Python7-数据结构
记录python学习,直到学会基本的爬虫,使用python搭建接口自动化测试就算学会了,在进阶webui自动化,app自动化
python基础7-数据结构的那些事儿
- 常见的数据结构有哪些?
- 线性数据结构有哪些?
- 非线性数据结构有哪些?
- 生活中有哪些常见的线性结构示例呢?
- 生活中有哪些常见的非线性结构示例呢?
- 时间复杂度优先级(从低到高(从优到劣))
- 列表(数组)的crud有哪些方法呢?时间复杂度如何?
- 创建(Create)
- 读取(Read)
- 更新(Update)
- 删除(Delete)
- 链表的crud有哪些方法呢?时间复杂度如何?
- 创建(Create)
- 读取(Read)
- 更新(Update)
- 删除(Delete)
- 实践是检验真理的唯一标准
常见的数据结构有哪些?
线性数据结构和非线性数据结构
线性数据结构有哪些?
数组(Array):也叫列表存储固定大小的相同类型元素的集合,其元素可以通过索引进行随机访问。
链表(Linked List):由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。链表分为单链表、双向链表和循环链表。
栈(Stack):遵循后进先出(LIFO)原则的线性表,主要操作有入栈(push)和出栈(pop)。
队列(Queue):遵循先进先出(FIFO)原则的线性表,主要操作有入队(enqueue)和出队(dequeue)。队列的变种包括双端队列(Deque)和优先队列(Priority Queue)。
字符串(String):字符的序列,可以看作是数组的一种特例,用于存储文本数据。
非线性数据结构有哪些?
树(Tree):由节点和边组成,具有层次结构。常见的树结构包括:
二叉树(Binary Tree):每个节点最多有两个子节点的树。
平衡树(Balanced Tree):如AVL树,通过自平衡操作来保持树的高度平衡。
二叉搜索树(Binary Search Tree, BST):每个节点的值大于或等于其左子树中的所有节点的值,小于或等于其右子树中的所有节点的值。
堆(Heap):一种特殊的完全二叉树,分为最大堆和最小堆,常用于实现优先队列。
B树(B-Tree)和B+树(B+Tree):用于数据库和文件系统的索引结构。
图(Graph):由顶点和边组成,顶点之间通过边相互连接。图可以分为无向图和有向图,还可以是加权图或非加权图。
哈希表(Hash Table):通过哈希函数将键映射到表中的一个位置来访问记录,实现快速的数据查找、插入和删除操作。
生活中有哪些常见的线性结构示例呢?
数组:数组是线性数据结构的一个例子。它存储元素的序列,每个元素都有一个索引,索引是元素在数组中的位置。例如,一个学生的成绩单可以看作是一个数组,其中每个索引对应一门课程的成绩。
链表:链表中的每个元素称为节点,每个节点包含数据和一个指向下一个节点的指针。例如,一个排队系统可以看作是一个链表,其中每个节点代表一个排队的人,指针指向下一个排队的人。
栈:栈是一种后进先出(LIFO)的数据结构。例如,一叠盘子可以看作是一个栈,最后一个放上去的盘子是第一个被拿下来的。
队列:队列是一种先进先出(FIFO)的数据结构。例如,银行的排队系统可以看作是一个队列,先来的顾客先得到服务。
生活中有哪些常见的非线性结构示例呢?
树:树是一种非线性数据结构,其中每个元素(称为节点)可以有多个子节点。例如,公司的组织结构可以看作是一棵树,其中每个部门是一个节点,部门下的员工是子节点。
图:图是由节点(顶点)和边组成的非线性数据结构。例如,社交网络可以看作是一个图,其中每个人是一个节点,朋友关系是边。
堆:堆是一种特殊的树形数据结构,其中每个节点的值都大于或等于其子节点的值(最大堆)或小于或等于其子节点的值(最小堆)。例如,一个任务调度系统可以使用堆来确定下一个要执行的任务。
散列表(哈希表):散列表通过哈希函数将键映射到表中的位置来存储数据。例如,一个电话簿可以看作是一个散列表,其中人名是键,电话号码是值。
时间复杂度优先级(从低到高(从优到劣))
常数时间复杂度O(1)
无论输入规模如何,算法的运行时间都是常数,不随输入规模变化。例如,访问数组的某个元素。
对数时间复杂度O(logn)
算法的运行时间与输入规模的对数成正比。例如,二分查找算法。
线性时间复杂度O(n)
算法的运行时间与输入规模成正比。例如,遍历数组中的每个元素。
线性对数时间复杂度O(n*logn)
算法的运行时间与输入规模的线性对数成正比。例如,快速排序、归并排序等高效的排序算法。
平方时间复杂度O(n^2)
算法的运行时间与输入规模的平方成正比。例如,冒泡排序、选择排序等简单排序算法。
立方时间复杂度O(n^3)
算法的运行时间与输入规模的立方成正比。例如,某些矩阵乘法算法。
指数时间复杂度O(2^n)
算法的运行时间随着输入规模的增加而指数增长。例如,解决某些组合问题的暴力搜索算法。
阶乘时间复杂度O(n!)
法的运行时间随着输入规模的增加而阶乘增长。例如,解决旅行商问题的暴力搜索算法。
列表(数组)的crud有哪些方法呢?时间复杂度如何?
创建(Create)
append(x):在列表的末尾添加一个元素x。
时间复杂度:O(1)(平均情况,因为可能需要扩容)
insert(i, x):在指定位置i插入一个元素x。
时间复杂度:O(n),因为可能需要移动插入点之后的所有元素。
读取(Read)
索引访问:使用索引访问列表中的元素,例如 list[i]。
时间复杂度:O(1),
index(x, start=None, end=None):找出元素x在列表中第一次出现的索引位置。
时间复杂度:O(n),因为可能需要遍历列表直到找到元素x。
count(x):返回x在列表中出现的次数。
时间复杂度:O(n),因为需要遍历整个列表来计数。
更新(Update)
索引赋值:使用索引直接更新列表中的元素,例如 list[i] = x。
时间复杂度:O(1)
切片赋值:使用切片语法更新列表中的一段元素,例如 list[i:j] = [x, y, z]。
时间复杂度:O(k),其中k是被赋值的元素数量。
删除(Delete)
pop():移除列表中的最后一个元素,并返回该元素。
时间复杂度:O(1)
pop(i):移除列表中指定位置i的元素,并返回该元素。
时间复杂度:O(n),因为可能需要移动删除点之后的所有元素。
remove(x):移除列表中第一次出现的元素x。
时间复杂度:O(n),因为可能需要遍历列表直到找到元素x。
clear():清空列表中的所有元素。
时间复杂度:O(1)
其他操作
sort():对列表中的元素进行排序。
时间复杂度:O(n log n),使用的是Timsort算法。
reverse():反转列表中的元素顺序。
时间复杂度:O(n)
python实战示例,咱就是这些都是一些基础东西,但是再离谱的业务逻辑也是由这些基础函数和方法构成的,所以需要代码加深下理解
# 创建(Create)
from astropy.io.fits import appendmy_list = [] # 创建一个空列表
print("初始列表:", my_list)# append(x):在列表的末尾添加一个元素x
my_list.append(10)
my_list.append(20)
print("使用append添加元素后:", my_list)# insert(i, x):在指定位置i插入一个元素x
my_list.insert(1, 15) # 在索引1的位置插入15
print("使用insert插入元素后:", my_list)# 读取(Read)
# 索引访问:使用索引访问列表中的元素
print("索引为2的元素:", my_list[2])# index(x, start=None, end=None):找出元素x在列表中第一次出现的索引位置
index_of_10 = my_list.index(10)
print("元素10的索引:", index_of_10)# count(x):返回x在列表中出现的次数
count_of_15 = my_list.count(15)
print("元素15出现的次数:", count_of_15)# 更新(Update)
# 索引赋值:使用索引直接更新列表中的元素
my_list[0] = 5
print("更新索引为0的元素后:", my_list)# 切片赋值:使用切片语法更新列表中的一段元素
# 这里需要注意是左开右比较的
my_list[1:3] = [12, 18]
print("使用切片赋值更新元素后:", my_list)# 删除(Delete)
# pop():移除列表中的最后一个元素,并返回该元素
last_element = my_list.pop()
print("使用pop移除最后一个元素后:", my_list)
print("移除的元素:", last_element)# pop(i):移除列表中指定位置i的元素,并返回该元素
element_at_index_1 = my_list.pop(1)
print("使用pop(1)移除索引为1的元素后:", my_list)
print("移除的元素:", element_at_index_1)# remove(x):移除列表中第一次出现的元素x
my_list.remove(5)
print("使用remove移除元素5后:", my_list)
my_list.append(1)
my_list.append(2)
print("append添加元素1,2",my_list)
# clear():清空列表中的所有元素
my_list.clear()
print("使用clear清空列表后:", my_list)# 其他操作
# sort():对列表中的元素进行排序
another_list = [3, 1, 4, 1, 5, 9, 2, 6]
another_list.sort()
print("排序后的列表:", another_list)# reverse():反转列表中的元素顺序
another_list.reverse()
print("反转后的列表:", another_list)
终端回显:
初始列表: []
使用append添加元素后: [10, 20]
使用insert插入元素后: [10, 15, 20]
索引为2的元素: 20
元素10的索引: 0
元素15出现的次数: 1
更新索引为0的元素后: [5, 15, 20]
使用切片赋值更新元素后: [5, 12, 18]
使用pop移除最后一个元素后: [5, 12]
移除的元素: 18
使用pop(1)移除索引为1的元素后: [5]
移除的元素: 12
使用remove移除元素5后: []
append添加元素1,2 [1, 2]
使用clear清空列表后: []
排序后的列表: [1, 1, 2, 3, 4, 5, 6, 9]
反转后的列表: [9, 6, 5, 4, 3, 2, 1, 1]

链表的crud有哪些方法呢?时间复杂度如何?
链表是一种线性数据结构,其中的元素通过指针连接在一起。与数组不同,链表中的元素不必存储在连续的内存空间中。
创建(Create)
插入节点
在链表头部插入:创建一个新节点,并将其指针指向当前的头节点,然后更新头节点为新节点。
时间复杂度:O(1)
在链表尾部插入:遍历整个链表找到尾节点,然后在尾节点之后插入新节点。
时间复杂度:O(n),因为需要遍历整个链表。
在链表中间插入:找到插入位置的前一个节点,然后调整指针以插入新节点。
时间复杂度:O(n),因为需要遍历链表直到找到插入位置。
读取(Read)
访问特定节点
需要从头节点开始遍历链表,直到找到目标节点。
时间复杂度:O(n),因为最坏情况下需要遍历整个链表。
更新(Update)
更新节点的值
需要找到目标节点,然后更新其值。
时间复杂度:O(n),因为需要遍历链表直到找到目标节点。
删除(Delete)
删除节点
删除头节点:更新头节点为当前头节点的下一个节点。
时间复杂度:O(1)
删除尾节点或中间节点:需要找到目标节点的前一个节点,然后调整指针以绕过目标节点。
时间复杂度:O(n),因为需要遍历链表直到找到目标节点的前一个节点。
其他操作
查找节点
遍历链表,直到找到具有特定值的节点。
时间复杂度:O(n),因为需要遍历整个链表。
反转链表
遍历链表,同时反转每个节点的指针方向。
时间复杂度:O(n)
class Node:def __init__(self, data):self.data = dataself.next = Noneclass LinkedList:def __init__(self):self.head = None# 创建(Create)# 在链表头部插入节点def insert_at_head(self, data):new_node = Node(data)new_node.next = self.headself.head = new_node# 在链表尾部插入节点def insert_at_tail(self, data):new_node = Node(data)if not self.head:self.head = new_nodereturncurrent = self.headwhile current.next:current = current.nextcurrent.next = new_node# 在链表中间插入节点def insert_after_node(self, prev_node_data, data):new_node = Node(data)current = self.headwhile current:if current.data == prev_node_data:new_node.next = current.nextcurrent.next = new_nodereturncurrent = current.nextprint(f"Node with data {prev_node_data} not found.")# 读取(Read)# 访问特定节点def get_node(self, index):current = self.headcount = 0while current:if count == index:return current.datacount += 1current = current.nextreturn "Index out of range."# 更新(Update)# 更新节点的值def update_node(self, old_data, new_data):current = self.headwhile current:if current.data == old_data:current.data = new_datareturncurrent = current.nextprint(f"Node with data {old_data} not found.")# 删除(Delete)# 删除头节点def delete_head(self):if self.head:self.head = self.head.nextelse:print("List is empty.")# 删除尾节点或中间节点def delete_node(self, data):if not self.head:print("List is empty.")returnif self.head.data == data:self.head = self.head.nextreturncurrent = self.headwhile current.next:if current.next.data == data:current.next = current.next.nextreturncurrent = current.nextprint(f"Node with data {data} not found.")# 其他操作# 查找节点def find_node(self, data):current = self.headwhile current:if current.data == data:return Truecurrent = current.nextreturn False# 反转链表def reverse(self):prev = Nonecurrent = self.headwhile current:next_node = current.nextcurrent.next = prevprev = currentcurrent = next_nodeself.head = prev# 打印链表def display(self):current = self.headwhile current:print(current.data, end=" -> ")current = current.nextprint("None")# 示例用法
ll = LinkedList()# 创建链表
ll.insert_at_head(1)
ll.insert_at_tail(2)
ll.insert_at_tail(3)
ll.insert_after_node(2, 4)
ll.display() # 输出: 1 -> 2 -> 4 -> 3 -> None# 读取链表
print(ll.get_node(2)) # 输出: 4# 更新链表
ll.update_node(4, 5)
ll.display() # 输出: 1 -> 2 -> 5 -> 3 -> None# 删除链表
ll.delete_head()
ll.display() # 输出: 2 -> 5 -> 3 -> None
ll.delete_node(5)
ll.display() # 输出: 2 -> 3 -> None# 查找节点
print(ll.find_node(3)) # 输出: True
print(ll.find_node(4)) # 输出: False# 反转链表
ll.reverse()
ll.display() # 输出: 3 -> 2 -> None
终端回显:
1 -> 2 -> 4 -> 3 -> None
4
1 -> 2 -> 5 -> 3 -> None
2 -> 5 -> 3 -> None
2 -> 3 -> None
True
False
3 -> 2 -> None
列表很好理解,链表其实也挺好理解的,就是手拉手的小朋友关系。实际中这种数据结构用的也挺多,虽然后端返回的字段对于前端来说都只是数据类型不一样,可能是对象,可能是大json等

实践是检验真理的唯一标准
相关文章:
Python7-数据结构
记录python学习,直到学会基本的爬虫,使用python搭建接口自动化测试就算学会了,在进阶webui自动化,app自动化 python基础7-数据结构的那些事儿 常见的数据结构有哪些?线性数据结构有哪些?非线性数据结构有哪…...

springboot指定ssl版本连接
在application.yml配置指定 server.ssl.protocolTLSv1.2结果应用依然接受低版本如TLSv1.0的连接 可以在ie浏览器:设置-Internet选项-高级,将当前连接改为TLSv1.0进行测试 这种情况可以通过增加配置仅由TLSv1.2支持的密码处理: server.ssl.…...

VTK编程指南<十二>:VTK图像数据结构及图像创建与显示
数字图像是一种重要的多媒体数据,广泛应用于工业生产、生物医学、地质、气象等重要领域。数字图像处理技术具有重要的应用价值。图像是VTK里非常重要的一种数据结构。本章重点讲解VTK在数字图像处理应用方面的相关技术。 1、VTK图像数据结构 数字图像文件内容由两个…...

EasyGBS国标GB28181平台P2P远程访问故障排查指南:客户端角度的排查思路
在现代视频监控系统中,P2P(点对点)技术因其便捷性和高效性而被广泛应用。然而,当用户在使用P2P远程访问时遇到设备不在线或无法访问的问题时,有效的排查方法显得尤为重要。本文将从客户端的角度出发,详细探…...

打造智慧医院挂号枢纽:SSM 与 Vue 融合的系统设计与实施
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

网络编程 02:IP 地址,IP 地址的作用、分类,通过 Java 实现 IP 地址的信息获取
一、概述 记录时间 [2024-12-18] 前置文章:网络编程 01:计算机网络概述,网络的作用,网络通信的要素,以及网络通信协议与分层模型 本文讲述网络编程相关知识——IP 地址,包括 IP 地址的作用、分类ÿ…...
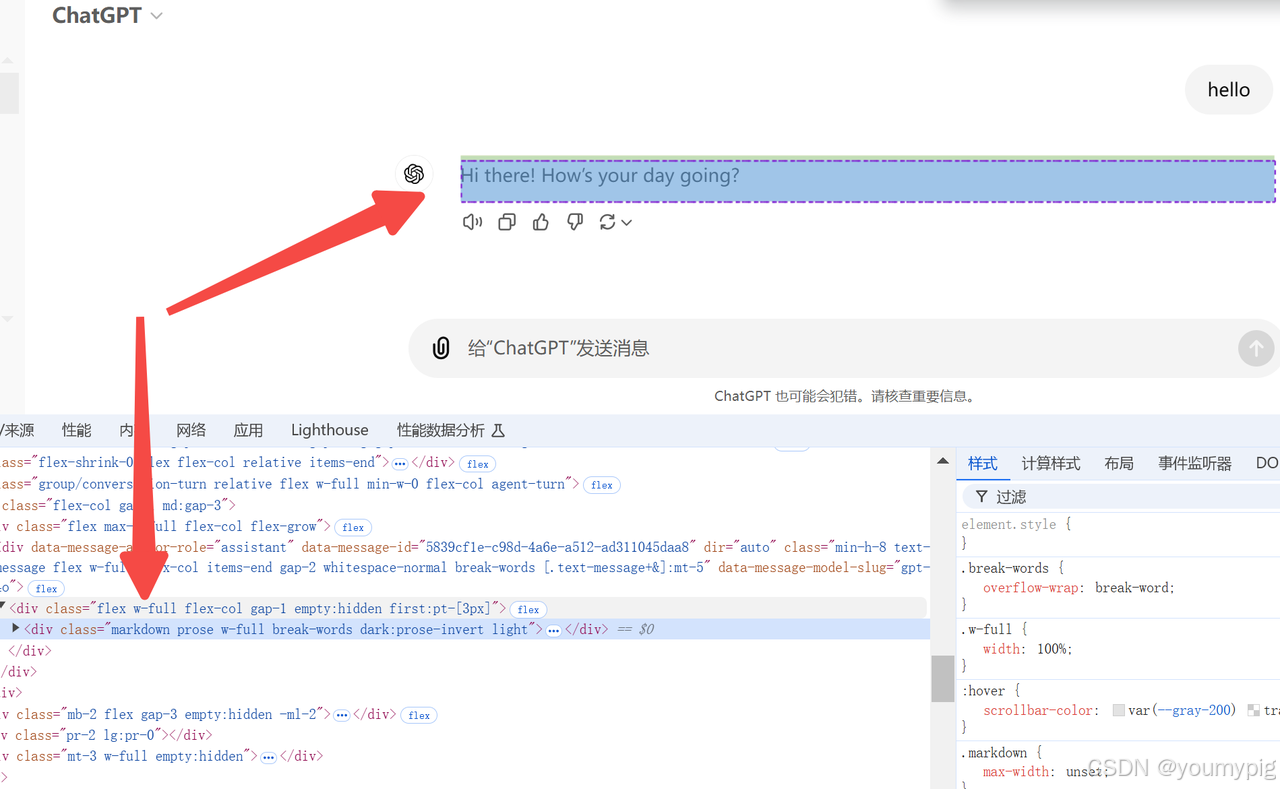
如何使用Python WebDriver爬取ChatGPT内容(完整教程)
大背景 虽然我们能用网页版chatGPT来聊天、写文章,但是我们采集大量的内容,就得不断地手动输入提问来获取答案,并且将结果复制到数据库来保存。如果整个过程能使用程序来做自然要节省很多的人力,精力和时间。 Python webdirver …...

WSL切换默认发行版
查看适用于wsl的子系统有哪些: wslconfig /list 设置wsl的默认发行版 wslconfig /setdefault Ubuntu-20.04...

全志H618 Android12修改doucmentsui功能菜单项
背景: 由于当前的文件管理器在我们的产品定义当中,某些界面有改动的需求,所以需要在Android12 rom中进行定制以符合当前产品定义。 需求: 在进入File文件管理器后,查看...功能菜单时,有不需要的功能菜单,需要隐藏,如:新建窗口、不显示的文件夹、故代码分析以及客制…...

移动网络(2,3,4,5G)设备TCP通讯调试方法
背景: 当设备是移动网络设备连接云平台的时候,如果服务器没有收到网络数据,移动物联设备发送不知道有没有有丢失数据的时候,需要一个抓取设备出来的数据和服务器下发的数据的方法。 1.服务器系统是很成熟的,一般是linu…...

网络安全概论——入侵检测系统IDS
一、入侵检测的概念 1、入侵检测的概念 检测对计算机系统的非授权访问对系统的运行状态进行监视,发现各种攻击企图、攻击行为或攻击结果,以保证系统资源的保密性、完整性和可用性识别针对计算机系统和网络系统或广义上的信息系统的非法攻击,…...

Linux通信System V:消息队列 信号量
Linux通信System V:消息队列 & 信号量 一、信号量概念二、信号量意义三、操作系统如何管理ipc资源(2.36版本)四、如何对信号量资源进行管理 一、信号量概念 信号量本质上就是计数器,用来保护共享资源。多个进程在进行通信时&a…...

计算机网络基础图解
注:本文为来自 猿小许 的 “计算机网络” 相关系列文章合辑。 一、计算机网络概述 猿小许于 2021-06-03 18:39:47 发布 一、计算机网络的概念 1.1 计算机网络 概念 计算机网络: 是一个将分散的、具有独立功能的计算机系统,通过通信设备与…...

TDesign:NavBar 导航栏
NavBar 导航栏 左图,右标 appBar: TDNavBar(padding: EdgeInsets.only(left: 0,right: 30.w), // 重写左右内边距centerTitle:false, // 不显示标题height: 45, // 高度titleWidget: TDImage( // 左图assetUrl: assets/img/logo.png,width: 147.w,height: 41.w,),ba…...

hive注释comment中文乱码解决
问题描述 当使用以下命令查看表的元数据信息时出现中文乱码(使用的是idea连接hive) desc formatted test.t_archer; 解决 连接保存hive元数据的MySQL数据库,执行以下命令: use hive3; show tables;alter table hive3.COLUMNS_…...

电脑提示ntdll.d缺失是什么原因?不处理的话会怎么样?ntdll.dll文件缺失快速解决方案来啦!
电脑提示ntdll.dll缺失:原因、影响与解决方案 在日常的电脑使用中,我们偶尔会遇到一些令人困惑的系统错误,其中“ntdll.dll缺失”便是较为常见的一种。作为软件开发从业者,我深知这一错误给用户带来的不便,因此&#…...

MFC/C++学习系列之简单记录——序列化机制
MFC/C学习系列之简单记录——序列化机制 前言简述六大机制序列化机制使用反序列化总结 前言 MFC有六大机制,分别是程序启动机制、窗口创建机制、动态创建机制、运行时类信息机制、消息映射机制、序列化机制。 简述六大机制 程序启动机制:全局的应用程序…...
二十、服务发布Ingress
Ingress Kubernetes使用了一个Ingress策略定义和一个具体提供转发服务的Ingress Controller,两者结合,实现了基于灵活Ingress策略定义的服务路由功能。如果是对Kubernetes集群外部的客户端提供服务,那么IngressController实现的是类似于边缘路由器(Edge Router)的功能。需…...

计算机网络 八股青春版
什么是HTTP?HTTP和HTTPS的区别 HTTP HTTP是超文本运输协议,是一种无状态(每次请求都是独立的)的应用层协议。用于在客户端和服务器之间传输超文本数据(如HTML文件)。默认端口是80数据以明文形式传输&#…...

java全栈day18--Web后端实战(java操作数据库2)
前言:在上节入门程序当中我们见到了JDBC所提供的API,本节来详细说明一下。 一、JDBC--API详解 1.1DriverManager(驱动管理器) 回顾:作用获取连接,调用它里面的getConnection。即如下 作用 1.注册驱动解…...

指纹采集器模块选型指南|如何选择合适的指纹采集模块
在做指纹门禁、指纹考勤、指纹保险箱或嵌入式终端时, 指纹采集器模块几乎是整个系统的核心。 模块选对了,项目推进顺畅;选错了,后期调试、售后问题不断。 本文不讲复杂参数,只从实际应用出发, 用最通俗的方…...

2026年最容易上手的5个AI副业
前言: 2026年,AI工具已经彻底改变了副业的门槛。过去需要3-5年积累的技能,借助AI可能只需3-5周就能开始接单赚钱。 这篇文章精选了5个最容易上手、最快出收益的AI副业方向,每个方向都附上了具体操作路径。 一、为什么现在是做AI副业的最好时机? 三个关键信号: 需求爆发…...

ARM P-Channel接口设计与低功耗SoC电源管理实践
1. ARM P-Channel接口深度解析在低功耗SoC设计中,电源管理接口的可靠性和时序一致性直接决定了系统的能效表现。ARM P-Channel作为专为电源管理设计的标准化接口协议,通过独特的四阶段握手机制,为设备与电源控制器之间建立了高效的状态协商通…...

taotoken用量看板如何帮助项目管理者精细化追踪api成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken用量看板如何帮助项目管理者精细化追踪api成本 对于依赖大模型API进行开发的项目团队而言,成本控制始终是一个…...

工位是公司的,腰是自己的:00后正在重塑职场观
来自:推荐一个程序员编程资料站:http://cxyroad.com副业赚钱专栏:https://xbt100.top2024年IDEA最新激活方法后台回复:激活码CSDN免登录复制代码插件下载:CSDN复制插件以下是正文。我是小路。最近看到一个特别有意思的…...

CrapFixer深度解析:为什么这个7年老工具依然是Windows优化的首选
CrapFixer深度解析:为什么这个7年老工具依然是Windows优化的首选 【免费下载链接】Crapfixer Cr*ap Fixer 项目地址: https://gitcode.com/gh_mirrors/cr/Crapfixer 在Windows 11和Windows 10系统中,你是否厌倦了无处不在的广告、烦人的数据收集和…...

昇腾C解交织API文档
DeInterleave 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...

5分钟掌握HTML转Word:html-to-docx让文档格式转换变得简单高效
5分钟掌握HTML转Word:html-to-docx让文档格式转换变得简单高效 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx 还在为HTML内容无法完美转换为Word文档而烦恼吗?html-to-docx是…...

5分钟快速上手Kafka-UI:开源Kafka集群管理工具完整指南
5分钟快速上手Kafka-UI:开源Kafka集群管理工具完整指南 【免费下载链接】kafka-ui Open-Source Web UI for managing Apache Kafka clusters 项目地址: https://gitcode.com/gh_mirrors/kaf/kafka-ui Apache Kafka作为现代数据架构的核心组件,其集…...

CH340G模块除了下载程序,还能这么玩?一个硬件调试小技巧分享
CH340G模块的隐藏技能:用串口调试提升硬件开发效率 当你拿到一片CH340G模块时,第一反应可能是"这是个下载程序的好工具"。确实,这个价格亲民的小模块在51单片机开发中扮演着重要角色。但今天,我要分享的是它另一个被低估…...