S n t α / 2 ( n − 1 ) } = 1 − α P\left\{ \bar{X} - \frac{S}{\sqrt{n}} t_{\alpha/2}(n-1) < \mu < \bar{X} + \frac{S}{\sqrt{n}} t_{\alpha/2}(n-1) \right\} = 1-\alpha P{Xˉ−nStα/2(n−1)<μ<Xˉ+nStα/2(n−1)}=1−α
因此 μ \mu μ 的一个置信水平为 1 − α 1-\alpha 1−α 的置信区间为
( X ˉ − S n t α / 2 ( n − 1 ) , X ˉ + S n t α / 2 ( n − 1 ) ) \left(\bar{X} - \frac{S}{\sqrt{n}} t_{\alpha/2}(n-1), \bar{X} + \frac{S}{\sqrt{n}} t_{\alpha/2}(n-1) \right) (Xˉ−nStα/2(n−1),Xˉ+nStα/2(n−1))
方差 σ 2 \sigma^2 σ2 的区间估计
(1) μ \mu μ 已知
由抽样分布定理,应选取枢轴量
χ 2 = 1 σ 2 ∑ i = 1 n ( X i − μ ) 2 ∼ χ 2 ( n ) \chi^2 = \frac{1}{\sigma^2} \sum_{i=1}^n (X_i - \mu)^2 \sim \chi^2(n) χ2=σ21i=1∑n(Xi−μ)2∼χ2(n)
注意右边的枢轴量(即自由度为 n n n 的 χ \chi χ 分布)并不依赖于任何未知参数,因此有
P { χ 1 − α / 2 2 ( n ) < 1 σ 2 ∑ i = 1 n ( X i − μ ) 2 < χ α / 2 2 ( n ) } = 1 − α P\left\{ \chi_{1-\alpha/2}^2(n) < \frac{1}{\sigma^2} \sum_{i=1}^n (X_i - \mu)^2 < \chi_{\alpha/2}^2(n) \right\} = 1-\alpha P{χ1−α/22(n)<σ21i=1∑n(Xi−μ)2<χα/22(n)}=1−α
等价变形为
P { ∑ i = 1 n ( X i − μ ) 2 χ α / 2 2 ( n ) < σ 2 < ∑ i = 1 n ( X i − μ ) 2 χ 1 − α / 2 2 ( n ) } = 1 − α P\left\{ \frac{\sum_{i=1}^n (X_i - \mu)^2}{\chi_{\alpha/2}^2(n)} < \sigma^2 < \frac{\sum_{i=1}^n (X_i - \mu)^2}{\chi_{1-\alpha/2}^2(n)} \right\} = 1-\alpha P{χα/22(n)∑i=1n(Xi−μ)2<σ2<χ1−α/22(n)∑i=1n(Xi−μ)2}=1−α
因此 σ 2 \sigma^2 σ2 的一个置信水平为 1 − α 1-\alpha 1−α 的置信区间为
( ∑ i = 1 n ( X i − μ ) 2 χ α / 2 2 ( n ) , ∑ i = 1 n ( X i − μ ) 2 χ 1 − α / 2 2 ( n ) ) \left(\frac{\sum_{i=1}^n (X_i - \mu)^2}{\chi_{\alpha/2}^2(n)}, \frac{\sum_{i=1}^n (X_i - \mu)^2}{\chi_{1-\alpha/2}^2(n)} \right) (χα/22(n)∑i=1n(Xi−μ)2,χ1−α/22(n)∑i=1n(Xi−μ)2)
(2) μ \mu μ 未知
考虑 S 2 S^2 S2 为 σ 2 \sigma^2 σ2 的无偏估计,由抽样分布定理,应选取枢轴量
χ 2 = n − 1 σ 2 S 2 ∼ χ 2 ( n − 1 ) \chi^2 = \frac{n-1}{\sigma^2} S^2 \sim \chi^2(n-1) χ2=σ2n−1S2∼χ2(n−1)
注意右边的枢轴量(即自由度为 n − 1 n-1 n−1 的 χ \chi χ 分布)并不依赖于任何未知参数,因此有
P { χ 1 − α / 2 2 ( n − 1 ) < n − 1 σ 2 S 2 < χ α / 2 2 ( n − 1 ) } = 1 − α P\left\{ \chi_{1-\alpha/2}^2(n-1) < \frac{n-1}{\sigma^2} S^2 < \chi_{\alpha/2}^2(n-1) \right\} = 1-\alpha P{χ1−α/22(n−1)<σ2n−1S2<χα/22(n−1)}=1−α
等价变形为
P { ( n − 1 ) S 2 χ α / 2 2 ( n ) < σ 2 < ( n − 1 ) S 2 χ 1 − α / 2 2 ( n ) } = 1 − α P\left\{ \frac{(n-1)S^2}{\chi_{\alpha/2}^2(n)} < \sigma^2 < \frac{(n-1)S^2}{\chi_{1-\alpha/2}^2(n)} \right\} = 1-\alpha P{χα/22(n)(n−1)S2<σ2<χ1−α/22(n)(n−1)S2}=1−α
因此 σ 2 \sigma^2 σ2 的一个置信水平为 1 − α 1-\alpha 1−α 的置信区间为
( ( n − 1 ) S 2 χ α / 2 2 ( n ) , ( n − 1 ) S 2 χ 1 − α / 2 2 ( n ) ) \left(\frac{(n-1)S^2}{\chi_{\alpha/2}^2(n)}, \frac{(n-1)S^2}{\chi_{1-\alpha/2}^2(n)} \right) (χα/22(n)(n−1)S2,χ1−α/22(n)(n−1)S2)
两个正态总体参数的区间估计(略)
(略)
补充:单侧置信区间
【定义 1】设总体的未知参数为 θ \theta θ,由样本 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn 确定的统计量
θ ^ = θ ^ ( X 1 , X 2 , . . . , X n ) \hat{\theta} = \hat{\theta} (X_1,X_2,...,X_n) θ^=θ^(X1,X2,...,Xn)
对于给定的实数 α ( o < α < 1 ) \alpha(o<\alpha<1) α(o<α<1),满足
P { θ > θ ^ } ≥ 1 − α , ∀ θ ∈ Θ P\{ \theta > \hat{\theta} \} \geq 1-\alpha, \forall \theta \in \Theta P{θ>θ^}≥1−α,∀θ∈Θ
则称随机区间 ( θ ^ , + ∞ ) (\hat{\theta}, +\infty) (θ^,+∞) 是 θ \theta θ 的置信水平为 1 − α 1-\alpha 1−α 的单侧置信区间, θ ^ \hat{\theta} θ^ 称为 θ \theta θ 的置信水平为 1 − α 1-\alpha 1−α 的单侧置信下限。
【定义 2】设总体的未知参数为 θ \theta θ,由样本 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn 确定的统计量
θ ^ = θ ^ ( X 1 , X 2 , . . . , X n ) \hat{\theta} = \hat{\theta} (X_1,X_2,...,X_n) θ^=θ^(X1,X2,...,Xn)
对于给定的实数 α ( o < α < 1 ) \alpha(o<\alpha<1) α(o<α<1),满足
P { θ < θ ^ } ≥ 1 − α , ∀ θ ∈ Θ P\{ \theta < \hat{\theta} \} \geq 1-\alpha, \forall \theta \in \Theta P{θ<θ^}≥1−α,∀θ∈Θ
则称随机区间 ( − ∞ , θ ^ ) (-\infty, \hat{\theta}) (−∞,θ^) 是 θ \theta θ 的置信水平为 1 − α 1-\alpha 1−α 的单侧置信区间, θ ^ \hat{\theta} θ^ 称为 θ \theta θ 的置信水平为 1 − α 1-\alpha 1−α 的单侧置信上限。
【举例】对于正态总体 X X X,若均值 μ \mu μ、方差 σ 2 \sigma^2 σ2 均未知,设 X 1 , . . . , X n X_1,...,X_n X1,...,Xn 是一个样本,由
X ˉ − μ S / n ∼ t ( n − 1 ) \frac{\bar{X} - \mu}{S/\sqrt{n}} \sim t(n-1) S/nXˉ−μ∼t(n−1)
得
P { X ˉ − μ S / n < t α ( n − 1 ) } = 1 − α P\left\{ \frac{\bar{X} - \mu}{S/\sqrt{n}} < t_{\alpha}(n-1) \right\} = 1-\alpha P{S/nXˉ−μ<tα(n−1)}=1−α
等价变形为
P { μ > X ˉ − S n t α ( n − 1 ) } = 1 − α P\left\{ \mu > \bar{X} - \frac{S}{\sqrt{n}} t_{\alpha}(n-1) \right\} = 1-\alpha P{μ>Xˉ−nStα(n−1)}=1−α
因此 μ \mu μ 的一个置信水平为 1 − α 1-\alpha 1−α 的单侧置信区间为
( X ˉ − S n t α ( n − 1 ) , + ∞ ) \left(\bar{X} - \frac{S}{\sqrt{n}} t_{\alpha}(n-1), +\infty \right) (Xˉ−nStα(n−1),+∞)
【总结】在形式上,只需将置信区间的上下限中的 α / 2 \alpha/2 α/2 改成 α \alpha α,就能得到相应的单侧置信上下限了。
相关文章:

【数理统计】参数估计
文章目录 点估计矩估计法最大似然估计法 区间估计单个正态总体参数的区间估计均值 μ \mu μ 的区间估计方差 σ 2 \sigma^2 σ2 的区间估计 两个正态总体参数的区间估计(略)补充:单侧置信区间 点估计 矩估计法 【定义】设 X X X 是随机…...

ios 混合开发应用白屏问题
一、问题场景 项目业务中某个前端页面中使用了多个echart 组件来显示历史数据, 在反复切换到这个页面后,会出现白屏问题。 二、问题分析 0x116000ab0 - GPUProcessProxy::didClose: 0x116000ab0 - GPUProcessProxy::gpuProcessExited: reasonCrash 0x11…...

对分布式系统的理解以及redis的分布式实现
对分布式系统有哪些了解? 分布式系统是由多个独立的计算节点(通常是计算机或服务器)组成的系统,这些节点通过网络相互通信和协作,共同完成任务。分布式系统的设计旨在提供可扩展性、容错性和高可用性,适用于大规模的数据处理和服务场景。 1. 分布式系统的核心特点 分布…...

VS项目,在生成的时候自动修改版本号
demo示例:https://gitee.com/chenheze90/L28_AutoVSversion 可通过下载demo运行即可。 原理:通过csproject项目文件中的Target标签,实现在项目编译之前对项目版本号进行修改,避免手动修改; 1.基础版 效果图如下 部…...

【蓝桥杯】43699-四平方和
四平方和 题目描述 四平方和定理,又称为拉格朗日定理: 每个正整数都可以表示为至多 4 个正整数的平方和。如果把 0 包括进去,就正好可以表示为 4 个数的平方和。 比如: 502021222 712121222; 对于一个给定的正整数,可…...

我的“双胞同体”发布模式的描述与展望
当被“激情”晕染,重创标题、摘要探索“吸睛”。 (笔记模板由python脚本于2024年12月19日 15:23:44创建,本篇笔记适合喜欢编撰csdn博客的coder翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免…...

flask_socketio 以继承 Namespace方式实现一个网页聊天应用
点击进入上一篇,可作为参考 实验环境 python 用的是3.11.11 其他环境可以通过这种方式一键安装: pip install flask3.1.0 Flask-SocketIO5.4.1 gevent-websocket0.10.1 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple pip list 详情如下&am…...

go mod tidy 命令
go mod tidy 是 Go 语言的命令,用于清理和更新 go.mod 和 go.sum 文件。它主要有以下功能: 移除未使用的依赖项:从 go.mod 文件中删除那些在代码中不再使用的依赖项。 添加缺失的依赖项:添加代码中使用但尚未记录在 go.mod 文件中…...

(11)YOLOv9算法基本原理
一、YOLOv9 的结构 YOLOv9 引入了可编程梯度信息(PGI),以及基于梯度路径规划的新型轻量级网络架构,为目标检测领域带来了突破性的成果。 Yolov9 网络模型主要由BackBone(主干网络)、Neck(颈层&…...

python学opencv|读取图像(十七)认识alpha通道
【1】引言 前序学习进程中,我们已经掌握了RGB和HSV图像的通道拆分和合并,获得了很多意想不到的效果,相关链接包括且不限于: python学opencv|读取图像(十二)BGR图像转HSV图像-CSDN博客 python学opencv|读…...

中小学教室多媒体电脑安全登录解决方案
中小学教室多媒体电脑面临学生随意登录的问题,主要涉及到设备使用、网络安全、教学秩序等多个方面。以下是对这一问题的详细分析: 一、设备使用问题 1. 设备损坏风险 学生随意登录可能导致多媒体电脑设备过度使用,增加设备损坏的风险。不当…...

Redis篇之Redis高可用模式参数调优,提高Redis性能
1. Redis高可用模式核心 Redis高可用模式的核心是使用主从复制和自动故障转移机制来确保系统在某些节点发生故障时仍然可以正常工作。 常用的高可用架构包括Redis Sentinel模式和Redis Cluster模式,其中Sentinel模式是为了提供高可用性而专门设计的解决方案。 在Re…...

linux-----进程execl簇函数
execl函数族概述 在Linux中,execl函数族用于在一个进程中加载并执行一个新的程序,它会替换当前进程的地址空间(代码段、数据段、堆和栈等)。这个函数族包括execl、execlp、execle、execv、execvp和execvpe,它们的主要功…...

Vue + ECharts 实现山东地图展示与交互
这篇文章中,我将逐步介绍如何使用 Vue 和 ECharts 实现一个互动式的地图展示组件,其中支持返回上一层地图、点击查看不同城市的详细信息,以及根据数据动态展示不同的统计信息。 效果图:玩转山东地图:用Echarts打造交互…...

【Verilog】UDP用户原语
User-defined primitives 概述基本语法组合逻辑的UDP时序逻辑的UDPUDP 符号表 Verilog HDL(简称 Verilog )是一种硬件描述语言,用于数字电路的系统设计。可对算法级、门级、开关级等多种抽象设计层次进行建模。 Verilog 不仅定义了语法&…...

问题小记-达梦数据库报错“字符串转换出错”处理
最近遇到一个达梦数据库报错“-6111: 字符串转换出错”的问题,这个问题主要是涉及到一条sql语句的执行,在此分享下这个报错的处理过程。 问题表现为:一样的表结构和数据,执行相同的SQL,在Oracle数据库中执行正常&…...

MyBatis入门的详细应用实例
目录 MyBatis第一章:代理Dao方式的CRUD操作1. 代理Dao方式的增删改查 第二章:MyBatis参数详解1. parameterType2. resultType 第三章:SqlMapConfig.xml配置文件1. 定义properties标签的方式管理数据库的信息2. 类型别名定义 MyBatis 第一章&…...

Sequelize ORM sql 语句工具
Sequelize ORM sql 语句工具 初始化配置 Sequelize orm 配置文章落日沉溺于海 在命令行中全局安装 npm i -g sequelize-clisequelize 执行需要匹配 mysql2 对应的依赖(安装 mysql2) npm i sequelize mysql2初始化项目 sequelize init熟悉初始化项目后…...

增强LabVIEW与PLC通信稳定性
在工业自动化系统中,上位机与PLC之间的通信稳定性至关重要,尤其是在数据采集和控制任务的实时性要求较高的场景中。LabVIEW作为常用的上位机开发平台,通过合理优化通信协议、硬件接口、数据传输方式以及系统容错机制,可以大大提升…...

UDP系统控制器_音量控制、电脑关机、文件打开、PPT演示、任务栏自动隐藏
UDP系统控制器(ShuiYX) 帮助文档 概述 本程序设计用于通过UDP协议接收指令来远程控制计算机的音量、执行特定命令和其他功能。为了确保程序正常工作,请确认防火墙和网络设置允许UDP通信,并且程序启动后会最小化到托盘图标。 命令格式及说明 音量控制…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...
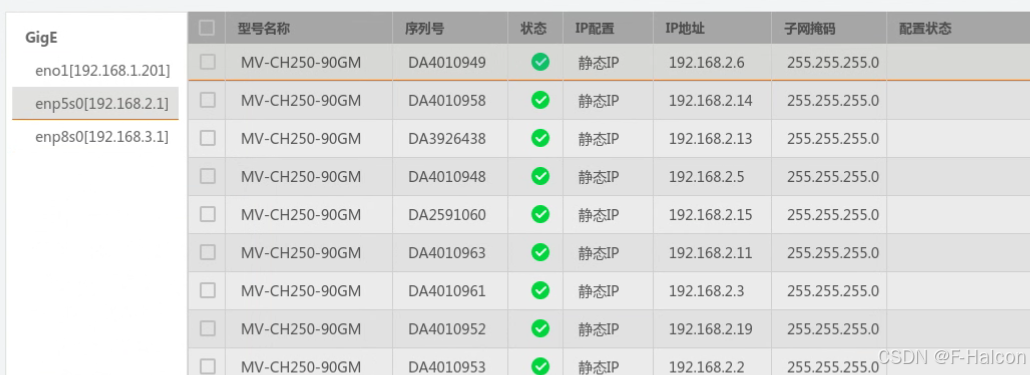
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...
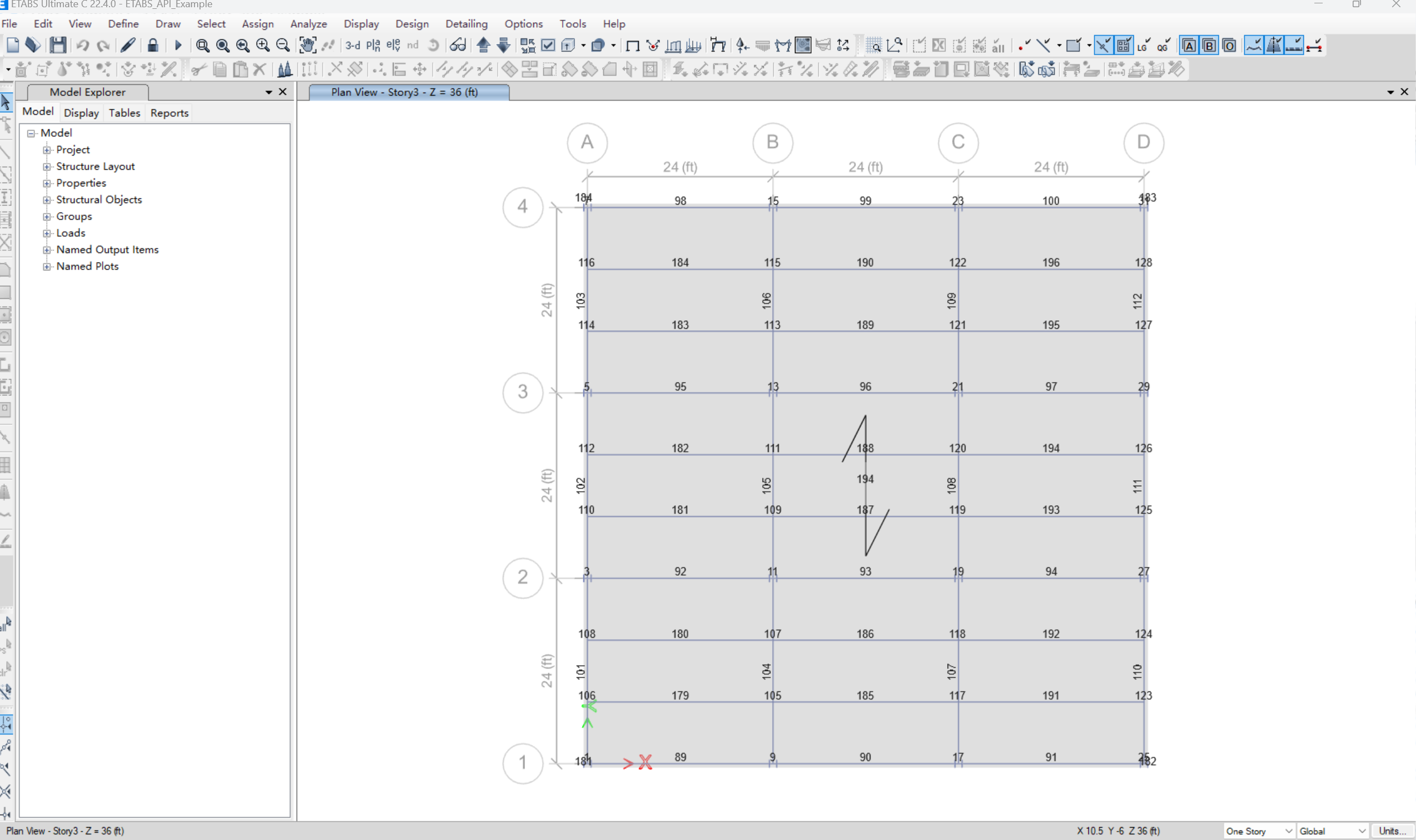
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...
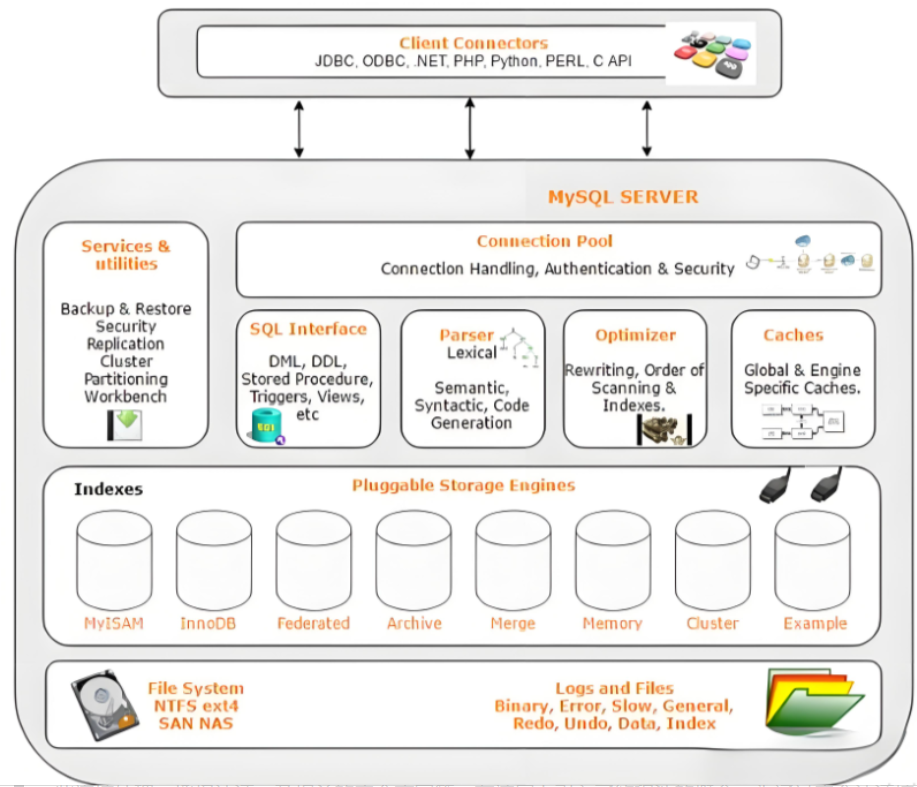
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...

基于Uniapp的HarmonyOS 5.0体育应用开发攻略
一、技术架构设计 1.混合开发框架选型 (1)使用Uniapp 3.8版本支持ArkTS编译 (2)通过uni-harmony插件调用原生能力 (3)分层架构设计: graph TDA[UI层] -->|Vue语法| B(Uniapp框架)B --&g…...